Map = 50 Wrote input for Map #0 Wrote input for Map #1 Wrote input for Map #2 Wrote input for Map #3 Wrote input for Map #4 Wrote input for Map #5 Wrote input for Map #6 Wrote input for Map #7 Wrote input for Map #8 Wrote input for Map #9 Wrote input for Map #10 Wrote input for Map #11 Wrote input for Map #12 …...
![Hadoop on Cubieboard CUBIEBOARD [email protected]](https://files.speakerdeck.com/presentations/85c15430da28013055fd7e2f83e9150d/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
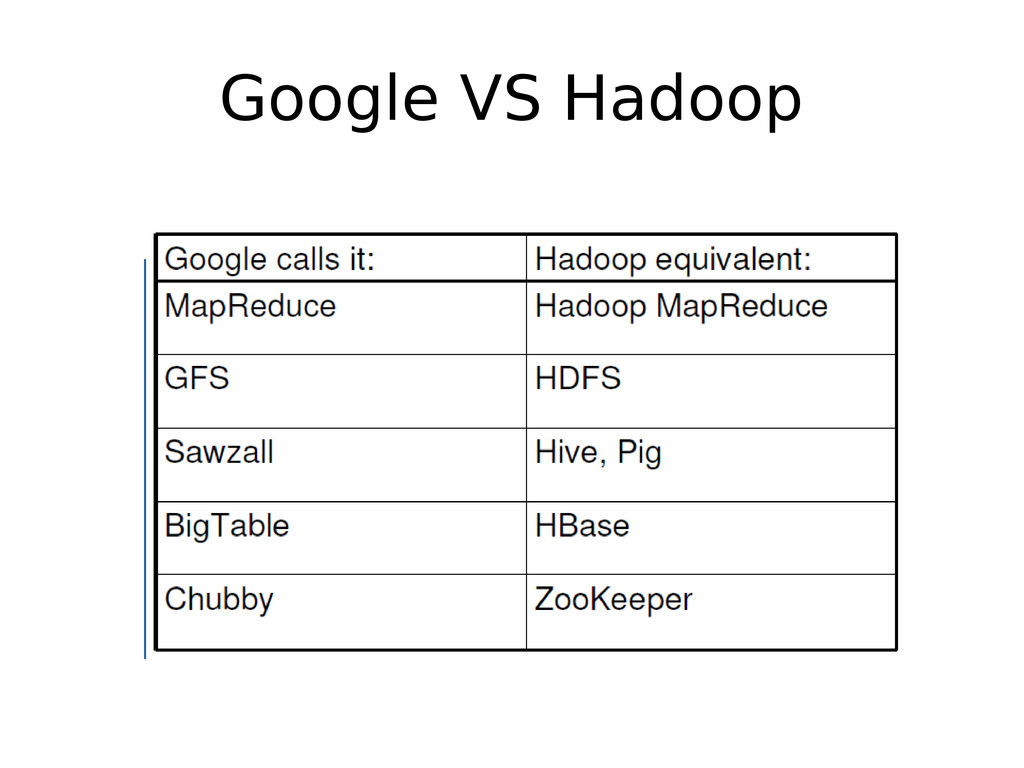{kind=link}
{kind=link}
{kind=link}
{kind=link}
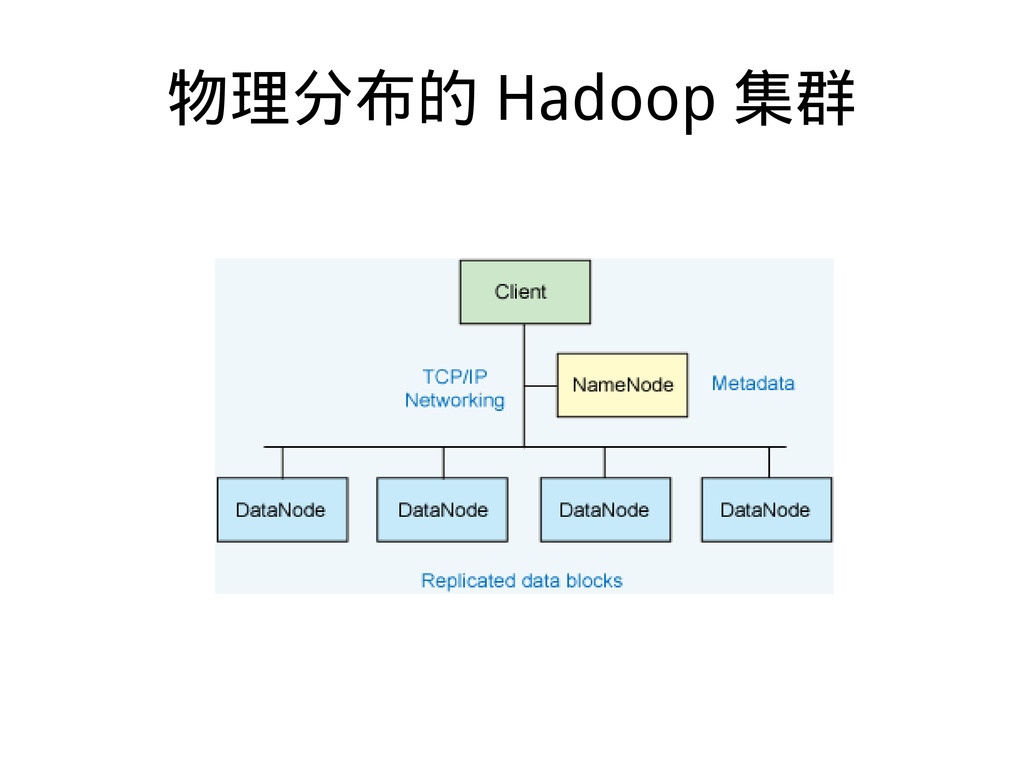{kind=link}
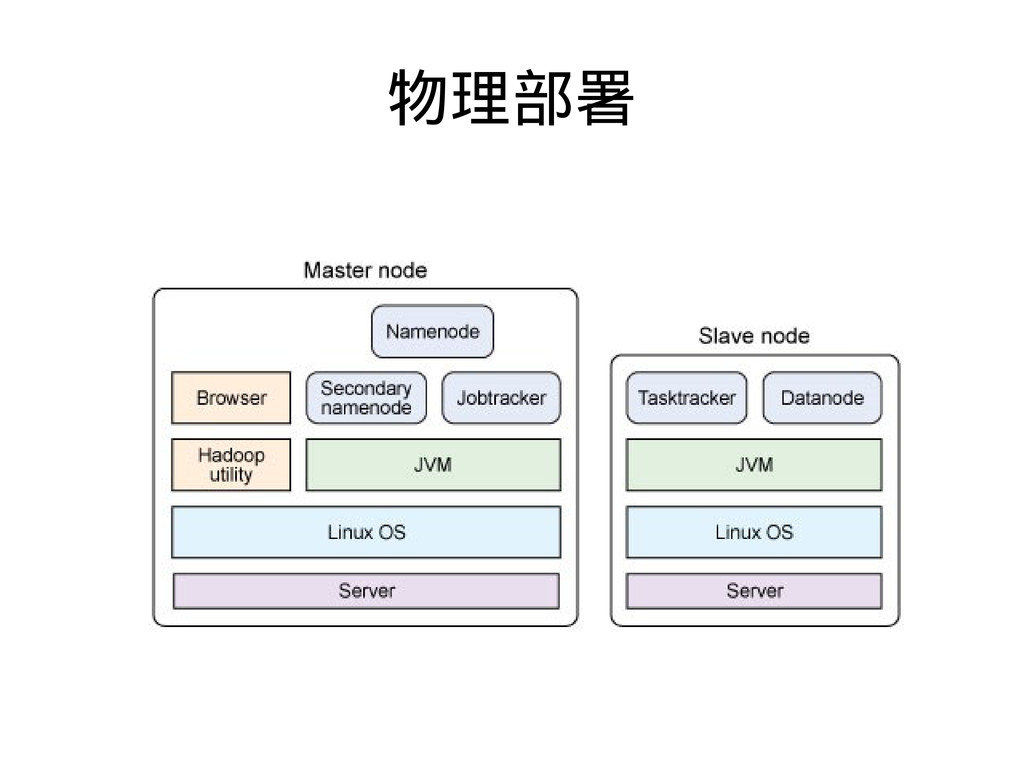{kind=link}
{kind=link}
{kind=link}
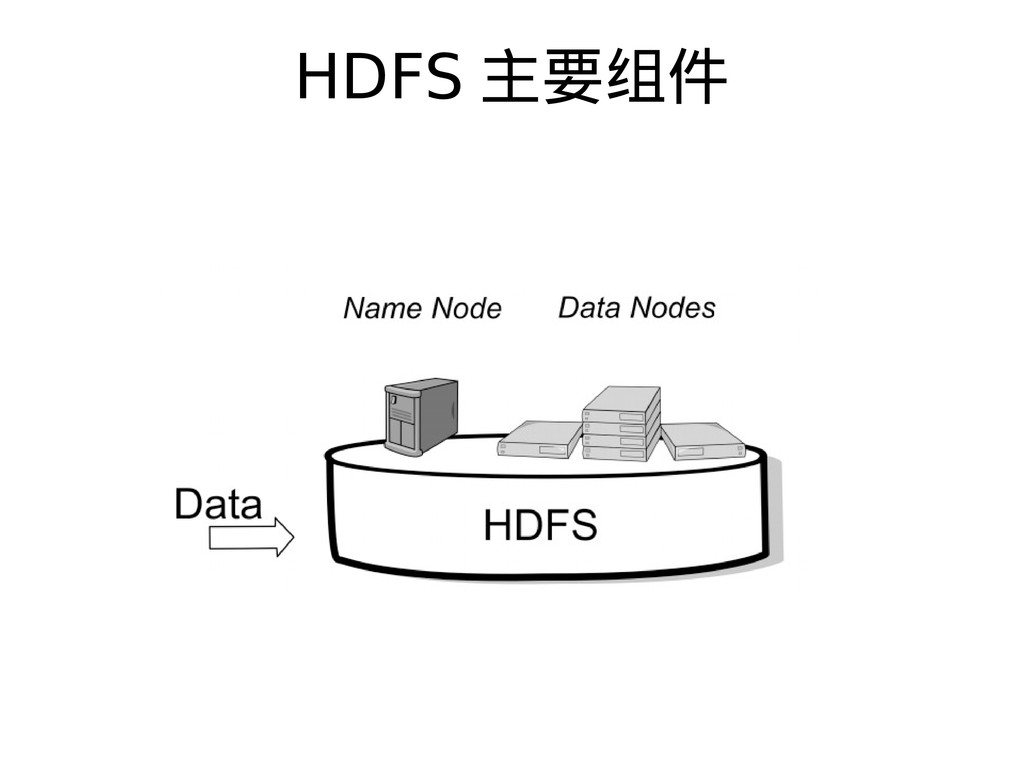{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}