MR jobs? • How many MR jobs Hive generates? • How to optimize HQL to make query faster? • How to find root cause when fail? • Why Hive jobs are so slow?
– we need a DataWarehouse for analytic job and reporting • if not this, what else? – GreenPlum, Teradata, Oracle Exadata, Sybase IQ, AsterData, Vertica, InfoBright ……
on HDFS • example: USE tmp; CREATE TABLE page_view(viewTime INT, userid BIGINT, page_url STRING, referrer_url STRING, ip STRING COMMENT 'IP Address of the User') COMMENT 'This is the page view table' PARTITIONED BY(dt STRING, country STRING) CLUSTERED BY(userid) SORTED BY(viewTime) INTO 32 BUCKETS ROW FORMAT DELIMITED FIELDS TERMINATED BY '1' COLLECTION ITEMS TERMINATED BY '2' MAP KEYS TERMINATED BY '3' STORED AS SEQUENCEFILE;
bucket dt='2013-07-07',country='CN' /user/hive/warehouse/tmp.db/page_view/ Hive part-00000 /user/hive/warehouse/tmp.db/page_view/ dt=2013-07-07/country=CN/ database table partition /user/hive/warehouse/tmp.db/page_view/ dt=2013-07-07/country=CN/part- 00000/ row records 1373126400 1 http://www.dianping.com http://t.dianping.com 202.87.12.206 /user/hive/warehouse/tmp.db/page_view/ dt=2013-07-07/country=CN/part- 00000/a.txt • row : STORED AS SEQUENCEFILE SequenceFileRecordReader reads each line as a row • field : ROW FORMAT DELIMITED FIELDS TERMINATED BY '1' COLLECTION ITEMS TERMINATED BY '2' MAP KEYS TERMINATED BY '3' LazySimpleSerDe inspect each filed value of a row
