Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
デプロイを恐れていたSpringチームが、月200回リリースするまで 〜真のリスクは停滞だった〜
Search
igu
June 03, 2026
Technology
36
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
デプロイを恐れていたSpringチームが、月200回リリースするまで 〜真のリスクは停滞だった〜
JJUG CCC 2026 Spring で登壇したセッションの資料です。
本番デプロイの抱えていたプロダクトがその問題を解消し、真の課題に気づいたという事例を紹介します。
igu
June 03, 2026
More Decks by igu
See All by igu
膨大なデータをどうさばく? Java × MQで作るPub/Subアーキテクチャ
zenta
0
1.1k
Other Decks in Technology
See All in Technology
探索・可視化・自動化を一本化 Amazon Quickでデータ活用スピードを上げる方法
koheiyoshikawa
0
160
複数プロダクトで進めるAI機能実装 ── 実践から得たリアルな学びとロードマップ実現への挑戦 / AICon2026_yanari
rakus_dev
0
250
伝票作成AIエージェントを支える、LLMOpsとインフラの選択肢 / AICon2026_takeda
rakus_dev
0
250
AIが当たり前の組織で エンジニアはどう育つか
nishihira
1
900
Making sense of Google’s agentic dev tools
glaforge
1
300
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
240
全員がリーダーである世界へ キリマンジャロ登頂とシェアド・リーダー
jinwatanabe
0
120
ここは地獄!つらい朝会を体験することで、チームとしてのより良い振る舞いに気づくワークショップ / The stand-up meeting from hell in the game industry
scrummasudar
0
210
Webアプリ認証の全体像 / The Big Picture of Web App Authentication
kitano_yuichi
1
400
AIが実装を自走する時代の認知負債との戦い
lycorptech_jp
PRO
2
1k
発表と総括 / Presentations and Summary
ks91
PRO
0
180
JAWS_ICEBERG_BASECAMP
iqbocchi
2
100
Featured
See All Featured
Breaking role norms: Why Content Design is so much more than writing copy - Taylor Woolridge
uxyall
0
350
The Cost Of JavaScript in 2023
addyosmani
55
10k
Getting science done with accelerated Python computing platforms
