Probabilistic Programming Languages (modern) • Bayesian Logic (compiler Swift [Wu et al. 2016]) • TerpreT (Gaunt et al. 2016) • and a LONG list of other PPLs • Neural Abstract Machines (contemporary)
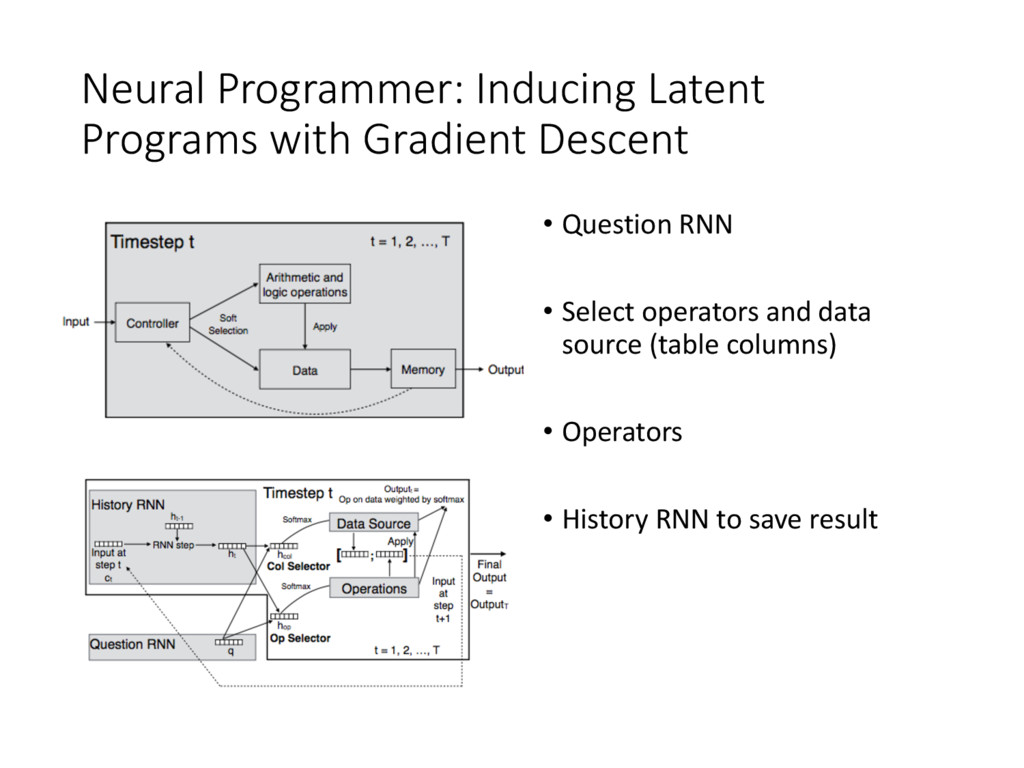
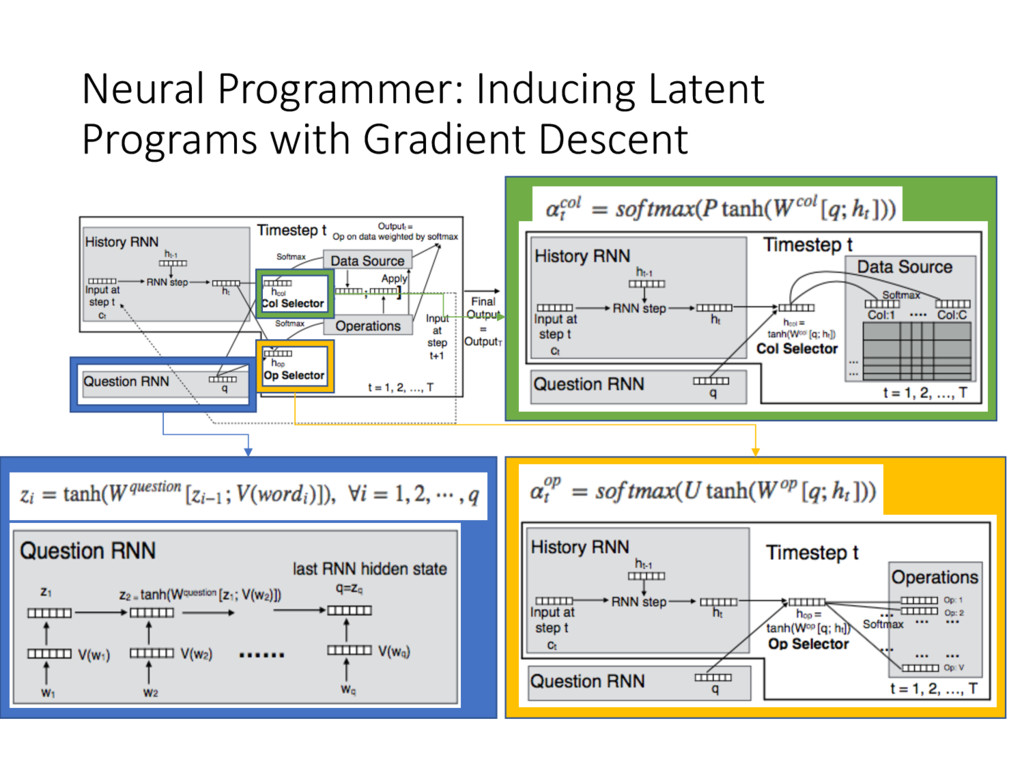
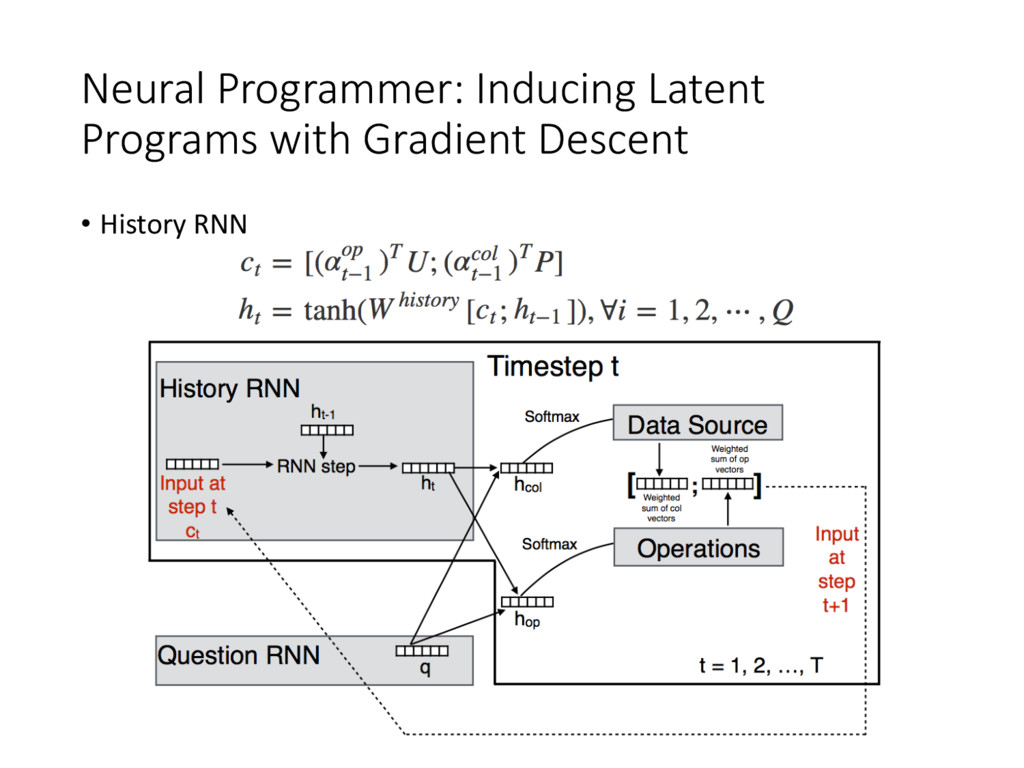
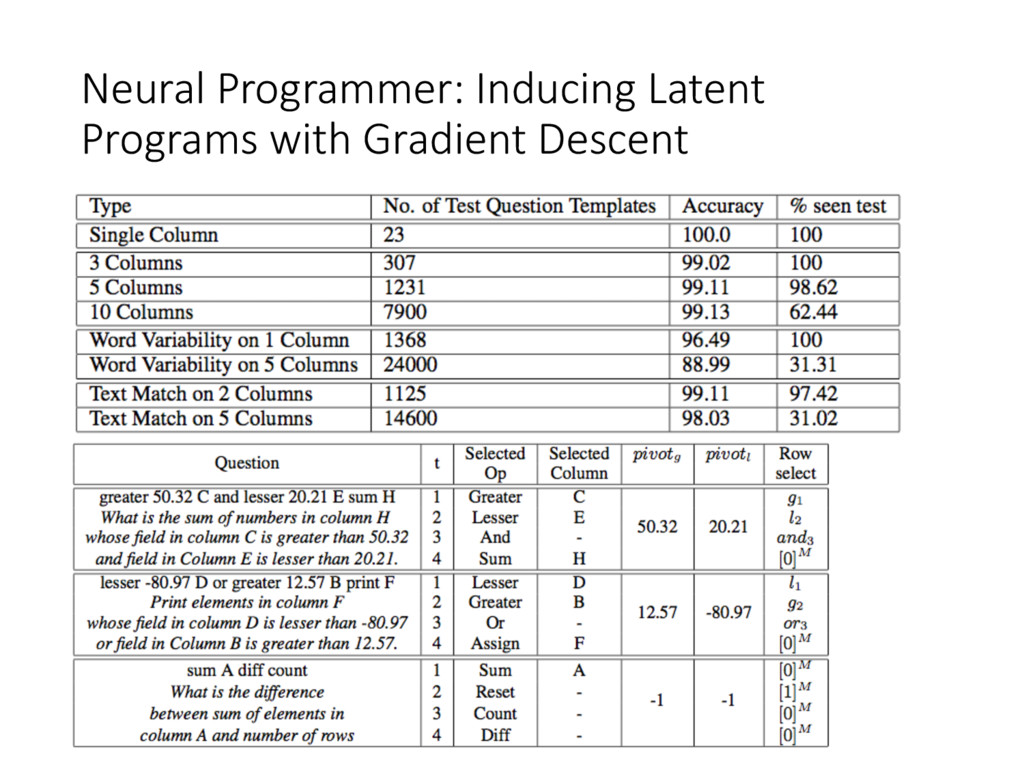
• NN are unable to learn even simple arithmetic and logic operations (Joulin and Mikolov, 2015) • Tasks like QA need complex reasoning • Contributions • Neural Programmer, an NN augmented with arithmetic and logic operators • Learn from weak supervision • Fully differentiable • KeyPoint: select operators and save results iteratively for T timesteps • Synthetic Dataset (tables)
• Maintained Output Variables: • + ∈ ℝ, scalar answer of t step, init to 0 • + ∈ 0,1 6×8, selection prob. of entry (i, j), init to 0 • + ∈ [0,1]6, selection prob. of row i, init to 1 • Operator List
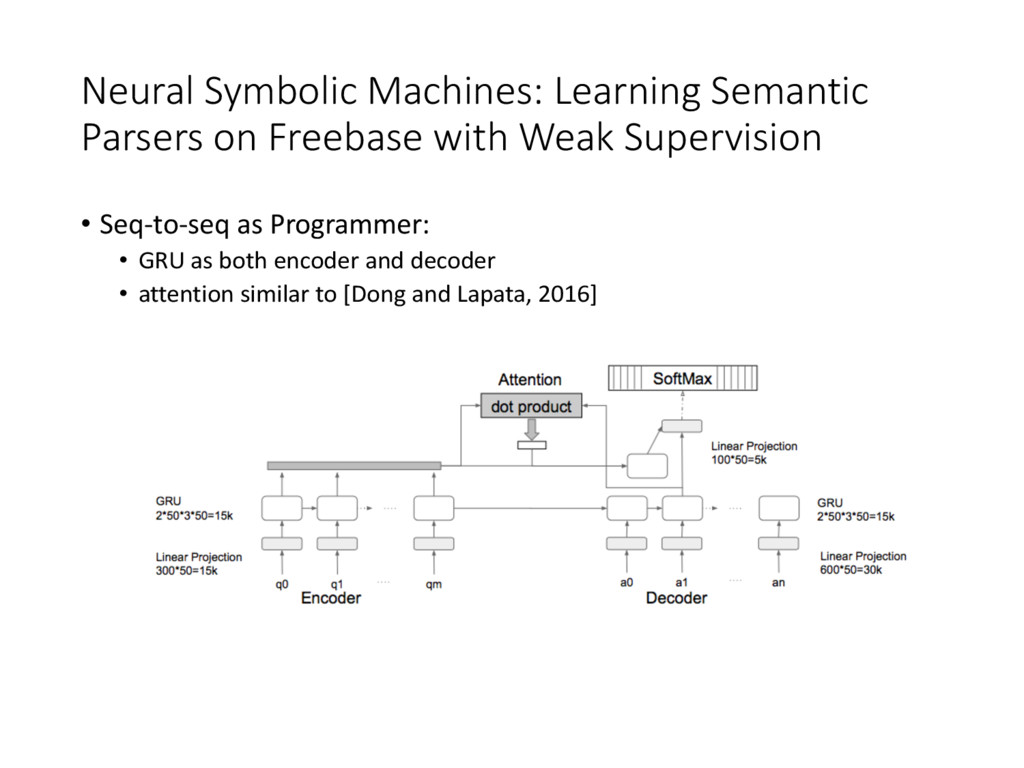
