Usually “large” databases are considered as such for the high number of records they hold, reaching billions or even more than that. But what about creating a billion... tables? Sometime ago, this apparently crazy question was found in a database soup (http://it.toolbox.com/blogs/database-soup/one-billion-tables-or-bust-46270). It may not be your day-to-day task, but the task of creating them exposes some topics about PostgreSQL internals, performance and large databases that may be really worth for your day-to-day. Join us for this talk, where we'll be discussing topics such as catalogue structure and storage requirements, table speed creation, differences between PostgreSQL versions and durability vs. table creation speed tradeoffs, among others. And, of course, how long a “\dt” takes on a 1B tables database :)
This talk will explore all the steps taken to achieve such a result, raising questions on topics such as: The catalogue structure and its storage requirements, Table creation speed, Durability tradeoffs to achieve the desired goal, Strategy to be able to create the 1B tables. Scripts / programs used, How the database behaves under such a high table count, Differences in table creation speed and other shortcuts between different PostgreSQL versions, How the storage media and database memory affects the table creation speed and the feasibility of the task, If it makes sense to have such a database.
It is intended to be a funny, open talk, for a beginner to medium level audience, interested in large databases, performance and PostgreSQL internals.
![Billion Tables Project (BTP) Álvaro Hernández Tortosa <[email protected]> José Luis](https://files.speakerdeck.com/presentations/21abb459c3f74cf99501441bc6a38c18/slide_0.jpg){kind=link}
![Who I am • Álvaro Hernández Tortosa <[email protected]> • CTO](https://files.speakerdeck.com/presentations/21abb459c3f74cf99501441bc6a38c18/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
