Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
BigQuery の日本語データを Dataflow と Vertex AI でトピックモデリ...
Search
Hiroka Zaitsu
April 20, 2022
Technology
6.4k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
BigQuery の日本語データを Dataflow と Vertex AI でトピックモデリング / Topic modeling of Japanese data in BigQuery with Dataflow and Vertex AI
2022.04.20 Data Engineering Meetup 【ZOZO × GMOペパボ】
https://pepabo.connpass.com/event/242688/
Hiroka Zaitsu
April 20, 2022
More Decks by Hiroka Zaitsu
See All by Hiroka Zaitsu
データで人の行動を変える - ペパボのデータ基盤 Bigfoot - / Driving Behavior Change with Data - Bigfoot: Pepabo's Data Platform
zaimy
0
20
AI が Approve する開発フロー / How AI Reviewers Accelerate Our Development
zaimy
1
380
Agent Ready になるためにデータ基盤チームが今年やること / How We're Making Our Data Platform Agent-Ready
zaimy
0
280
GMOペパボのデータ基盤とデータ活用の現在地 / Current State of GMO Pepabo's Data Infrastructure and Data Utilization
zaimy
3
410
ビジネス職が分析も担う事業部制組織でのデータ活用の仕組みづくり / Enabling Data Analytics in Business-Led Divisional Organizations
zaimy
1
850
Vertex AI Matching Engine と CLIP を使って EC サービスの類似画像検索機能を作る / Development of similar image search function for EC services using Vertex AI Matching Engine and CLIP
zaimy
0
810
データサイエンティストの仕事紹介 / Data Scientist Job Introduction
zaimy
1
680
GMOペパボのサービスと研究開発を支えるデータ基盤の裏側 / Inside Story of Data Infrastructure Supporting GMO Pepabo's Services and R&D
zaimy
1
1.9k
正則化とロジスティック回帰/machine-learning-lecture-regularization-and-logistic-regression
zaimy
0
9.2k
Other Decks in Technology