• Use complete program execution sequence as supervision • Core LSTM + domain-specific encoders, for various environments • Augmented with programs saved in key-value memory environments arguments domain-specific encoder prob(end-of-prog) program key next argument next env next program
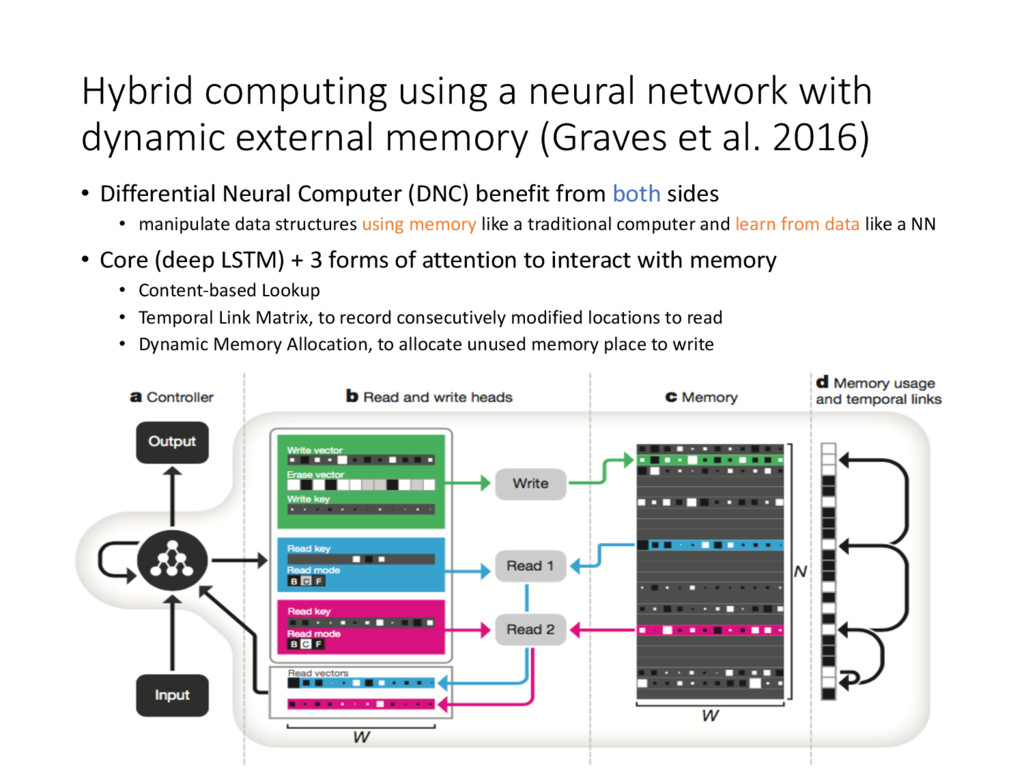
(Graves et al. 2016) • Differential Neural Computer (DNC) benefit from both sides • manipulate data structures using memory like a traditional computer and learn from data like a NN • Core (deep LSTM) + 3 forms of attention to interact with memory • Content-based Lookup • Temporal Link Matrix, to record consecutively modified locations to read • Dynamic Memory Allocation, to allocate unused memory place to write
(Graves et al. 2016) • Read from memory • the weights domain: non-negative orthant with a unit simplex as boundary • suppose we have R read weights • the read vectors are: (i = 1, 2, ..., R) • Write to memory • writing weight, , erase vector , write vector • then erase and write to the memory:
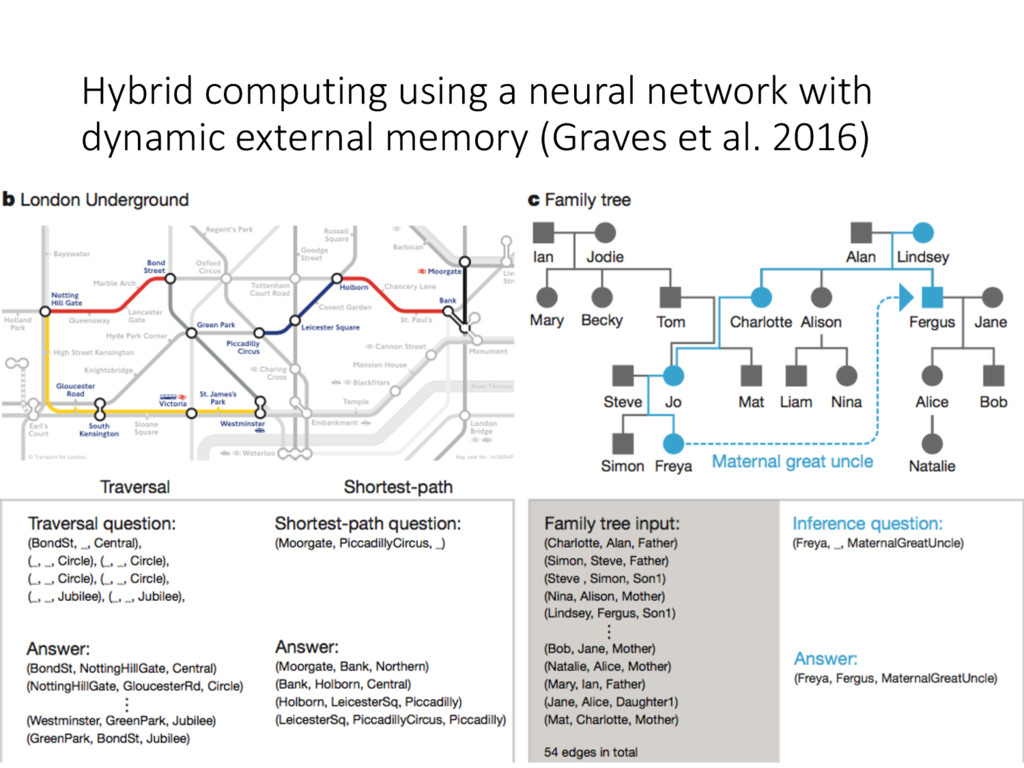
of free memory in a traditional computer) • Synthesize the free gates for every previous read vector • Update the usage vector: • Sort the usage vector as phi (phi[1] the index of the least usage) • Allocation: • Combined with Content-based attention Hybrid computing using a neural network with dynamic external memory (Graves et al. 2016)