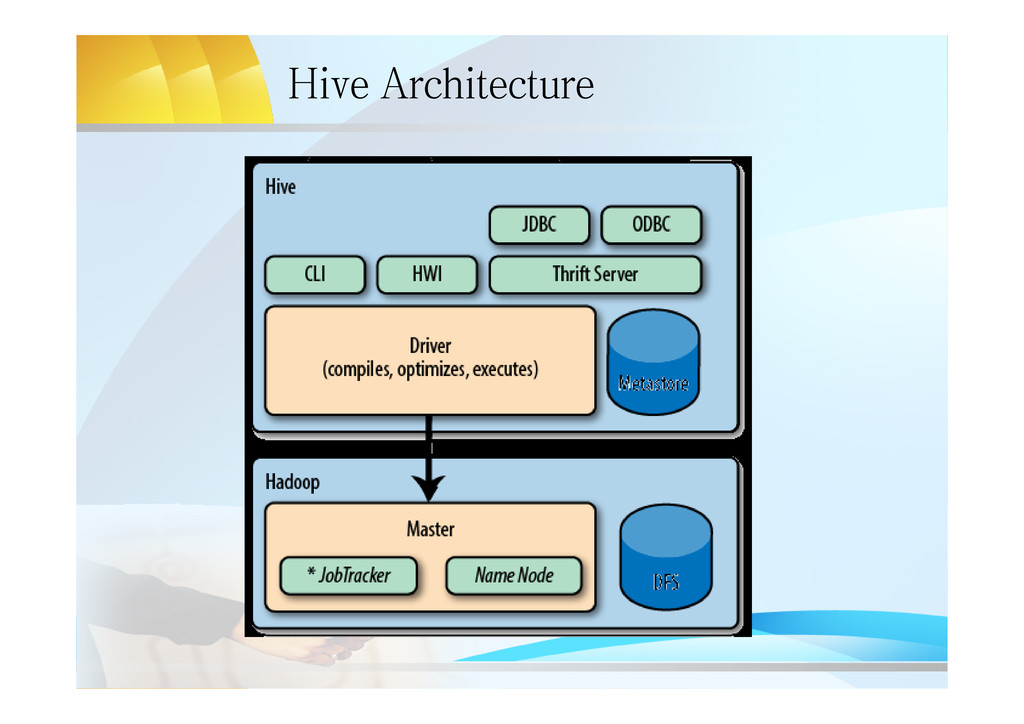
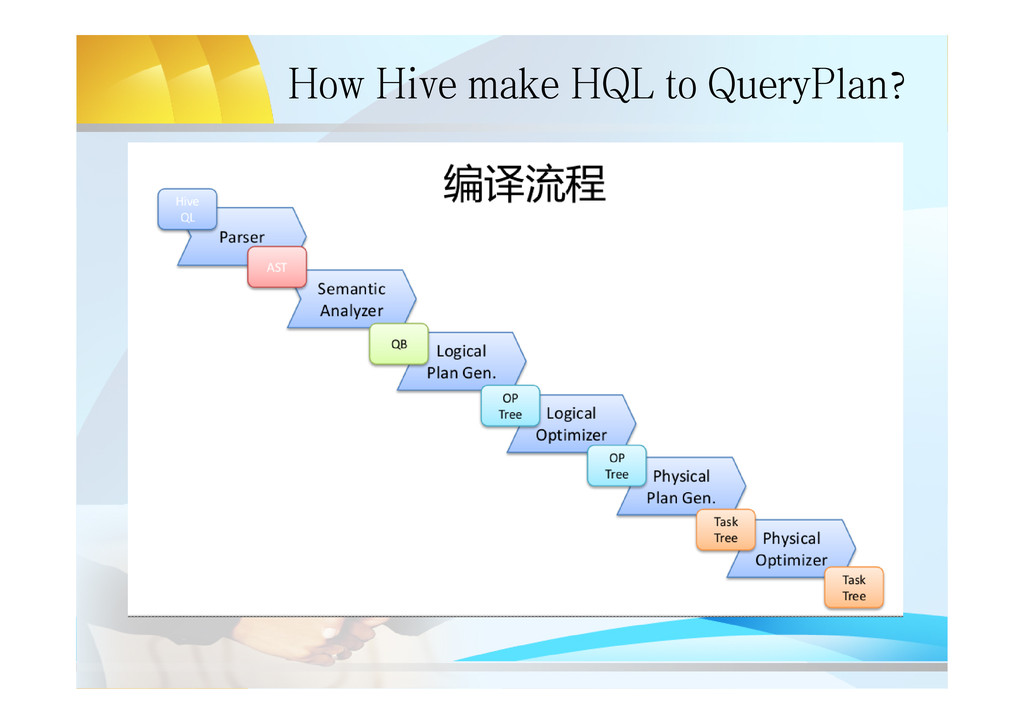
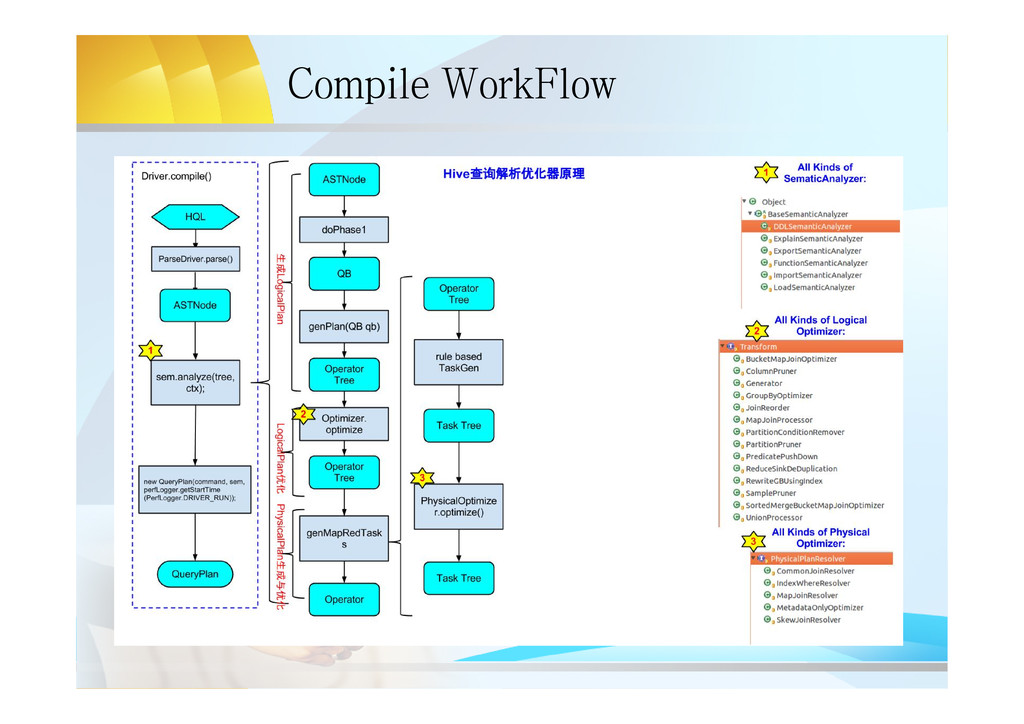
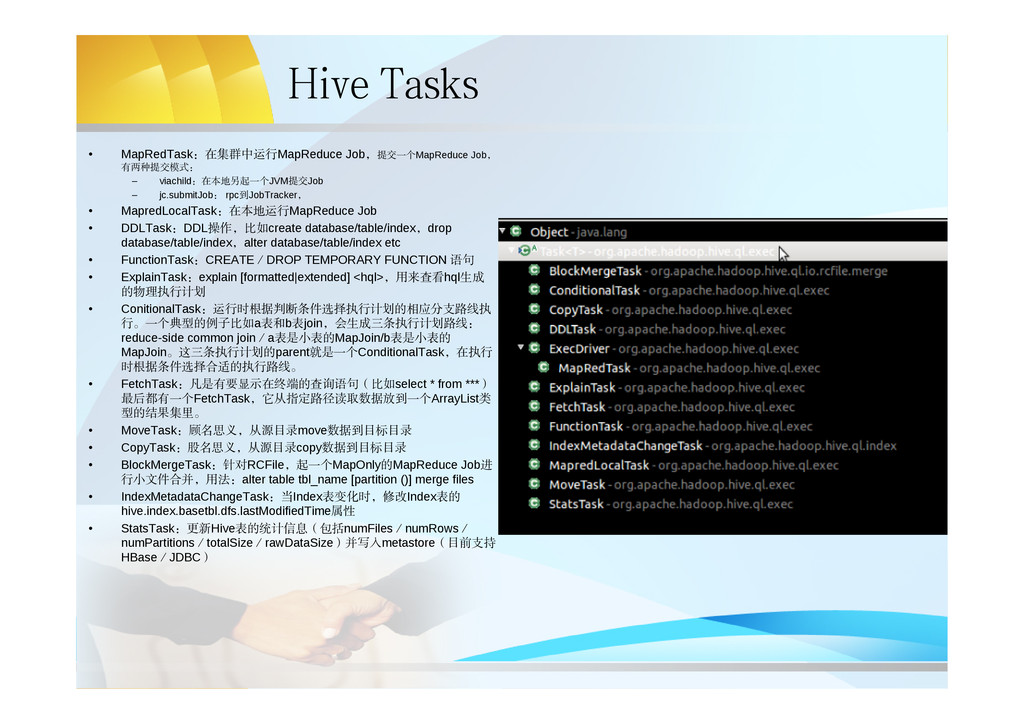
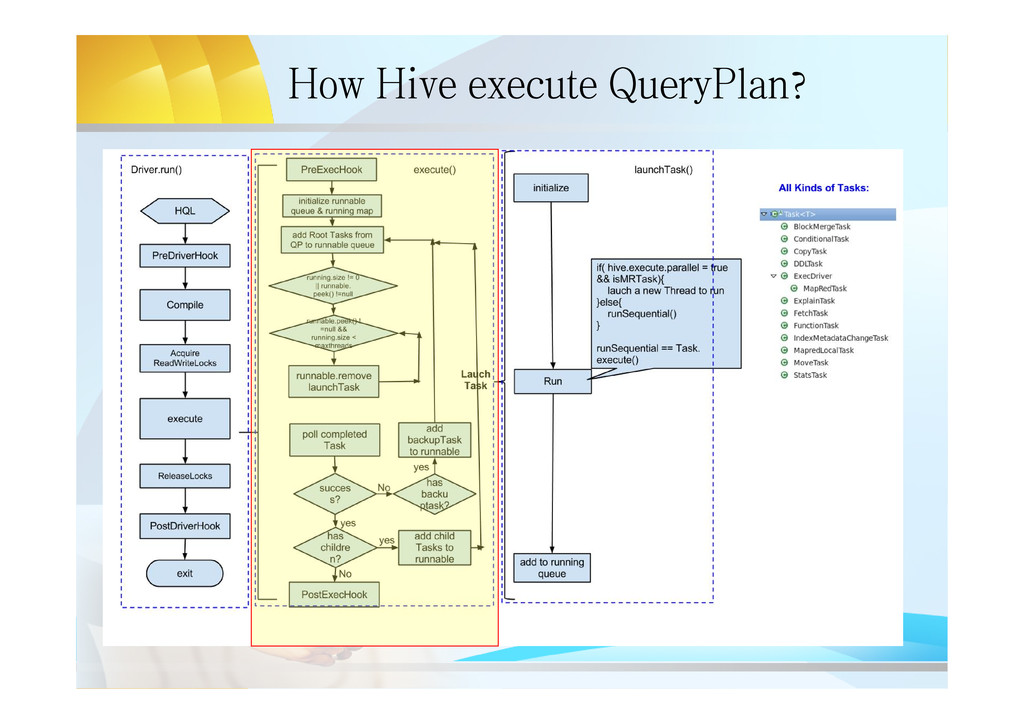
line interface – HWI: Web interface – JDBC/ODBC Server: JDBC/ODBC compatible interface based on thrift server • Driver – Query Compiler: compile HQL into a DAG QueryPlan – Optimizer: optimize M/R tasks on the DAG QP – execution Engine: execute the QP(submit MR Job/ Write or Read HDFS) • Metastore: – hold all the information about the tables and partitions that are in the warehouse.