jacobtomlinson
2
340
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
jQuery: Nuts, Bolts and Bling
dougneiner
66
8.5k
Practical Orchestrator
shlominoach
191
11k
What does AI have to do with Human Rights?
axbom
PRO
1
2.3k
GraphQLとの向き合い方2022年版
quramy
50
15k
Making Projects Easy
brettharned
120
6.7k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Site-Speed That Sticks
csswizardry
13
1.3k
Imperfection Machines: The Place of Print at Facebook
scottboms
270
14k
Transcript
None
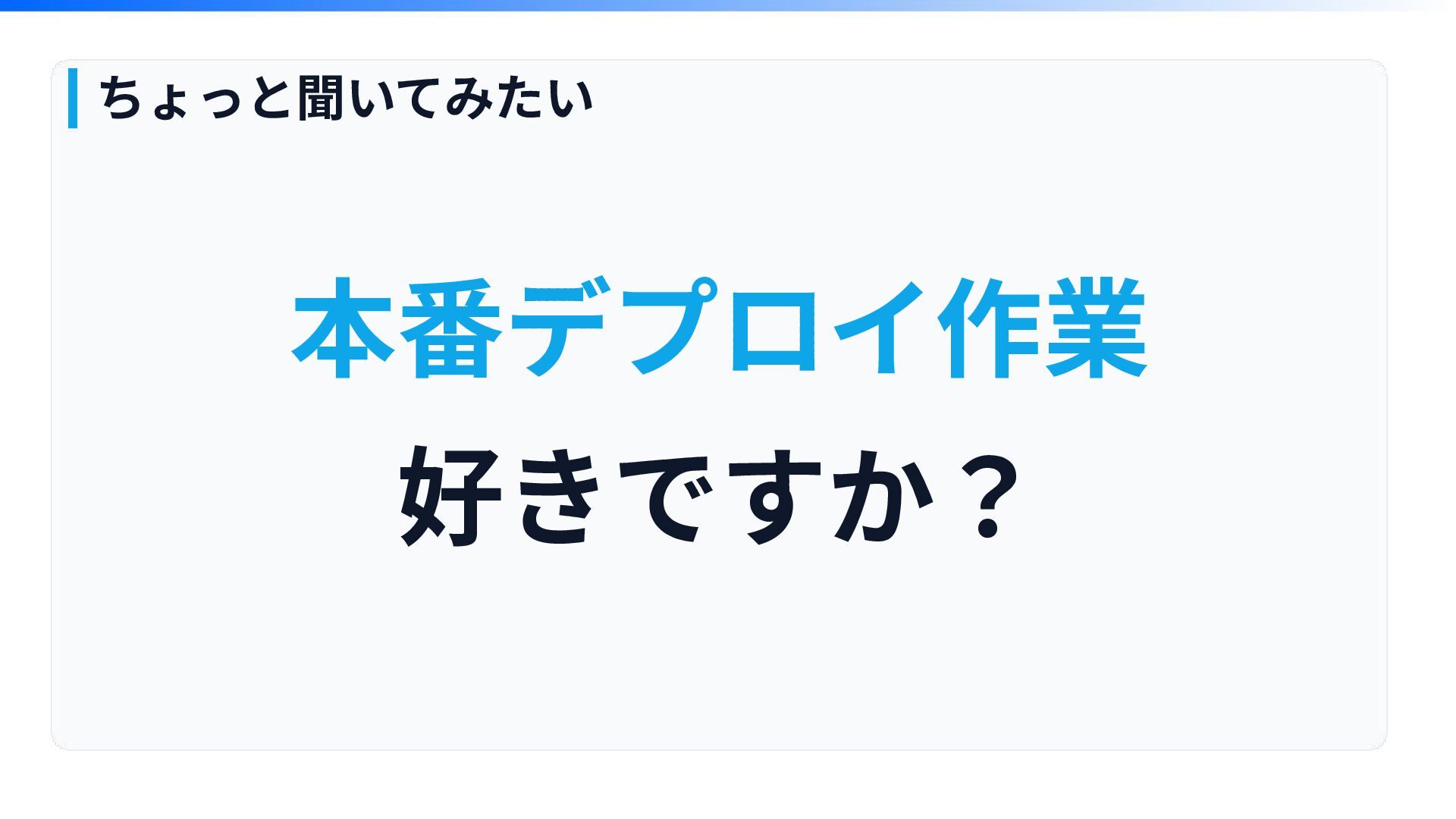
本番デプロイ作業 好きですか? ちょっと聞いてみたい
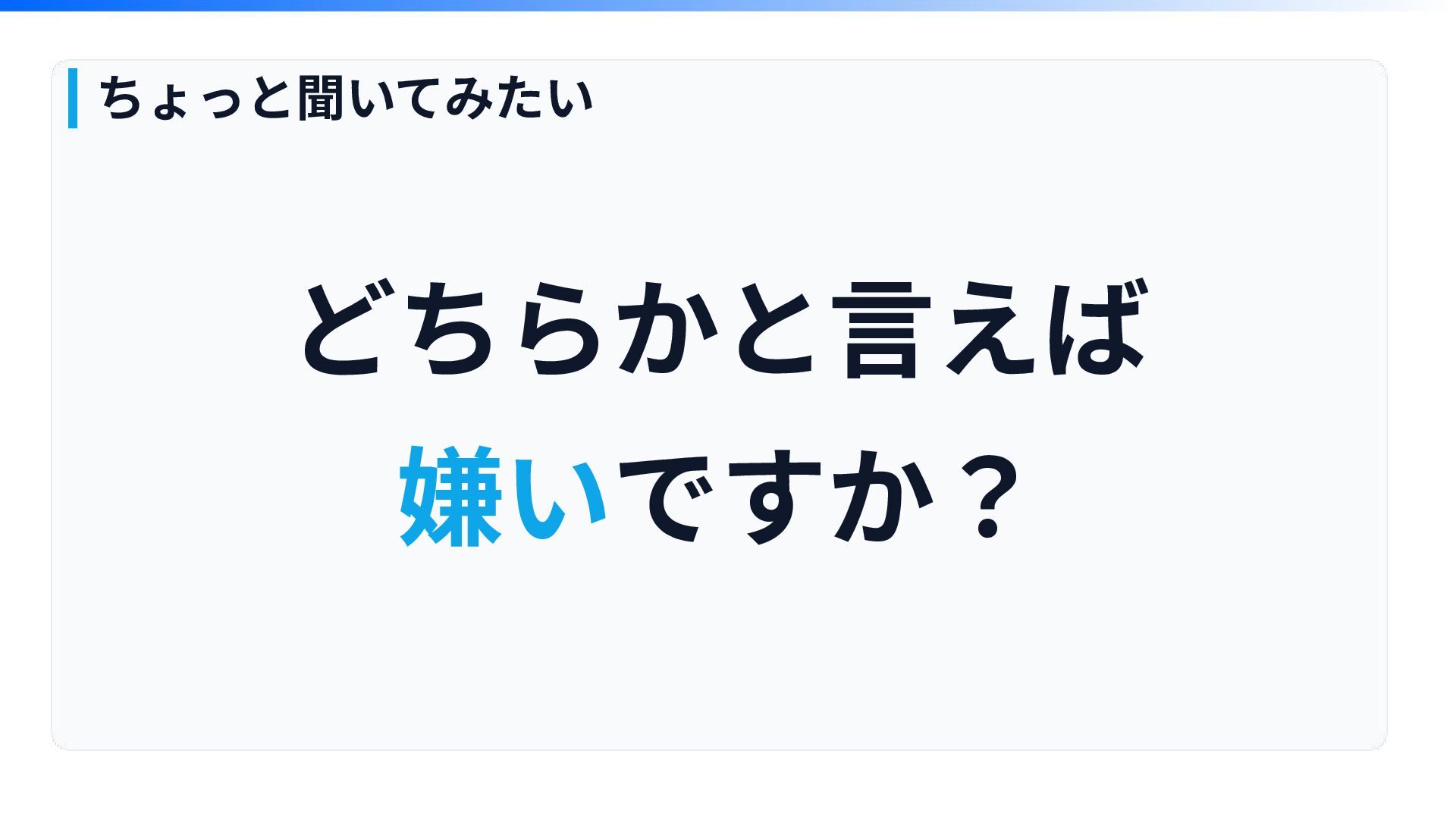
どちらかと⾔えば 嫌いですか? ちょっと聞いてみたい
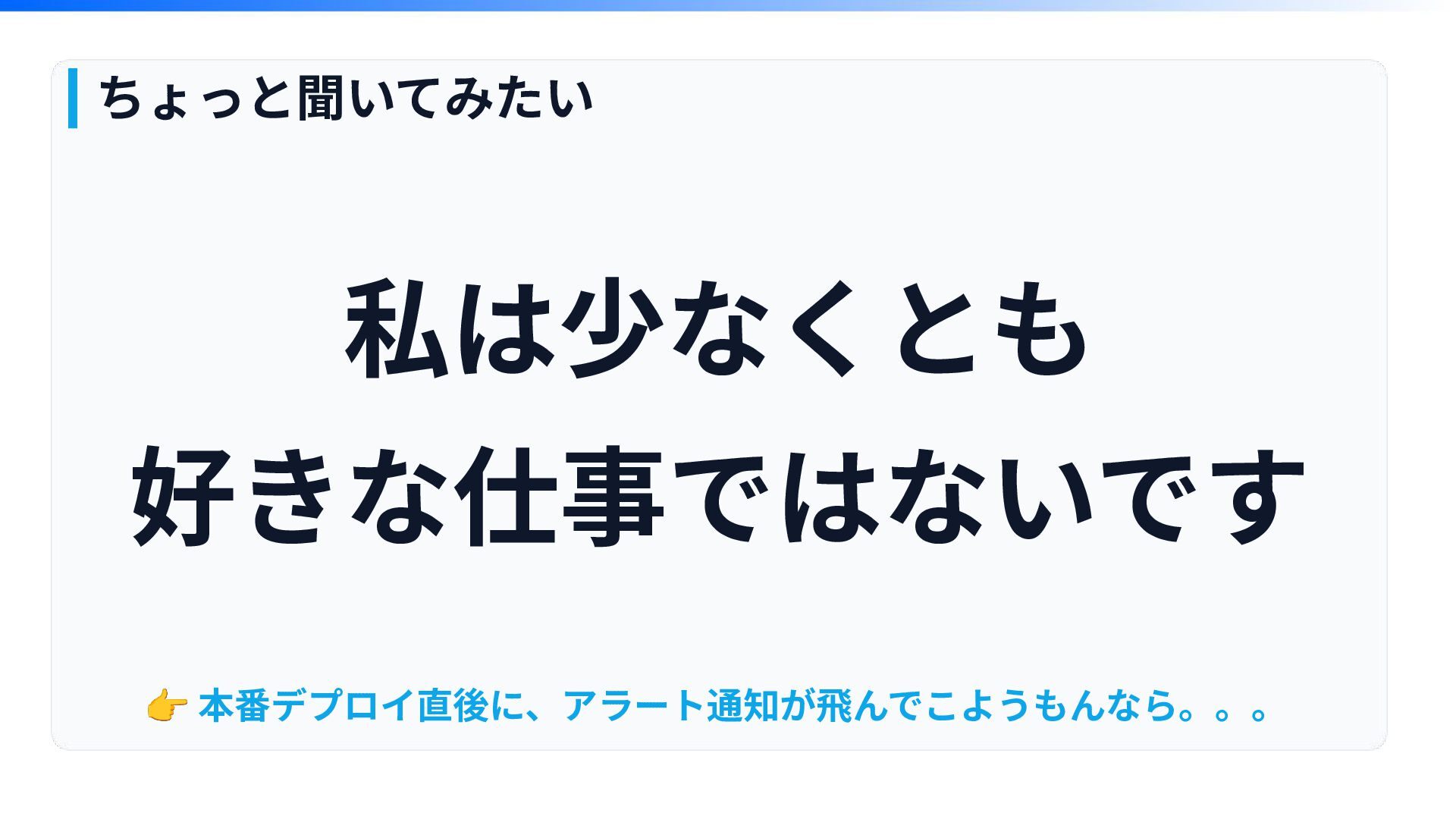
私は少なくとも 好きな仕事ではないです ちょっと聞いてみたい 👉 本番デプロイ直後に、アラート通知が⾶んでこようもんなら。。。
もう1つ聞かせてください もう1つ聞かせてください
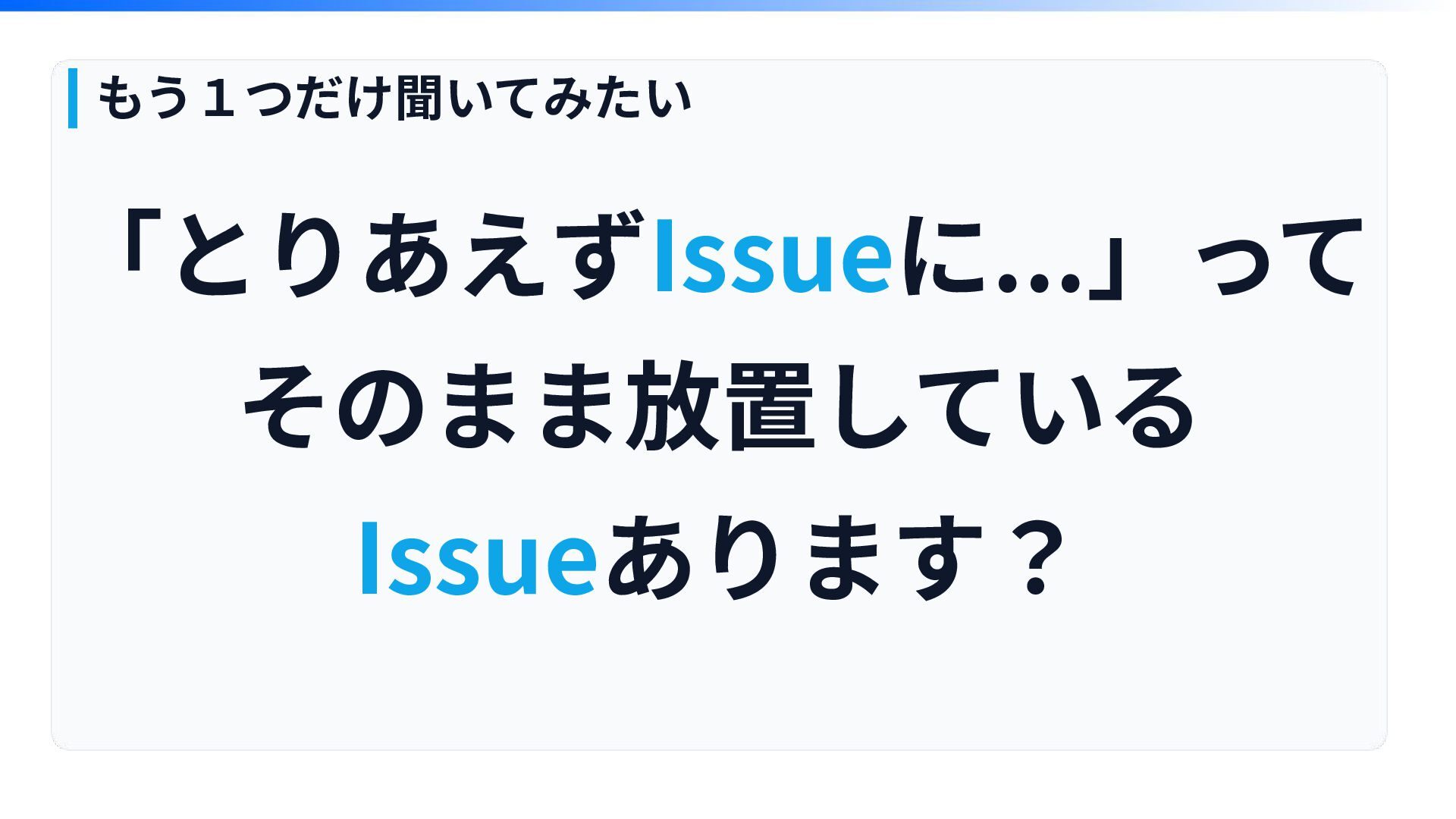
「とりあえずIssueに...」って そのまま放置している Issueあります? もう1つだけ聞いてみたい
私はあります フレッシュなものから 熟成されたものまで 品揃えは豊富に。。。 もう1つだけ聞いてみたい 👉 他にもソースのTODO、バックログ、JIRAチケットと幅広く☺
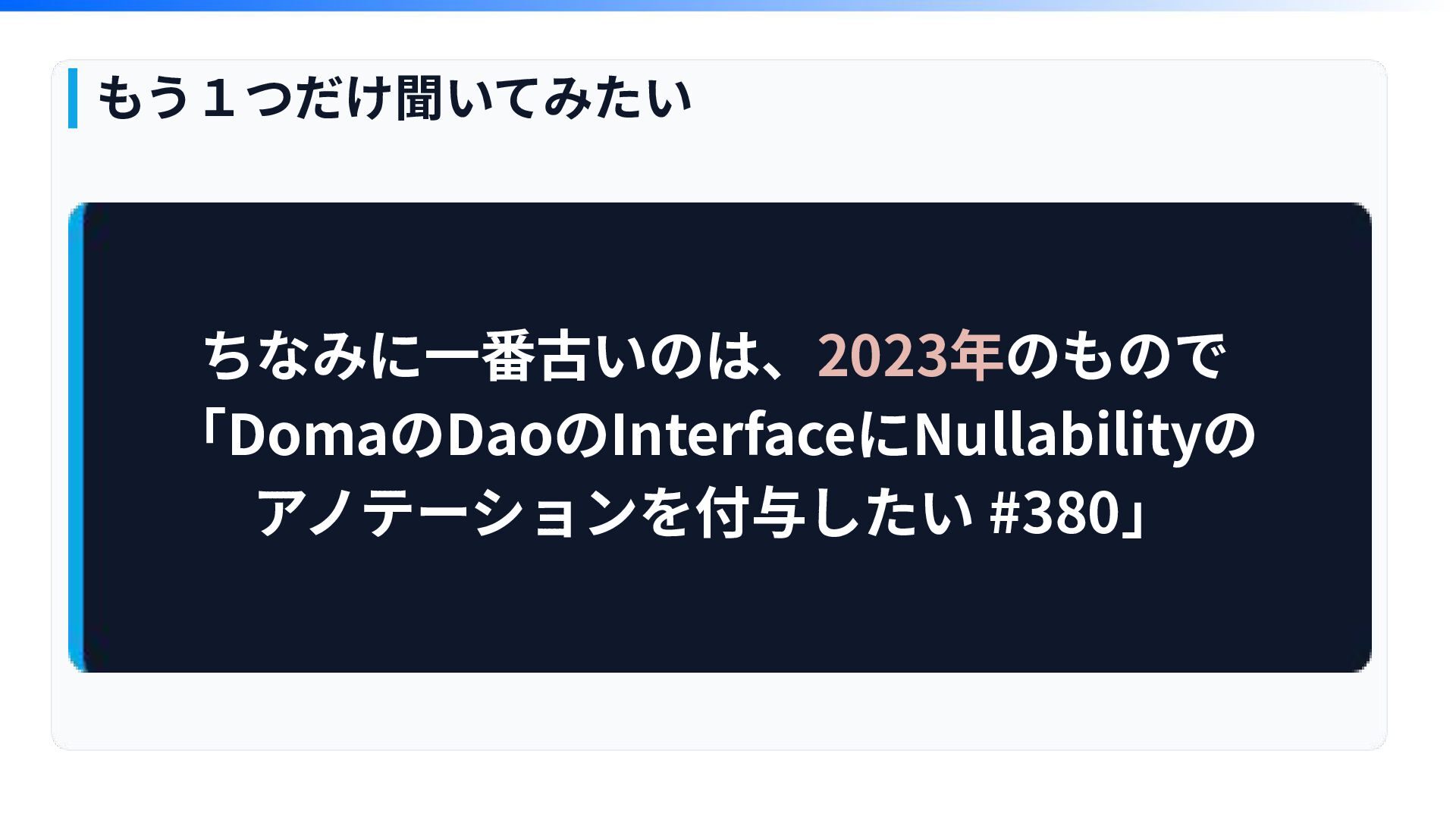
私はあります 品揃えは豊富で フレッシュなものから 熟成されたものまで もう1つだけ聞いてみたい ちなみに⼀番古いのは、2023年のもので 「DomaのDaoのInterfaceにNullabilityの アノテーションを付与したい #380」
そうした、お悩み もしかしたら … もしかしたら…
今⽇のセッションを聞いたら 解消できるかも。
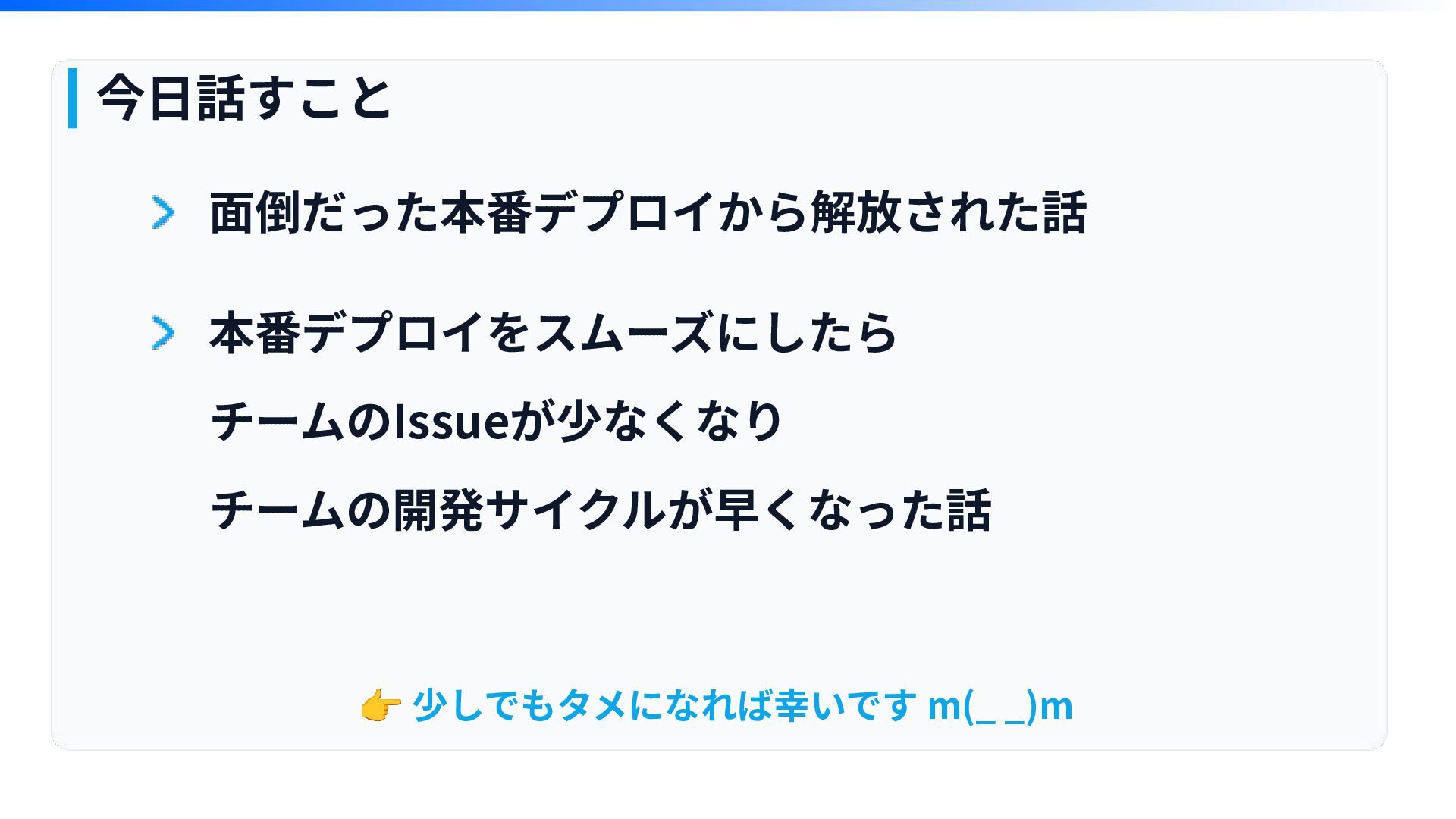
今⽇話すこと ⾯倒だった本番デプロイから解放された話 本番デプロイをスムーズにしたら チームのIssueが少なくなり チームの開発サイクルが早くなった話 👉 少しでもタメになれば幸いです m(_ _)m
⾃⼰紹介 名前:igu 所属:株式会社ZOZO X : https://x.com/Zntig
⾃⼰紹介 名前:igu 所属:株式会社ZOZO 【Attention】 今⽇の話は、ZOZOでの話ではないです。 以前の6年ほど働いていた 某事業会社の検索広告システムのDevOpsチームでの話です
あとは"本番リリース" ボタンを 押すだけなのに… 第1章