vector • Update the usage vector: • Sort the usage vector as phi (phi[1] the index of the least usage) • Allocation: • Combined with Content-based attention Hybrid computing using a neural network with dynamic external memory (Graves et al. 2016)
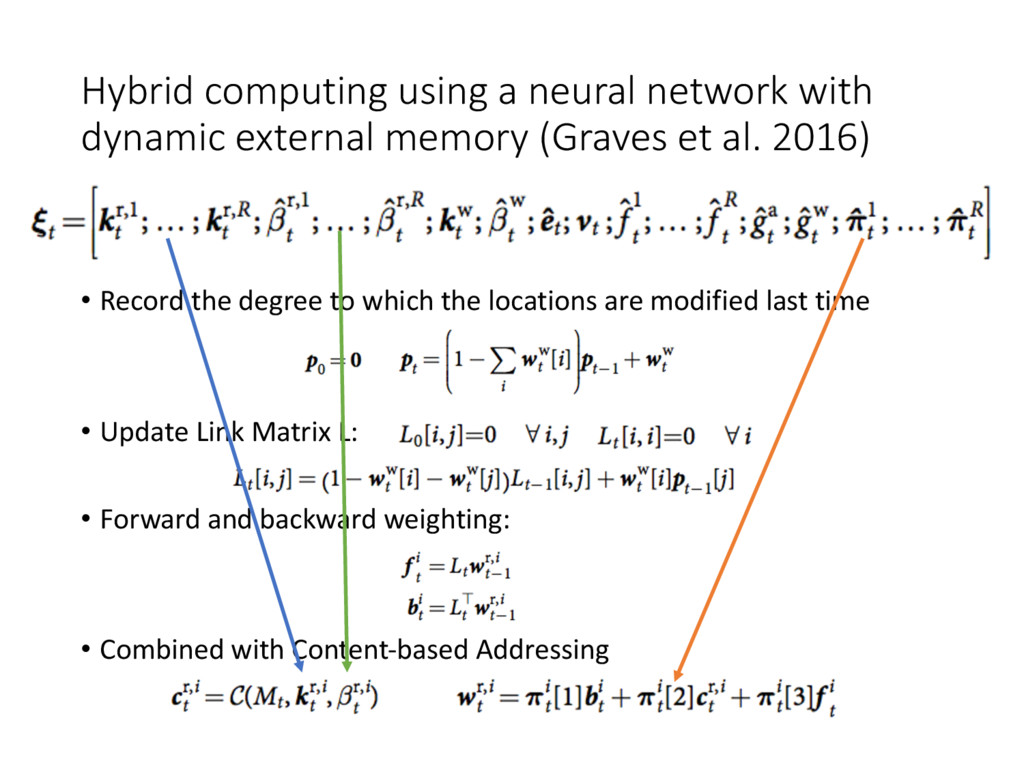
(Graves et al. 2016) • Attention 3: Temporal Memory Linkage, the cell L[i, j] is the degree to which location i is updated after j • Record the degree to which the locations are modified last time • Update Link Matrix L: • Forward and backward weighting: • Combined with Content-based Addressing
(Graves et al. 2016) • • Record the degree to which the locations are modified last time • Update Link Matrix L: • Forward and backward weighting: • Combined with Content-based Addressing
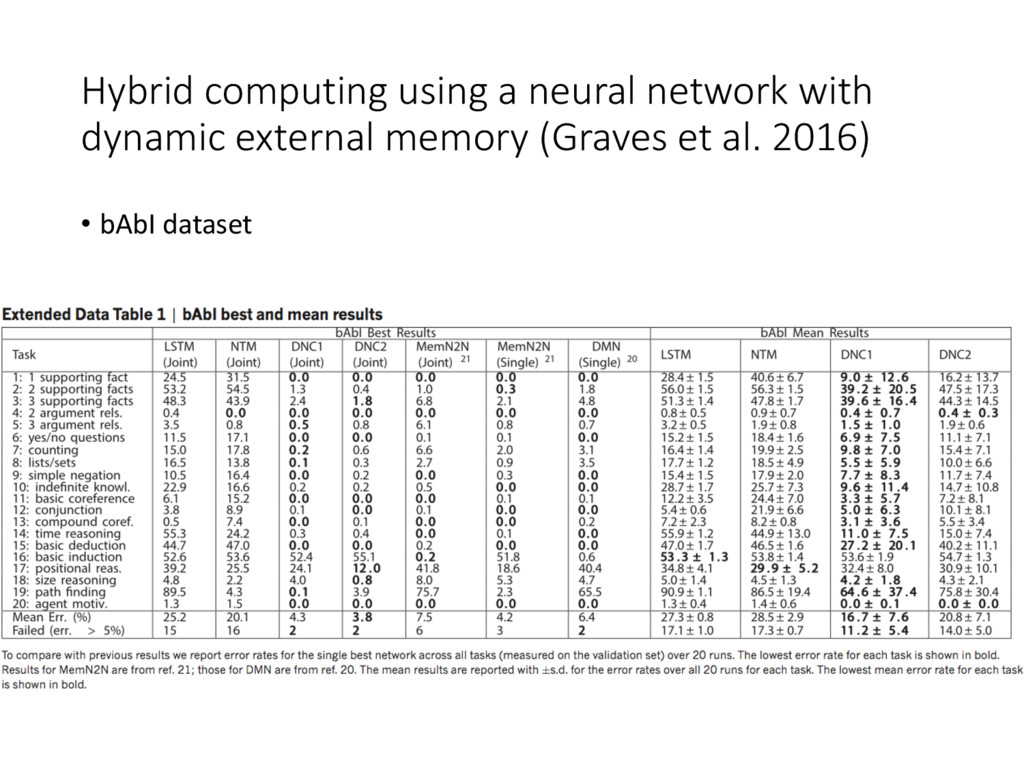
