Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
正則化とロジスティック回帰/machine-learning-lecture-regulari...
Search
Hiroka Zaitsu
July 16, 2020
Technology
9.2k
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
正則化とロジスティック回帰/machine-learning-lecture-regularization-and-logistic-regression
GMOペパボ新卒研修2020 機械学習入門 補足資料#04 #05
Hiroka Zaitsu
July 16, 2020
More Decks by Hiroka Zaitsu
See All by Hiroka Zaitsu
データで人の行動を変える - ペパボのデータ基盤 Bigfoot - / Driving Behavior Change with Data - Bigfoot: Pepabo's Data Platform
zaimy
0
20
AI が Approve する開発フロー / How AI Reviewers Accelerate Our Development
zaimy
1
380
Agent Ready になるためにデータ基盤チームが今年やること / How We're Making Our Data Platform Agent-Ready
zaimy
0
280
GMOペパボのデータ基盤とデータ活用の現在地 / Current State of GMO Pepabo's Data Infrastructure and Data Utilization
zaimy
3
410
ビジネス職が分析も担う事業部制組織でのデータ活用の仕組みづくり / Enabling Data Analytics in Business-Led Divisional Organizations
zaimy
1
850
Vertex AI Matching Engine と CLIP を使って EC サービスの類似画像検索機能を作る / Development of similar image search function for EC services using Vertex AI Matching Engine and CLIP
zaimy
0
810
BigQuery の日本語データを Dataflow と Vertex AI でトピックモデリング / Topic modeling of Japanese data in BigQuery with Dataflow and Vertex AI
zaimy
1
6.4k
データサイエンティストの仕事紹介 / Data Scientist Job Introduction
zaimy
1
680
GMOペパボのサービスと研究開発を支えるデータ基盤の裏側 / Inside Story of Data Infrastructure Supporting GMO Pepabo's Services and R&D
zaimy
1
1.9k
Other Decks in Technology
See All in Technology
公式ドキュメントの歩き方etc
coco_se
1
120
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
310
Oracle Base Database Service 技術詳細