See All in Technology
ruby.wasmとPicoRuby.wasmに対応した仮想DOMライブラリを作ってる話 #kaigieffect_kaigi
sue445
PRO
0
150
ガバナンスの「ちょうどいい落とし所」を探れ!開発スピードを妨げない運用判断の勘所 / SRE NEXT 2026
genda
1
220
Amazon EVS で VCF 9.0 / 9.1 のサポート開始まとめ
mtoyoda
0
310
企業でAWS Organizationsを動かすための組織設計の考え方
nrinetcom
PRO
1
100
「ちゃんとやっている」は独りよがりだった ― 不安に寄り添うインシデント対応へ / Towards incident response that addresses anxieties
chmikata
1
5.8k
関数型の考えを TypeScript に持ち込んで、テストしやすい純粋関数を増やす / Pure at the Core, Effects at the Edge: Bringing Functional Thinking into TypeScript
kaminashi
2
130
Data + AI Summit 2026 イベントレポート: 「AIがビジネスで意思決定するデータ基盤」へ
nek0128
0
250
[2026-07-15] AI Ready なはずだったアーキテクチャと、見えてきた課題・次に目指す状態
wxyzzz
9
3.9k
公式ドキュメントの歩き方etc
coco_se
1
120
シンガポールで登壇してきます
yama3133
0
240
End-to-Endで考える信頼性 — LINEアプリにおける クライアント開発×SRE連携の実践
maruloop
4
4.5k
タスクの複雑さでモデルを選ぶ ── Thompson Samplingで動かす“トークン/コスト最適化
satohy0323
0
540
Featured
See All Featured
10 Git Anti Patterns You Should be Aware of
lemiorhan
PRO
659
62k
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Navigating Weather and Climate Data
rabernat
0
350
HTML-Aware ERB: The Path to Reactive Rendering @ RubyCon 2026, Rimini, Italy
marcoroth
2
330
How to Think Like a Performance Engineer
csswizardry
28
2.7k
Fight the Zombie Pattern Library - RWD Summit 2016
marcelosomers
234
17k
How GitHub (no longer) Works
holman
316
150k
Accessibility Awareness
sabderemane
1
150
Facilitating Awesome Meetings
lara
57
7k
AI in Enterprises - Java and Open Source to the Rescue
ivargrimstad
0
1.4k
