Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Google Espresso解説(2017年)
Search
__kaname__
September 22, 2022
Technology
1.9k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Google Espresso解説(2017年)
過去の社内勉強会(2017)の資料です。
Google Espressoの論文を解説した内容です。
もう古い内容ですが...
__kaname__
September 22, 2022
More Decks by __kaname__
See All by __kaname__
KDDIの社長会見、何が素晴らしかったか振り返ろう
__kaname__
1
1k
Other Decks in Technology
See All in Technology
「ビジネスがわかるエンジニア」とは何か?
ryooob
0
480
作る力から、見極める力へ — AI時代に広がるエンジニアの価値と役割
rince
0
400
NDIAS CTF 2026 問題解説会資料
bata_24
0
170
AWS Blocks を触ってみた/first-tach-aws-blocks
fossamagna
2
130
Terraform 101 (初心者向け) 資料
shuadachi
0
160
なぜ人は自分のプロジェクトを 「なんちゃってアジャイル」と 自嘲するのか
kozotaira
0
240
AIで政治は変わるのか? — 中高生と考えたAI時代の民主主義(東海高校サタデープログラム)
eitarosuda
0
360
背中から、背中へ /paying forward to community
naitosatoshi
0
210
記録をかんたんに、提案をパーソナルに ── AIであすけんが目指すもの
oprstchn
0
120
そのタスクオンスケですか?
poropinai1966
0
110
AWS Summit 2026で見えたSIerにとっての Amazon Quickの位置づけ
maf_0521
0
150
Multi-Agent並列開発を 安全に回すための技術 / Technology for Safely Multi-Agent Parallel Development
tooppoo
0
250
Featured
See All Featured
Mind Mapping
helmedeiros
PRO
1
270
Cheating the UX When There Is Nothing More to Optimize - PixelPioneers
stephaniewalter
287
14k
What's in a price? How to price your products and services
michaelherold
247
13k
The Cost Of JavaScript in 2023
addyosmani
55
10k
HU Berlin: Industrial-Strength Natural Language Processing with spaCy and Prodigy
inesmontani
PRO
0
430
Why Your Marketing Sucks and What You Can Do About It - Sophie Logan
marketingsoph
0
180
Build your cross-platform service in a week with App Engine
jlugia
234
18k
