Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
データプロダクト開発の歩み
Search
10xinc
December 04, 2024
5.5k
5
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
データプロダクト開発の歩み
10xinc
December 04, 2024
More Decks by 10xinc
See All by 10xinc
ディメンショナルモデリングを支えるData Vaultについて
10xinc
1
380
プロダクト本部カジュアル面談資料
10xinc
0
600
dbtとAIエージェントを組み合わせて見えたデータ調査の新しい形
10xinc
7
3.4k
データエンジニアがこの先生きのこるには...?
10xinc
0
810
株式会社10X - Company Deck
10xinc
90
1.7M
dbt開発 with Claude Codeのためのガードレール設計
10xinc
2
8.5k
会社にデータエンジニアがいることでできるようになること
10xinc
11
8.5k
アセスメントで紐解く、10Xのデータマネジメントの軌跡
10xinc
2
2.4k
スーパーマーケットのこれまでとこれから
10xinc
6
13k
Featured
See All Featured
Mind Mapping
helmedeiros
PRO
1
290
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
Save Time (by Creating Custom Rails Generators)
garrettdimon
PRO
32
3.9k
Leadership Guide Workshop - DevTernity 2021
reverentgeek
1
330
svc-hook: hooking system calls on ARM64 by binary rewriting
retrage
2
380
For a Future-Friendly Web
brad_frost
183
10k
Believing is Seeing
oripsolob
1
170
How STYLIGHT went responsive
nonsquared
100
6.2k
Statistics for Hackers
jakevdp
799
230k
Utilizing Notion as your number one productivity tool
mfonobong
4
460
Testing 201, or: Great Expectations
jmmastey
46
8.2k
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
Transcript
©2024 10X, Inc. データプロダクト開発の歩み 2024/11/26 Yuta Yoshida
©2024 10X, Inc. 吉田 勇太(@yutatatatata) 2 株式会社10X/データプロダクトマネージャー 経歴: 株式会社ブレインパッドにてデータサイエンティスト(新卒から8年) →
現職(1年8ヶ月)
©2024 10X, Inc. 目次 3 1. 10Xのビジネスについて 2. データプロダクトとは 3.
10Xのデータプロダクトとは 4. データプロダクト開発の歩み 5. データプロダクトと品質 6. プロダクト開発とスクラム 7. データプロダクトとスキルセット 8. データプロダクトとデータ基盤
©2024 10X, Inc. 4 10Xのビジネスについて
©2024 10X, Inc. 小売チェーン向けECプラットフォーム「Stailer」 5 https://10x.co.jp/product/ 2020年5月 リリースなので 4歳半
©10X, Inc. All Rights Reserved. 6 お客様アプリ AIによる推薦や高精度の検索により数万点の SKUからスムーズに買い物ができる UX
主な機能 • 数万SKUから商品からスムーズにカゴを作成 • キーワード・カテゴリ検索・お気に入り・注文変更・購入履 歴といった基本機能 • 商品の受け取り方法を選択 • 注文状況・配達状況の確認や通知 • Web(オプションにて提供)
©2024 10X, Inc. 提供プロダクト スタッフアプリ • ピッキングリストを自動生成 • 移動距離最短化、複数スタッフに並行作業可能 •
バーコード照合でのヒューマンエラー防止をサポート • 多様な受け取り方法に対応 ミスが少なく効率的な 業務オペレーションシステムを提供 主な機能 7
©2024 10X, Inc. 提供サービス 商品・在庫ロジック 構築 マスタの半自動生成 店舗でのお買い物に限りなく近い品揃えを実現 半自動の商品在庫マスタ生成プロセスを提供し 欠品と運用コストを削減
データソース特定 データI/F開発 アルゴリズム開発 日別店別 在庫マスタ生成 発注データ 販売データ 廃棄データ 販促データ 店舗A 店舗B 店舗C 店舗D Stailerと つなぐ I/Fの開発 アルゴリズムの 開発 販促情報 発注周期 品揃除外 etc. 8
©2024 10X, Inc. 9 お近くにお店が あれば是非! • 1店舗から数百店舗まで • 地方スーパーから都市型
スーパーまで • 店舗型も倉庫型も さまざまな規模・形態の小売企業 に対してネットスーパーの”プラッ トフォーム”となるべくStailerの開 発改善を続けています 10Xが支援する小売企業は全国に広がる
©2024 10X, Inc. (余談)ネットスーパーについてよく聞かれること 10 >お店で買うより高いんでしょ? ◦ そんなことないよ!昨今の物価価格人件費高騰を受けて値上げしてるところもあ るけど、ほとんどは同じ値段だよ >配送料高いんでしょ?
◦ 2024年11月現在、そんなに高くないよ 大体300円とか ▪ (炎天下、子供連れ、重い荷物を運ぶ苦労と比べると…) >使えるエリア狭いんでしょ? ◦ まだどこでもとはいえないけど意外に使えるよ。特に都心部
©2024 10X, Inc. 10Xのビジネスモデル概要 11 • ネットスーパー/ネットドラッグストアの売上のうちの数%をいただく売上連動モデル ◦ +システム利用固定費 •
パートナーの売上が増えるほど10Xも儲かる! ◦ パートナーと10Xの両者のインセンティブが一致している ◦ アプリ構築で終わらず、売上を伸ばすための分析や施策立案も行う伴走型ビジネス パートナーの売上 10Xの収益
©2024 10X, Inc. 10XはBtoBtoCビジネス 12 10X 小売企業 (10Xでは、契約先の小 売企業様をパートナーと 呼んでいます)
ユーザー 関連記事: プロダクトビジョンとプロダクト方針の作成 - 10X Product Blog 「1人の難題を巨大な市場から解く。」 直接の顧客 ネットスーパーやドラッグストア 事業を継続的に運営できる手段 を提供 間接的な顧客 日常の買い物負担を減らし、買 い物を便利にする 使いやすいアプリを作る(toC)だけではなく、直接の顧客である小売企業の複雑な問題を解く(toB) B C B ネットスーパー・ ネットドラッグストアの 立ち上げと成長を支援 便利な買い物手段 の提供
©2024 10X, Inc. プロダクトチームとその業務領域 13 パートナー データ Stailer App 売場
画面 検索・ 推薦 売場チー ム お客様体 験チーム 商品デー タチーム 商品 データ 分析用 データ基盤 データ基 盤チーム 決済 お会計 チーム 配送 ピックパック お届け チーム リライアビリティ&セキュ リティチーム QA チーム 品質保証 9チーム 約40名のエンジニアで開発 店舗関連情報 サービス信頼性・セキュリティー 店舗チー ム ユーザー 店舗 所属しているところ。 今回はここの話が中心
©2024 10X, Inc. (補足)ネットスーパービジネスは何が難しい?1 14 業界的難しさ • 小売業は薄利多売の業界 ◦ 粗利益率が低く投資余力が限られる
◦ 特にIT, DX, AIへの投資。先行事例も少ないため意思決定が難しい • エネルギー価格高騰・円安進行による原価高騰のプレッシャー • 労働集約的な現場 ◦ パートタイムワーカーの依存度が高く、人材力不足が深刻化 ▪ 労働生産性改善が急務 • 一方で、電子決済やセルフレジ等、時代に合わせた対応への圧力も高い • 日本人の食へのこだわり。サービスへの要求レベルが高い。
©2024 10X, Inc. (補足)ネットスーパービジネスは何が難しい?2 15 技術的難しさ • 基幹システム・データが各社バラバラ ◦ そもそもネットスーパーをやる用のデータではない。必要なデータがあったりなかったり。
▪ 場合によってマニュアルデータで補完する必要もある ▪ データの種類も量もバラバラ • 現場判断で売価が常に変化する ◦ 臨機応変に売価を柔軟に変更する仕組みが必要。かつそれをどのようにデータマネージするか • 上記の理由により複雑なデータ変換を行うにもかかわらず、原則、1レコードの間違いも発生させてはい けないというデータ品質への厳しさ ◦ ex. 金額を間違って安く販売してしまうと赤字が出る ◦ ex. 金額を間違って高く販売するとユーザーから指摘がくる、対応コストがかかる ◦ ex. 在庫がないのに販売してしまうとユーザーへ代替え品などの電話連絡をするオペレーションコ ストが発生する ◦ そのような厳密なデータ変換をどのような技術構成で行うか、どのようにデータ品質をモニタリ ングしたり改善したら良いかのノウハウが少ない
©2024 10X, Inc. (補足)ネットスーパービジネスは何が難しい?3 16 現場の複雑さ、それをデジタルへ写像(DX)する難しさ • ネットスーパーのオペレーションは(愚直にやると)現場への負担が高い ◦ 注文された商品のピッキング・パッキング作業コスト、配送コストが必要。ペイできるか?