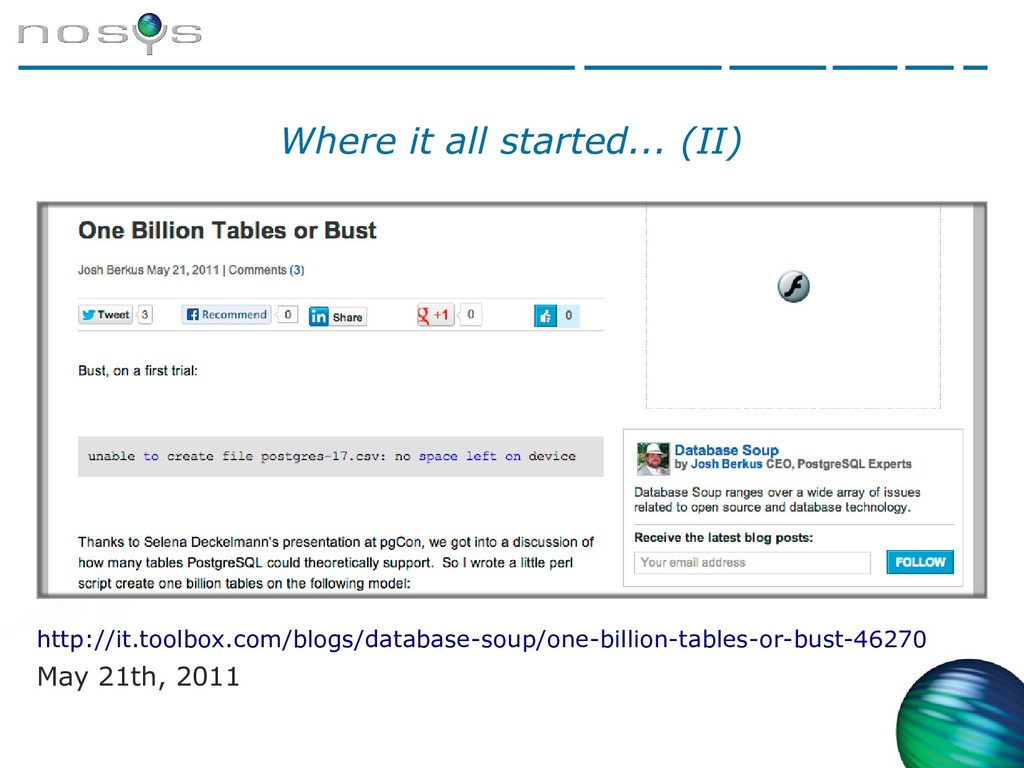
![Where it all started... • 2002, mail to [email protected]: “I'm](https://files.speakerdeck.com/presentations/21abb459c3f74cf99501441bc6a38c18/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
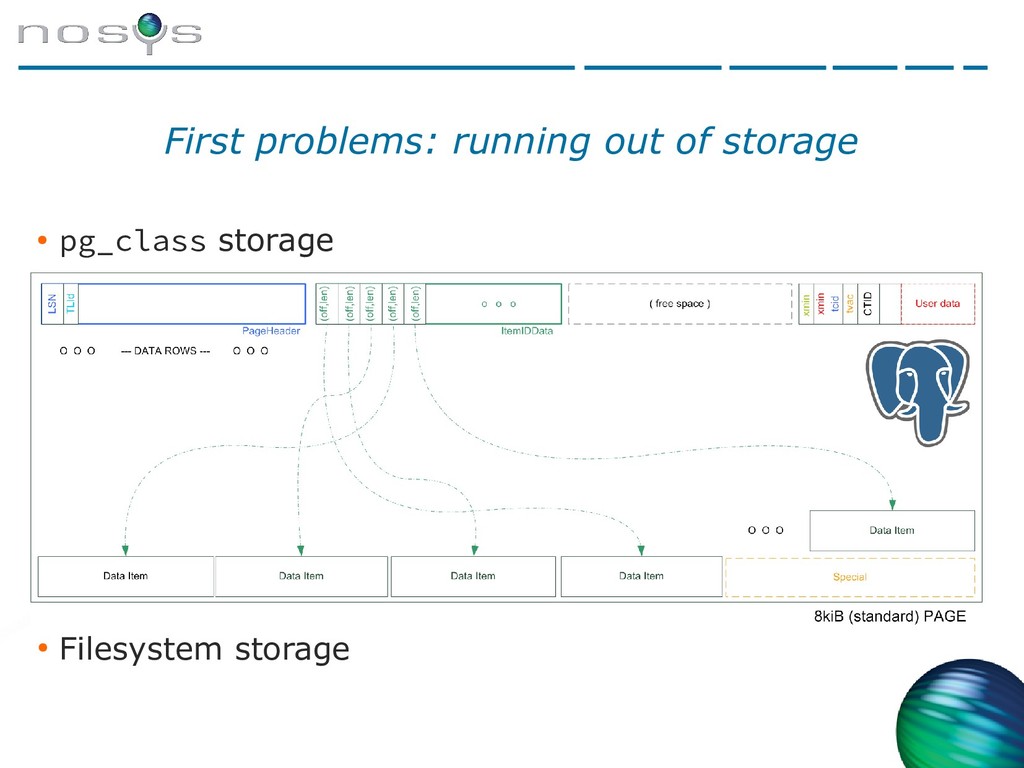{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