oracle4engineer
PRO
15
110k
CDKで書くECSのベストプラクティス、 改めて考え直す2026 #cdkconf2026
makies
3
760
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
260
“それは自分の仕事じゃない"を 越えて行け
yuukiyo
1
470
シンガポールで登壇してきます
yama3133
0
240
ファミコンでPHPを動かす / PHP on the Famicom
tomzoh
2
330
10年目を迎えた「ABEMA」がどのように AI 活用を推進して、AI 駆動開発にシフトしているのか / How ABEMA, entering its 10th year, is promoting the use of AI and shifting toward AI-driven development
miyukki
0
250
「AIに依存している」と 「AIを使いこなしている」の違い
k8yasuma
0
110
AI Coding Agent時代のcdk-nagガードレール 〜組織ルールを強制CIで守り抜く設計の挑戦〜
mhrtech
3
390
SRE依存からの脱却 運用を開 発チームへ移す、 フルサイ クル開 発体制の実践
joooee0000
0
3.1k
Featured
See All Featured
How STYLIGHT went responsive
nonsquared
100
6.2k
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
330
Keith and Marios Guide to Fast Websites
keithpitt
413
23k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Navigating the Design Leadership Dip - Product Design Week Design Leaders+ Conference 2024
apolaine
1
370
エンジニアに許された特別な時間の終わり
watany
108
250k
Joys of Absence: A Defence of Solitary Play
codingconduct
1
410
The Impact of AI in SEO - AI Overviews June 2024 Edition
aleyda
5
1.1k
Tips & Tricks on How to Get Your First Job In Tech
honzajavorek
1
590
AI Search: Implications for SEO and How to Move Forward - #ShenzhenSEOConference
aleyda
1
1.3k
実際に使うSQLの書き方 徹底解説 / pgcon21j-tutorial
soudai
PRO
201
75k
B2B Lead Gen: Tactics, Traps & Triumph
marketingsoph
0
170
Transcript
1 正則化と ロジスティック回帰 ペパボ研究所 財津大夏 新卒研修 機械学習入門 補足資料 #04 #05
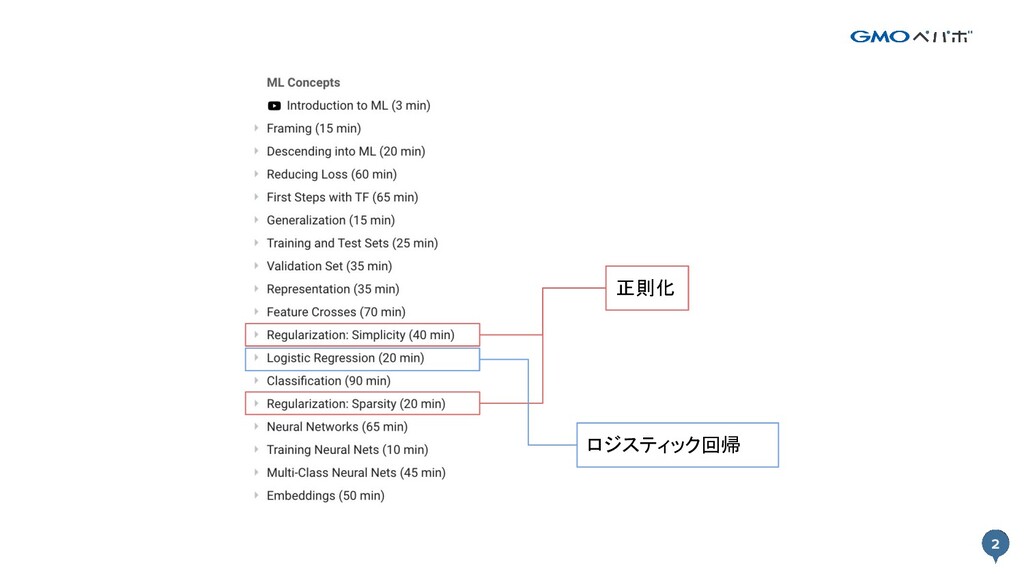
2 2 正則化 ロジスティック回帰
3 正則化 Section 1 3 Regularization