Money Talks: Using Revenue to Get Sh*t Done
nikkihalliwell
0
380
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
490
Transcript
BigQuery の日本語データを Dataflow と Vertex AI で トピックモデリング 財津 大夏
/ GMO PEPABO inc. 2022.04.20 Data Engineering Meetup 1
2 自己紹介 技術部 データ基盤チーム 2012年 入社 • データサイエンティスト • ペパボのデータ基盤「Bigfoot」の開発/運用
• Bigfoot を使ったデータ分析/活用 • Twitter : @HirokaZaitsu #データ基盤 #DataOps #MLOps #Python #SQL #統計学 #機械学習 #スバル #Fallout 財津 大夏 Hiroka Zaitsu
3 アジェンダ 1. BigQuery 使ってますか? 2. BigQuery に保存した日本語データのトピックモデリング 1. トピックモデリングとは
2. 必要なものと BigQuery での制限 3. 今回の構成 1. Dataflow で形態素解析 2. Vertex AI でトピックモデリング 3. Cloud Composer でオーケストレーション 4. まとめと今後の展望
4 1. BigQuery 使ってますか?
BigQuery 使ってますか? 5 • フルマネージド型の分析データウェアハウス • オンデマンド課金で安い(一部定額課金にすることも可能) • 大量のデータに対して標準SQLで高速に集計可能 •
タイムマシンや列レベルセキュリティなどDWHを運用する上でありがたい機能が色々 → ペパボではデータ基盤「Bigfoot」のDWHとして使っています Google Cloud BigQuery
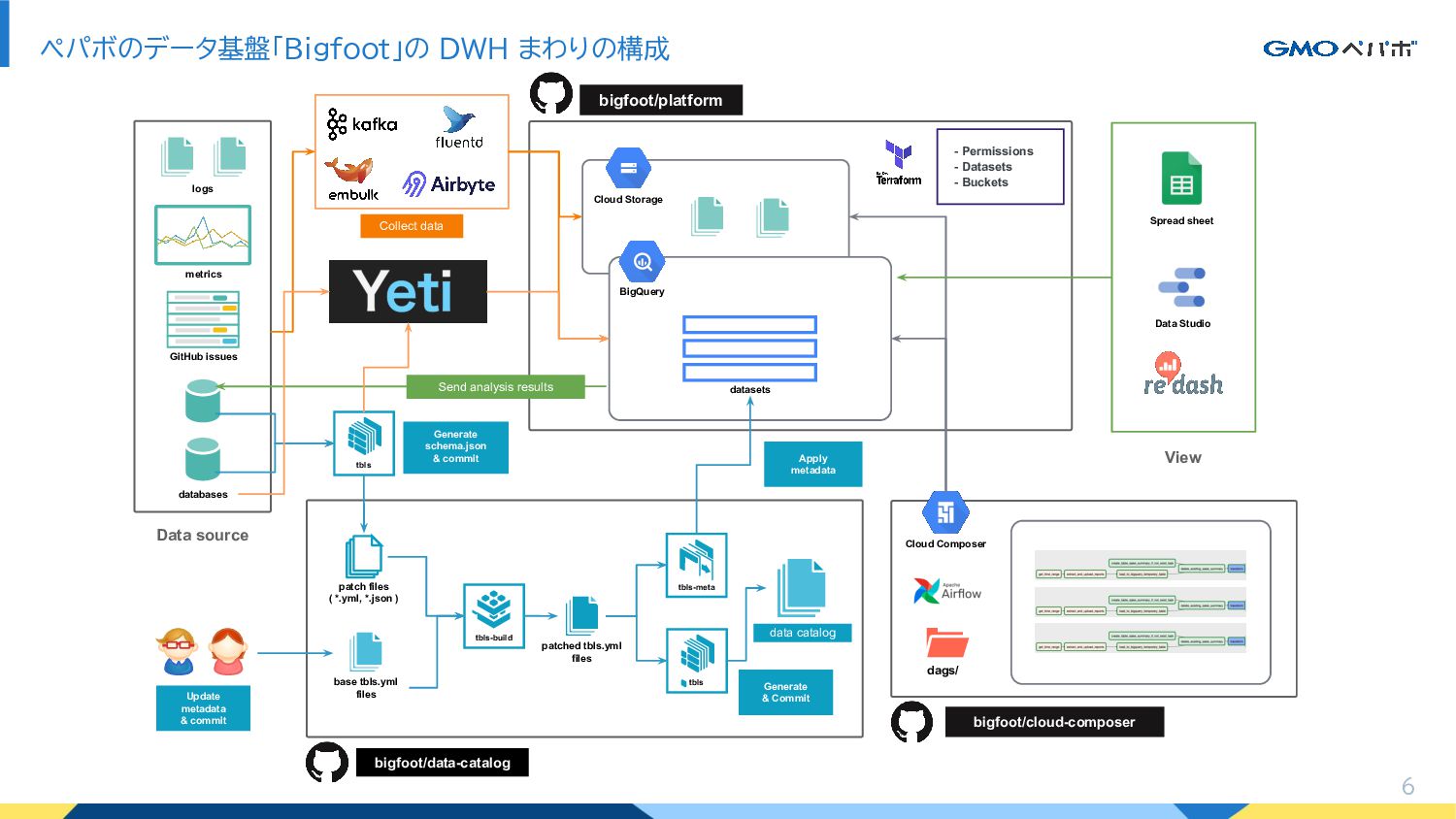
ペパボのデータ基盤「Bigfoot」の DWH まわりの構成 6 Data source logs metrics GitHub issues
databases Collect data tbls datasets BigQuery bigfoot/platform Cloud Storage - Permissions - Datasets - Buckets Data Studio bigfoot/cloud-composer Cloud Composer dags/ tbls-build base tbls.yml files patch files ( *.yml, *.json ) patched tbls.yml files tbls-meta tbls data catalog Apply metadata Generate & Commit Generate schema.json & commit bigfoot/data-catalog Update metadata & commit Spread sheet View Send analysis results
BigQuery 使ってますか? 7 • データの種類 • サービス利用者の行動ログのデータ • サービスのデータベースから ELT
