Presentation at Social Science Data Lab, MZES, Mannheim (2017-03-15)
Additional materials: https://github.com/SocialScienceDataLab/building-infrastructure-for-data-driven-research/settings
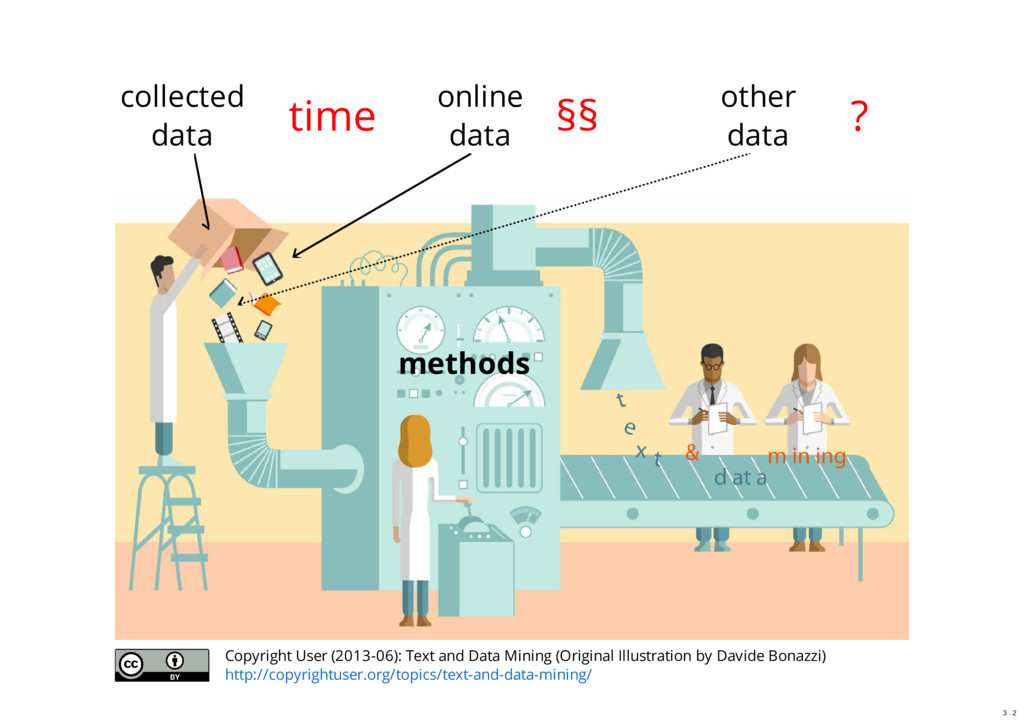
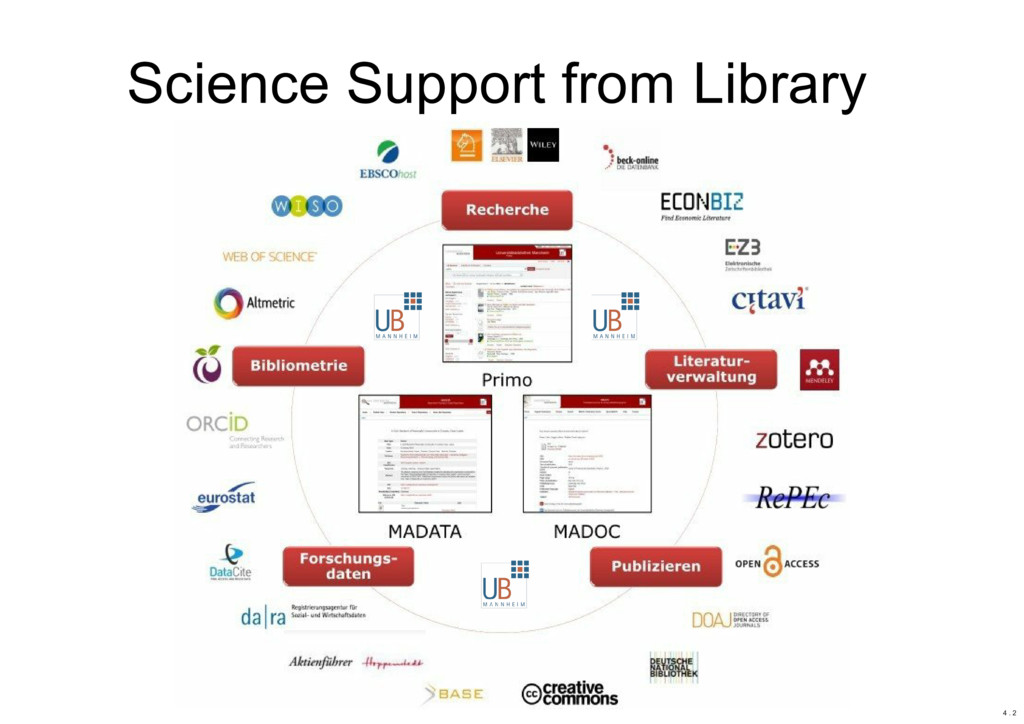
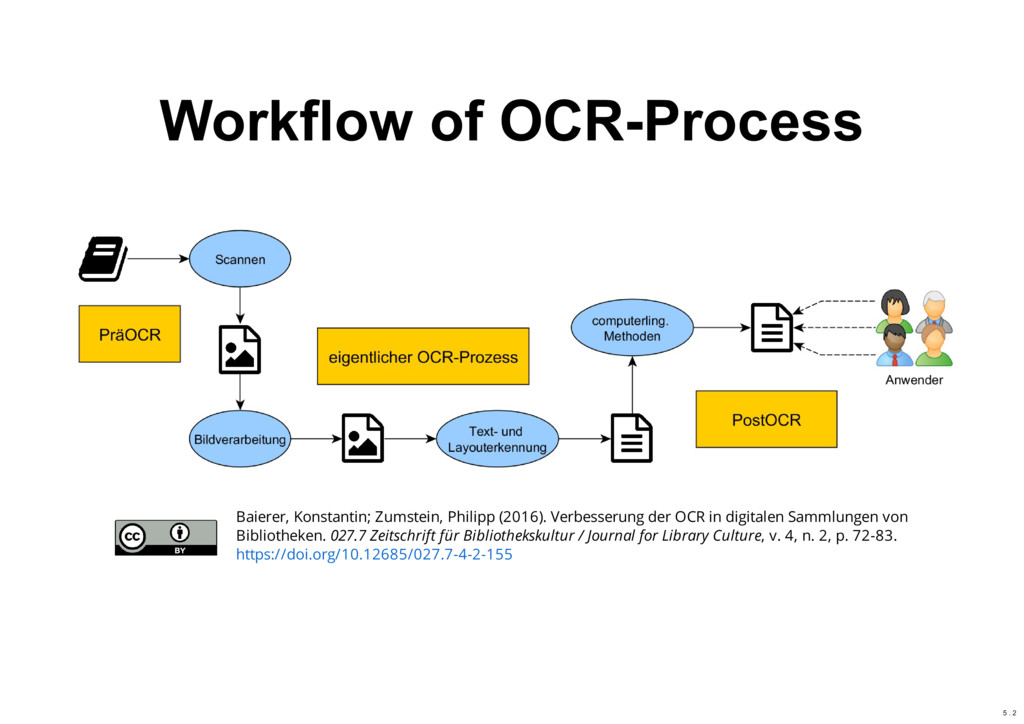
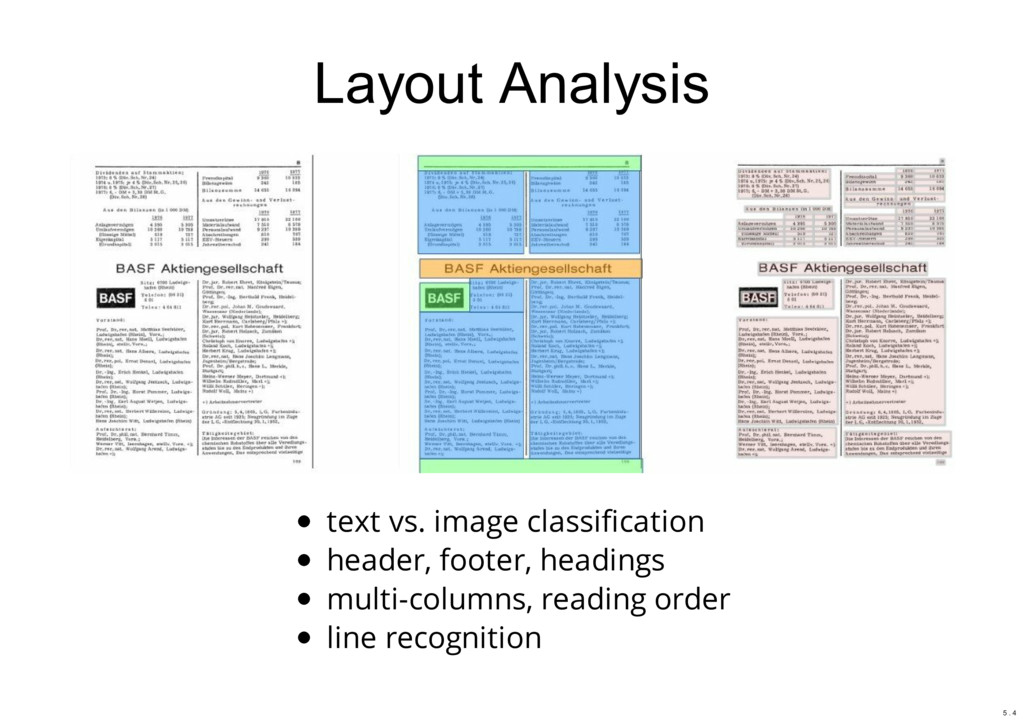