(Graves et al. 2016) • Comparison with Neural Turing Machine (NTM) • similar architecture: neural network + memory • differed in the attention mechanism with memory. NTM use location-based instead of content-based addressing, thus memory is more likely to be allocated sequentially. • Drawbacks of NTM: • NTM do not ensure the allocated blocks do not overlap and interfere. DNC do not need the assurance because the allocated blocks are not contiguous • NTM do not free memory but DNC has free gates. • NTM preserve the sequential information only when continuously iterating memory. DNC has Temporal Link Matrix.
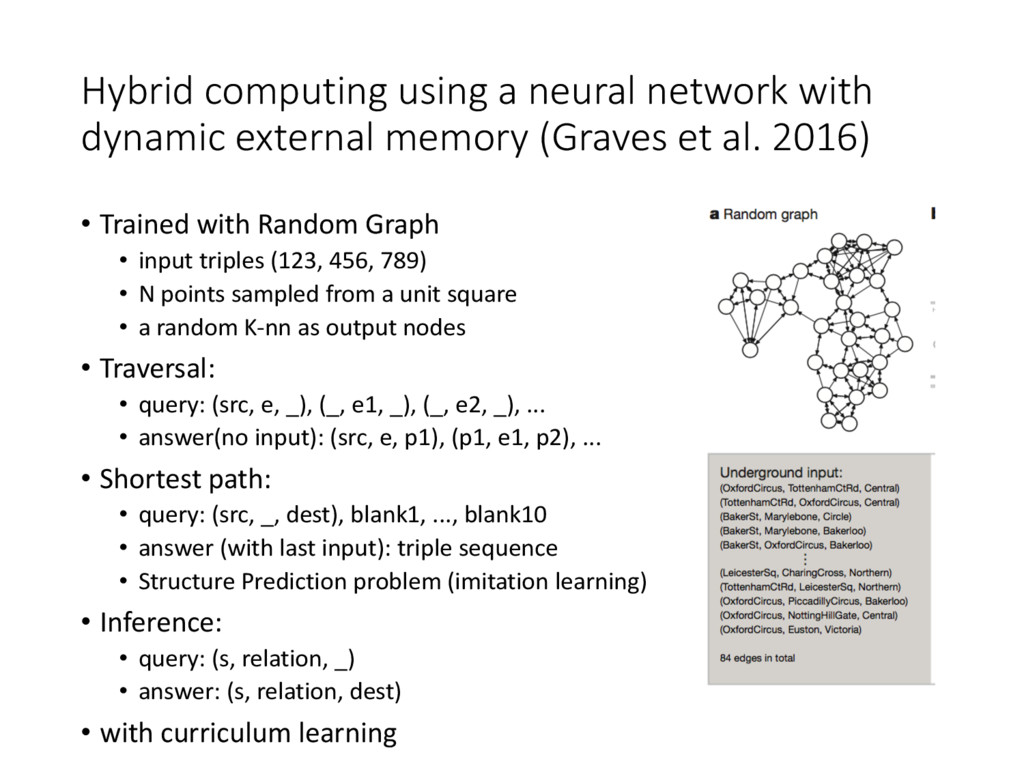
(Graves et al. 2016) • Other experiments dismissed: • Functional: • a puzzle game inspired by Winograd’s SHRDLU(Winograd, 1971): mini-SHRDLU • + Reinforcement Learning • Theoretic: • How garbage memory is re-allocated • the allocation is independent with memory size and content • effect of the sparse temporal link matrix • hyper-parameters and cross validation • curriculum learning
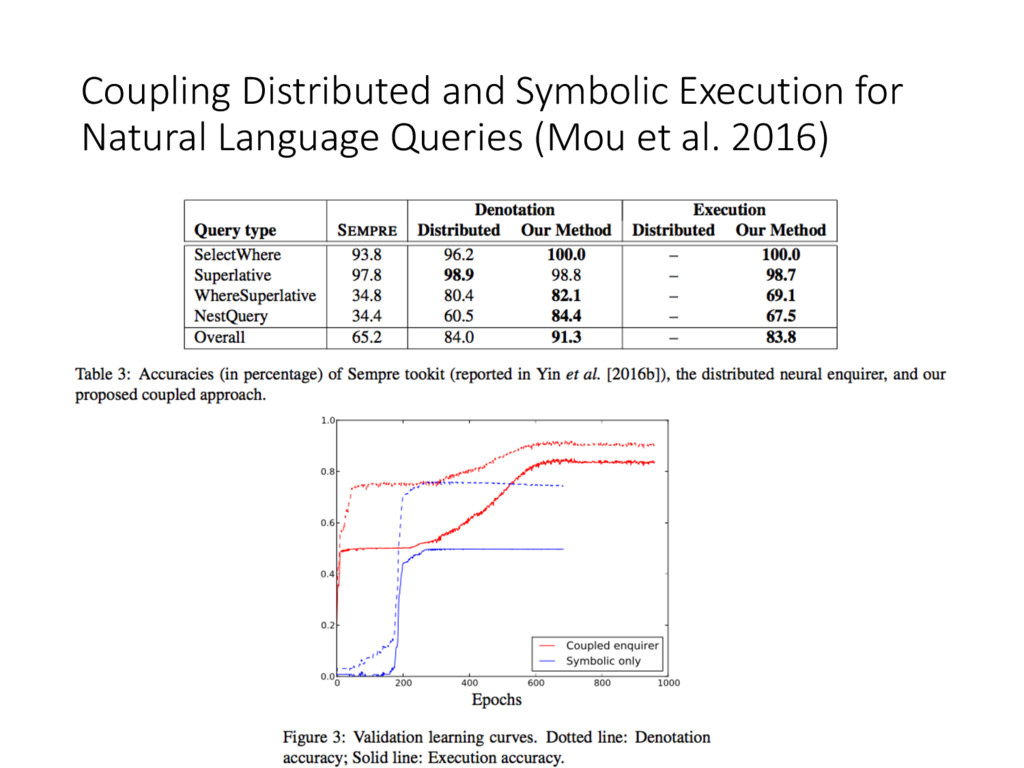
Generative QA [Yin et al. 2016a] • Human-Computer conversation [Wen et al. 2016] • Table Query [This work] • Derived from Semantic Parsing(language to logic forms): • [Long et