とにかくデプロイが⾯倒 第1章
なぜか? 第1章
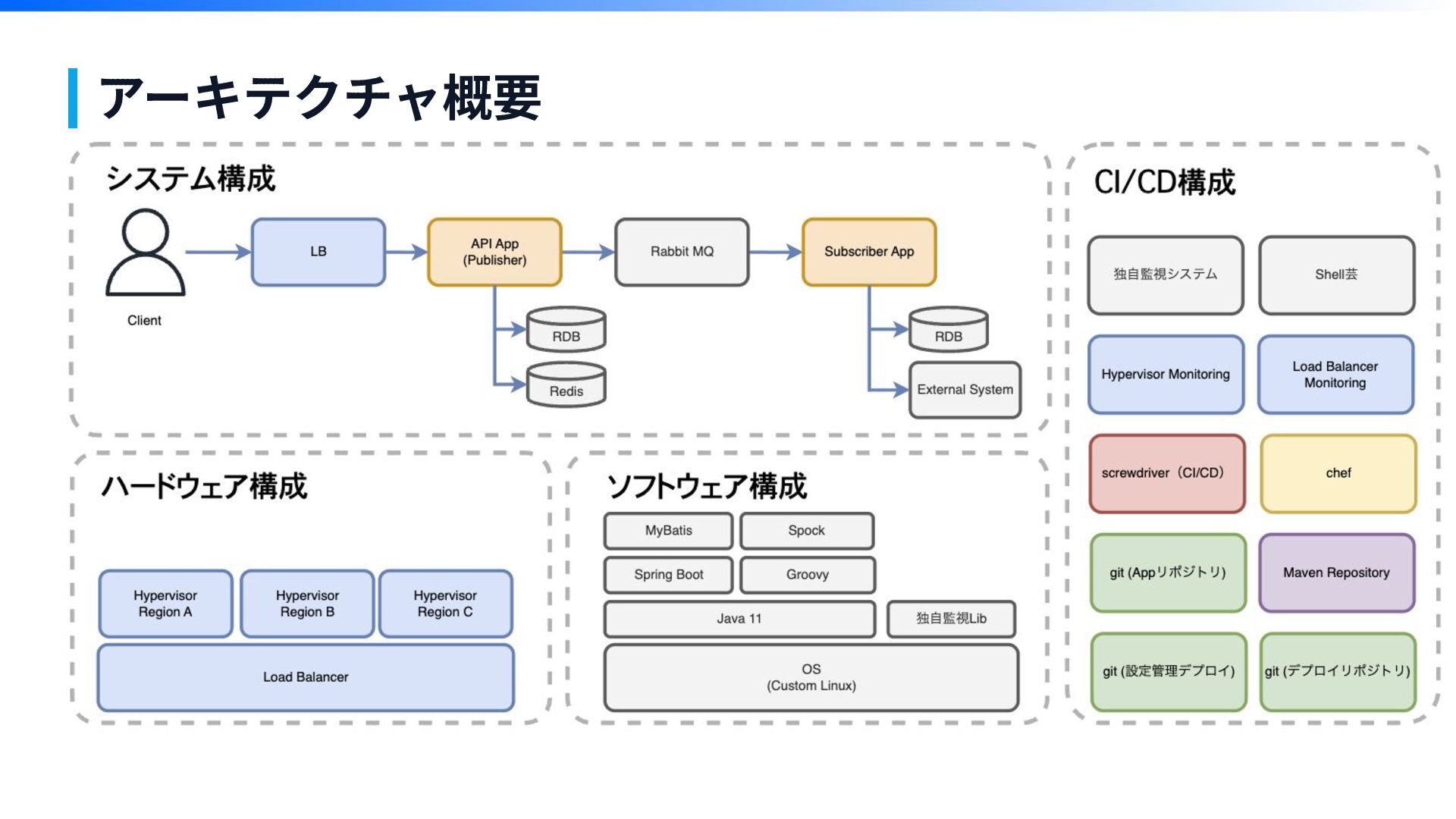
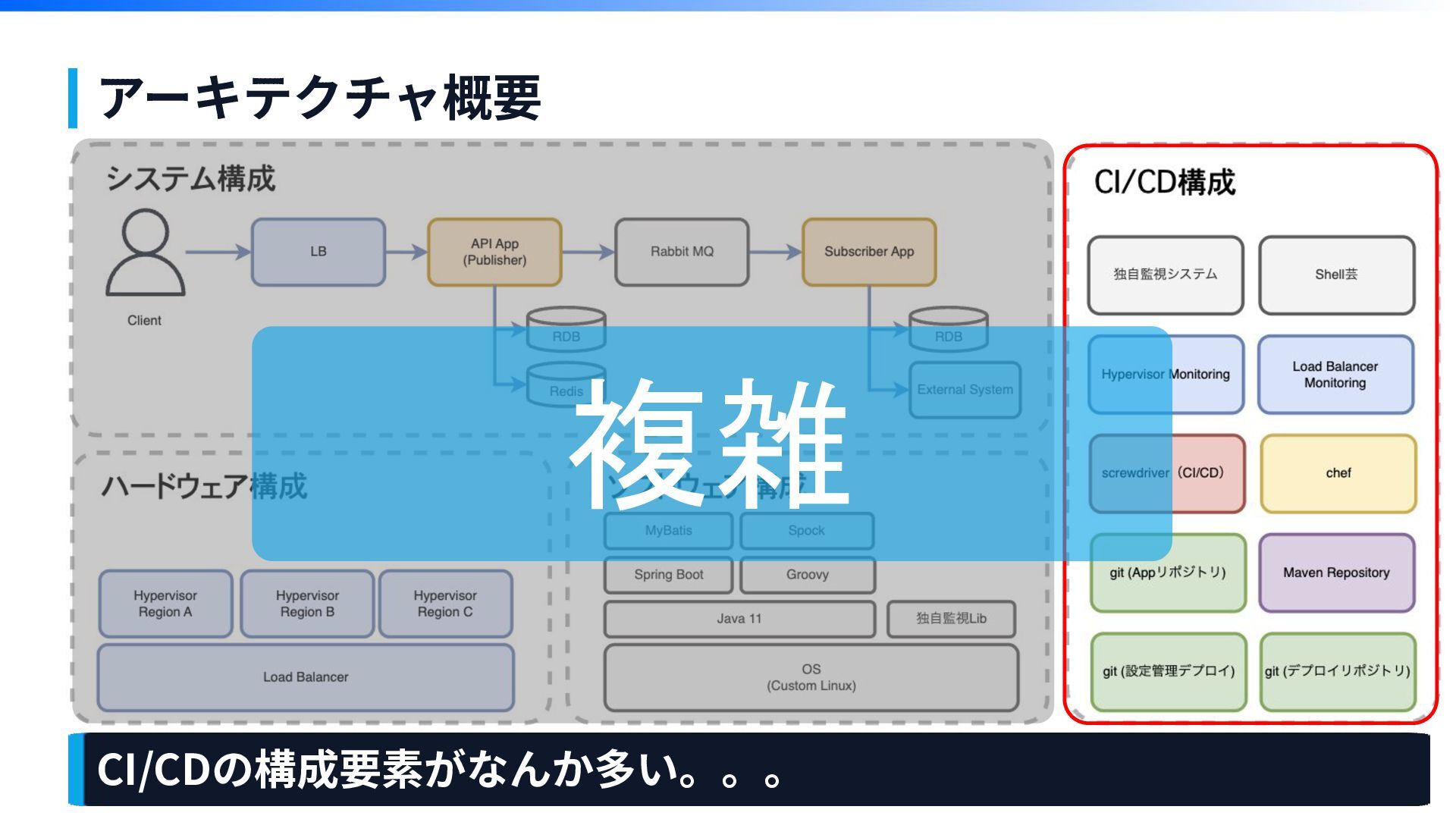
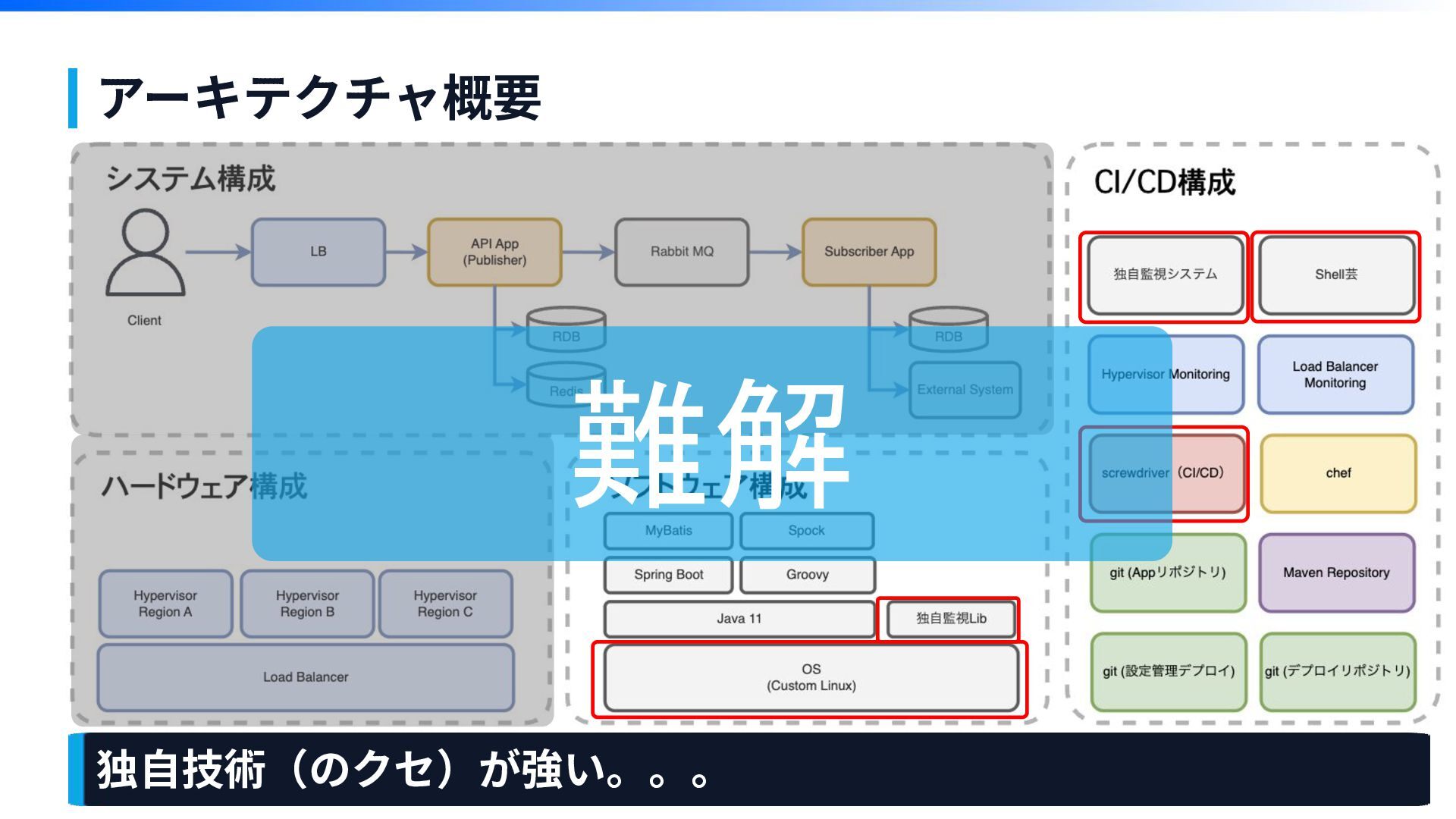
【その1】 システム構成が 複雑で難解で量が多い 第1章
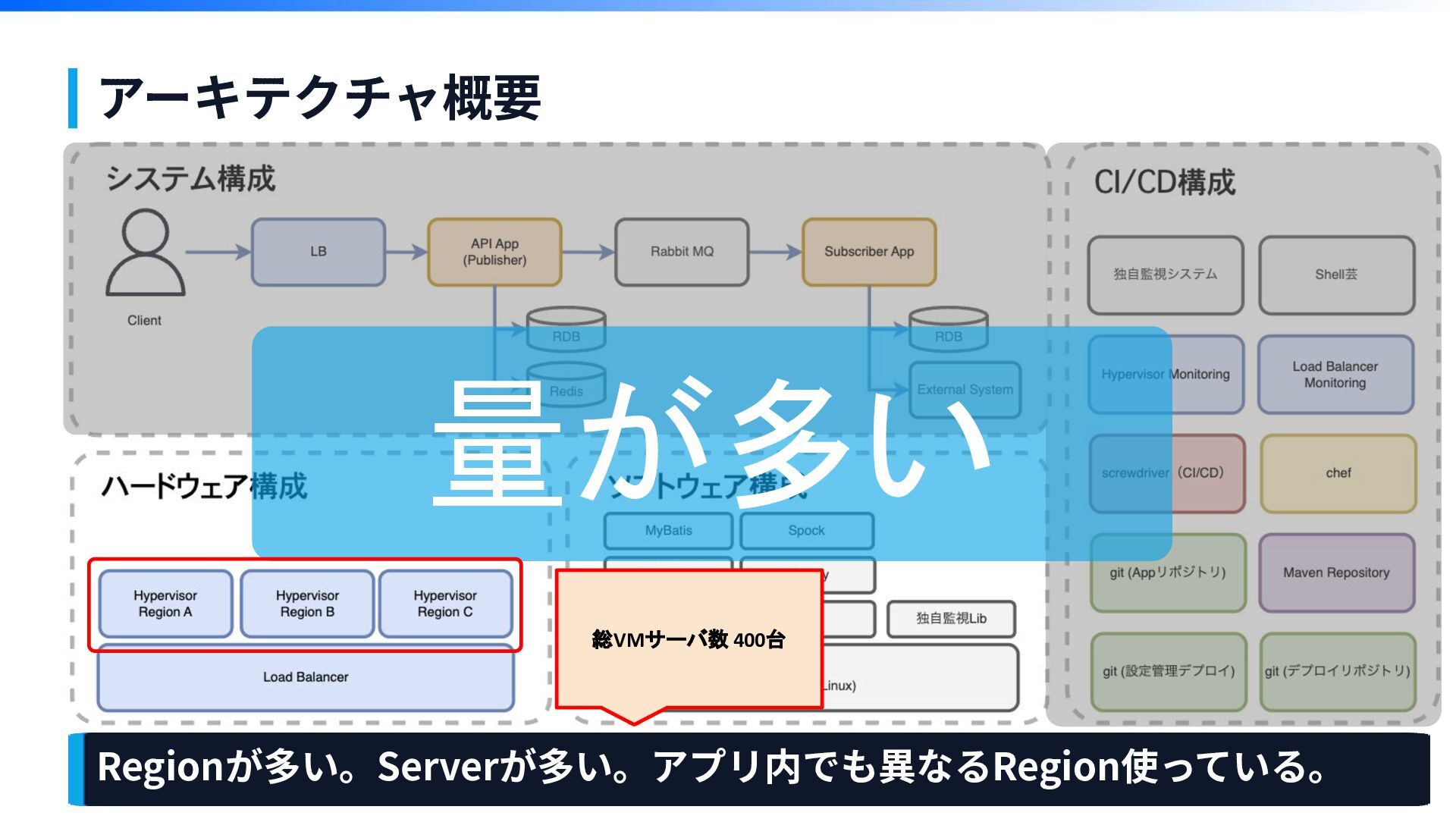
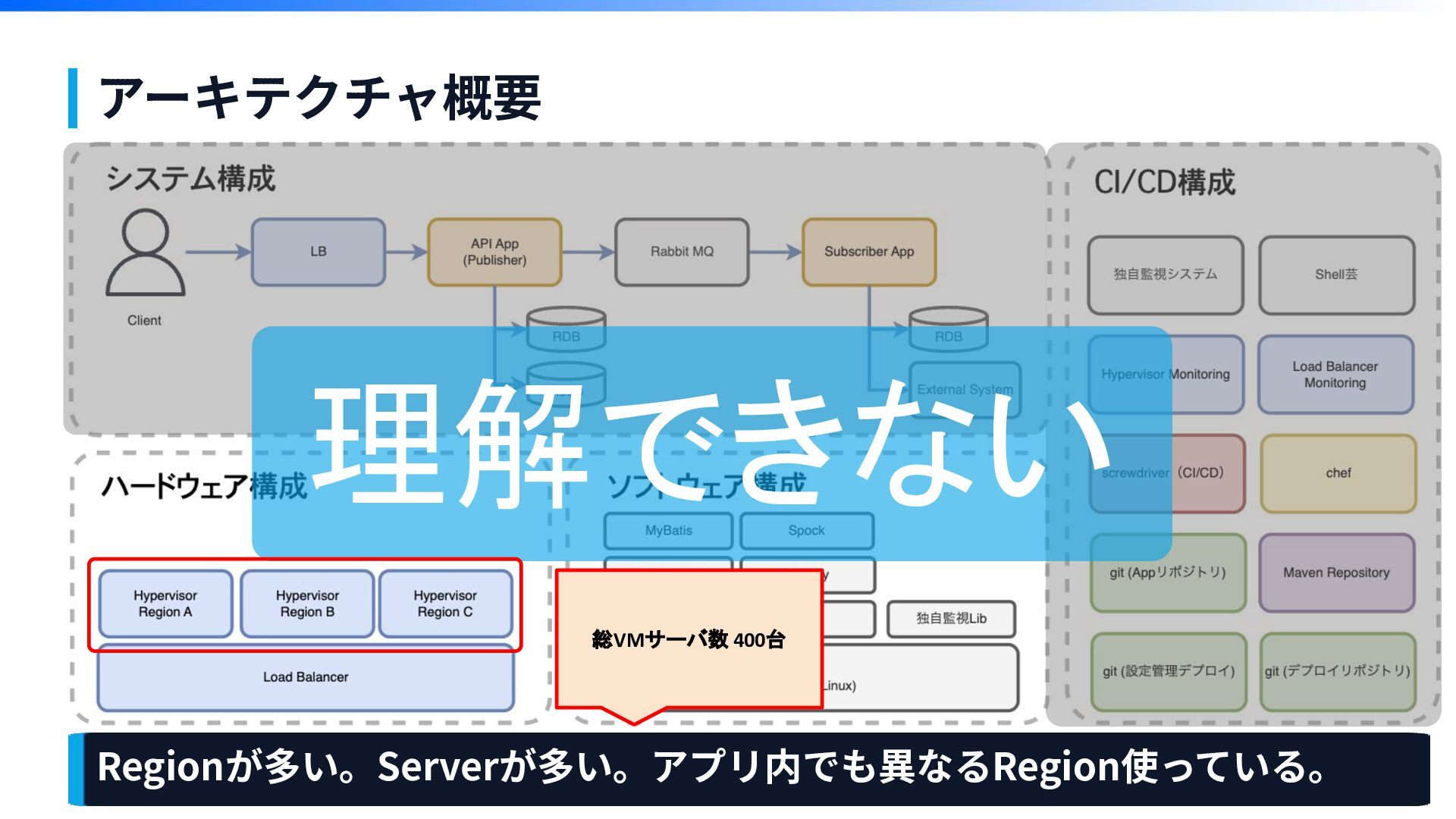
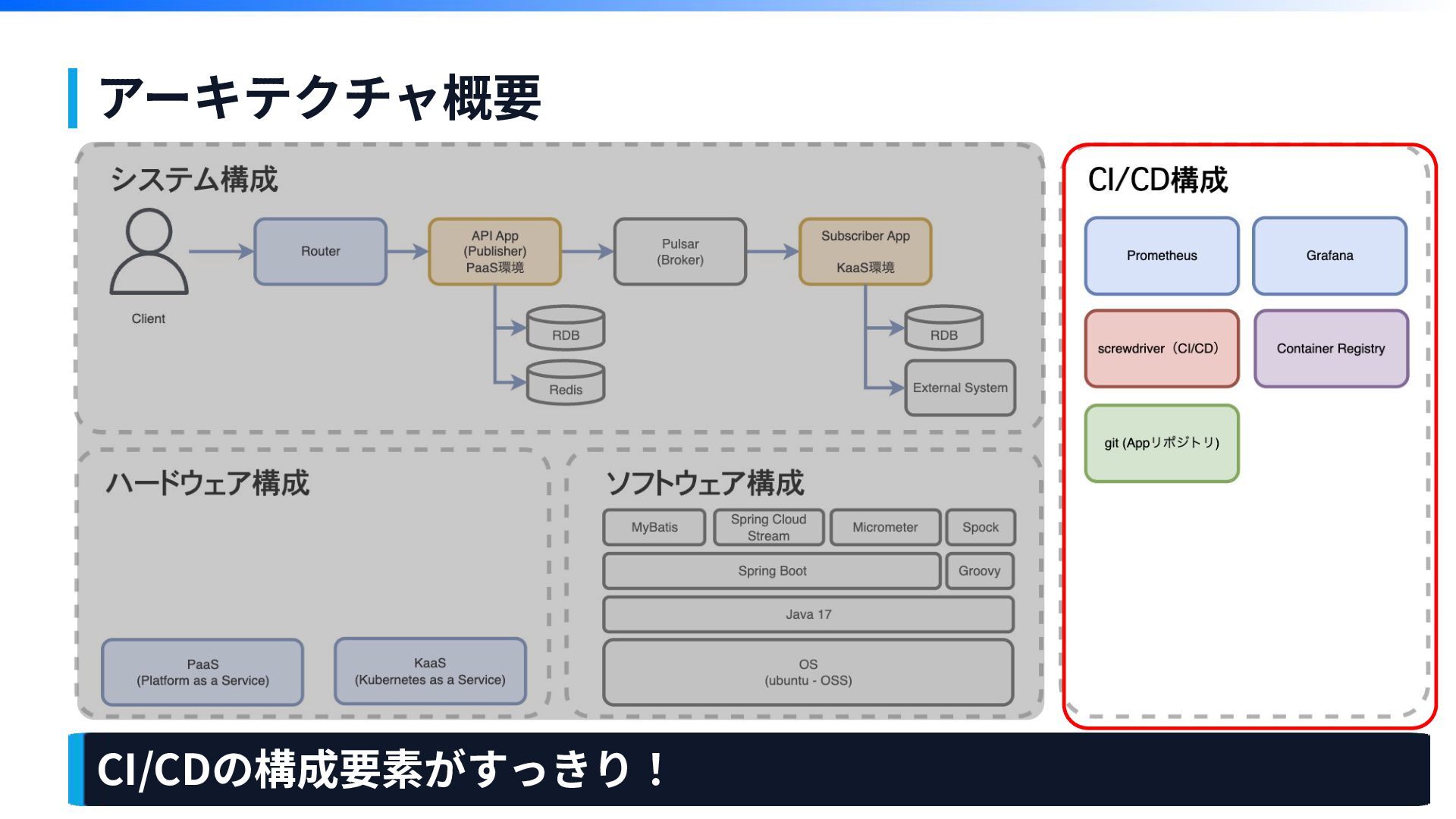
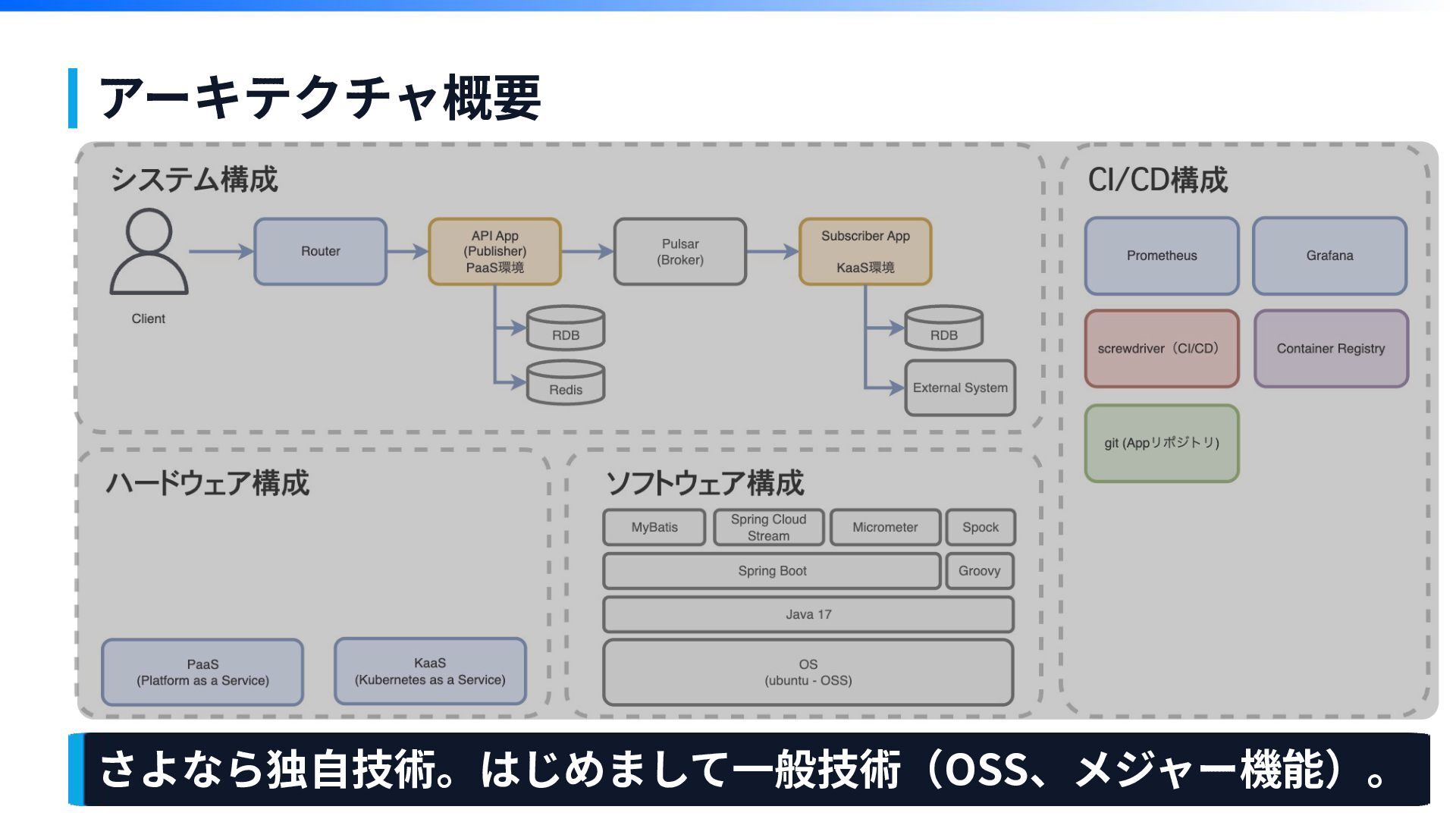
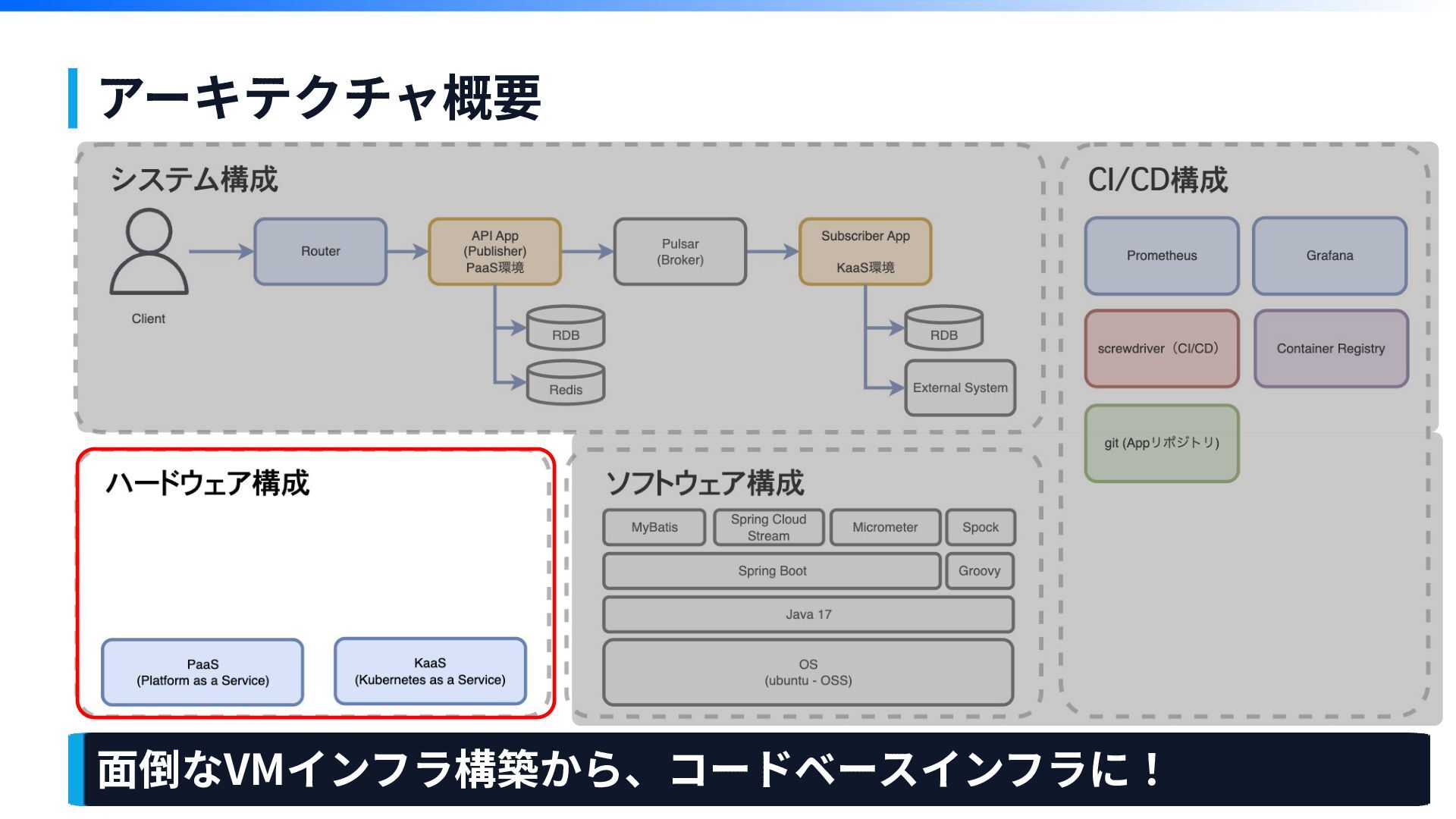
アーキテクチャ概要
アーキテクチャ概要 CI/CDの構成要素がなんか多い。。。 複雑
アーキテクチャ概要 独⾃技術(のクセ)が強い。。。 難解
アーキテクチャ概要 Regionが多い。Serverが多い。アプリ内でも異なるRegion使っている。 総VMサーバ数 400台 量が多い
アーキテクチャ概要 Regionが多い。Serverが多い。アプリ内でも異なるRegion使っている。 総VMサーバ数 400台 理解できない
【その2】 デプロイ⼿順が複雑で多い 第1章
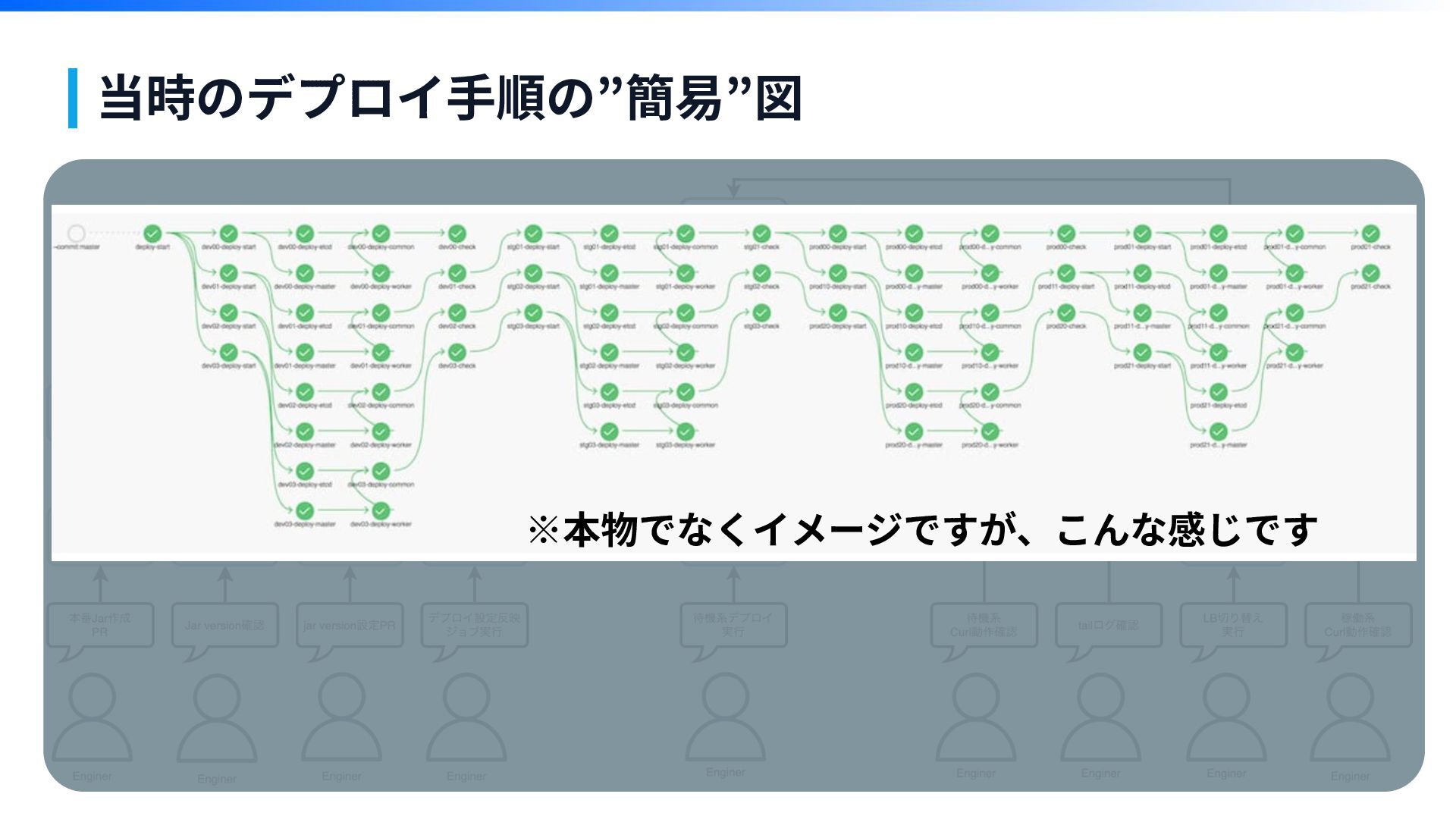
デプロイパイプラインの ジョブを可視化すると こんな感じです 第1章
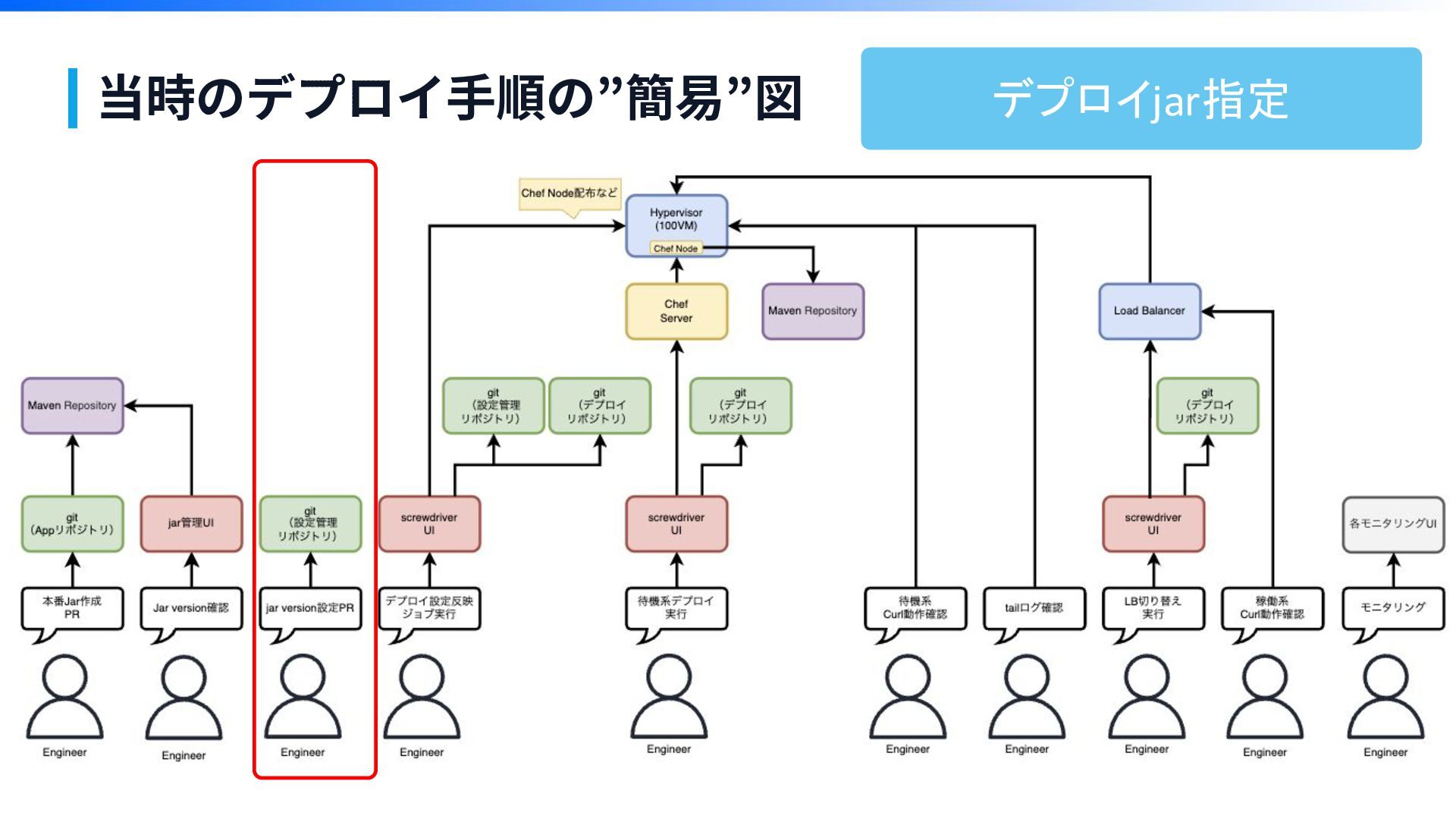
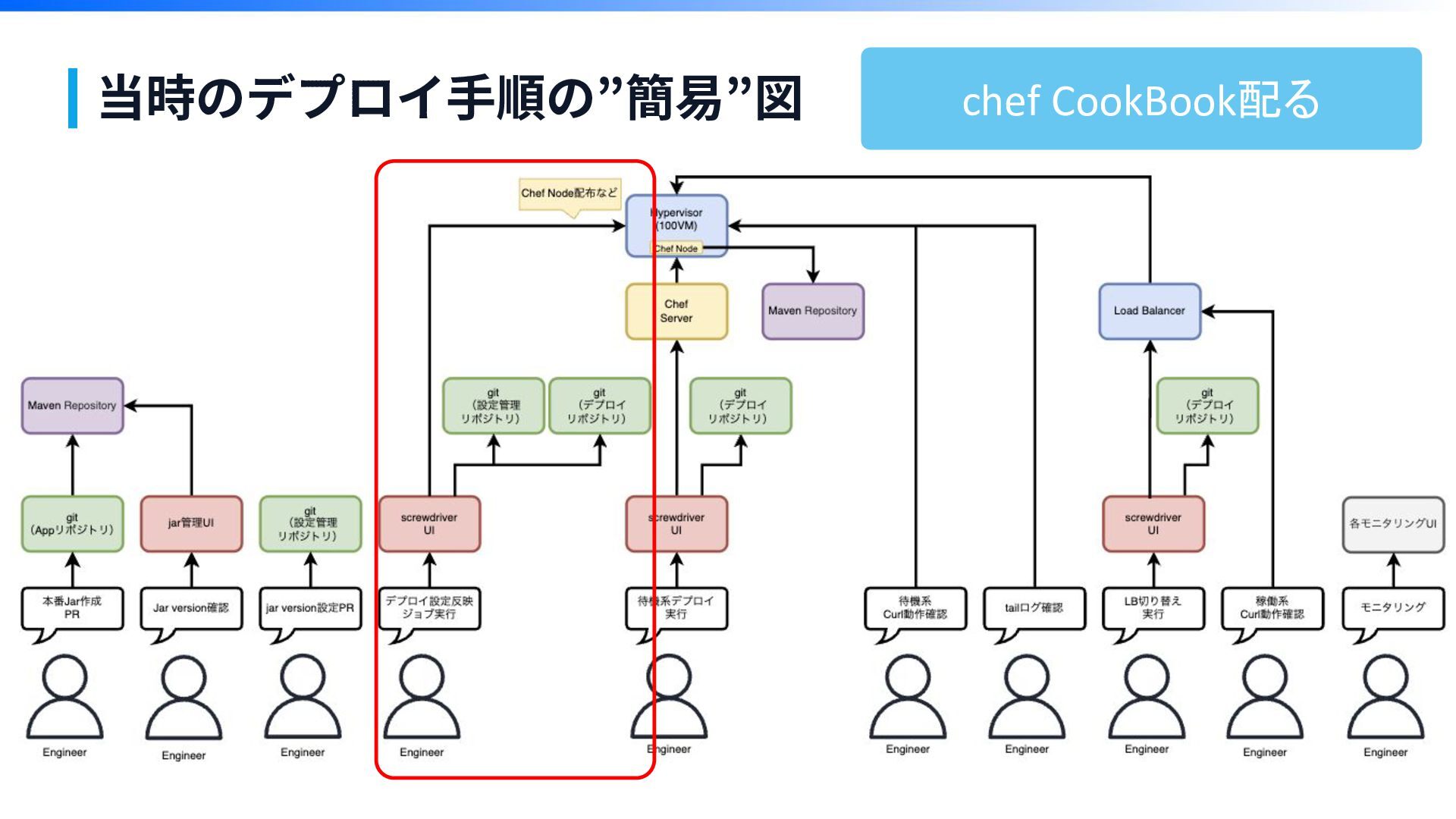
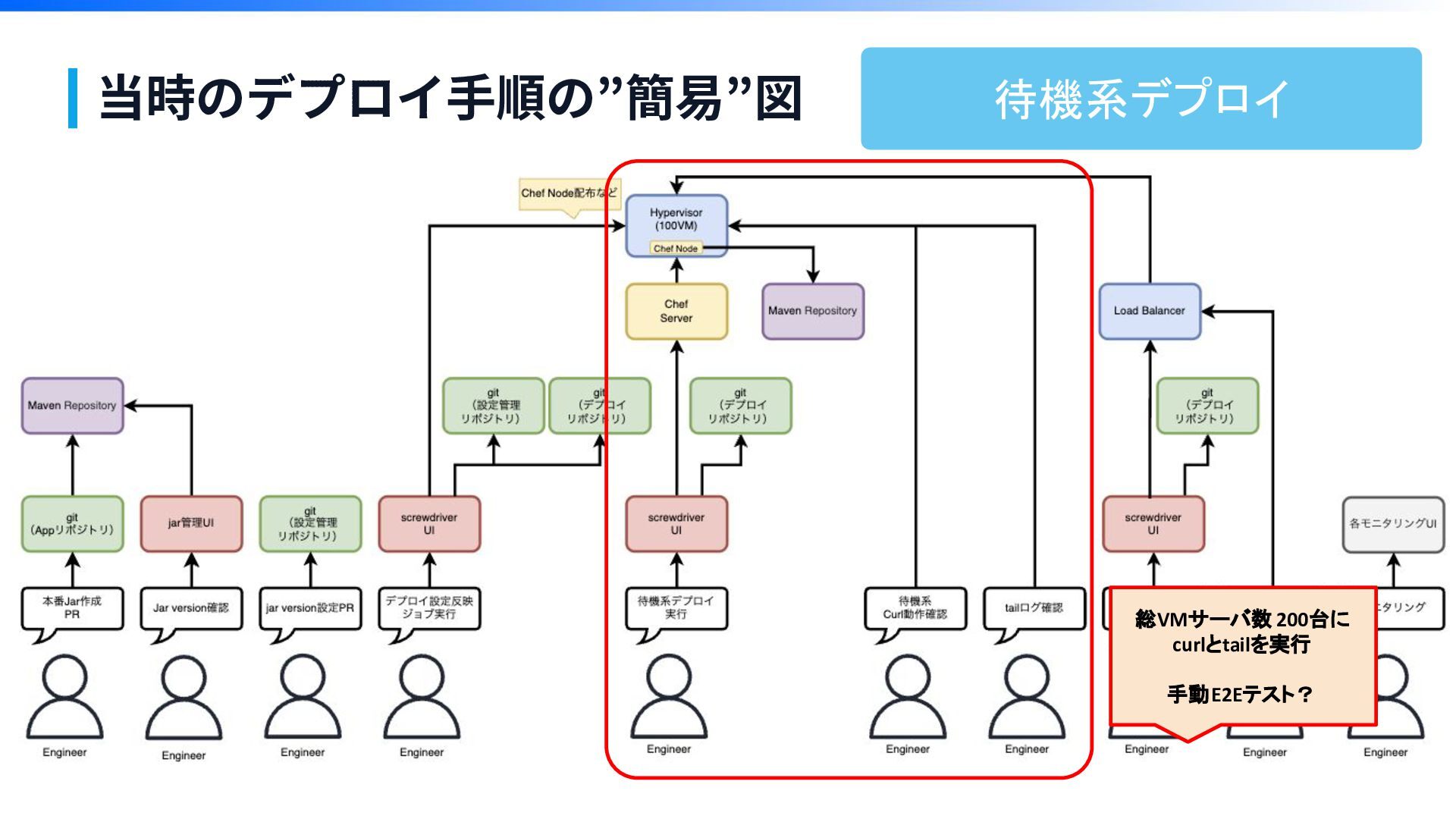
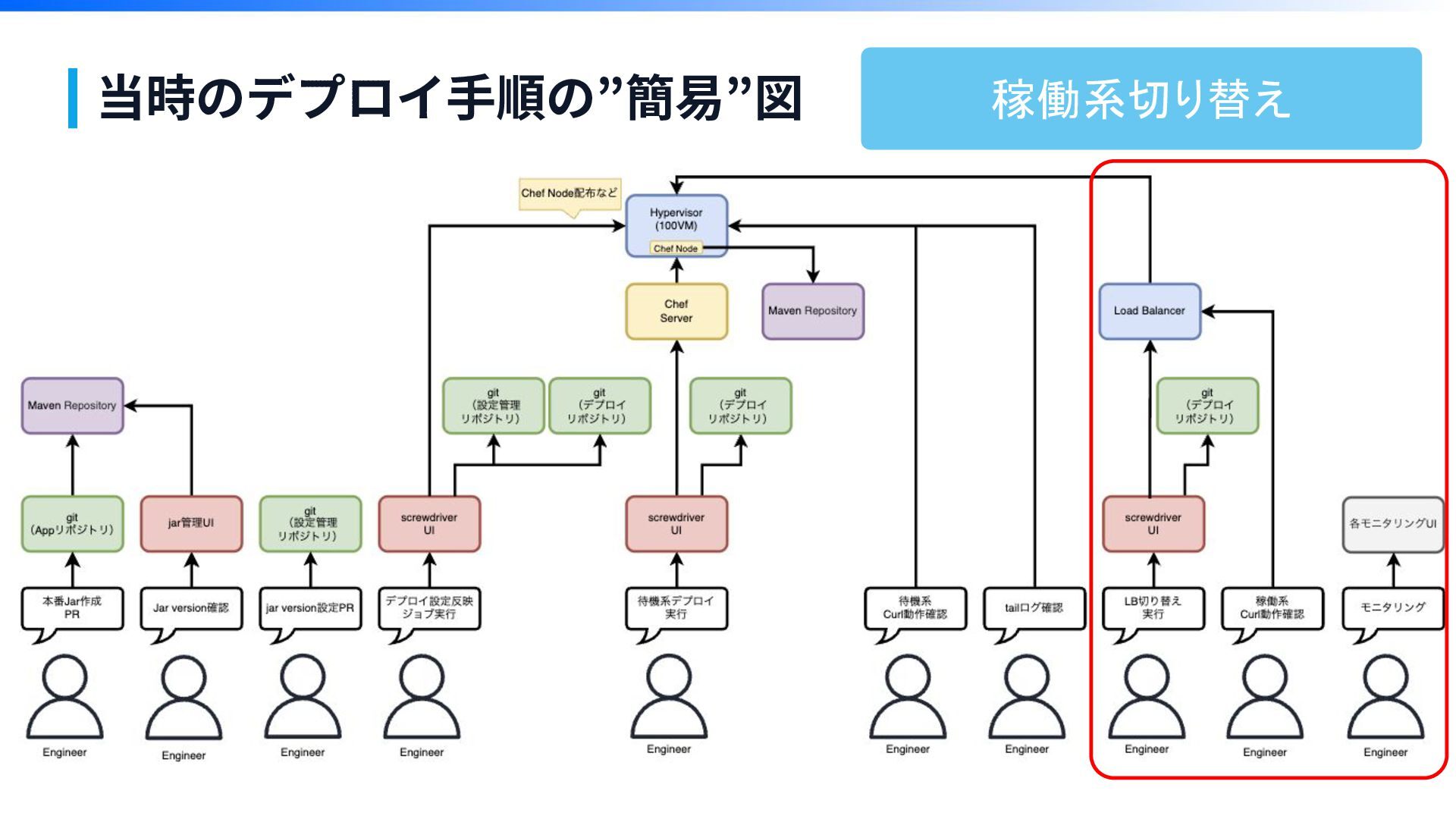
当時のデプロイ⼿順の”簡易”図 ※本物でなくイメージですが、こんな感じです
当時のデプロイ⼿順の”簡易”図 ※本物でなくイメージですが、こんな感じです ごちゃごちゃ
これを簡単に説明すると 第1章
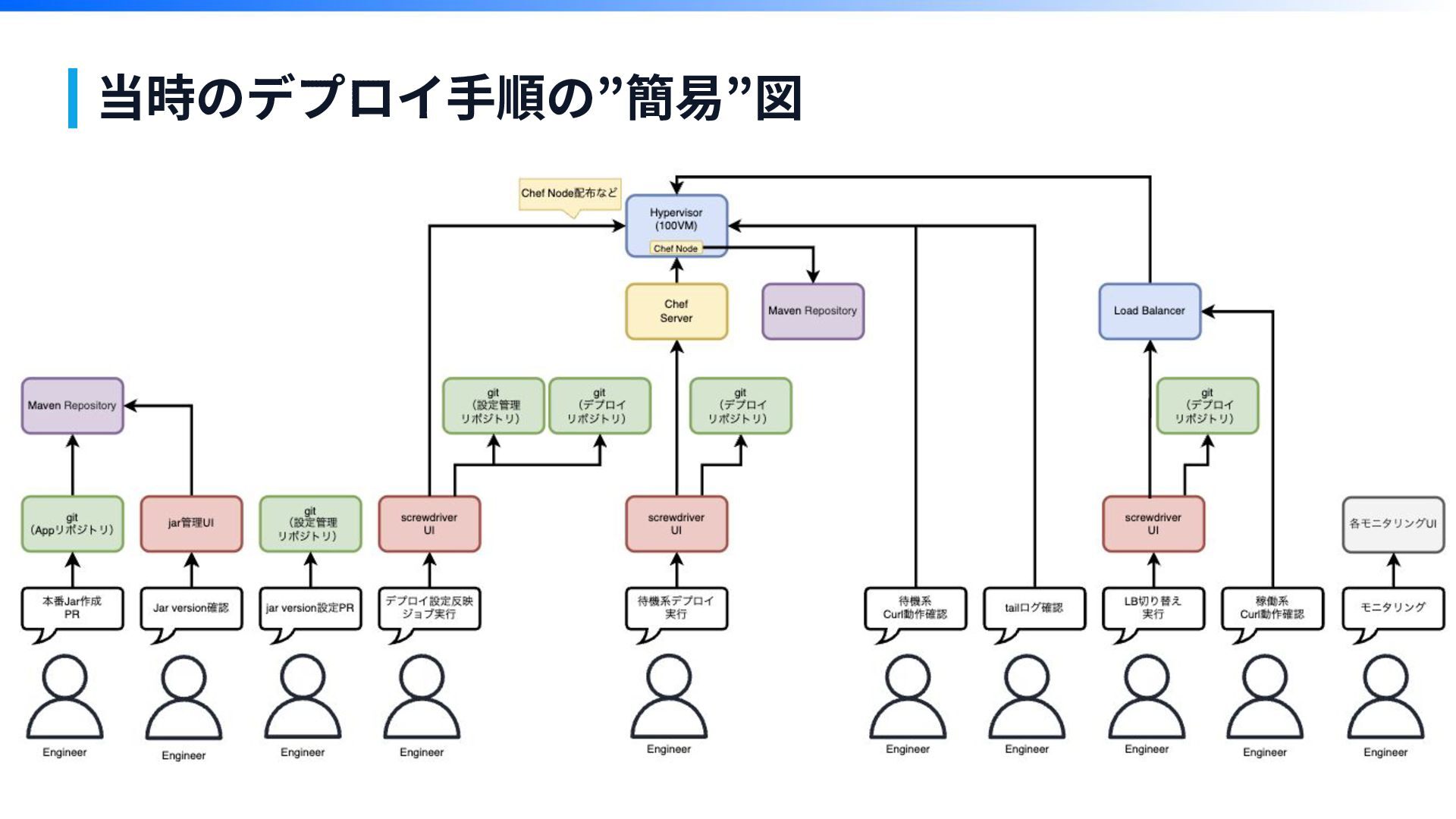
当時のデプロイ⼿順の”簡易”図
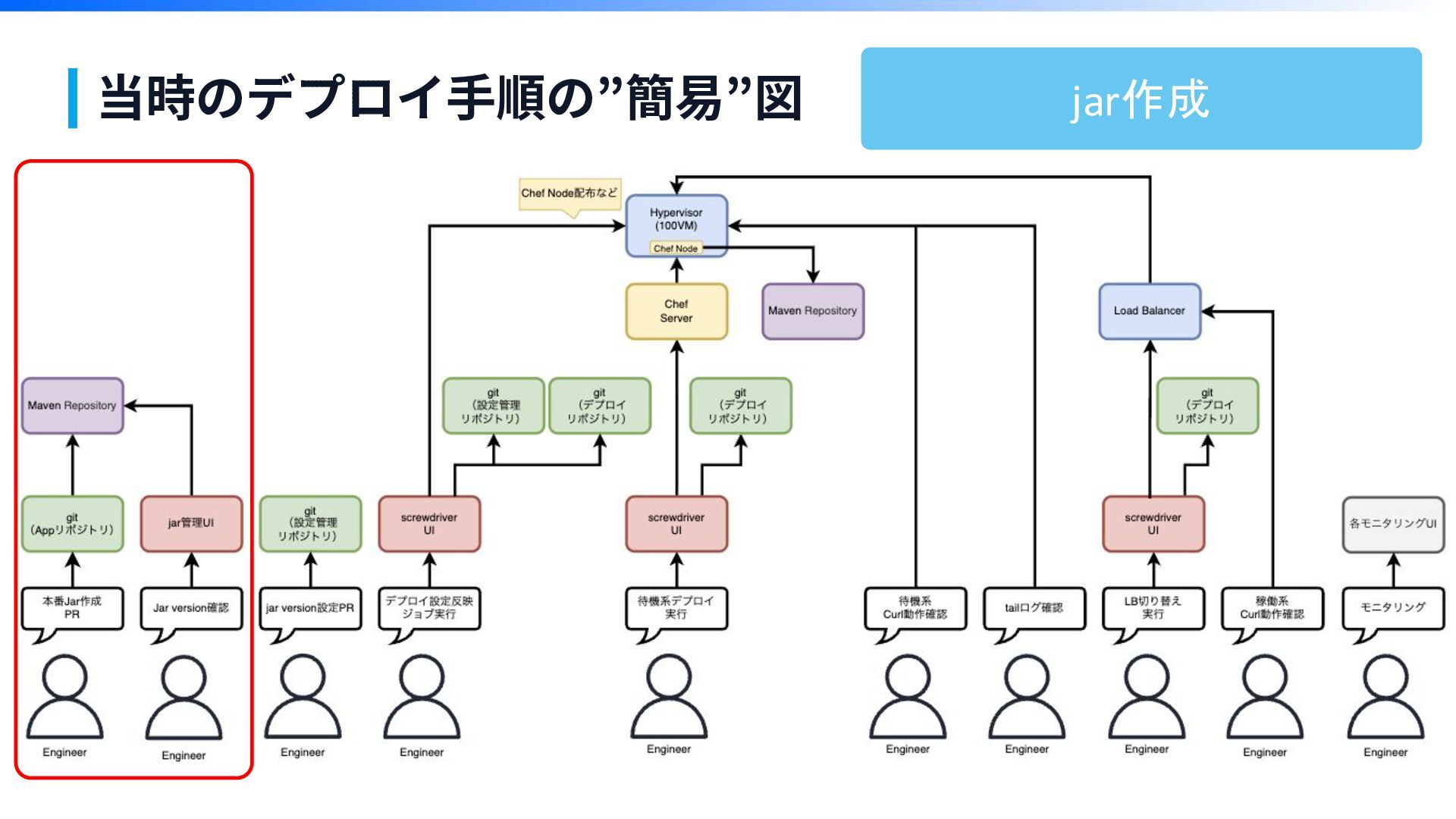
当時のデプロイ⼿順の”簡易”図 jar作成
当時のデプロイ⼿順の”簡易”図 デプロイjar指定
当時のデプロイ⼿順の”簡易”図 chef CookBook配る
当時のデプロイ⼿順の”簡易”図 総VMサーバ数 200台に curlとtailを実行 手動E2Eテスト? 待機系デプロイ
当時のデプロイ⼿順の”簡易”図 稼働系切り替え
当時のデプロイ⼿順の”簡易”図 10工程 うまくいかないと半 日潰れる
複雑かつ難解で、量が多い デプロイ⼯程の弊害 第1章
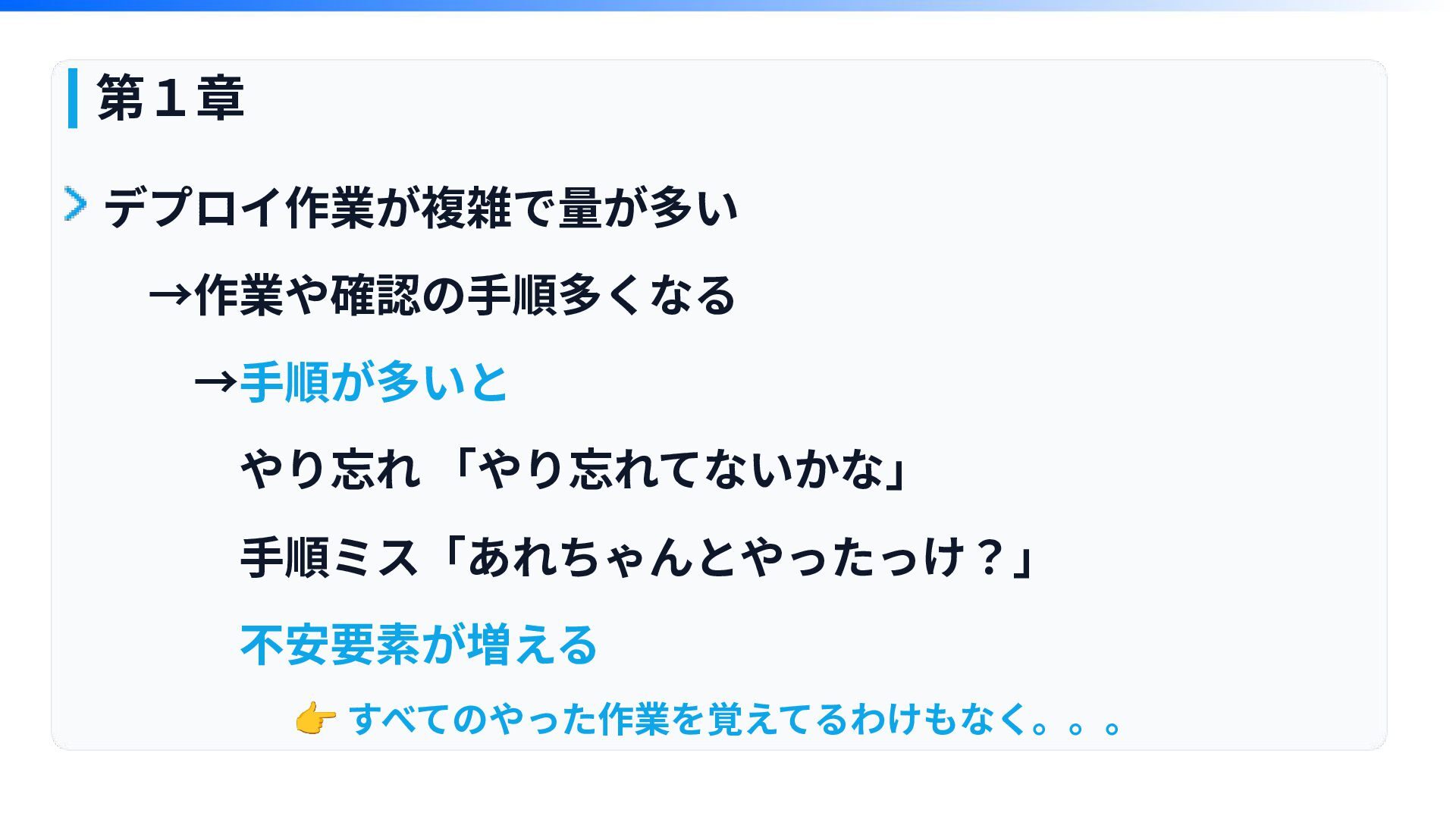
第1章 デプロイ作業が複雑で量が多い →作業や確認の⼿順多くなる →⼿順が多いと やり忘れ 「やり忘れてないかな」 ⼿順ミス「あれちゃんとやったっけ?」 不安要素が増える 👉 すべてのやった作業を覚えてるわけもなく。。。
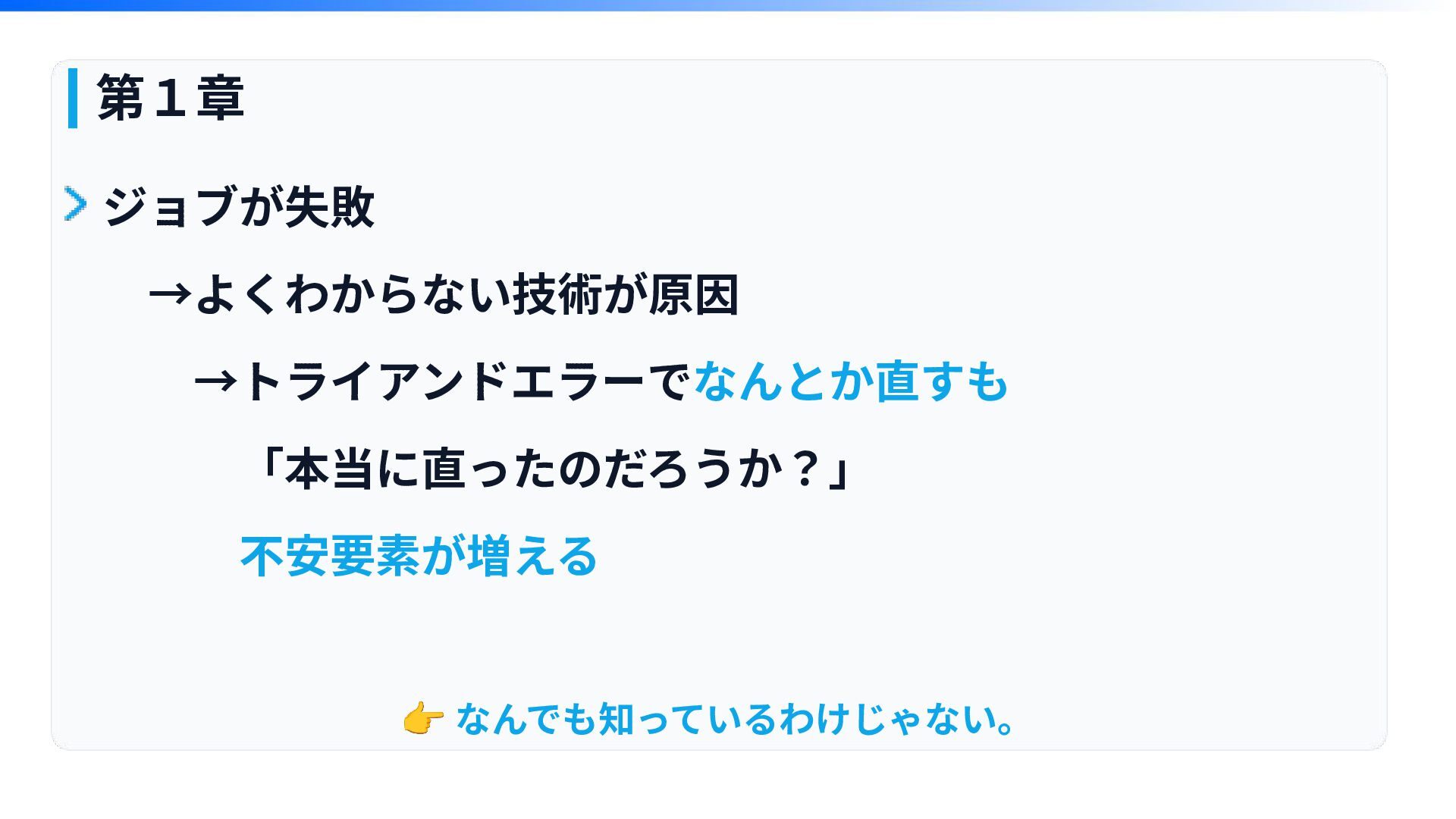