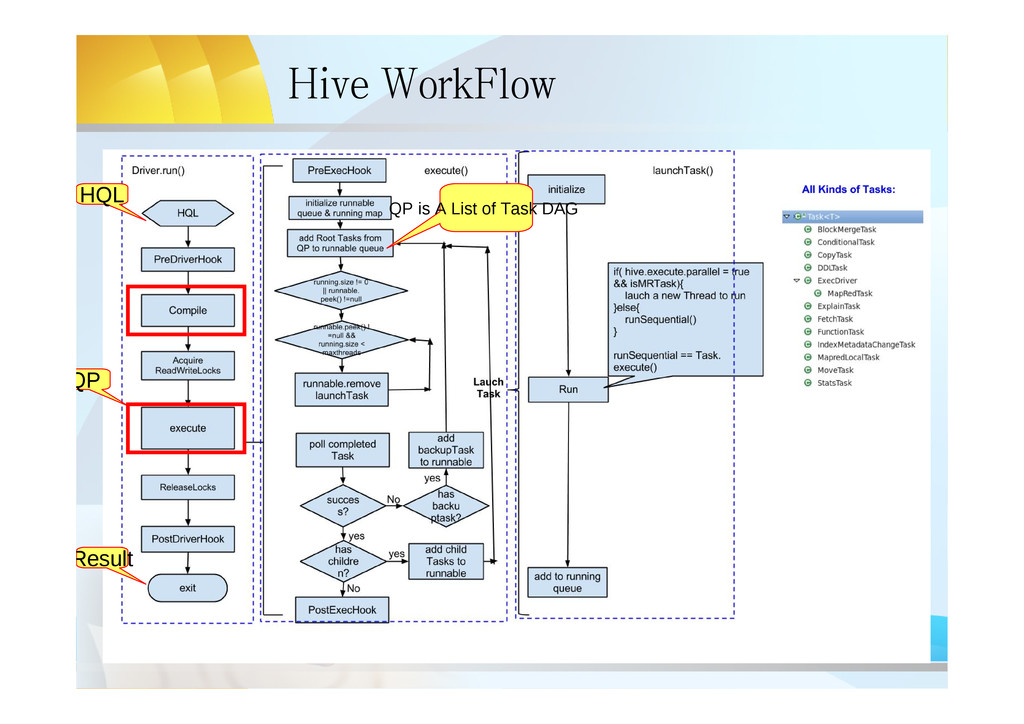
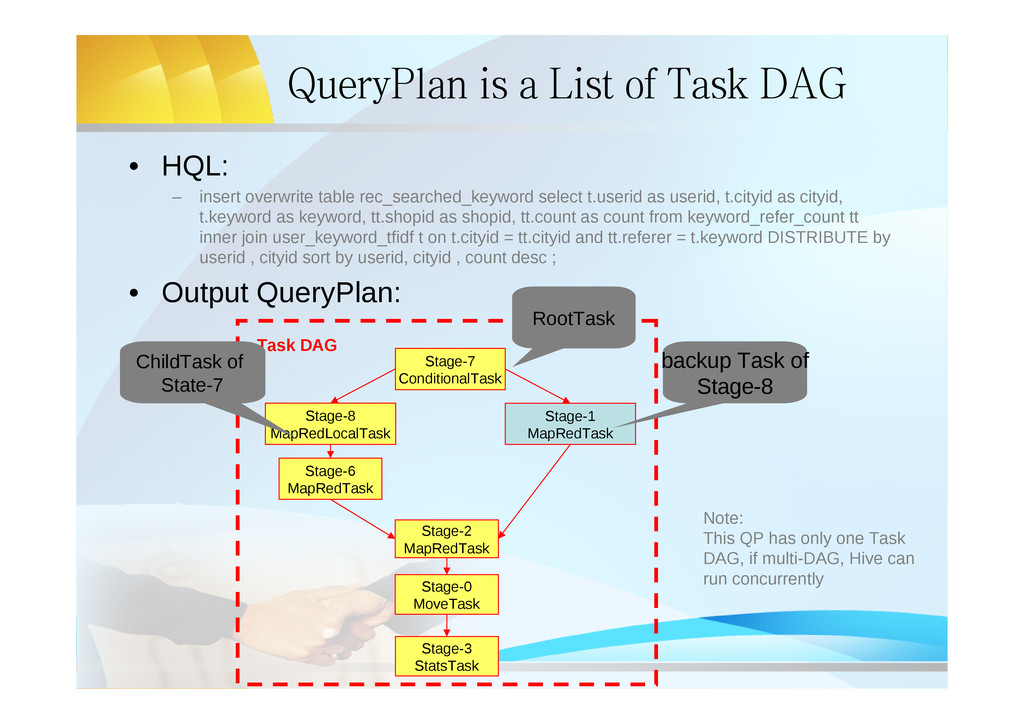
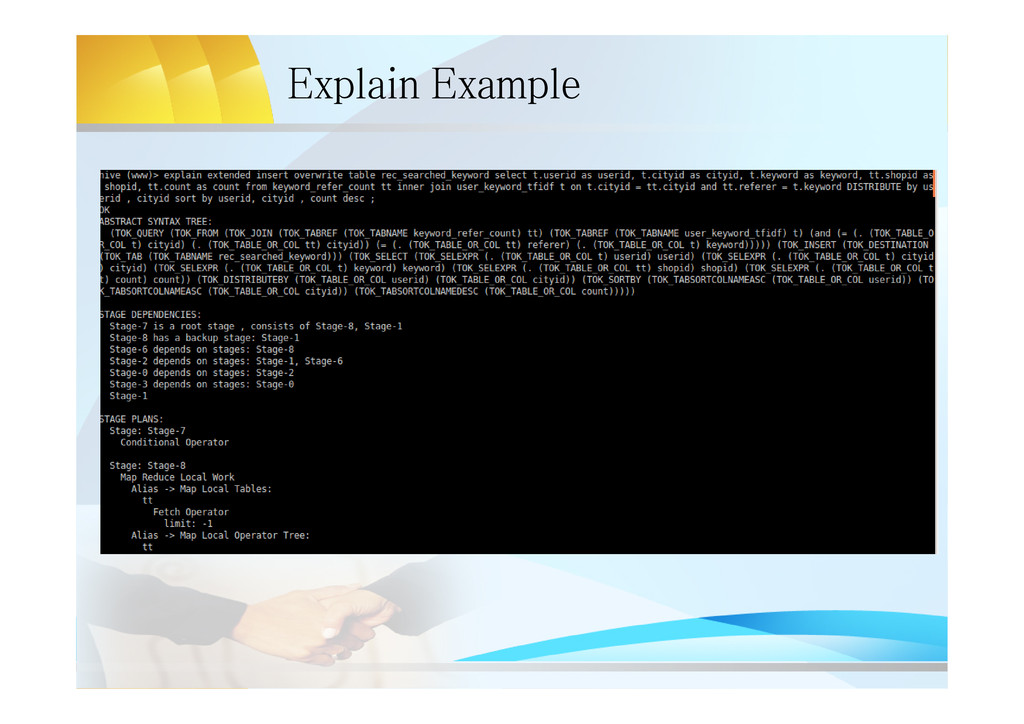
insert overwrite table rec_searched_keyword select t.userid as userid, t.cityid as cityid, t.keyword as keyword, tt.shopid as shopid, tt.count as count from keyword_refer_count tt inner join user_keyword_tfidf t on t.cityid = tt.cityid and tt.referer = t.keyword DISTRIBUTE by userid , cityid sort by userid, cityid , count desc ; • Output QueryPlan: Stage-7 ConditionalTask Stage-8 