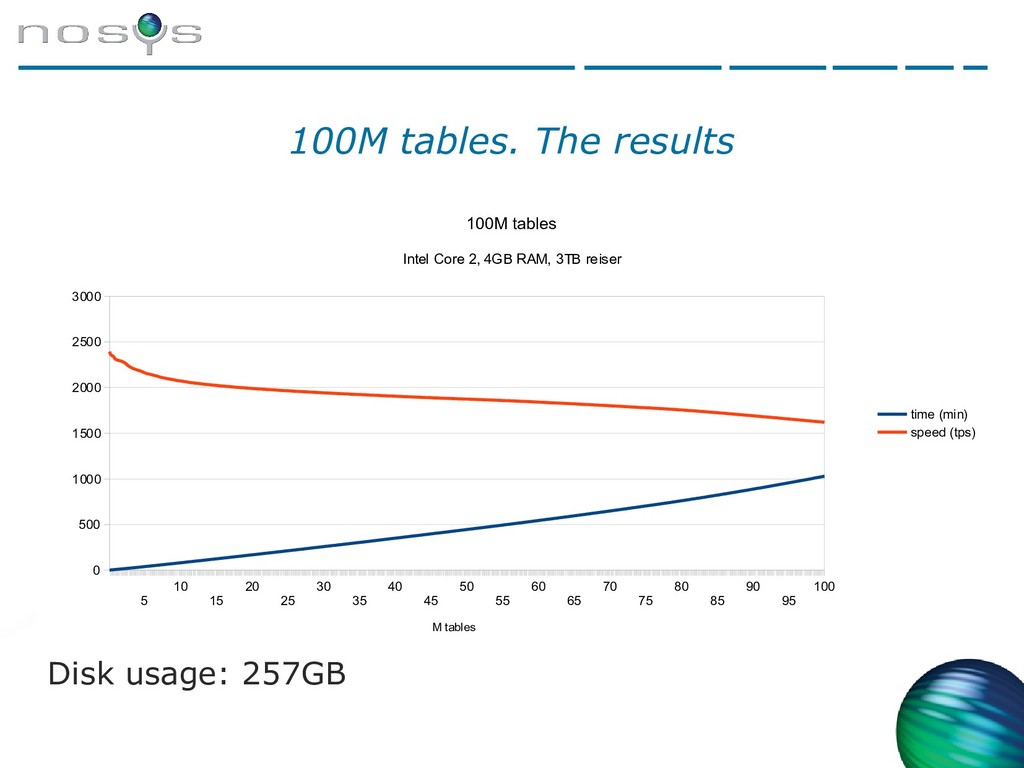{kind=link}
{kind=link}
{kind=link}
{kind=link}
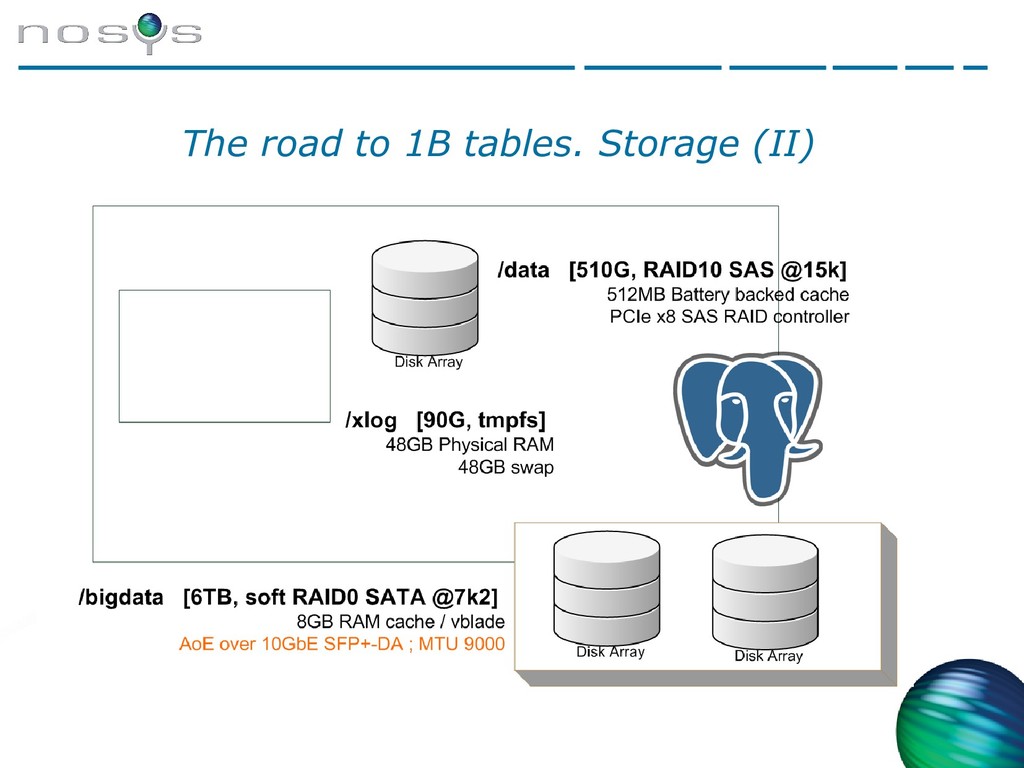{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
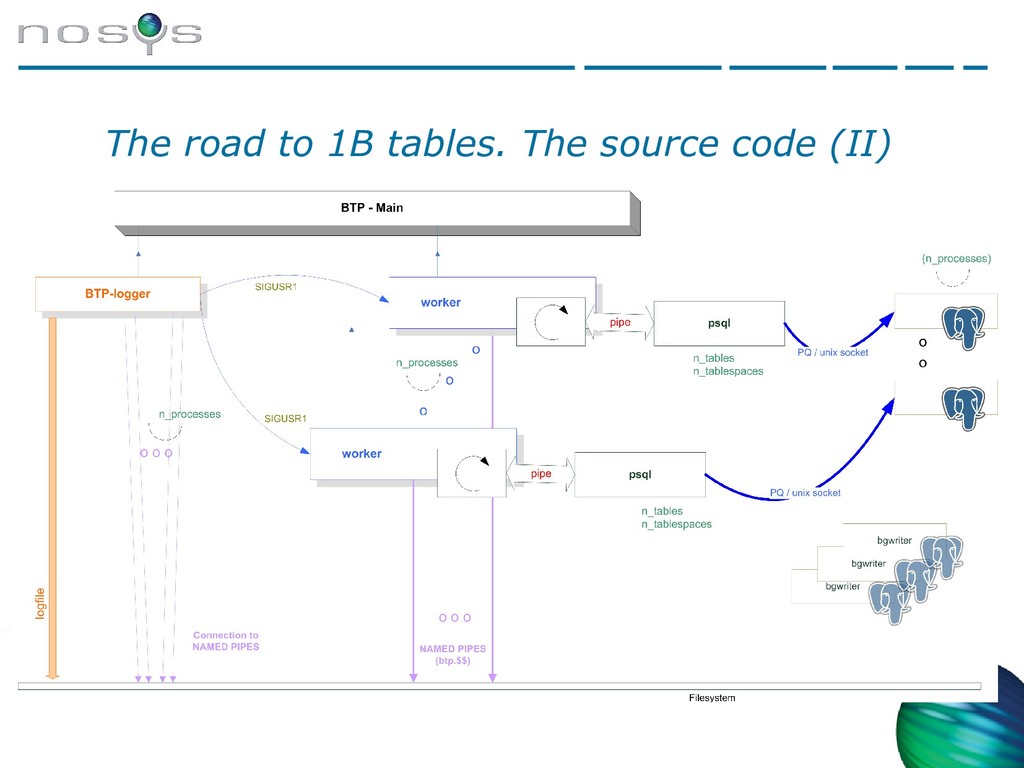{kind=link}
{kind=link}
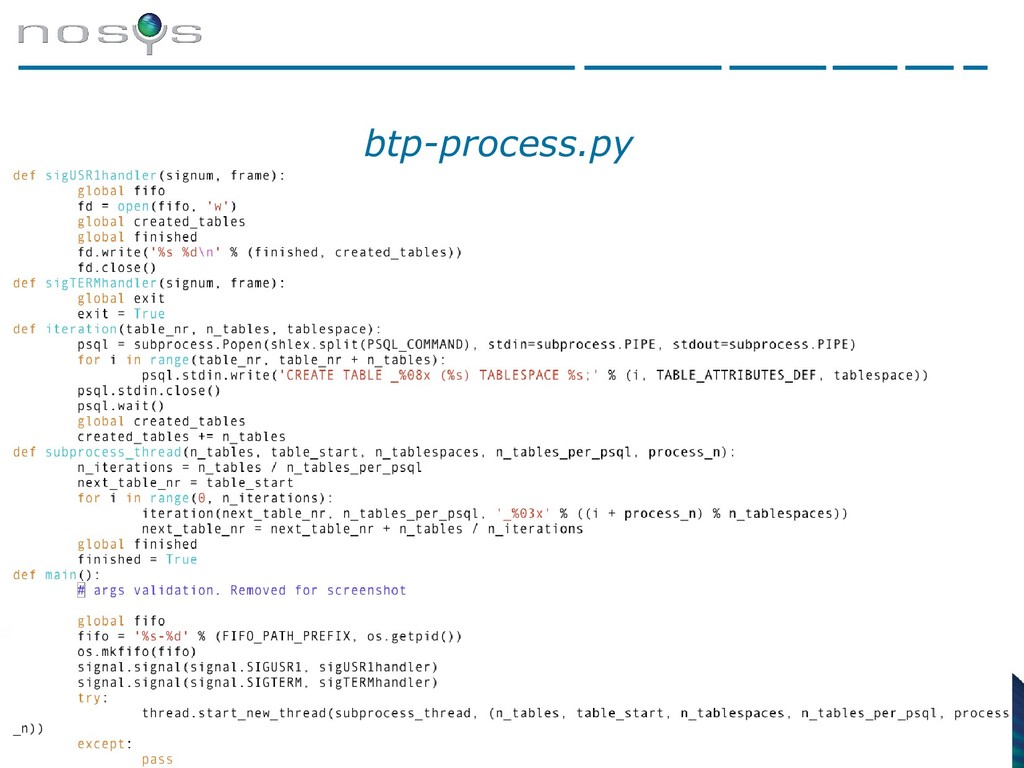{kind=link}
{kind=link}
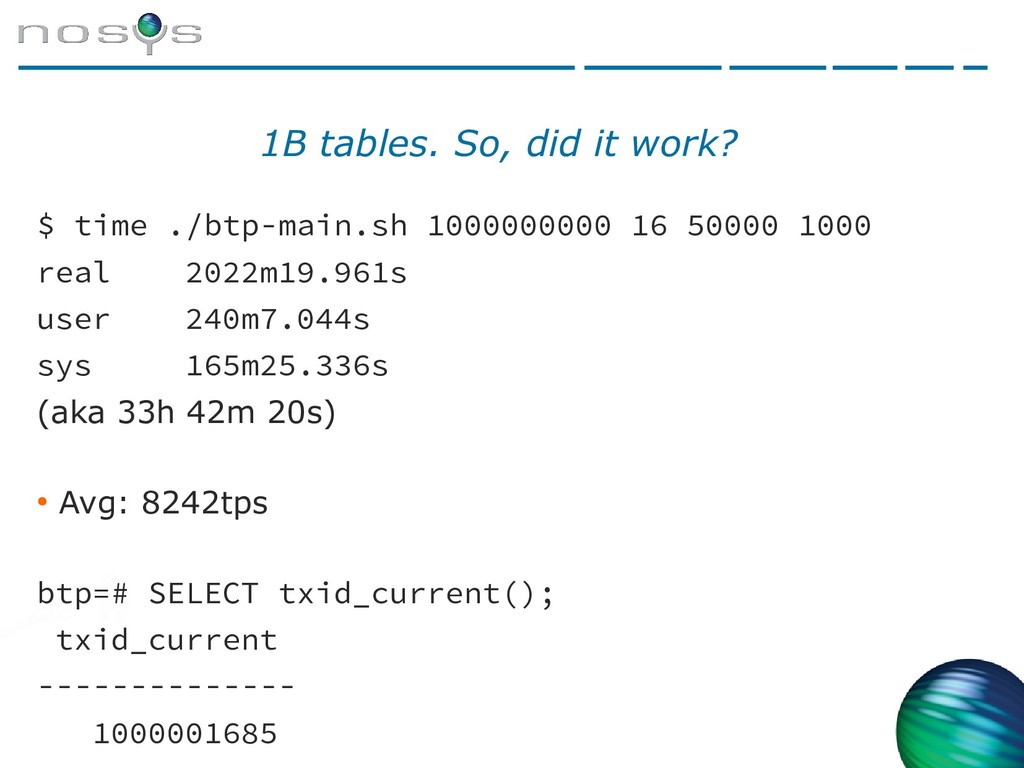{kind=link}
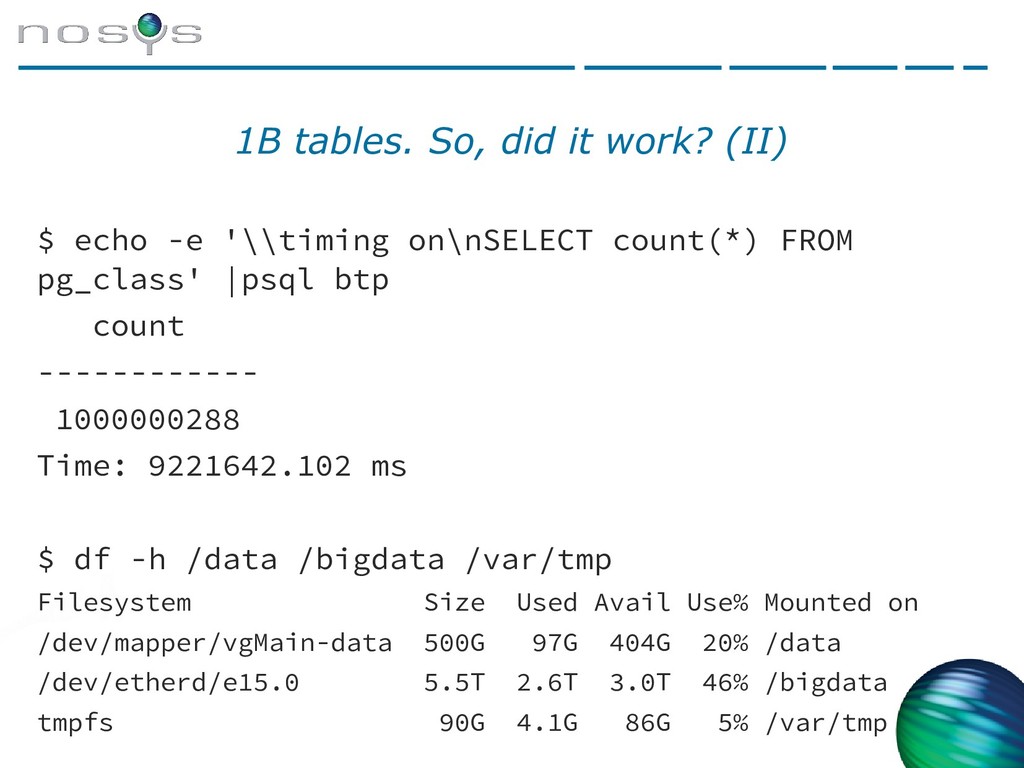{kind=link}