al. 2016; Pasupat and Liang, 2016 (further over 2015)] • Seq2seq: groundtruth LF as supervision • [Dong and Lapata, 2016] seq2tree, and [Xiao et al. 2016] DSP • Neural Semantic Parsing • [Yin et al. 2016b] Neural enquirer (basis of this work), lack of explicit interpretation • [Neelakantan et al. 2016] neural programmer, ICLR-2016 • symbolic operations only for numeric tables, not for string matching • exponential number of combinatorial states • [Liang et al. 2016] neural symbolic machines, REINFORCE is sensitive to initial policy Coupling Distributed and Symbolic Execution for Natural Language Queries (Mou et al. 2016)
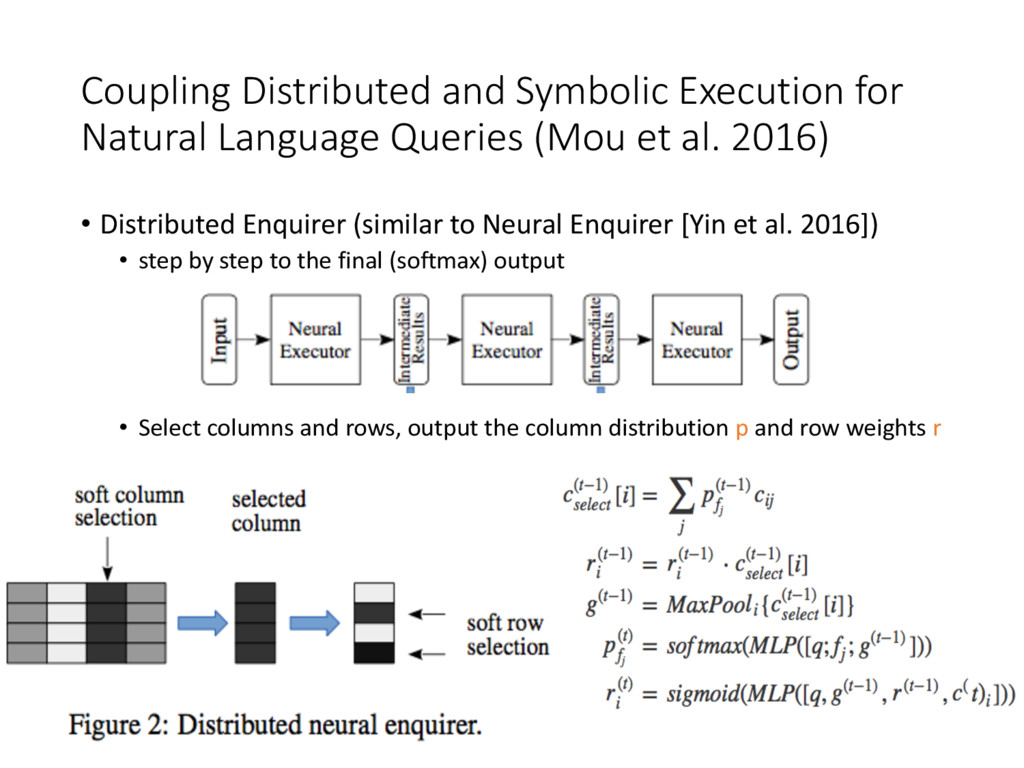
et al. 2016) • Distributed Enquirer (similar to Neural Enquirer [Yin et al. 2016]) • step by step to the final (softmax) output • Select columns and rows, output the column distribution p and row weights r
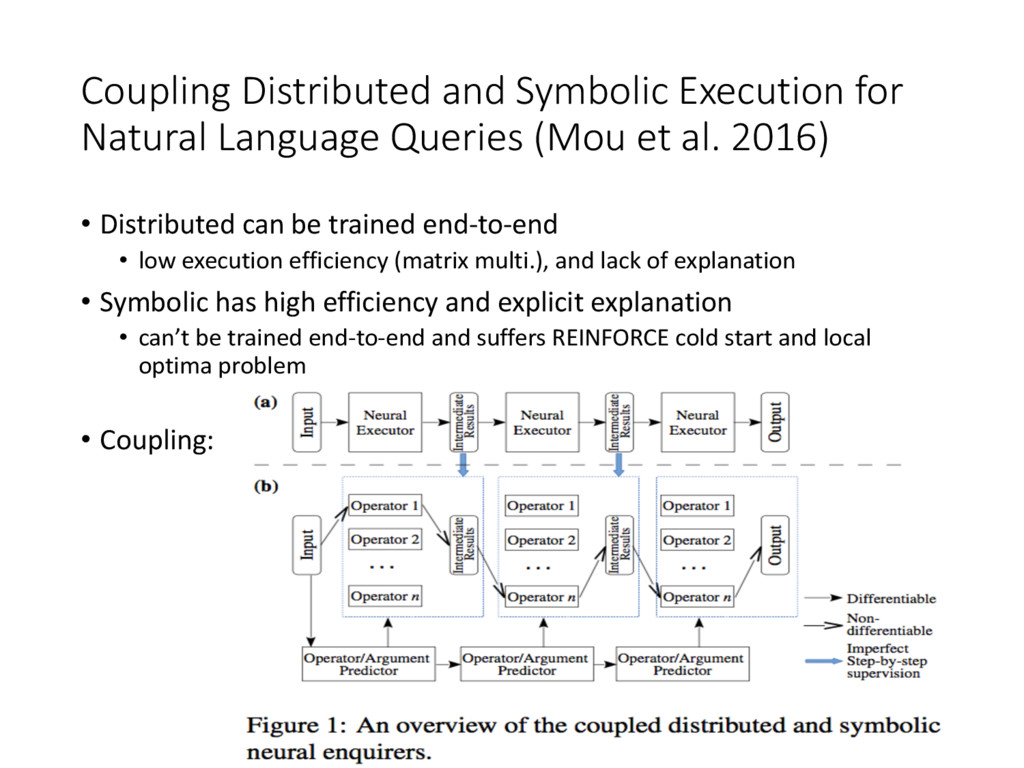
et al. 2016) • Distributed can be trained end-to-end • low execution efficiency (matrix multi.), and lack of explanation • Symbolic has high efficiency and explicit explanation • can’t be trained end-to-end and suffers REINFORCE cold start and local optima problem • Coupling:
