Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
トランクベース開発の実現に向けた開発プロセスとCIパイプラインの継続的改善
Search
Sponsored
·
SiteGround - Reliable hosting with speed, security, and support you can count on.
→
aanrii
March 20, 2023
Programming
6k
7
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
トランクベース開発の実現に向けた開発プロセスとCIパイプラインの継続的改善
CI/CD Conference 2023
https://event.cloudnativedays.jp/cicd2023/talks/1774
aanrii
March 20, 2023
Other Decks in Programming
See All in Programming
技術記事、 専門家としてのプログラマ、 言語化
mizchi
13
7.1k
Datadog LLM Observabilityで実現する 安全なLLM Usage 管理
3150
0
130
[2026年度第1回ORセミナー] 計画最適化ベンチャーと競技プログラミング人材
terryu16
0
280
スマートグラスで並列バイブコーディング
hyshu
0
270
Oxcを導入して開発体験が向上した話
yug1224
4
360
Hunting Vulnerabilities in Symfony with LLMs
vinceamstoutz
0
570
コンテキストの使い捨てをやめる — ビジネスルール駆動開発と miko —
ioki
0
260
技術的負債解消で開発者の未来を開く- AIの力でコード刷新
kmd2kmd
0
130
セキュリティの専門家じゃなくてもできる。「セキュリティ意識」をアップデートして サプライチェーン攻撃への耐性を高めよう。
tk3fftk
5
1k
ローカルLLMを使ってB2Bサービスを作っていての学び
yaotti
0
220
ランチタイムLT会3周年!ランチタイムLT会を3年間続けられたお話
y0hgi
1
120
Developing with AI Agents — Codex, Claude Code & Cowork Practical Guide
x5gtrn
PRO
0
1.3k
Featured
See All Featured
Music & Morning Musume
bryan
47
7.3k
Prompt Engineering for Job Search
mfonobong
0
360
What Being in a Rock Band Can Teach Us About Real World SEO
427marketing
0
1k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
290
Stop Working from a Prison Cell
hatefulcrawdad
274
21k