The #1 spot is gone: here's how to win anyway
tamaranovitovic
3
1.1k
How to Get Subject Matter Experts Bought In and Actively Contributing to SEO & PR Initiatives.
livdayseo
0
150
Kristin Tynski - Automating Marketing Tasks With AI
techseoconnect
PRO
0
280
Efficient Content Optimization with Google Search Console & Apps Script
katarinadahlin
PRO
1
650
Between Models and Reality
mayunak
4
360
Transcript
Googleの論文から読み解く 最新DC/NWアーキテクチャ 技術開発セミナー 2017.10.20 技術開発部 西塚要 Google Espresso編
最初に • ACM SIGCOMM 2017 で発表された以下の論 文の内容に基づいて、解説します – Taking the
Edge off with Espresso: Scale, Reliability and Programmability for Global Internet Peering – 詳細については、元の論文を参照ください • インターネット基礎的な話は割愛いたします • 明日からすぐに使えるアーキテクチャではあ りません
1. イントロダクション
背景 • Google/Facebookなどの巨大コンテンツホル ダは、ユーザーへコンテンツを提供する上で BGPによる制御だけではネットワークのリンク を有効的に活用できないことを問題視 • Google/Facebookがそれぞれ、独自の最適化 手法について、SIGCOMM 2017で発表
– Google: Espresso – Facebook: Edge Fabric
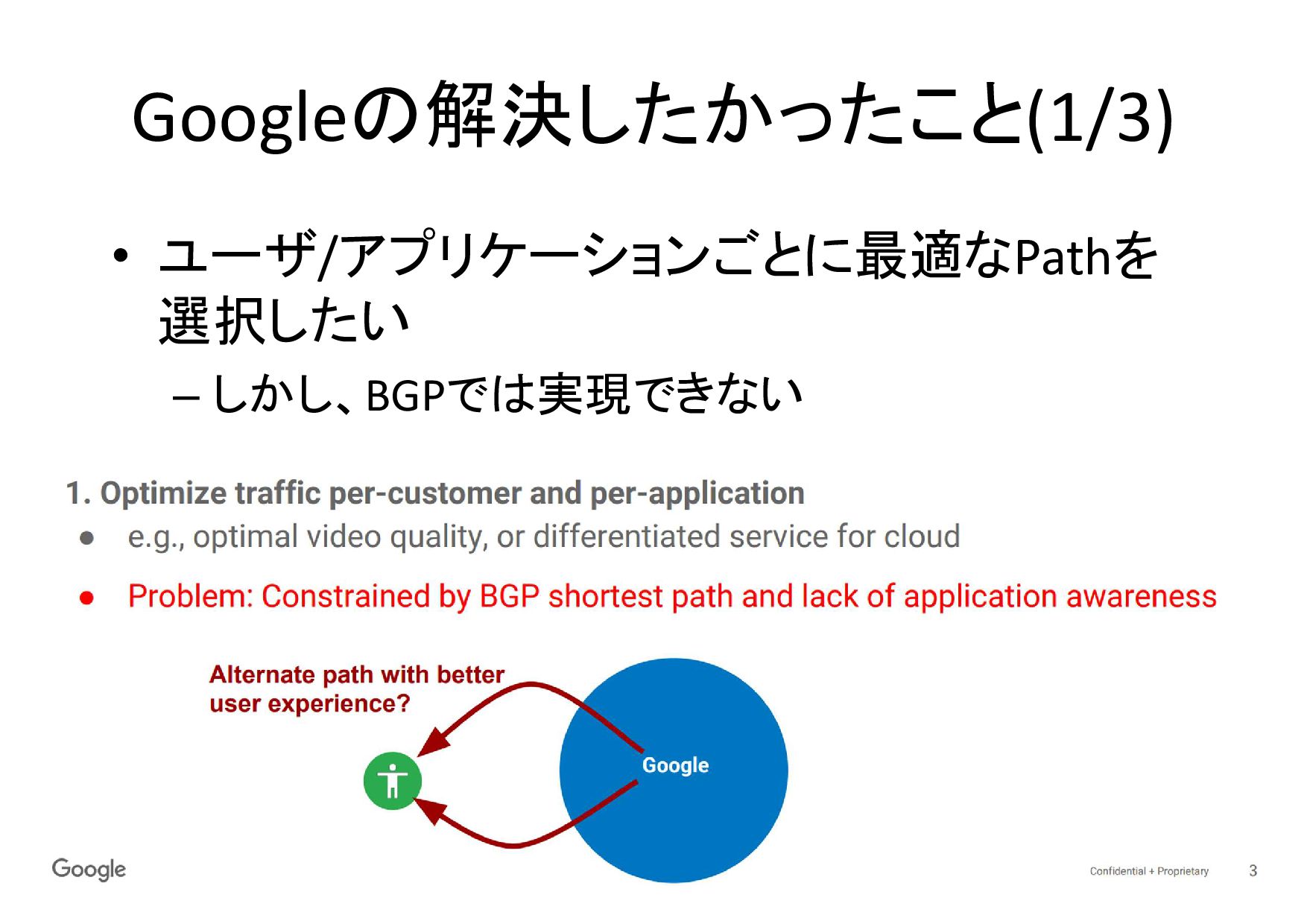
Googleの解決したかったこと(1/3) • ユーザ/アプリケーションごとに最適なPathを 選択したい – しかし、BGPでは実現できない
BGPによる制御の制約問題 • GoogleのTraffic Engineering(以下、TE) – 何百万の個々のユーザとの間で、高帯域/低遅 延となるegress ポートをリアルタイム計測している • BGP経路単位での経路の切り替えは、荒すぎ
る – ユーザセグメントの単位が大きすぎる – アプリケーション単位ではない
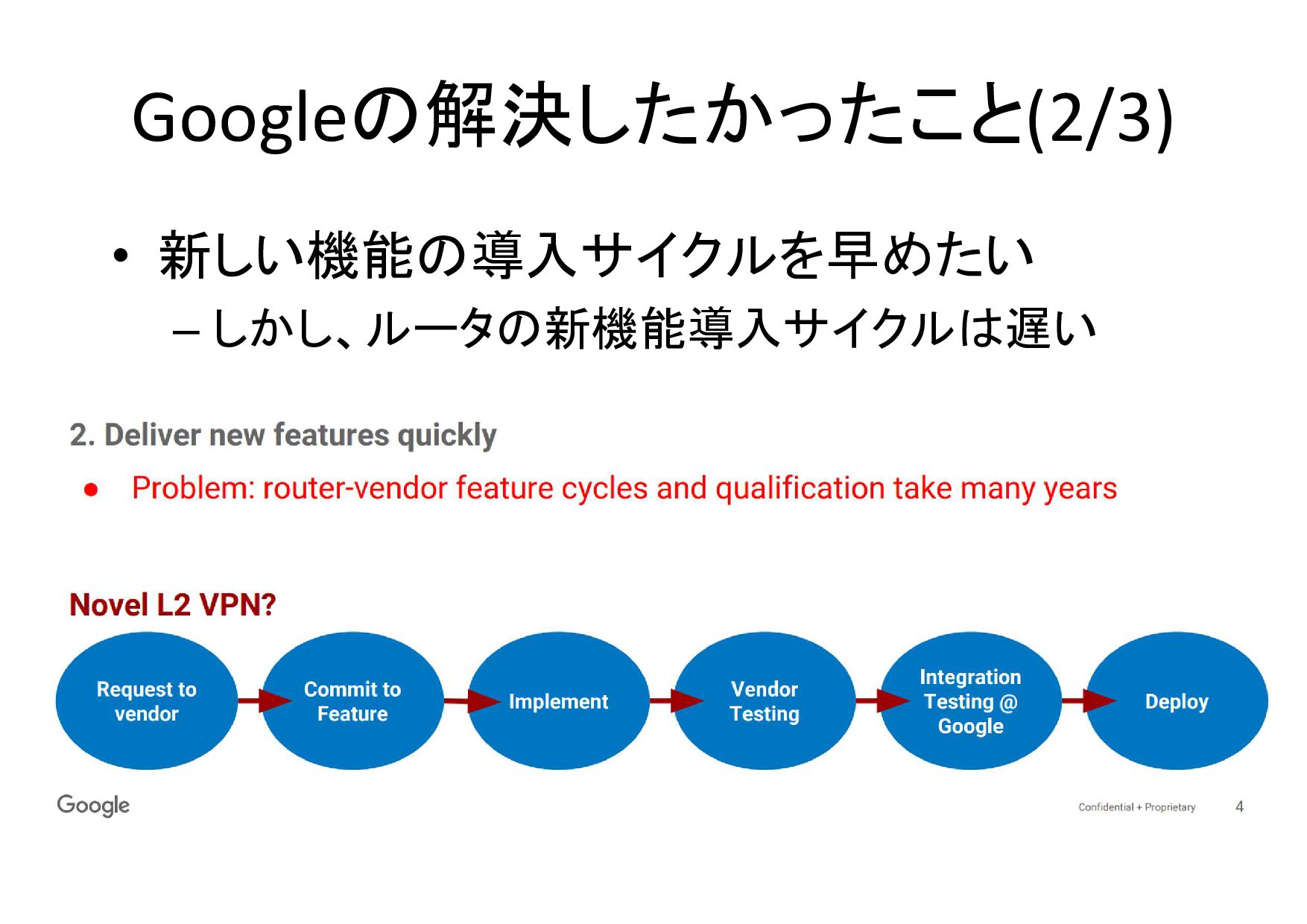
Googleの解決したかったこと(2/3) • 新しい機能の導入サイクルを早めたい – しかし、ルータの新機能導入サイクルは遅い
ルータの機能改善サイクル問題 • 新機能の導入にはベンダのHWやSWの変更 が必要 – 少しの変更でも検証に1年かかったり – 標準化に時間がかかったり – 新しい
シリコンを待たなければいけなかったり • しかもアップグレードに失敗すると影響が大き い
Googleの解決したかったこと(3/3) • ピア用ルータのコストを下げたい – テラbps級のトラフィック • 高画質動画 • クラウドトラフィック –
数百ポート/1筐体のポート密度 – フルルート対応 – 巨大なACL(DoS対策) • エッジ構成において、ピア用ルータの価格がコストの支 配項 – エッジルータは、一つ内側のルータのコストの 4-10倍 • 一つ内側のルータのACLや転送に関する要求はそれほど高くない