Supervision • To use NN to language understanding and symbolic reasoning • complex operations • external memory • Existing neural program induction methods are • differentiable (Memory Network) • low-level (Neural Turing Machine) • limited to small synthetic dataset • The proposed MPC framework • non-differentiable • support abstract, scalable and precise operations
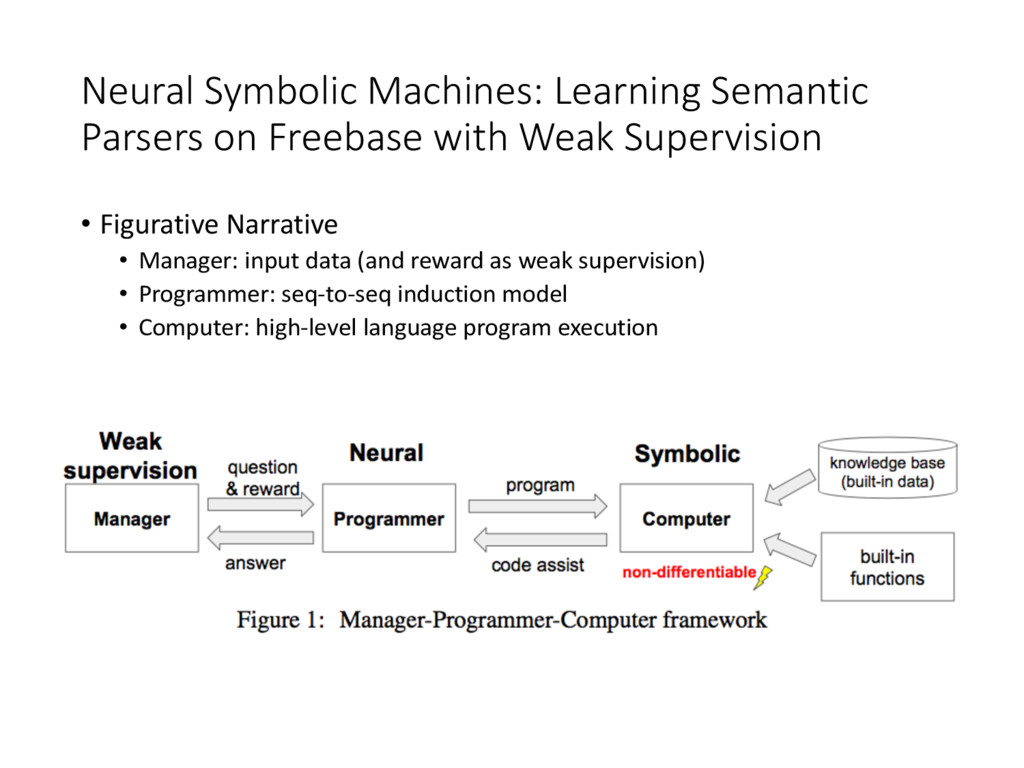
Supervision • Figurative Narrative • Manager: input data (and reward as weak supervision) • Programmer: seq-to-seq induction model • Computer: high-level language program execution
Supervision • Computer executes the programs consisting of LISP-style expressions • Code-Assistant: Computer will help Programmer with the restriction on the next token to be the set of valid tokens • ( -> Hop -> v, then the next token must be a relation reachable from v • similar to typing constraint in functional programming • another way is to induce derivations rather than tokens (Xiao et al. 2016)
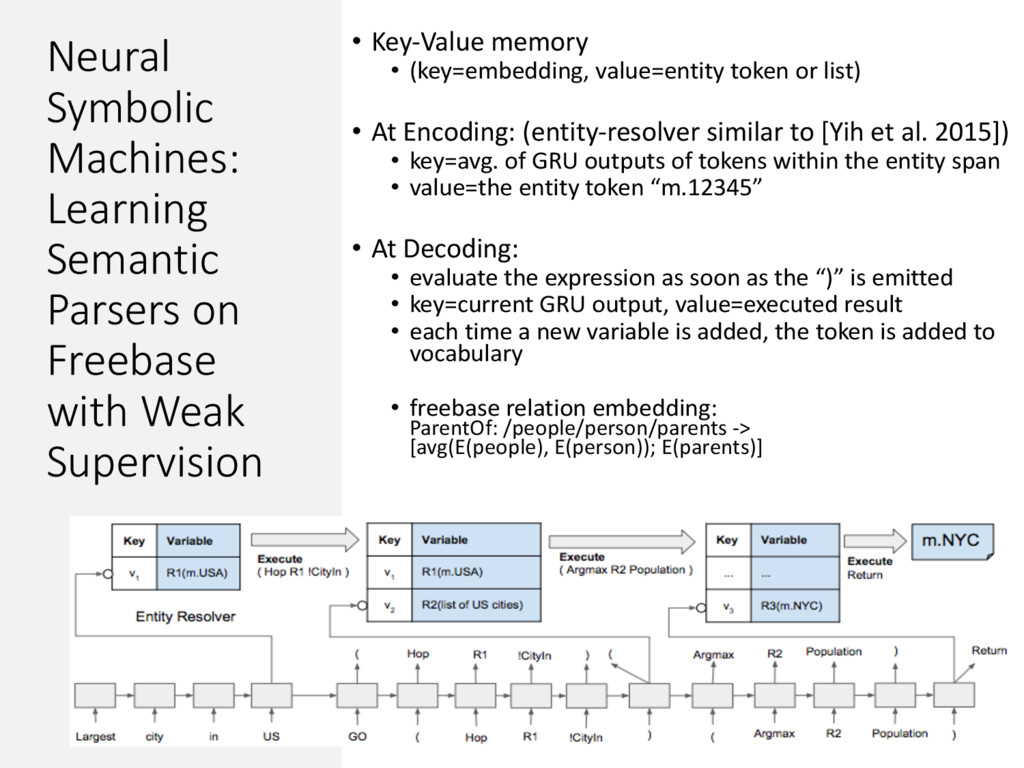