MapRedLocalTask Stage-1 MapRedTask Stage-6 MapRedTask Stage-2 MapRedTask Stage-0 MoveTask Stage-3 StatsTask Task DAG RootTask ChildTask of State-7 backup Task of Stage-8 Note: This QP has only one Task DAG, if multi-DAG, Hive can run concurrently
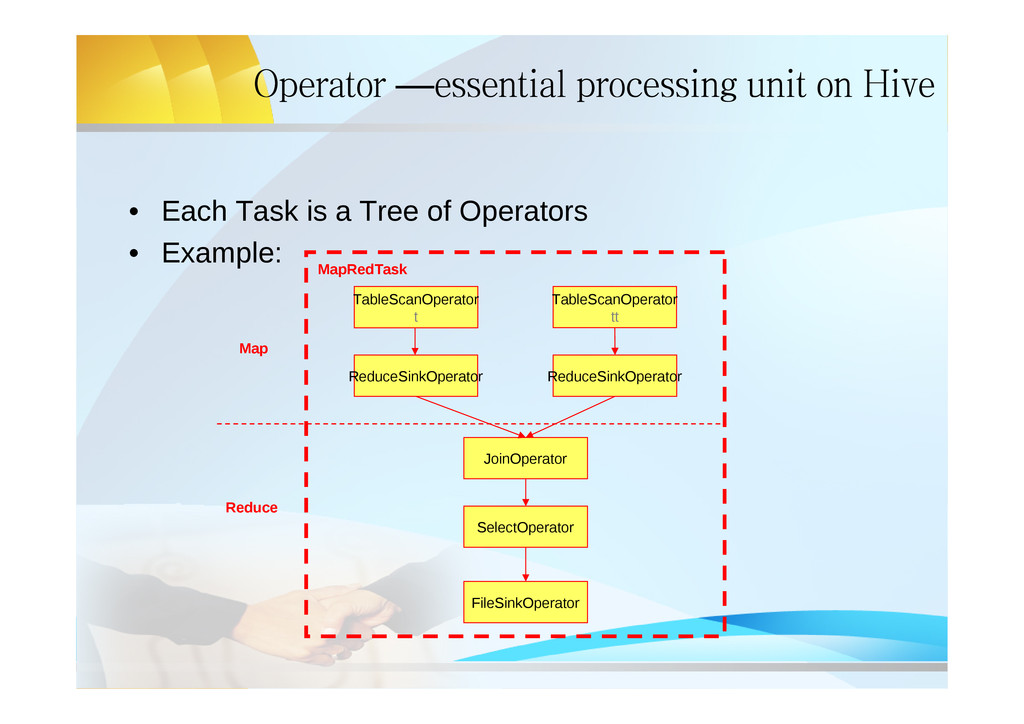
a Tree of Operators • Example: TableScanOperator t TableScanOperator tt ReduceSinkOperator ReduceSinkOperator JoinOperator SelectOperator FileSinkOperator MapRedTask Map Reduce