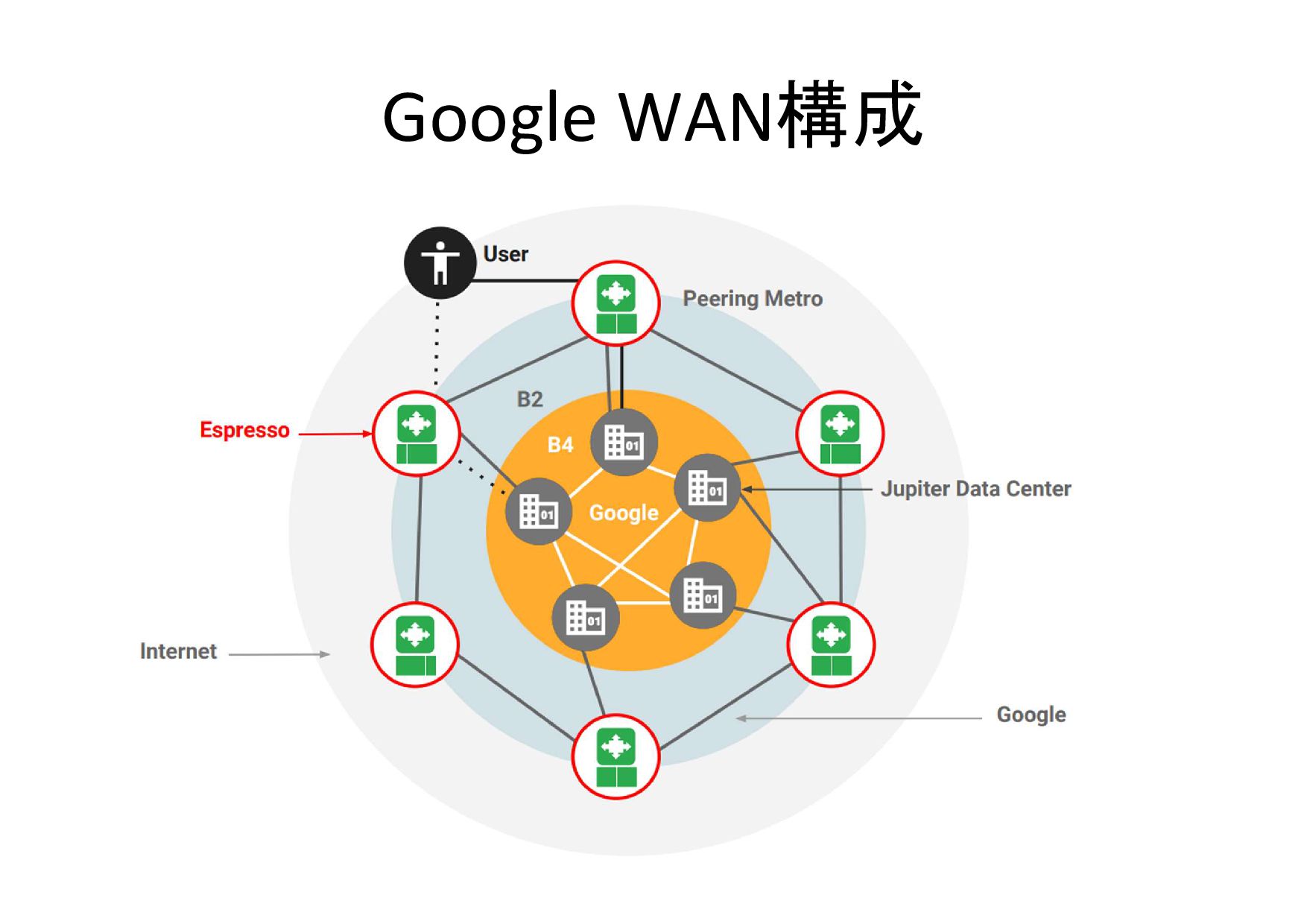
Google WAN構成
GoogleのSDN技術 • Jupiter [SIGCOMM 2015] • B4 [SIGCOMM 2013] –
GoogleのDC間SDN • Espresso [SIGCOMM 2017] – Jupiter/B4で培ったSDN技術を、対外接続に応用
(補足) ISPの立場で ISP-A ISP X ISP Y Googleのどこからダウンロードトラフィックが吐かれるかは、 ISP側からはBGPでも制御できない ISPから見ると、通常のBGPピア
2. Espressoの導入
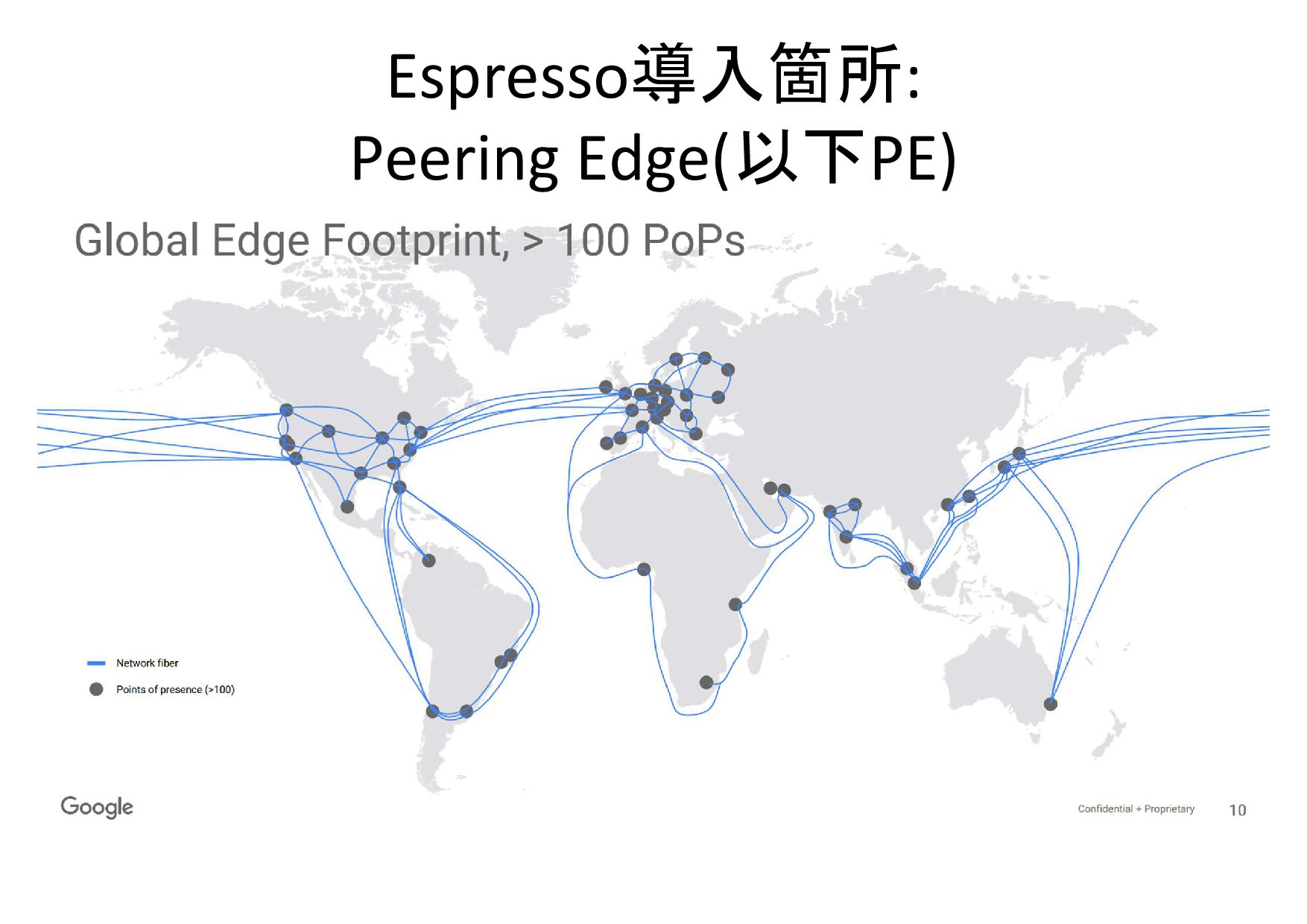
Espresso導入箇所: Peering Edge(以下PE)
Espresso導入箇所: Peering Edge(以下PE) • 構成要素 – テラビット級ルータ – メガワット級コンピュートノードとストレージ •
PEの機能 – 他のASとのpeering – reverse proxy として TCP の終端 – 静的なコンテンツのキャッシュ • PEの効用 – エンドユーザへの latency を小さく – DoS への耐性(被害範囲の限定) – 大容量のバックホールを要しない
Espressoの特徴(1/2) • Externalizing BGP – 概念としては、control を外だしして、ルータには data-plane だけ残す •
ルータの代わりに安価な MPLS switchで済む – BGP はサーバ上のソフトウェアで走らせた(ルータ のCPUは貧弱なので) • Externalizing Packet Processing – forwarding table や ACL のパケットプロセッシング を エッジにすでに存在する高性能サーバのソフト ウェアパケットプロセッサに移した
Espressoの特徴(2/2) • Hierarchical control plane – Metro内(local)での最適化: Location Controller(LC) –
Metroを超えた(global)最適化: Global Controller(GC) – 二層のコントローラにより、早い収束時間とフェール セーフを実現 • Application Aware Routing – パケットプロセッシングをするフロントサーバが、アプ リケーションごとの品質を、グローバルのトラフィック 最適化機構にフィードバック
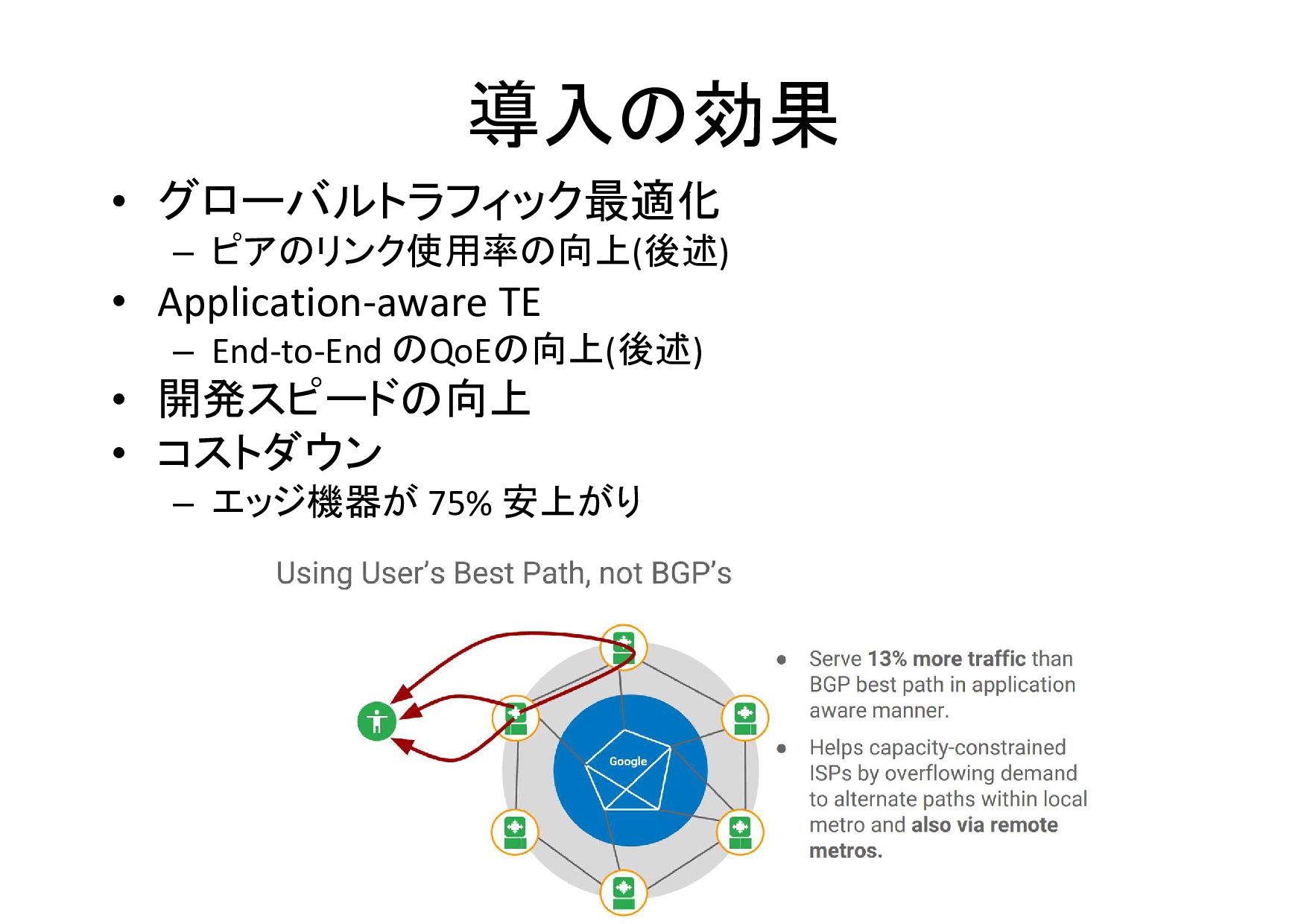
導入の効果 • グローバルトラフィック最適化 – ピアのリンク使用率の向上(後述) • Application-aware TE – End-to-End
のQoEの向上(後述) • 開発スピードの向上 • コストダウン – エッジ機器が 75% 安上がり
利用状況 • 発表時点(2017/8)で、Googleから吐かれるトラフィッ ク全体の22%がEspresso利用 – 直近2カ月では、トータルトラフィックの伸びよりも2.24倍の 伸び
3. アーキテクチャ概要
サーバ(Reverse Proxy) • Metroには大量のReverse Proxy(L7)が存在する – ユーザのコネクションを終端する • ユーザ向けのレイテンシを抑える –
キャッシュコンテンツをさばく • バックボーン向けのトラフィックを減らす • キャッシュできるコンテンツのパフォーマンスを向上させる • Espressoの鍵は、「すでに存在するこれらのサー バにパケット転送やACL処理を肩代わりさせるこ と(リソースの一部を有効活用) 」
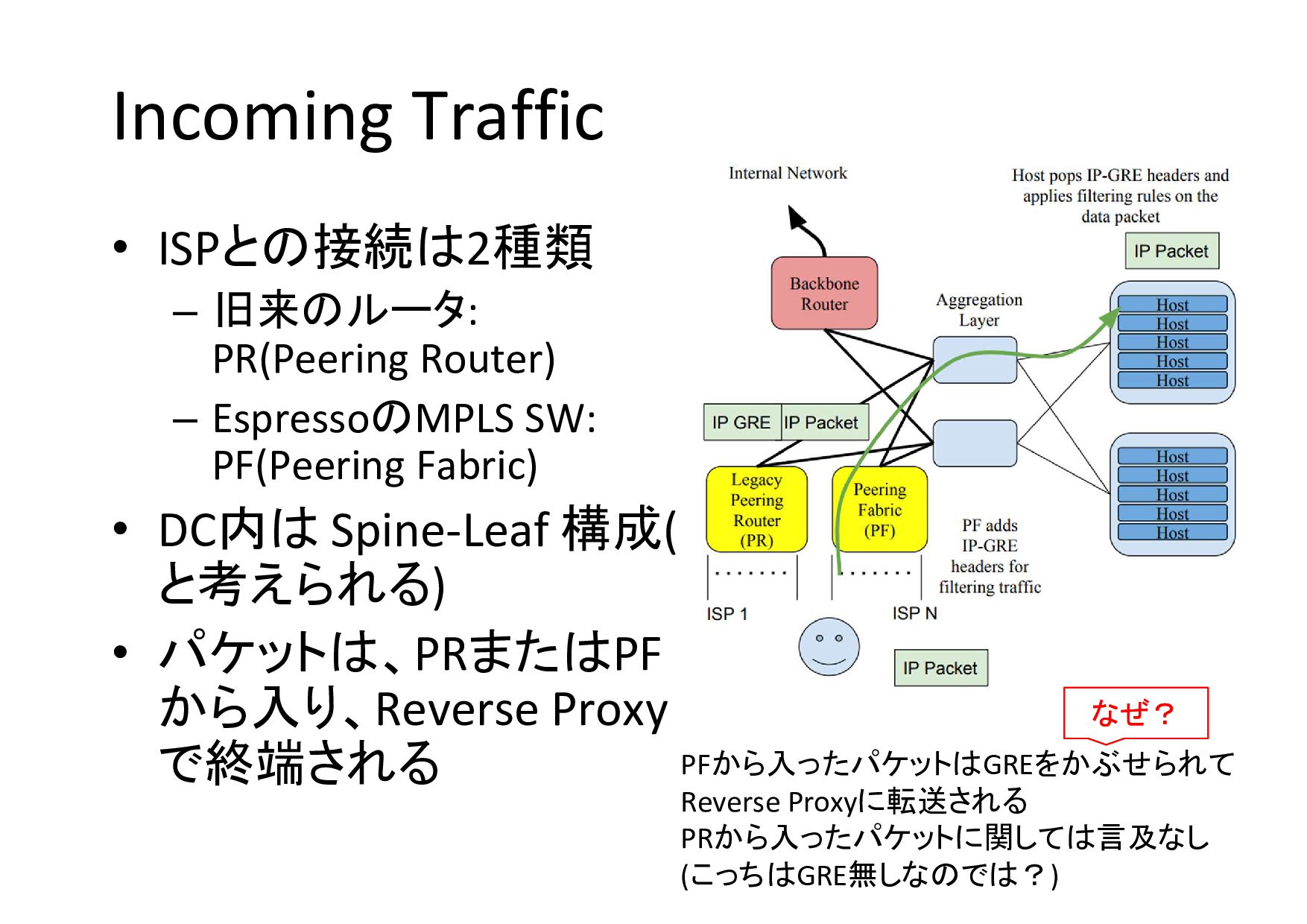