第1章 ジョブが失敗 →よくわからない技術が原因 →トライアンドエラーでなんとか直すも 「本当に直ったのだろうか?」 不安要素が増える 👉 なんでも知っているわけじゃない。
不安要素が増えると 最後のボタンを押すのが怖い 第1章
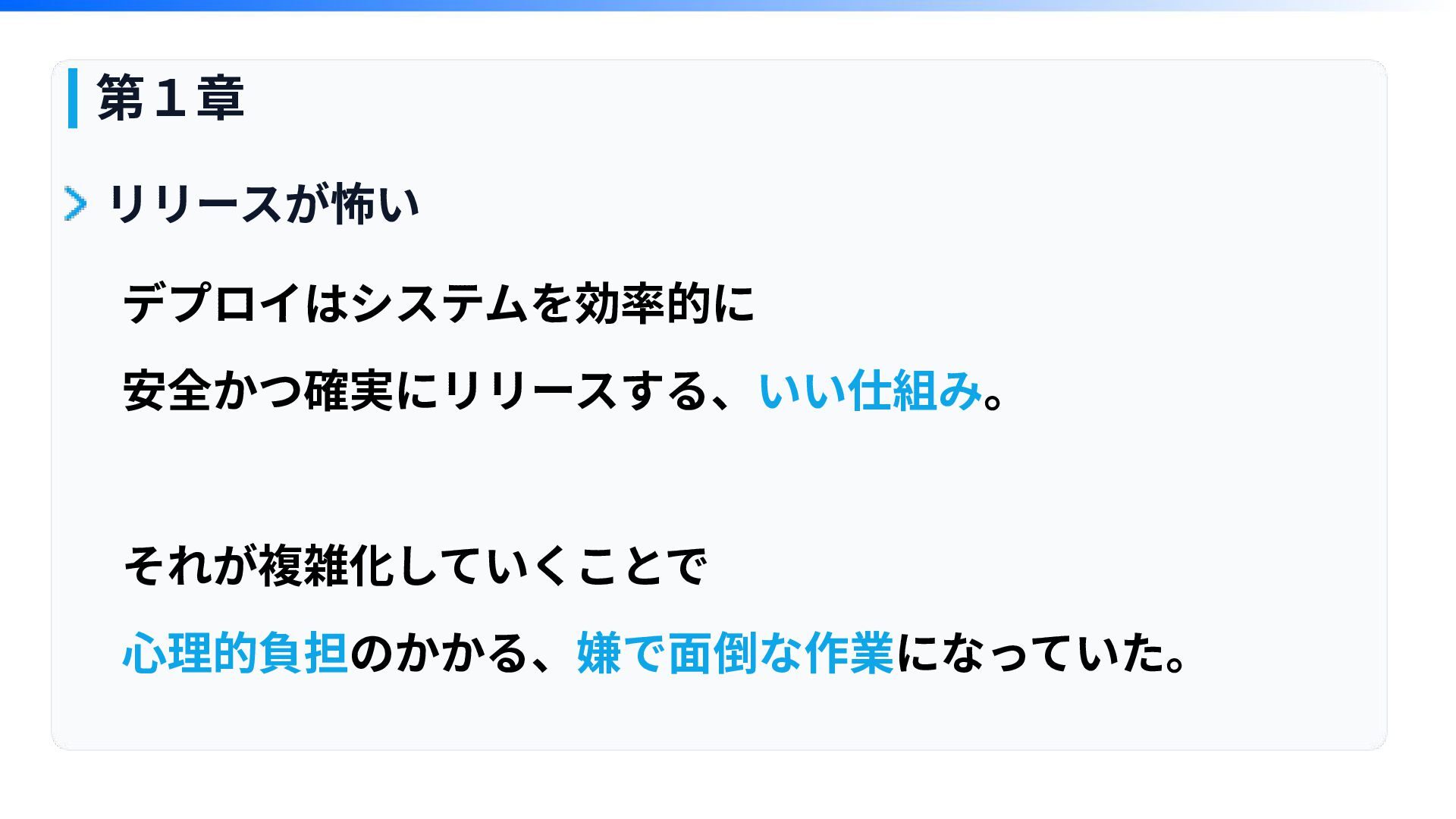
第1章 リリースが怖い デプロイはシステムを効率的に 安全かつ確実にリリースする、いい仕組み。 それが複雑化していくことで ⼼理的負担のかかる、嫌で⾯倒な作業になっていた。
第1章 👉デプロイの負のスパイラル。これが停滞の正体。 不安が⼤きくなる = 最後のボタンを押すのが怖い → 不安だから、できるだけリリースしたくない →リリース頻度が減る →ビッグバンリリースが増え →さらに不安が増える
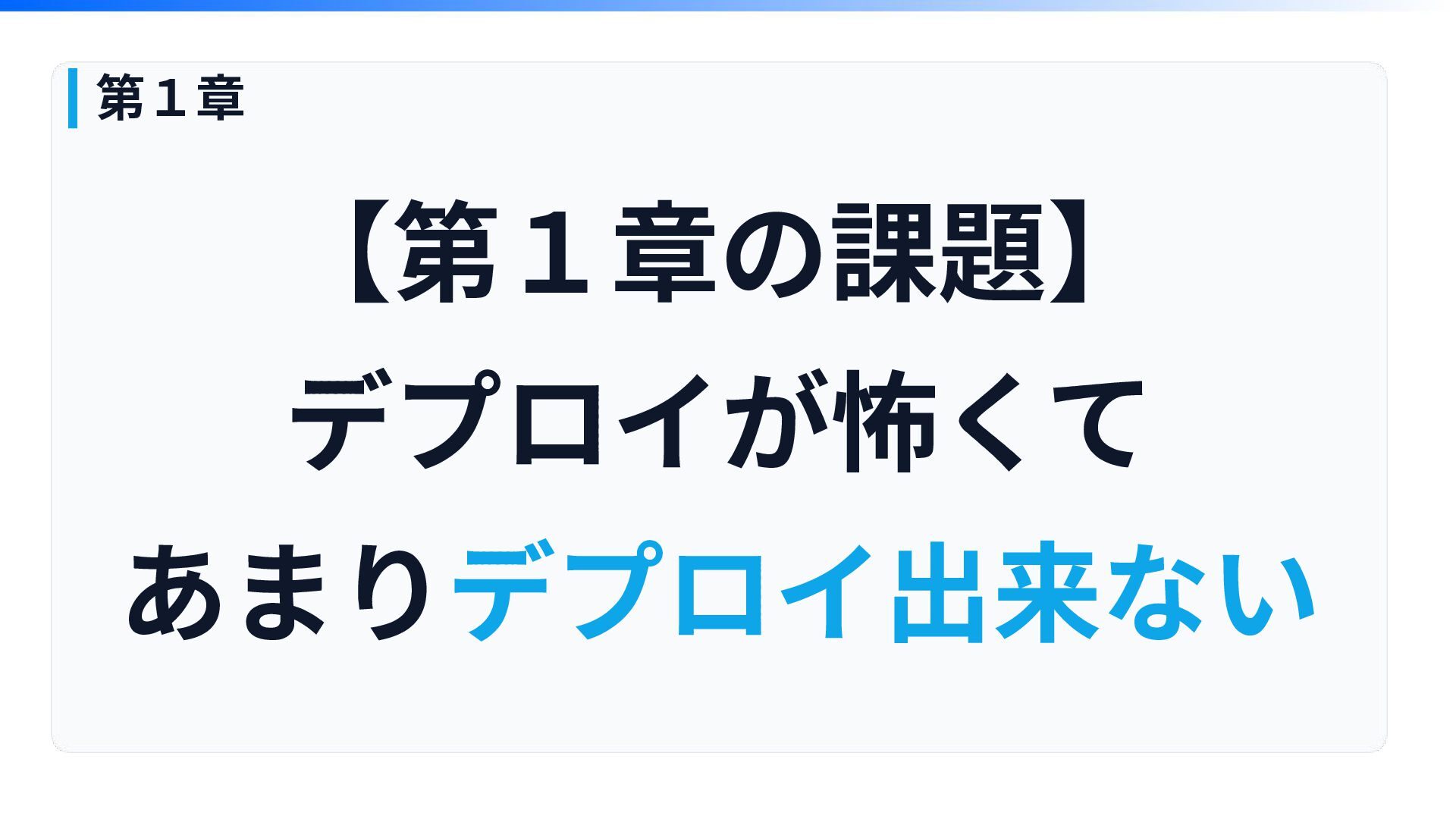
【第1章の課題】 デプロイが怖くて あまりデプロイ出来ない 第1章
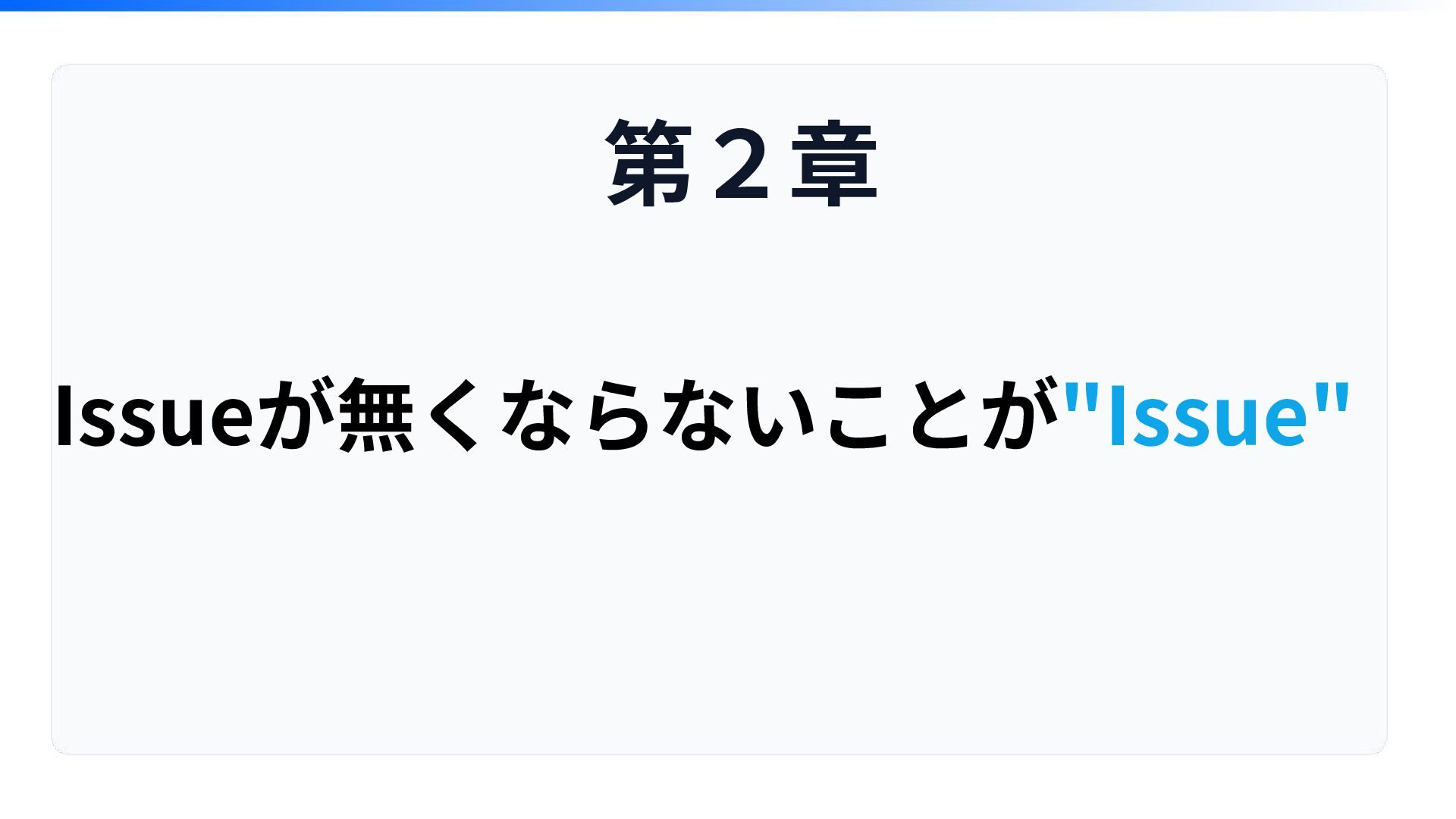
Issueが無くならないことが"Issue" 第2章
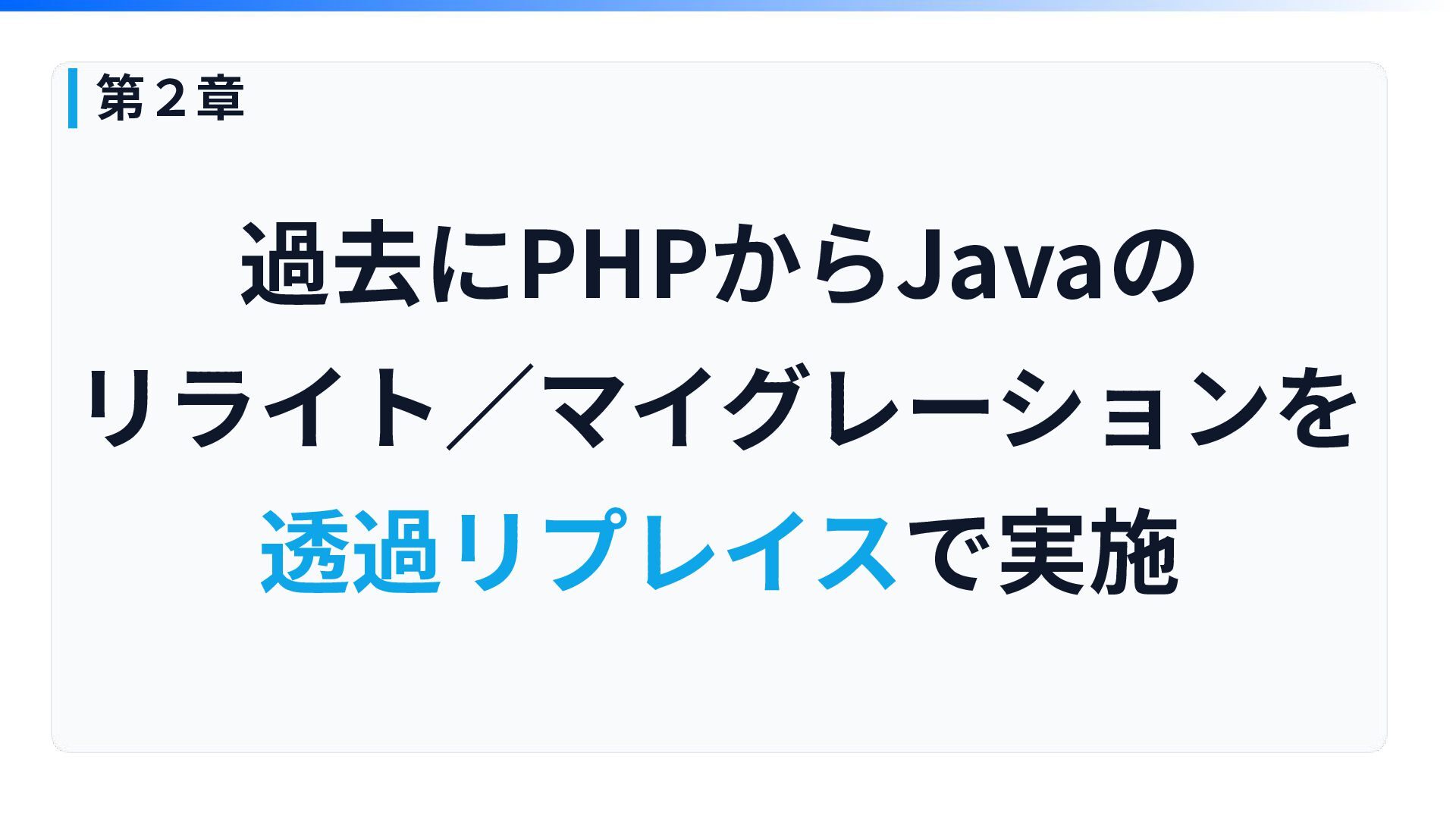
過去にPHPからJavaの リライト∕マイグレーションを 透過リプレイスで実施 第2章
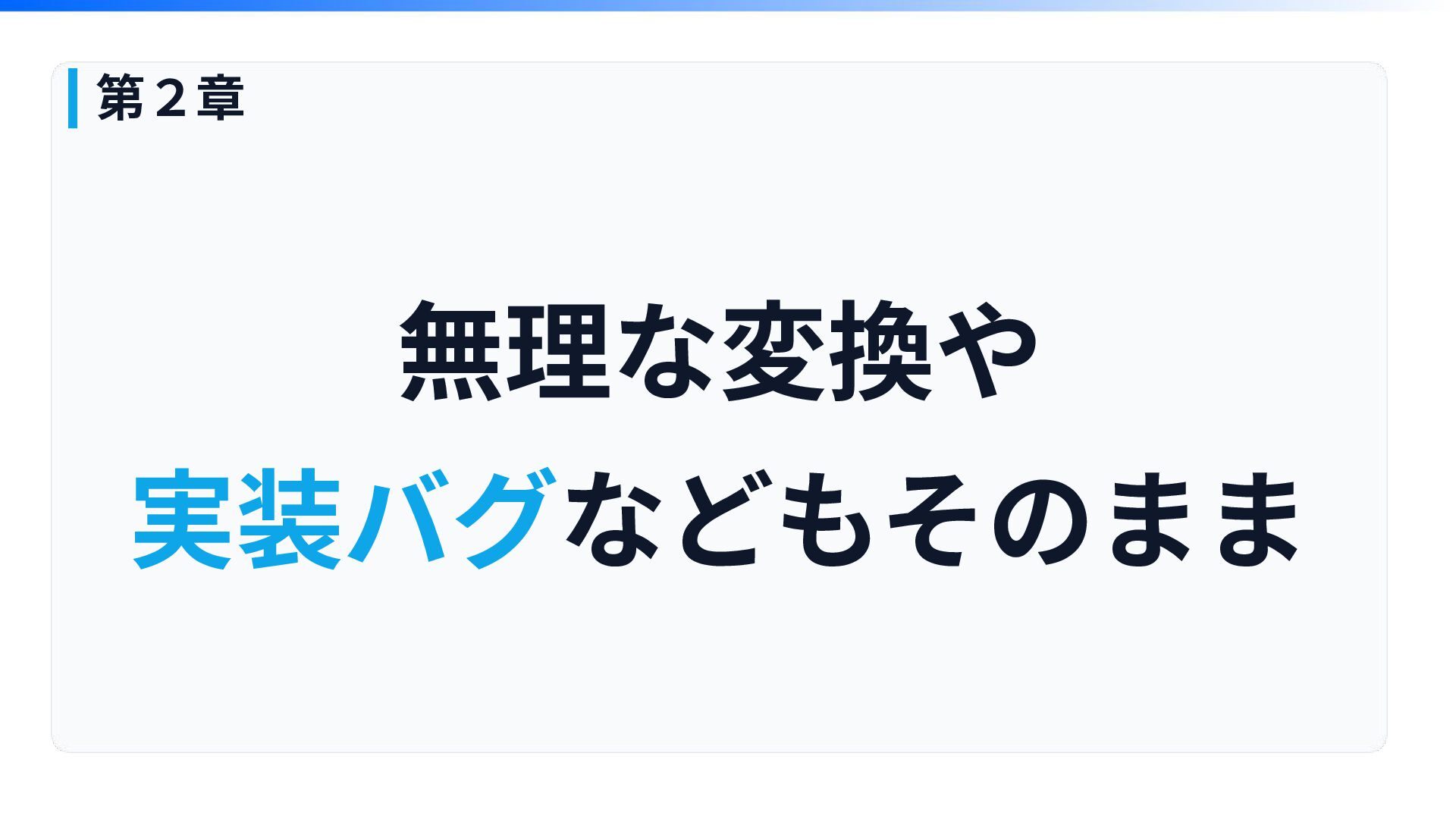
無理な変換や 実装バグなどもそのまま 第2章
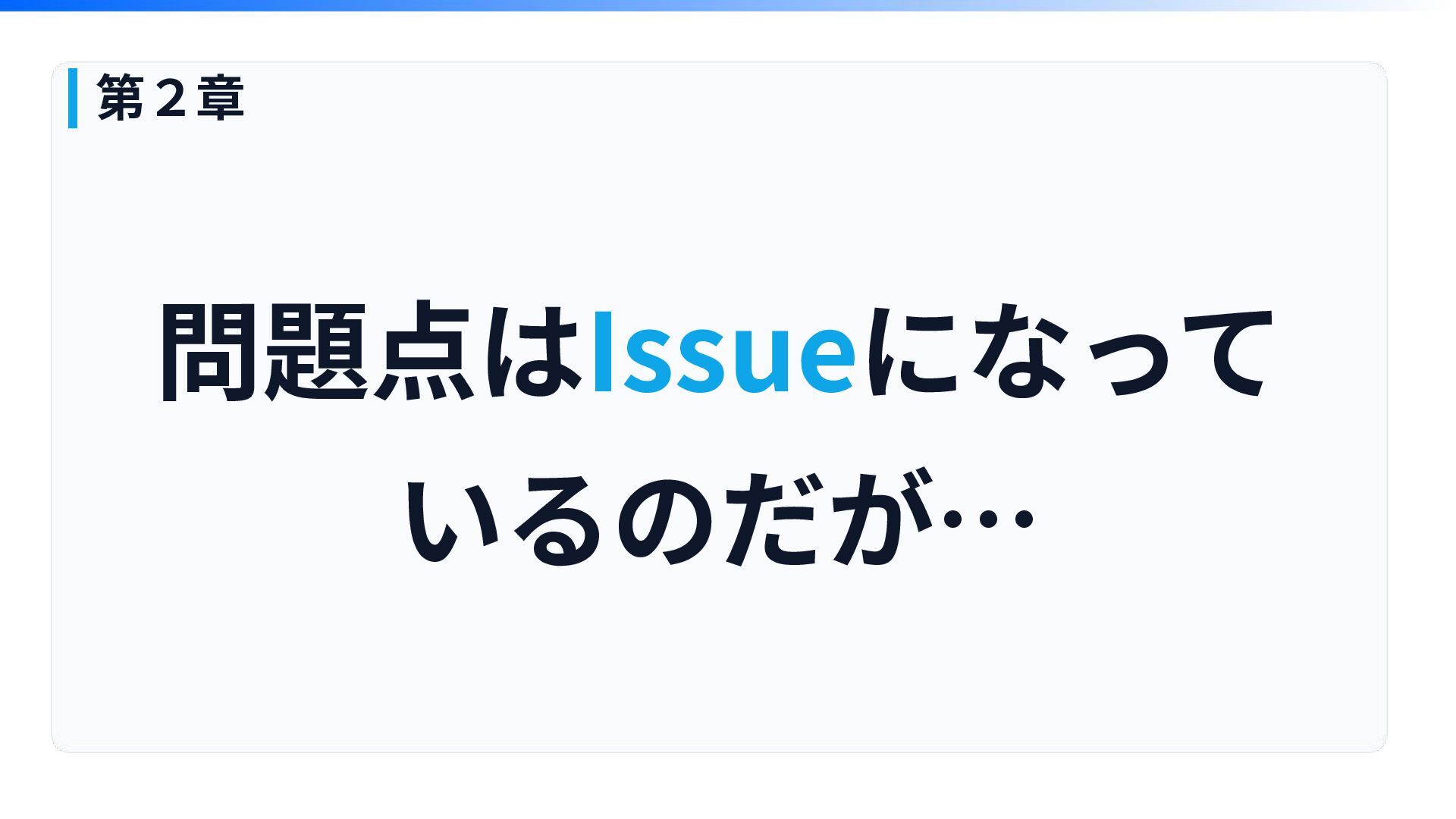
問題点はIssueになって いるのだが… 第2章
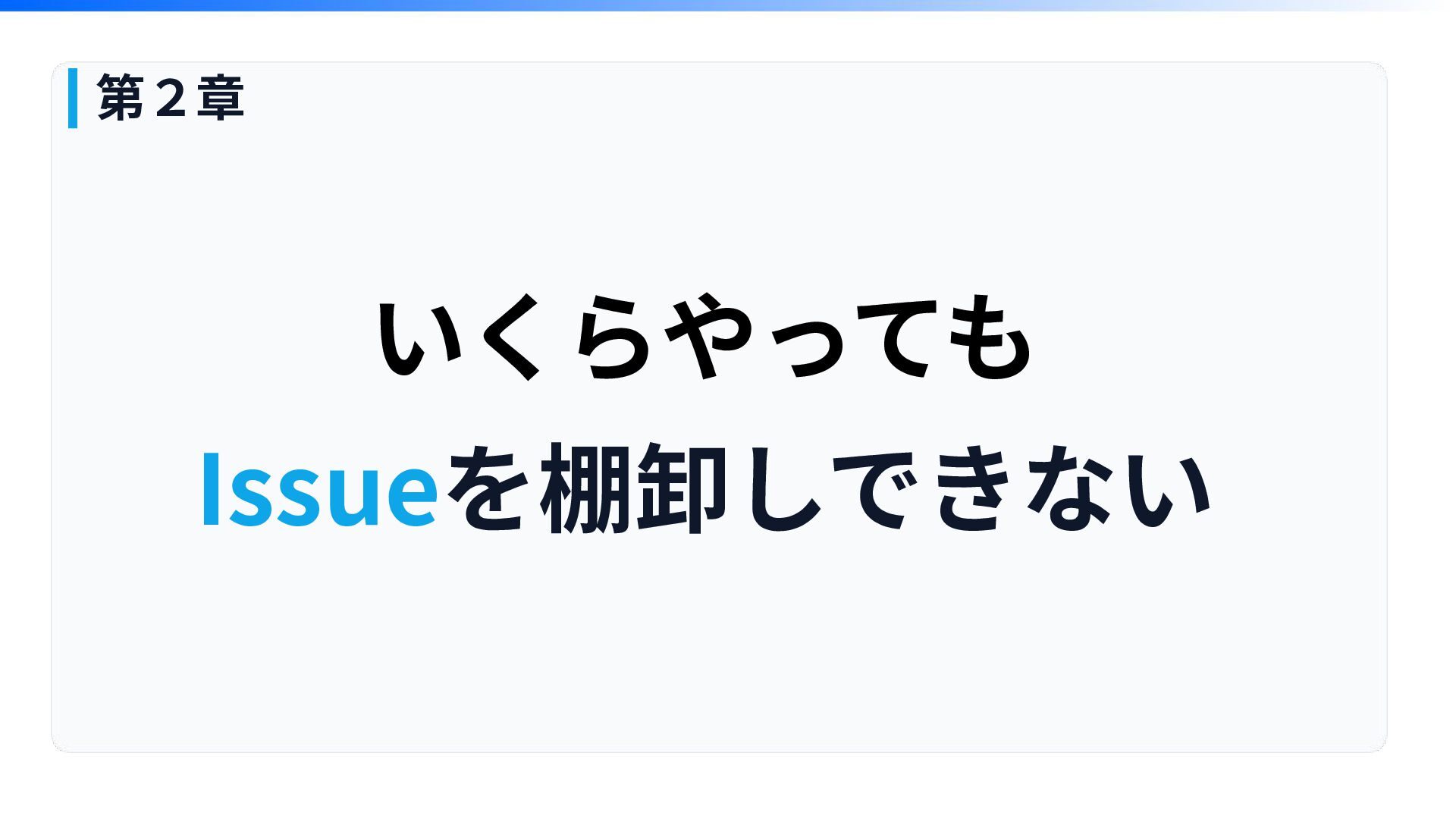
いくらやっても Issueを棚卸しできない 第2章
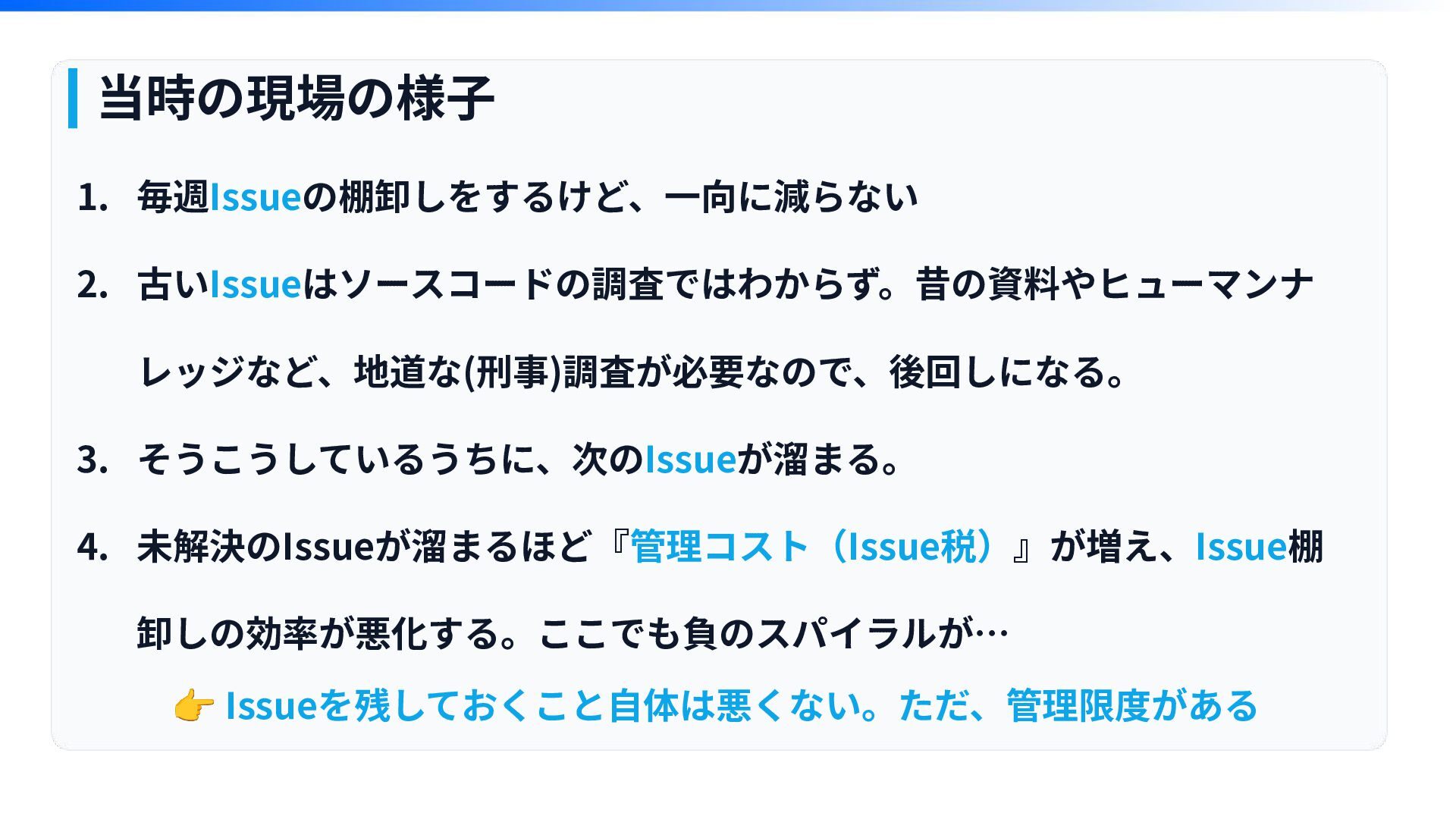
当時の現場の様⼦ 1. 毎週Issueの棚卸しをするけど、⼀向に減らない 2. 古いIssueはソースコードの調査ではわからず。昔の資料やヒューマンナ レッジなど、地道な(刑事)調査が必要なので、後回しになる。 3. そうこうしているうちに、次のIssueが溜まる。 4. 未解決のIssueが溜まるほど『管理コスト(Issue税)』が増え、Issue棚
卸しの効率が悪化する。ここでも負のスパイラルが… 👉 Issueを残しておくこと⾃体は悪くない。ただ、管理限度がある
Issue、Issue、Issueと Issueを考えすぎて Issueがなんだか わからなくなってきた 第2章
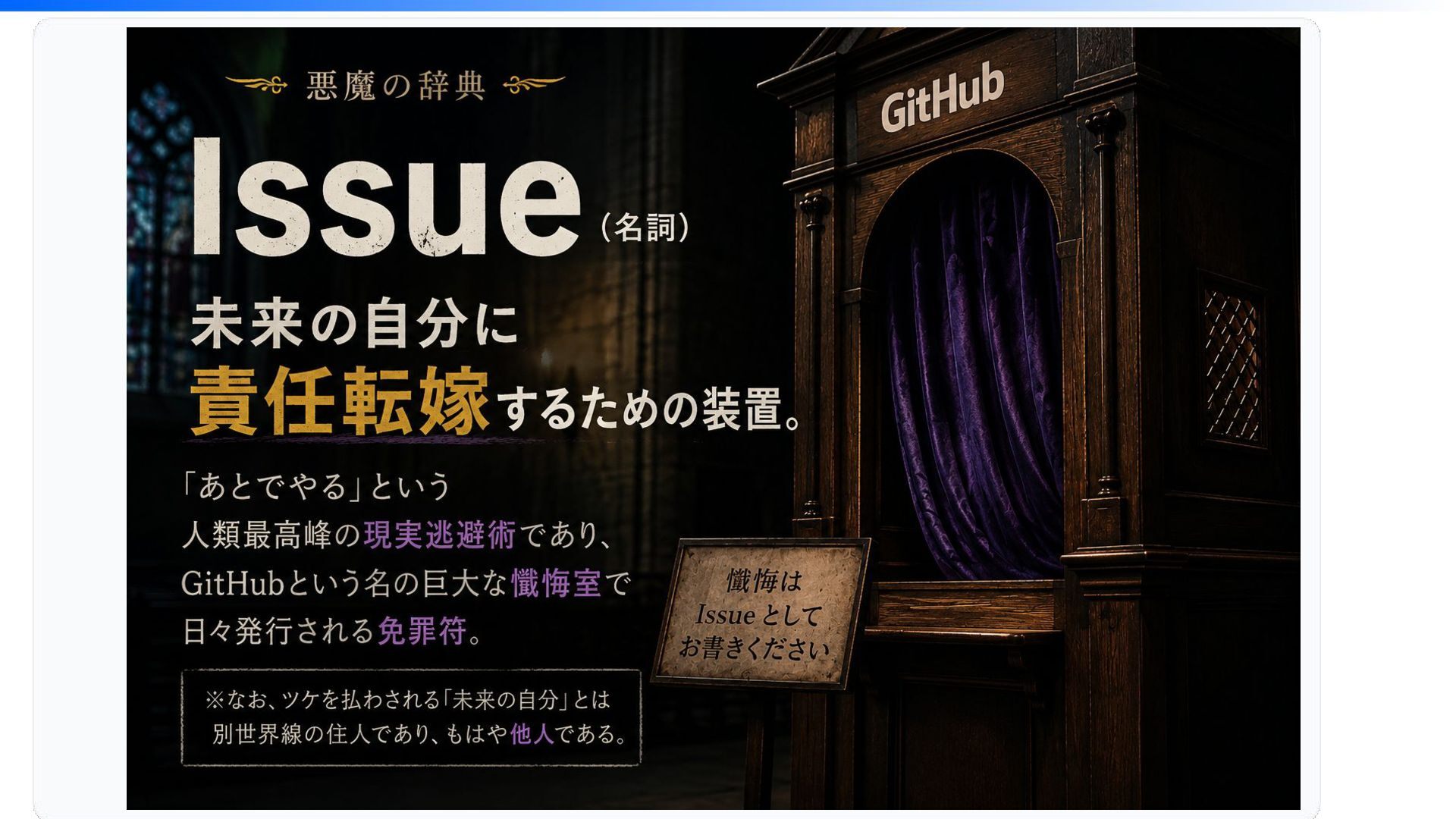
Geminiに「Issueとは?」 聞いてみた AIに聞いてみた
None
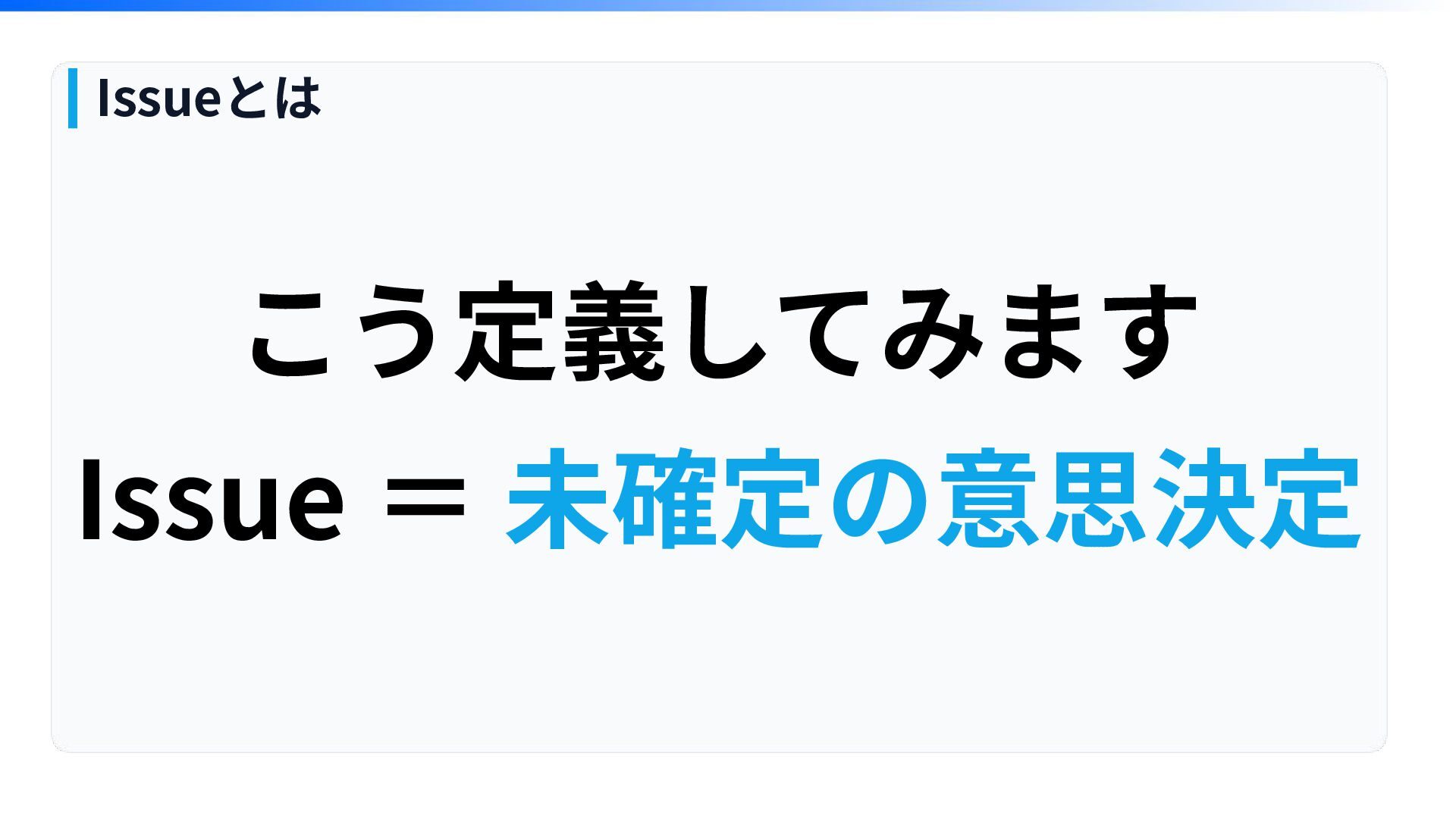
こう定義してみます Issue = 未確定の意思決定 Issueとは
【第2章の課題】 ⼀向に減らない Issue(未確定の意思決定) 第2章
変化の兆し、モダン化 第3章
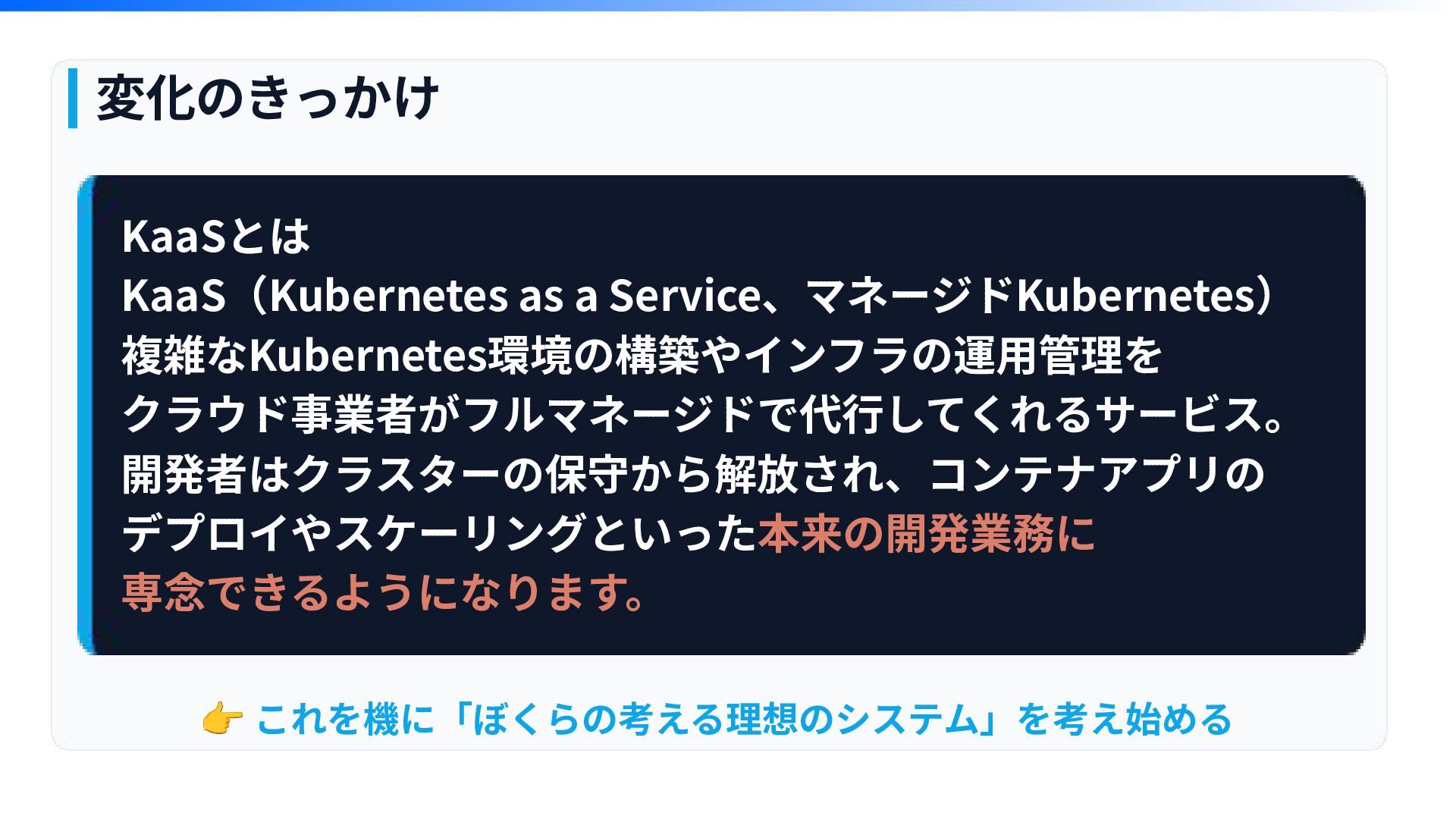
変化のきっかけ モダン化して、イケてるDevOpsを⽬指せとの号令 あわせて、SREに取り組めとの号令 👉 これを機に「ぼくらの考える理想のシステム」を考え始める → 仮想サーバから、KaaSのCloudService移⾏ → 独⾃監視システムから⼀般的なObservability システムに移⾏
