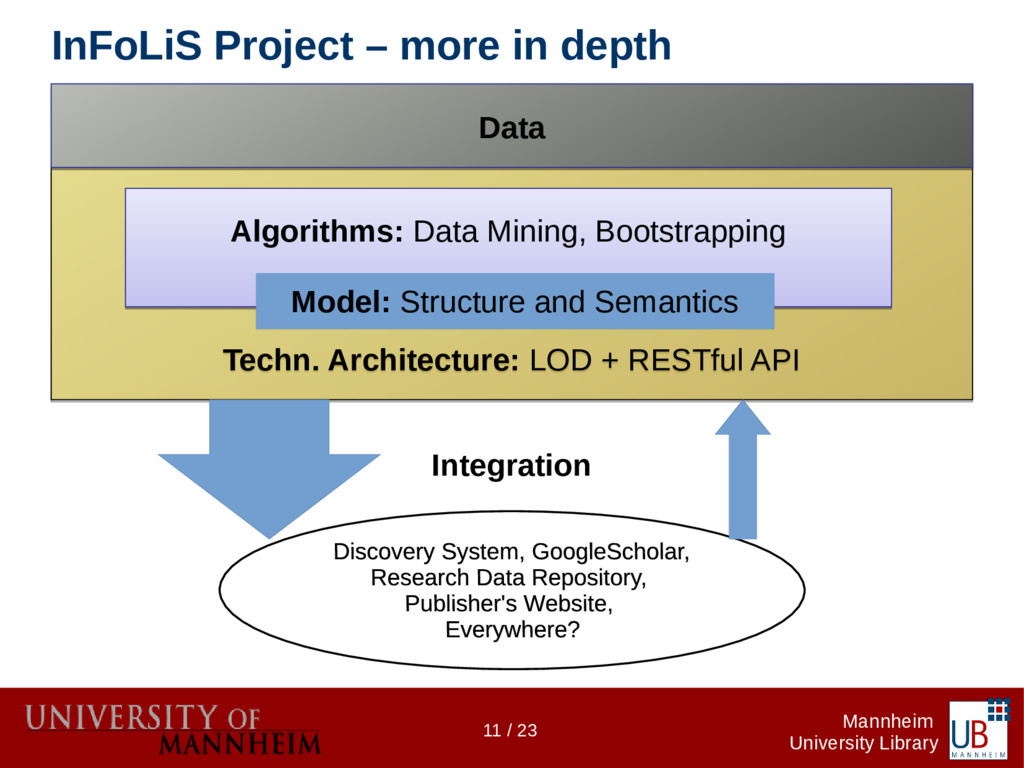
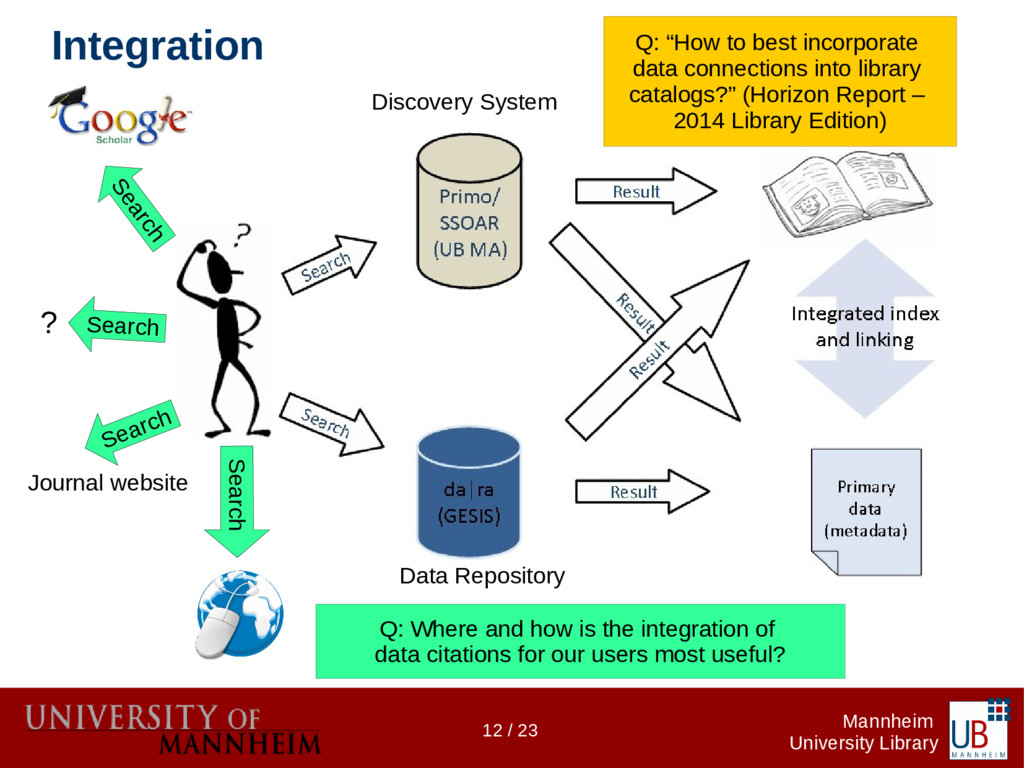
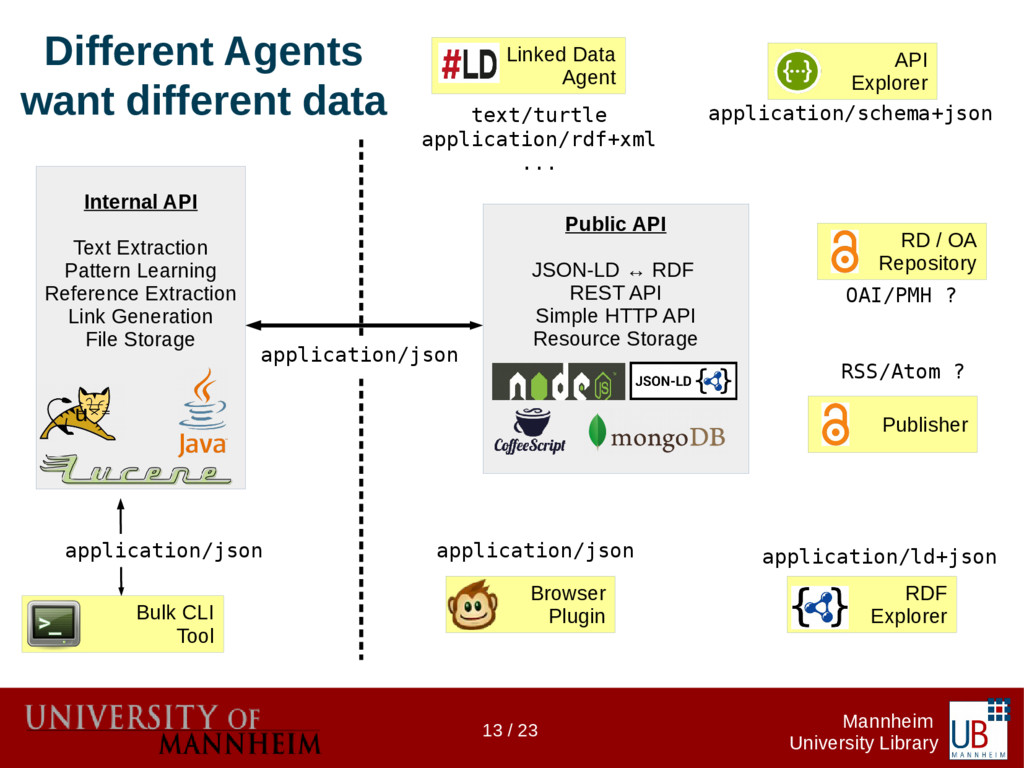
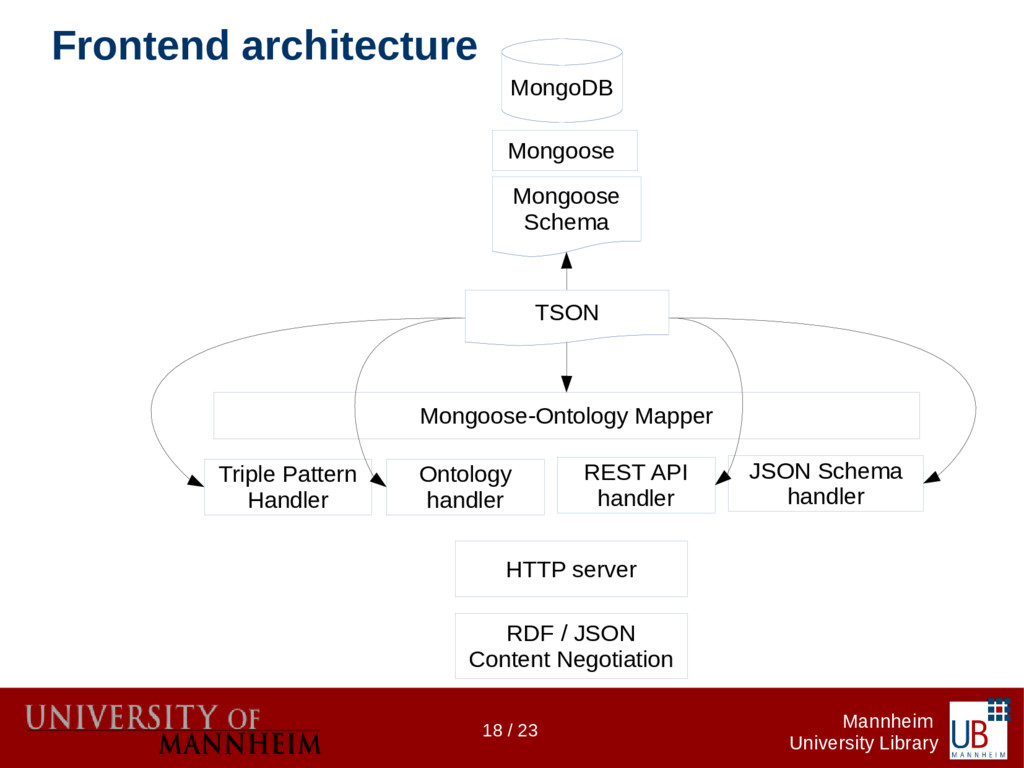
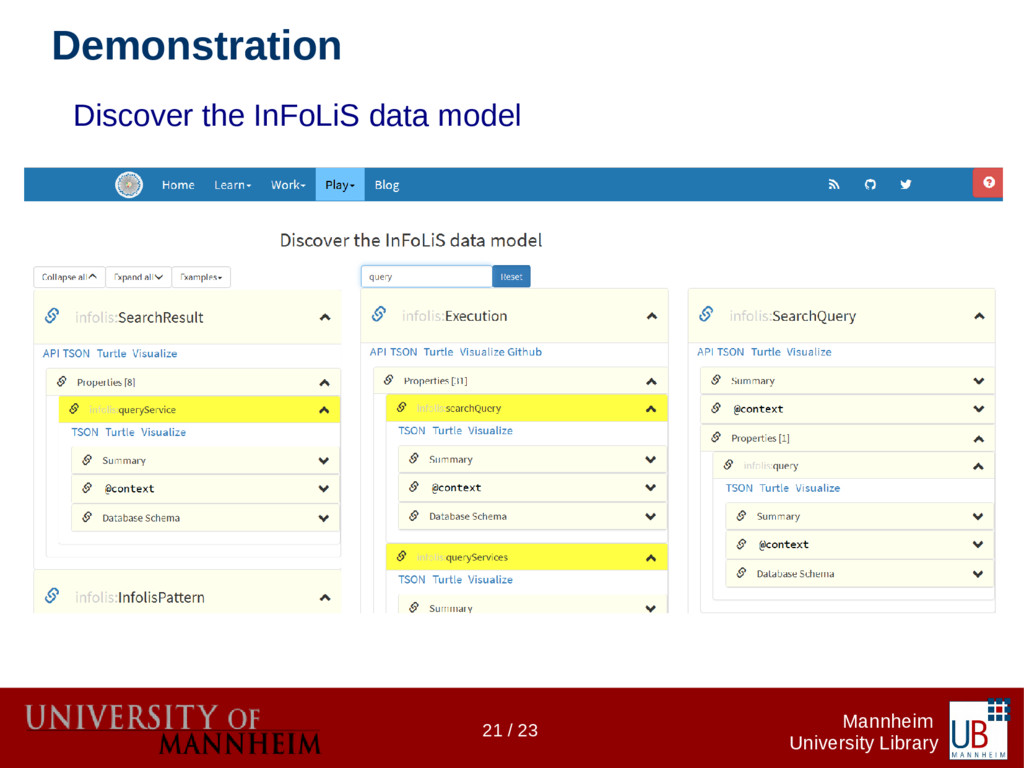
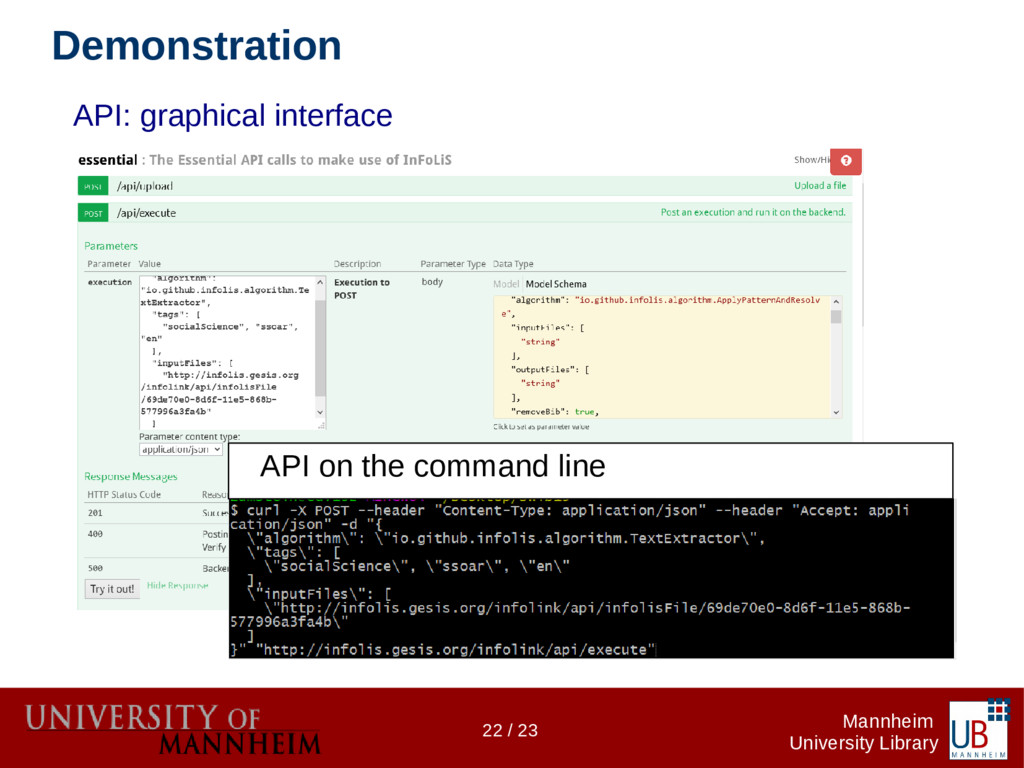
Data citations are more common today, but more often than not the references to research data don't follow any formalism as do references to publications. The InFoLiS project makes those "hidden" references explicit using text mining techniques. They are made available for integration by software agents (e.g. for retrieval systems). In the second phase of the project we aim to build a flexible and long-term sustainable infrastructure to house the algorithms as well as APIs for embedding them into existing systems. The infrastructure's primary directive is to provide lightweight read/write access to the resources that define the InFoLiS data model (algorithms, metadata, patterns, publications, etc.). The InFoLiS data model is implemented as a JSON schema and provides full forward compatibility with RDF through JSON-LD using a JSON-to-RDF schema-ontology mapping, reusing established vocabularies whenever possible. We are neither using a triplestore nor an RDBMS, but a document database (MongoDB). This allows us to adhere to the Linked Data principles, while minimizing the complexity of mappings between different resource representations. Consequently, our web services are lightweight, making it easy to integrate InFoLiS data into information retrieval systems, publication management systems or reference management software. On the other hand, Linked Data agents expecting RDF can consume the API responses as triples; they can query the SPARQL endpoint or download a full RDF dump of the database. We will demonstrate a lightweight tool that uses the InFoLiS web services to augment the web browsing experience for data scientists and librarians.
Conference Website: http://swib.org/swib15/index.html
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}