Ruling the World: When Life Gets Gamed
codingconduct
0
270
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.4k
Embracing the Ebb and Flow
colly
88
5.1k
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Automating Front-end Workflow
addyosmani
1370
210k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.6k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
Transcript
トランクベース開発の実現に向けた 開発プロセスと CIパイプラインの継続的改善 合同会社DMM.com 小林杏理
小林杏理 https://twitter.com/aanriit 合同会社DMM.com プラットフォーム事業本部第三開発部 マイクロサービスアーキテクトグループ 認証認可チーム リーダー 専門領域: Webバックエンド、DevOps、Go システムアーキテクチャ
トランクベース開発とは • バージョニング (ex. git) を使った開発の速度を向上するための方法論 • 認証認可チームでは、トランクベース開発を導入し 開発のサイクルタイムを短く保つことに成功
トランクベース開発とは • バージョニング (ex. git) を使った開発の速度を向上するための方法論 • 認証認可チームでは、トランクベース開発を導入し 開発のサイクルタイムを短く保つことに成功 →サイクルタイムとは?
Four Keys GoogleのDevOps Research and Assesment (DORA) チームが提唱する ソフトウェア開発チームのパフォーマンスを示す 4
つの指標 • デプロイの頻度 - 組織による正常な本番環境へのリリースの頻度 • 変更のリードタイム - commit から本番環境稼働までの所要時間 • 変更障害率 - デプロイが原因で本番環境で障害が発生する割合(%) • サービス復元時間 - 組織が本番環境での障害から回復するのにかかる時間
Four Keys GoogleのDevOps Research and Assesment (DORA) チームが提唱する ソフトウェア開発チームのパフォーマンスを示す 4
つの指標 • デプロイの頻度 - 組織による正常な本番環境へのリリースの頻度 • 変更のリードタイム - commit から本番環境稼働までの所要時間 ◦ 短ければ短いほど、開発チームのアウトプットの最大化につながる • 変更障害率 - デプロイが原因で本番環境で障害が発生する割合(%) • サービス復元時間 - 組織が本番環境での障害から回復するのにかかる時間
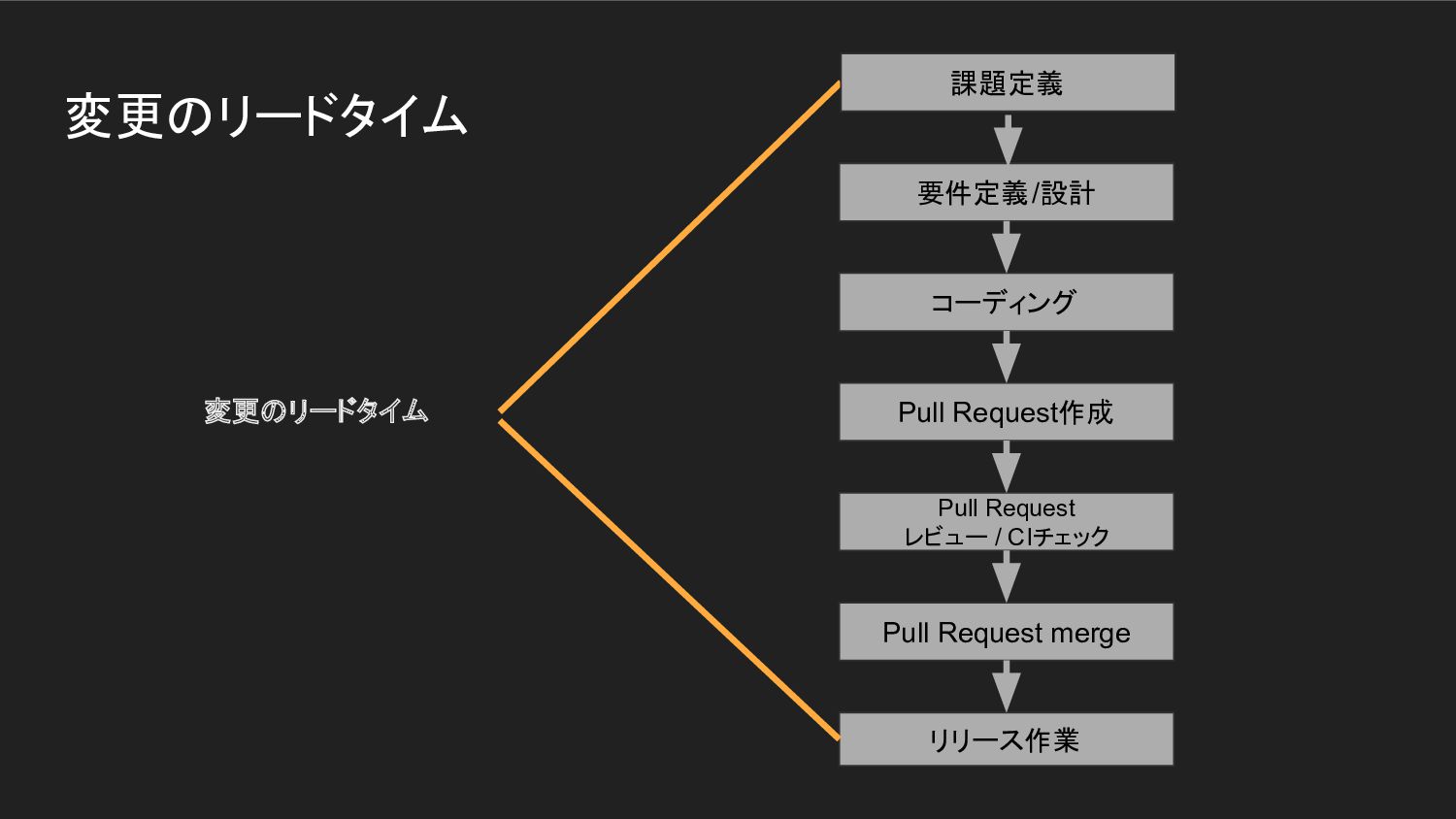
変更のリードタイム コーディング Pull Request作成 Pull Request レビュー / CIチェック Pull
Request merge リリース作業 要件定義/設計 課題定義