変化のきっかけ モダン化して、イケてるDevOpsを⽬指せとの号令 あわせて、SREに取り組めとの号令 👉 これを機に「ぼくらの考える理想のシステム」を考え始める → 仮想サーバから、KaaSのCloudService移⾏ → 独⾃監視システムから⼀般的なObservability システムに移⾏
KaaSとは KaaS(Kubernetes as a Service、マネージドKubernetes) 複雑なKubernetes環境の構築やインフラの運⽤管理を クラウド事業者がフルマネージドで代⾏してくれるサービス。 開発者はクラスターの保守から解放され、コンテナアプリの デプロイやスケーリングといった本来の開発業務に 専念できるようになります。
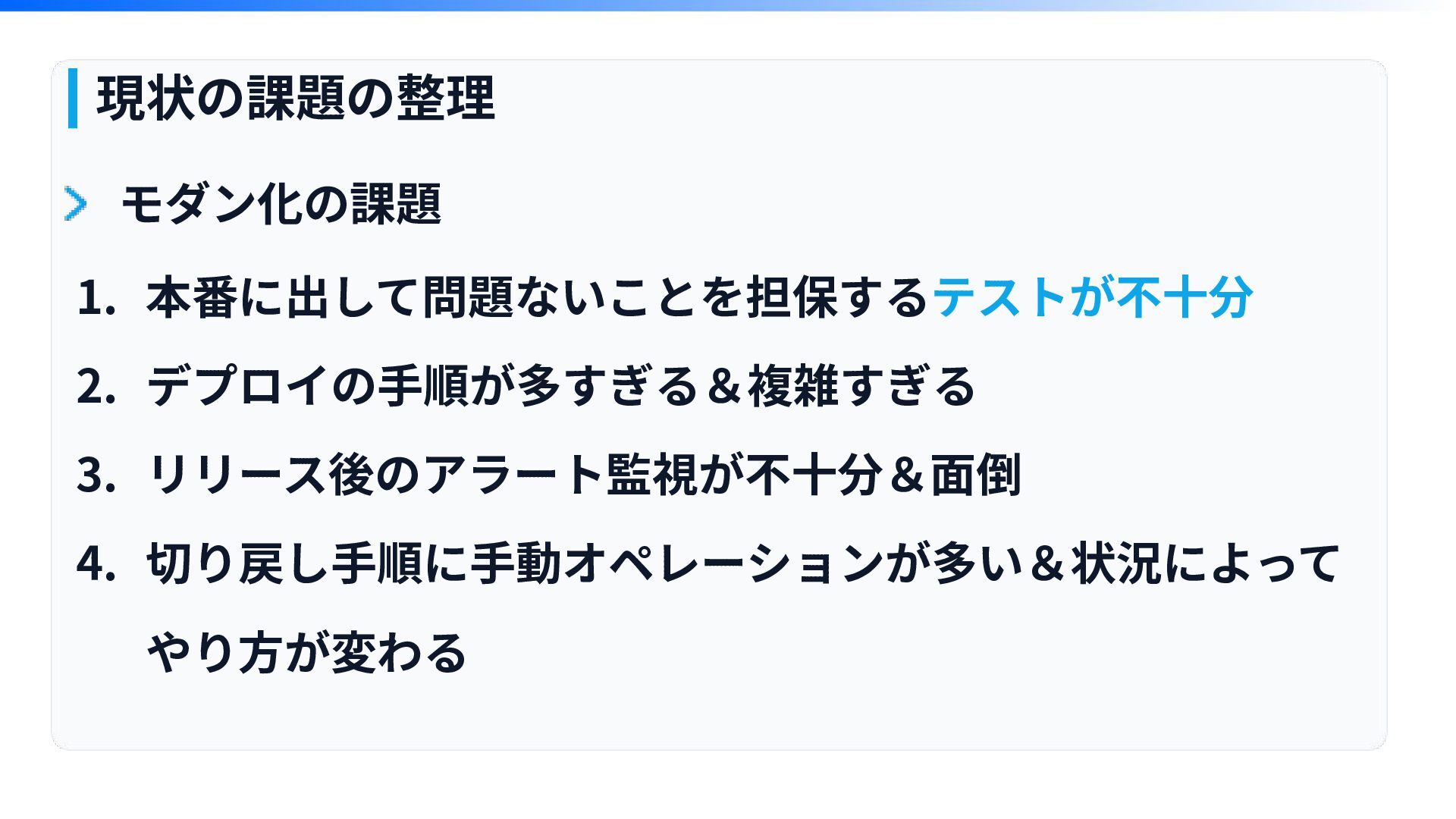
モダン化の課題 第3章
現状の課題の整理 1. 本番に出して問題ないことを担保するテストが不⼗分 2. デプロイの⼿順が多すぎる&複雑すぎる 3. リリース後のアラート監視が不⼗分&⾯倒 4. 切り戻し⼿順に⼿動オペレーションが多い&状況によって やり⽅が変わる
モダン化の課題
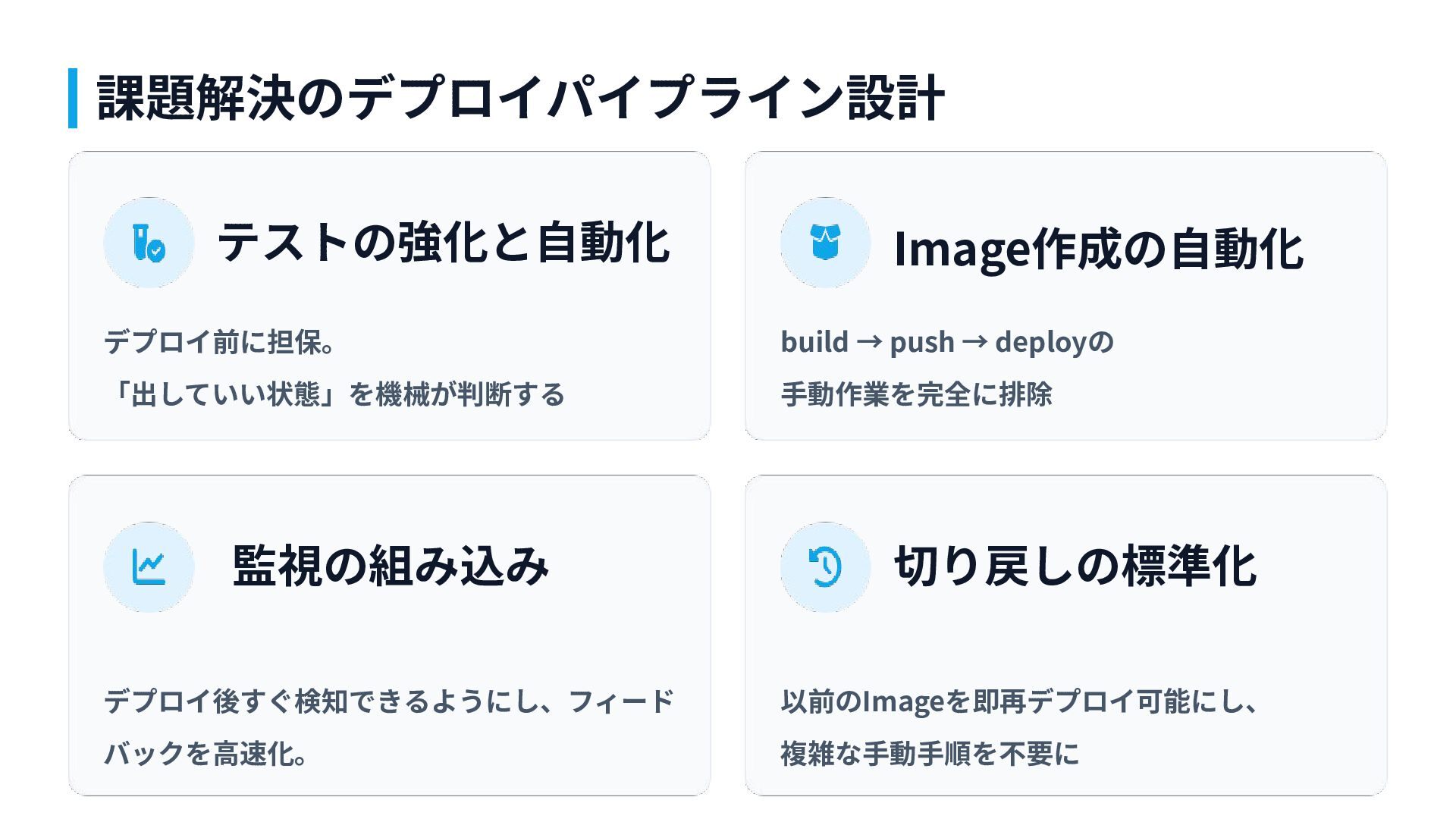
理想のデプロイ設計を 考えてみた 第3章
テストの強化と⾃動化 デプロイ前に担保。 「出していい状態」を機械が判断する Image作成の⾃動化 build → push → deployの ⼿動作業を完全に排除
監視の組み込み デプロイ後すぐ検知できるようにし、フィード バックを⾼速化。 切り戻しの標準化 以前のImageを即再デプロイ可能にし、 複雑な⼿動⼿順を不要に 課題解決のデプロイパイプライン設計
理想の デプロイパイプライン 第3章
当時のデプロイ⼿順の”簡易”図 10工程 うまくいかないと半 日潰れる
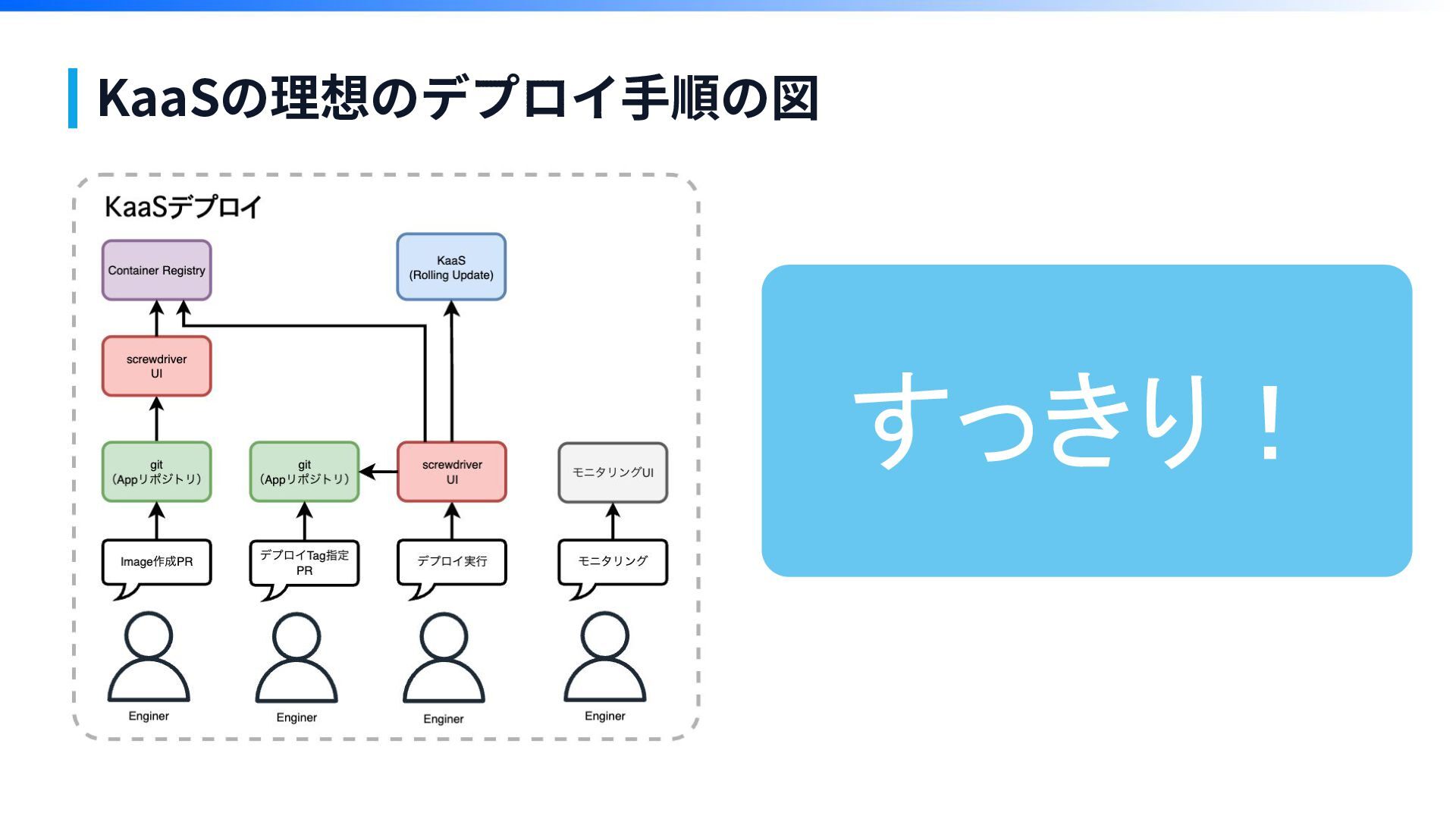
KaaSの理想のデプロイ⼿順の図 すっきり!
デプロイ⼿順 1. Image作成 2. デプロイTag指定 3. デプロイ実⾏ 4. モニタリング監視 第3章
10工程 4工程
改善した デプロイパイプライン KaaS(k8s Deploy) 第3章
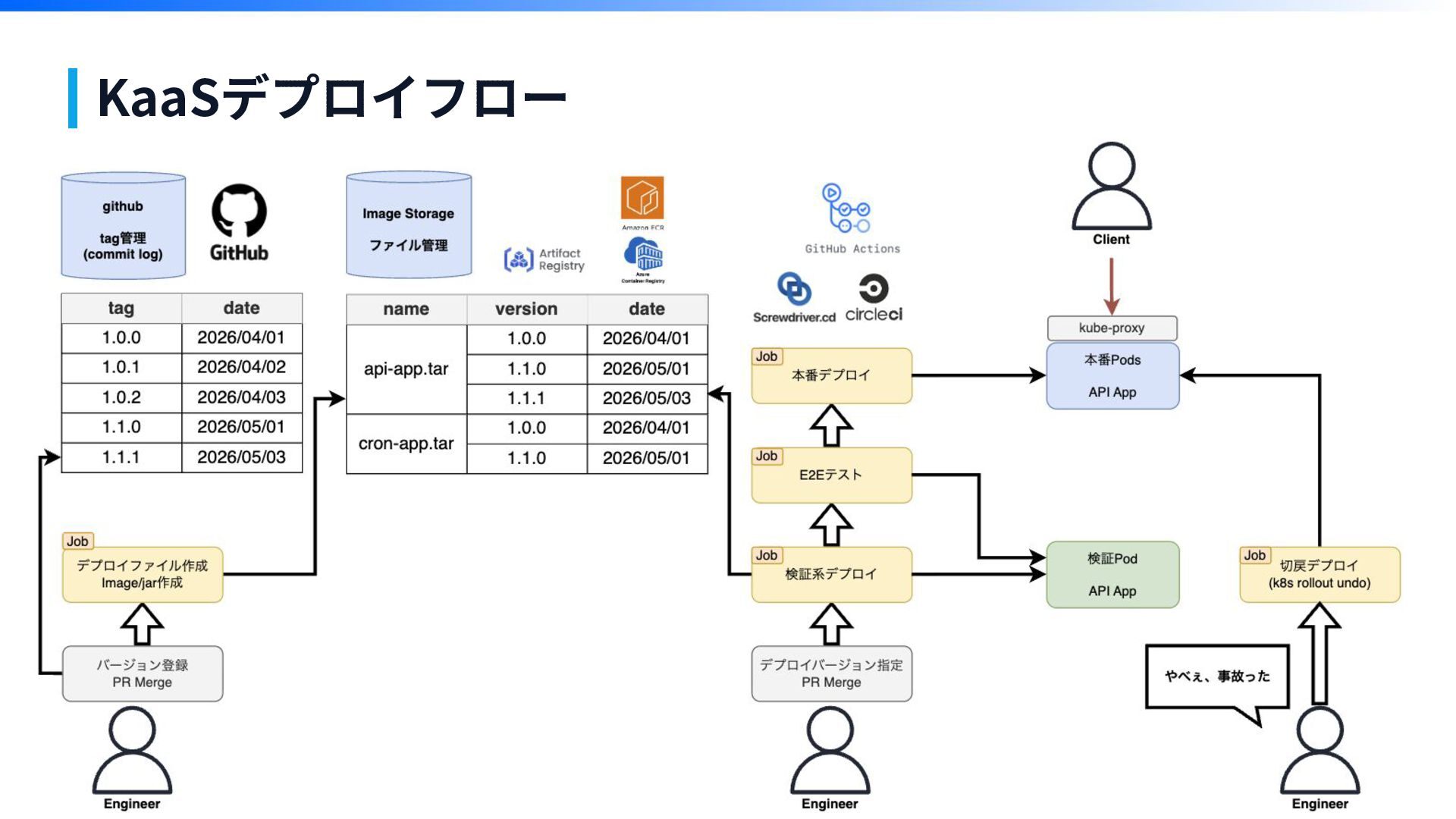
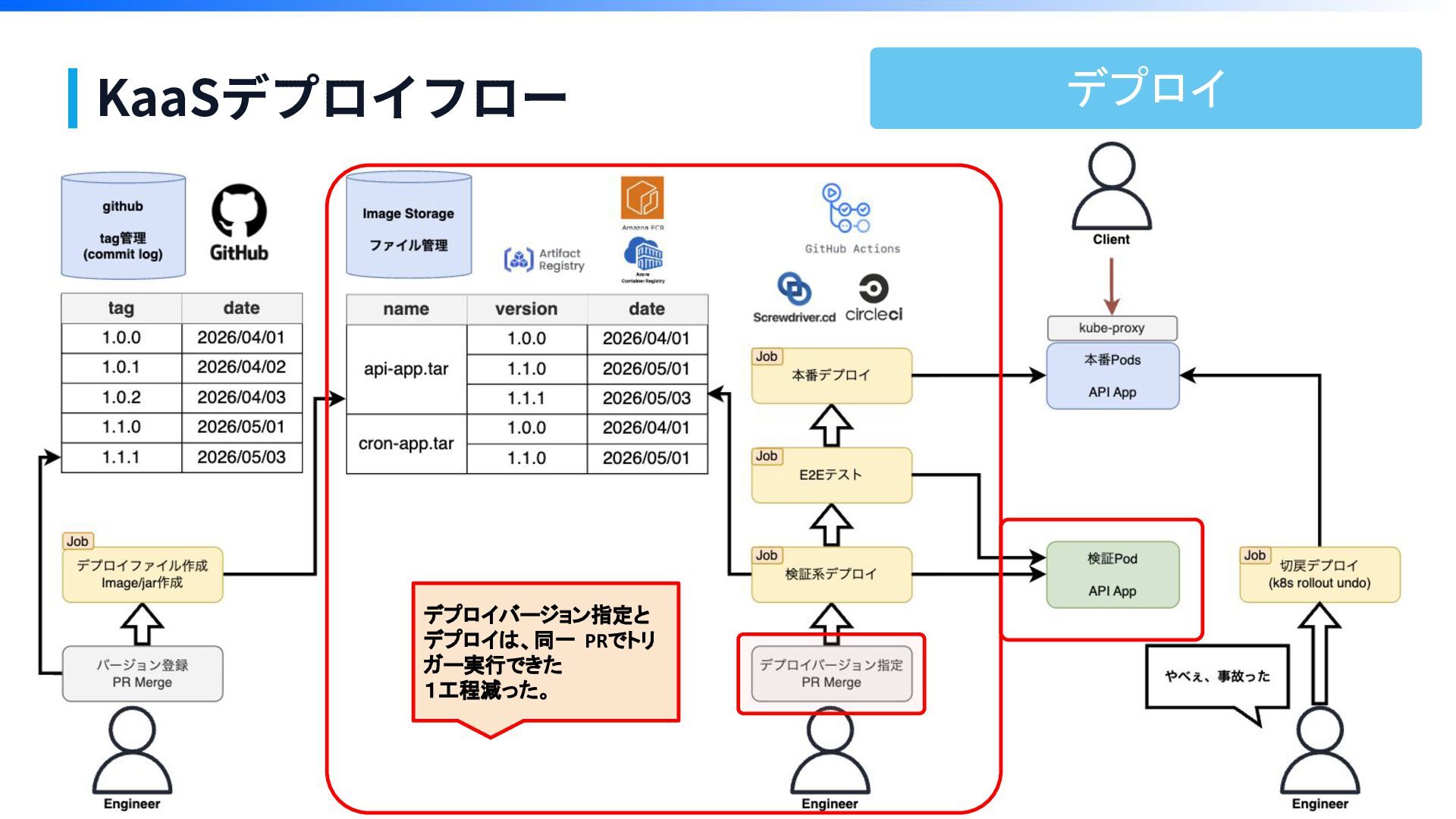
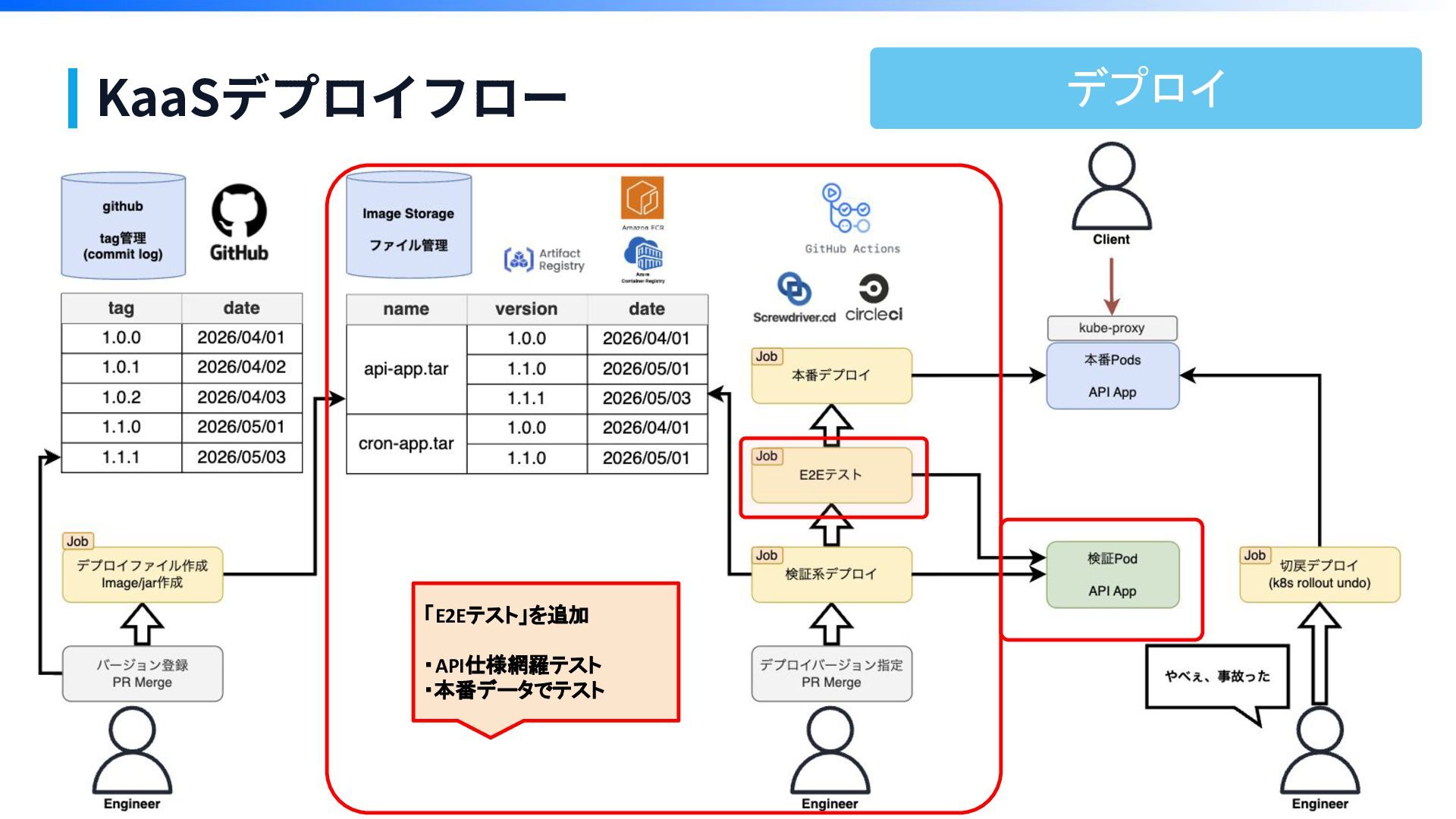
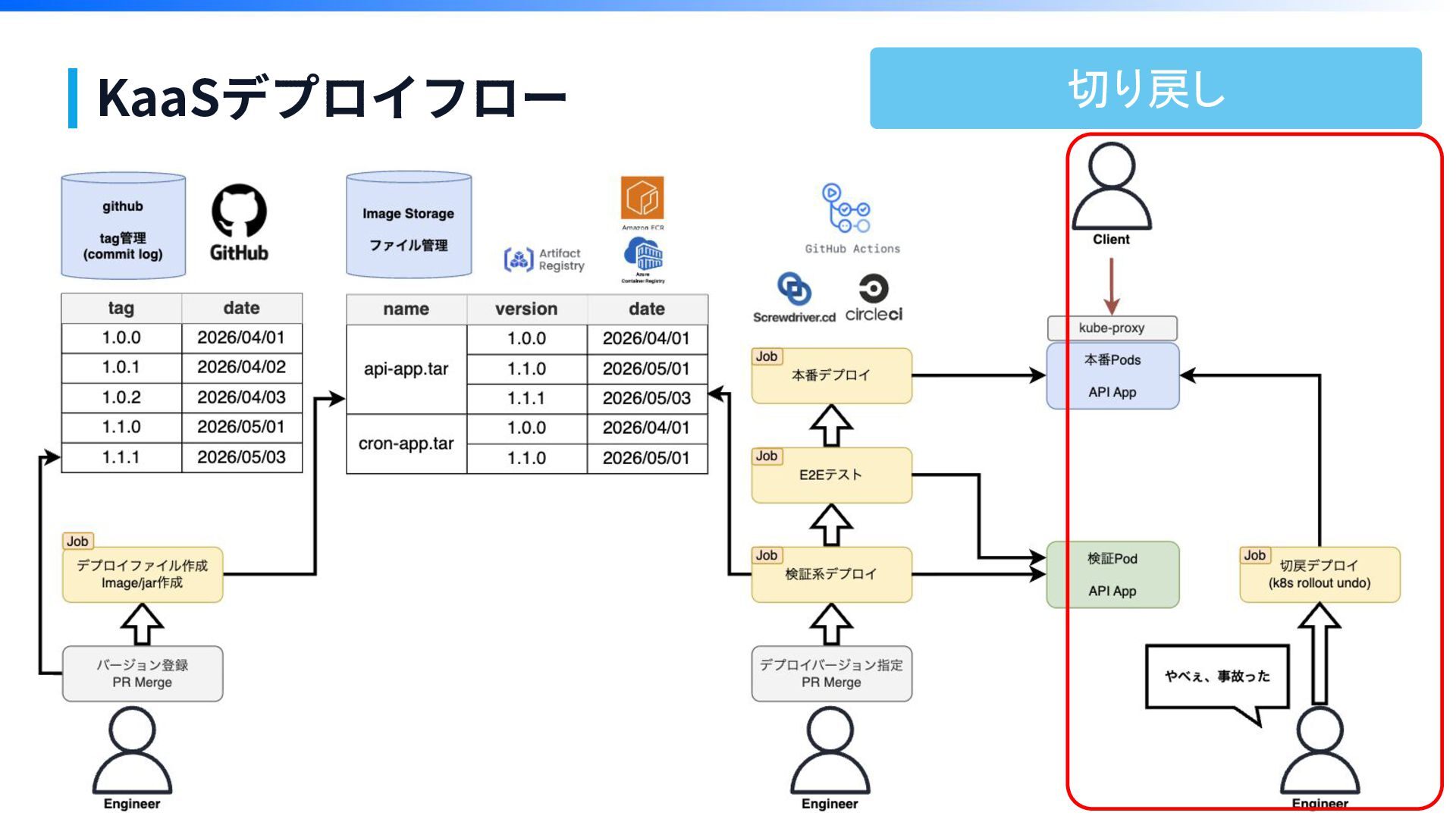
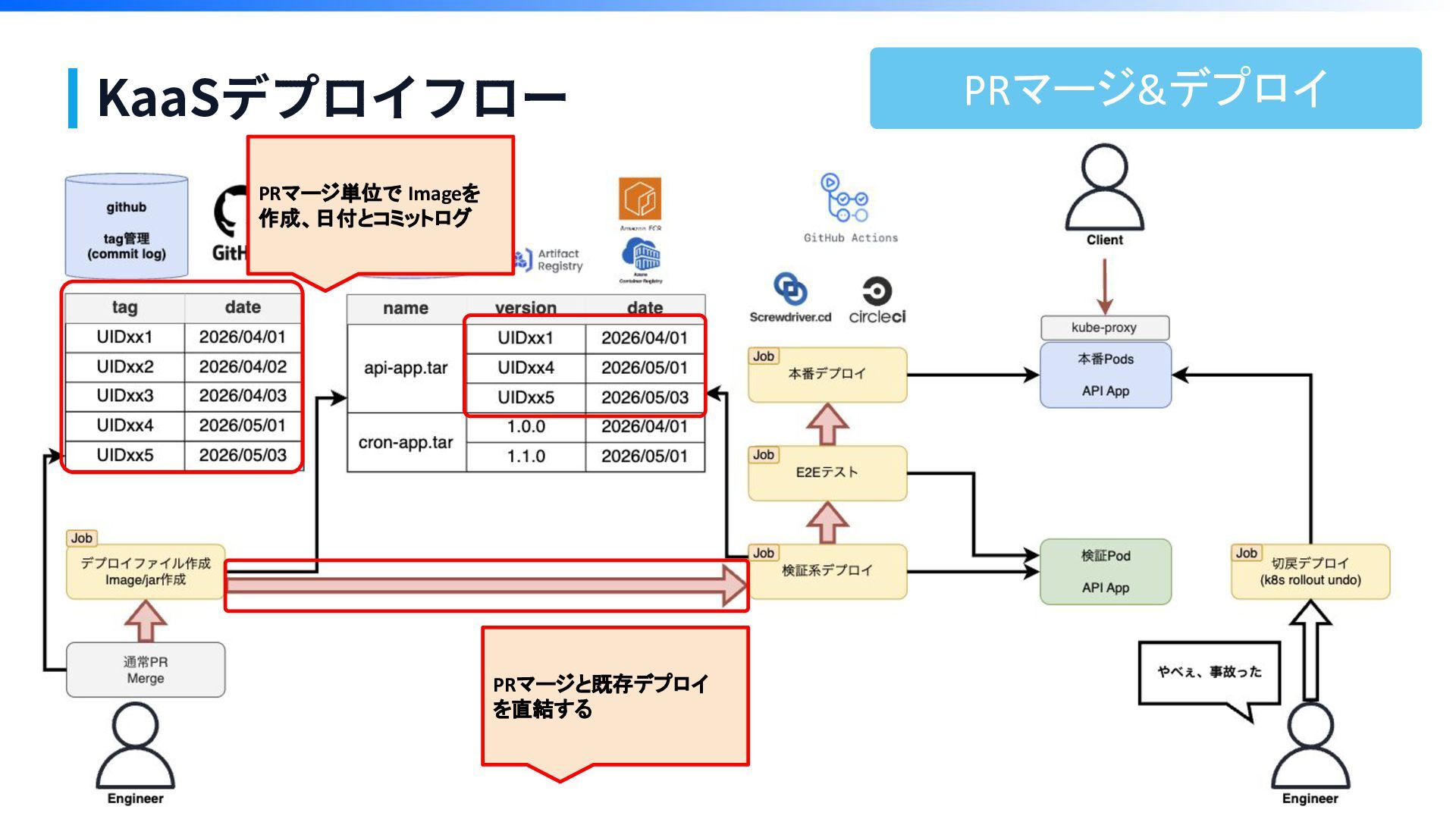
KaaSデプロイフロー
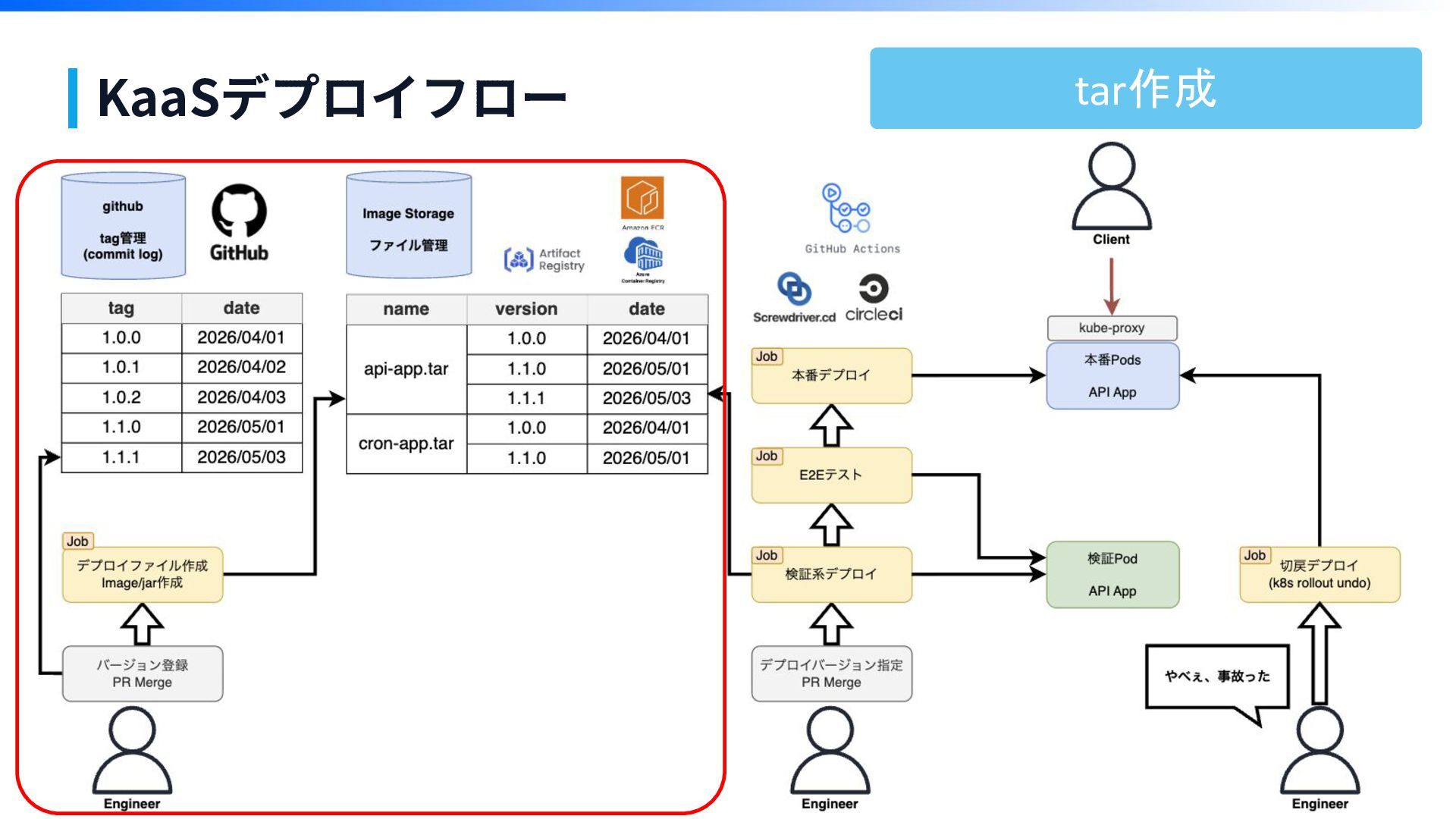
KaaSデプロイフロー tar作成
KaaSデプロイフロー デプロイバージョン指定と デプロイは、同一 PRでトリ ガー実行できた 1工程減った。 デプロイ
KaaSデプロイフロー 「E2Eテスト」を追加 ・API仕様網羅テスト ・本番データでテスト デプロイ
KaaSデプロイフロー 切り戻し
改善した システム構成 第3章
アーキテクチャ概要 CI/CDの構成要素がすっきり!
