本資料はSatAI.challengeのサーベイメンバーと共に作成したものです。
SatAI.challengeは、リモートセンシング技術にAIを適用した論文の調査や、
より俯瞰した技術トレンドの調査や国際学会のメタサーベイを行う研究グループです。
speakerdeckではSatAI.challenge内での勉強会で使用した資料をWeb上で共有しています。
https://x.com/sataichallenge
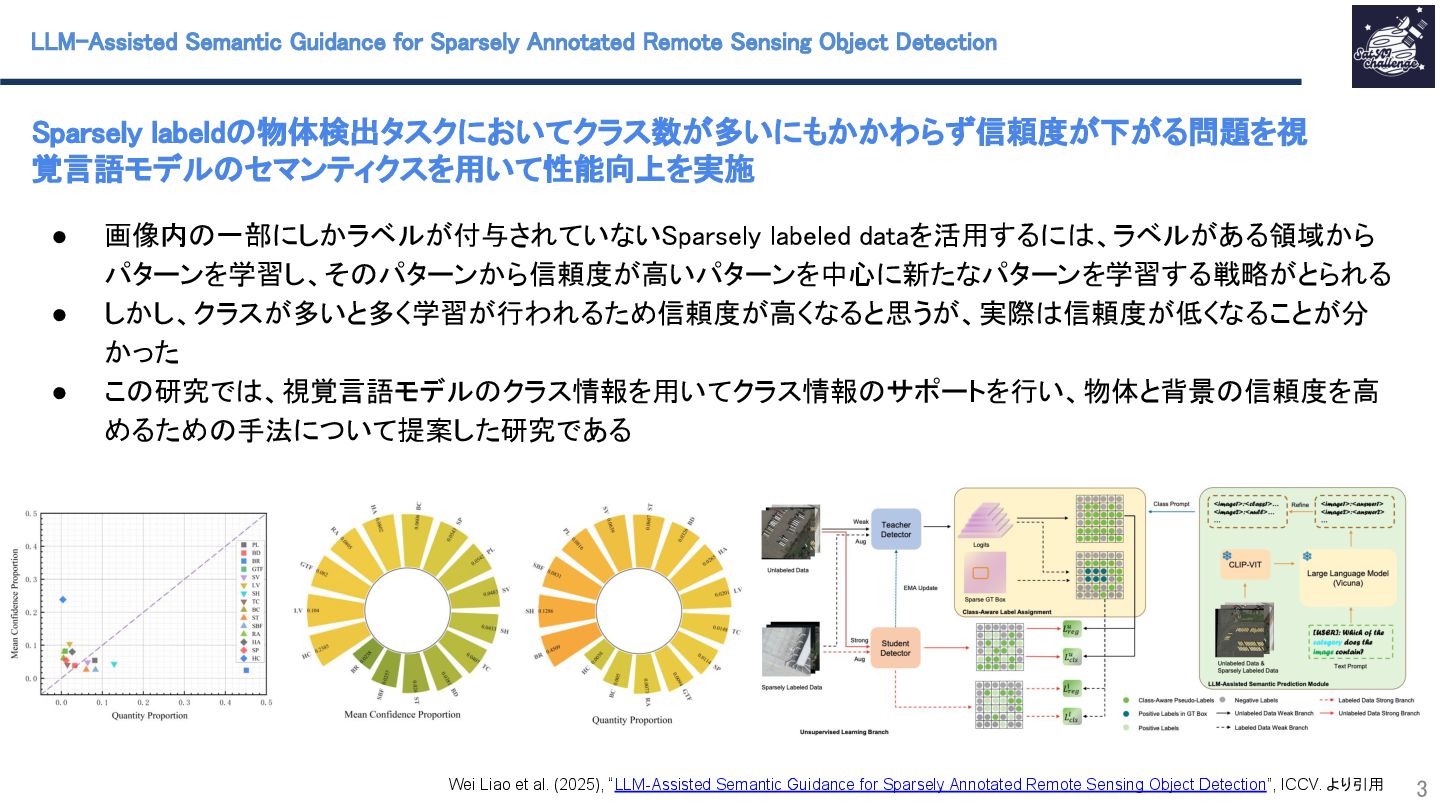