Incoming Traffic • ISPとの接続は2種類 – 旧来のルータ: PR(Peering Router) – EspressoのMPLS
SW: PF(Peering Fabric) • DC内は Spine-Leaf 構成( と考えられる) • パケットは、PRまたはPF から入り、Reverse Proxy で終端される PFから入ったパケットはGREをかぶせられて Reverse Proxyに転送される PRから入ったパケットに関しては言及なし (こっちはGRE無しなのでは?) なぜ? なぜ?
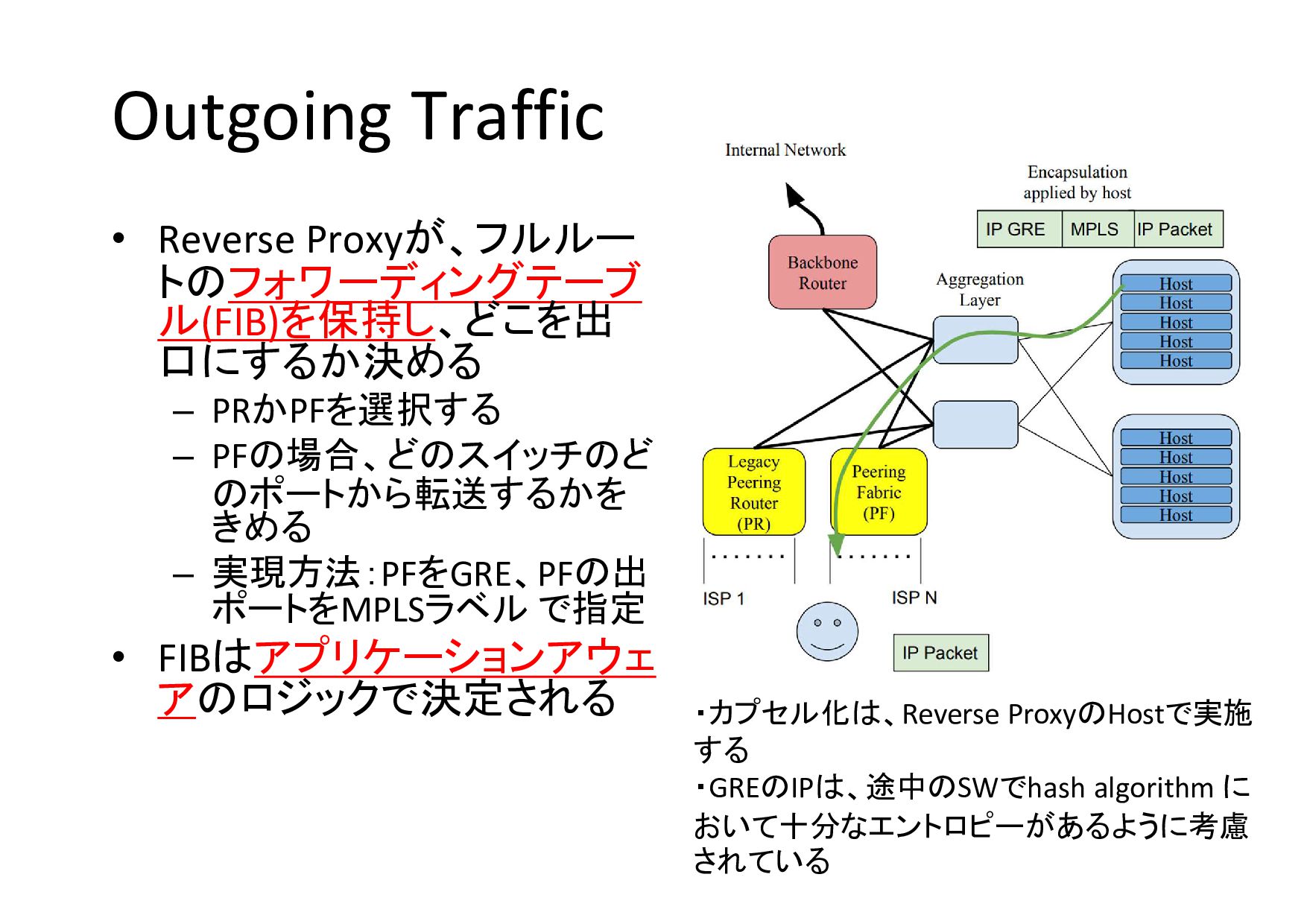
Outgoing Traffic • Reverse Proxyが、フルルー トのフォワーディングテーブ ル(FIB)を保持し、どこを出 口にするか決める – PRかPFを選択する
– PFの場合、どのスイッチのど のポートから転送するかを きめる – 実現方法:PFをGRE、PFの出 ポートをMPLSラベル で指定 • FIBはアプリケーションアウェ アのロジックで決定される ・カプセル化は、Reverse ProxyのHostで実施 する ・GREのIPは、途中のSWでhash algorithm に おいて十分なエントロピーがあるように考慮 されている
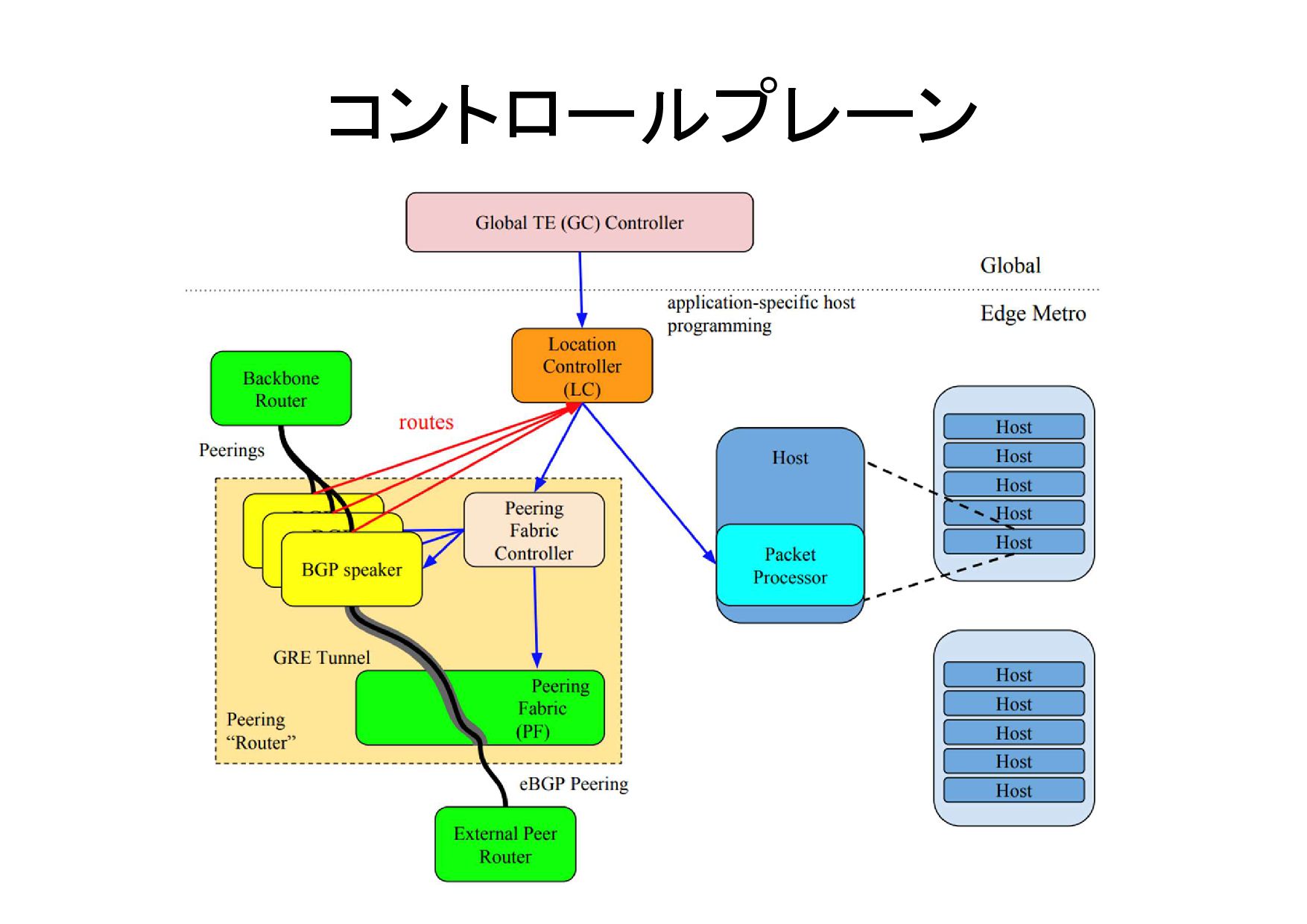
コントロールプレーン
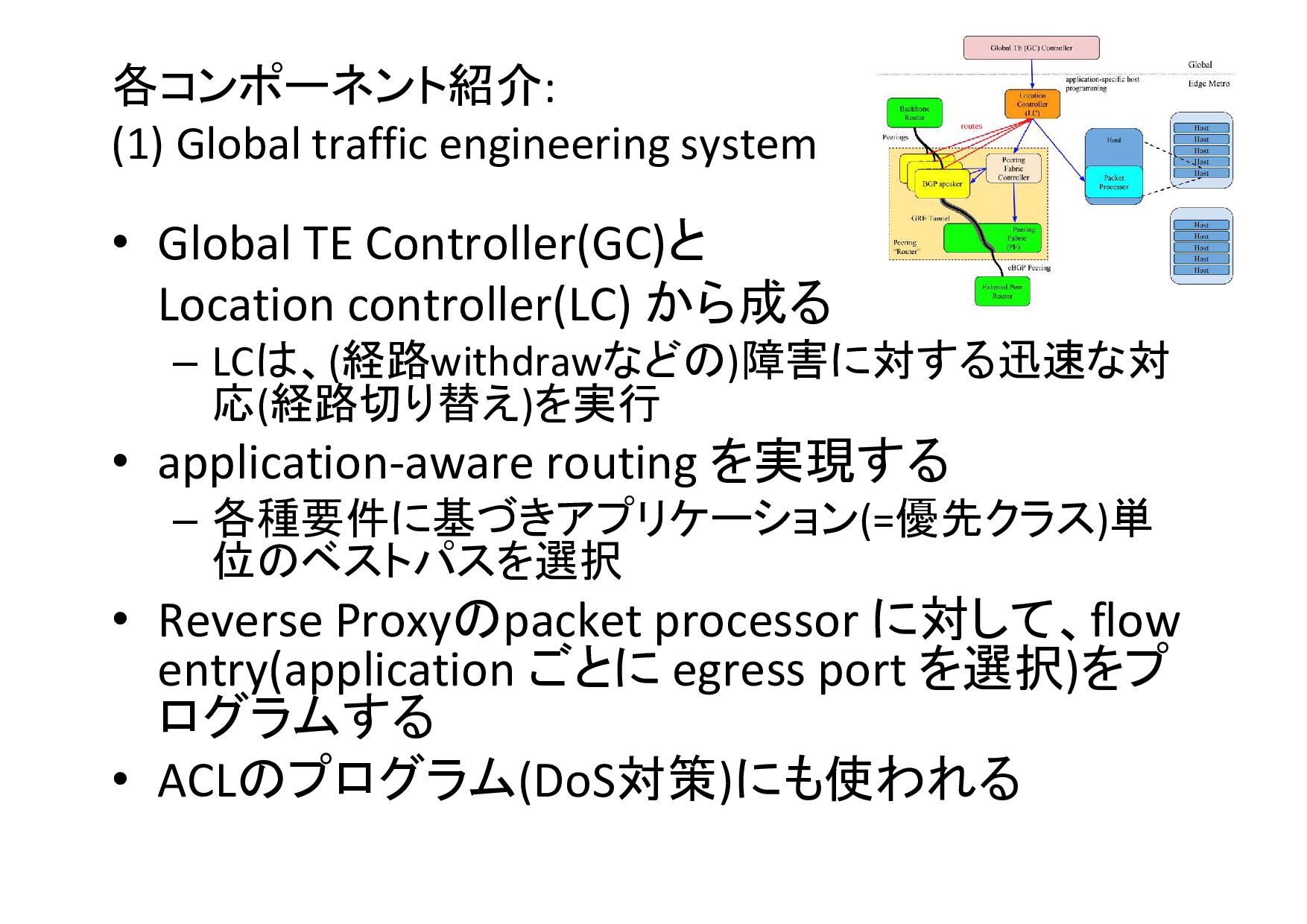
各コンポーネント紹介: (1) Global traffic engineering system • Global TE Controller(GC)と
Location controller(LC) から成る – LCは、(経路withdrawなどの)障害に対する迅速な対 応(経路切り替え)を実行 • application-aware routing を実現する – 各種要件に基づきアプリケーション(=優先クラス)単 位のベストパスを選択 • Reverse Proxyのpacket processor に対して、flow entry(application ごとに egress port を選択)をプ ログラムする • ACLのプログラム(DoS対策)にも使われる
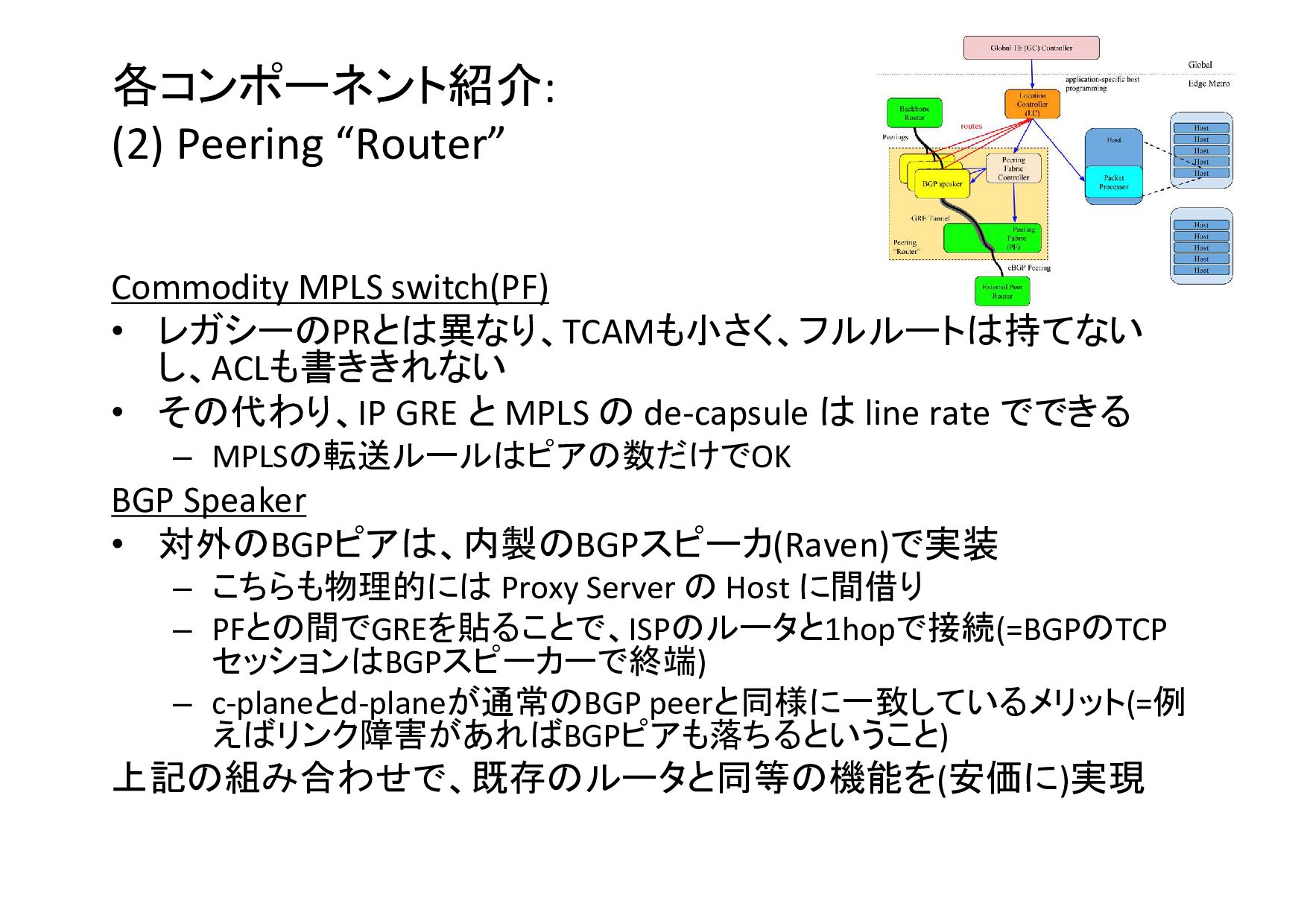
各コンポーネント紹介: (2) Peering “Router” Commodity MPLS switch(PF) • レガシーのPRとは異なり、TCAMも小さく、フルルートは持てない し、ACLも書ききれない
• その代わり、IP GRE と MPLS の de-capsule は line rate でできる – MPLSの転送ルールはピアの数だけでOK BGP Speaker • 対外のBGPピアは、内製のBGPスピーカ(Raven)で実装 – こちらも物理的には Proxy Server の Host に間借り – PFとの間でGREを貼ることで、ISPのルータと1hopで接続(=BGPのTCP セッションはBGPスピーカーで終端) – c-planeとd-planeが通常のBGP peerと同様に一致しているメリット(=例 えばリンク障害があればBGPピアも落ちるということ) 上記の組み合わせで、既存のルータと同等の機能を(安価に)実現
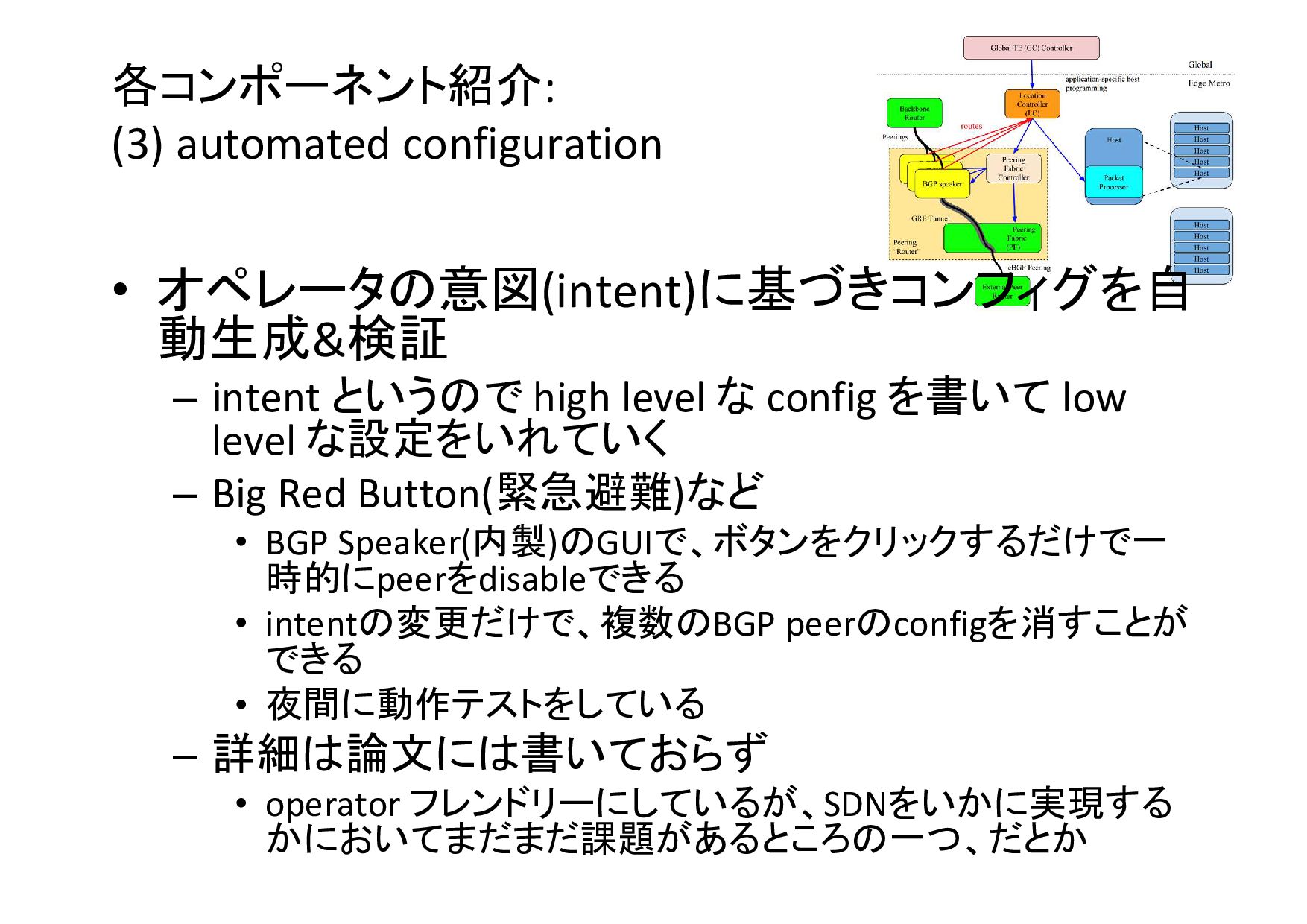
各コンポーネント紹介: (3) automated configuration • オペレータの意図(intent)に基づきコンフィグを自 動生成&検証 – intent というので