• 在庫管理がそもそも難しい。 ◦ じゃがいもは箱買いする。そこに何個入っているかはわからない。 ◦ 期限が迫った生鮮のいくつかが組み合わさって惣菜に変化したり ◦ 不定貫商品の在庫管理をどうするか ◦ 電子機器(amazon等)やアパレル(ユニクロやzozo等)は管理コストを払っても採算が取れる。一方 で、「白菜一個」の管理を電子タグ等で追跡したいかというと…? • 在庫管理の重要さに濃淡がある ◦ 日配や缶詰などの賞味期限が違う話 ▪ 日配(牛乳・卵などの毎日売れるもの。賞味期限が短いもの)管理する前にさっさと並べて さっさと売る圧力が強い • 毎日売れて毎日発注するなら厳密な在庫数はわからなくても困らない ▪ 缶詰は売れなくても長く棚に並べておく。過剰に在庫は持ちたくないので在庫管理しておきたい
©2024 10X, Inc. (補足)不定貫商品 17 • 重量や数量が変化し、それによって価格も変わる商品のこと ◦ 量り売りの肉や魚など •
単価(gあたり金額) x 量目(内容量) で金額が決定される • 量目は現場で臨機応変に決まる ◦ 肉は決まった重さで切れても、魚は”1匹単位”で売る 等 • 量目によって販売価格が変わるため、在庫管理が複雑になる ◦ 520gの鶏肉が1つ、310gの鶏肉が1つ、... と在庫管理する意味はあるか?
©2024 10X, Inc. 18 データプロダクトとは
©2024 10X, Inc. データプロダクトとは 19 19 • Data as a
Product / データを製品(プロダクト)のように開発する という考え方 • その考えで作られた成果物(ソリューション・アプリケーション)がデータプロダクト • 「製品のように」とは ◦ 単なるデータの管理や提供を超え、製品開発に準じた視点やプロセスをデータ 管理に適用する ▪ 品質保証 • ex. データに対するテストやモニタリングの実施 ▪ 保守性改善 • ex. データパイプラインの継続アップデート、保守運用 ▪ etc…
©2024 10X, Inc. データプロダクトの5つのタイプ 20 20 データプロダクトはデータを元にしたソリューション、アプリケーション。 昨今はデータの価値発揮先が増えており、故に様々な形態が存在。 考える コスト
小 大 データプロダクト 例 データを使って最終的な目標を達成することを 第一の目的とする製品 人間とのインターフェース 生データ 派生データ アルゴリズム 意思決定の支援 意思決定の自動化 データウェアハウス ビジネスの主要 KPIを視覚化する 企業ダッシュボード 自動運転 SQL 可視化 Visualization 車 「Data as a Product vs data products. What are the differences?」の内容を図示 , 発表者が一部加筆
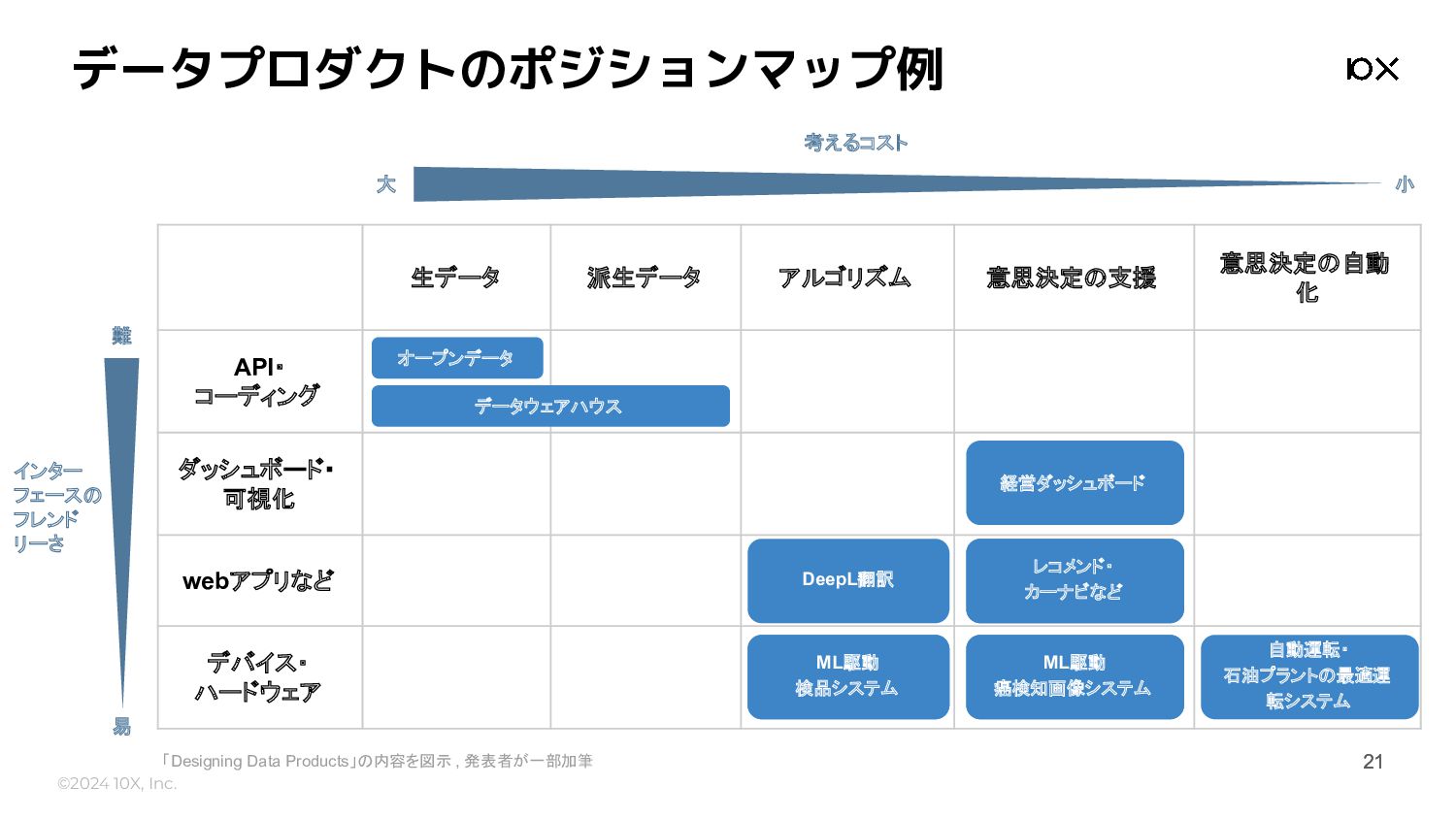
©2024 10X, Inc. データプロダクトのポジションマップ例 21 21 「Designing Data Products」の内容を図示 ,
発表者が一部加筆 生データ 派生データ アルゴリズム 意思決定の支援 意思決定の自動 化 API・ コーディング ダッシュボード・ 可視化 webアプリなど デバイス・ ハードウェア インター フェースの フレンド リーさ 易 難 考えるコスト 小 大 オープンデータ データウェアハウス 経営ダッシュボード レコメンド カーナビなど レコメンド・ カーナビなど DeepL翻訳 ML駆動 検品システム ML駆動 検品システム ML駆動 癌検知画像システム ML駆動 癌検知画像システム 自動運転・ 石油プラントの最適運 転システム
©2024 10X, Inc. (余談)プロダクトの方向性 生データ 派生データ アルゴリズム 意思決定の支援 意思決定の自動 化
API・ コーディング ダッシュボード・ 可視化 webアプリなど デバイス・ ハードウェア インター フェースの フレンド リーさ 易 難 考えるコスト 小 大 オープンデータ データウェアハウス 企業ダッシュボード レコメンド カーナビなど レコメンド カーナビなど DeepL翻訳 ML駆動 検品システム ML駆動 検品システム ML駆動 癌検知画像システム ML駆動 癌検知画像システム 自動運転 石油プラントの最適運 転システム ソフトウェアビジネス化 AIビジネス化 22 「Designing Data Products」の内容を図示 , 発表者が一部加筆 「何も考えなくても簡単に扱える」方向へ。これはデータプロダクトでも変わらない
©2023 10X, Inc. 23 10Xのデータプロダクトとは
©2024 10X, Inc. 商品データチームがつくっているデータプロダクト(の生成物) 24 商品カテゴリー セールス種類 商品画像 商品名 金額(税率)
当該店舗の 在庫数量 商品説明文 「商品データ」と呼ばれる どの商品が、いつ、どの店舗に、いくらで、何個あるか を 全パートナー、全店舗、全商品で、毎日生成🛒 1店舗だけで数万種類の商品! 関連記事: ネットスーパーの要!?あなたの知らない「商品マスタ」の世界 - 10X Blog
©2023 10X, Inc. データ処理 by パートナー個社データ (input) 商品データ (output) ユーザー
Stailer App (Dart) アプリに載せる ・ ・ ・ A社 基幹データ X社 基幹データ A社 商品データ X社 商品データ Data Product (BigQuery with dbt) X社の ネットスーパーアプリ 商品データチームのデータプロダクト超概要
©2024 10X, Inc. (補足)dbt; data build tool とは 26 •
データエンジニアリングやデータ分析のプロセスを効率化するために設計されたOSS • 主にデータウェアハウス上でのETL(Extract, Transform, Load)プロセスの中で、特に 「T(Transform)」の部分を担う • 同じチームの @takimoさん が日本コミュニティーの立ち上げと運営を行っている with hoge as (...), fuga as (...), …. 以後50個くらいのCTE句 1000行くらいの.sql🤮🤮🤮 source_1 source_2 source_3 logical_a logical_b mart_x dbtなら データソースの処 理層 クレンジングや ロジックの処理層 完成品のデータ マート層 - モデルとして関係性を表現(データモデリング)でき、かつモデル感の依存関係も 自動で可視化 - モデルごとにテストを実施し、データやロジックの妥当性の検証も可能 - gitで管理できる 例えば、 関連記事: dbt日本コミュニティの立ち上げと10Xでdbtの実践を行った2022 - SpeakerDeck dbtを使ったELTデータパイプライン構築と運用事例 - SpeakerDeck