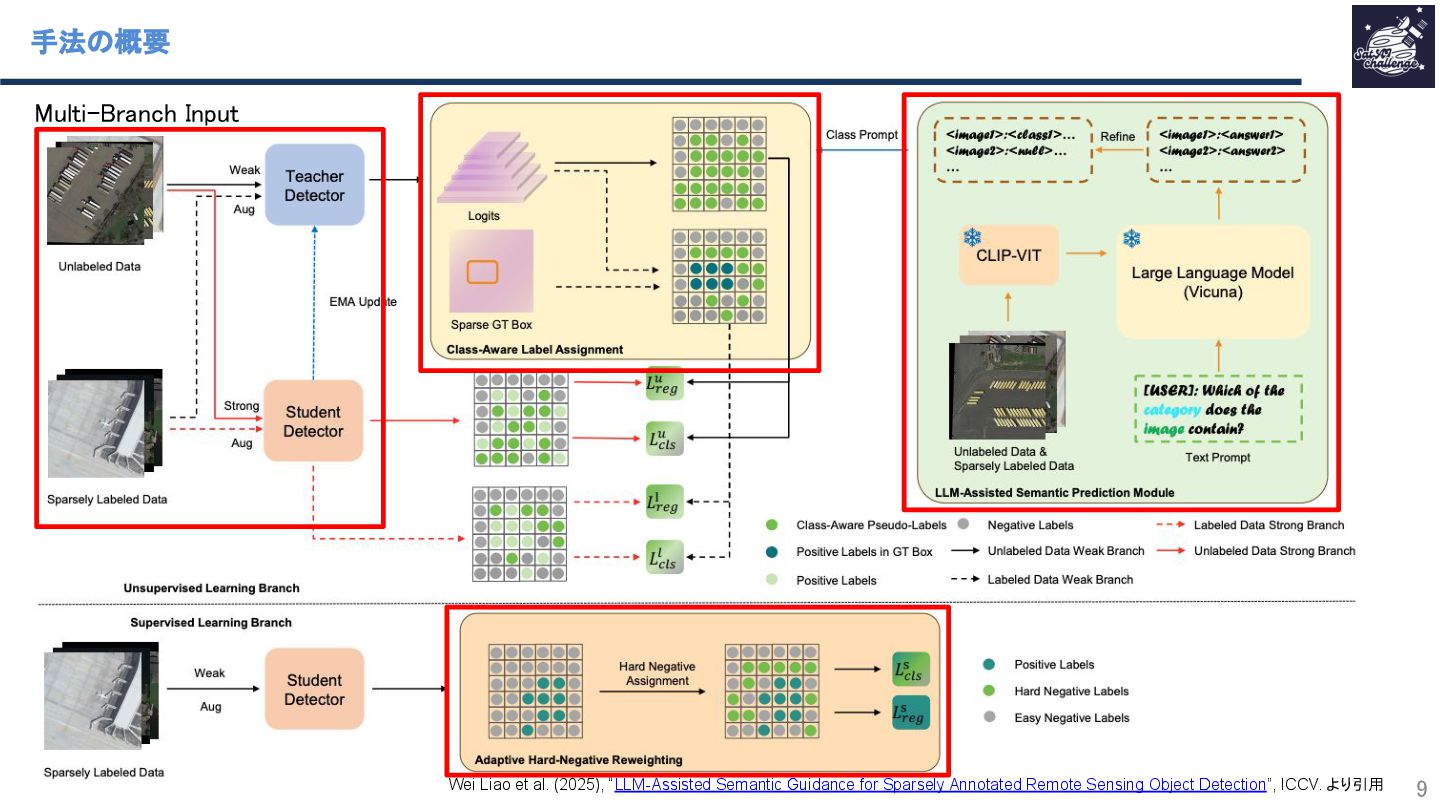
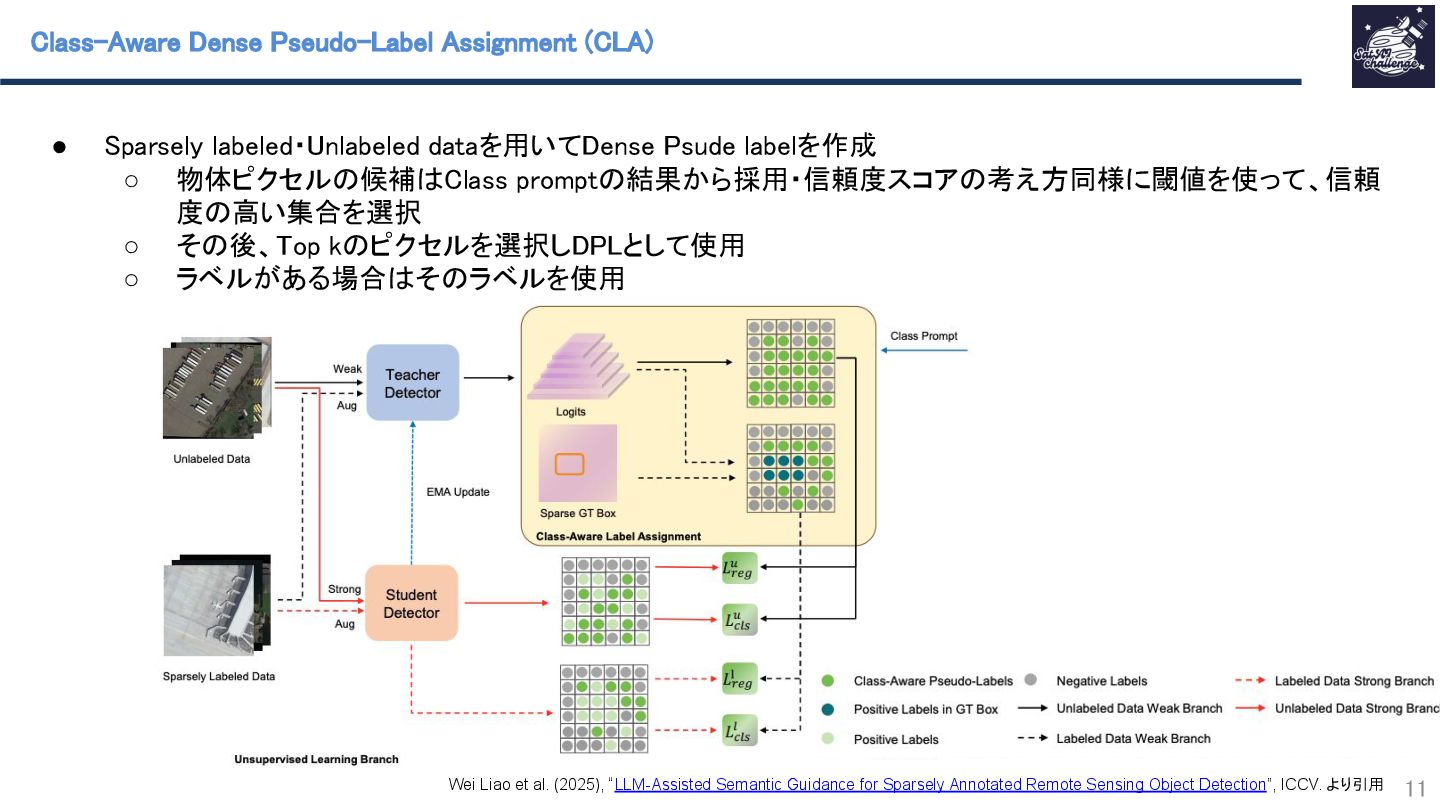
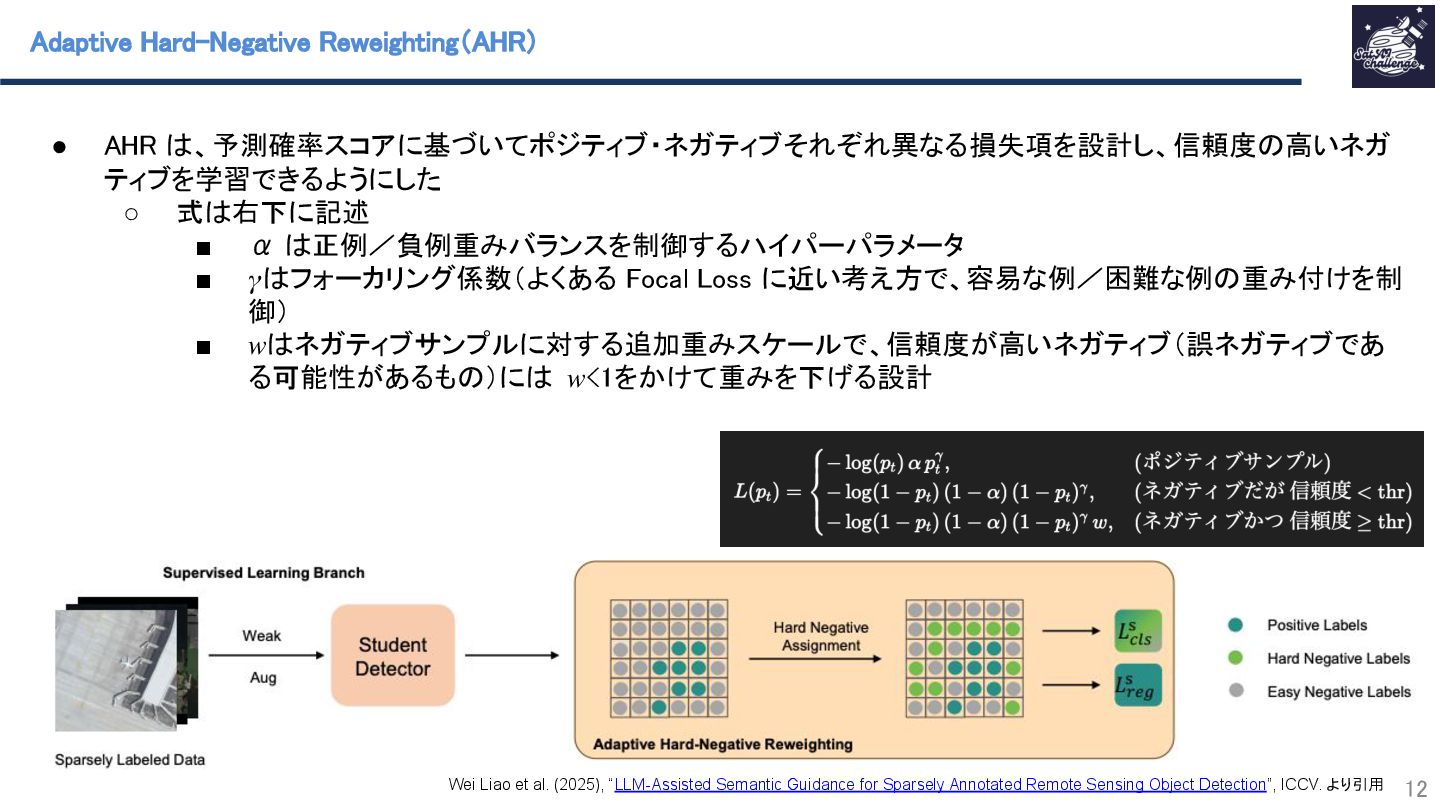