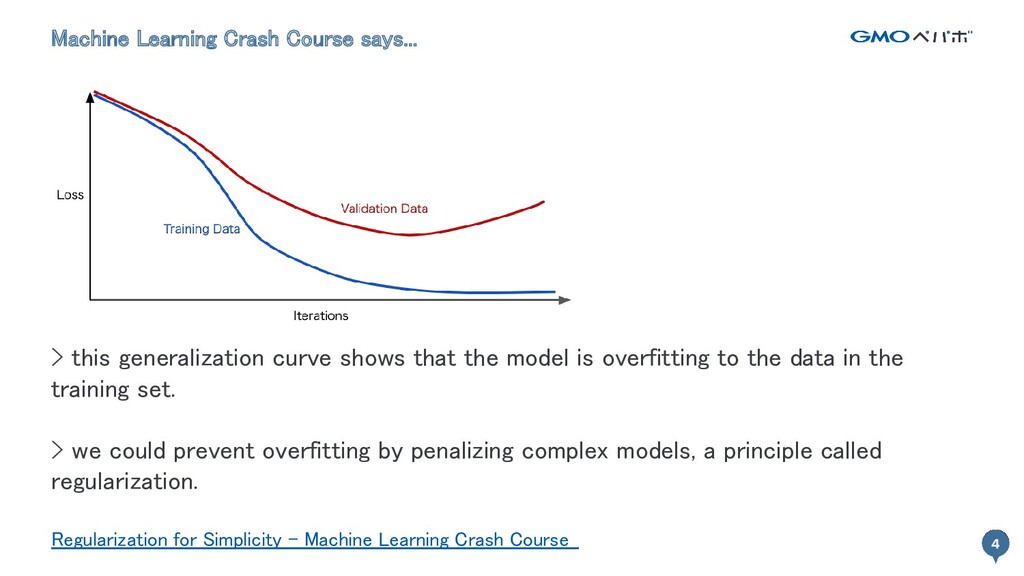
4 Machine Learning Crash Course says... 4 > this generalization
curve shows that the model is overfitting to the data in the training set. > we could prevent overfitting by penalizing complex models, a principle called regularization. Regularization for Simplicity - Machine Learning Crash Course
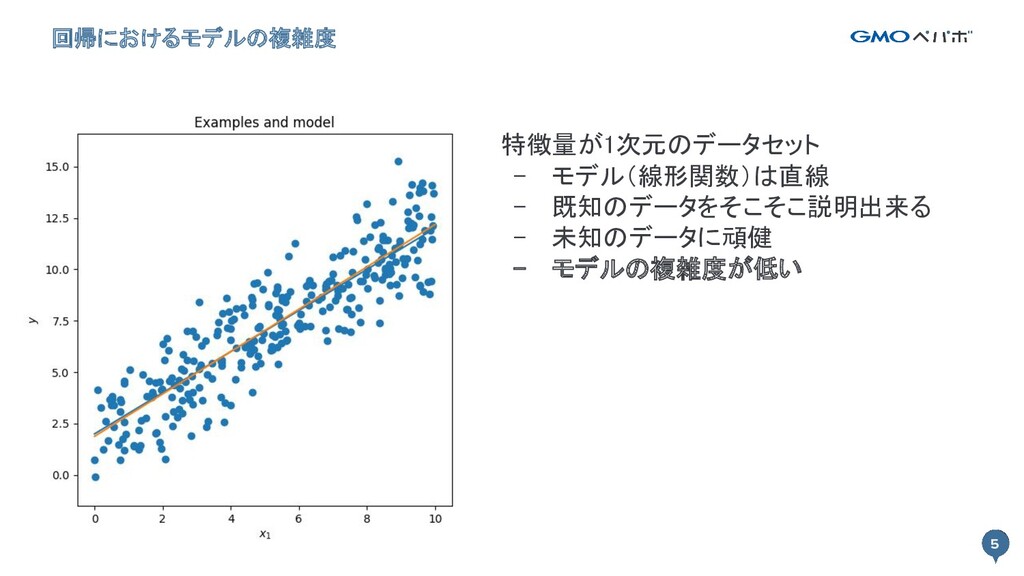
5 回帰におけるモデルの複雑度 5 特徴量が1次元のデータセット - モデル(線形関数)は直線 - 既知のデータをそこそこ説明出来る - 未知のデータに頑健
- モデルの複雑度が低い
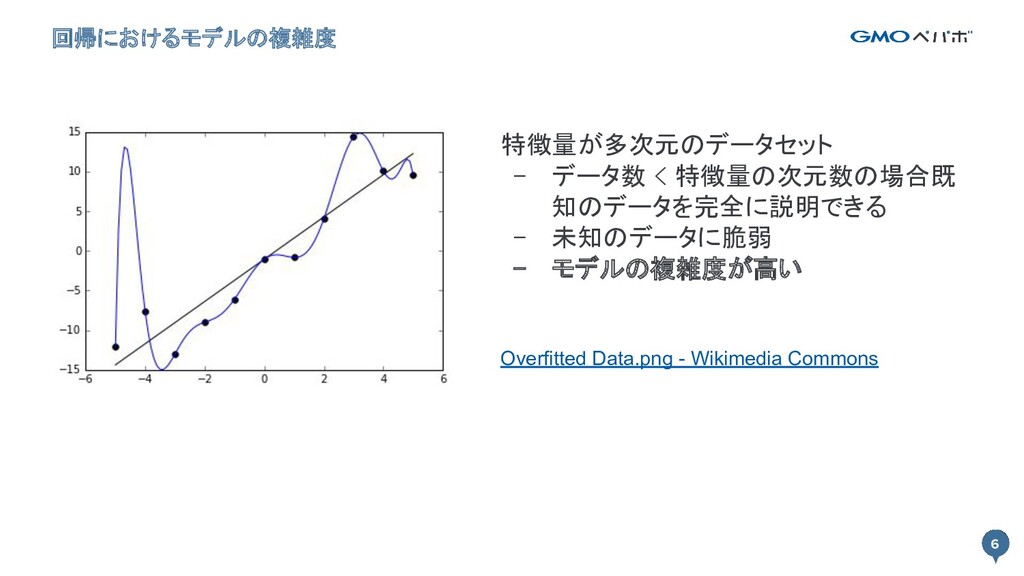
6 回帰におけるモデルの複雑度 6 特徴量が多次元のデータセット - データ数 < 特徴量の次元数の場合既 知のデータを完全に説明できる -
未知のデータに脆弱 - モデルの複雑度が高い Overfitted Data.png - Wikimedia Commons
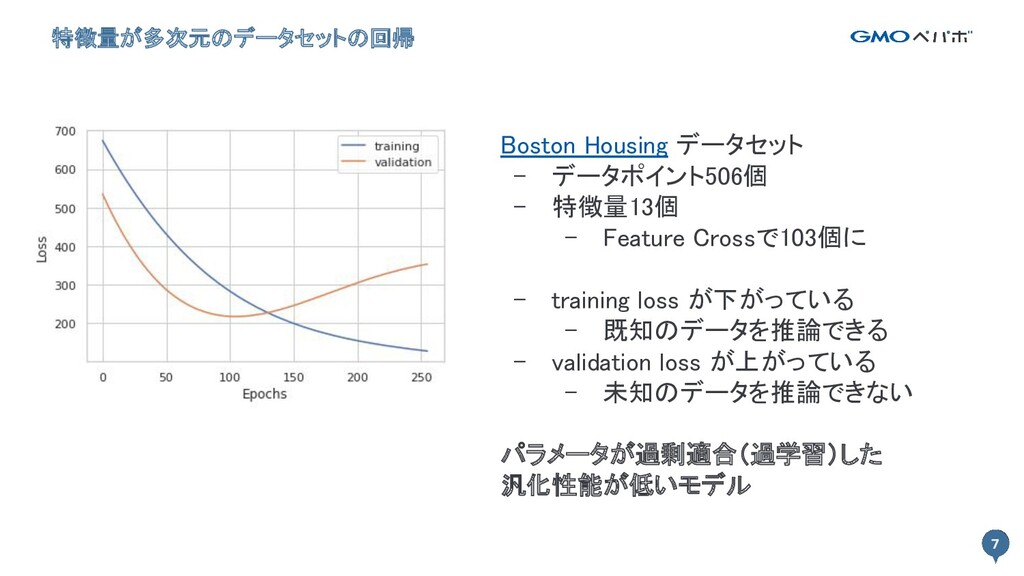
7 特徴量が多次元のデータセットの回帰 7 Boston Housing データセット - データポイント506個 - 特徴量13個