©2023 10X, Inc. データ処理 by パートナー個社データ (input) 商品データ (output) ユーザー
Stailer App (Dart) アプリに載せる ・ ・ ・ A社 基幹データ X社 基幹データ A社 商品データ X社 商品データ Data Product (BigQuery with dbt) X社の ネットスーパーアプリ ① 商品・在庫数等のデータを受領して 商品データチームのデータプロダクト超概要
©2023 10X, Inc. データ処理 by パートナー個社データ (input) 商品データ (output) ユーザー
Stailer App (Dart) アプリに載せる ・ ・ ・ A社 基幹データ X社 基幹データ A社 商品データ X社 商品データ Data Product (BigQuery with dbt) X社の ネットスーパーアプリ ① 商品・在庫数等のデータを受領して ② dbtで整理・変形・計算 商品データチームのデータプロダクト超概要
©2023 10X, Inc. データ処理 by パートナー個社データ (input) 商品データ (output) ユーザー
Stailer App (Dart) アプリに載せる ・ ・ ・ A社 基幹データ X社 基幹データ A社 商品データ X社 商品データ Data Product (BigQuery with dbt) X社の ネットスーパーアプリ ① 商品・在庫数等のデータを受領して ② dbtで整理・変形・計算 ③ 整理された商品データを出力 商品データチームのデータプロダクト超概要
©2023 10X, Inc. データ処理 by パートナー個社データ (input) 商品データ (output) ユーザー
Stailer App (Dart) アプリに載せる ・ ・ ・ A社 基幹データ X社 基幹データ A社 商品データ X社 商品データ Data Product (BigQuery with dbt) X社の ネットスーパーアプリ ① 商品・在庫数等のデータを受領して ② dbtで整理・変形・計算 ③ 整理された商品データを出力 ④ データをアプリに載せる 商品データチームのデータプロダクト超概要
©2024 10X, Inc. dbt部分をもう少し詳しく 31 10X BQ (source data) 基幹データ
マニュアルデータ gateway doman service application DataYard(と呼んでいる) DataExpress(と呼んでいる) input Data Product output 各パートナー独自の要件を 吸収するレイヤー ネットスーパー構築に必要な ドメインデータをここで作る どんなデータをどんな粒度で 作るかがポイント ドメイン層以降は全パートナー で共通の処理を行い商品データ を完成させる dbtで4つのレイヤー構造を作り、開発の効率化を行っている。 アプリで表示する ためにFirestoreに 格納
©2023 10X, Inc. ネット 店舗売場での創意工夫で魅力的な購買体験をお届け 売場業務を再現するために必要なデータ整理を行うこと・柔軟性を持つことが重要 基幹データ 任意の特集やセールも 臨機応変に実施できるよう にする
リアル 店舗 商品データはネット上の「売場」を構成する 商品データ 32
©2023 10X, Inc. 生データ 派生データ アルゴリズム 意思決定の支援 意思決定の自動 化 API・
コーディング ダッシュボード・ 可視化 webアプリなど デバイス・ ハードウェア インター フェースの フレンド リーさ 易 難 人間の考えるコスト 小 大 オープンデータ データウェアハウス 企業ダッシュボード レコメンド カーナビなど レコメンド・ カーナビ DeepL翻訳 ML駆動 検品システム ML駆動 検品システム ML駆動 癌検知画像システム ML駆動 癌検知画像システム 自動運転・ 石油プラントの最適運 転システム dbtによるスケーラブルな データ処理パイプライン 推薦アルゴリズム等 「Designing Data Products」の内容を図示 , 発表者が一部加筆 (余談)10X商品データプロダクトのポジション
©2023 10X, Inc. データ処理 by パートナー個社データ (input) 商品データ (output) ユーザー
Stailer App (Dart) アプリに載せる ・ ・ ・ A社 基幹データ X社 基幹データ A社 商品データ X社 商品データ Data Product (BigQuery with dbt) X社の ネットスーパーアプリ ① 商品・在庫数等のデータを受領して ② dbtで整理・変形・計算 ③ 整理された商品データを出力 ④ データをアプリに載せる 10X商品データプロダクトの特徴 作成したデータがほぼそのままユーザーに提示されるところ (プロダクションに直結している!!) 34
©2023 10X, Inc. デジタル上の売場そのものなので 現場からも厳しいチェック 売上にも直結するため データ品質が非常にシビア 商品情報の多さ = 売場の充実度
(商品の多さ、欠品具合)となり、 ユーザー体験に大きく影響する。 商品データ パートナー目線 ユーザー目線 商品データはネット上の”売場”そのもの。故に厳しい 35
©2024 10X, Inc. この章のまとめ 36 36 • データプロダクトと呼ばれる新しい開発領域について概要説明 • 10Xではデータプロダクトとして「商品データ」を作成している
• 商品データのデータプロダクトでは、dbtでレイヤ構造化させたデータモデリングを行っ ている • このパイプラインで作成したデータはプロダクションに直結している • 商品データは直接ユーザーが触るものであり、間違いがあるとパートナー(小売企業) にも損害がでるため非常にシビアである
©2024 10X, Inc. 37 データプロダクト開発の歩み
©2024 10X, Inc. パートナーローンチの歴史 38 2020 2022 サイトコントローラー による操作 アプリケーション
コードの中でSQL 実行 データモデリング での実装 dbtで実装 DataExpress世代 38 Stailer native 第4世代 サイトコントローラー時代 Stailer native 第1世代 Stailer native 第2世代 Stailer native 第3世代 DataExpressの誕生 ※ドラッグストアは 紫枠 2021 2023 アプリのリリース時期でマッピング