high level な config を書いて low level な設定をいれていく – Big Red Button(緊急避難)など • BGP Speaker(内製)のGUIで、ボタンをクリックするだけで一 時的にpeerをdisableできる • intentの変更だけで、複数のBGP peerのconfigを消すことが できる • 夜間に動作テストをしている – 詳細は論文には書いておらず • operator フレンドリーにしているが、SDNをいかに実現する かにおいてまだまだ課題があるところの一つ、だとか
4. Application-aware TE system
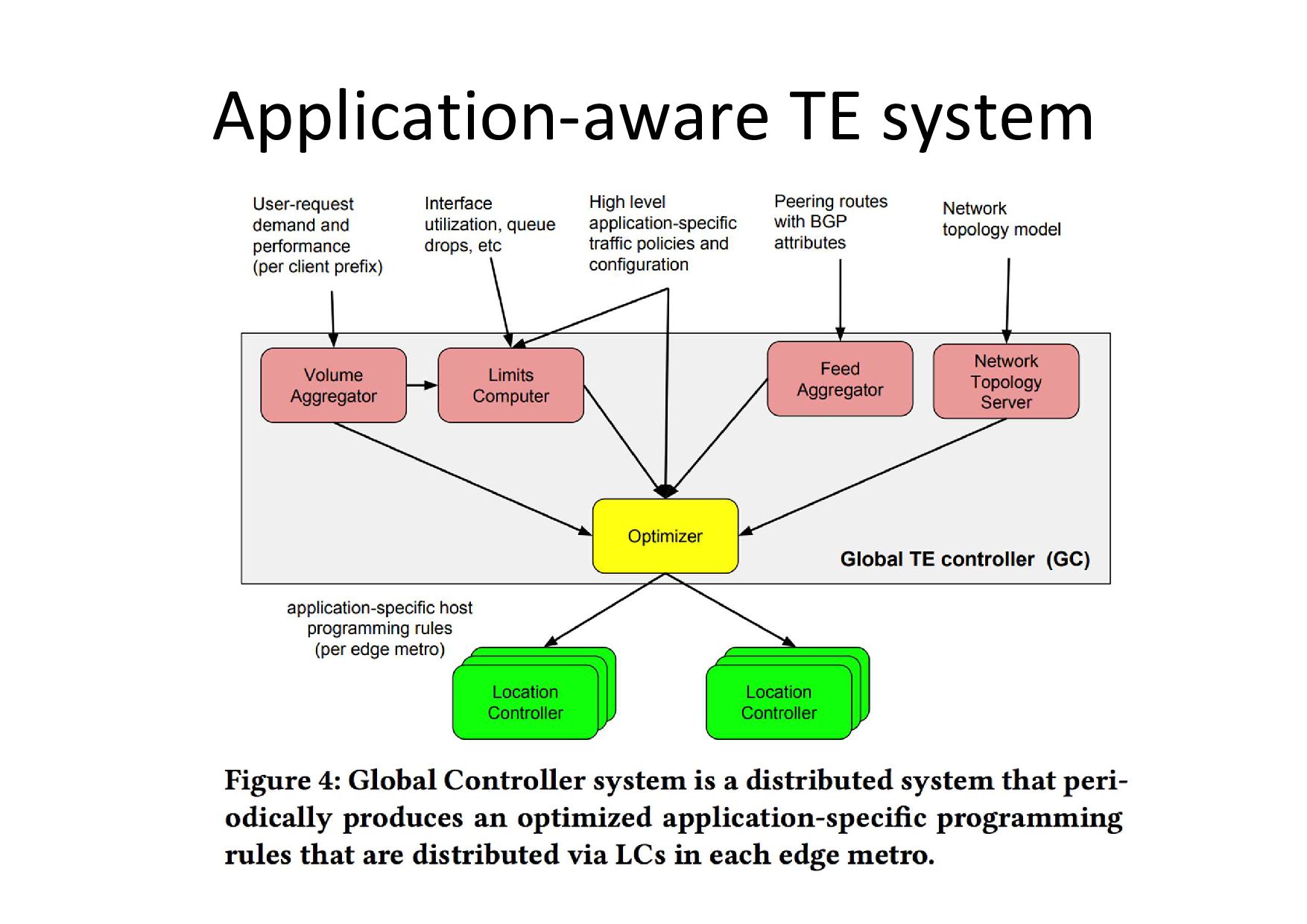
Application-aware TE system
FIBのプログラミング • Internet Scale の FIB はReverse Proxy にあ り!
– DRAMに保持(評価は後述) • 適用順序 – GCが全てのBGP/品質/コスト情報を集める – application-aware FIBを計算し、結果をLCに渡す – LC が FIB を host のパケットプロセッサにインス トール
GC: Global TE Controller • GCはレガシーとEspresso両方をサポートしている • GCの出力は、 – <PoP,
Client Prefix, Service Level> に対する <PR/PF の出力 port のリスト> – egress mapと呼ぶ – ひらたく言うと、「このPoPの、このユーザprefixの、このサービス (Youtubeとか…)は、このルータのこのportから出力する」という ルール • GCの入力は、 – 1) Peering Route – 2) User Bandwidth Usage and performance – 3) Link utilization – と、コストなどのハイレベルなポリシ(論文では強調していないが)
1) Peering Route • LCがPoP内のBGP Speaker(PR/PF両方)から経 路情報を集め、GCに伝える • GC内の Feed
Aggregator がLCからの情報を集 約する – AS-PATHなどの通常のBGP attribute 情報を利用し て、prefixごとの出口ポートの優先リストを作成
2) User Bandwidth Usage and performance • Reverse proxyで計測した client
prefix ごとの bandwidth, throughput, RTT, retransmitなどの 情報を、GCの Volume Aggregator が集める • client prefix は /24 (IPv6は/48)ごと • Routing情報の中で、/24単位でlatencyに偏り があった場合、同程度の品質の塊になるよう に de-aggregation(prefix分割)する – この動作を額面どおり受け取るならば、分割した経 路をBGPに乗せたりはしない
3) Link utilization ピアリングリンクの使用率 • リンク使用率、パケットドロップ率、リンク速度を計算にいれる • GCの Limit Computer
がこの情報をユーザの要求(=ダウン ロードトラフィック量)と結びつけて、service class, link ごとに帯 域を割り当てる • dropがあるようなリンクはアグレッシブに割り当てを減らす • peering link の利用率を17%改善(後述) エンドツーエンド品質 • end-to-end の path のクオリティをReverse Proxyで計測 – 最良時の品質でclient prefix, AS-path, peering linkをグループ化 • このグループごとに、品質劣化時に混雑しているリンクから動 かす • 170%ユーザ体感を改善(後述)