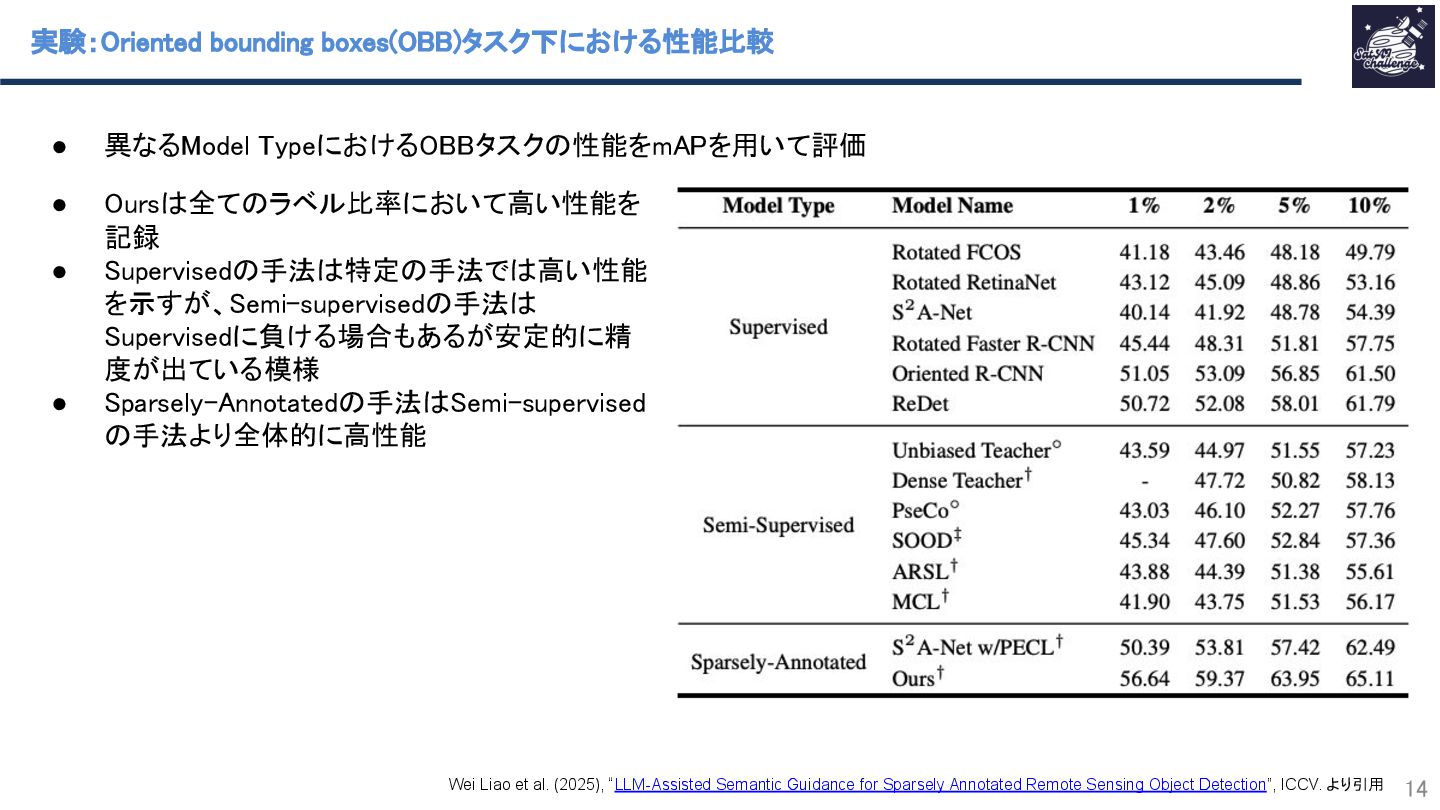
紹介する論文は、「LLM-Assisted Semantic Guidance for Sparsely Annotated Remote Sensing Object Detection」です。