©2024 10X, Inc. 最初はサイトコントローラーから始まった 39 39 2020 2023 2021 2022
データ受領は行っておらず、サイト コントローラーによって先方サービ スを操作。商品データは作成してい なかった。 • 10X社の最初のサービス”タベリー”(現在はサービス終了) では、献立の提案をし、その食材を小売流通企業のネット スーパーでシームレスに注文できた • 当時、ネットスーパーへの注文はサイトコントローラーで 行われており、10Xが直接データをもっていたわけではない • アプリリリースの了承を取るために小売流通企業に訪問。 タベリーのシステムを評価され、公式のネットスーパーアプ リ作成を正式に受注 ◦ これが現在のStailerへ繋がる サイトコントローラー時代 https://x.com/tabelyapp 関連記事: タベリーからStailerへ - 10X Blog
©2024 10X, Inc. (補足)サイトコントローラーとは 40 40 • Stailerアプリで操作すると、裏側で公式のweb画面を操作して買い物を完了させる仕組み • スクレイピングは情報収集、サイトコントローラーは操作・管理が目的
◦ スクレイピングと違って、直接決済まで行うところなどが大きな違い • 代表的なものは宿泊予約まとめサイト、飛行機価格比較サイトなど • 操作先のサイト構造が変わると動かなくなるので大変 https://everyday-fresta.jp/ パートナー公式のwebサイトに対し、 10Xがサイトコントローラーで決済まで 操作するという仕組みだった
©2024 10X, Inc. 基幹データを受領し、Stailer nativeで駆動 41 41 2020 2023 2021
2022 当時はDartコードの中でSQLを実行し商品データを操作していた (の仮サンプル) • 初めてのstailer nativeへ ◦ サイトコントローラーではなく、パートナー(のベンダー) から基幹データを10X GCPへデータ連携してもらい、その データを処理してStailerを動かす ◦ 100店舗分を超えるデータ量を捌く必要があった • スーパーだけではなくドラッグストアでもStailerを展開 ◦ 医薬品のネットでの販売ルールなど、新たな専門知識が必要 になる Stailer native 第1世代
©2024 10X, Inc. (補足)StailerはFlutter(Dart)で動いている 42 42 • StailerはFlutterというモバイルアプリ用のフレームワークで開発されており、FlutterはDartで書く • Flutterは
iOS/Androidの両方にコンパイルできるメリットがある ◦ OS毎に開発チームを作らなくて良い。開発者が少ない組織にはメリット 関連記事: 「なぜDartなのか」CTO石川が技術選定に込めた想いとその背景 - 10X Blog
©2024 10X, Inc. dbtを採用し商品データ作成ロジックを分離する 43 43 2020 2023 2021 2022
• 通常、データ変換をそれほど行わない場合はアプリケーション コード(10Xではdart)の中でSQLを書いてデータを呼ぶことは それほど珍しいことではない(らしい) • 商品データ作成に複雑なデータ変換が必要となることを当時は予 期していなかった • SQLでのデータ変換に加え、Dartでも一部データ変換のロジック を作っていたので至る所でデータ変換ロジックが散らばり、この 後、変更・保守が難しくなっていった • これを改善するため、商品データ作成部分の実装を Dart + SQL から dbt に変更 ◦ 商品データに関するデータ変換は dbt にロジックを寄せる ◦ dbtが作成したデータマートを Dart は呼ぶだけにした (Dartでのデータ変換は行わない) • dbtが生成したデータがサービスプロダクションに直結している (直接ユーザーが触るデータになる)はまだ事例が少ない Stailer native 第2世代 これまでの実装の知見を生かしつつ 開発を進めるが、まだ各パートナー 毎にスクラッチで作っていた
©2024 10X, Inc. データモデリングの導入 44 44 2020 2023 2021 2022
Stailer native 第3世代 gateway, domainなどのレイヤー 構造の採用 開発者を増やすのではなくモデリ ングを洗練させる方針へ • パートナー実装を繰り返すことで、ネットスーパーで求められ る共通機能がわかってきた(ドメイン知識が溜まってきた) • それを生かしてパートナー共通のドメインを定義し、データモ デリングを始める ◦ gateway層やdomain層ができ始める • ドメインが定まることでパートナーに請求すべき受領データも 定まってきた ◦ 無秩序に基幹データを受領するのではなく、実現したい ロジックを元に事前にパートナー側(のベンダー)に データを作成してもらいそれを10Xが受領することで下 流での複雑な変換を減らす ◦ 体感で従来の1/10くらいの労力でローンチできるパート ナーが出始める
©2024 10X, Inc. dbt部分をもう少し詳しく 45 10X BQ (source data) 基幹データ
マニュアルデータ gateway doman service application DataYard(と呼んでいる) DataExpress(と呼んでいる) input Data Product output 各パートナー独自の要件を 吸収するレイヤー ネットスーパー構築に必要な ドメインデータをここで作る どんなデータをどんな粒度で 作るかがポイント ドメイン層以降は全パートナー で共通の処理を行い商品データ を完成させる dbtで4つのレイヤー構造を作り、開発の効率化を行っている。 アプリで表示する ためにFirestoreに 格納 ここができた 再掲
©2024 10X, Inc. DataExpressの誕生とローンチの高速化 46 46 2020 2023 2021 2022
• ドメインの理解が深まってきた。処理を更に抽象化し、パートナー共 有処理部分は社内パッケージ化した(”DataExpress”と命名) ◦ ドメイン層ができれば後はDataExpressに流すだけになるまで 実装が効率化。 ◦ DataExpressをパッケージバージョン管理し、プラットフォー ムとしての機能はここに入るようにする • 受領データフォーマットを作成し、データ受領工程の圧縮 • ここまでの改善の成果として、半年ほどで一気に6パートナーをリリー スできるまでに Stailer native 第4世代 DataExpressの誕生