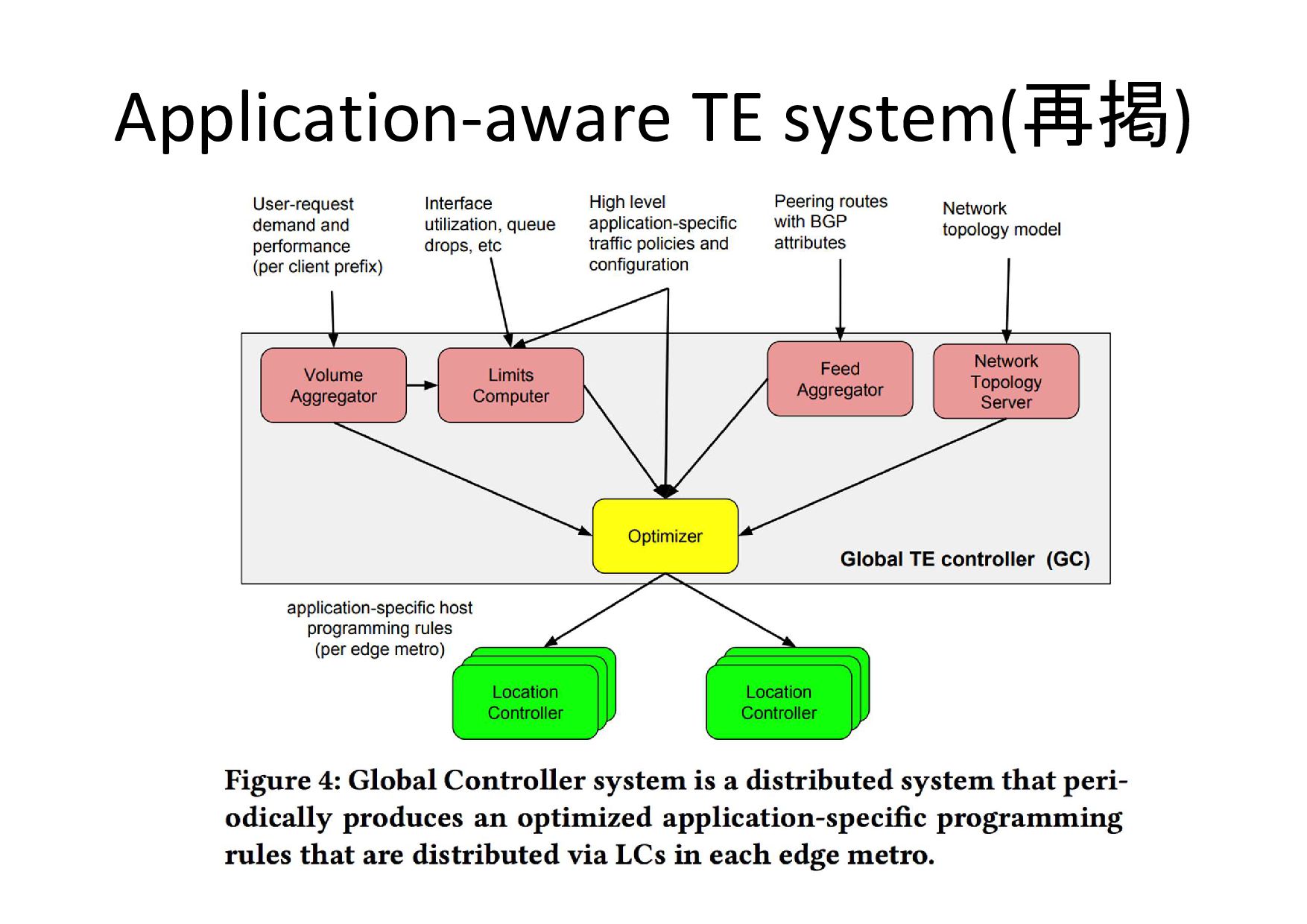
Application-aware TE system(再掲)
最適化? • どのような重み付けの計算をしているかは、論 文からは不明 • 最適化手法 – 線形計画法(LP)より早いので貪欲法(greedy)を採 用 –
LPよりもlatencyが3-5%少ないという結果がでたが、 Future Work
ピアのリンク帯域の利用方法(貪欲法) • 優先順の高いトラフィックから帯域を割当 – 最良リンクに最優先トラフィックから順に割当 – リンクの容量を超えたら次のリンクに割当 • リンク障害があっても優先度の高いトラフィックが 救われるように、割当の余地を残しておく
– 余地はパケロスに強い低優先トラフィック(low QoS)で 埋める – キューのドロップを起こさないまでのトラフィックレベル を動的に決定して詰め込む • 計測パケット損失率が閾値以上になったら他経路を利用
安全性(safety) • 計算結果が前回と異なりすぎる場合は前回結果 を用いるなどの保守的な動作をする – last-valid map を信頼する • GCの冗長化
– 複数データセンタに分散 – 分散ロック方式でマスター選出 • GCから通知されたegress map をLCはまずは一部 のパケットプロセッサに適用(炭鉱のカナリア) – サービス影響時にはロールバック&エンジニアへのエ スカレーション これはBGPの制御では難しい これはBGPの制御では難しい
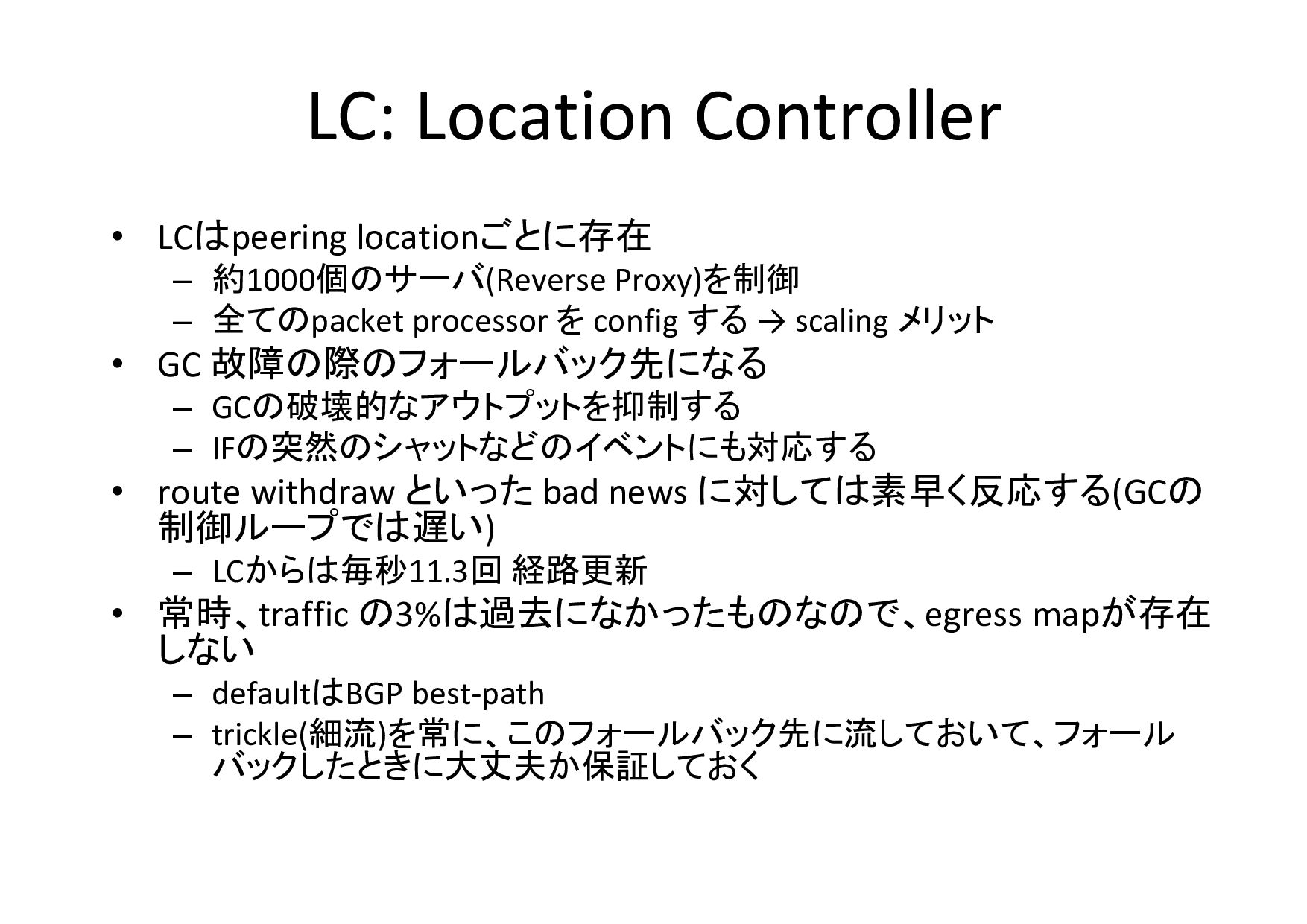
LC: Location Controller • LCはpeering locationごとに存在 – 約1000個のサーバ(Reverse Proxy)を制御 –
全てのpacket processor を config する → scaling メリット • GC 故障の際のフォールバック先になる – GCの破壊的なアウトプットを抑制する – IFの突然のシャットなどのイベントにも対応する • route withdraw といった bad news に対しては素早く反応する(GCの 制御ループでは遅い) – LCからは毎秒11.3回 経路更新 • 常時、traffic の3%は過去になかったものなので、egress mapが存在 しない – defaultはBGP best-path – trickle(細流)を常に、このフォールバック先に流しておいて、フォール バックしたときに大丈夫か保証しておく
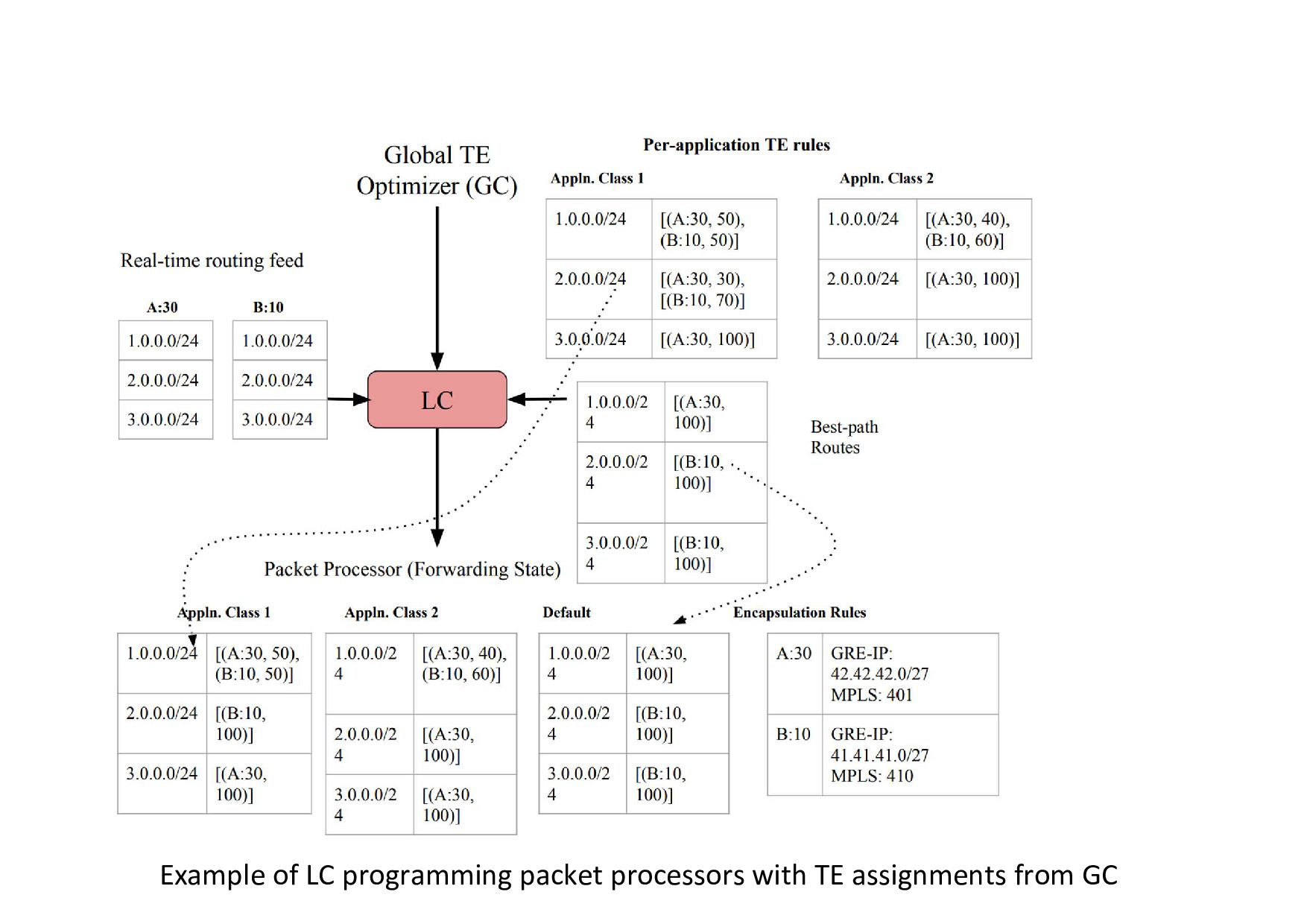
Example of LC programming packet processors with TE assignments from
GC
Example of LC programming packet processors with TE assignments from
GC ルータAのポート30 から転送する場合 は、このGRE-IPと MPLSラベルでカプ セル化 このユーザプレフィックス(1.0.0.0/24)の、このサービ ス(App Class1) については、ルータAのポート30から 50%, ルータBのポート10から50%トラフィックを出す、 というルール(egress map) がGCから与えられる LCは、BGPでのベストパスをデフォルトとして、各 サービスのトラフィックをリンクに割り当てていく