Supervision • Key-Value memory • (key=embedding, value=entity token or list) • At Encoding: (entity-resolver similar to [Yih et al. 2015]) • key=avg. of GRU outputs of tokens within the entity span • value=the entity token “m.12345” • At Decoding: • evaluate the expression as soon as the “)” is emitted • key=current GRU output, value=executed result • each time a new variable is added, the token is added to vocabulary • freebase relation embedding: ParentOf: /people/person/parents -> [avg(E(people), E(person)); E(parents)]
Supervision • Abstract: • Use Lisp-style expression rather than low-level operations • Scalable: • Executable on the whole freebase • Precise: • Use exact token rather than embeddings
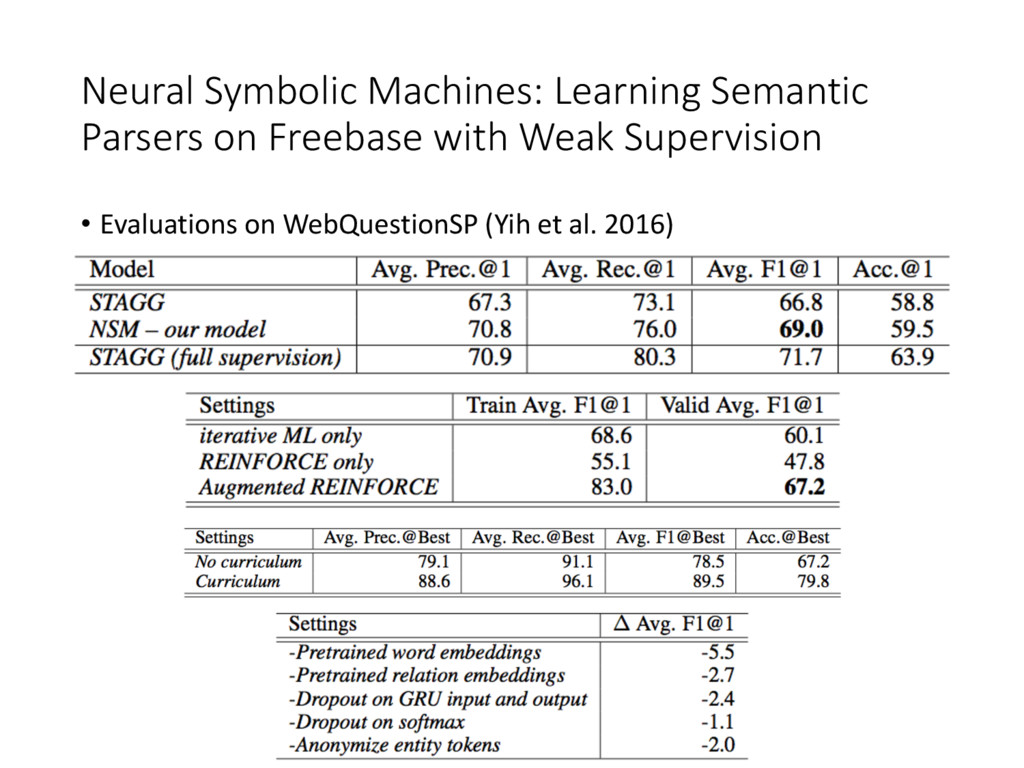
Supervision • Training with REINFORCE algorithm (Williams, 1992) • action: given tokens by the computer • state: question, and the action sequence up to now • reward: non-zero only at the last step • policy π(s, a, theta) = • environment is deterministic: • Loss:
Supervision • REINFORCE algorithm suffers from • local optimum problem • search space is too large • Find Approximate Gold Programs using maximum likelihood loss: • where is the program that achieved highest reward with shortest length on a question so far (question is ignored if no such program is found). • Drawback: spurious program (correct result with incorrect program), no negative examples make it hard to compute • Curriculum Learning (complexity: functions used, program length) • first 10 iterations for ML training, using only Hop function and length 2 • iterations again, using both Hop and Equal with length 3
Supervision • Augmented REINFORCE (similar to [Game of Go] and [Google MT]) • add to the final beam with prob. alpha=0.1 • others prob. = (1 - alpha) = 0.9
of real reasoning to some degree. • Combining neural networks with symbolic methods is promising • powerful • explicitly explainable • High-level operators can be designed to target the very task • better at scaling up, e.g. to the magnitude of freebase • Low-level operations can be reused for various tasks • Memory is essential for high-level operators to achieve expression composition
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}