変更のリードタイム コーディング Pull Request作成 Pull Request レビュー / CIチェック Pull
Request merge リリース作業 要件定義/設計 変更のリードタイム 課題定義
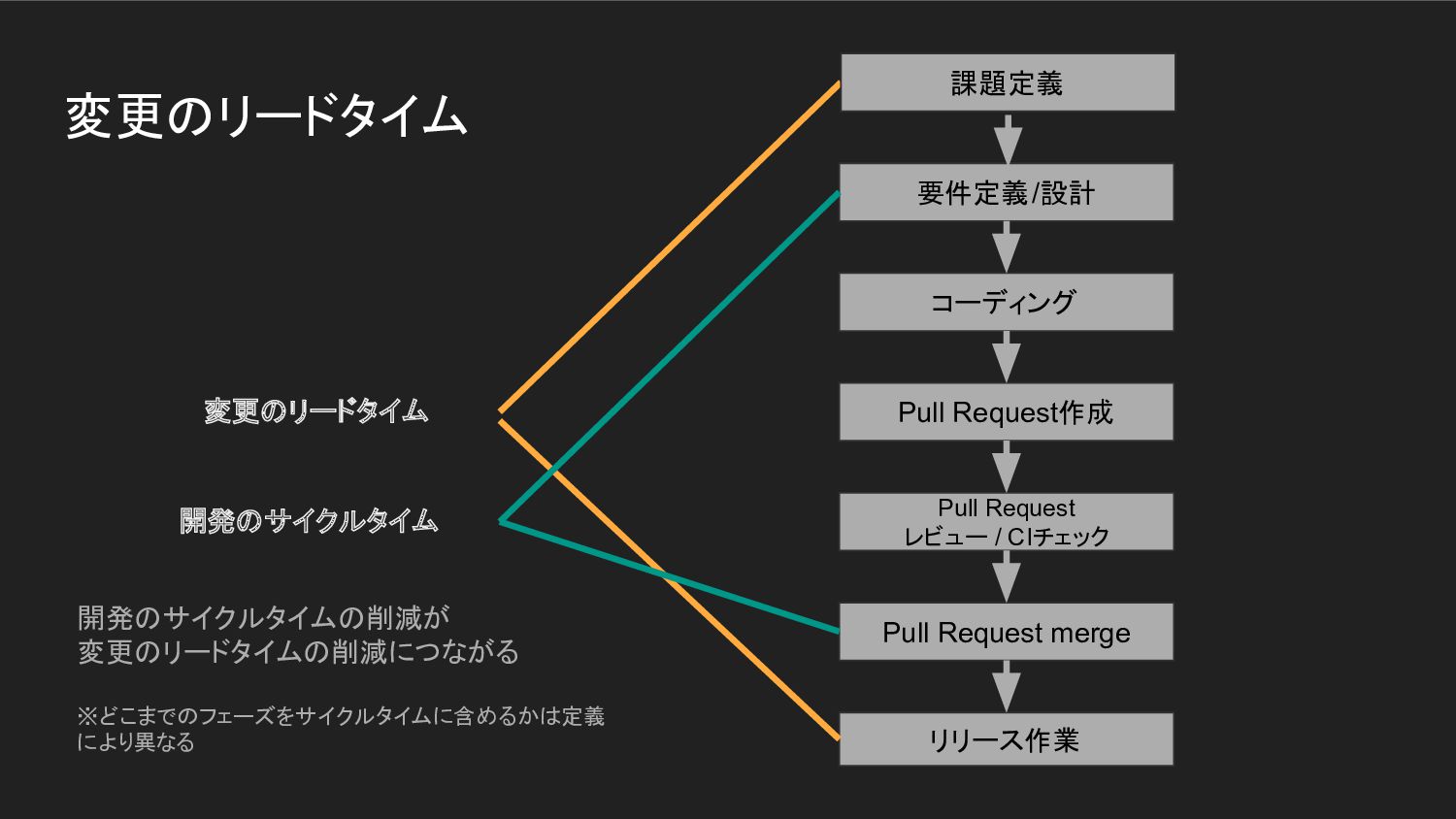
変更のリードタイム コーディング Pull Request作成 Pull Request レビュー / CIチェック Pull
Request merge リリース作業 要件定義/設計 変更のリードタイム 課題定義 開発のサイクルタイム 開発のサイクルタイムの削減が 変更のリードタイムの削減につながる ※どこまでのフェーズをサイクルタイムに含めるかは定義 により異なる
トランクベース開発のねらい 開発のサイクルタイムの短縮を通じて変更のリードタイムを短縮し 開発チームのアウトプットを最大化する
アジェンダ • トランクベース開発とは? • トランクベース開発をどのように実践したか? • 開発フローをどのように改善していったか?
トランクベース開発とは?
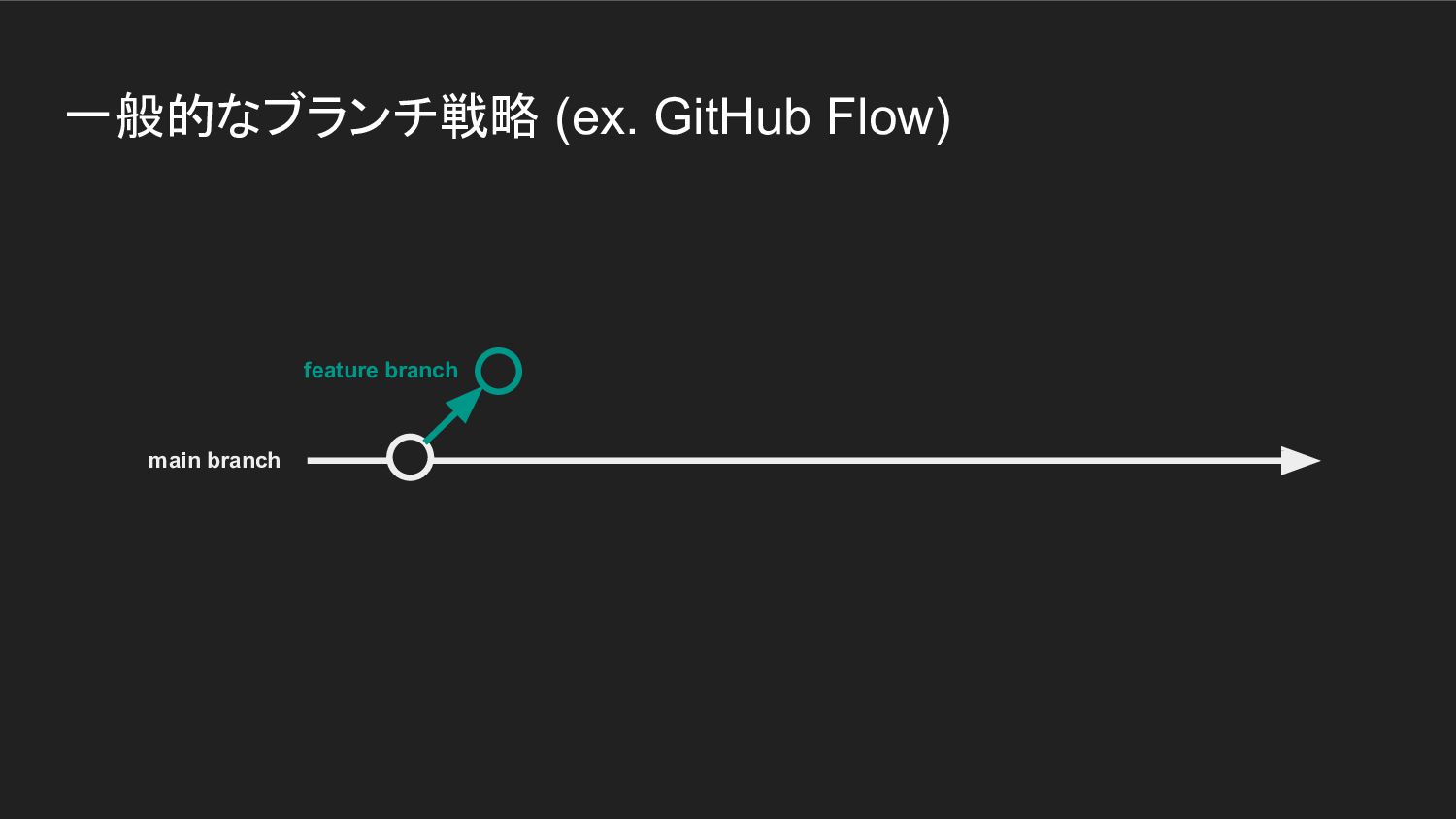
トランクベース開発とは • バージョニング (ex. git) を使った開発の速度を向上するための方法論 • ブランチ戦略の一種とも言える
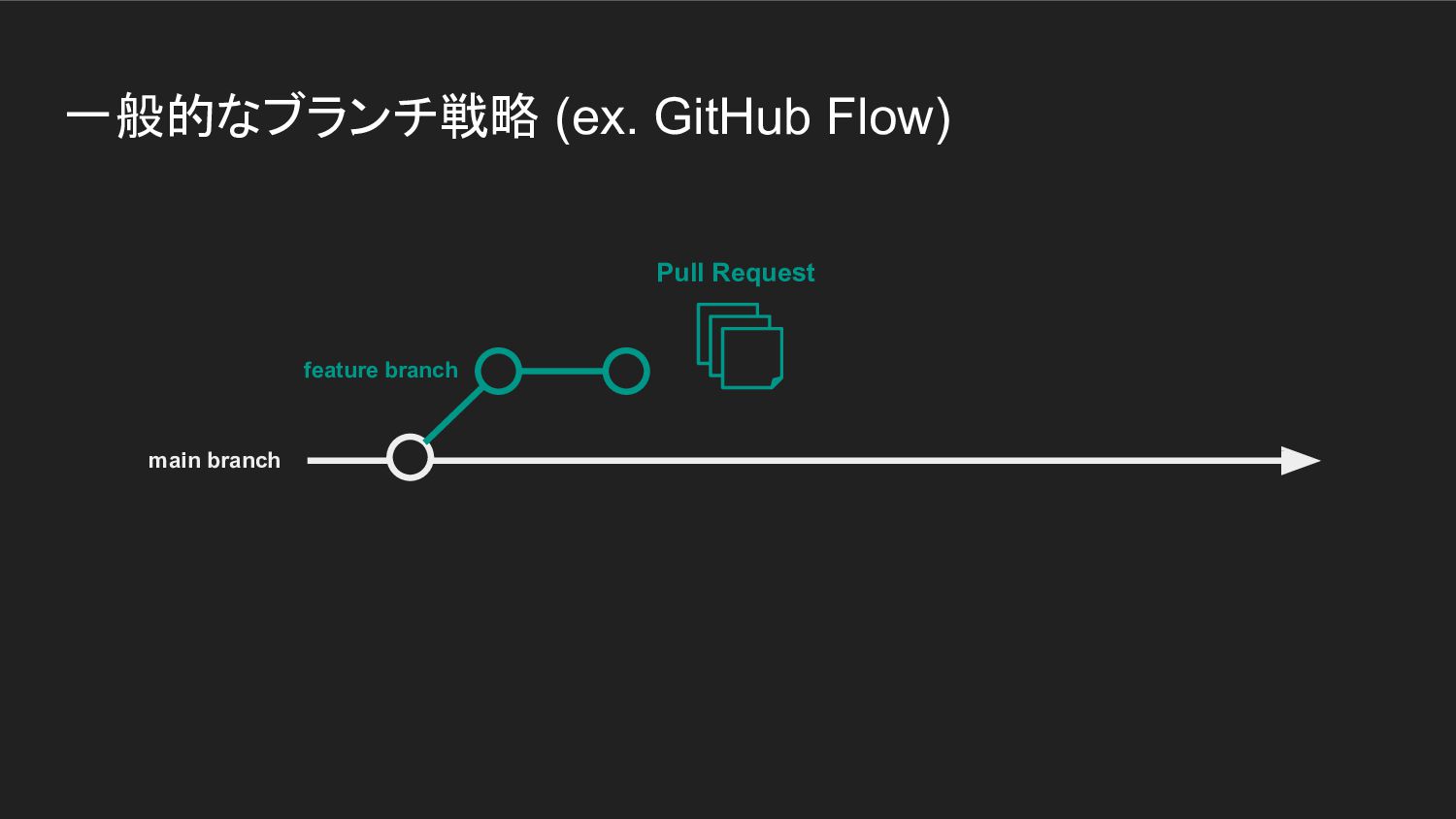
一般的なブランチ戦略 (ex. GitHub Flow) main branch
一般的なブランチ戦略 (ex. GitHub Flow) feature branch main branch
一般的なブランチ戦略 (ex. GitHub Flow) Pull Request feature branch main branch
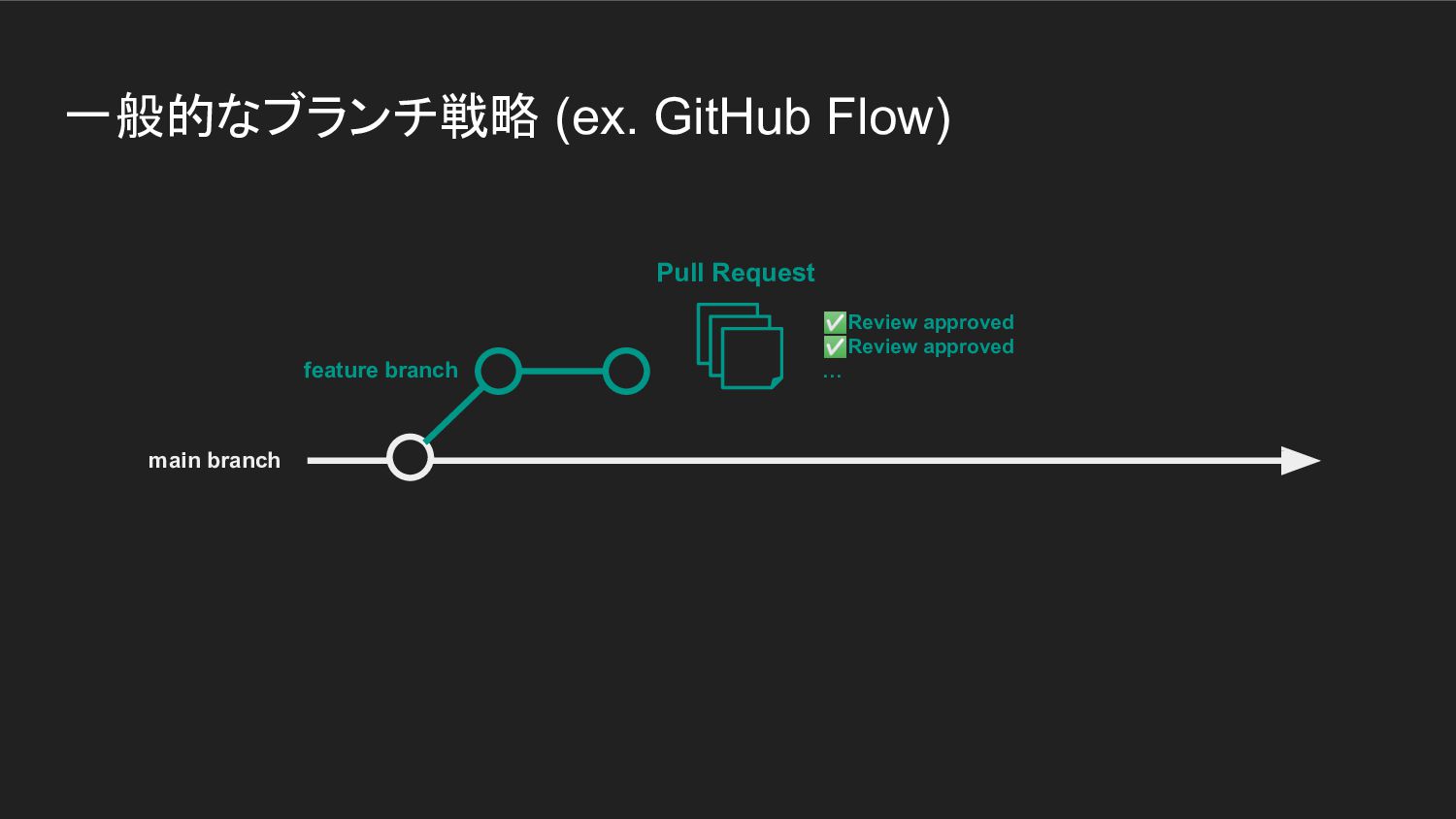
一般的なブランチ戦略 (ex. GitHub Flow) Pull Request feature branch main branch
✅Review approved ✅Review approved …
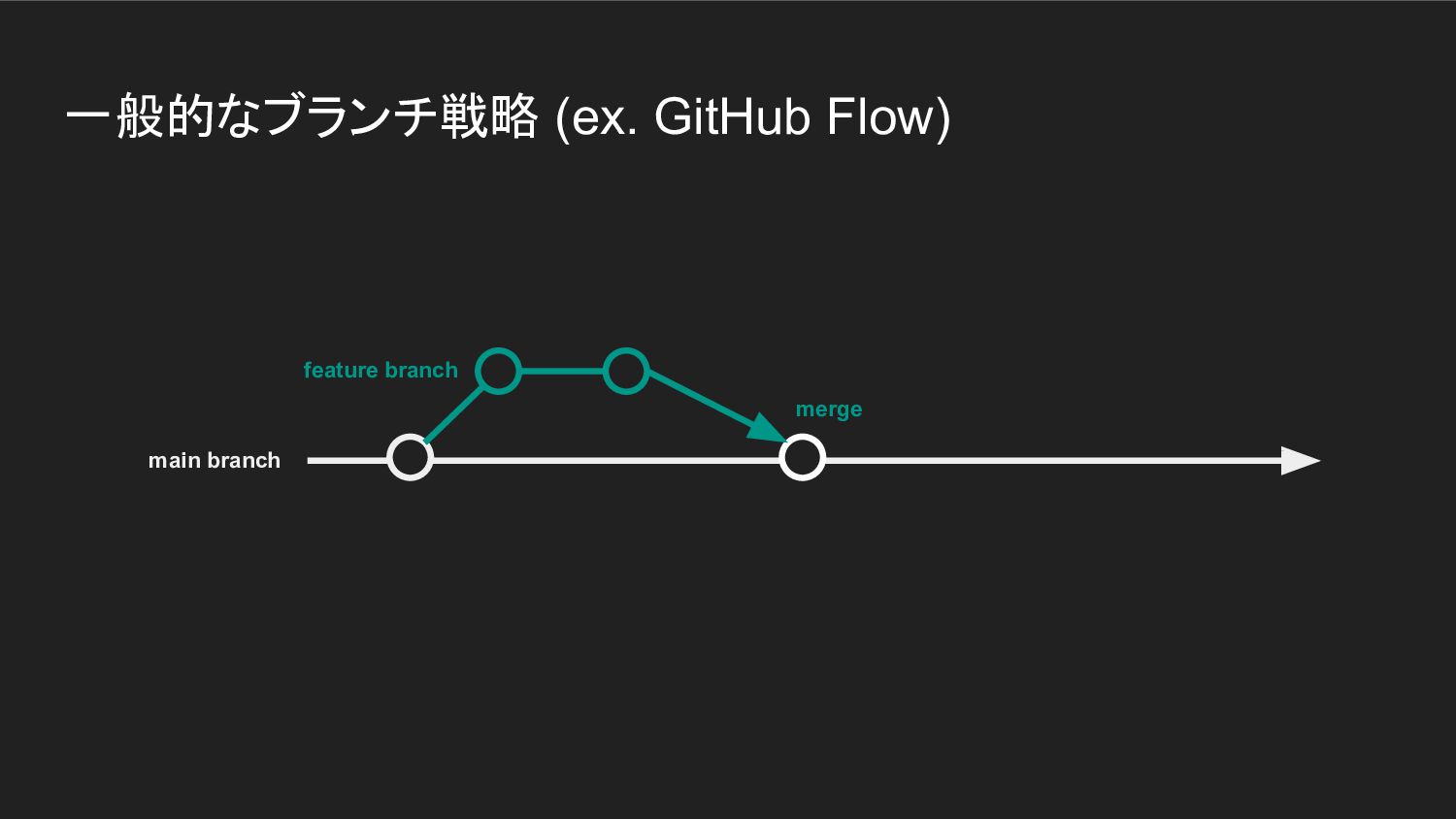
一般的なブランチ戦略 (ex. GitHub Flow) merge feature branch main branch
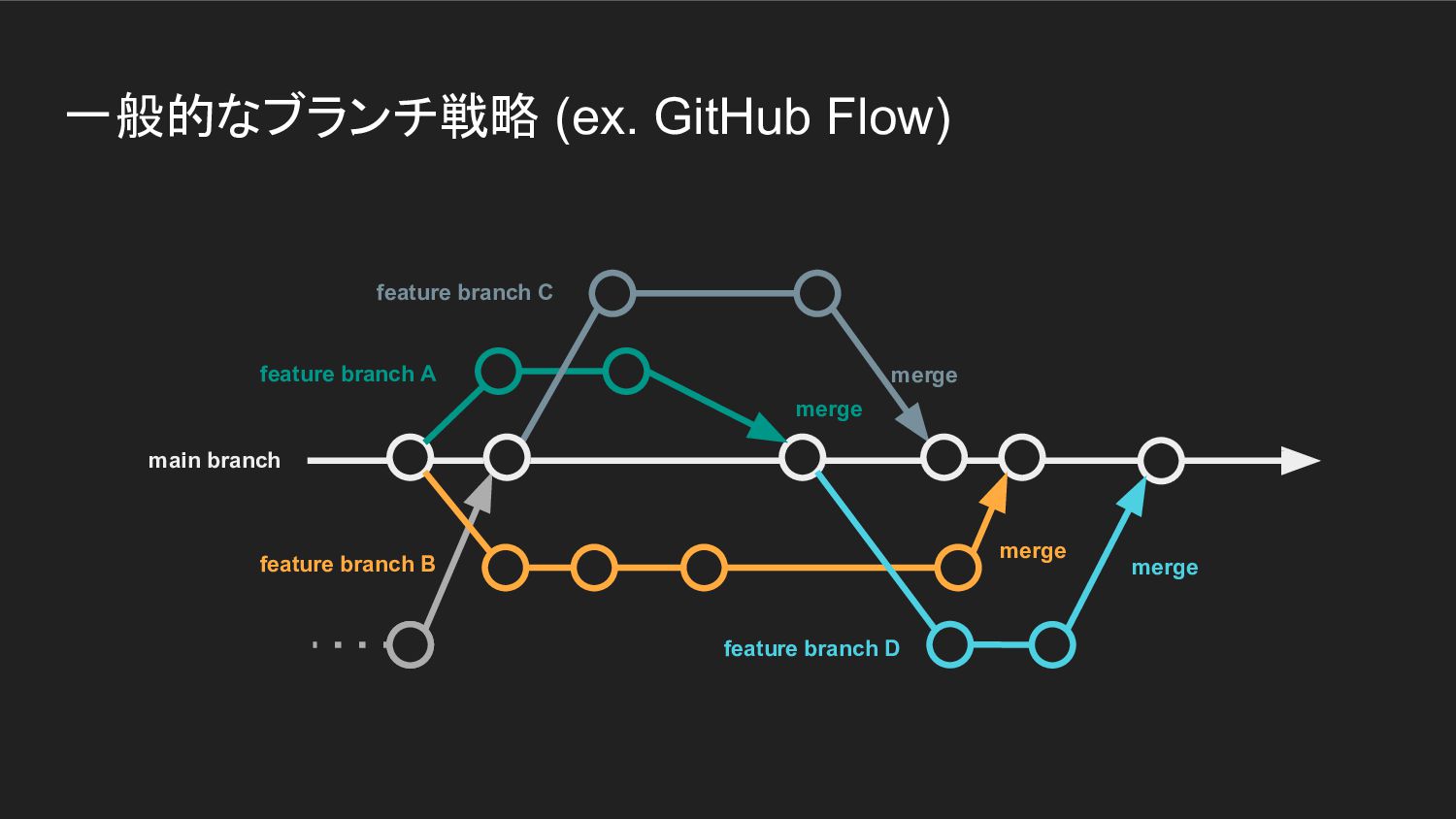
一般的なブランチ戦略 (ex. GitHub Flow) main branch feature branch A feature
branch B merge merge
一般的なブランチ戦略 (ex. GitHub Flow) main branch feature branch A merge
merge merge feature branch D feature branch B feature branch C merge
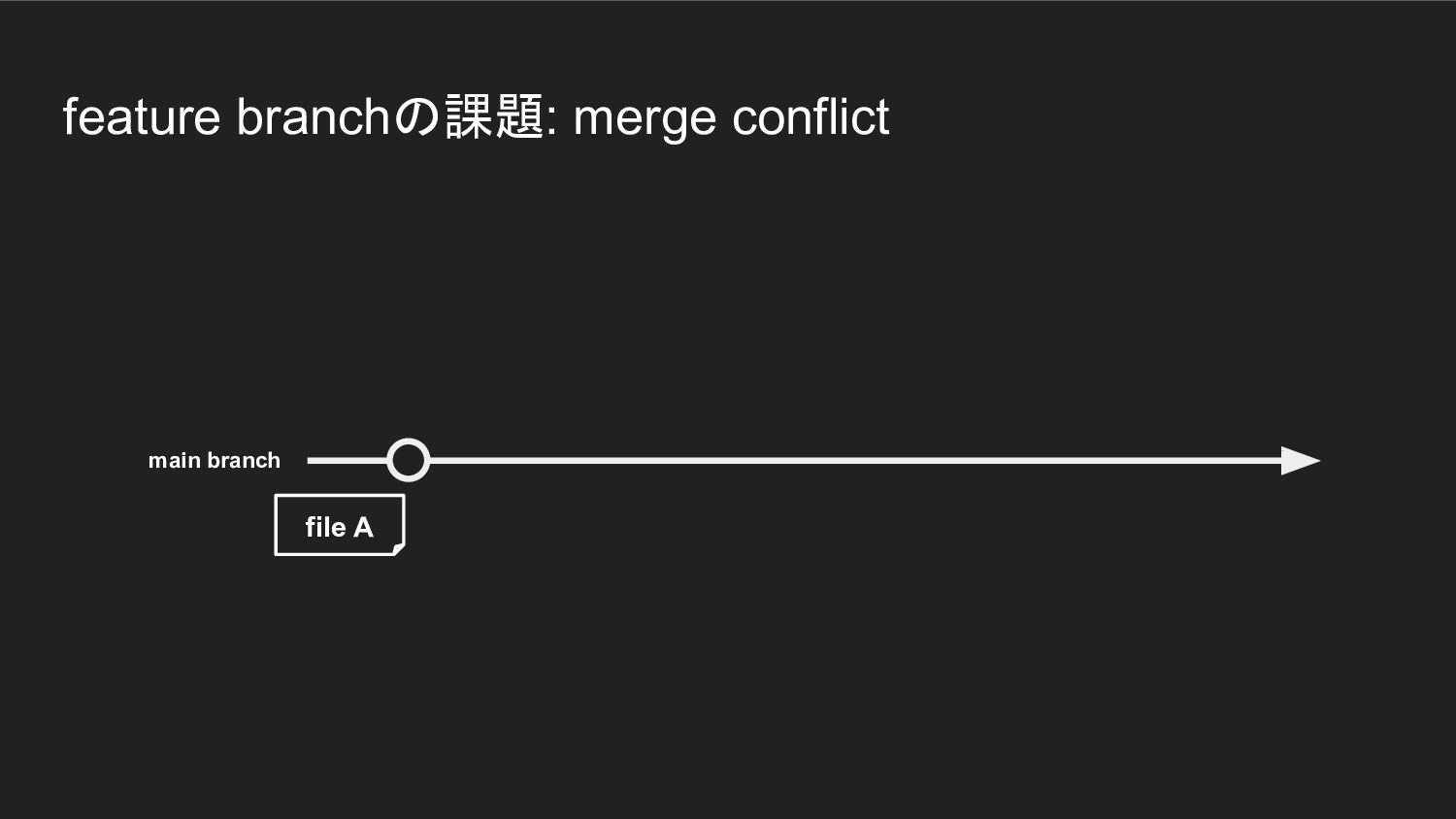
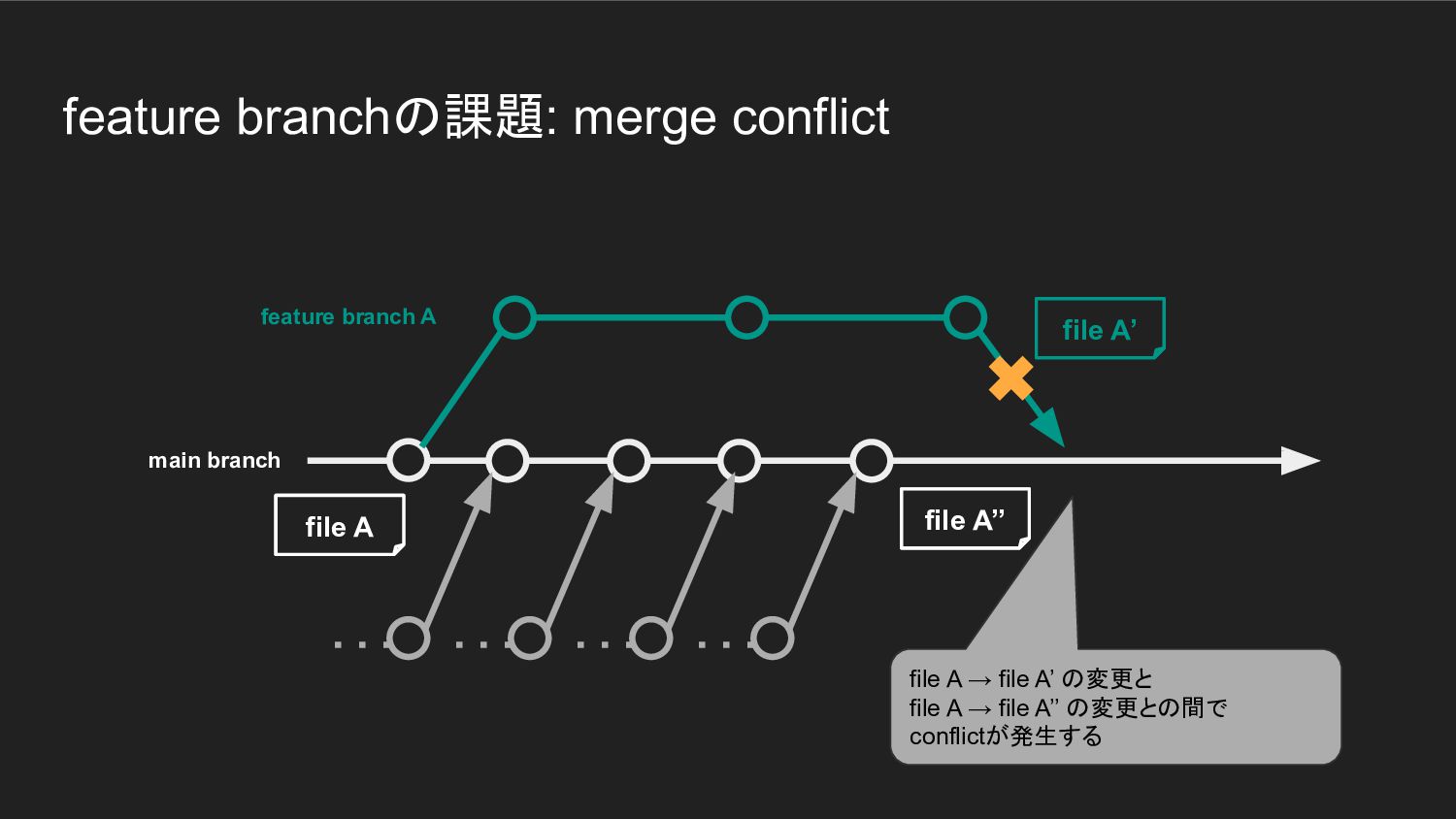
feature branchの課題: merge conflict main branch file A