- Feature Crossで103個に - training loss が下がっている - 既知のデータを推論できる - validation loss が上がっている - 未知のデータを推論できない パラメータが過剰適合(過学習)した 汎化性能が低いモデル
8 正則化 8
9 過学習を防ぐためのアプローチ 9 - 過学習したモデルはトレーニングデータに過剰適合したパラメータを持つ - 誤差関数にトレーニングデータ以外の制約を加えて過学習を防ぐ - 特徴量のパラメータ自体を小さくするように学習させる -
パラメータの大きさはノルムで表現できる w1 w2 L1ノルム L2ノルム n=2 のとき
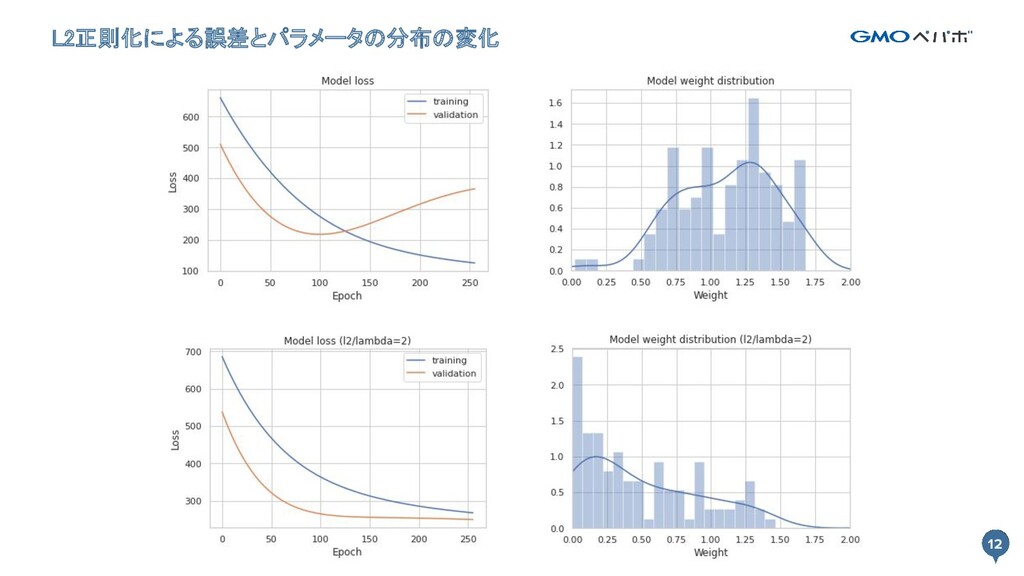
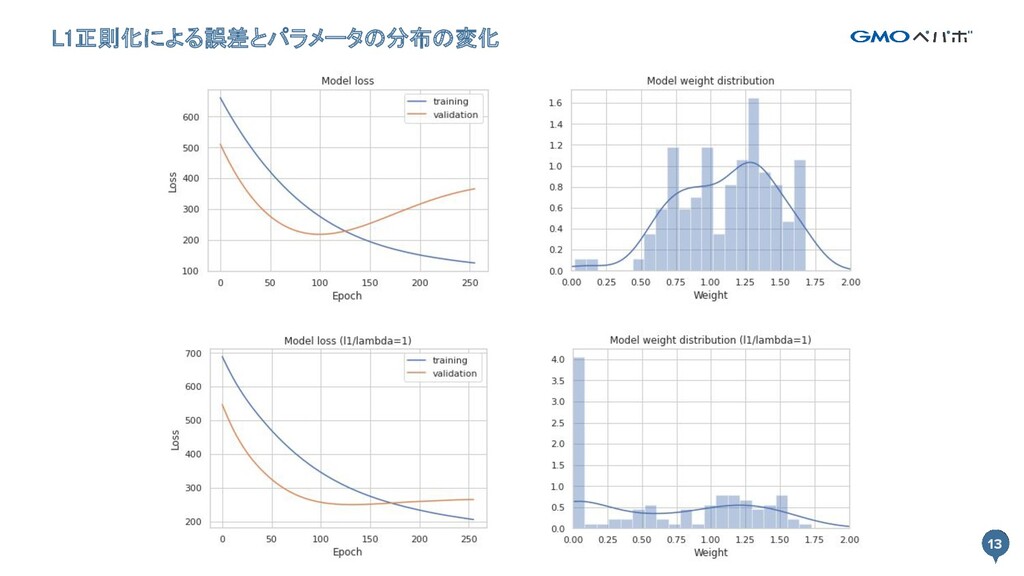
10 誤差関数にパラメータのノルムを加える 10 - 誤差関数に制約条件を加える a. トレーニングデータに対する推論の誤差を小さくする(既存の条件) b. パラメータのノルムを小さくする -
個別の特徴量が出力に与える影響が小さくなる - トレーニングデータに対する性能が下がるが汎化性能が上がる - L2ノルムで正則化するとリッジ回帰(Ridge Regression) - L1ノルムで正則化するとラッソ回帰(Lasso Regression) 制約条件a 制約条件b
11 L2正則化した誤差関数の導関数 11
12 L2正則化による誤差とパラメータの分布の変化 12
13 L1正則化による誤差とパラメータの分布の変化 13
14 まとめ - 正則化によりモデルの複雑度を下げて汎化性能を上げる - L2正則化とL1正則化 - L2正則化 - パラメータの絶対値が小さくなる