analystic job large latency: mins ~ hours Batch Adhoc query DataSize: GB~TB one-click query low latency: sec ~ mins streaming Live Data event driven low latency: sec Actually, we launched more adhoc query than reporting batch job. But Hive is so weight for adhoc query offline hive Jobs for reporting or large size processing Not implemented in DP, but most valuable
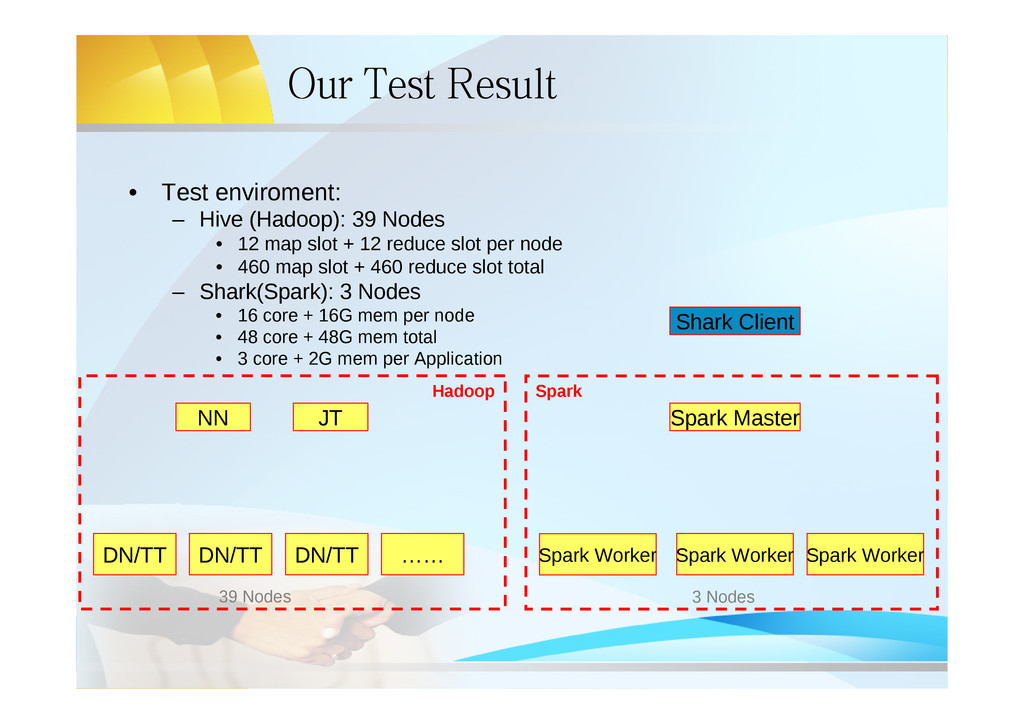
builds on Spark (MapReduce deterministic, idempotent tasks), – scales out and is fault-tolerant, – supports low-latency, interactive queries through in-memory