アーキテクチャ概要 さよなら独⾃技術。はじめまして⼀般技術(OSS、メジャー機能)。
アーキテクチャ概要 ⾯倒なVMインフラ構築から、コードベースインフラに!
以上がモダン化対応 第3章
SRE対応の課題 第3章
SREってなんぞ? (SREがわからない) 第3章
Site Reliability Engineering サイト‧リライアビリティ‧エンジニアリング SREとは
計測と⾃動化により 信頼性と開発速度を両⽴する SREを極めて簡潔に⾔うと
計測って なにを測るの? SRE取り込み
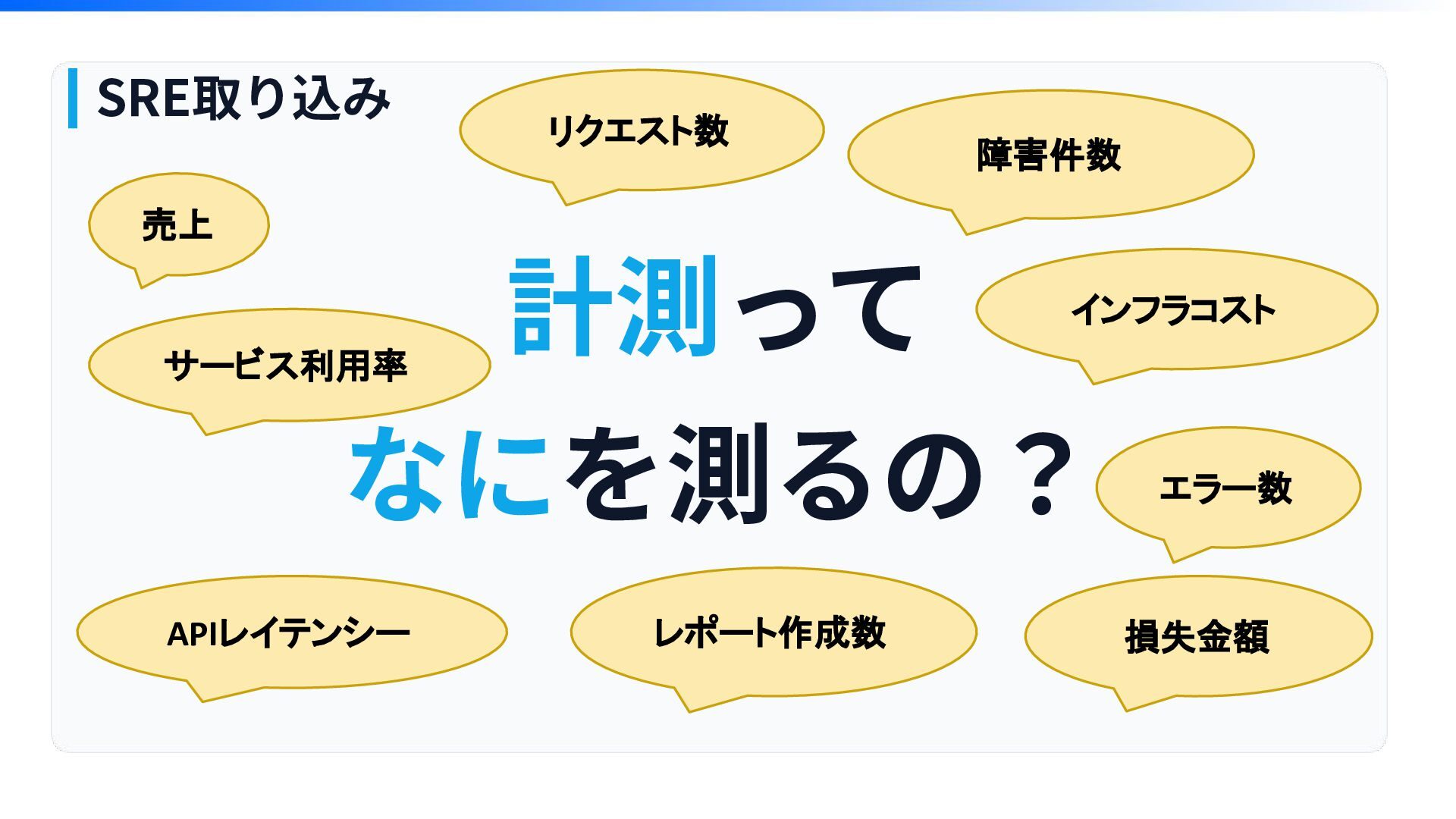
計測って なにを測るの? SRE取り込み 売上 サービス利用率 エラー数 APIレイテンシー リクエスト数 レポート作成数 障害件数
損失金額 インフラコスト
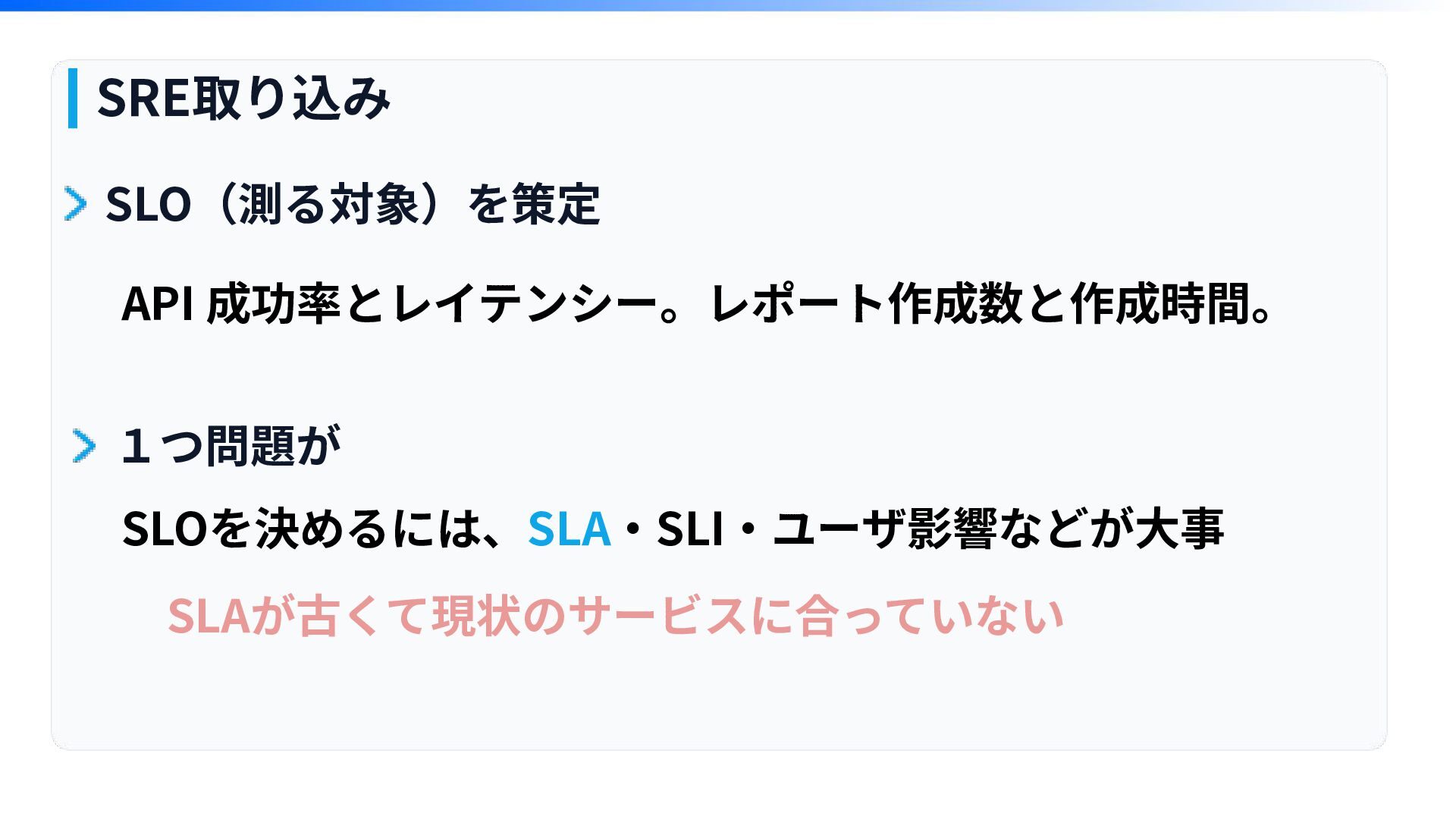
SRE取り込み SLO(測る対象)を策定 API 成功率とレイテンシー。レポート作成数と作成時間。 SLOを決めるには、SLA‧SLI‧ユーザ影響などが⼤事 SLAが古くて現状のサービスに合っていない 1つ問題が
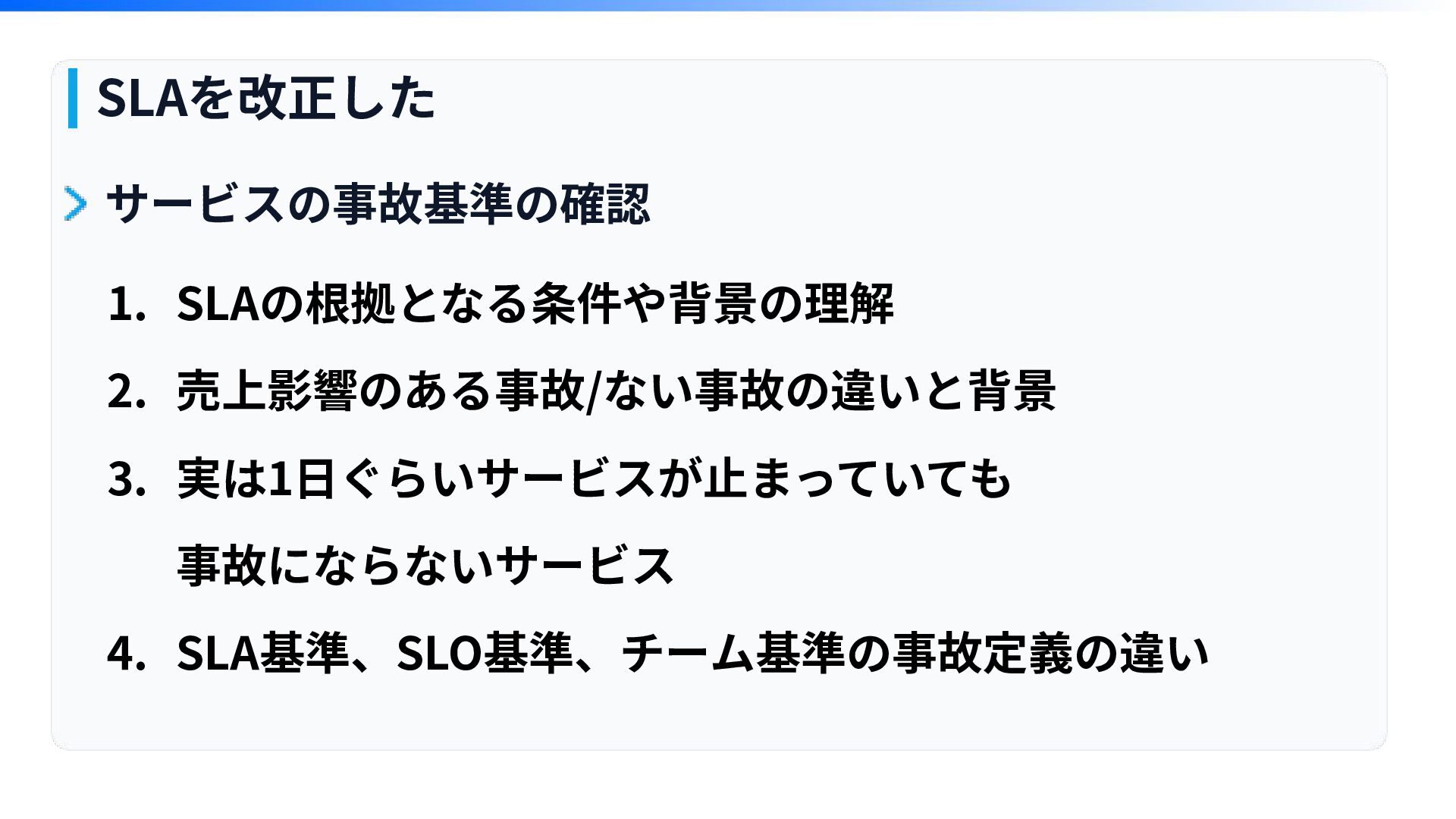
SLAを改正した サービスの事故基準の確認 1. SLAの根拠となる条件や背景の理解 2. 売上影響のある事故/ない事故の違いと背景 3. 実は1⽇ぐらいサービスが⽌まっていても 事故にならないサービス 4.
SLA基準、SLO基準、チーム基準の事故定義の違い
SLA,SLO策定業務の中で サービスの理解度が ⼤きく増した SRE取り込み 👉SLA、SLOを⾼い解像度で理解したことが、デプロイ200回の鍵
改善した 監視システム 第3章
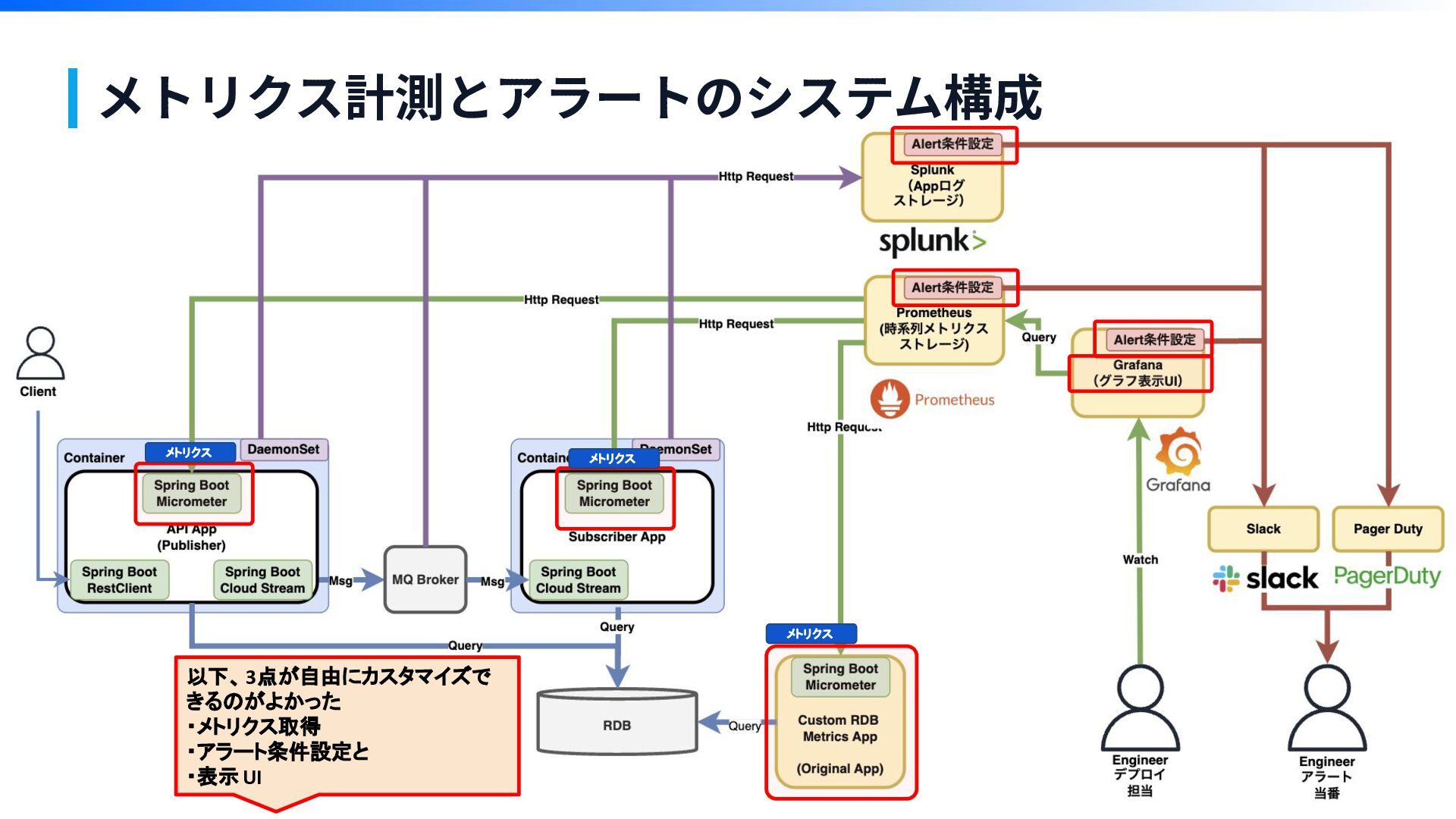
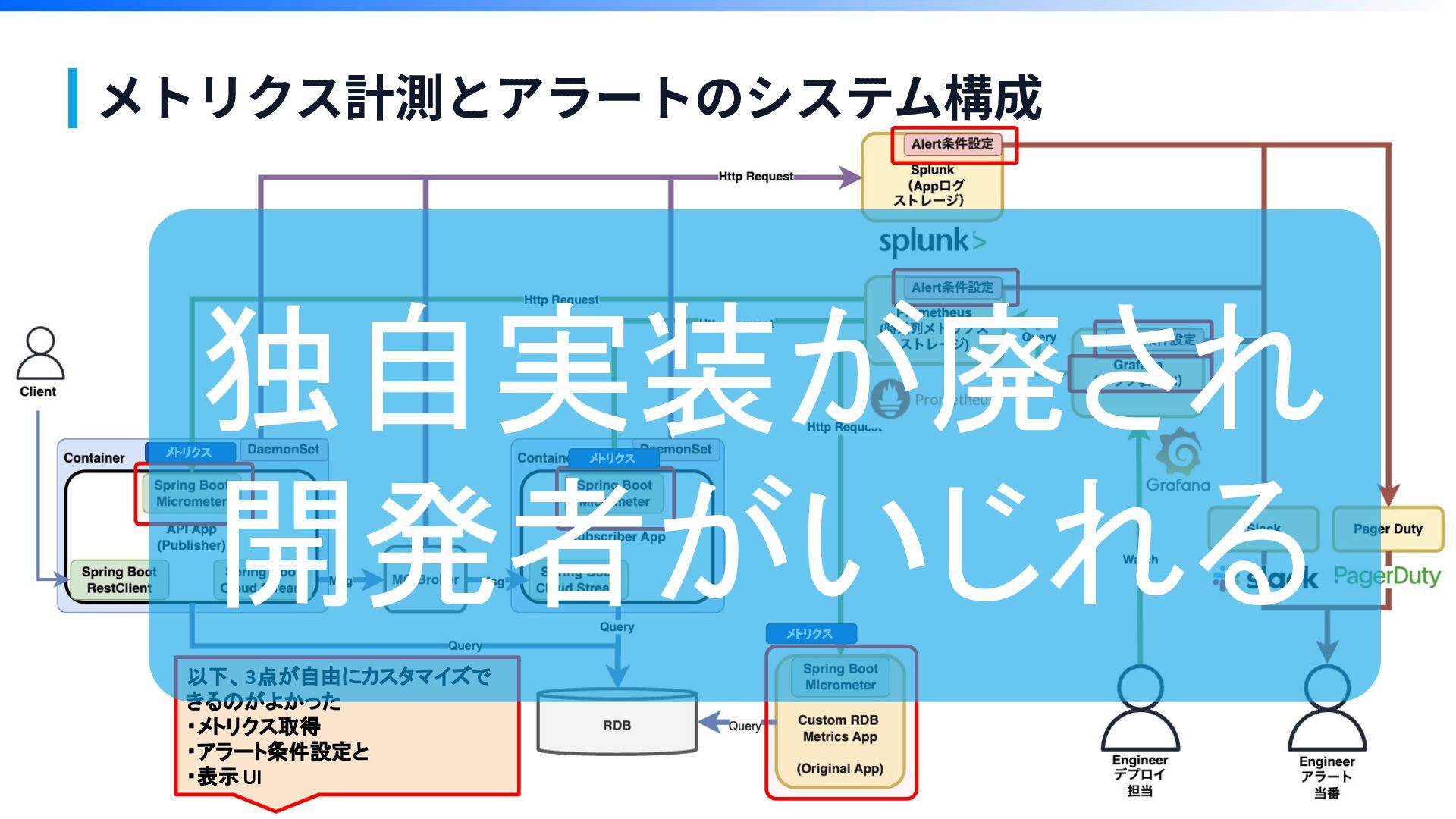
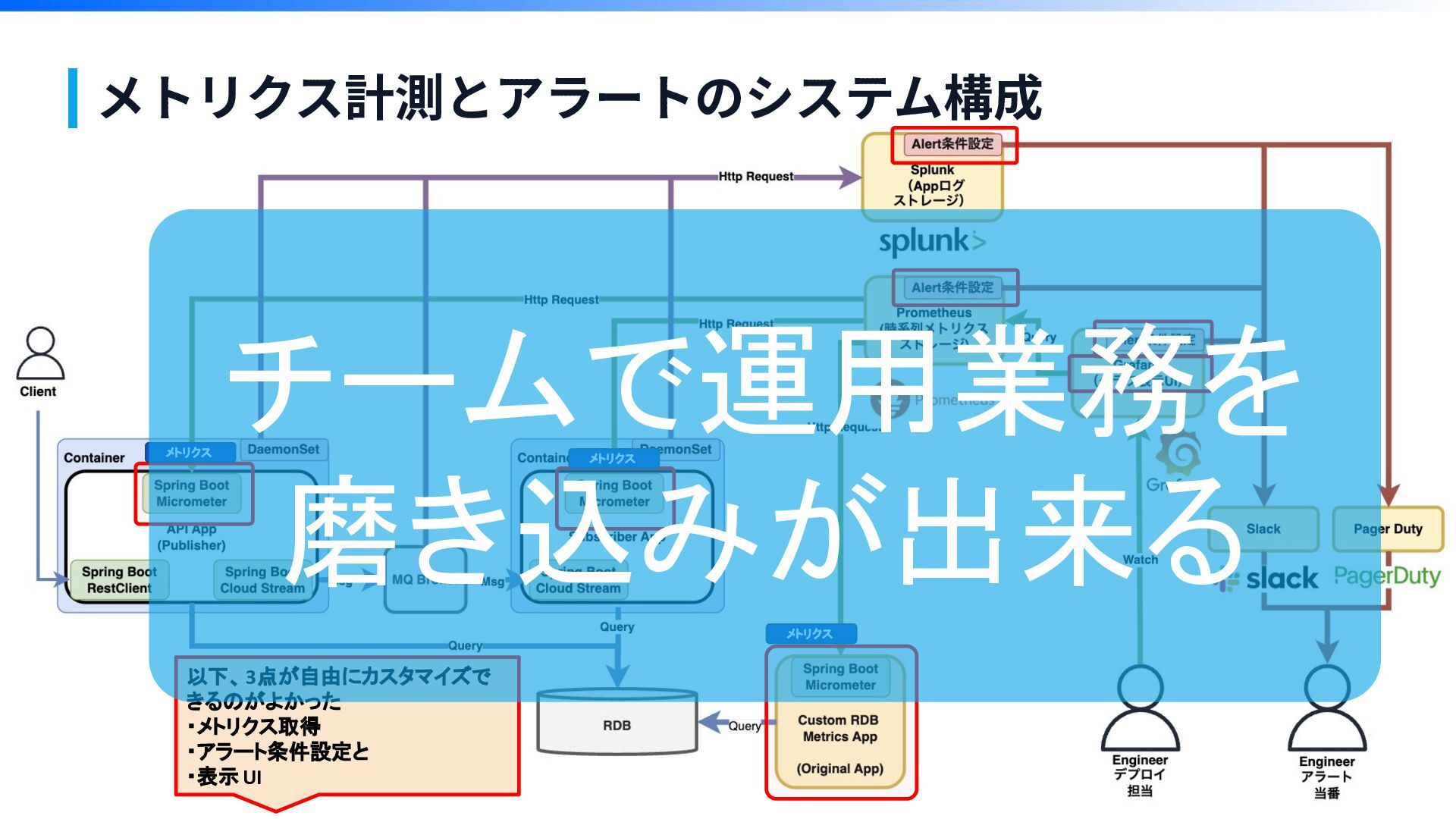
オブザーバビリティ (Observability) 構築 メトリクス計測とアラートのシステム構成
メトリクス計測とアラートのシステム構成 以下、3点が自由にカスタマイズで きるのがよかった ・メトリクス取得 ・アラート条件設定と ・表示UI メトリクス メトリクス メトリクス
メトリクス計測とアラートのシステム構成 以下、3点が自由にカスタマイズで きるのがよかった ・メトリクス取得 ・アラート条件設定と ・表示UI メトリクス メトリクス メトリクス 独自実装が廃され