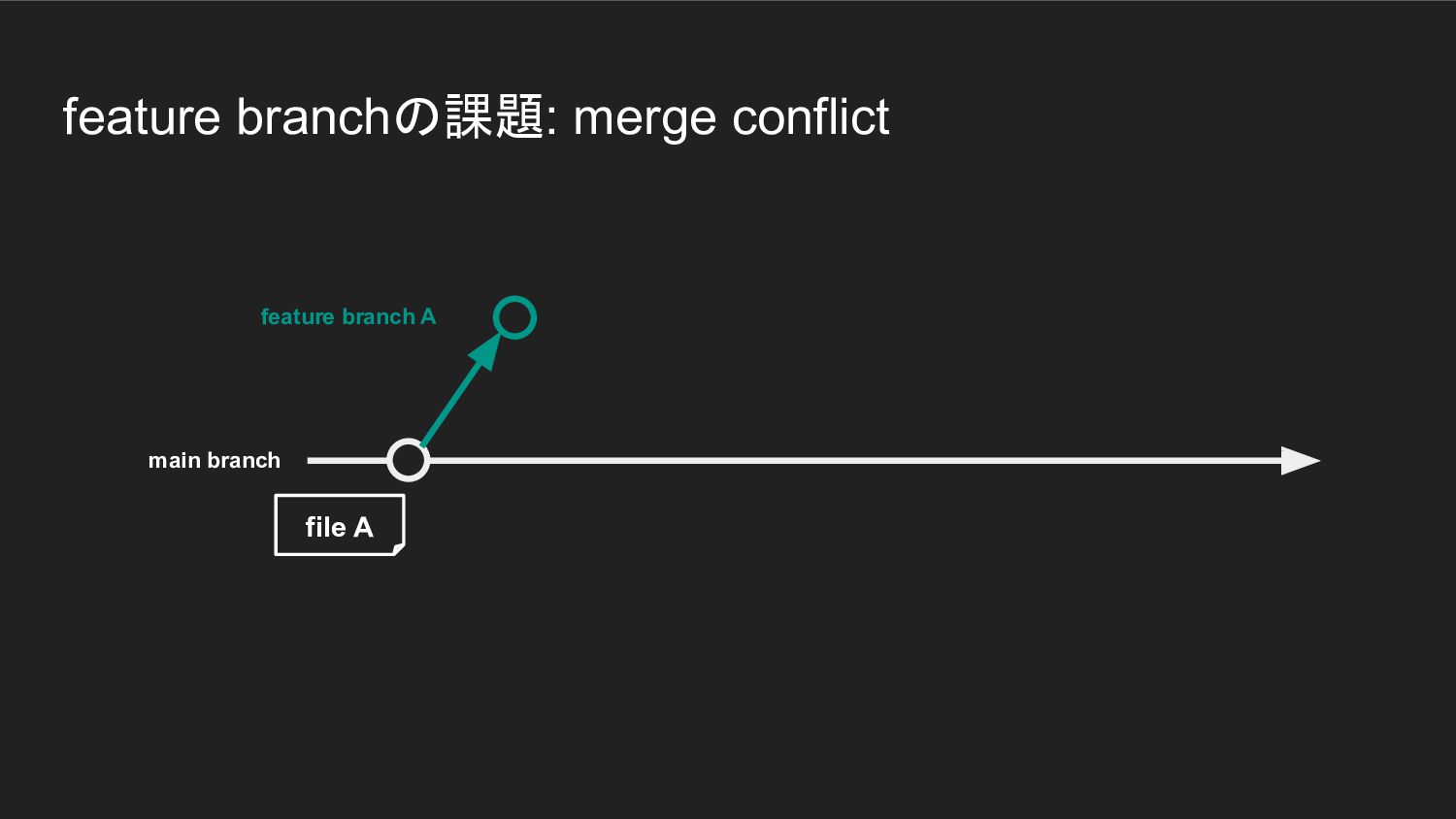
feature branchの課題: merge conflict main branch feature branch A file
A
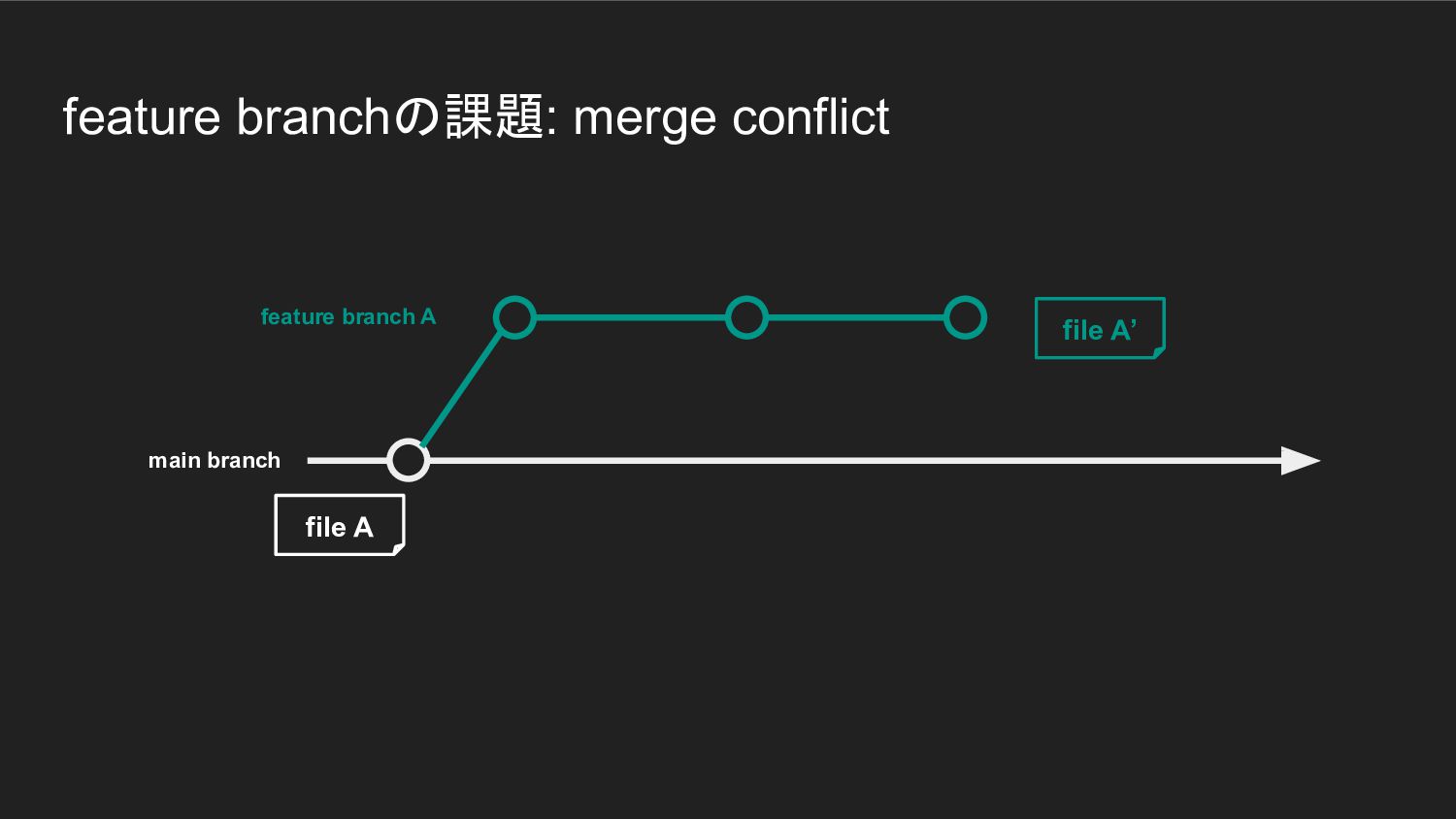
feature branchの課題: merge conflict main branch feature branch A file
A file A’
feature branchの課題: merge conflict main branch feature branch A file
A file A’’ file A’
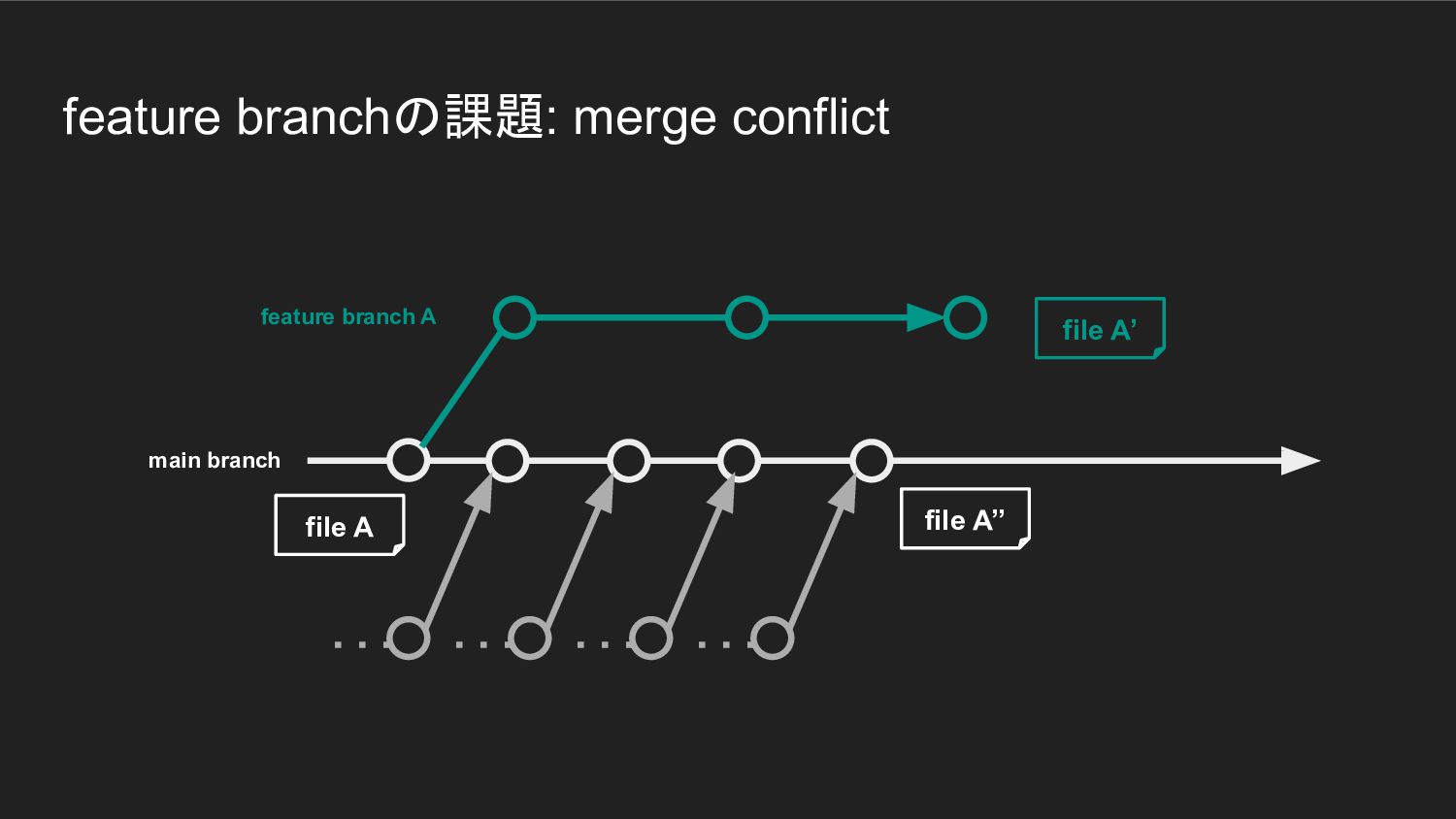
feature branchの課題: merge conflict main branch feature branch A file
A file A’’ file A’ file A → file A’ の変更と file A → file A’’ の変更との間で conflictが発生する file A file A’’ file A’
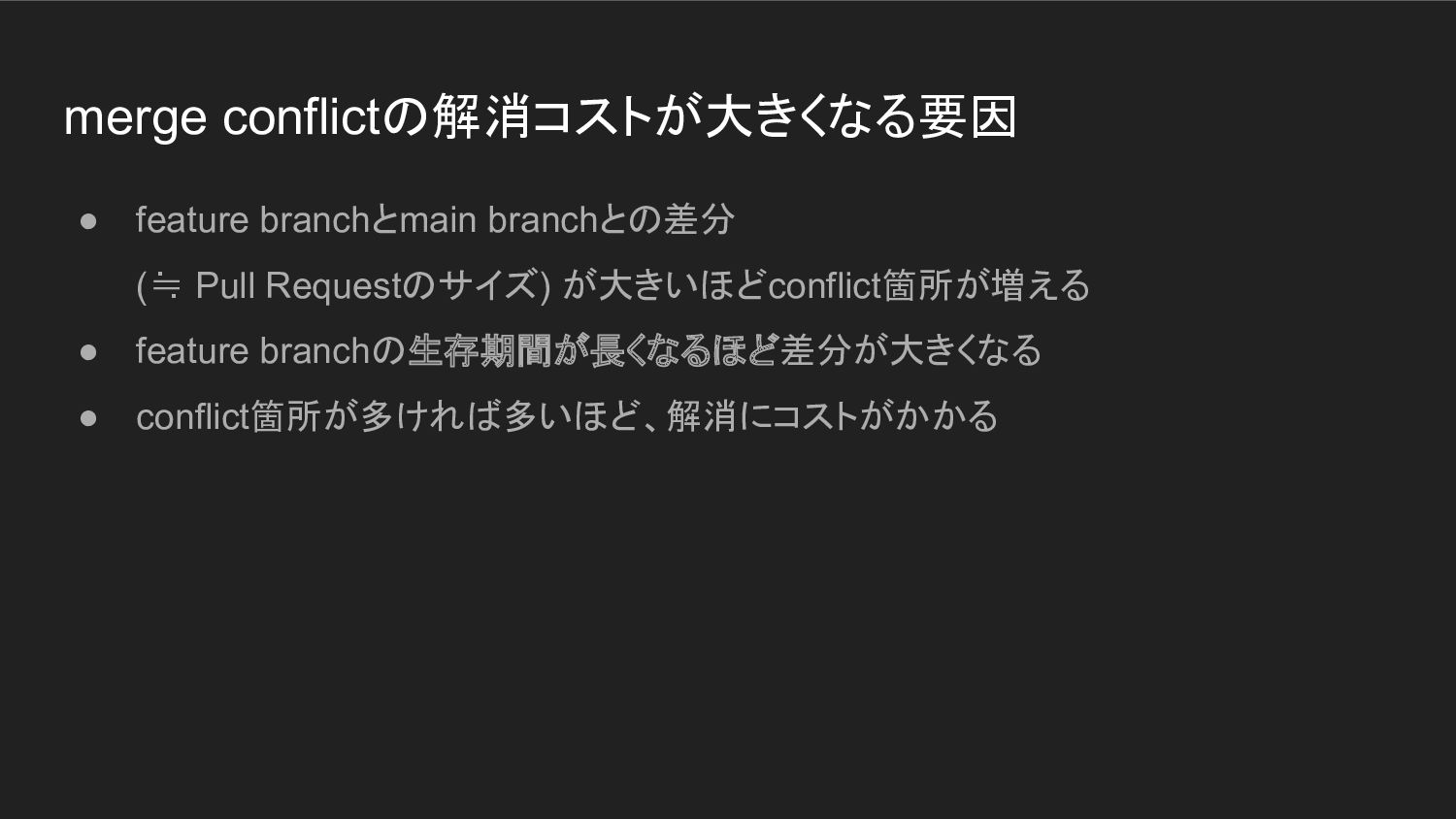
merge conflictの解消コストが大きくなる要因 • feature branchとmain branchとの差分 (≒ Pull Requestのサイズ) が大きいほどconflict箇所が増える
• feature branchの生存期間が長くなるほど差分が大きくなる • conflict箇所が多ければ多いほど、解消にコストがかかる
conflictのリスク・コストが現実的に問題になる場面 • ひとつのコードベース (リポジトリ) を大人数で開発する場合 ◦ 人数が増えれば増えるほど conflict頻度・解消コストが高まる → 開発者を増やしても開発速度が上がりにくくなる
• feature branchのサイズが大きい場合 • コーディング完了からコードレビューまでの待機時間が長い場合 etc
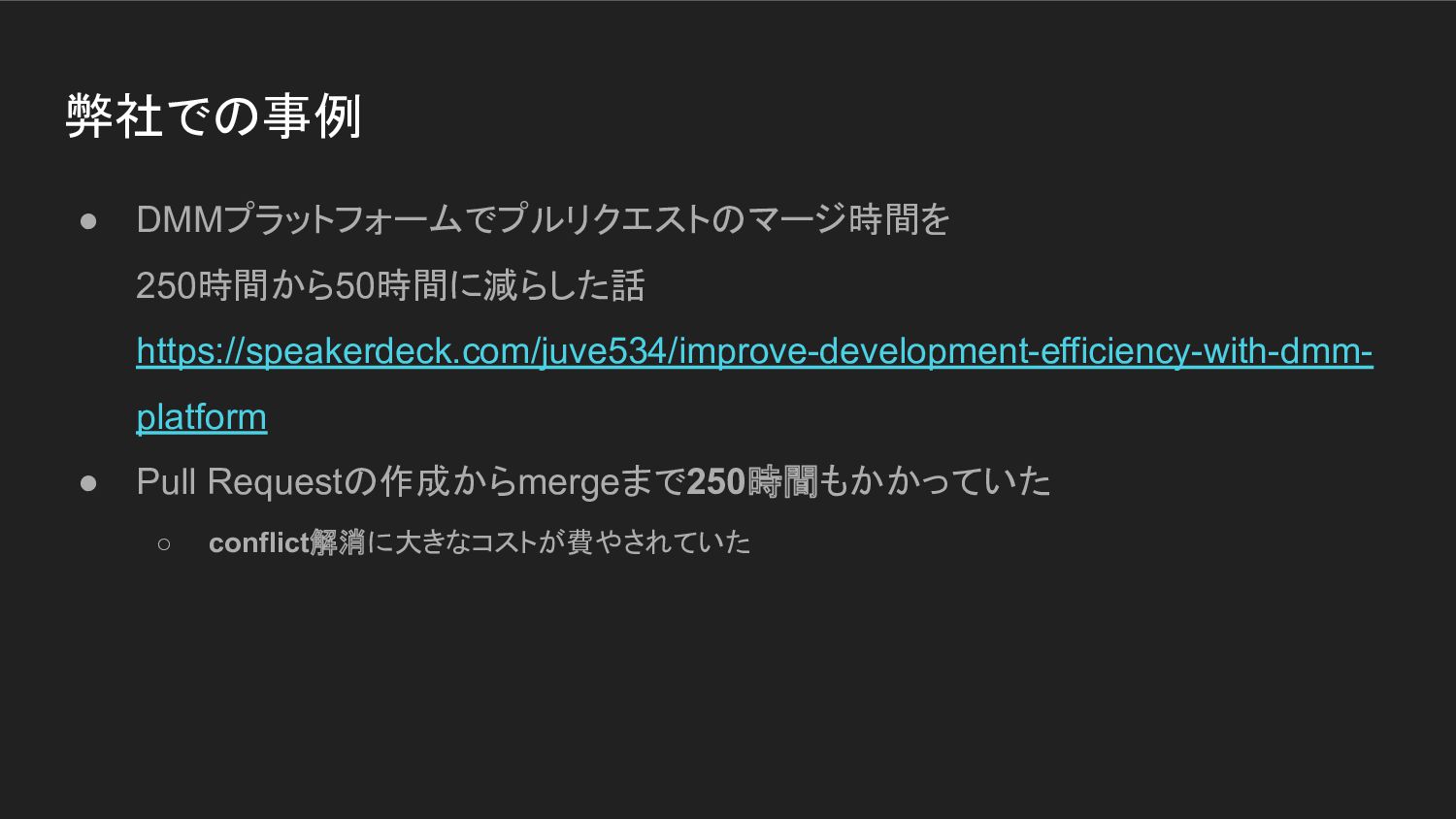
弊社での事例 • DMMプラットフォームでプルリクエストのマージ時間を 250時間から50時間に減らした話 https://speakerdeck.com/juve534/improve-development-efficiency-with-dmm- platform • Pull Requestの作成からmergeまで250時間もかかっていた ◦
conflict解消に大きなコストが費やされていた
トランクベース開発
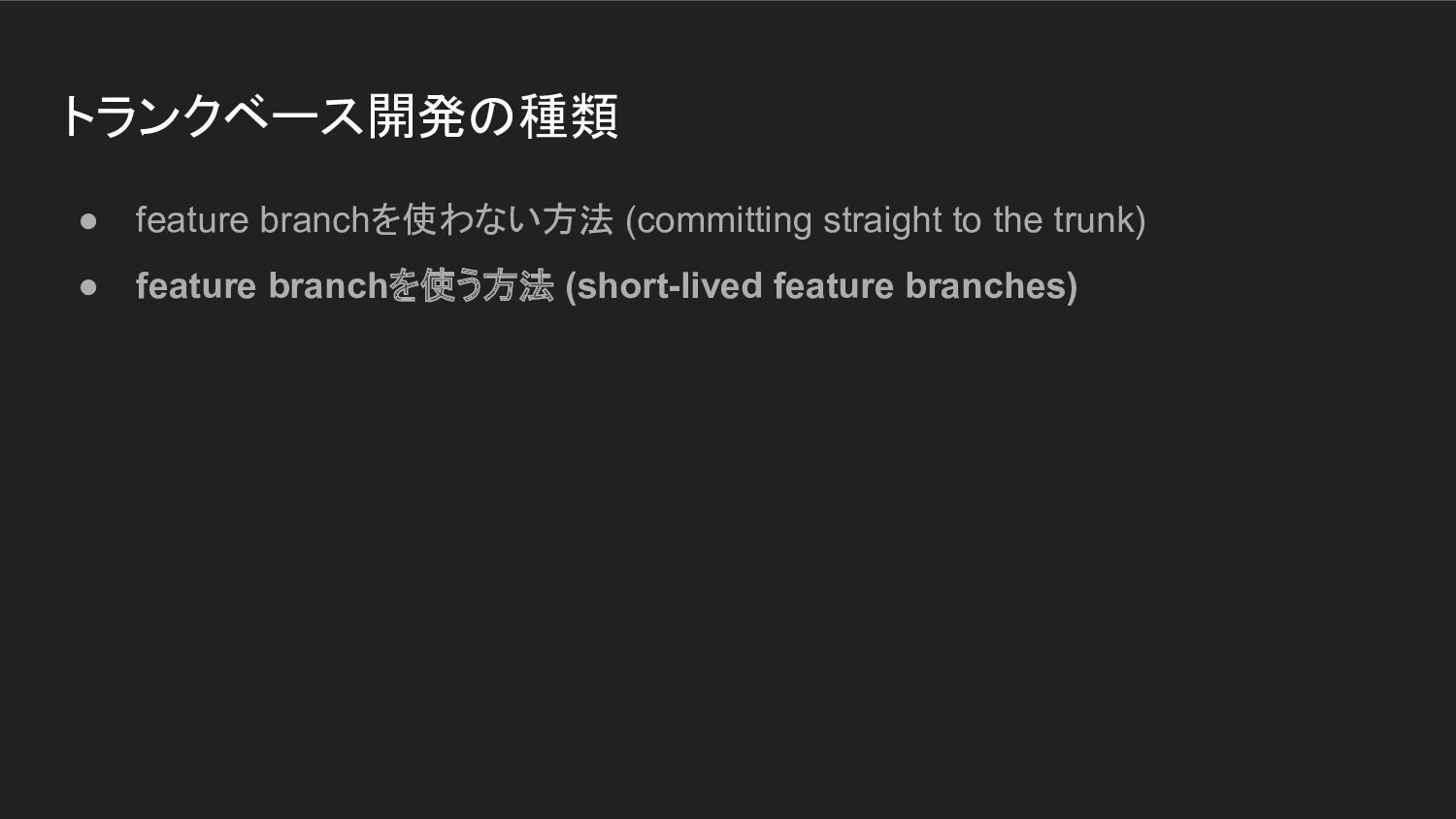
トランクベース開発の種類 • feature branchを使わない方法 (committing straight to the trunk) •
feature branchを使う方法 (short-lived feature branches) ◦ 認証認可チームで採用している方法はこれ