computation, – supports both SQL and complex analytics such as machine learning, – is compatible with Apache Hive (storage, serdes, UDFs, types, metadata).
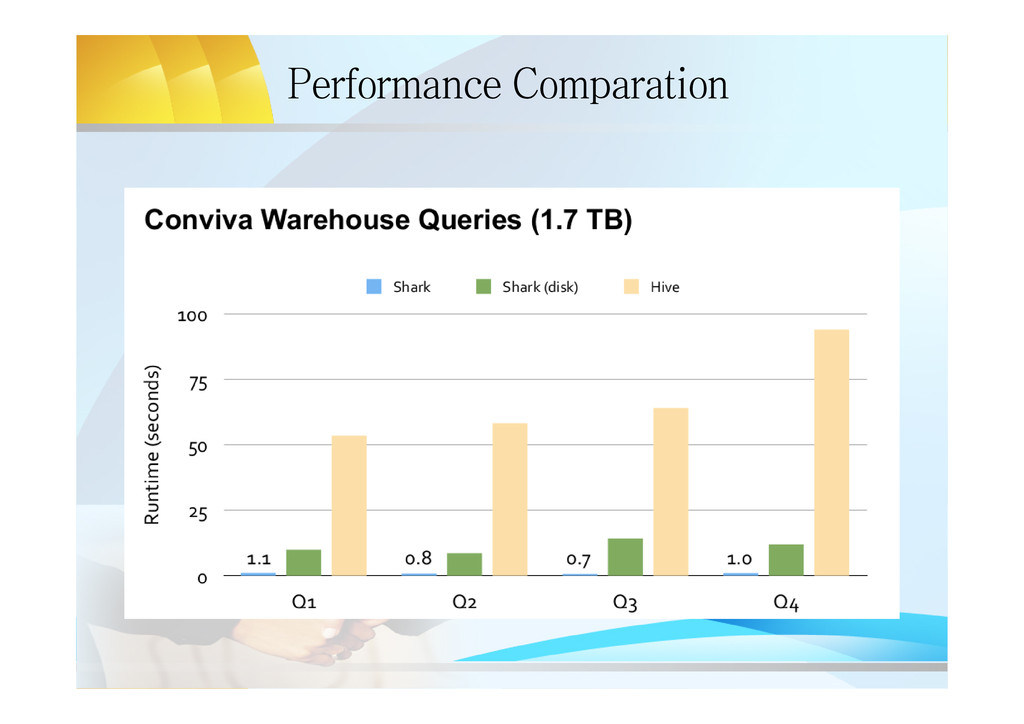
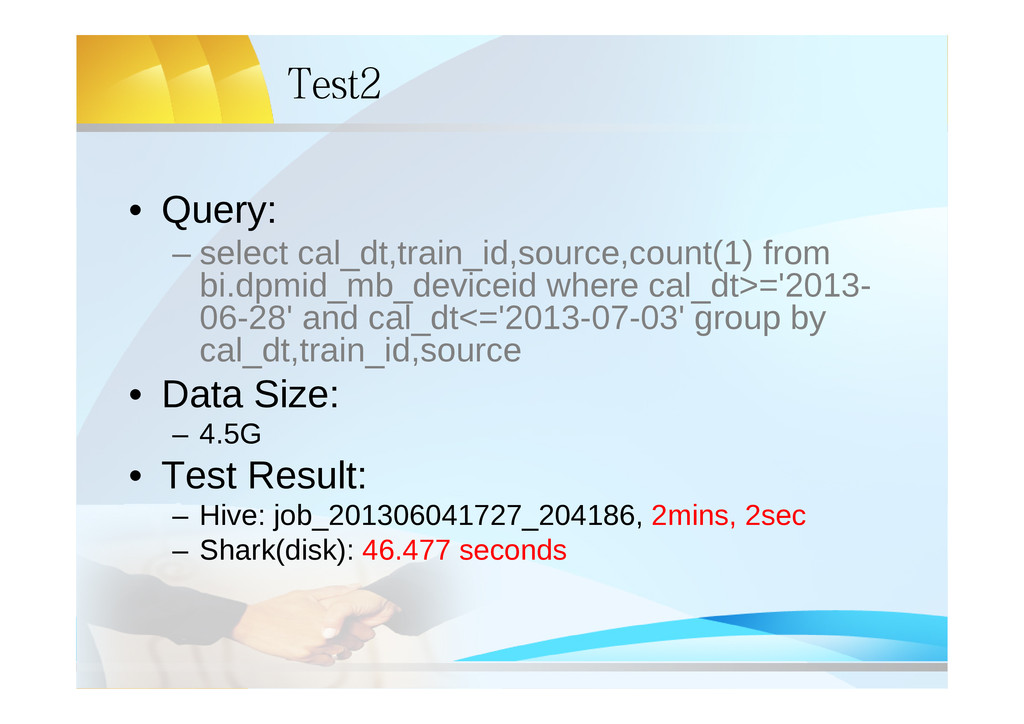
06-28' and cal_dt<='2013-07-03' group by cal_dt,train_id,source • Data Size: – 4.5G • Test Result: – Hive: job_201306041727_204186, 2mins, 2sec – Shark(disk): 46.477 seconds
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
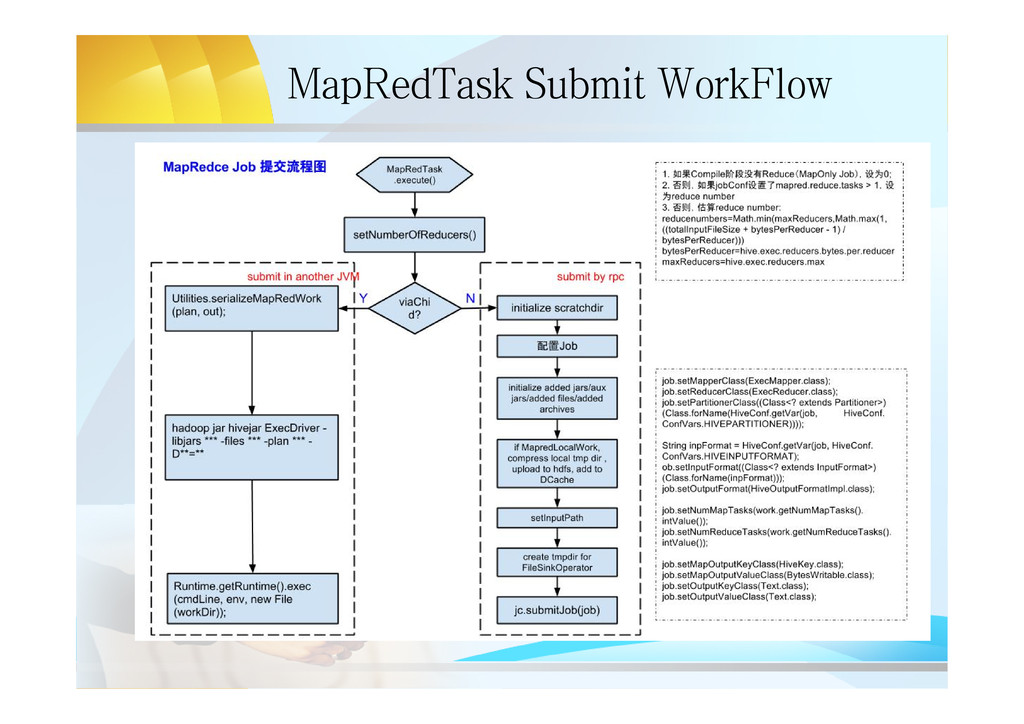{kind=link}