©2024 10X, Inc. パートナーローンチの歴史 47 2020 2022 サイトコントローラー による操作 アプリケーション
コードの中でSQL 実行 データモデリング での実装 dbtで実装 DataExpress世代 47 Stailer native 第4世代 サイトコントローラー時代 Stailer native 第1世代 Stailer native 第2世代 Stailer native 第3世代 DataExpressの誕生 ※ドラッグストアは 紫枠 2021 2023 再掲
©2024 10X, Inc. この章のまとめ 48 48 • 最初期はサイトコントローラーによって商品購入を実現していた • データが受領できるようになり、Dart
+ SQL で商品データを作成していた • ロジックが複雑化したため、dbtを導入し、商品データロジックとアプリケーションコー ドを分離した • 複数パートナーのローンチを繰り返すことで、必須の機能/個別のニーズがあぶり出され ていき、ドメイン知識が蓄積された。 • それを元にデータモデリングが進み、処理が抽象化されることで開発効率が上がった ◦ DataExpressという共通処理パッケージも作成 • 現在は13パートナー様の商品データパイプラインを運用・改善していっている
©2024 10X, Inc. 49 データプロダクトと品質
©2024 10X, Inc. パートナーローンチの歴史 50 2020 2022 サイトコントローラー による操作 アプリケーション
コードの中でSQL 実行 データモデリング での実装 dbtで実装 DataExpress世代 50 Stailer native 第4世代 サイトコントローラー時代 Stailer native 第1世代 Stailer native 第2世代 Stailer native 第3世代 DataExpressの誕生 ※ドラッグストアは 紫枠 2021 2023 2024年以降は? 再掲
©2024 10X, Inc. 必ずぶち当たる”品質”問題 51 51 • ローンチラッシュを超える • それにより10を超えるパートナーの運用と保守が始まる
• 各パートナーからの問い合わせが開発チームに寄せられる ◦ 商品データの価格 / 在庫数が期待と違う ◦ 売場に出てほしい商品がない / 期待外の商品が出ている ◦ マニュアルデータを入稿したら意図しない状態になった etc • バグ修正も、業務委託メンバーからのPRレビューも追いつかない • 直しても他のところが壊れる...直してもデグレ直してもデグレ直しても...
©2024 10X, Inc. なぜそんなことになったのか 52 52 • スタートアップでは「リリースすること」が至上命題になりがち ◦ リリースしないことには何も始まらないから
◦ サービスを動かしてキャッシュインを早めないとキャッシュがなくなるから ◦ パートナーからの期待とプレッシャー。「動くものを早く見たい」「可能な限り早くリリースしたい」 ◦ サービスを動かすことで改善のPDCAを回す思想 • 故に、「チームで」というより「各個撃破」スタイルで仕事を最短で完了させるスタイルになる
©2024 10X, Inc. 一人一殺開発 53 53 • 「各人が各個撃破しながらタスクをこなす」開発スタイルを 一人一殺開発 と(最初は冗談交じりに)言っ
ていた ◦ 1パートナーの実装を1人が最初から最後まで担当 ◦ 属人的なやり方の積極採用 • 「とにかく動くものを早く作る」ことが最優先の現場で登場する
©2024 10X, Inc. (余談)スタートアップと一人一殺開発の引力 54 54 • スタートアップが行うプロダクト開発では、世の中にまだ「だいたいこれが正解」というプロダクトがない • その場合、「何を作るべきか」「どう作るか」を作りながら理解する側面が強い
• 「早く探索する」「動くものを作る」ことが最優先の現場と ”一人一殺開発” は相性が良い ◦ いい意味でプロフェッショナルなシニア人材の自律性をフルに使う
©2024 10X, Inc. 55 • DataExpressを開発し、どのメンバーでも比較的短期でローンチできる仕組みを構築 • 各メンバーが一人一殺し、短期間に複数パートナーを並行ローンチ • 型化を進め、業務委託メンバーだけの工数で実装/ローンチする快挙も達成
一人一殺開発がうまくいっているときもあった
©2024 10X, Inc. • 「最短で動くものを作る」ことを最優先(トレードオフ)したため品質/保守性が犠牲になった • 各メンバーが自身が担当したパートナー以外の仕様/実装を詳細には把握できていない 56 一人一殺の先に待っていたプロダクトの状態
©2024 10X, Inc. 57 全員が別々のことを やっているので、お互いが 順調なのか遅れているのか 分からない 進捗確認は、「間に合いそ うか」「依頼されたバグは
直ったか」のみ 振り返りも「お互い大変だね」と ねぎらう場になり共通の学びが 得られづらい 朝会も振り返りも 欠席者が増える スクラムとデッドライン壊れゆくチームをつなぎとめるもの/Scrum and Deadlines - Speaker Deck 一人一殺の先に待っていたチームの状態
©2024 10X, Inc. 58 • 商品データチームの品質問題が事業成長のボトルネックに • チームではなく、「個人事業主の集まり」状態 ◦ 「チームで仕事している意味がない」
◦ 「個人の専門性を全く活かせていない」 結果、2023年末の状態
©2024 10X, Inc. 59 • 何を壊すかわからなくて、怖くてコードを触れない • 仕様が不明瞭なので真っ当なレビューができない • チームで問題を話そうにも途方もなさすぎる
• ヘルプも厳しい。全員が各自対応をしていて余裕がない • タスクをコントロールできていない。場当たりで対応しているだけ感 自分もかなり参っていた
©2024 10X, Inc. 60 プロダクト開発とスクラム
©2024 10X, Inc. 61 スクラムとデッドライン壊れゆくチームをつなぎとめるもの/Scrum and Deadlines - Speaker Deck
年明けに流れてきたスライド
©2024 10X, Inc. 62 俺達の話か?というほど ほぼそのまんまだった スクラムとデッドライン壊れゆくチームをつなぎとめるもの/Scrum and Deadlines -
Speaker Deck
©2024 10X, Inc. 63 • 完全に「開発アルアル話」の一つだとわかった ◦ つまり、世の中に解決方法がある • どうやらそれは『スクラム』というらしい
◦ 藁にも縋る思いで、必要に迫られて始まった ここからでも逆転する方法があるんですか ?!
