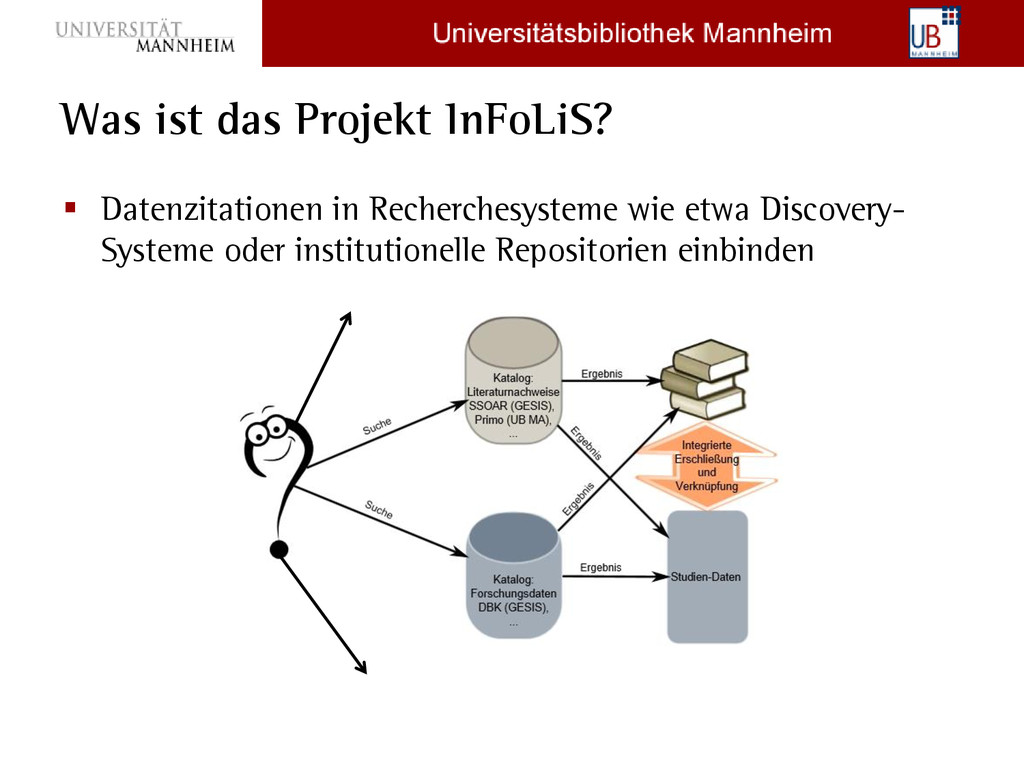
In einer wissenschaftlichen Publikation sollen die verwendeten Forschungsdaten möglichst gleich wie die verwendete Literatur angegeben werden. Wenn bei diesen Datenzitationen die Forschungsdaten über eine DOI referenziert werden, dann können diese Beziehungen auch einfach maschinell verarbeitet werden. Die genaue Formattierung und Reihung der Metadatenfelder in Datenzitationen ist bereits in etlichen Empfehlungen und Zitationsstilen geregelt. In der Praxis wird aber häufig nur der Name einer Studie (in unterschiedlichen Varianten) oder evtl. der Name der Datenbank im Fließtext angegeben. Genau hier setzt das Projekt InFoLiS [1] der UB Mannheim in Kooperation mit der GESIS und der HdM Stuttgart/Universität Mannheim an. Ziel dieses DFG-Projektes ist es, mit Hilfe von Text-Mining-Techniken die Datenzitationen zwischen Publikationen und Forschungsdaten explizit zu machen und diese Beziehungen in Recherchesysteme wie etwa Discovery-Systeme oder institutionelle Repositorien einzubinden.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}