したデータ • その他, 広告やお問い合わせなどのデータ • パイプライン構成 • Yeti や Airbyte, SaaS の ELT ツール と Cloud Composer で ELT や集計を行う • 集計結果をダッシュボードや BI ツール, サービスのシステムから利用 • 生データや集計結果を機械学習モデルの入力データとして使用 👈 ここの話をします ペパボで BigQuery に保存しているデータ
8 2. BigQuery に保存した 日本語データのトピックモデリング
BigQuery に保存した日本語データのトピックモデリング 9 • データの潜在的なトピック(話題や分野)を教師なしで確率的に推定するモデル • 文章への適用例が多いが画像や音声にも適用可能 • 文章の場合は語のトピックを推定 →
文章に含まれる語から文章のトピックを推定 • Python だと gensim に LDA アルゴリズムの実装がある • TensorFlow Probability にも LDA の参考実装 トピックモデリングとは 画像は “Latent Dirichlet Allocation”. David M.Blei, Andrew Y.Ng, Michael I.Jordan. Journal of Machine Learning Research, vol.3, pp.993-1022, 2003. より引用 (参考)統計数理研究所 H24年度公開講座「確率的トピックモデル」 https://www.ism.ac.jp/~daichi/lectures/H24-TopicModel/ISM-2012-TopicModels-daichi.pdf
• 推薦 • 現在閲覧している商品や記事と同じトピックの商品を推薦して回遊率を高める • 検索 • 直近の閲覧履歴に基づいてユーザーが好む(と思われる)トピックの商品を上位に表示して CTR を高める
→ ペパボが運営するハンドメイド EC の minne で トピックモデリングをやりたい BigQuery に保存した日本語データのトピックモデリング 10 ウェブサービスでのトピックモデリングの用途の例 minne.com での推薦のイメージ
• トピックモデリングは語のトピックを推定する • 文章から語(形態素)への分解が必要 • 英語など語をスペースで区切る言語の場合は(語形を無視すれば)スペースで分割できる • 日本語は機械的な区切りが文章中に存在しないので形態素解析器を使う • 今回はサービスで既に利用している
Kuromoji を使いたい • 不要な語の除去なども重要 BigQuery に保存した日本語データのトピックモデリング 11 トピックモデリングに必要な前処理 mecab (http://taku910.github.io/mecab/) を用いた形態素解析の例
BigQuery に保存した日本語データのトピックモデリング 12 • 高速かつ関数も豊富なので集計や簡単な文字列操作による前処理ができる • 正規化, ストップワードの除去, 語の出現頻度による除去など •
Javascript UDF が利用可能 • 外部ライブラリを使って日本語の形態素解析も出来る • 但しコードリソースの最大サイズ 1MB の制約があり形態素解析の場合は TinySegmenter(MeCab + ipadic 互換)でないと実行が難しい 必要な前処理を BigQuery で行うことを考える TinySegmenter: http://chasen.org/~taku/software/TinySegmenter/