Internet ACL • GoogleのACLは商用シリコンでは書ききれない – しかし、計測してみると、5%のACLが99%のトラフィック ボリュームを占める – 一部のACLだけPF(MPLS SW)に書いて、残りはホスト
(Reverse Proxy)で処理 – 粗いザル→細かいザル • ACLルールもLCからサーバに配布される – ACLのテストのために、一つのLCにだけ適応して様子を 見る(これも炭鉱のカナリア) • サーバのパケットプロセッサでのACLは、高度な DoS対策も実現できる
モニタリング • データプレーンでの障害は即座にコンロトーラに 送られる – 例えば、ピアダウンは BGP timeout を待つことなく、 BGP
speaker に伝わる • コントロールプレーンのイベントは全てHTTP/gRPC エンドポイントに送られる • Prometheus で可視化 • end-to-end probeも活用 – ACLの有効/無効を調べる • モニタリングに関する記述は残念ながら少ない
5. 評価(効果)
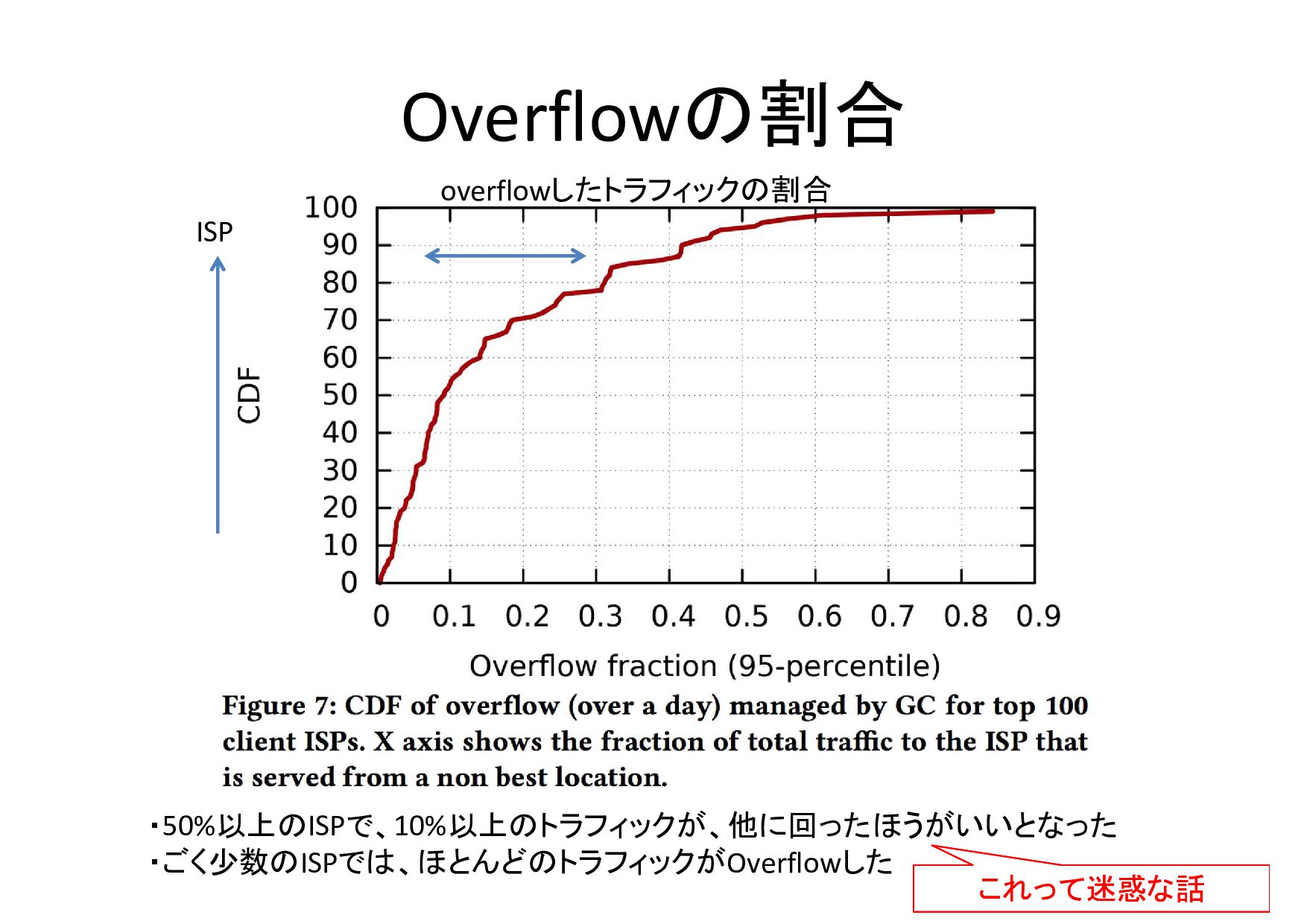
Overflow • ベスト経路と異なるpeerに流したトラフィックを overflow と定義 – 同一Metro内の別ピア: 30% – 別のMetroに回されるもの:
70% • 機構がなかった時と比較して、ピーク時により 多くのトラフィック(13%)を流せる
Overflowの割合 overflowしたトラフィックの割合 ISP ・50%以上のISPで、10%以上のトラフィックが、他に回ったほうがいいとなった ・ごく少数のISPでは、ほとんどのトラフィックがOverflowした これって迷惑な話 これって迷惑な話
ピアのリンク使用率の向上 使用帯域(95%タイル値) ピアの リンク ・使用率50%以上(95%タイル値)のピアが40%程度 ・使用率80%以上のピアが17% これは、調査によると業界の平均的な使用率より高い かなり詰めてる かなり詰めてる
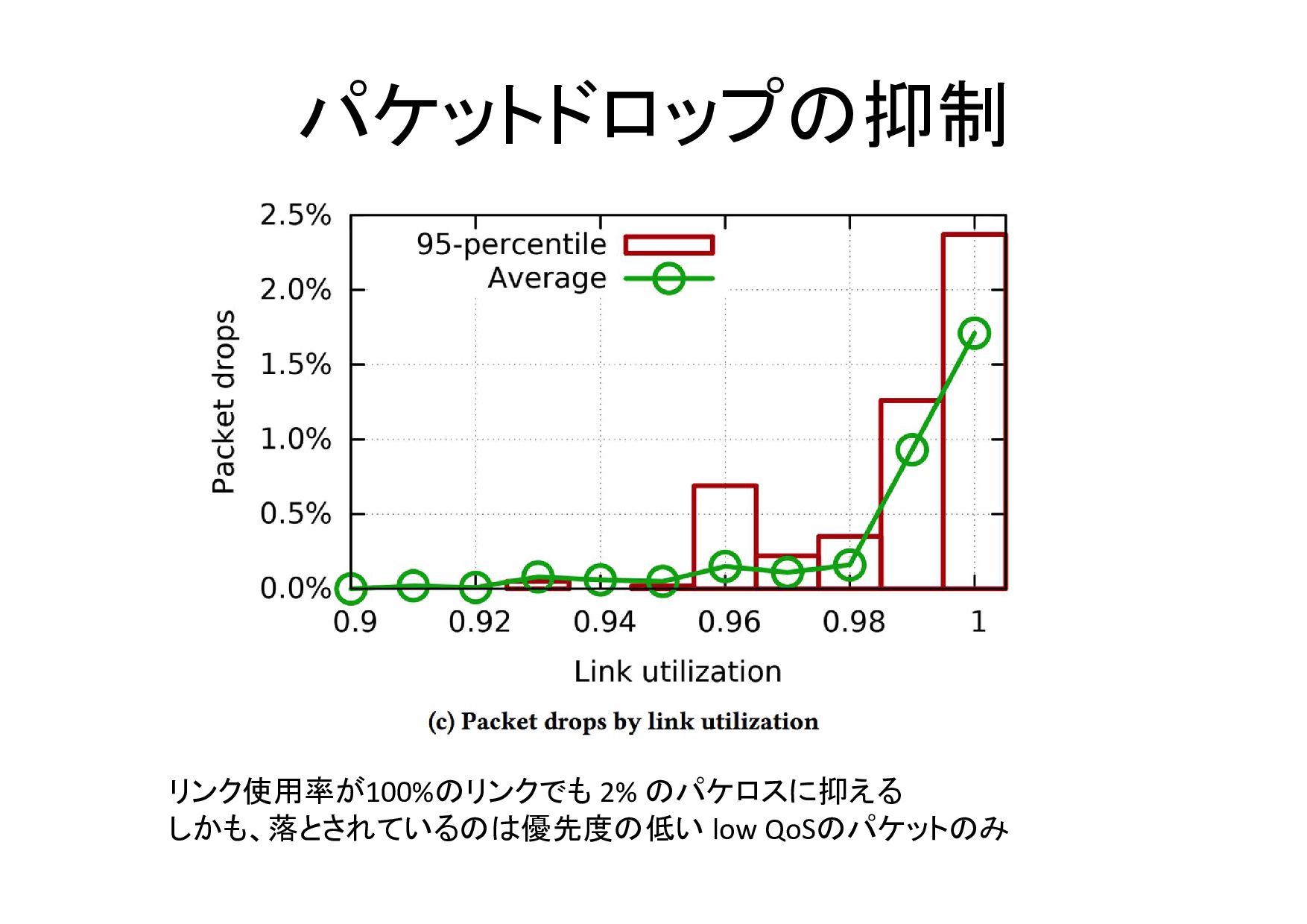
パケットドロップの抑制 リンク使用率が100%のリンクでも 2% のパケロスに抑える しかも、落とされているのは優先度の低い low QoSのパケットのみ
End-to-End のQoEの向上 video streaming service の QoEを劇的に高める リバッファリング(動画の停止)の平均発生間隔(MTBR)が彼らの重 要な尺度らしい GoogleとISPでのピアでの輻輳はなかったので、Googleの外部の
輻輳を回避できたと主張している
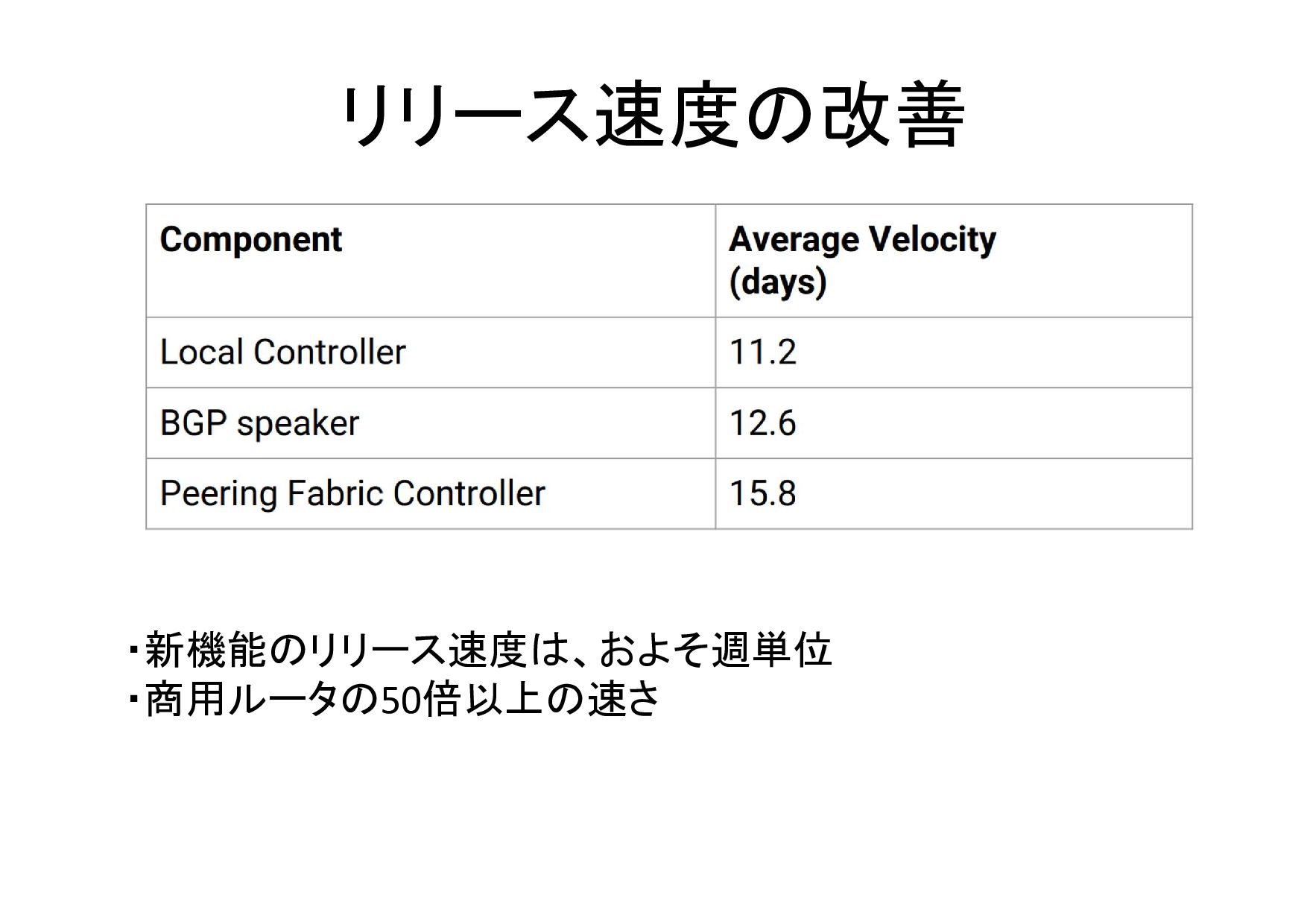
リリース速度の改善 ・新機能のリリース速度は、およそ週単位 ・商用ルータの50倍以上の速さ
BGP Speakerの評価 • ソフトウェアBGP Speakerとして以下を比較 – Quagga/Bird/XORP/Raven(内製) • 最初は Quagga
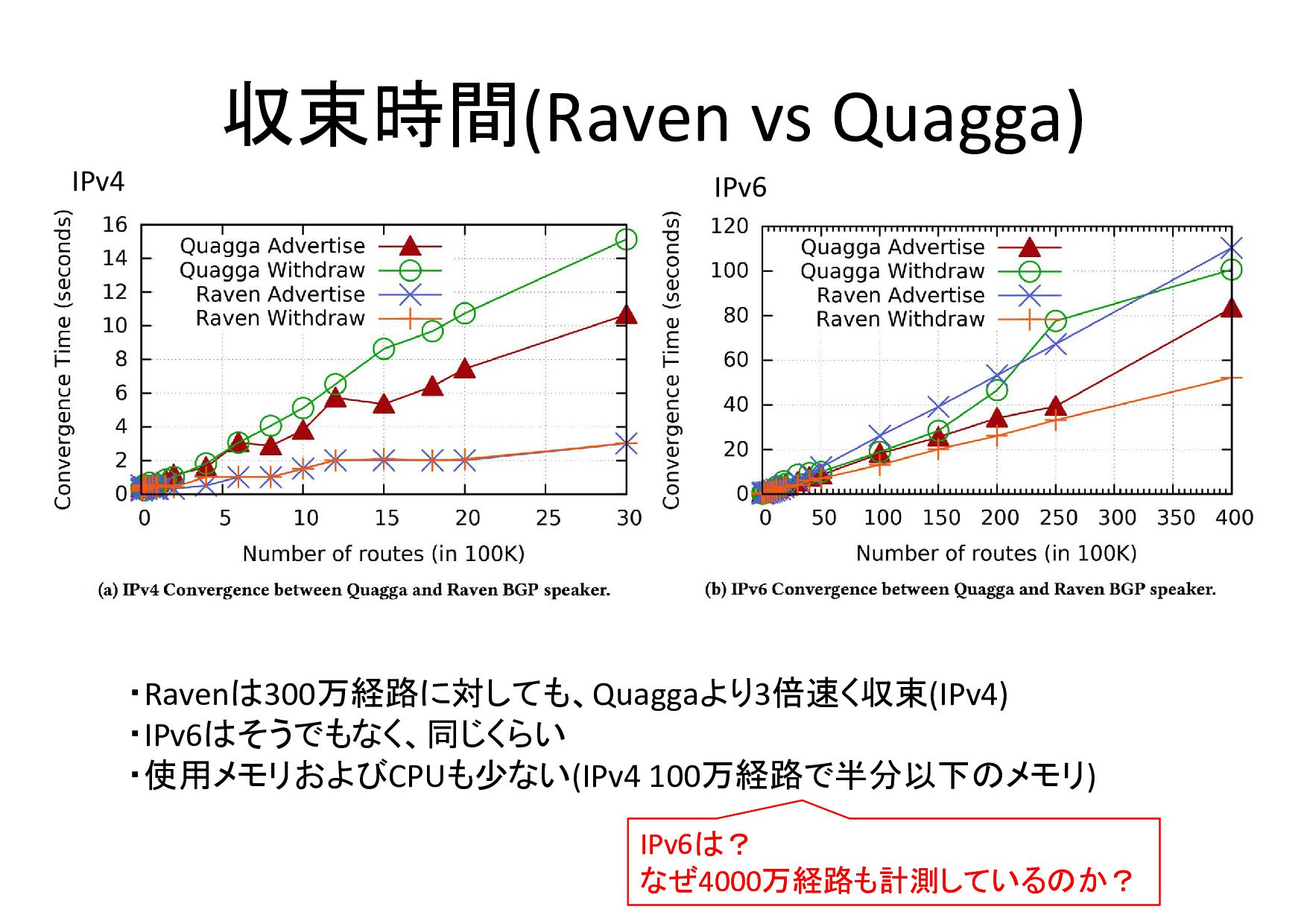
を使ったが以下の問題があっ た – single thread – C based – limited testing support • 収束時間が決め手でRavenを採用した – 比較は主にB4プロジェクトで実施
収束時間(Raven vs Quagga) IPv4 IPv6 ・Ravenは300万経路に対しても、Quaggaより3倍速く収束(IPv4) ・IPv6はそうでもなく、同じくらい ・使用メモリおよびCPUも少ない(IPv4 100万経路で半分以下のメモリ) IPv6は?
なぜ4000万経路も計測しているのか? IPv6は? なぜ4000万経路も計測しているのか?