トランクベース開発の種類 • feature branchを使わない方法 (committing straight to the trunk) •
feature branchを使う方法 (short-lived feature branches)
トランクベース開発 (feature branchを使わない方法) main branch (trunk)
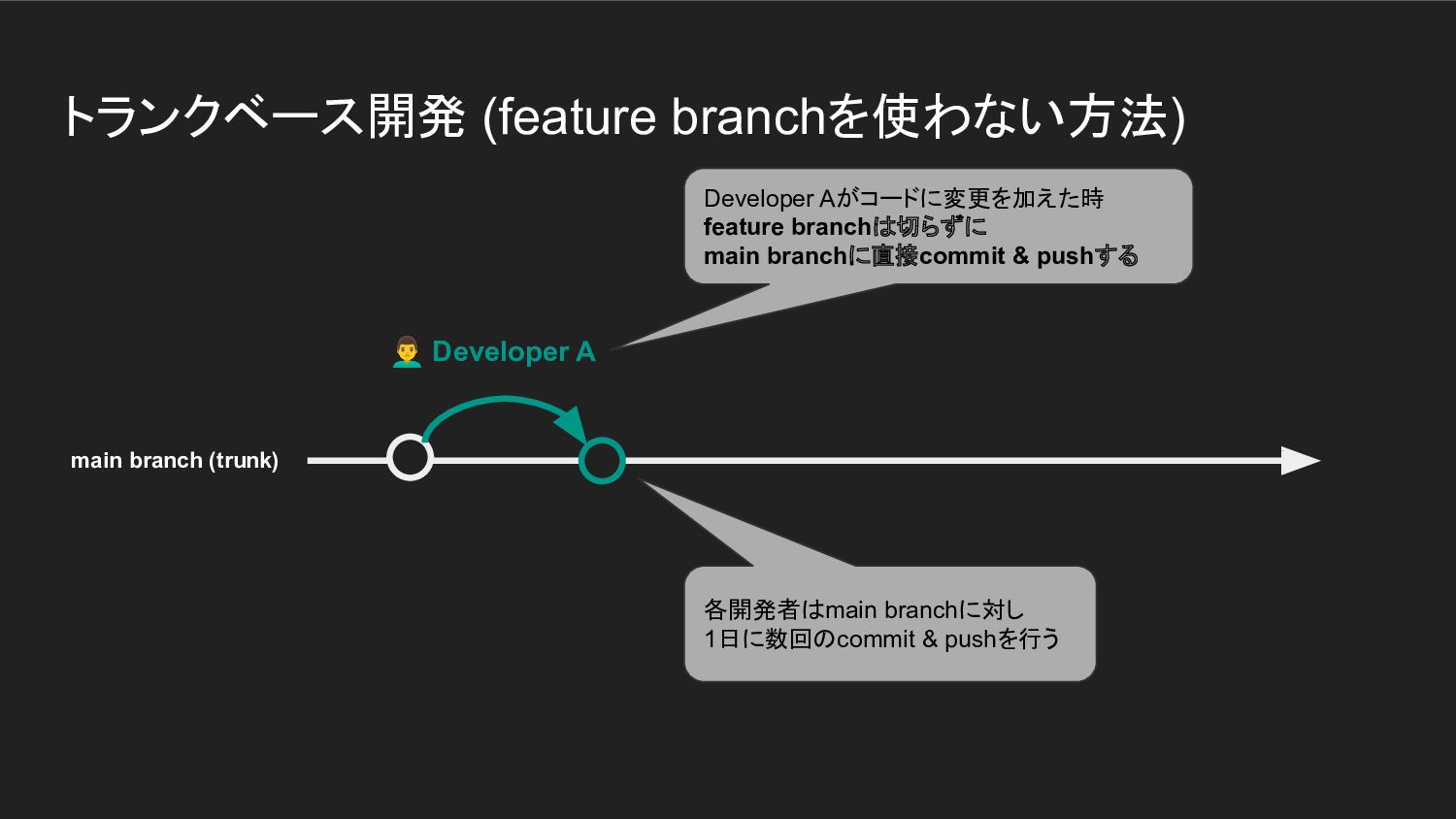
トランクベース開発 (feature branchを使わない方法) Developer A Developer Aがコードに変更を加えた時 feature branchは切らずに
main branchに直接commit & pushする 各開発者はmain branchに対し 1日に数回のcommit & pushを行う main branch (trunk)
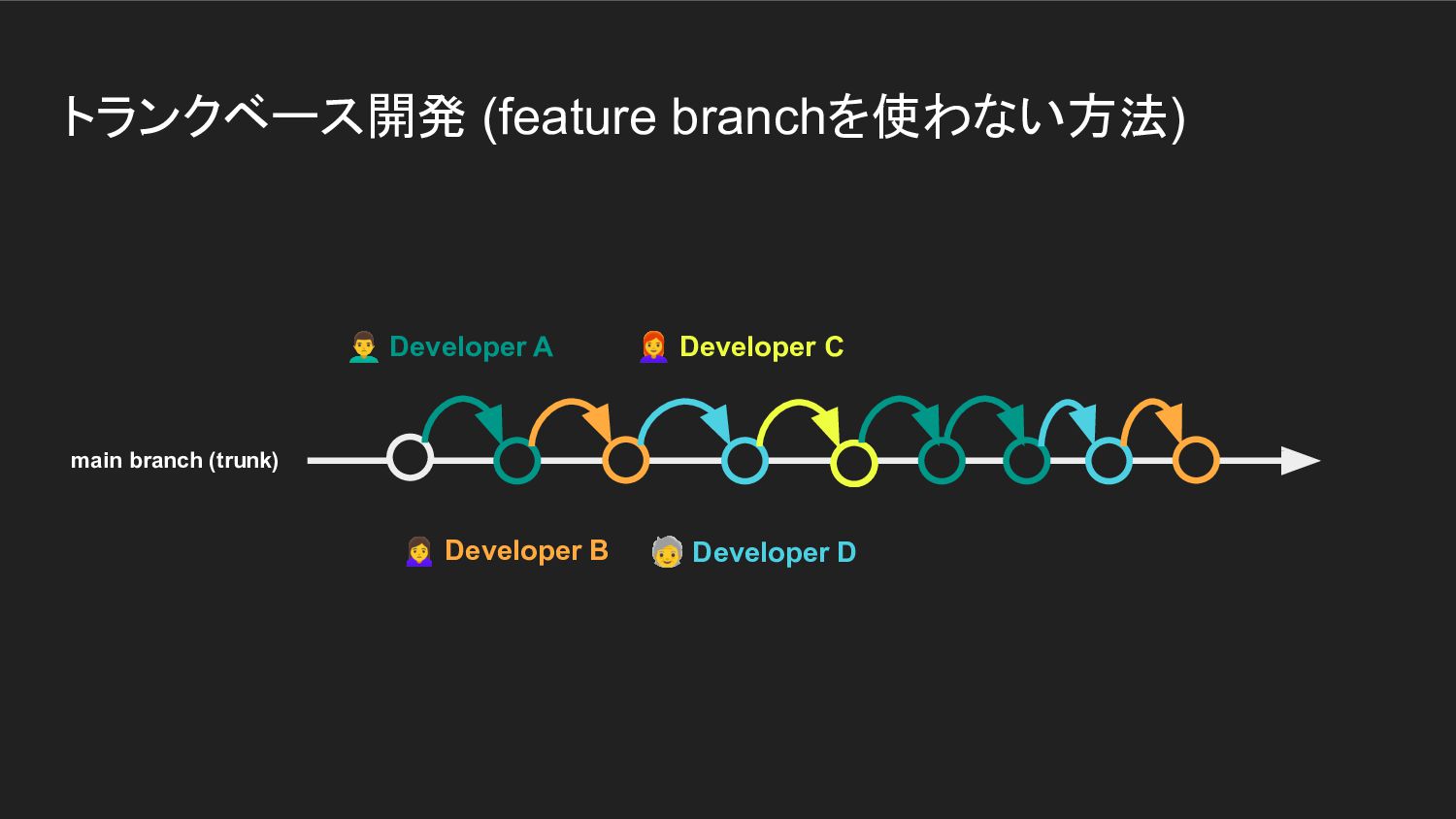
トランクベース開発 (feature branchを使わない方法) Developer A Developer B 他の開発者も同じく
main branchで作業を行い 変更をcommit & pushする main branch (trunk)
トランクベース開発 (feature branchを使わない方法) Developer A Developer B 🧓
Developer D Developer C main branch (trunk)
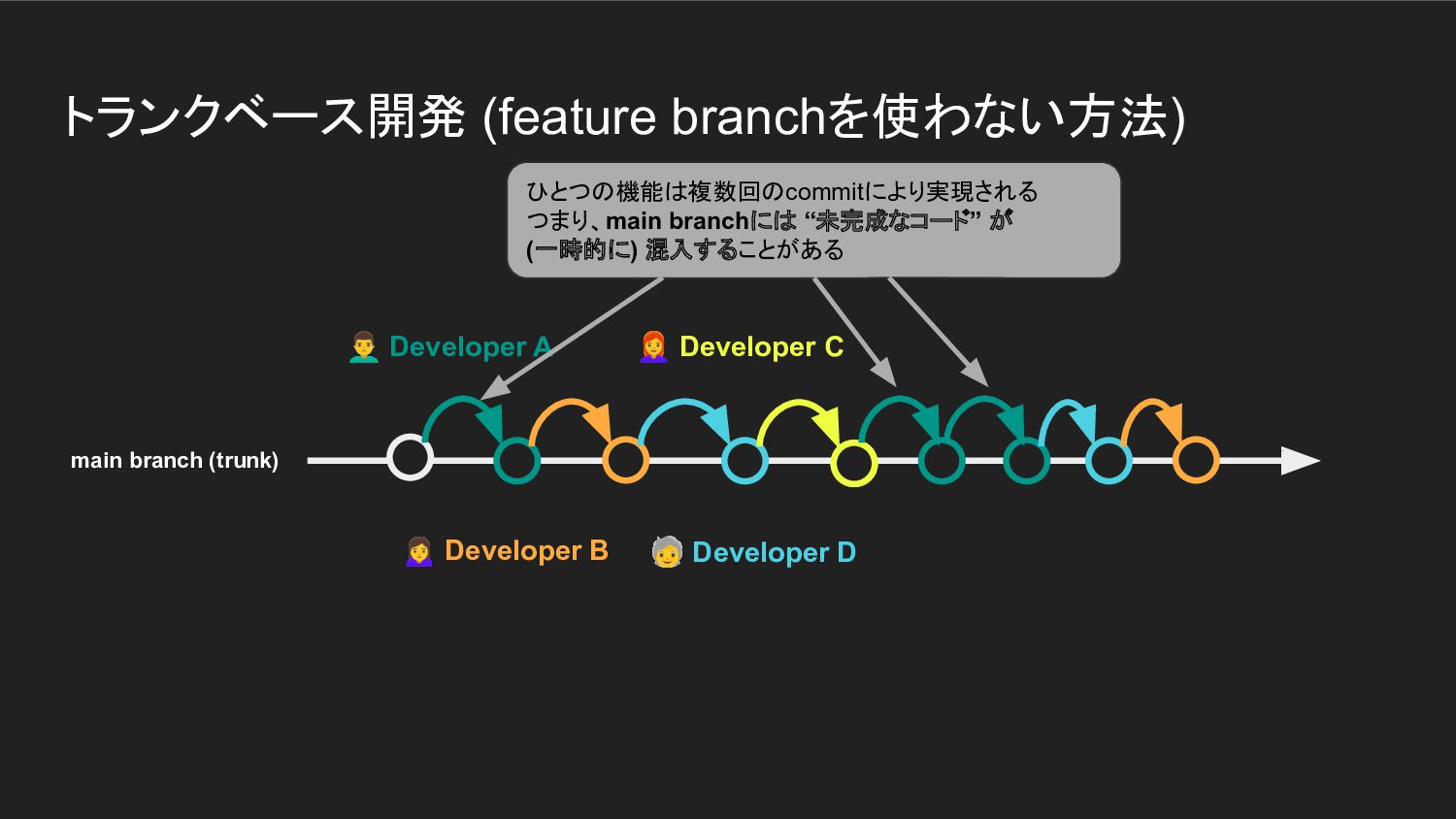
トランクベース開発 (feature branchを使わない方法) Developer A Developer B 🧓
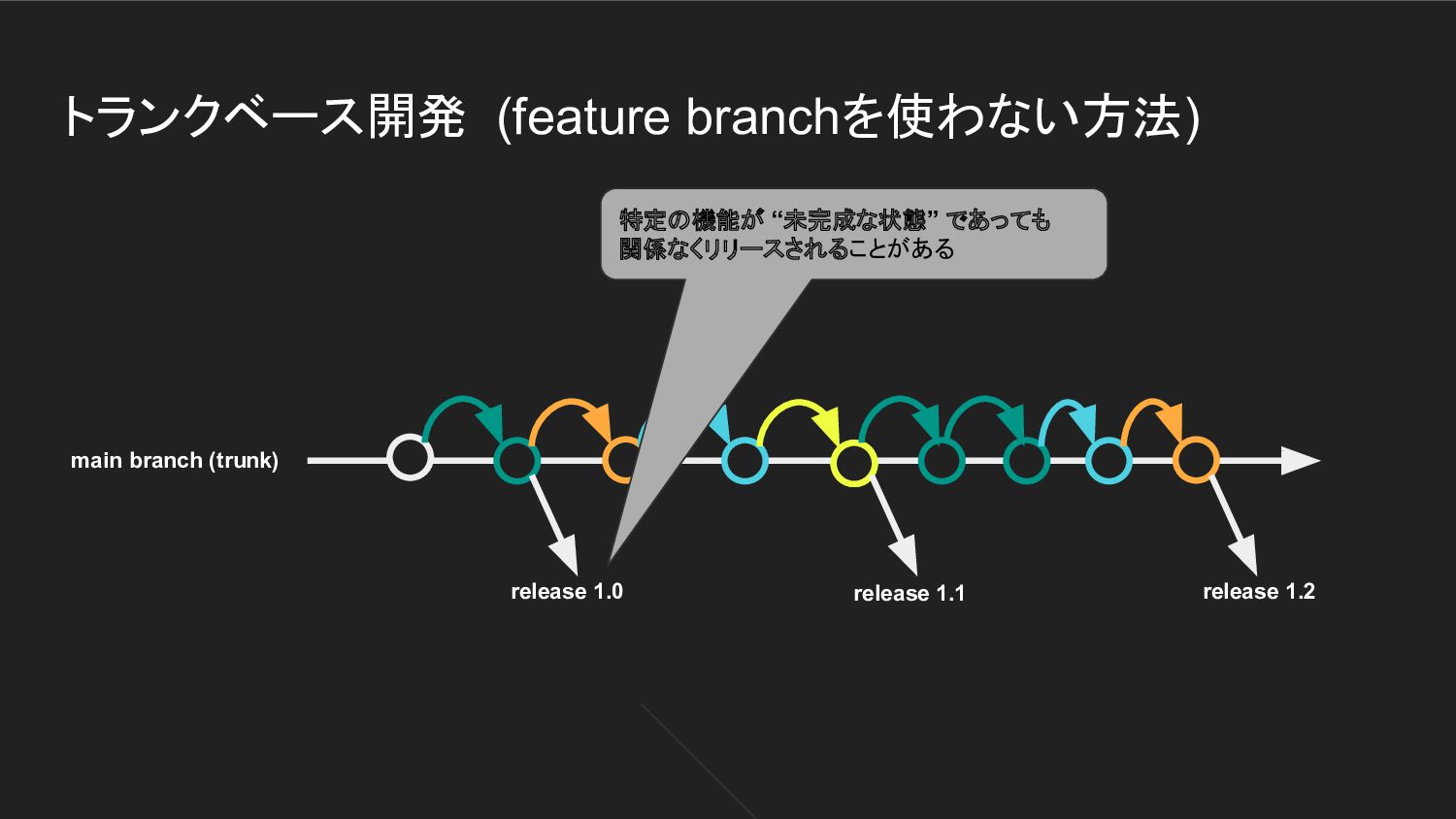
Developer D Developer C ひとつの機能は複数回のcommitにより実現される つまり、main branchには “未完成なコード” が (一時的に) 混入することがある main branch (trunk)
トランクベース開発 (feature branchを使わない方法) release 1.0 release 1.1 release 1.2 特定の機能が
“未完成な状態” であっても 関係なくリリースされることがある main branch (trunk)
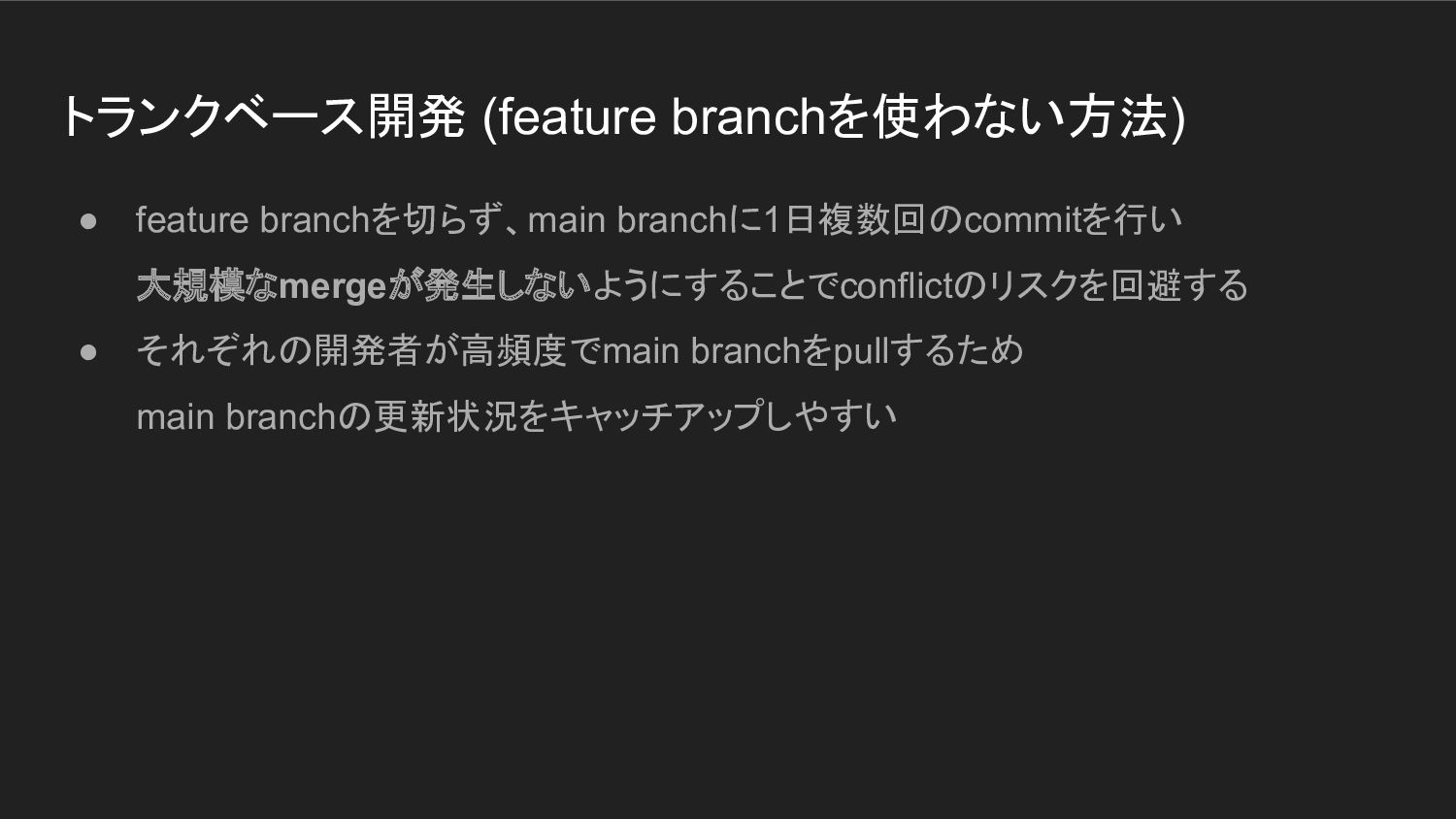
トランクベース開発 (feature branchを使わない方法) • feature branchを切らず、main branchに1日複数回のcommitを行い 大規模なmergeが発生しないようにすることでconflictのリスクを回避する • それぞれの開発者が高頻度でmain
branchをpullするため main branchの更新状況をキャッチアップしやすい
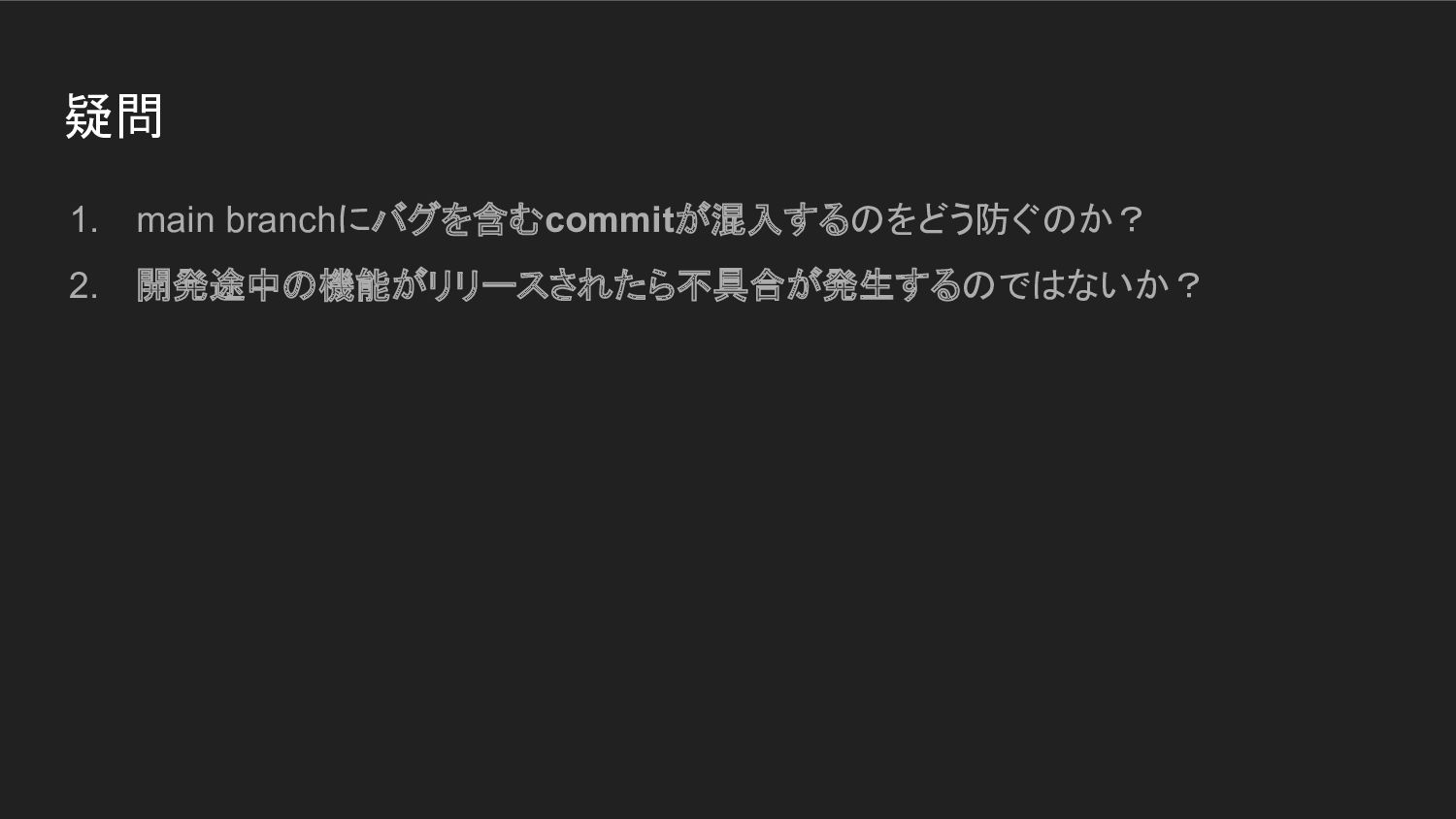
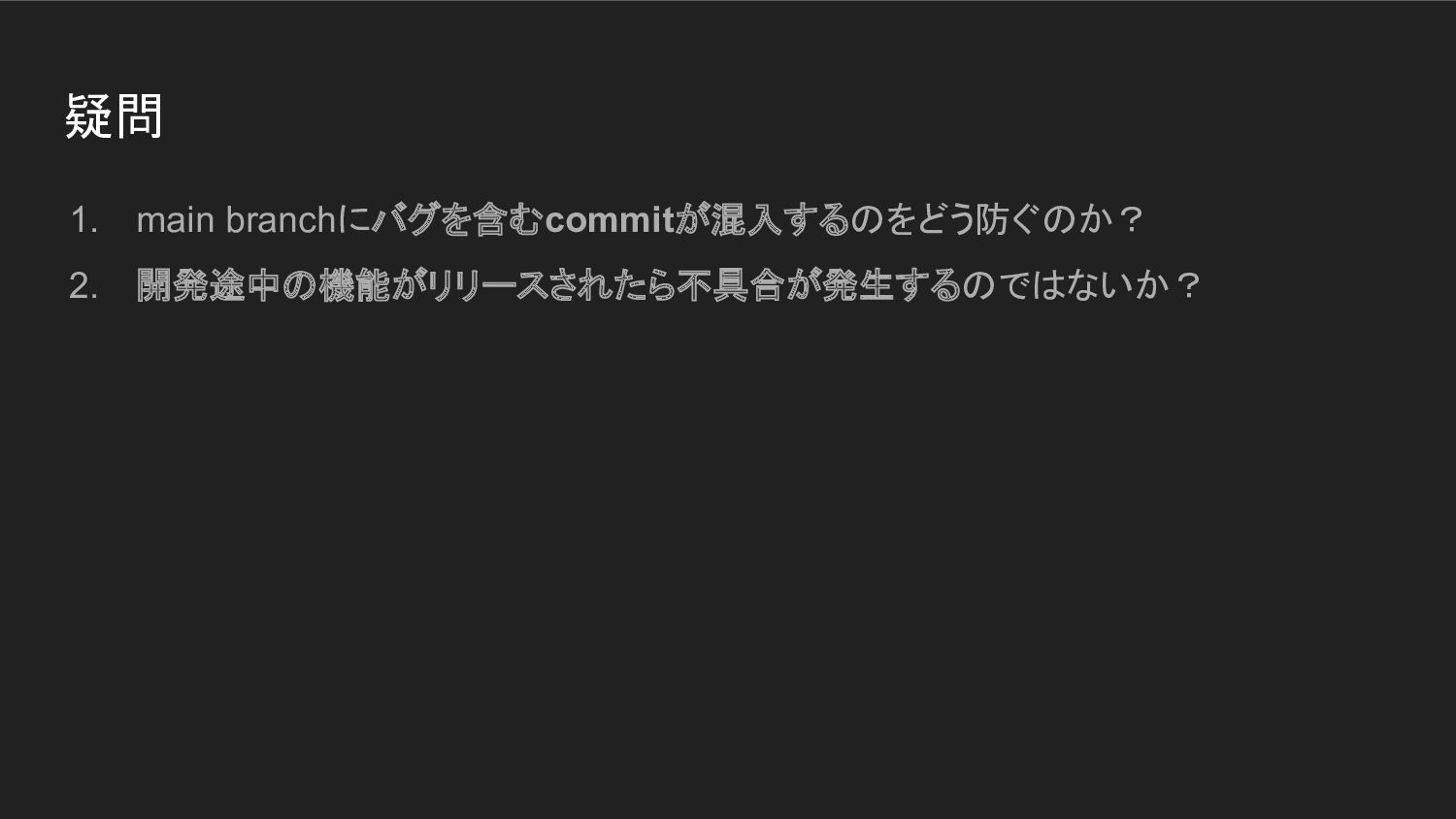
疑問 1. main branchにバグを含むcommitが混入するのをどう防ぐのか? 2. 開発途中の機能がリリースされたら不具合が発生するのではないか?