• やりたいこと: BigQuery に保存した日本語データをトピックモデリングしたい • 主に必要なもの: • 形態素解析以外の前処理, 後段の集計を行う環境 →
BigQuery • 形態素解析を行う環境 • トピックモデリングを実行する環境 • 制約: • Kuromoji を使いたいので BigQuery の JavaScript UDF で 形態素解析を行うことは難しい BigQuery に保存した日本語データのトピックモデリング 13 ここまでのまとめ
4. 今回の構成 14
• やりたいこと: BigQuery に保存した日本語データをトピックモデリングしたい • 主に必要なもの: • 形態素解析以外の前処理, 後段の集計を行う環境 →
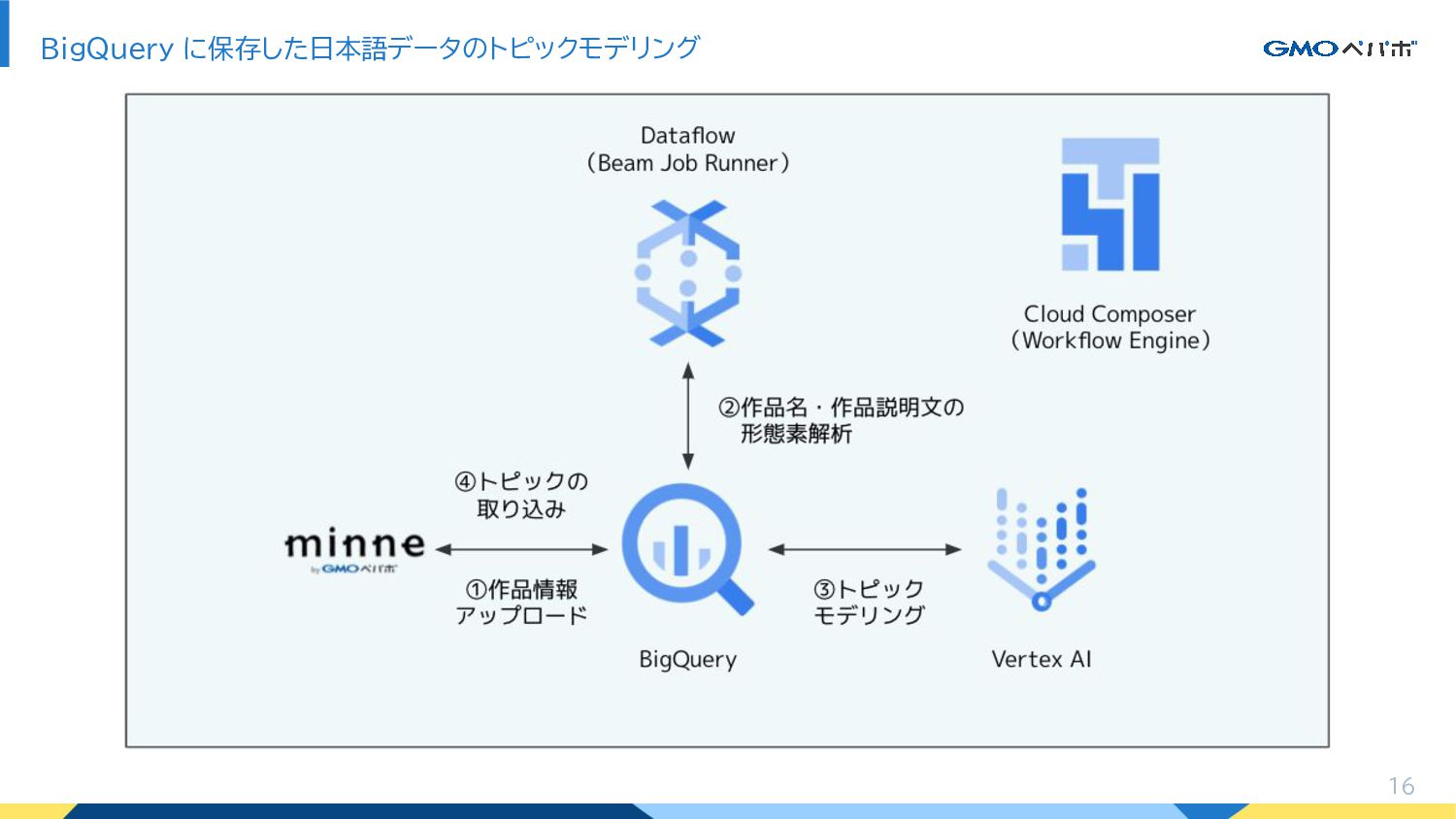
BigQuery • 形態素解析を行う環境 → Dataflow (Beam Job Runner) • トピックモデリングを実行する環境 → Vertex AI のカスタムジョブ • 全体は Cloud Composer でオーケストレーションする 今回の構成 15 全体像
BigQuery に保存した日本語データのトピックモデリング 16
今回の構成 17 • Apache Beam の Runner • Beam なので並列化が容易
• サーバレスでリソースサイズを自由に変えられる • yu-iskw/kuromoji-for-bigquery を利用 • Contribute もさせていただいてます 🙏 • Airflow から利用可能にする変更 • Beam のバージョンアップ Dataflow で形態素解析 yu-iskw/kuromoji-for-bigquery: https://github.com/yu-iskw/kuromoji-for-bigquery 画像は https://github.com/yu-iskw/kuromoji-for-bigquery/README.md から引用
今回の構成 18 kuromoji-for-bigquery での形態素解析の例
• 機械学習の統合プラットフォーム • 機械学習に関わるタスク • 入力データのクレンジング, ラベル付け(アノテーション), 特徴量生成 • モデルの選定・設計
• ハイパーパラメータの学習ごとの記録 • モデルの性能の管理・評価, デプロイ • これらのオーケストレーション • 機械学習に関わる環境 • 学習させる環境 • 推論させる環境(モデルの API 化) • 試行錯誤するための開発環境 今回の構成 19 Vertex AI の概要
• 元々トピックモデリングの処理は Beam Pipeline として作っていた • 分散処理の観点では Beam Pipeline が有利
• サービスのエンジニアと協力して開発するので Beam を使うとややハードルがある • 性能監視などがしづらかった 今回の構成 20 Vertex AI でトピックモデリング
• Vertex AI ではコンテナを使ったカスタムトレーニングジョブとして学習させる • gensim でトピックモデリングを行うコードと Dockerfile を用意 •