Abstract: Most methods for data-driven research (including Big Data, Data Science, and Digital Humanities) work primarily on text data or numbers. However, there is also a lot of information which is only available in printed books or newspapers. This information has to be first digitized and then further processed to extract the text or data. The main focus of the talk is optical character recognition (OCR). We will see the OCR workflow in general, discuss some OCR software, and how you can use these tools practically. Building such an infrastructure or performing these initial steps may need a reasonable amount of time and resources, or also be a project itself. The Mannheim University Library has in this area some infrastructure projects which are briefly mentioned.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
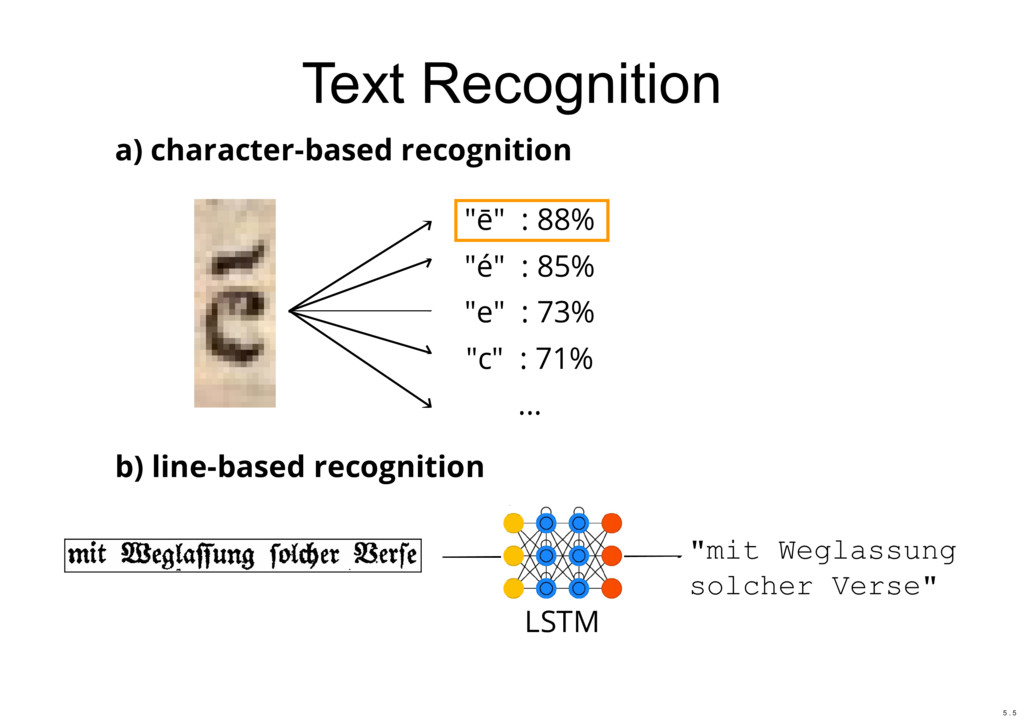{kind=link}
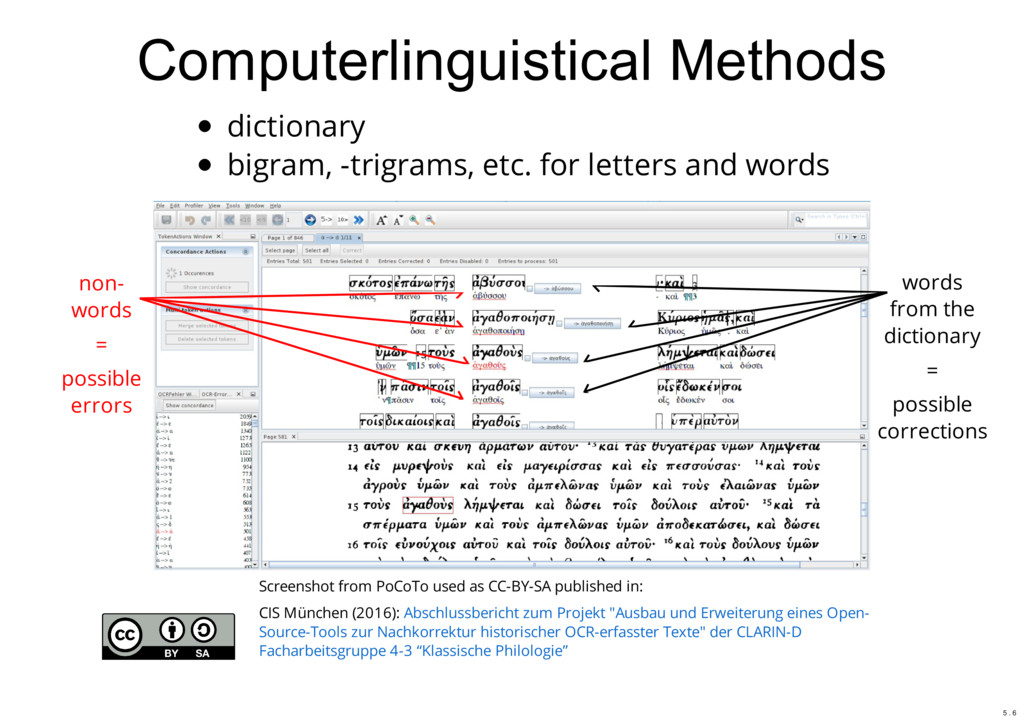{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
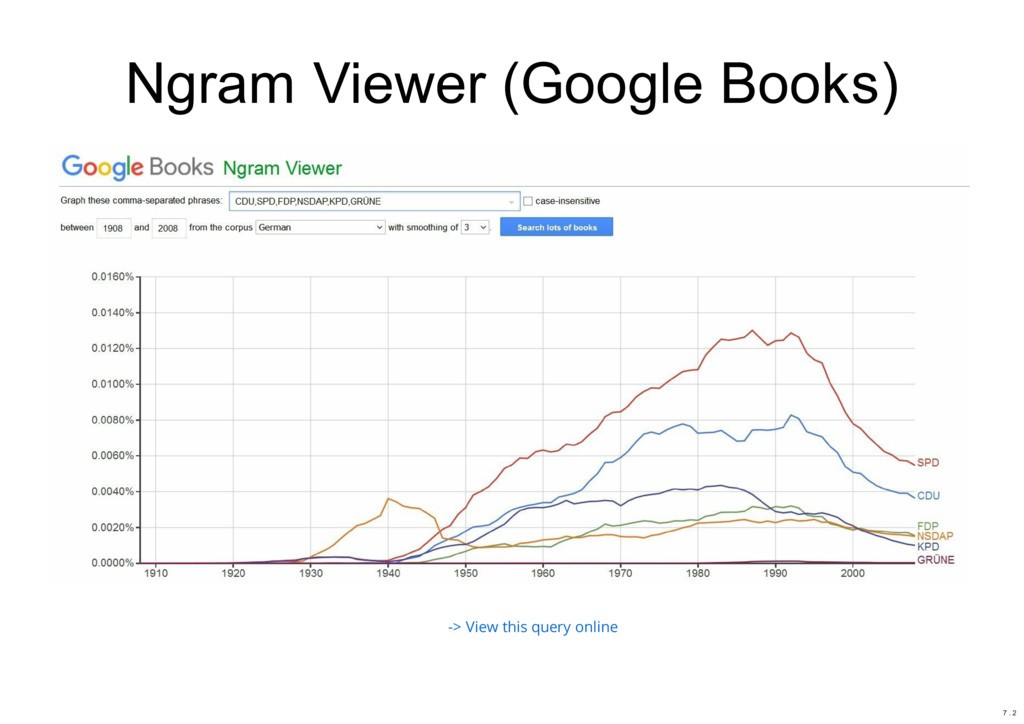{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}