バグの混入をどう防ぐのか? • バグの混入を未然に防ぐ • バグが発見されたら除去する
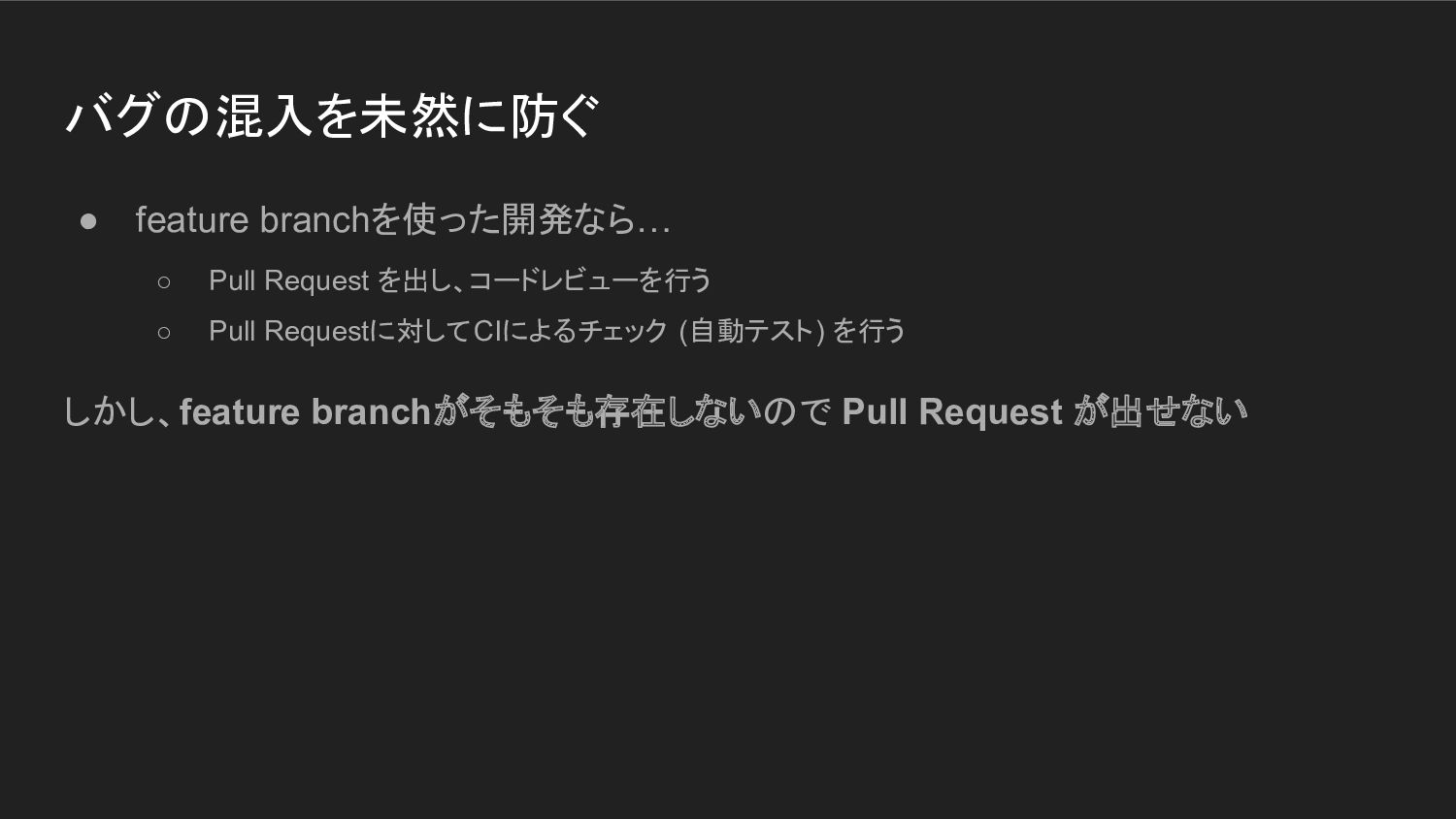
バグの混入を未然に防ぐ • feature branchを使った開発なら… ◦ Pull Request を出し、コードレビューを行う ◦ Pull
Requestに対してCIによるチェック (自動テスト) を行う
バグの混入を未然に防ぐ • feature branchを使った開発なら… ◦ Pull Request を出し、コードレビューを行う ◦ Pull
Requestに対してCIによるチェック (自動テスト) を行う しかし、feature branchがそもそも存在しないので Pull Request が出せない
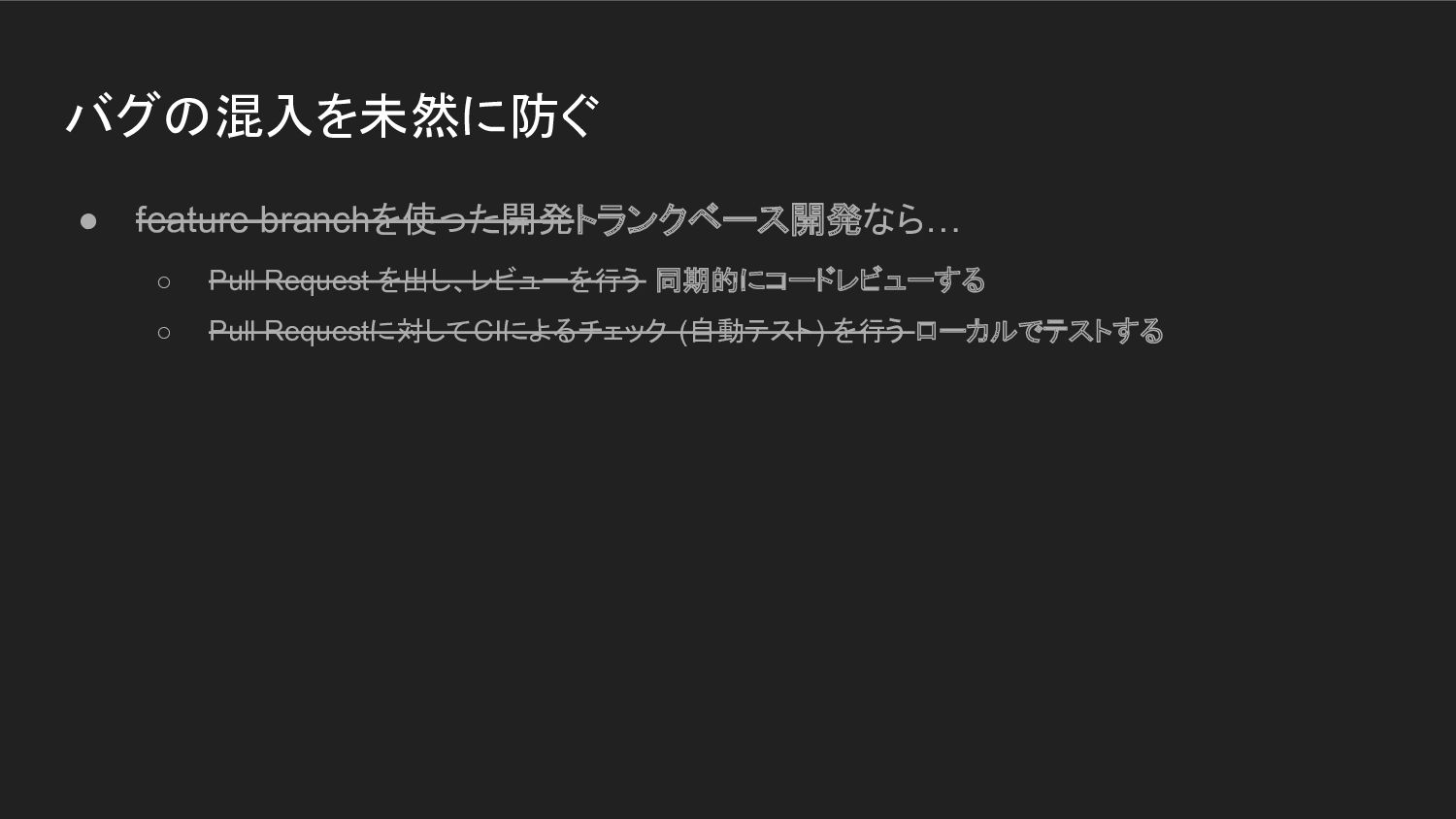
バグの混入を未然に防ぐ • feature branchを使った開発トランクベース開発なら… ◦ Pull Request を出し、レビューを行う 同期的にコードレビューする ◦
Pull Requestに対してCIによるチェック (自動テスト) を行う ローカルでテストする
同期的にコードレビューする • 変更をいち早くmain branchに取り込むために必要 ◦ レビュー着手が遅れれば遅れるほど main branchの変更に追従しにくくなり、 conflictが発生しやすくなる •
具体的な方法 ◦ commitの準備ができた段階でレビューを依頼する ▪ レビュイーとレビュアーが同席のもとでレビューを行う ◦ ペアプログラミングする ▪ 複数人でコードを書きながら、内容について相互に合意を取っていく
同期的なコードレビューを実現するために • 「レビュー待ち」の状況をなるべく回避する ◦ 「後で見ておきます」は極力避ける ◦ レビュー待ちの間に他のタスクを進めることも原則禁止 • 承認プロセスをシンプルに保つ ◦
commitするのに多くのレビュアーによる承認が必要な場合 レビューに多くの時間が費やされてしまう
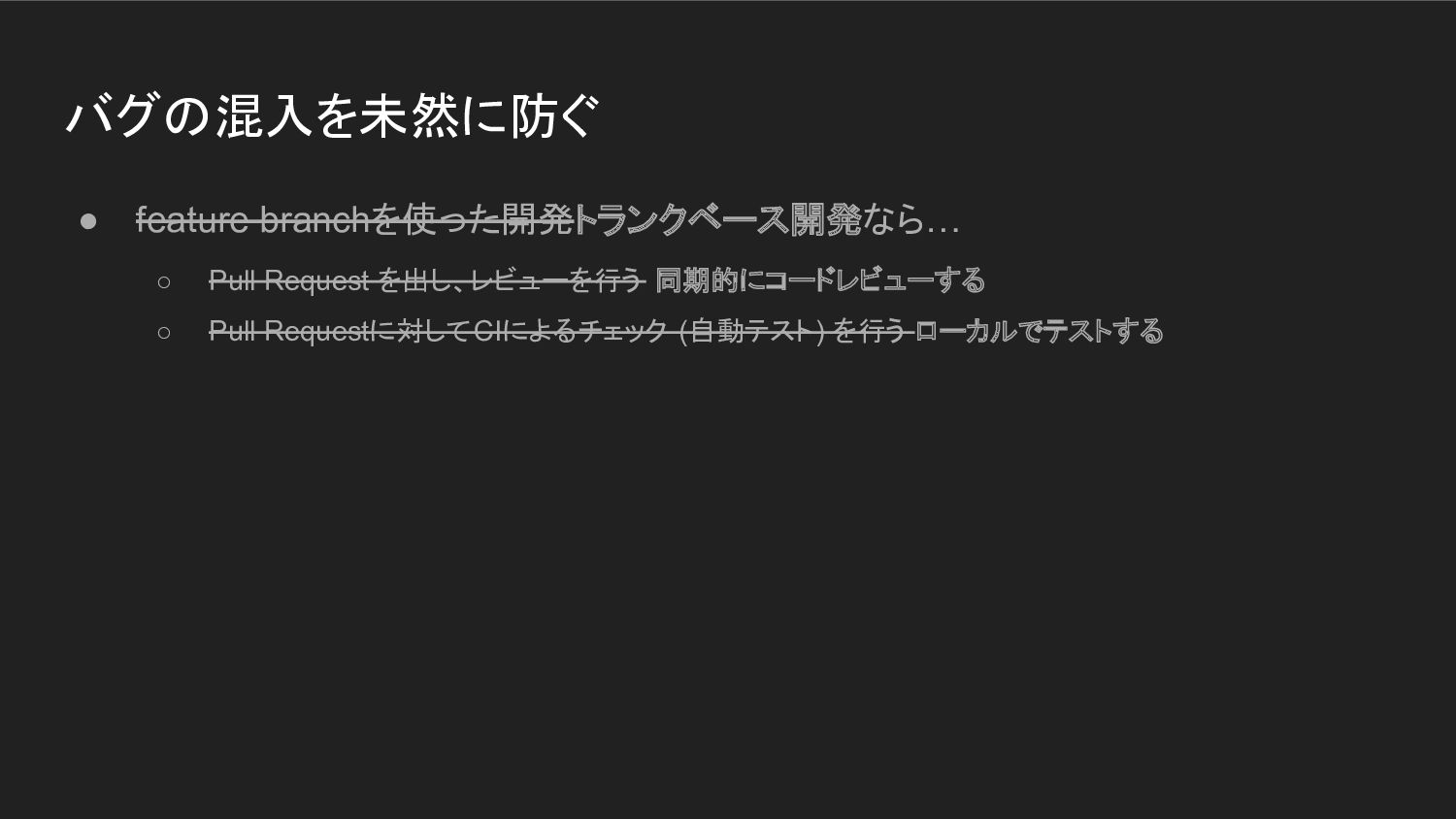
バグの混入を未然に防ぐ • feature branchを使った開発トランクベース開発なら… ◦ Pull Request を出し、レビューを行う 同期的にコードレビューする ◦
Pull Requestに対してCIによるチェック (自動テスト) を行う ローカルでテストする
ローカルでテストする • 変更をcommitする前に、開発者自身で品質を保証する • 開発者自身が速やかに品質保証できる手段を用意する必要がある ◦ 自動テスト, Lint, etc ◦
速やかに結果が得られるようにしておく ▪ ビルドやテストはなるべく早く終わらせる ◦ 全ての開発者が等しい結果を得られるようにしておく ▪ 開発環境によってはテストが失敗する、などという状況は好ましくない
それでもバグは混入してしまう可能性がある • 例: ローカルでのテスト実行を忘れてしまう
バグが発見されたら除去する • ローカル環境だけでなく、CI環境でもテストを行う ◦ main branchへのpushにフックさせてビルドやテストを実行する • CI環境でのテストが失敗したら速やかにロールバックする ◦ アラートを発報して開発者に手動ロールバックさせる
◦ CIパイプラインの中で自動ロールバックする
疑問 1. main branchにバグを含むcommitが混入するのをどう防ぐのか? 2. 開発途中の機能がリリースされたら不具合が発生するのではないか?