コンテナには慣れている & 手元で動かしやすいのでハードルを下げられそう • プラットフォームに乗せて性能監視やハイパーパラメータチューニングしやすい状態になった 今回の構成 21 Vertex AI でトピックモデリング $ gcloud builds submit \ --tag gcr.io/project_foo/image_bar:0.0.1 $ gcloud ai custom-jobs create \ --region=us-central1 \ --display-name=minne_product_topic_model_test \ --config=custom_job_config_development.yaml \ --service-account="foo@project_foo.iam.gserviceaccount.com" # custom_job_config_development.yaml workerPoolSpecs: machineSpec: machineType: n1-standard-4 replicaCount: 1 containerSpec: imageUri: gcr.io/project_foo/image_bar:0.0.1 env: - name: ENV value: development - name: INPUT_TABLE_ID value: hoge - …
今回の構成 22 トピックモデリングの結果(一部抜粋) トピックID 作品名 1 籐のふたつきかご(大) 1 モスグリーンファークッションカバー 1
ひょうたんランプ---secret garden 2 ネコのコースター(革ひもセット) 2 カワイイ~くまちゃん&お化けちゃんのハロウィンパーティー 2 幸せの青い鳥welcomeボード ♬*゜羊毛フェルト 3 ☆フルーツ&ドーナツ☆フォトフレーム 3 ストロベリー グラデーション ガラスのカフェトレイ・M グリーン・植物 動物 食べ物
• Beam Pipeline は BeamRunJavaPipelineOperator で起動 • 基本的にオプションを渡すだけで大丈夫 今回の構成 23
Cloud Composer でオーケストレーション (Beam Pipeline) BeamRunJavaPipelineOperator( task_id=f"{OWNER}_{BASE_DAG_ID}_morphological_analysis", jar="/home/airflow/gcs/dags/bigfoot/kuromoji-for-bigquery-bundled-0.3.0.jar", runner="DataflowRunner", pipeline_options={ # kuromoji-for-bigquery に必要なオプションを渡す "project": PROJECTS["bigfoot"], "inputDataset": DATASETS[OWNER], … }, dataflow_config={ "job_name": f"{OWNER}_{BASE_DAG_ID}_dag_morphological_analysis", "gcp_conn_id": google_cloud_platform_conn_id(), }, )
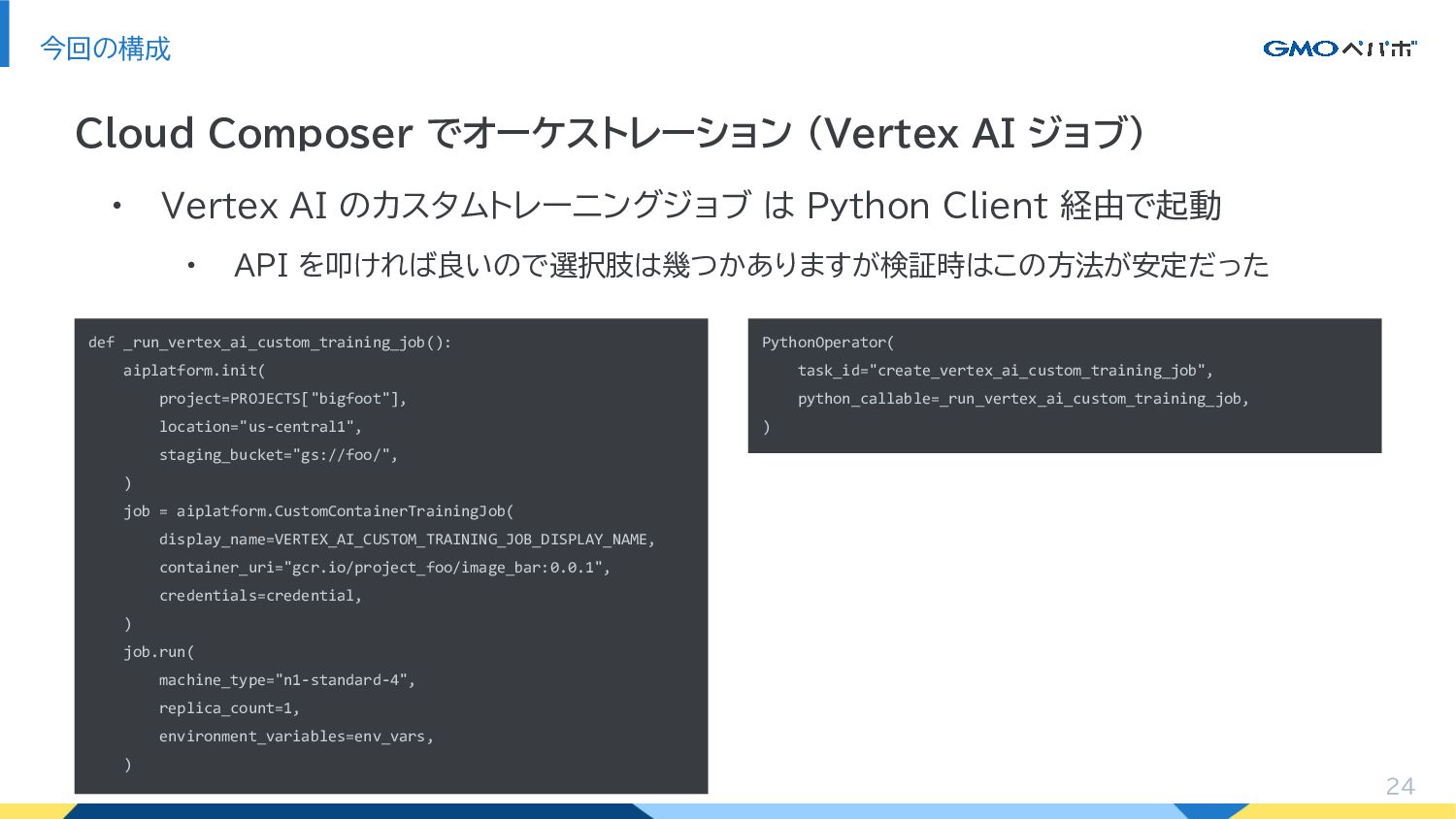
• Vertex AI のカスタムトレーニングジョブ は Python Client 経由で起動 • API