{kind=link}
{kind=link}
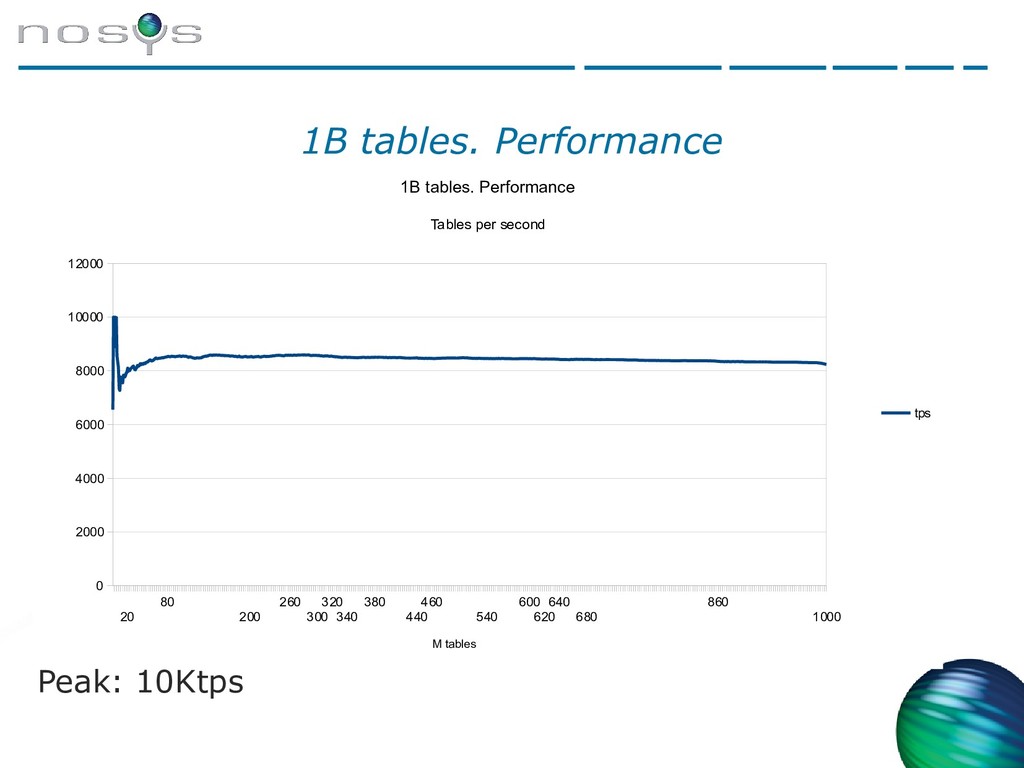{kind=link}
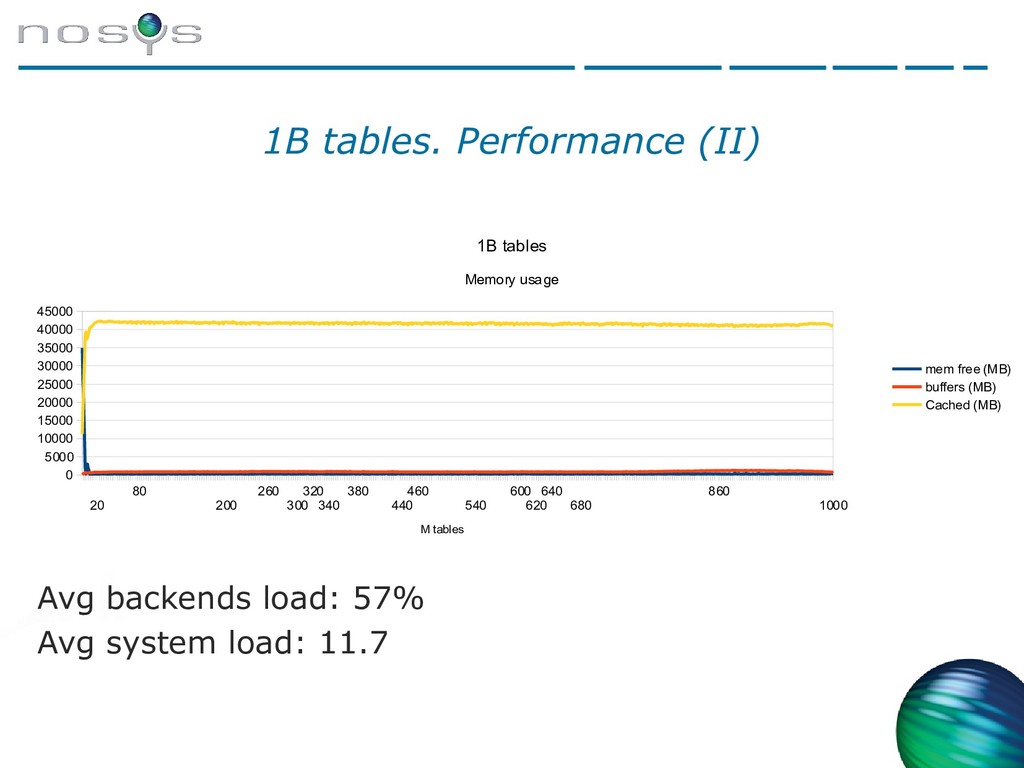{kind=link}
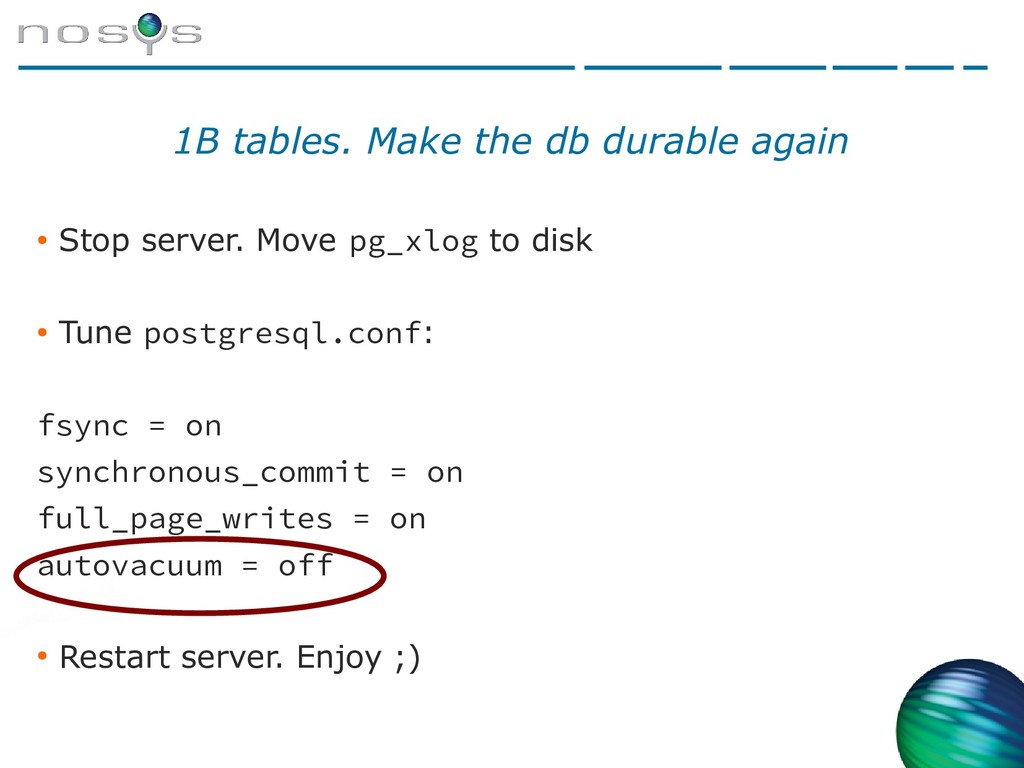{kind=link}
{kind=link}
![Billion Tables Project (BTP) Álvaro Hernández Tortosa <[email protected]> José Luis](https://files.speakerdeck.com/presentations/21abb459c3f74cf99501441bc6a38c18/slide_37.jpg){kind=link}