本研究では、衛星画像に付与されたラベル(バウンディングボックス)が一部欠損しているSparsely labeled dataの条件下を対象としており、その条件下で生じるラベル付けされたクラス数が多いにもかかわらず疑似ラベルの信頼度が低い問題に対処するために、視覚言語モデルのセマンティクスを利用することで性能改善を行った。その他にも半教師あり学習の疑似ラベル付与過程をSparsely labeled data向けに改善したマルチブランチインプット戦略や背景情報への信頼度向上のモジュールAdaptive Hard-Negative Reweightingも提案している。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
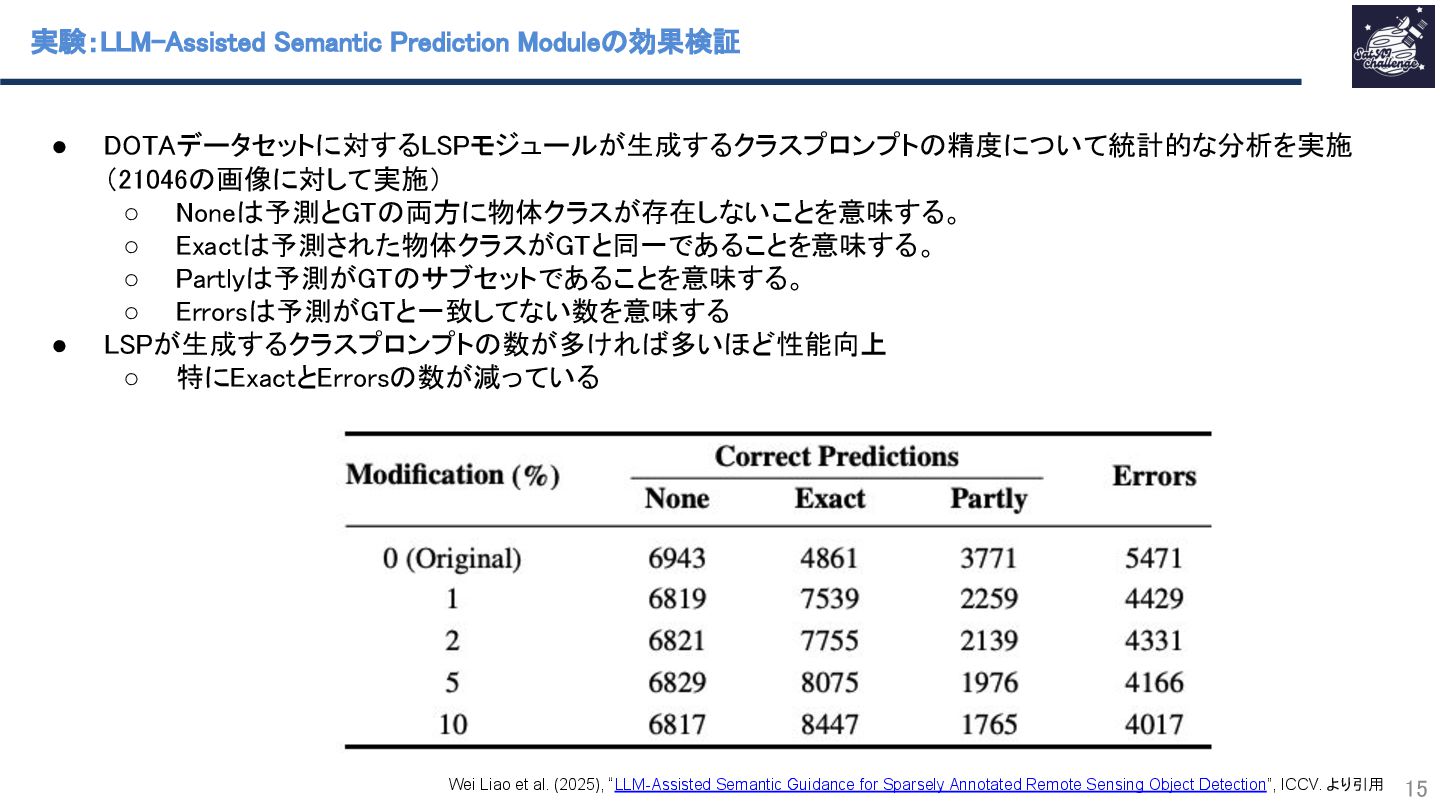{kind=link}