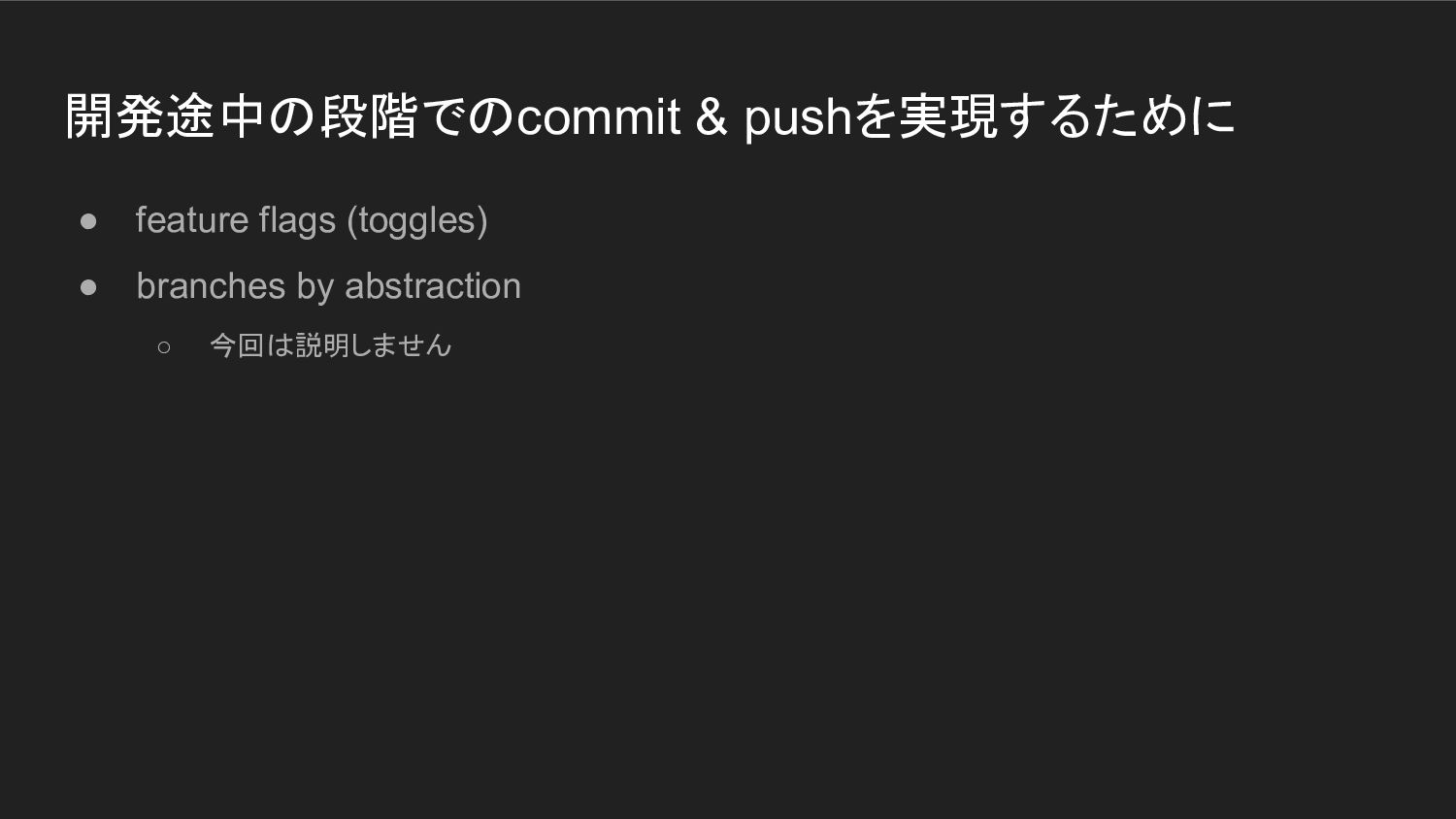
開発途中の段階でのcommit & pushを実現するために • feature flags (toggles) • branches by
abstraction ◦ 今回は説明しません
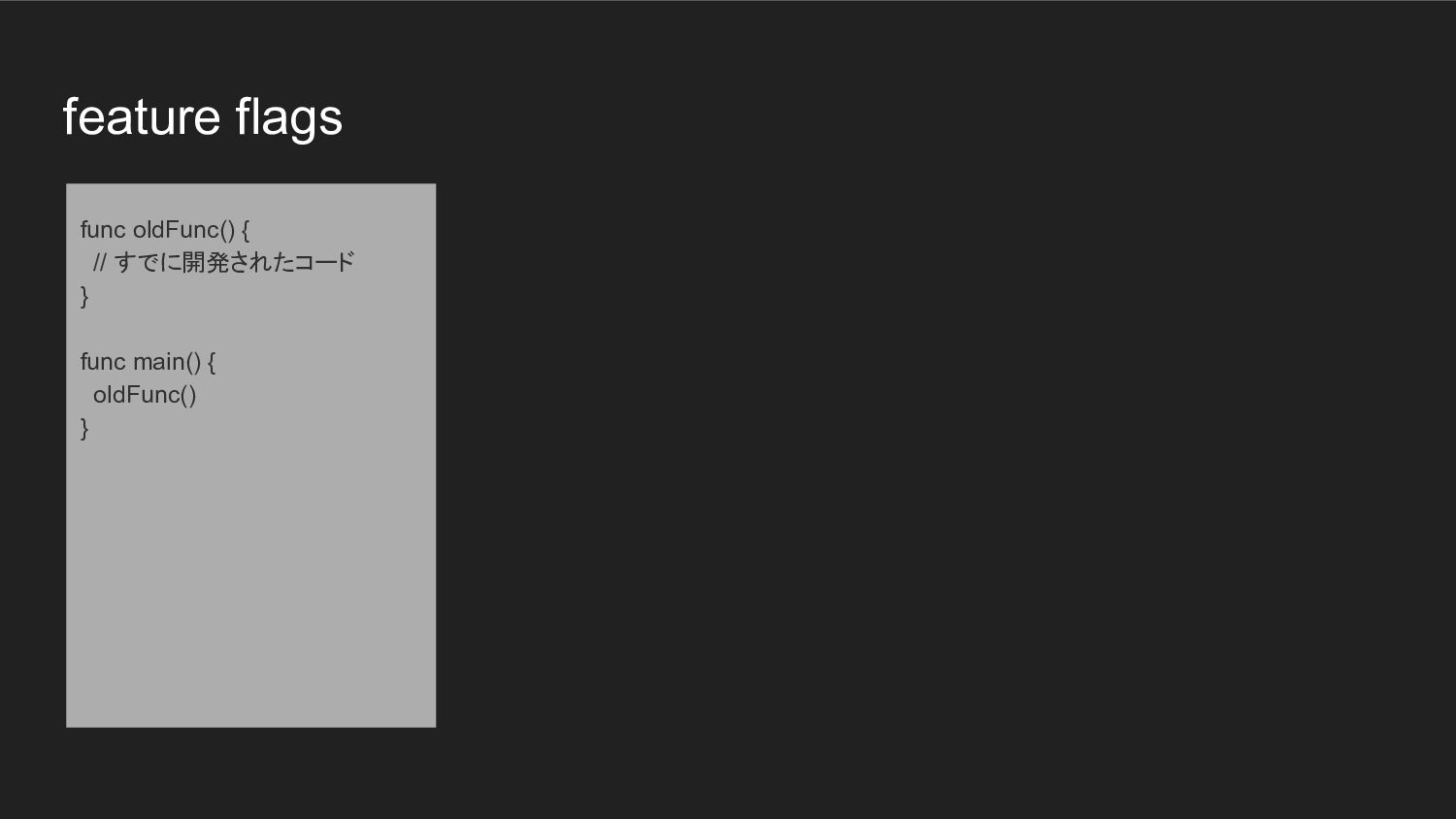
feature flags func oldFunc() { // すでに開発されたコード } func main()
{ oldFunc() }
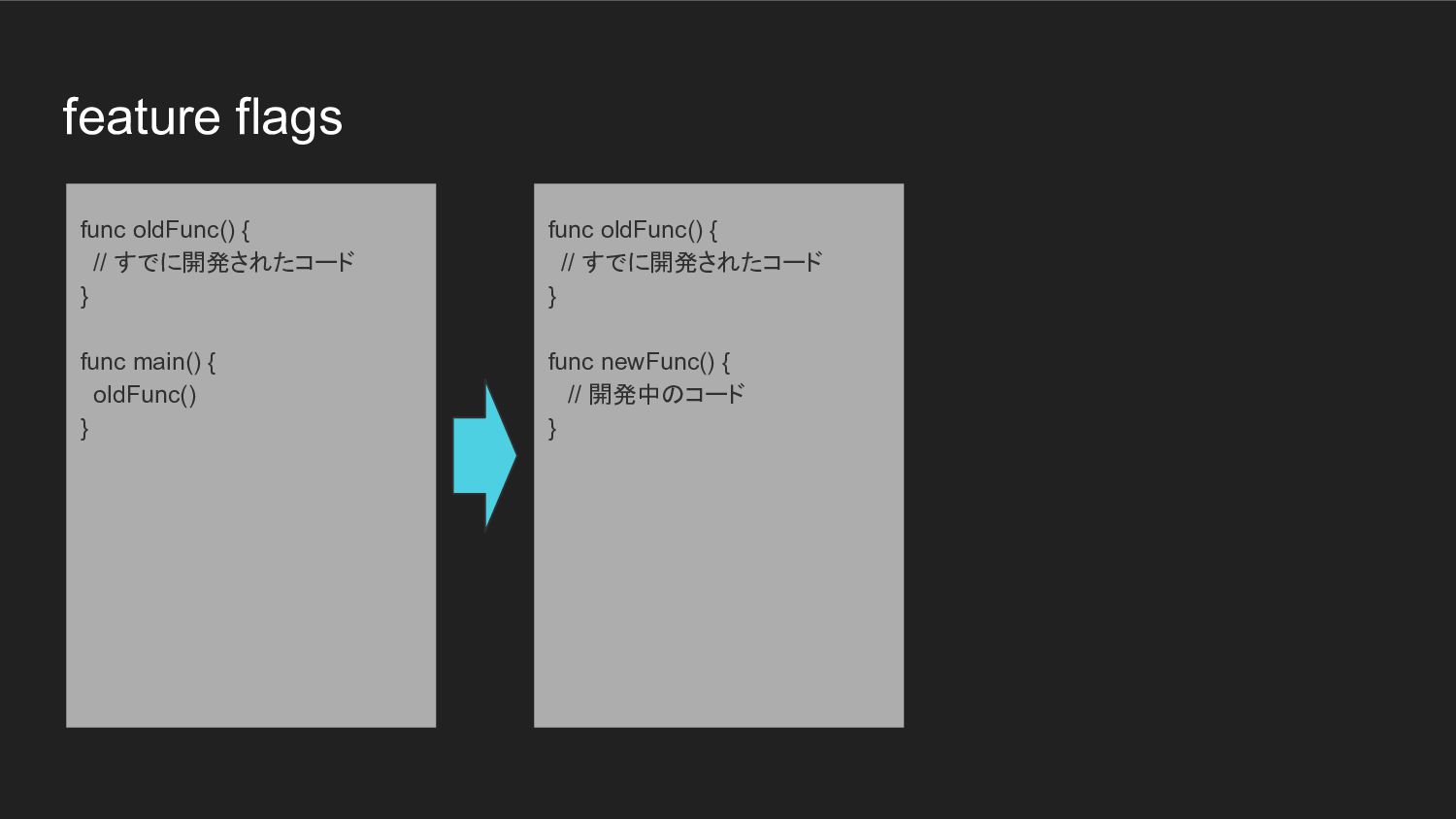
feature flags func oldFunc() { // すでに開発されたコード } func newFunc()
{ // 開発中のコード } func oldFunc() { // すでに開発されたコード } func main() { oldFunc() }
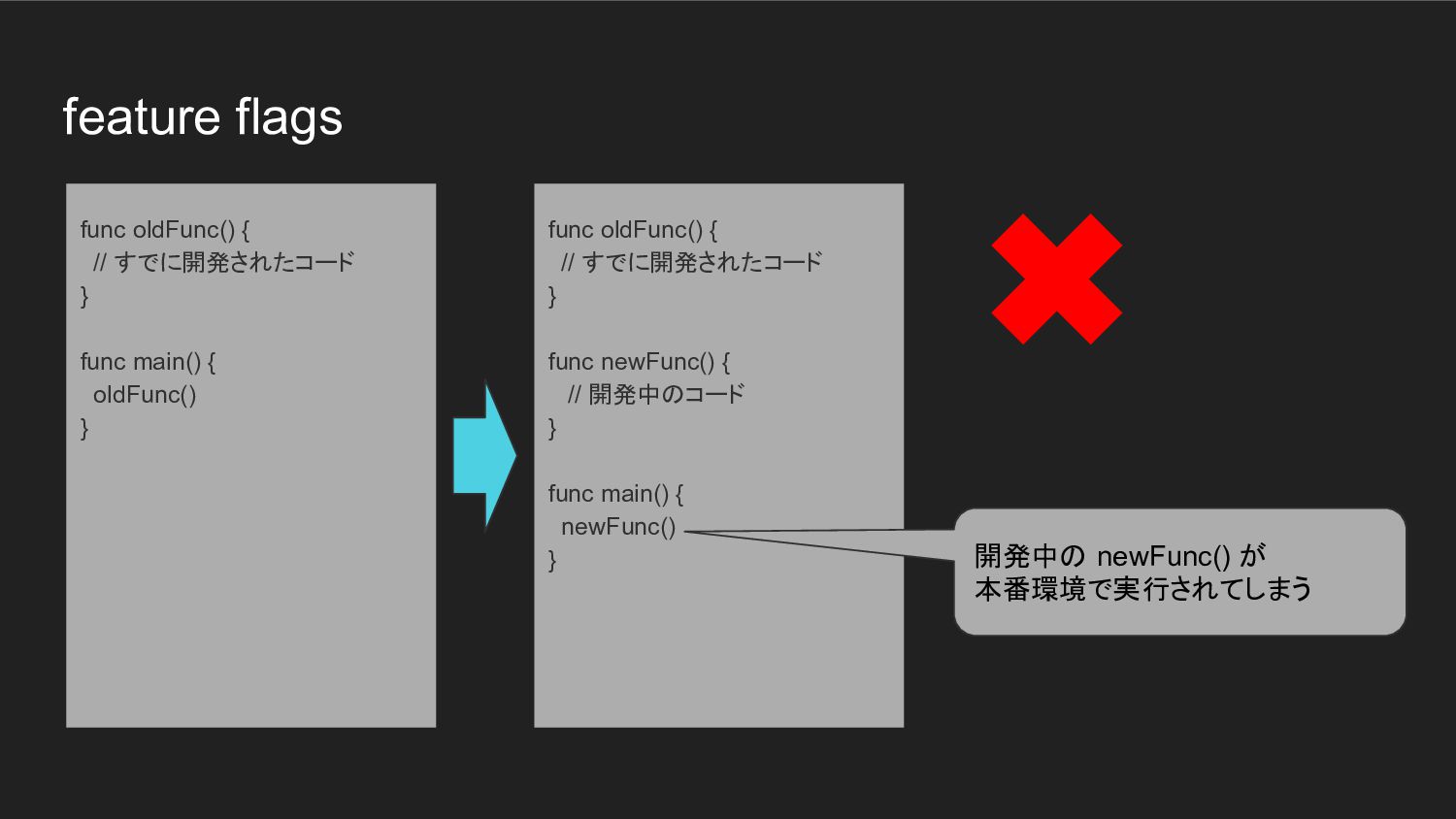
feature flags func oldFunc() { // すでに開発されたコード } func newFunc()
{ // 開発中のコード } func main() { newFunc() } func oldFunc() { // すでに開発されたコード } func main() { oldFunc() } 開発中の newFunc() が 本番環境で実行されてしまう
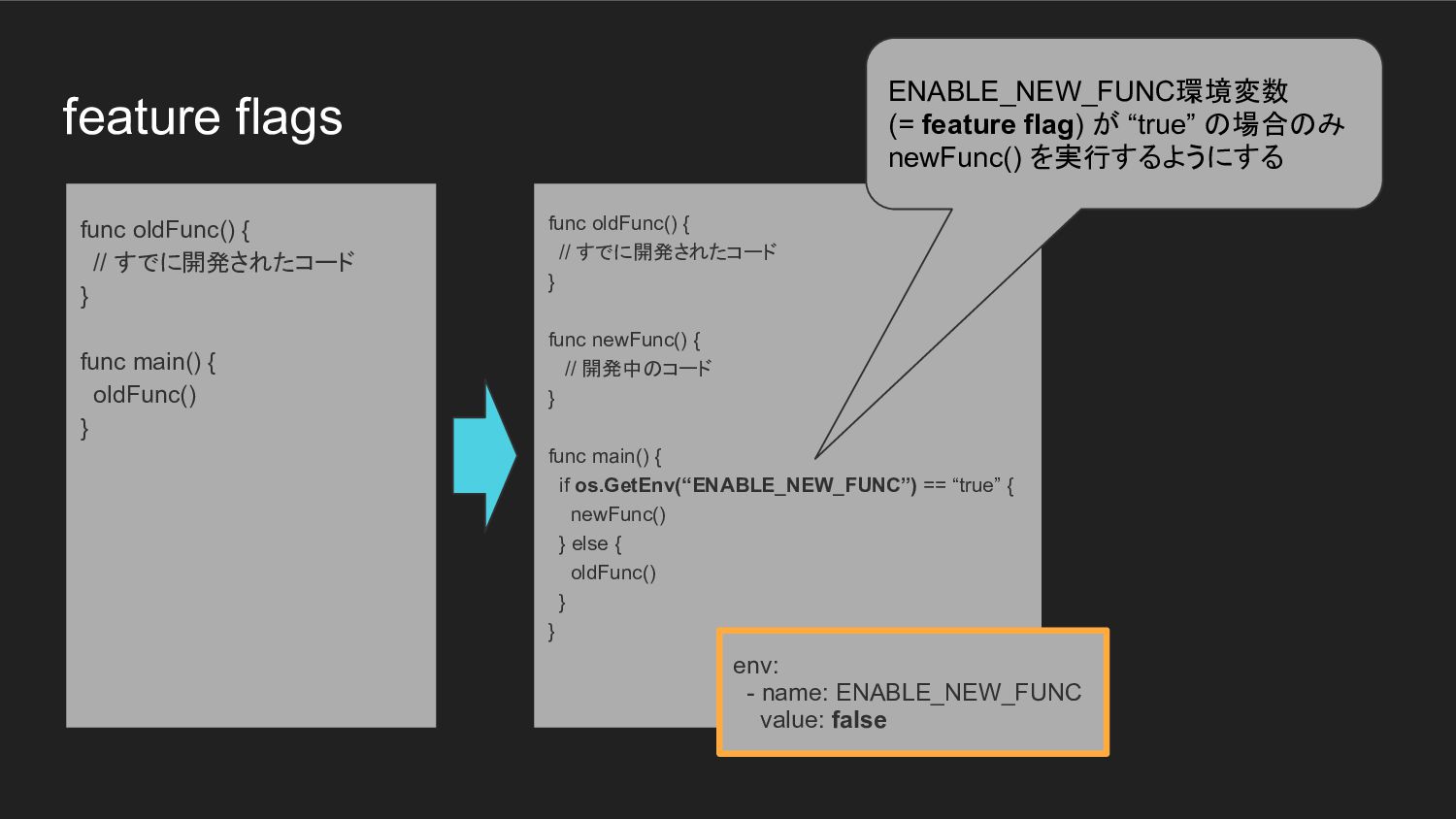
feature flags func oldFunc() { // すでに開発されたコード } func newFunc()
{ // 開発中のコード } func main() { if os.GetEnv(“ENABLE_NEW_FUNC”) == “true” { newFunc() } else { oldFunc() } } func oldFunc() { // すでに開発されたコード } func main() { oldFunc() } env: - name: ENABLE_NEW_FUNC value: false
feature flags func oldFunc() { // すでに開発されたコード } func newFunc()
{ // 開発中のコード } func main() { if os.GetEnv(“ENABLE_NEW_FUNC”) == “true” { newFunc() } else { oldFunc() } } func oldFunc() { // すでに開発されたコード } func main() { oldFunc() } ENABLE_NEW_FUNC環境変数 (= feature flag) が “true” の場合のみ newFunc() を実行するようにする env: - name: ENABLE_NEW_FUNC value: false
feature flags func oldFunc() { // すでに開発されたコード } func newFunc()
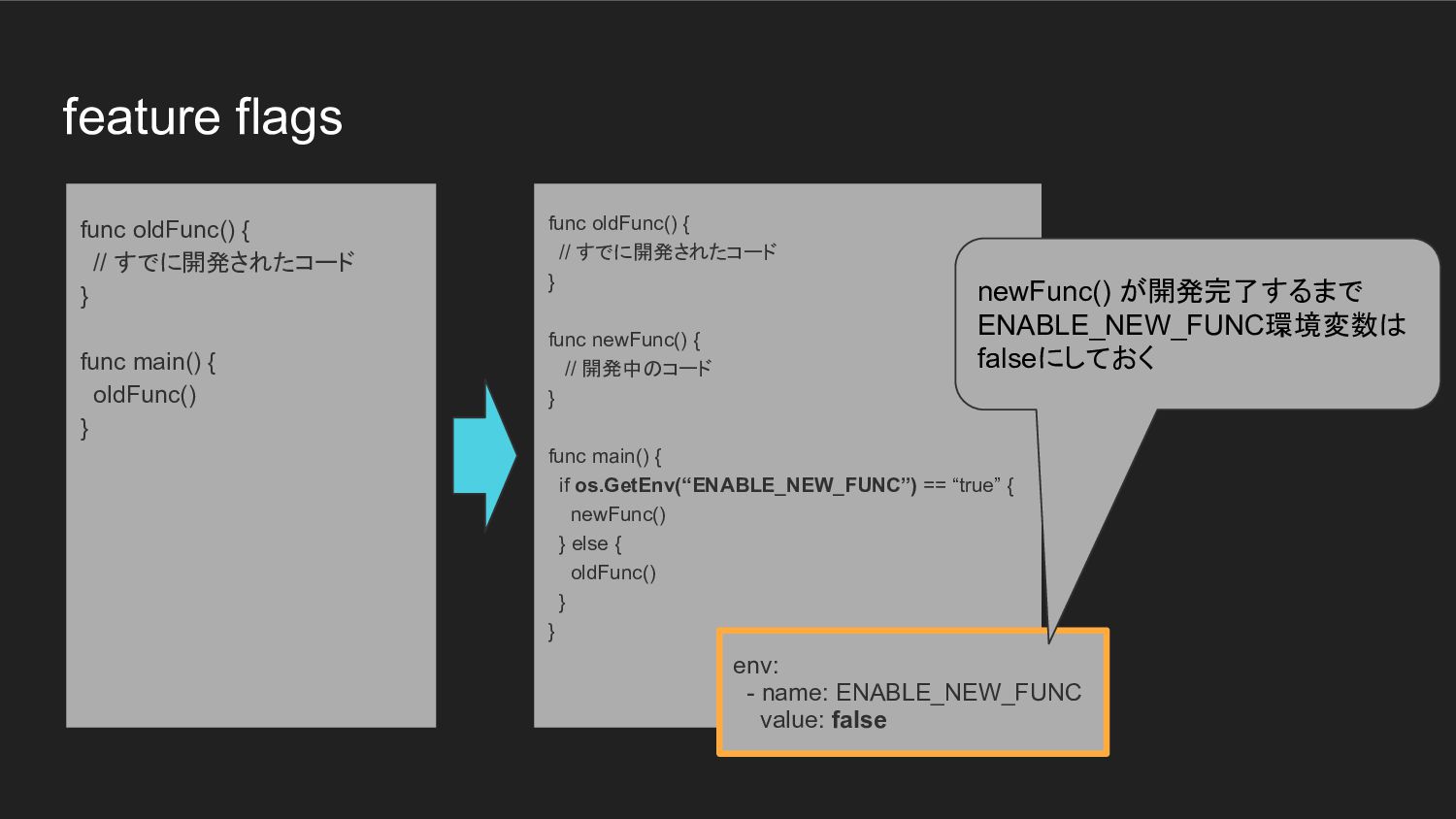
{ // 開発中のコード } func main() { if os.GetEnv(“ENABLE_NEW_FUNC”) == “true” { newFunc() } else { oldFunc() } } func oldFunc() { // すでに開発されたコード } func main() { oldFunc() } env: - name: ENABLE_NEW_FUNC value: false newFunc() が開発完了するまで ENABLE_NEW_FUNC環境変数は falseにしておく
feature flags func oldFunc() { // すでに開発されたコード } func newFunc()
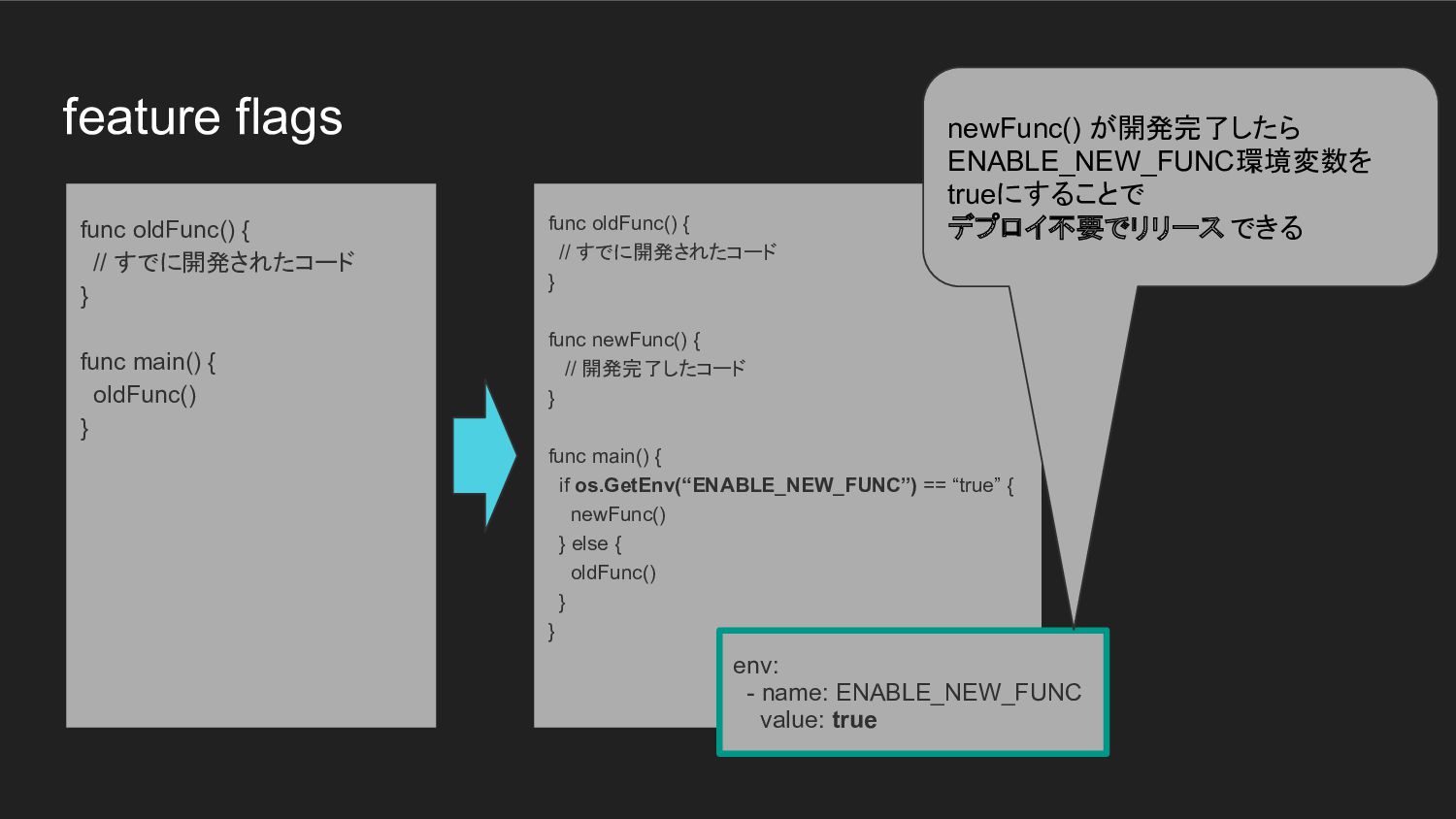