- 解析的に解ける(微分可能) - L1正則化 - パラメータの一部が0になる - 特徴量選択に利用できる - 解析的に解けないので推定で求める - L2正則化とL1正則化を組み合わせた ElasticNet もある - いずれかの正則化が常に優れているということはない 14
15 ロジスティック回帰 Section 2 15 Logistic Regression
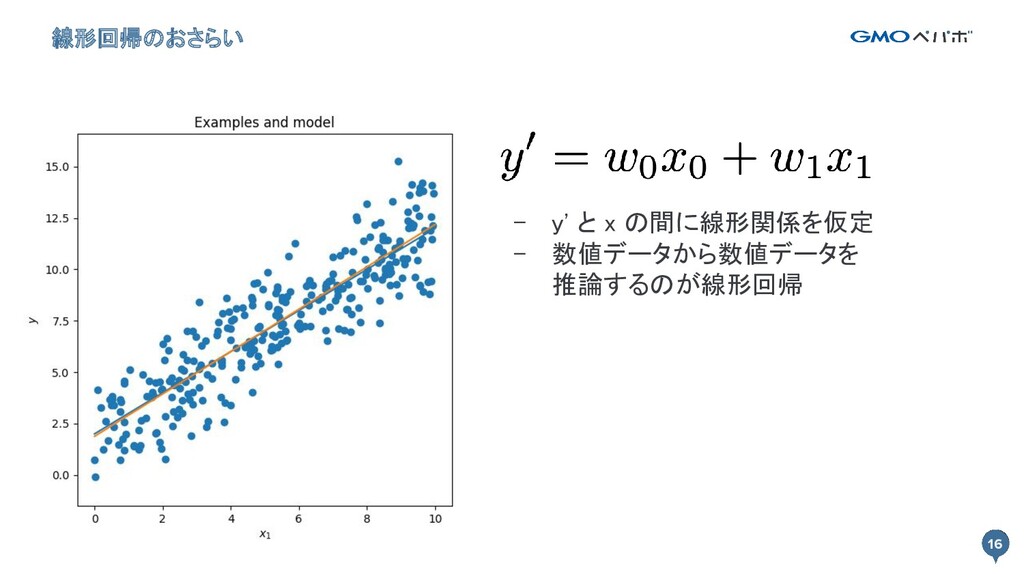
16 - y' と x の間に線形関係を仮定 - 数値データから数値データを 推論するのが線形回帰 線形回帰のおさらい
16
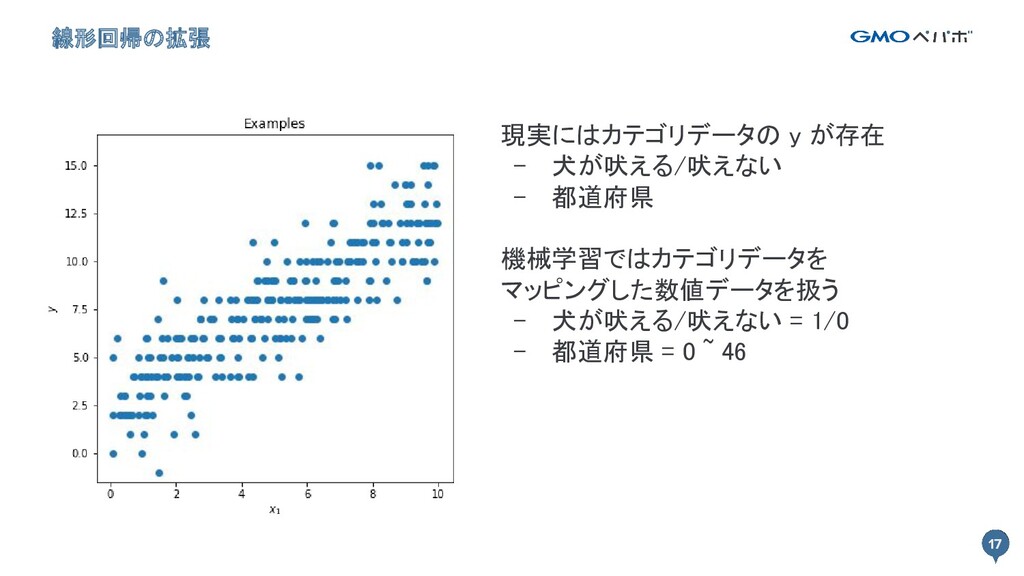
17 線形回帰の拡張 17 現実にはカテゴリデータの y が存在 - 犬が吠える/吠えない - 都道府県
機械学習ではカテゴリデータを マッピングした数値データを扱う - 犬が吠える/吠えない = 1/0 - 都道府県 = 0 ~ 46
18 カテゴリデータをマッピングした y を線形回帰すると... 18 都道府県 { y ∈ N
| 0 ≦ y ≦ 46 } の場合 x の値によって y' ≧ 47 になる - カテゴリデータ y の値は x の値により 線形に変化しない - カテゴリデータをマッピングした 数値に数値としての意味はない - カテゴリデータは線形回帰できない
19 やりたいこと 19 カテゴリデータで表現される y を推論したい ロジスティック回帰の方針 1. 事象が起きる確率
p を出力する 2. p を任意の閾値と比較することで y' を推論する
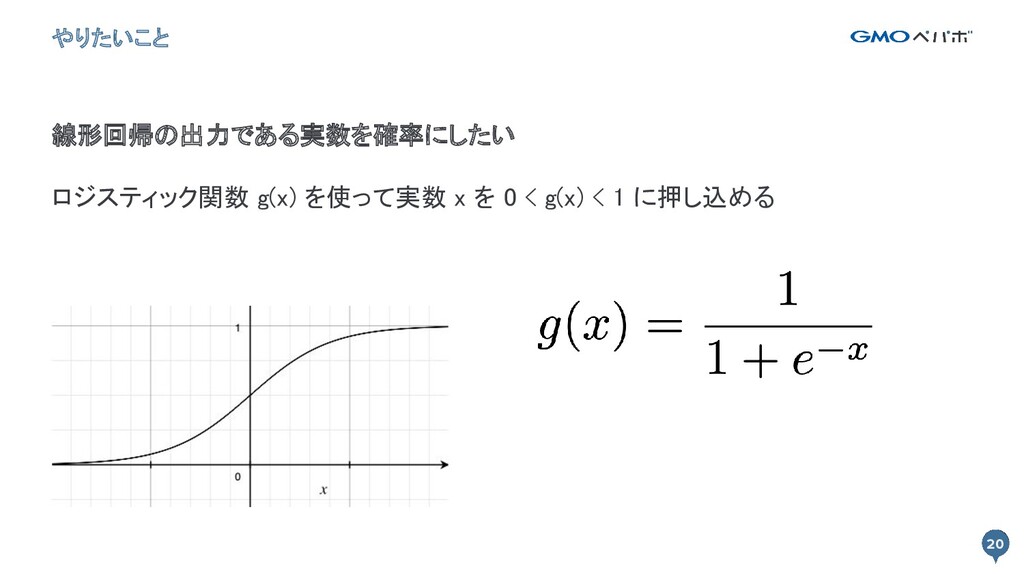
20 やりたいこと 20 線形回帰の出力である実数を確率にしたい ロジスティック関数 g(x) を使って実数 x を
0 < g(x) < 1 に押し込める