![use Explain to analyze QP • usage: – explain [extended|formatted]](https://files.speakerdeck.com/presentations/8cc3b680c9c201304b167a256e1aaa1f/slide_20.jpg){kind=link}
{kind=link}
{kind=link}
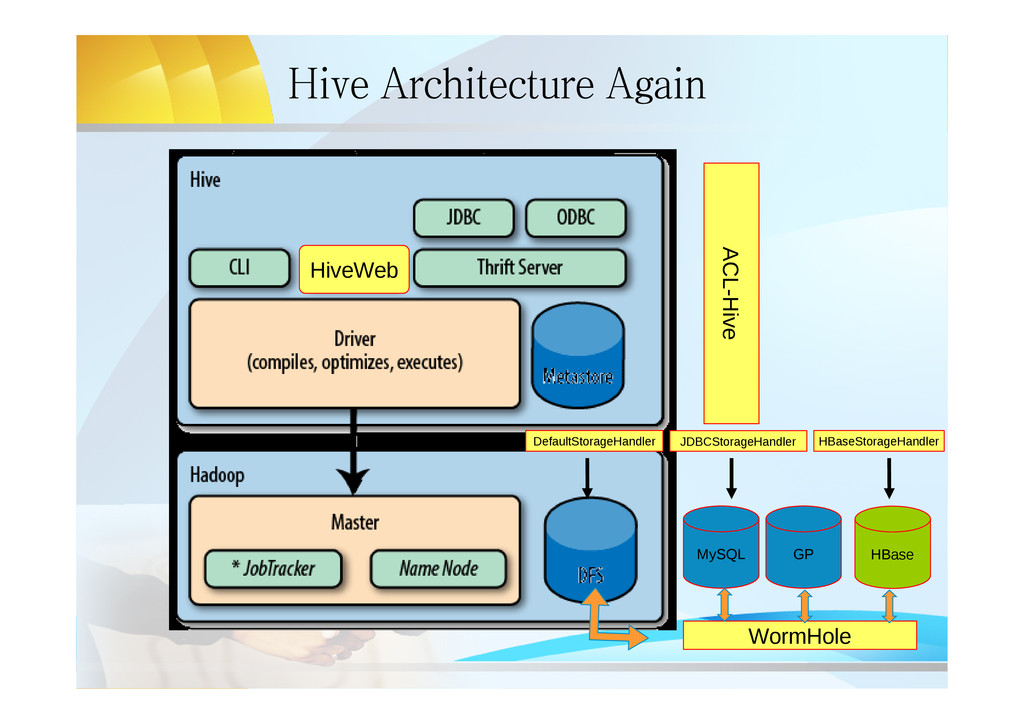{kind=link}
{kind=link}
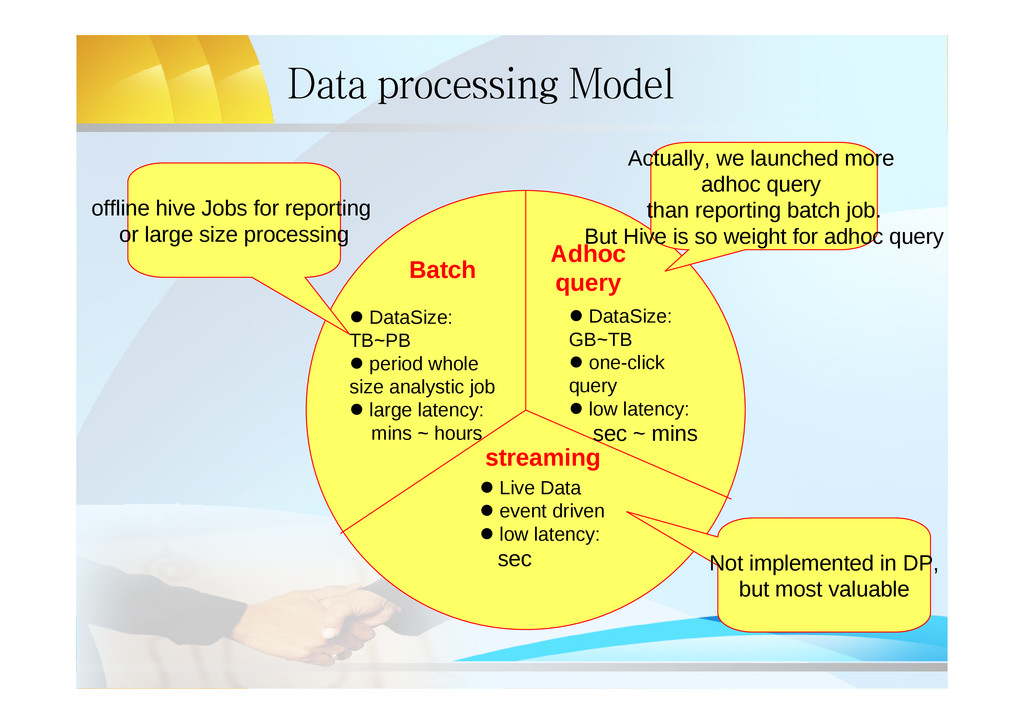{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks and QA [email protected] github.com/dianping/hive](https://files.speakerdeck.com/presentations/8cc3b680c9c201304b167a256e1aaa1f/slide_33.jpg){kind=link}