開発者がいじれる
メトリクス計測とアラートのシステム構成 以下、3点が自由にカスタマイズで きるのがよかった ・メトリクス取得 ・アラート条件設定と ・表示UI メトリクス メトリクス メトリクス チームで運用業務を
磨き込みが出来る
Grafana UIイメージ 理想の運用が 作れる基盤構築
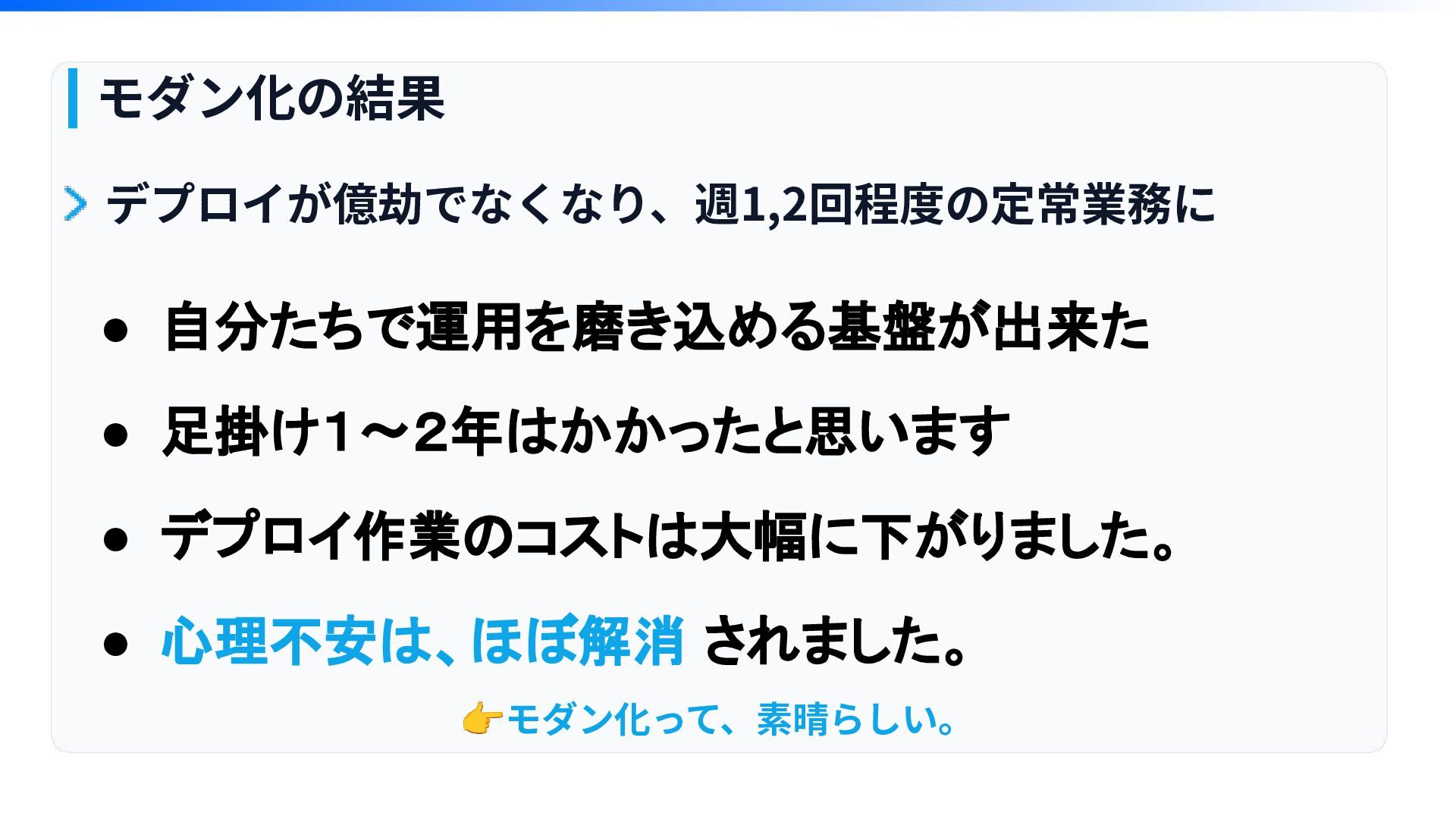
• 自分たちで運用を磨き込める基盤が出来た • 足掛け1〜2年はかかったと思います • デプロイ作業のコストは大幅に下がりました。 • 心理不安は、ほぼ解消 されました。 モダン化の結果
デプロイが億劫でなくなり、週1,2回程度の定常業務に 👉モダン化って、素晴らしい。
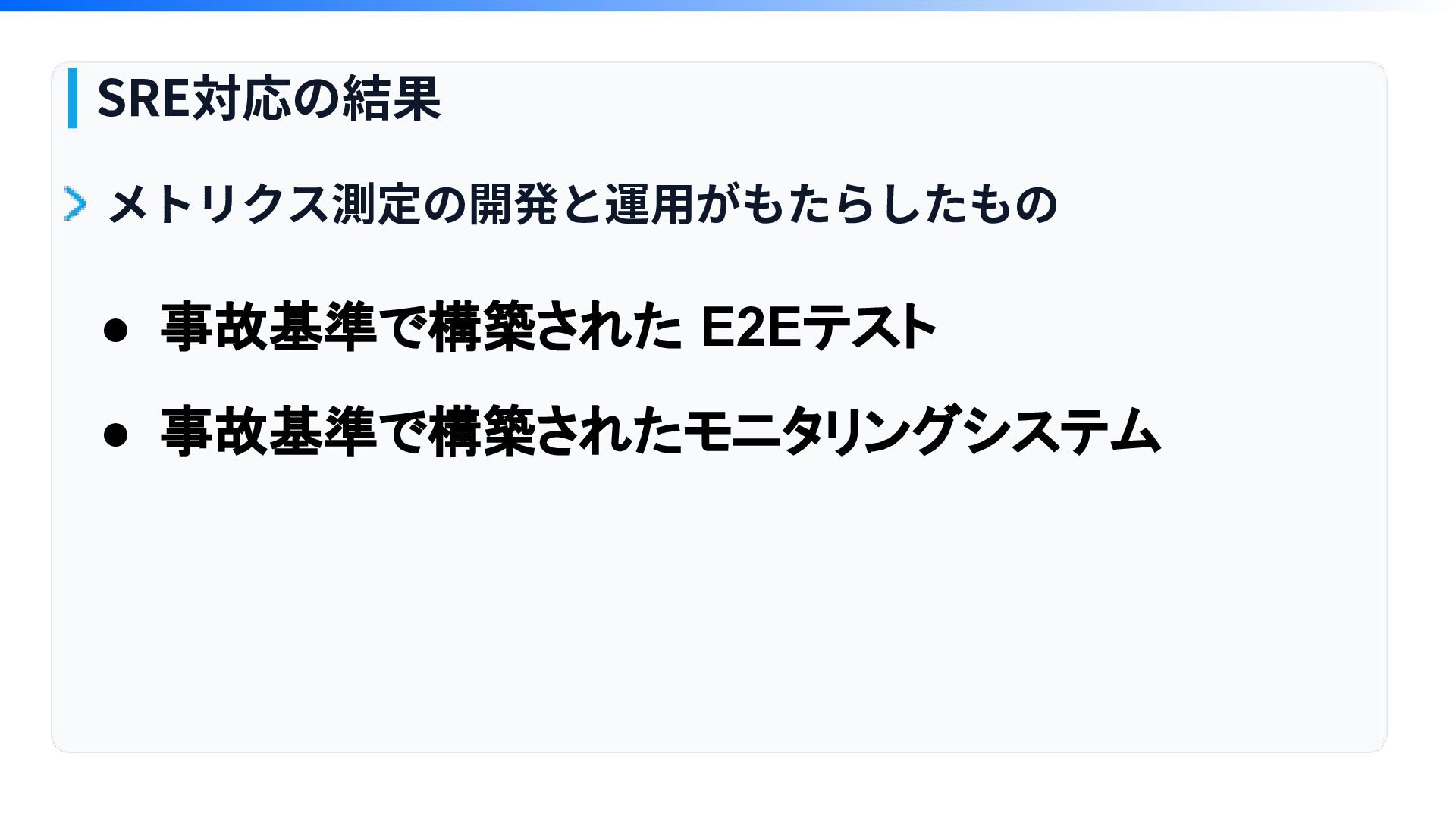
• 事故基準で構築された E2Eテスト • 事故基準で構築されたモニタリングシステム SRE対応の結果 メトリクス測定の開発と運⽤がもたらしたもの
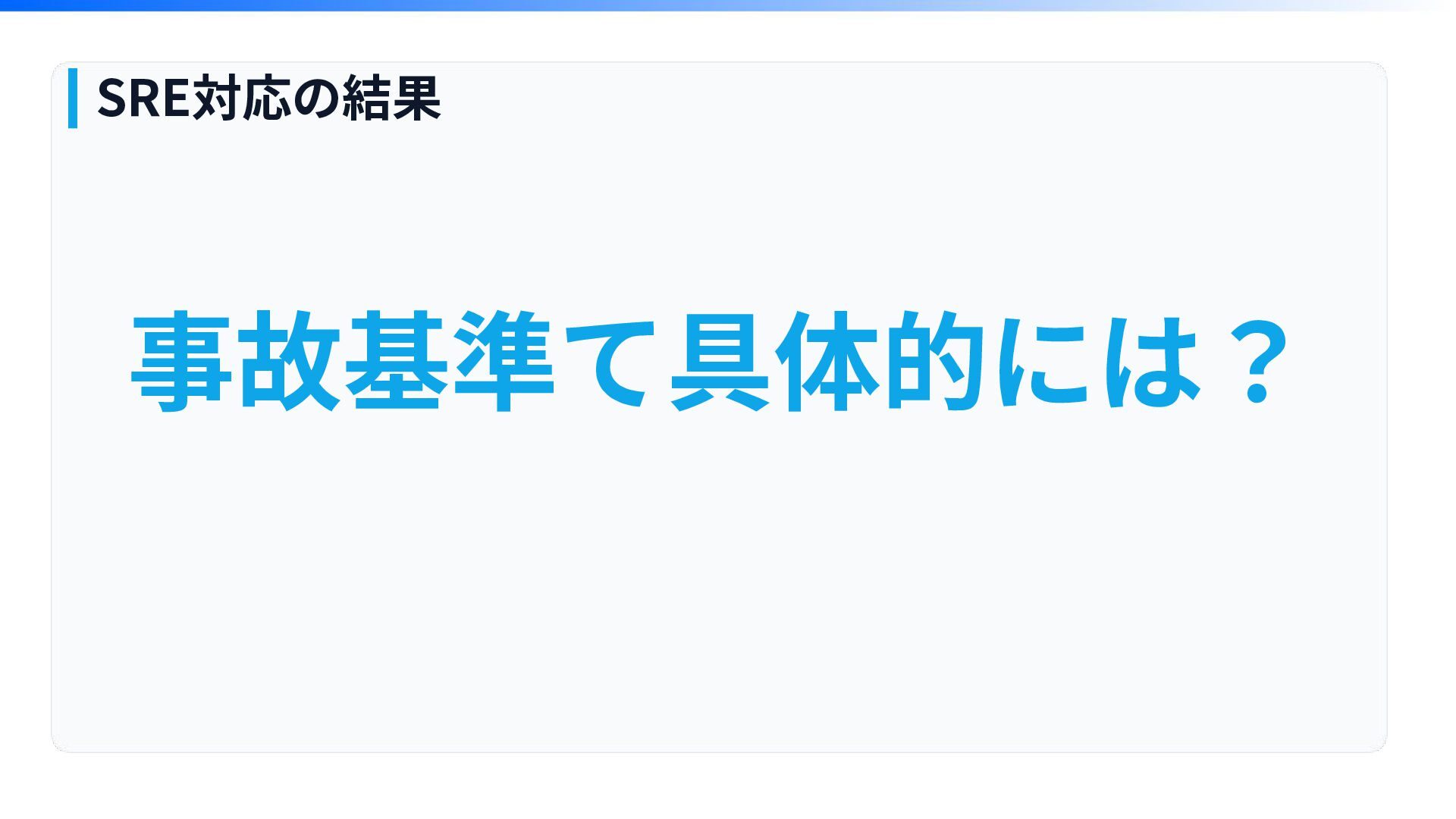
事故基準て具体的には? SRE対応の結果
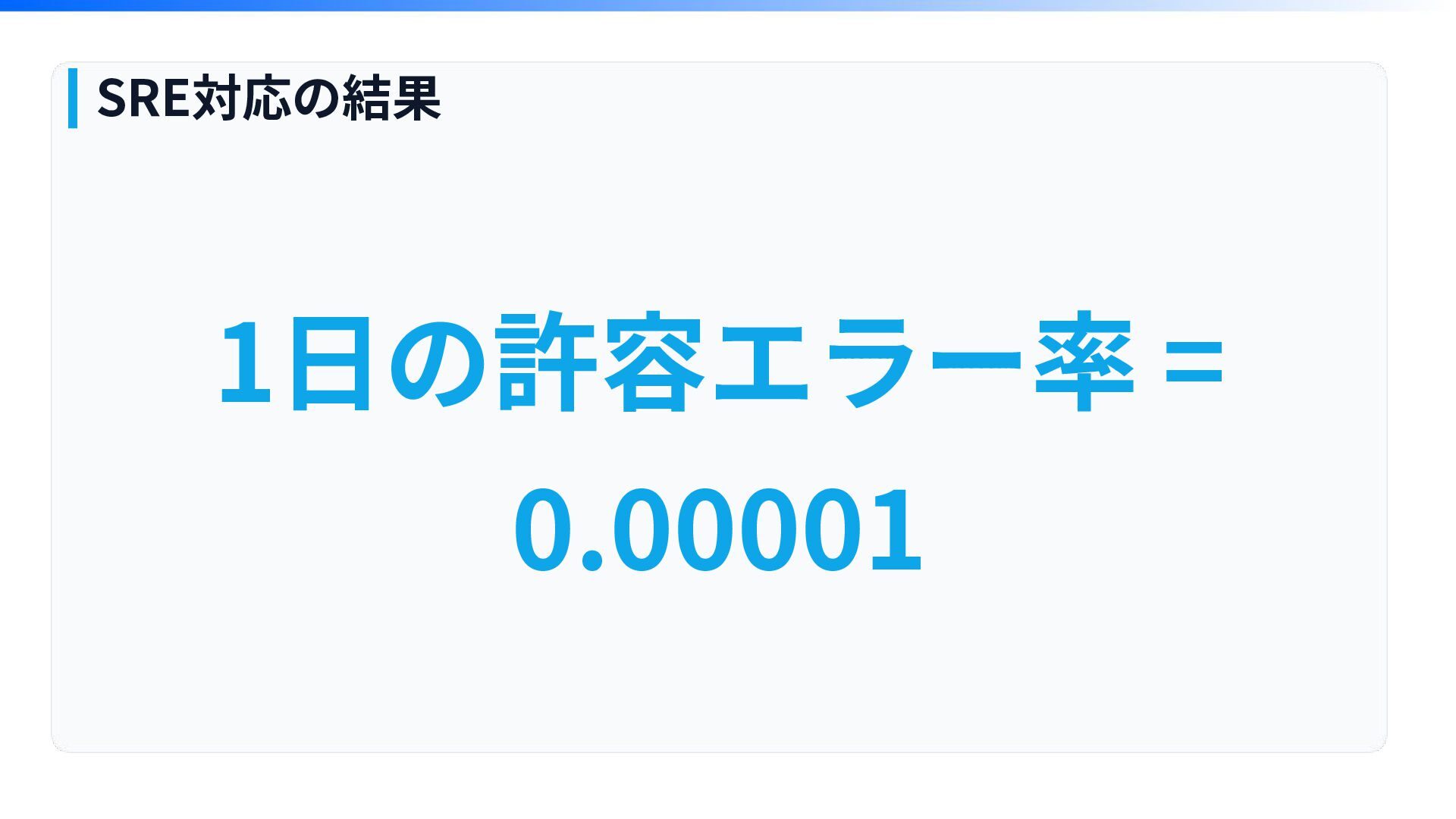
1⽇の許容エラー率 = 0.00001 SRE対応の結果
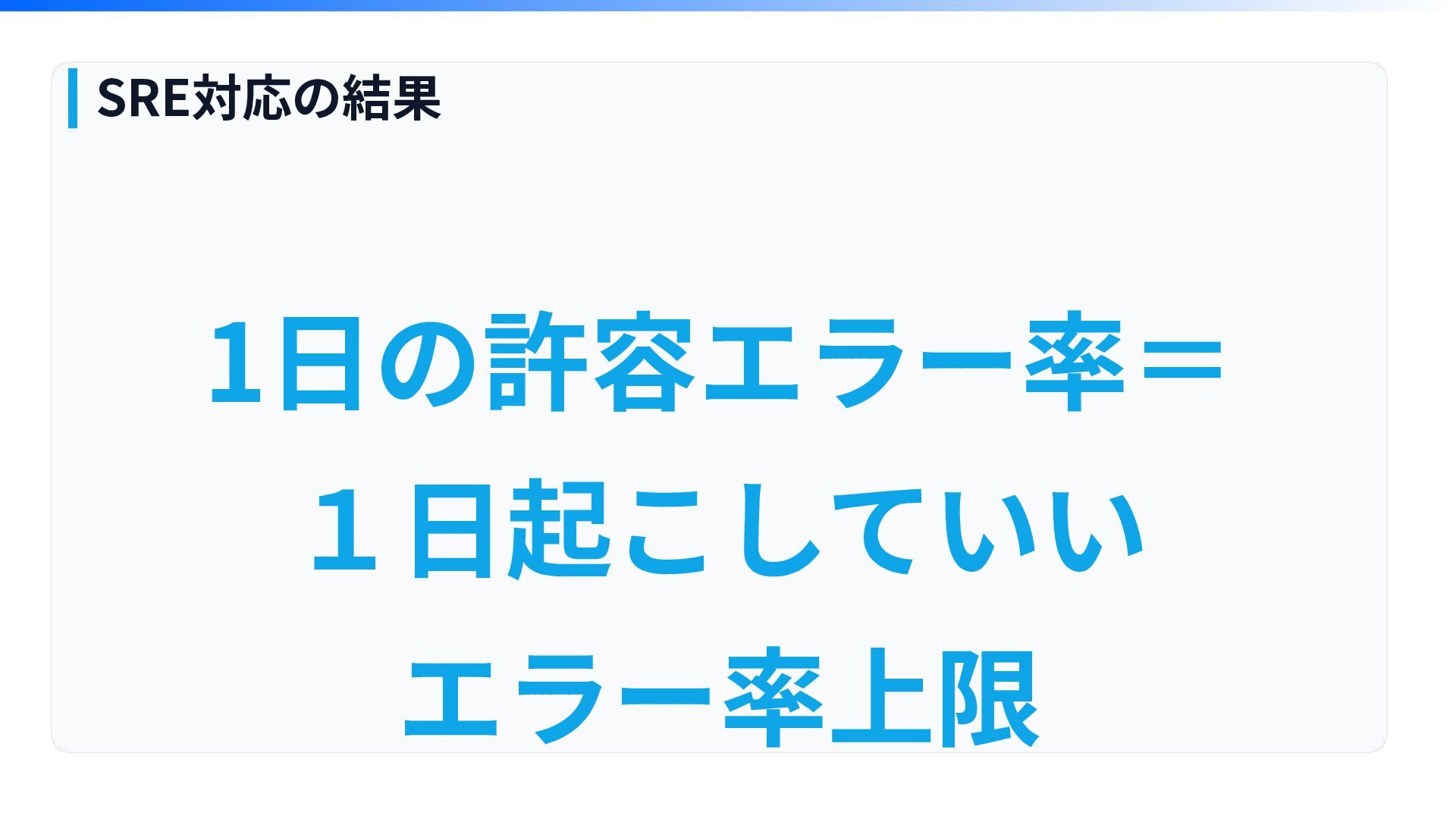
1⽇の許容エラー率= 1⽇起こしていい エラー率上限 SRE対応の結果
そして、エンジニアの 意識が変わった SRE対応の結果
テストが通れば問題なし SRE対応の結果
アラートが鳴らなければ 問題なし SRE対応の結果
エラーが出ても 事故(SLO違反)以外は かすり傷 SRE対応の結果
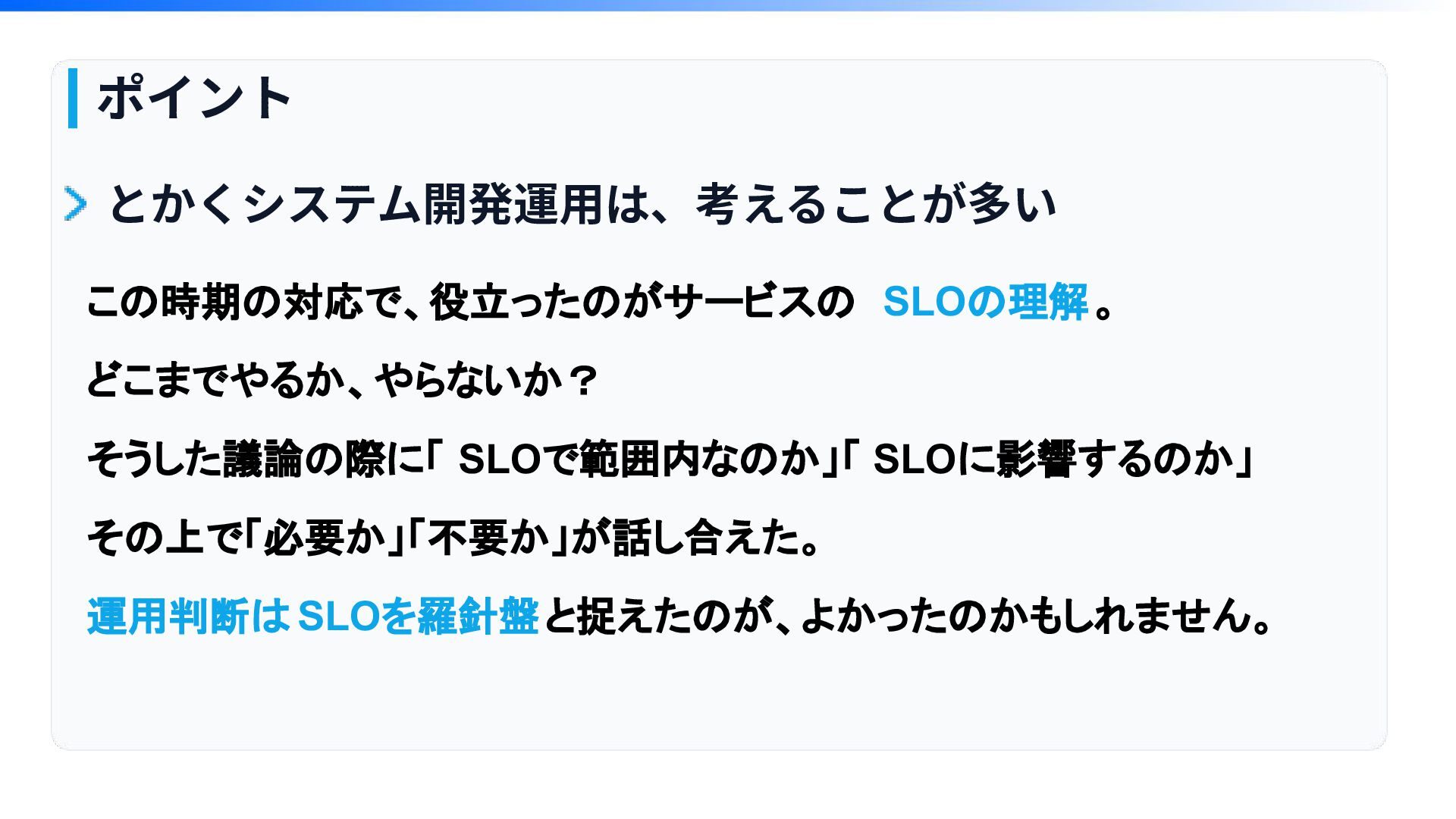
ポイント とかくシステム開発運⽤は、考えることが多い この時期の対応で、役立ったのがサービスの SLOの理解。 どこまでやるか、やらないか? そうした議論の際に「 SLOで範囲内なのか」「 SLOに影響するのか」 その上で「必要か」「不要か」が話し合えた。 運用判断は
SLOを羅針盤と捉えたのが、よかったのかもしれません。
加速する世界 第4章
もっと、早くできないか 本番デプロイが安定し、監視も安定してくると 欲がでる 本番デプロイ作業は、誰がやっても⼀緒。 コレ⾃動化できるんじゃないか?