収束時間(Raven vs 市販ルータ) IPv4+IPv6(実際のフルルートからの抜粋) ・市販のルータよりも、収束早い ・実際のフルルートから抜粋した様々なルートセットで計測 ・CPU数やメモリサイズが市販ルータの10倍以上だったので、当然の結果 60万経路 60万経路
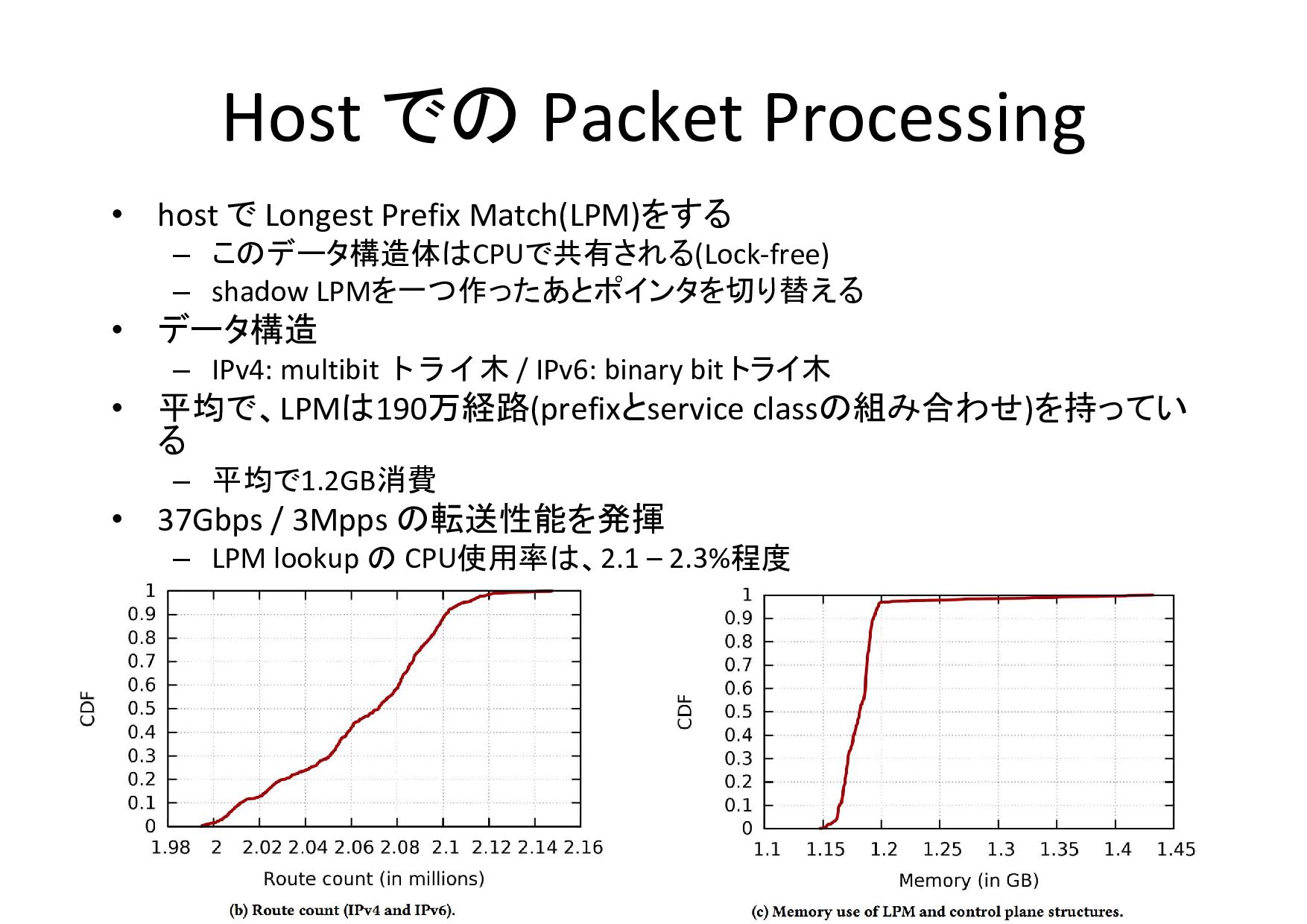
Host での Packet Processing 60万経路 60万経路 • host で Longest
Prefix Match(LPM)をする – このデータ構造体はCPUで共有される(Lock-free) – shadow LPMを一つ作ったあとポインタを切り替える • データ構造 – IPv4: multibit トライ木 / IPv6: binary bit トライ木 • 平均で、LPMは190万経路(prefixとservice classの組み合わせ)を持ってい る – 平均で1.2GB消費 • 37Gbps / 3Mpps の転送性能を発揮 – LPM lookup の CPU使用率は、2.1 – 2.3%程度
6. 実運用での経験から
(1)Reporting Library のバグ • 全てのソフトウェアが同一のレポーティングラ イブラリを使っていた – 同ライブラリのバグによるスレッド枯渇でcontrol- plane の全滅
– Espresso経由のトラフィックが全てレガシーのルー タにフォールバックした • ワークアラウンドとして有効だったので、ユーザには気 づかれなかった • 結合試験にコントロールとマネジメントプレー ンのコンポーネントも入れるべき
(2) Localized control plane for fast response • Espresso導入当初は2階層モデルではなく、GCだけを 使っていた
• ピアがアップして新しいprefixを受け取ってもすぐに使 われない – (経路揺らぎを抑える機構で)GCへの経路の伝搬に時間を 要していたため • LCでデフォルトのトラフィックパターンを計算するように 変更した – GCでの上記の計算がなくなり経路反映が早くなった – Metro内でのフォールバックも可能に • 階層型のコントロールプレーンは、全体の最適化と信 頼性の向上の両方に寄与することを学んだ
(3) Global drain of PF traffic • オペミスで、全ての Espressoからトラフィックを抜 く設定をGCに入れてしまった(!)
– レガシーのルータにフォールバックしたのでこちらも ユーザ影響は最小だった • セーフティチェックの強化 – 試験環境でのシミュレーションにおいて、大きなトラ フィック移動が発生する時はエラー扱いにした – さらに追加の仕組みをGCに入れた(具体的には不明) • 中央集権的SDNは危険なので安全チェックが多 重に必要 Googleも意外と人間的 Googleも意外と人間的
(4) Ingress traffic blackholing • 一部のACLしかPFに入っていない状況(PFのTCAMに上 限があるため)で、PF経由で全トラフィックを引き込ん でしまい、ACL(allow)に書いていないVPN系のトラフィッ クがブラックホールされてしまった •
一番の大規模障害 – バックボーンルータでの設定変更(no-export か何か?)で、 レガシーのPRからの広報が止まった、と読める • ACLの精査と、hostでのACLの展開を進めるきっかけに なった • 既存インフラへの少しの変更が大きな障害を引き起こ すことがあると認識
7. Facebookとの比較
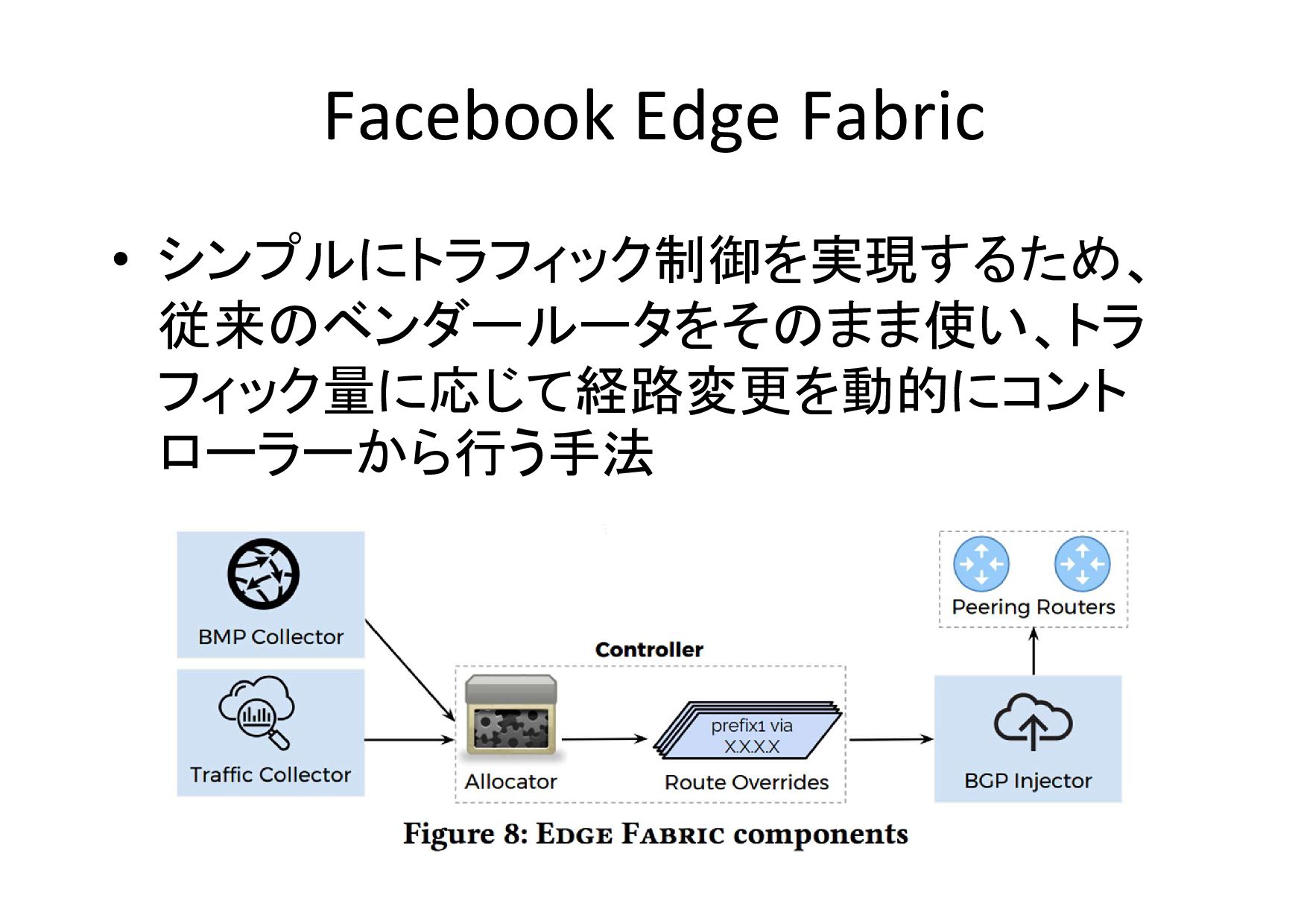
Facebook Edge Fabric • シンプルにトラフィック制御を実現するため、 従来のベンダールータをそのまま使い、トラ フィック量に応じて経路変更を動的にコント ローラーから行う手法
Facebook Edge Fabric • 従来のベンダー製ルータを利用して外部ASとのピアリ ングを行う – 今までの運用ノウハウを生かす – 万が一コントローラーで障害が発生したとしても従来通り
動き続ける • トラフィック最適化方法 – ピアやIX向けのリンク帯域が不足している場合にトラ フィックを分割し、 分割したトラフィックを別のリンクへ迂回 させるという最適化 • 実現方法 – トラフィック量を監視し経路を最適化するコントローラーを 用意し、BGPで経路をルータに注入し、トラフィックを迂回 させる
Googleからの視点では • 目的が若干異なる – Facebook: 拠点のピアの輻輳をさける – Google: 全体でのトラフィック最適化 •
Facebook は、トラフィックの切り替えをBGPに 頼っている(のがいけていない) • また、MPLS SWを採用しているのでBGPルー タよりも安い • Facebook 対処できていない種類の輻輳問題 にも対処できている
Facebookからの視点では • 最適化手法のデザインに大きな違いがある – Facebook: 運用コストを考慮したシンプルな手法 – Google: プログラマビリティを重視した手法 •
Google は、複雑なコントローラアーキテクチャが 必要 – HostでのFIBを全体で同期できないと、ブラックホール になる危険性が高い • 最適化結果の制御をピアリングルータにのみ プッシュするので、Hostをルーティングから分離 できる(ので運用しやすい)
8. まとめ
論文のまとめ • 新規性 – エンドユーザのメトリックを導入したセントラライズ ドなSDNはいままでなかった • 特徴 – 保守的動作(fail
safe)、部分的導入、相互運用 性、プログラマビリティ、試験のしやすさ • 達成 – グローバルトラフィック最適化、End-to-End のQoE 向上、開発スピードの向上、コストダウン
読者視点のまとめ • コストダウンとはいえ、既存のReverse Proxy の余剰計 算リソースの活用による効果 • Googleの規模感(複数PoP、ピア)がないと、”グローバ ル最適化”の旨味がない •
Host の Packet Processor のプログラミングの詳細につ いては、論文では明らかにされていない • BGP機能の分離やACLの外部化など、アーキテクチャ 設計のヒントになる要素は散りばめられている • ISPの視点では、制御方法の内情が明らかになったの で、対Googleの運用のヒントになるのでは • Google でも人為ミスはする
FAQ • Espressoピアは見分けられますか? – 経験はないですが、対向のMACアドレスを見たり、 BGPのOPENメッセージなどの特徴を見ればわかるか もしれません。 • TEはどのようなロジックなのでしょうか。ISP側か らコントロールすることはできないでしょうか?
– TEのロジックは外部からはわかりません – ISP側からも品質を測定することで想定外のOverflow を指摘するといったことは可能かもしれません
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![GoogleのSDN技術 • Jupiter [SIGCOMM 2015] • B4 [SIGCOMM 2013] –](https://files.speakerdeck.com/presentations/6442617562ac429ba1efaf651e8babbe/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}