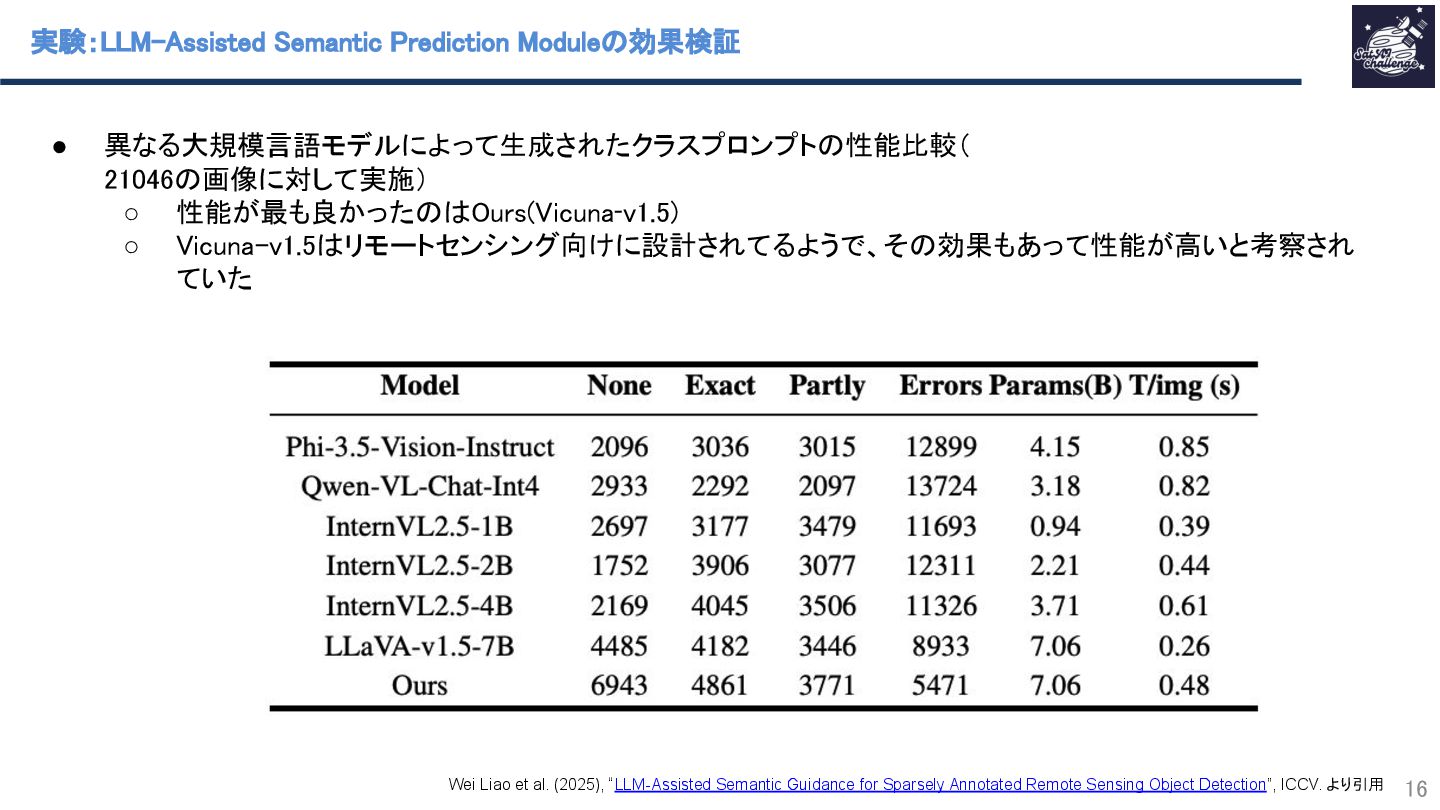{kind=link}
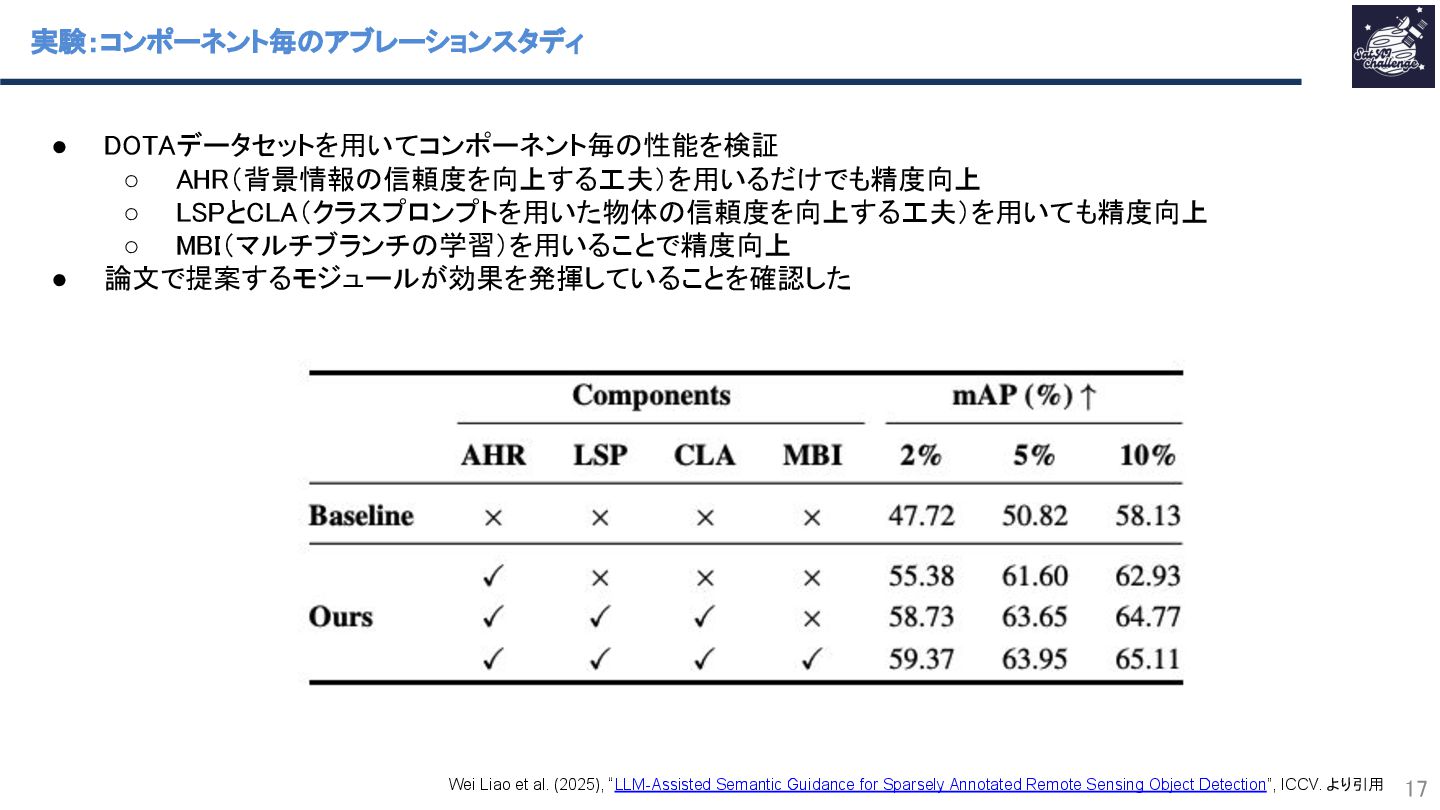{kind=link}
{kind=link}
{kind=link}