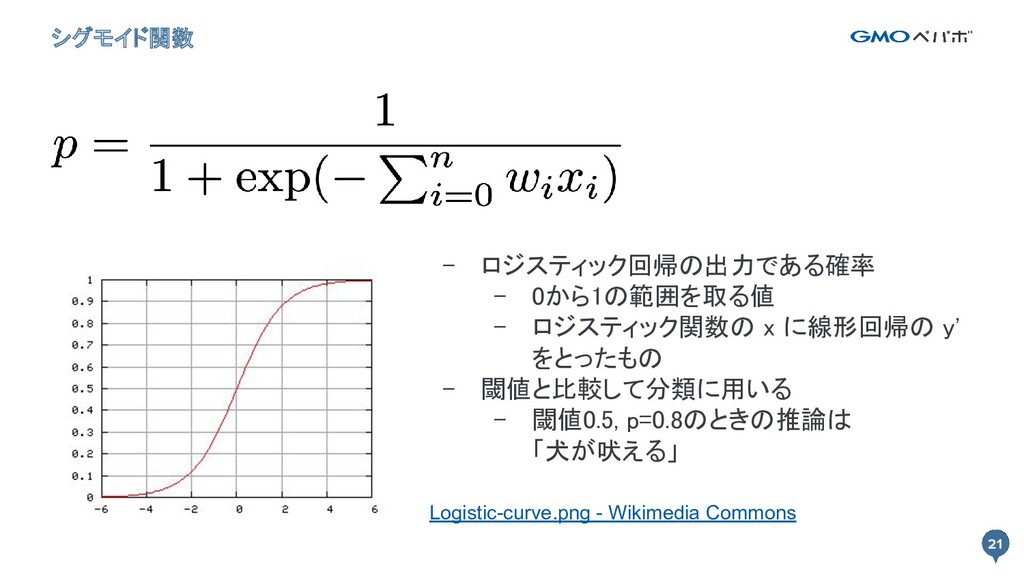
21 シグモイド関数 21 - ロジスティック回帰の出力である確率 - 0から1の範囲を取る値 - ロジスティック関数の x
に線形回帰の y' をとったもの - 閾値と比較して分類に用いる - 閾値0.5, p=0.8のときの推論は 「犬が吠える」 Logistic-curve.png - Wikimedia Commons
22 ロジスティック回帰の誤差関数(1) 22 - ロジスティック回帰の y はカテゴリデータ - y の変化量が定まらないので最小二乗法が使えない
- 数値 x が1変化した時のカテゴリ y の変化量? - 二値のカテゴリ変数は確率変数 k をとるベルヌーイ分布に従う - 「ある事象が起きる」/「起きない」 - 多値分類の場合はある値とそれ以外の値の二値分類の組み合わせ
23 ロジスティック回帰の誤差関数(2) 23 - 最小二乗法ではなく最尤法を使う - 最も尤もらしい確率分布を求める - パラメータθに従う確率分布にデータが従っている度合いが尤度 -
尤度関数 L(θ) の対数を取って和の形にする(対数尤度関数)
24 まとめ 24 - ロジスティック回帰ではカテゴリデータを扱うために線形回帰を拡張する - 線形回帰の出力をロジスティック関数で変換して確率として扱う - ロジスティック関数の x
に線形回帰の出力を取るシグモイド関数 - 出力される確率に閾値を定めて分類問題に利用する - ロジスティック回帰のパラメータθは最尤法により求める - 数値 x が1変化した時のカテゴリ y の変化量を求めづらいため - 機械学習では負の対数尤度を誤差として利用する
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}