©2024 10X, Inc. プロダクト品質を改善するには? 64 64 - 属人的な解決方法ではプロダクトはスケールしない。チームで問題を認識し、継続的な改善アクションを中 長期のスパンで積み重ねないとスケールしない -
我々のチームにおいては、 - 「実装者しか知らない知識」を如何にして「チームの知識」にするか - 「実装した人がそのパートナーの担当」という「実装者の持ち物化してしまったもの」を如何に 「チームの持ち物」にするか - ソフトウェア開発の文脈では「スクラム開発」という便利な方法論がすでに存在している - どのようにチームのタスクを決定するか - どのようにチームの進捗を管理するか - どのようにチームとして知見を得てoutcomeに繋げるか - チームにユビキタス言語の浸透、開発のコンテクストの浸透をどのように行うのか - どのようにチームで反省し、次に活かすサイクルを作るか - etc… - スプリントを減る事に改善のサイクルを回し、継続的に良い開発チームになっていく方法論やメンタ リティーのプラクティスが転がっている
©2024 10X, Inc. 65 スクラム全然知らないし ぶっちゃけ違う業界の 話だと思ってました! データアナリスト/サイエンティスト、スクラムを知らない問題 • 商品データチームはデータアナリスト/サイエンティスト3名+データエンジニア2名で主に開発
◦ データ処理/データマネジメントのスキルを持ったメンバー • うち、アナリスト/サイエンティスト3名はスクラム知識なし
©2024 10X, Inc. • データ活用の下流側のタスクが主領域 • プロジェクト型の仕事(短期~中期)が多い • データから導き出されるインサイトが成果物 ◦
集計可視化、レポーティングなどでデータ活用を推進し現場を動かす系タスクも多い ◦ 特定期間内、特定用途向けのデータを対象とすることが多い ▪ 一旦既存システムとは独立した状態を仮定することが多い ◦ (PJ型の性質上)中長期先まで同じ利用できることはフォーカス外とすることが多い ▪ 故にテスト実施、品質保証もフォーカス外となることが多い • プロダクト開発/スクラム開発とは対象とする開発期間も、目指すものも、関心事も大きく異なる。 ◦ 別の文化圏の仕事の進め方を経験してきたメンバーたち • 輪読会をして知識をつけたり、意見交換して考え方をアップデートしたり頑張る データアナリスト/サイエンティスト職種の仕事範囲 66
©2024 10X, Inc. チームの課題 • チームの状況をうまく同期する仕組みをもっていない ◦ 朝会はいちおう集まりはするが... • タスクの優先順位が(チームに)ない
◦ 問い合わせが来た順、声の大きい順に対応 • 属人的に実装したため、実装の詳細を互いに知らない ◦ ドキュメントも乏しい • 実装の複雑化 ◦ (一定のルールはありつつも)各パートナー毎に個別に実装したためパートナーごとの 特別なロジックが存在 • プロダクト開発を行う能力がチームに足りていない ◦ メンバー間にスキルギャップがある
©2024 10X, Inc. チームの課題 • チームの状況をうまく同期する仕組みをもっていない ◦ 朝会はいちおう集まりはするが... • タスクの優先順位が(チームに)ない
◦ 問い合わせが来た順、声の大きい順に対応 • 属人的に実装したため、実装の詳細を互いに知らない ◦ ドキュメントも乏しい • 実装の複雑化 ◦ (一定のルールはありつつも)各パートナー毎に個別に実装したためパートナーごとの 特別なロジックが存在 • プロダクト開発を行う能力がチームに足りていない ◦ メンバー間にスキルギャップがある
©2024 10X, Inc. スクラムのイベントを週次で実施しチームを同期させる • スプリントプランニング(1週間のタスク決定):1h30min ◦ 次の一週間でチームでどのタスクをやるかを決定 ◦ 着手可能な粒度まである程度タスク分解する
• デイリースクラム(朝会):毎日20min ◦ 昨日なにをしたか、今日誰が何をするかの宣言 ◦ なにか困り事がないかの確認 • スプリントレビュー(一週間の成果報告会):1h ◦ どんな成果物ができたかをチームに共有 • スプリントレトロスペクティブ(一週間の反省会): 45min ◦ 今週を振り返り、チームで次の一週間に活かせる反省がないかを対話 • リファインメント:(チームのtodoリストの整理) 1h ◦ チームのタスク一覧(プロダクトバックログアイテム)を見直し、優先度を並べ直す ◦ 直近で取り掛かるタスクについてどれくらい工数が必要かを見積もる ▪ 不確実性が高く見積もれない場合、巨大な工数が必要な場合は原因を取り除くアクションを 洗い出す
©2024 10X, Inc. チームの課題 • チームの状況をうまく同期する仕組みをもっていない ◦ 朝会はいちおう集まりはするが... • タスクの優先順位が(チームに)ない
◦ 問い合わせが来た順、声の大きい順に対応 • 属人的に実装したため、実装の詳細を互いに知らない ◦ ドキュメントも乏しい • 実装の複雑化 ◦ (一定のルールはありつつも)各パートナー毎に個別に実装したためパートナーごとの 特別なロジックが存在 • プロダクト開発を行う能力がチームに足りていない ◦ メンバー間にスキルギャップがある
©2024 10X, Inc. プロダクトバックログアイテムを作る • チームが持っているタスク一覧を優先度順(取り組む順)に並べたもの(=プロダクトバックログ)を作成 • チームにPO(プロダクトオーナー)を立て、POが主に優先度を決定する ◦ 故に、POはチーム外の関係者とも密にコミュニケーションをとり、チームが受けるべきタスクを決
定し、バックログアイテムに順位付きで追加する ◦ そのために、チームの状態(稼働状況や抱えている課題)をチーム外に適切に共有する必要もある • チームメンバーはバックログを見て上から順にタスクを解決する • プロダクトバックログができることで、問い合わせされた順に対応することなく、今チームがやるべきこと に集中して対応することができる • プロダクトバックログベースでチーム外とタスク調整の会話をすることができる(XXを今やる選択をする なら、代わりにYYができなくなるけどいいか?等) ◦ これにより、「いまチームには保守性向上が必須である」ことを全社に訴え、優先タスクとして保守 性向上に関するタスクをチームが取り組める段取りができた(=保守性以外のタスクが後ろ倒しにな ることを合意できた)
©2024 10X, Inc. チームの課題 • チームの状況をうまく同期する仕組みをもっていない ◦ 朝会はいちおう集まりはするが... • タスクの優先順位が(チームに)ない