を叩ければ良いので選択肢は幾つかありますが検証時はこの方法が安定だった 今回の構成 24 Cloud Composer でオーケストレーション (Vertex AI ジョブ) def _run_vertex_ai_custom_training_job(): aiplatform.init( project=PROJECTS["bigfoot"], location="us-central1", staging_bucket="gs://foo/", ) job = aiplatform.CustomContainerTrainingJob( display_name=VERTEX_AI_CUSTOM_TRAINING_JOB_DISPLAY_NAME, container_uri="gcr.io/project_foo/image_bar:0.0.1", credentials=credential, ) job.run( machine_type="n1-standard-4", replica_count=1, environment_variables=env_vars, ) PythonOperator( task_id="create_vertex_ai_custom_training_job", python_callable=_run_vertex_ai_custom_training_job, )
• モデルから文章(作品)のトピックを得られる • ユーザーごとに直近の閲覧履歴に基づいて好む(と思われる)トピックを集計 → 作品のトピックとユーザーの好むトピックをそれぞれ BigQuery に保存 → minne
のシステムが BigQuery から KVS などに取り込んでサービスで利用 今回の構成 25 Cloud Composer でオーケストレーション (トピックの集計)
26 1. セクションタイトル 5. まとめと今後
• Google Cloud Platform でトピックモデリングのパイプラインを作った • データウェアハウスは BigQuery • 形態素解析は
Dataflow • サービスと同じ Kuromoji, 辞書を使える • モデルの学習は Vertex AI • モデルのパラメータチューニングや性能監視がしやすくなった • オーケストレーションは Cloud Composer • パイプラインをデータサイエンティストだけで構成できた • データが増えた際の並列化やリソースのマネジメントが比較的容易 • 本気でチューニングする場合はデータエンジニアと頑張る 🙏 まとめと今後 27 まとめと良かったポイント
• ペパボは事業部制 • 現状は機械学習モデルの管理や近似最近傍探索サーバの運用が事業部ごと → 機械学習関連のパイプラインは Bigfoot に乗せて基盤/知見を共通化していく 🚀 →
Vertex Matching Engine などマネージドな ML サービスも頼っていく 🚀 • 予測や仮説検証系のタスクをサービスごとのアナリストが担っている → 基盤を使った機械学習の利用を予測・仮説検証の分野でも進めてサイクルを高速化していく 🚀 まとめと今後 28 今後の展望
29 Thank You! Thank You! 資料は https://speakerdeck.com/zaimy/ に公開しています
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}