PRをmainマージしたら 本番デプロイする パイプライン やってみよう、つくってみよう
やってみた やってみよう、つくってみよう
KaaSデプロイフロー PRマージ&デプロイ PRマージと既存デプロイ を直結する PRマージ単位で Imageを 作成、日付とコミットログ
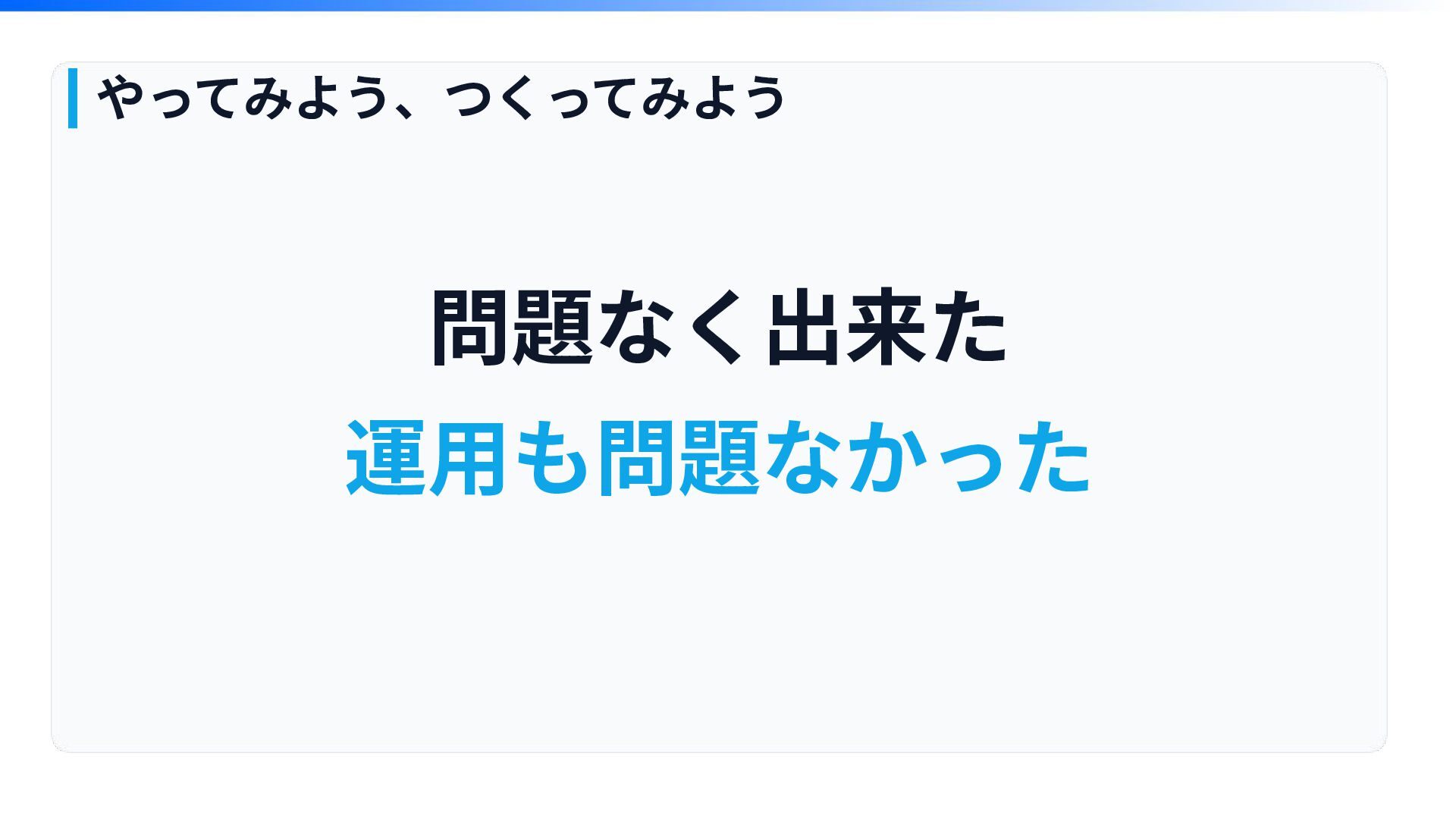
問題なく出来た 運⽤も問題なかった やってみよう、つくってみよう
1PRマージ=1デプロイ やってみよう、つくってみよう
なぜ出来たか? やってみよう、つくってみよう
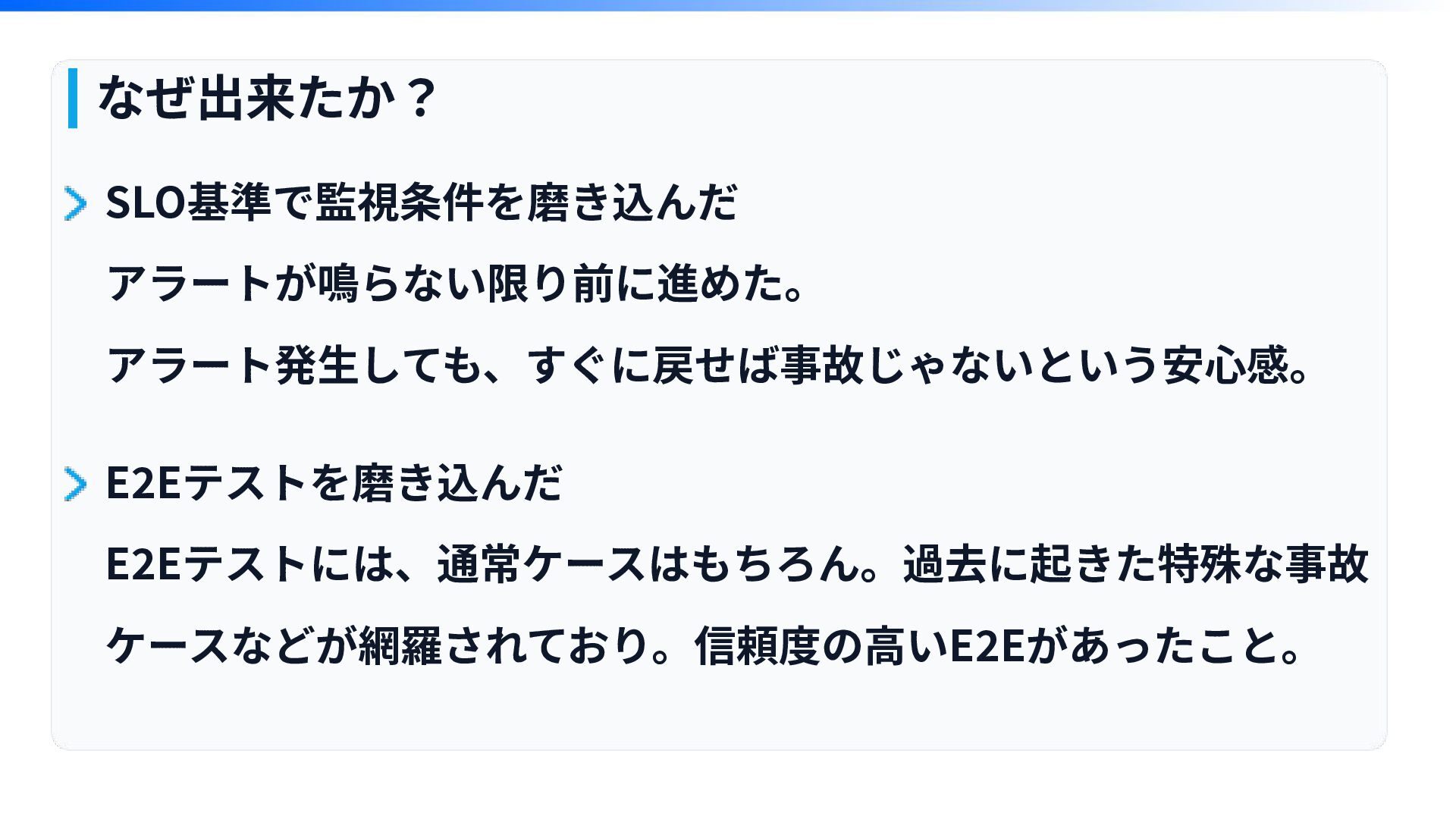
なぜ出来たか? SLO基準で監視条件を磨き込んだ アラートが鳴らない限り前に進めた。 アラート発⽣しても、すぐに戻せば事故じゃないという安⼼感。 E2Eテストを磨き込んだ E2Eテストには、通常ケースはもちろん。過去に起きた特殊な事故 ケースなどが網羅されており。信頼度の⾼いE2Eがあったこと。
そして起こった事 やってみよう、つくってみよう
ボトルネックの変化 👉 ボトルネックが移動していく 磨き込みのため、PRを出す必要がある →PR差分が多いとレビューに時間がかかる → どんどんPRサイズは⼩さくして、マージを優先 PRのレビューを安全かつ、⾼速で回す必要が出てきた →SlackでPRレビュー待ち⼀覧を通知し、PRレビューのサイクルを上げる PRが増えて、開発環境が利⽤待ちが増えた
→簡易に開発環境を作成するジョブを追加
ボトルネックが移っていく なにか聞いたことあるぞ 第4章
•ハービーのエピソード ボーイスカウトの遠⾜の隊列全体の速さは、 歩くのが⼀番遅い「ハービー」が決める。 では、彼の荷物を減らしてスピードを上げると、 どうなるか? 今度は「2番⽬に遅かった⼦供」が、 新たなハービーになる。 ――これは、私たちの仕事でも全く同じです。 ひとつの制約(ボトルネック)を解消すると、制約は必ず次 の場所へと移動する。
「ザ‧ゴール」の制約条件の理論(TOC) ※本のイメージ
パイプラインがもたらした世界 👉 ⼈が判断する⼯程が削られ、「出すこと」が怖くなくなった。 ⾃動化の結果 ⾏動の変化 (After) いつでも出せる すぐ戻せる 状態が常に分かる とりあえず出す
実際に本番環境で確認する ダメならすぐ戻す
チームで1⽇平均10PRマージ ⽉間200回デプロイ 気付いたら、結果として ( 10PR × 20営業⽇ = 200PR =
200deploy )
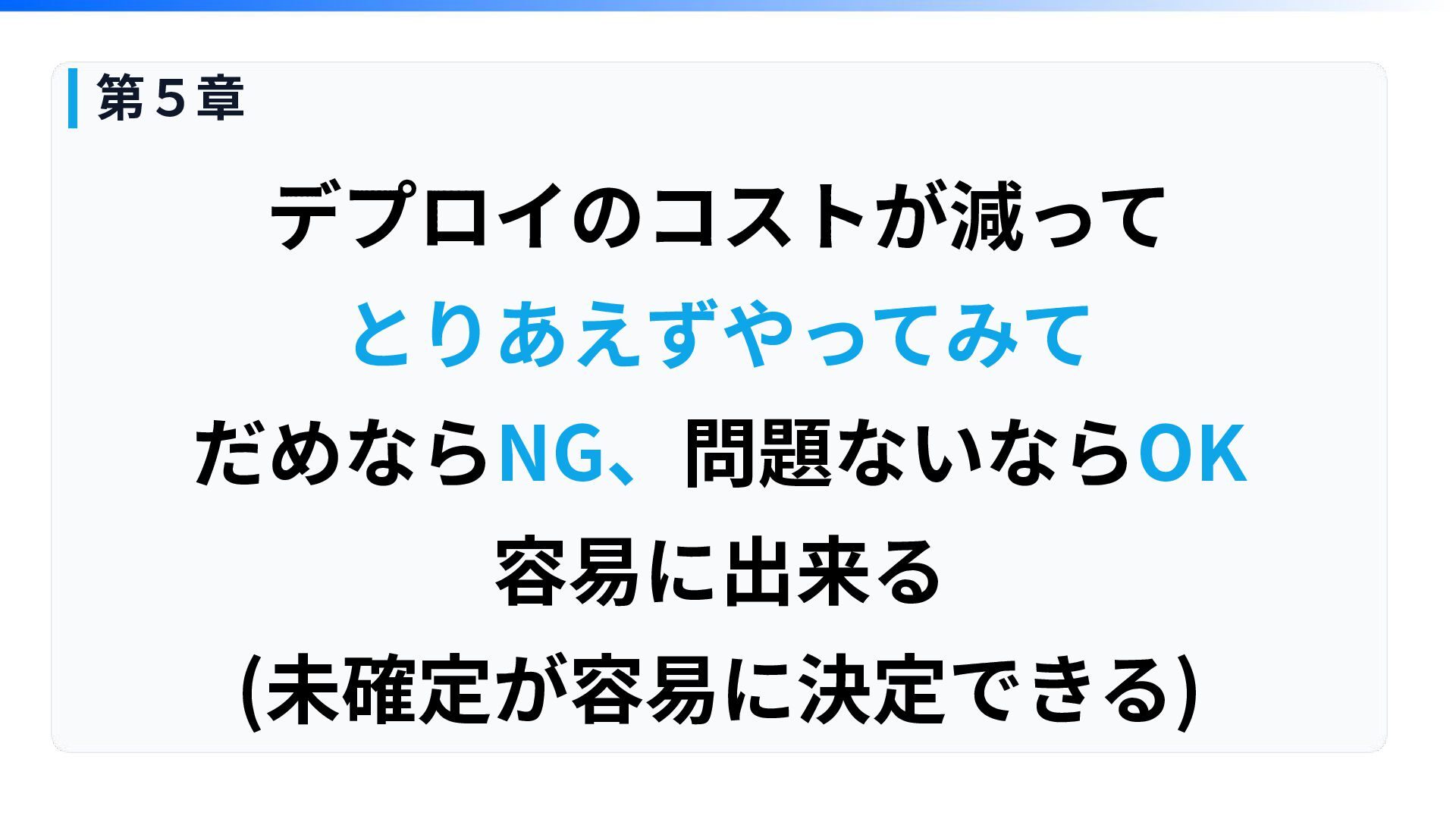
消えた、Issue 第5章
モダン化、SRE活動の結果 第5章
Issueどんどん減っていった 第5章
残るのはフレッシュなIssueだけ 第5章
Issue棚卸し定例もやめた 第5章
なぜか? 第5章
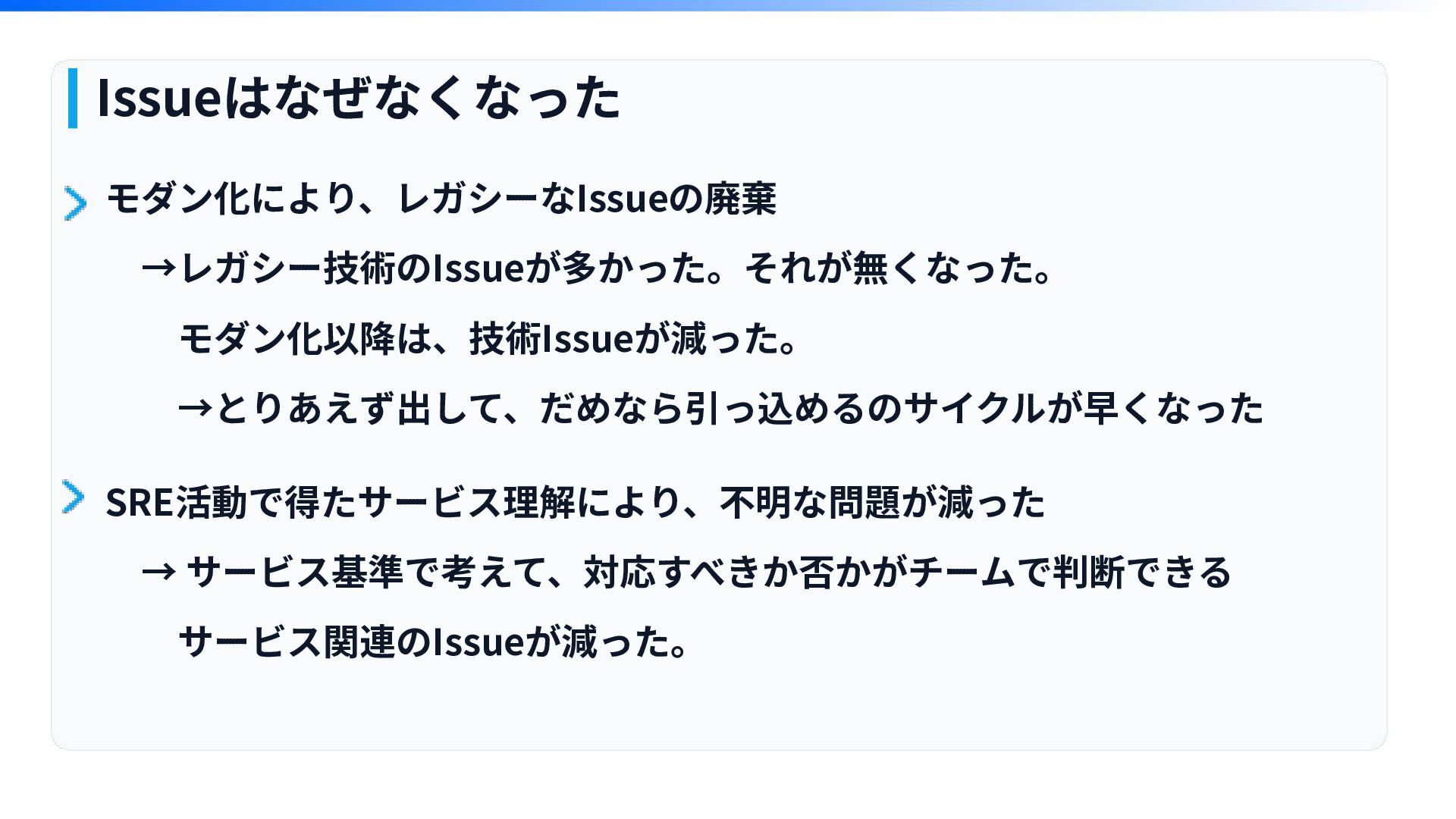
Issueはなぜなくなった モダン化により、レガシーなIssueの廃棄 →レガシー技術のIssueが多かった。それが無くなった。 モダン化以降は、技術Issueが減った。 →とりあえず出して、だめなら引っ込めるのサイクルが早くなった SRE活動で得たサービス理解により、不明な問題が減った → サービス基準で考えて、対応すべきか否かがチームで判断できる サービス関連のIssueが減った。
Issue = 未確定の意思決定 Issueとは
SRE活動を経て サービス知識が増えて 判断できる事が増えた (未確定の減少) 第5章
デプロイのコストが減って とりあえずやってみて だめならNG、問題ないならOK 容易に出来る (未確定が容易に決定できる) 第5章
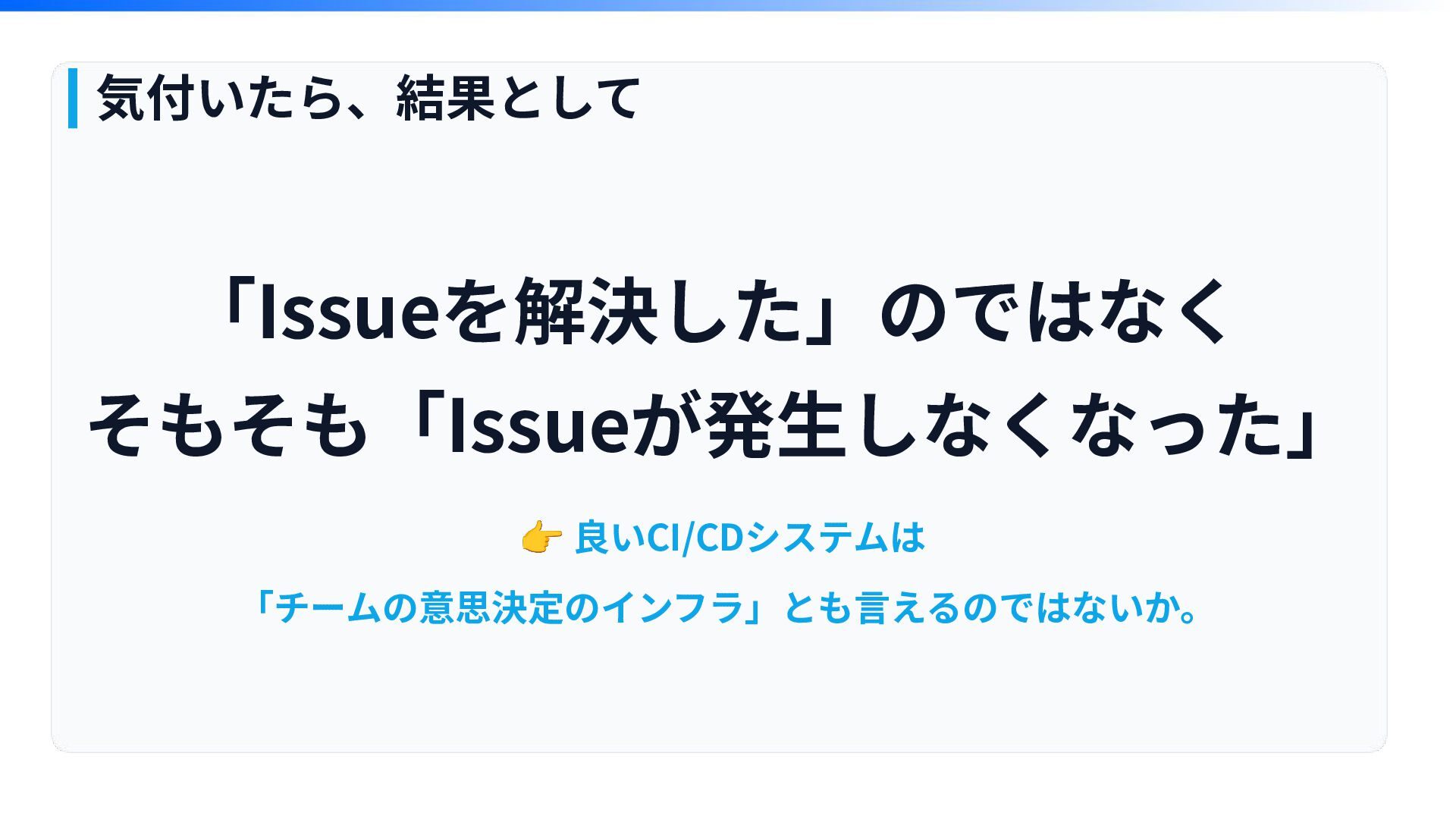
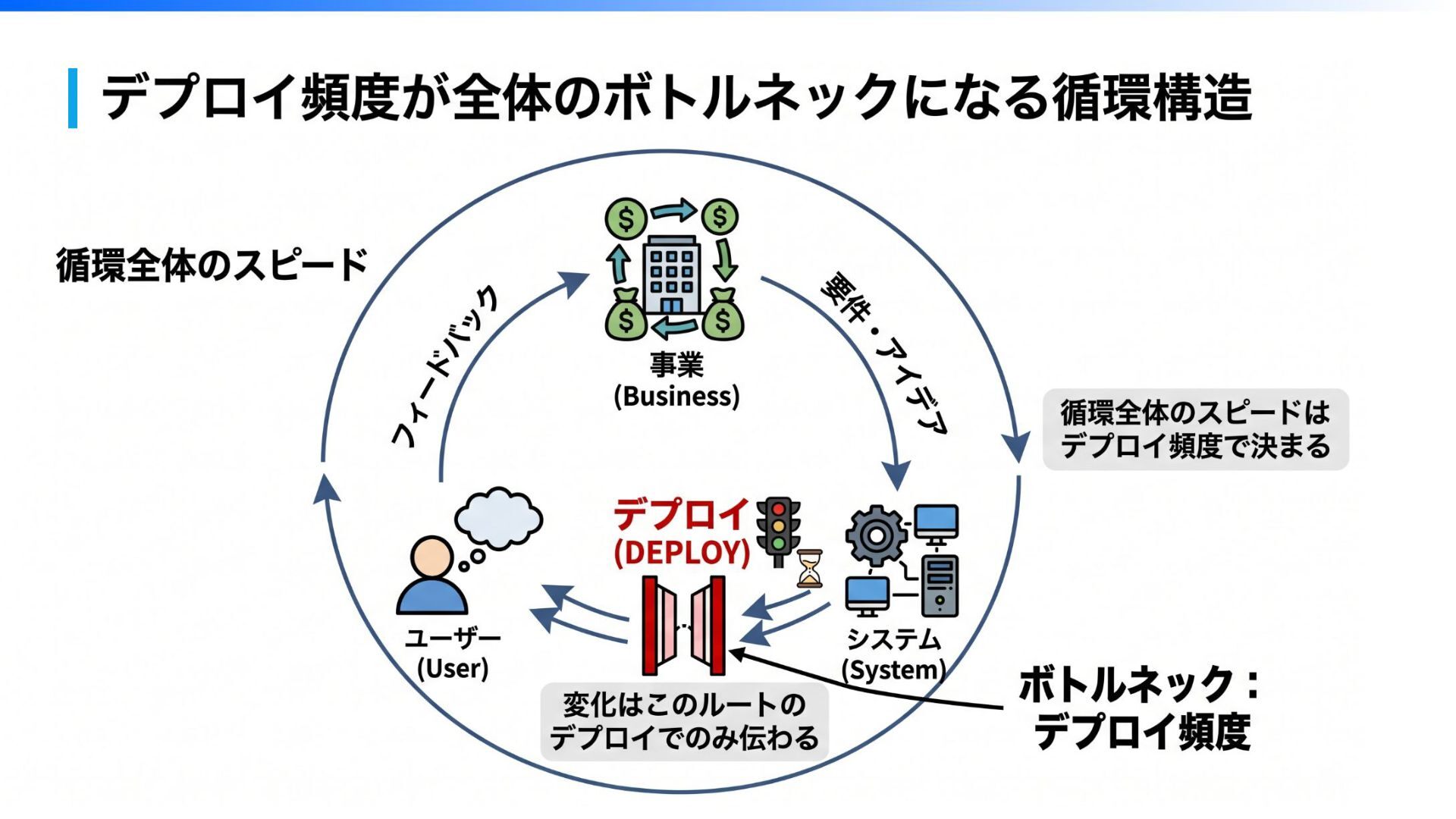
気付いたら、結果として 「Issueを解決した」のではなく そもそも「Issueが発⽣しなくなった」 👉 良いCI/CDシステムは 「チームの意思決定のインフラ」とも⾔えるのではないか。
まとめ 第6章
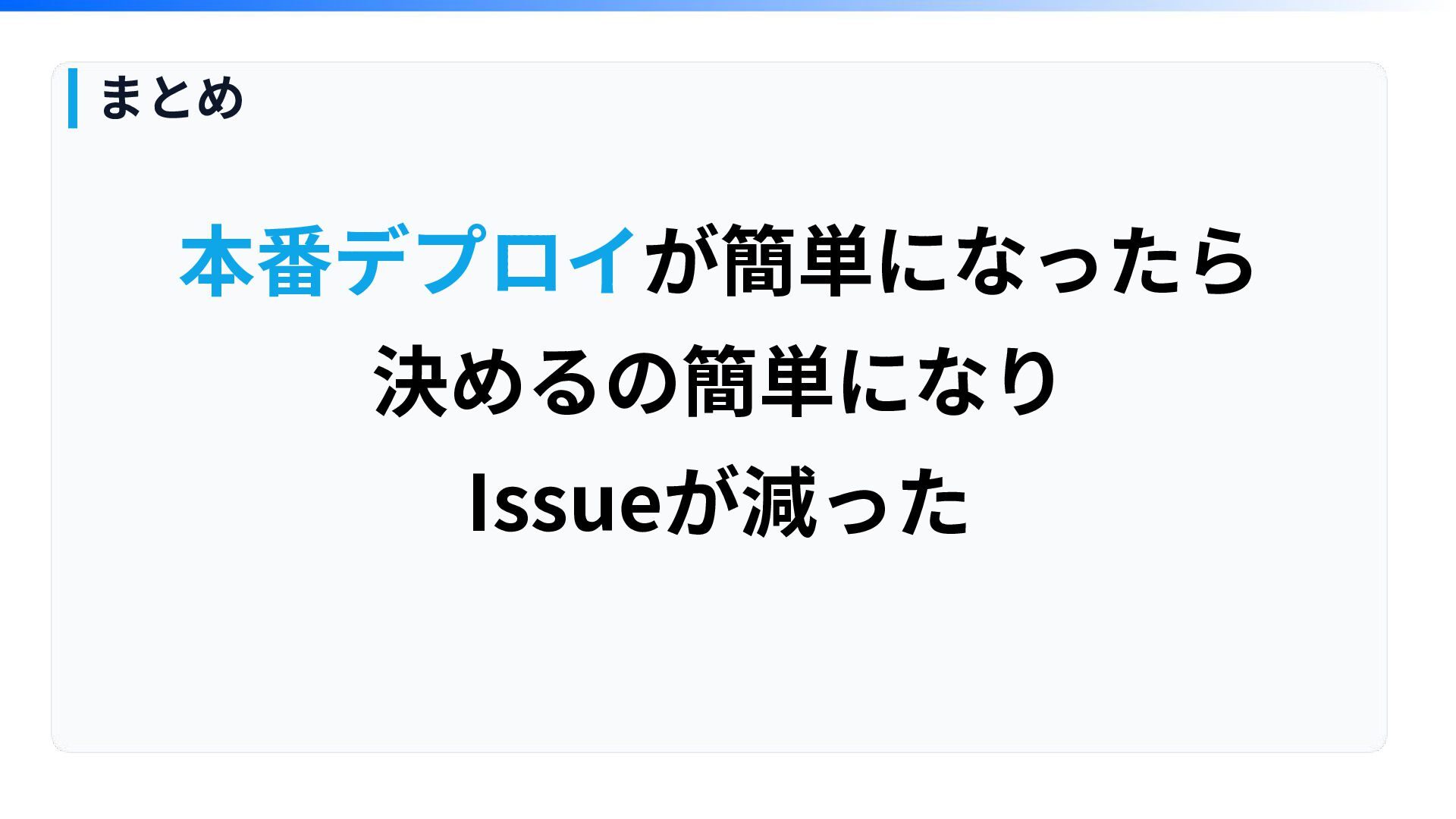
本番デプロイが簡単になったら 決めるの簡単になり Issueが減った まとめ
None
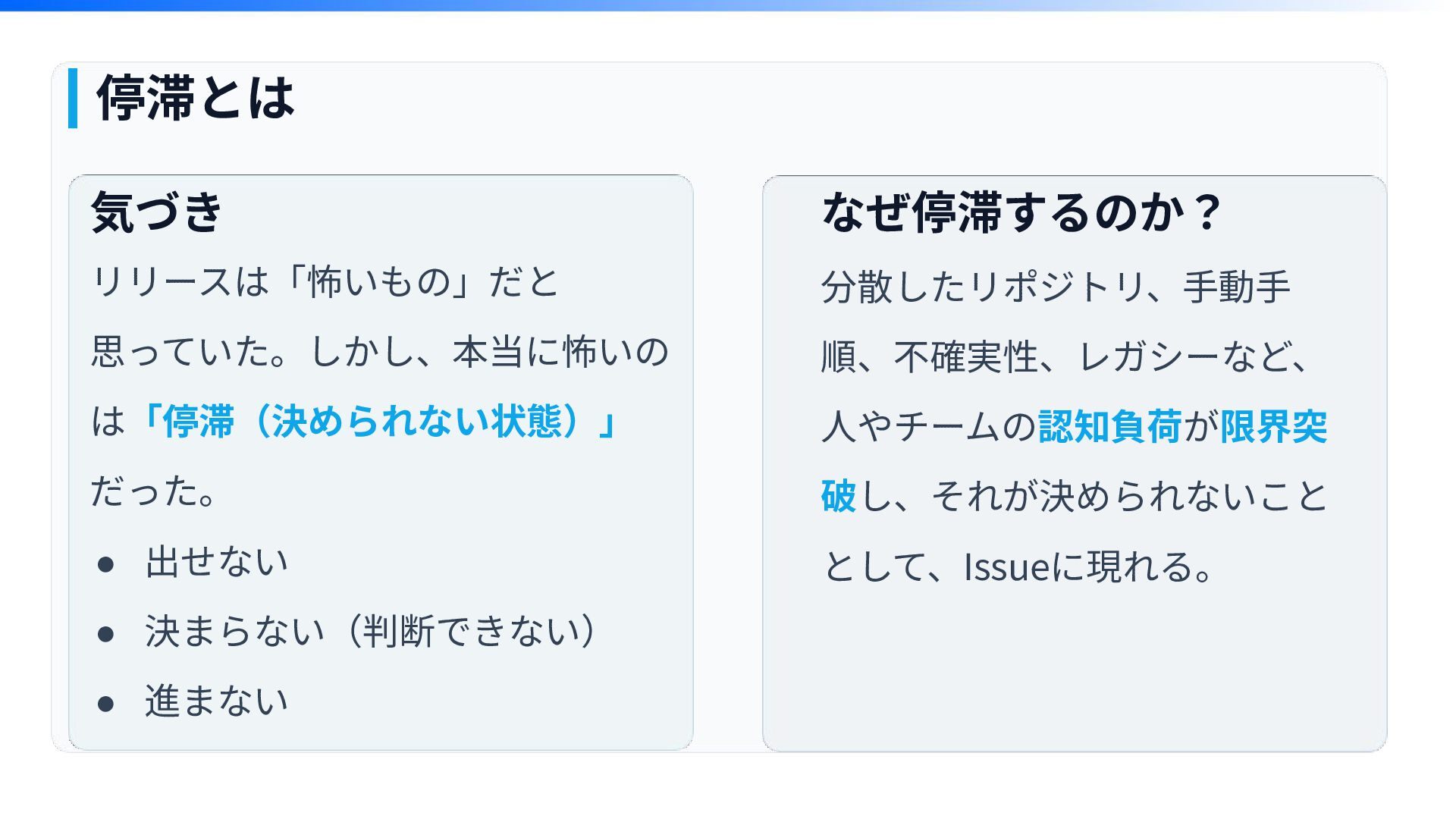
停滞とは 気づき リリースは「怖いもの」だと 思っていた。しかし、本当に怖いの は「停滞(決められない状態)」 だった。 • 出せない • 決まらない(判断できない)
• 進まない なぜ停滞するのか? 分散したリポジトリ、⼿動⼿ 順、不確実性、レガシーなど、 ⼈やチームの認知負荷が限界突 破し、それが決められないこと として、Issueに現れる。
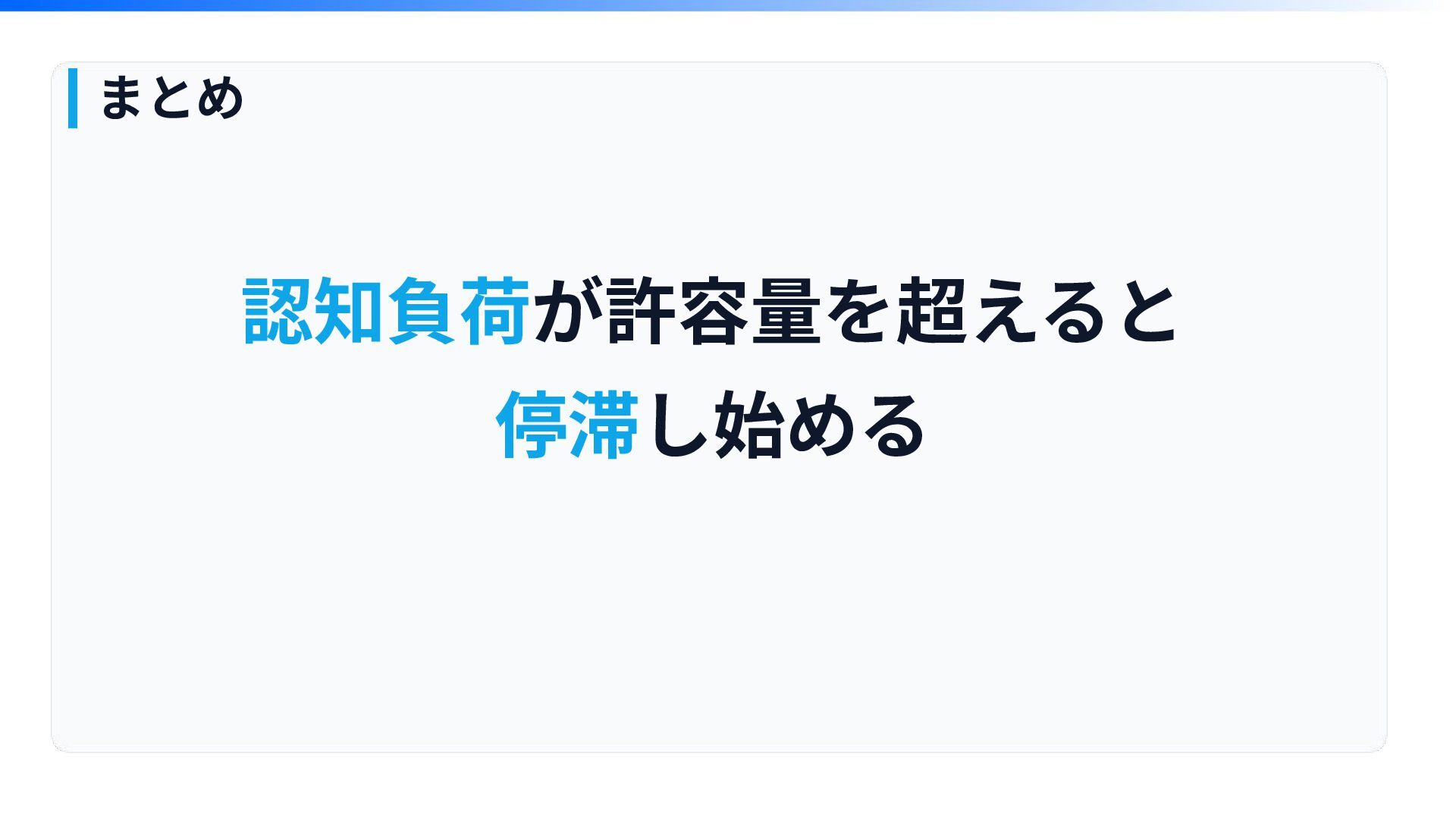
まとめ 認知負荷が許容量を超えると 停滞し始める
真のリスクは、 停滞である。 Issueが多いチームは忙しいのではなく 「停滞している」 リリースできない状態は、 チームの「決断」を停滞させ、 Issueの⼭を作ります。 だからこそ、デプロイの恐怖を取り除き 迷わず前に進める仕組みを作ること。 それが、変化に強いチーム(真のアジリティ)
への第⼀歩です。
停滞チェックリスト デプロイは「祈り」の儀式になっていないか? 「熟成されたIssue」が放置されていないか? サービスの「許容エラー率(SLO)」をチームで合意しているか? 「とりあえず出して、ダメならすぐ戻す」が簡単にできるか? ボタンを押すのが怖いなら、⾃動化とテスト強化に着⼿するサインです。 未確定の意思決定が溜まると、チームの認知負荷が限界を超え「停滞」を⽣みます。 どこまでやるか‧やらないかを決める「運⽤判断の羅針盤」が必要です。 このサイクルが回せるCI/CDこそが、チームの意思決定を加速させるインフラです。 1つでも気になったら、まずは「デプロイ⼿順を1つ削る」ことから始めてみませんか
ご清聴ありがとうございました おわり
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}