◦ 問い合わせが来た順、声の大きい順に対応 • 属人的に実装したため、実装の詳細を互いに知らない ◦ ドキュメントも乏しい • 実装の複雑化 ◦ (一定のルールはありつつも)各パートナー毎に個別に実装したためパートナーごとの 特別なロジックが存在 • プロダクト開発を行う能力がチームに足りていない ◦ メンバー間にスキルギャップがある
©2024 10X, Inc. 銀の弾丸はない。愚直に毎日コツコツ改善 • 属人的に実装したため、実装の詳細を互いに知らない ◦ → ドキュメントの補強, データソースのSSOT化
◦ → ペアプロ・ペア作業などで実装の解説、理解深堀り • 実装の複雑化 ◦ → 全パートナーのロジックを洗い出し。共通の処理, 課題を網羅 ▪ → 処理をパターン化しリファクタリングしていく ▪ → モデリングを見直してリファクタリングしていく ◦ → testの導入。小さくテストし、”安心できる部品”を積み上げる ◦ 自動チェックの仕組みを増やし、安心できる開発体制を整えていく • プロダクト開発を行う能力がチームに足りていない ◦ → スクラムイベントを通じて作業や知識の同期 ▪ 有識者の考えていることを聞いて「無知の知」を知る, 反省会を通して仕組みを改善させる ◦ → ペアプロ・モブプロなどで同期作業。知識移転 ▪ → 「コードを読む会」の実施, 輪読会の実施 ◦ →チーム出社日を増やし、密度をあげる
©2024 10X, Inc. 74 • 我々のチームにおいては、「プロダクトバックログの作成」が大きかった気がしている ◦ チームがやるべきことを明確になり同じ方向を向けるようになった、集中できるようになった ◦ チーム外と会話できるようになり、組織横断で課題感を共有できるようになった
▪ (経営層とも課題認識を揃えることができたが、これはCTOが組織にいる影響もあるかも) ◦ 一人一殺の断片的なインクリメント(成果)ではなく、開発/改善がチームとしての「積み上がる成果」に なった ◦ 重要度の高い属人的なタスクが可視化され、それを解消するために議論されるようになった ▪ 議論する中で、「データプロダクトは “ソフトウェア開発だったんだ”」 と発見した(何を今更と思う じゃろ?: 続く) スクラムを導入し、特に価値を感じていること
©2024 10X, Inc. 75 データプロダクトとスキルセット
©2024 10X, Inc. なぜこの開発が”ソフトウェア開発”であると気づくのに遅れたのか? 76 76 (ここまでの振り返り) • dbtの開発ではSQLをゴリゴリ書きまくる↓ ◦
SQLを書くのが得意なデータアナリスト系の人がチームに集まる↓ ◦ 実際に触っているのはBQとSQLのみなので、データアナリティクスの領分と思える↓ • 実際に動くdbtパイプラインは作れるので、リリースまでは到達できる↓ • リリースすると次は品質が問題になる ◦ 品質改善のためには多くのソフトウェアエンジニアリングのスキルが必要であると気づく ▪ スクラム、テスト、CI/CD, 障害対応 etc • 扱う対象は「データ」であるものの、使うスキルの大部分はソフトウェア開発の方法論と被ることに気づく ◦ 「あっ、データプロダクト開発は”ソフトウェア開発”だわ」 ◦ 実際はそれに加えて、効果的なdbtパイプライン設計のために「データモデリング」の知識も必要になる
©2024 10X, Inc. (余談)間抜けだったのか? 77 77 「SQLを書くからデータアナリストが必要」は誤算だったのか? そうは思えない。 • まだ「正解」がないものを手探りで作っていくフェーズだった
◦ 最初は開発の設計図もないところからBizDevと相談しながら手探りでパートナーが欲する機能を 作っていった。型化・共通化・抽象化よりも、まずは動くコードを作って提供することが至上命題。 道を切り開いた。 ▪ データの活用(実装)がまずあって、その後に問題に気づくことができる。 ▪ 他のデータ職種ができないとはいわないが、データアナリスト趣向の人のほうが燃えるシチュ エーションぽい。アドホックに立ち回る役目として一定は状況にfitしていた
©2024 10X, Inc. dbtというゲームチェンジャー 78 78 • dbtという新しい道具がソフトウェア開発文化をデータ領域に持ち込んだのも大きい ◦ 「データ処理文脈でSQLを書いていたら、気づけばソフトウェア開発に足を突っ込んでいた」状態
• SQLはデータ分析の道具の色が濃かった。しかしdbtの登場によってSQLでも プロダクト開発ができるよう になり ソフトウェア開発の色を濃くした。 ◦ そのときにより重要になるのはアドホックでクイックな黒魔術的な高度なSQL技術ではなく、 「ソフトウェア開発」を強く意識したコーディング技術だった ▪ 保守運用しやすいコード • 第三者にも意図が透けて伝わる関数命名、CTE句単位 ▪ テスト実施単位での疎結合化 ▪ ユビキタス言語やコンテクストマップの意識。ドメイン駆動開発 ▪ etc…
©2024 10X, Inc. 現在の開発体制 79 79 現在は、データエンジニア・ソフトウェアエンジニアを中心にソフトウェア開発のお作法でデータプロダクト開発 をおこなっている • データプロダクト開発として、次のステージに来ている感
• これまで獲得した知識を使った「保守性改善」と「プラットフォーム機能強化」に注力 ◦ データプロダクト領域とつながる部分のインターフェース定義(Data Contract) ▪ データプロダクトへのinputデータの再定義 ▪ データプロダクトからのアウトプットデータの再定義 ◦ DataExpressの開発を通じたプラットフォーム機能追加 ▪ 「プラットフォームとして提供すべき機能」「プラットフォームの外で作る個別機能」の考え 方をブラッシュアップ ◦ 保守性改善のための開発体験の向上、ドメインの再考、レイヤリングの再考 関連記事: 【Stailerの現在地】保守性改善からプラットフォームの道へ - 10X Blog
©2024 10X, Inc. ここまでの振り返り 80 80 • ベストプラクティスがなかった、ローンチすることが至上命題だったフェースではゴリゴリと目の前の要望 を叶えていくデータアナリストが道を切り開いていった •
そこを超えると、今度はプロダクト品質が問題になった ◦ スピードとのトレードオフで起こる問題 ◦ 解決できないとパートナー解約にも繋がるため死活問題 • しかし問題は明確だった。スクラムでその問題を少しつづ改善していく ◦ 中長期を目指したチーム構築を目指して開発体制、やり方論を一新する必要がある。ここで分解せず にうまくピボットできるか。 ▪ データアナリスト的文化から、ソフトウェア開発文化へのシフト • (可能不可能以前に、そのキャリアを目指したいかという個々人の問題もある) • ゼロから「データプロダクト開発」をするなら、似た道を辿るかもしれない
©2024 10X, Inc. データプロダクト開発に必要なスキル? 81 81 データ生成から活用までのプロセスにおいて、5つのデータ職種が主戦場としてそうなところ(主観含む) データ 収集・整備 基盤構築
分析 モデル構築 モデル運用 ・改善 ①データ エンジニア ②アナリティク スエンジニア ③データ アナリスト ④データサイ エンティスト ⑤MLエンジニア そして、データプロダクト開発に必要となるスキ ルは①と②の間の子、もしくは両方くらい? (現実の業務では前後に染み出ることが多いし実際に重なるところ が多いので区別にあまり意味はなさそうだが。) 上流 下流
©2024 10X, Inc. 82 データプロダクトとデータ基盤
©2024 10X, Inc. 10Xの2つのデータチームの違いってなんだろう? 83 83 • ところで、10Xにはデータ活用・BI提供を行う「データ基盤チーム」と、これまで紹介してきた商品デー タのデータプロダクトを開発する「商品データチーム」がある •
2チームの必要なスキルセットはほとんど同じ ◦ SQL、データモデリング、ETLツール、クラウドプラットフォーム • 根本的に何かが違ったりしているのだろうか?(とふと思ったので考えてみた) データ プロダクト ダッシュ ボード データ基盤 hoge “データ基盤”と”データプロダクト”の関係は 世の中的には何となくこんなイメージ? “データ基盤”の中にいろいろ入っている感じ? 「データ基盤チーム」については以下を参照 関係記事: 10Xでのデータ基盤の変遷とこれから - speakerdeck
©2024 10X, Inc. 84 84 10Xにおけるデータプロダクトとデータ基盤の立ち位置 基幹データ データ プロダクト 商品データ
app データ (売上データ・ 行動ログ等) データ基盤 Stailer App 分析レポート BI 参考: データガバナンスチームの結成で得た学び - speakerdeck データプロダクト(商品データチーム) データ基盤(チーム) 価値の提供先 プロダクト(Stailer) - 各パートナー担当者 - 10Xのグロース担当者 提供する価値 売場構築に必要な商品データを、 より厳密に、安定的に供給する 売上状況データを可視化・分析し、 より正確に、より早く意思決定できる環境 アウトカム プロダクトの正常稼働 インサイトを得ることによるビジネスの駆動 確かにいろいろ違いそう
©2024 10X, Inc. データプロダクトのポジションマップ例 85 85 「Designing Data Products」の内容を図示 ,
発表者が一部加筆 生データ 派生データ アルゴリズム 意思決定の支援 意思決定の自動 化 API・ コーディング ダッシュボード・ 可視化 webアプリなど デバイス・ ハードウェア インター フェースの フレンド リーさ 易 難 考えるコスト 小 大 オープンデータ データウェアハウス 経営ダッシュボード レコメンド カーナビなど レコメンド・ カーナビなど DeepL翻訳 ML駆動 検品システム ML駆動 検品システム ML駆動 癌検知画像システム ML駆動 癌検知画像システム 自動運転・ 石油プラントの最適運 転システム 再掲
©2024 10X, Inc. 86 86 アウトプット観点でのデータプロダクトポジションマップ データ品質要求が厳しい 比較的厳しくない 価値の提供先が システム
価値の提供先が 人 - 経営ダッシュボード - 癌検知システム - 機械翻訳 - レコメンドエンジン - カーナビ - アドホックな分析ダッシュボード - 自動運転 - 食品検品システム - (プロダクションに乗る データ) (品質が良くない初期の システム向けデータプロダク ト) 人命や企業赤字に繋がるもの ① ② ③ ④ 関係 • ①と②の関係 ◦ ”インサイト”を人に与えることが価 値 ◦ コストが見合うなら①へ移動 • ③と④の関係 ◦ プロダクトの稼働が価値 ◦ 開発初期は④から始まり③へ進 む圧力が生まれる • ③の特徴 ◦ バージョンアップによる性能向上 が競争力になるためソフトウェア 開発の色が濃い ◦ データ品質、プロダクト品質ともに シビア • ①②③に優劣関係はなく、目的に応じて 必要な手段を選ぶ 「誰に提供するか」、「どのくらいのデータ品質を求められるか」で分けると、
©2024 10X, Inc. 87 87 データ品質要求が厳しい 比較的厳しくない 価値の提供先が システム 価値の提供先が
人 - 機械翻訳 - レコメンドエンジン - カーナビ - アドホックな分析ダッシュボード - 自動運転 - 食品検品システム - (プロダクションに乗る データ) (品質が良くない初期の システム向けデータプロダク ト) ① ② ③ ④ • 商品データチームは③の領域を、 データ基盤チームでは①②の領域を 扱っている という棲み分け ◦ (この2軸で分けた場合はそ ういう違いになる) • このため、スキルセットは近いもの の、扱うデータの種類も、開発手法 も異なる。 • それぞれが重い仕事なので別チーム になっている 人命や企業赤字に繋がるもの - 経営ダッシュボード - 癌検知システム 10Xでは③チームと、①②チームに分かれている
©2024 10X, Inc. 88 まとめ
©2024 10X, Inc. 89 1. 10Xのビジネスについて ◦ ネットスーパー立ち上げのBtoBtoCモデル。売上連動のビジネスモデル 2. データプロダクトとは
◦ Data as a Product / データを製品のように開発する という考え方のプロダクト開発領域 3. 10Xのデータプロダクトとは ◦ 「商品データ」を作るデータプロダクト開発。プロダクションに直結しているためシビア 4. データプロダクト開発の歩み ◦ データパイプラインのアーキテクチャとモデリング進化の歴史 5. データプロダクトと品質 ◦ プロダクト品質問題への発生。一人一殺開発の功罪。 6. プロダクト開発とスクラム ◦ データチームにおけるスクラムの導入。品質改善への取り組み、 7. データプロダクトとスキルセット ◦ データ分析文化からソフトウェア開発文化への体制変更 8. データプロダクトとデータ基盤 ◦ 10Xにおける2つのデータチームの違い このスライドの一行まとめ
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}