{ // 開発完了したコード } func main() { if os.GetEnv(“ENABLE_NEW_FUNC”) == “true” { newFunc() } else { oldFunc() } } func oldFunc() { // すでに開発されたコード } func main() { oldFunc() } env: - name: ENABLE_NEW_FUNC value: true newFunc() が開発完了したら ENABLE_NEW_FUNC環境変数を trueにすることで デプロイ不要でリリース できる
feature flags func oldFunc() { // すでに開発されたコード } func main()
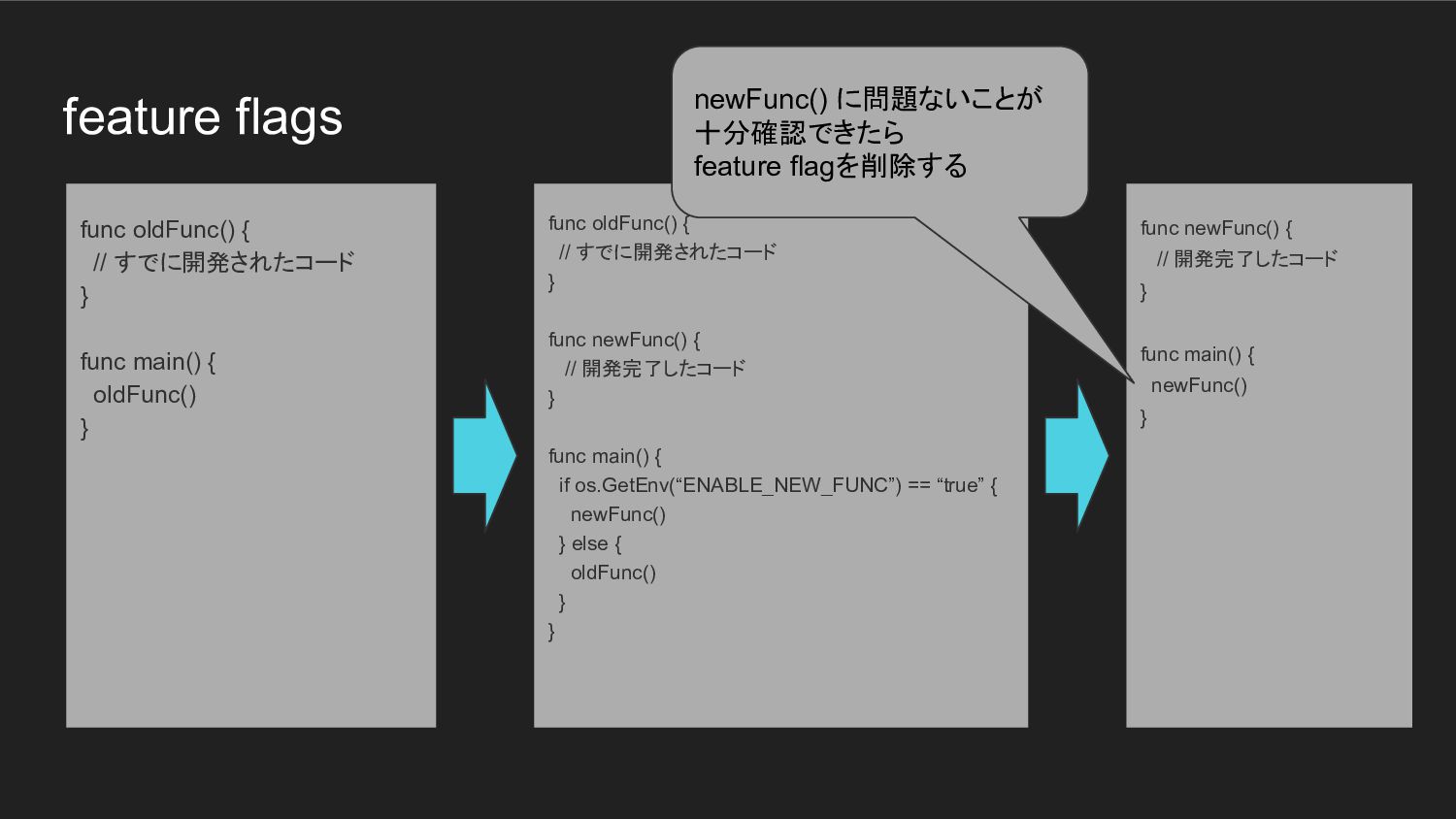
{ oldFunc() } func newFunc() { // 開発完了したコード } func main() { newFunc() } func oldFunc() { // すでに開発されたコード } func newFunc() { // 開発完了したコード } func main() { if os.GetEnv(“ENABLE_NEW_FUNC”) == “true” { newFunc() } else { oldFunc() } } newFunc() に問題ないことが 十分確認できたら feature flagを削除する
feature flagsのメリット • 「コードの変更」と「機能のリリース」 それぞれのタイミングを別々にコントロールできる ◦ main branchに開発途中のコードがあってもノーリスクでデプロイできる • コードに問題があっても迅速にロールバックできる
◦ feature flagsを折るだけでよい
feature flagsのデメリット • コードが複雑になる ◦ if文、デッドコード、etc • feature flags自体の管理コストがかかる ◦
flagが増えれば増えるほど管理が煩雑になる ◦ 専用の管理ツールもある (ex. LaunchDarkly)
feature flagsのデメリット • コードが複雑になる ◦ if文、デッドコード、etc • feature flags自体の管理コストがかかる ◦
flagが増えれば増えるほど管理が煩雑になる ◦ 専用の管理ツールもある (ex. LaunchDarkly) → 不要になったflagやif文、デッドコードはなるべく速やかに消す
トランクベース開発まとめ (feature branchを使わない方法) • メンバー全員がfeature branchを切らず main branchに直接commit & pushをすることで
merge conflictのリスクを回避する • 同期的なコードレビュー、ローカルでの自動テストにより 開発のアジリティを維持しつつコードの品質を保証する • feature flagsを用いることでmain branchを常にproduction readyにする
実際、feature branch無しで開発ができる? • 認証認可チームの判断としては「できなそう」 ◦ 同期レビューのタイミングを合わせることが困難 ▪ レビューの回数自体が多い ▪ レビュアーのスケジュールが詰まっている
◦ Pull RequestでのCI checkなしでmain commitの判断を下すことが困難 ▪ 当時チーム内の開発スキルにばらつきがあった
トランクベース開発の種類 • feature branchを使わない方法 (committing straight to the trunk) •
feature branchを使う方法 (short-lived feature branches)
トランクベース開発の種類 • feature branchを使わない方法 (committing straight to the trunk) •
feature branchを使う方法 (short-lived feature branches)
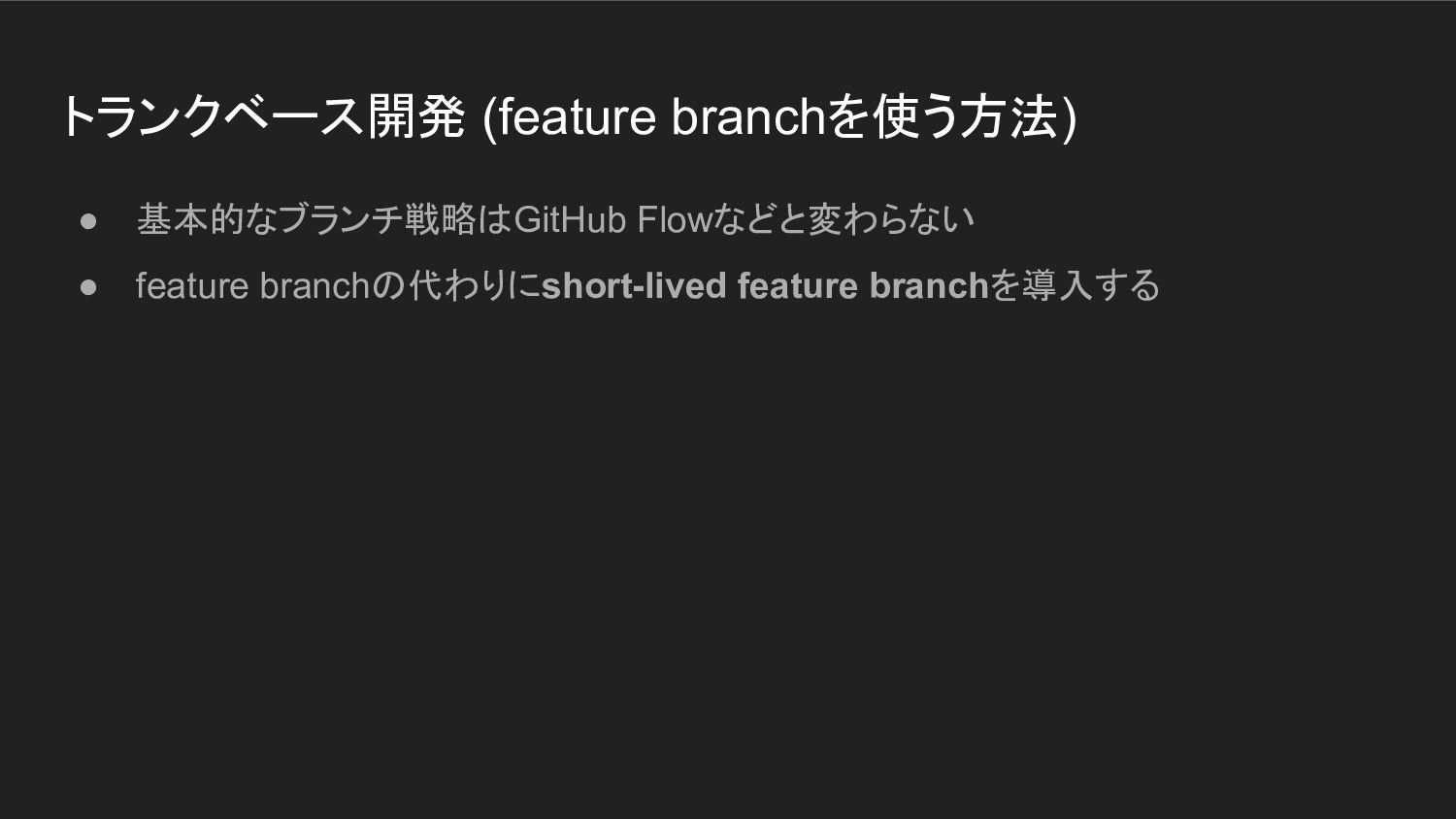
トランクベース開発 (feature branchを使う方法) • 基本的なブランチ戦略はGitHub Flowなどと変わらない • feature branchの代わりにshort-lived feature
branchを導入する
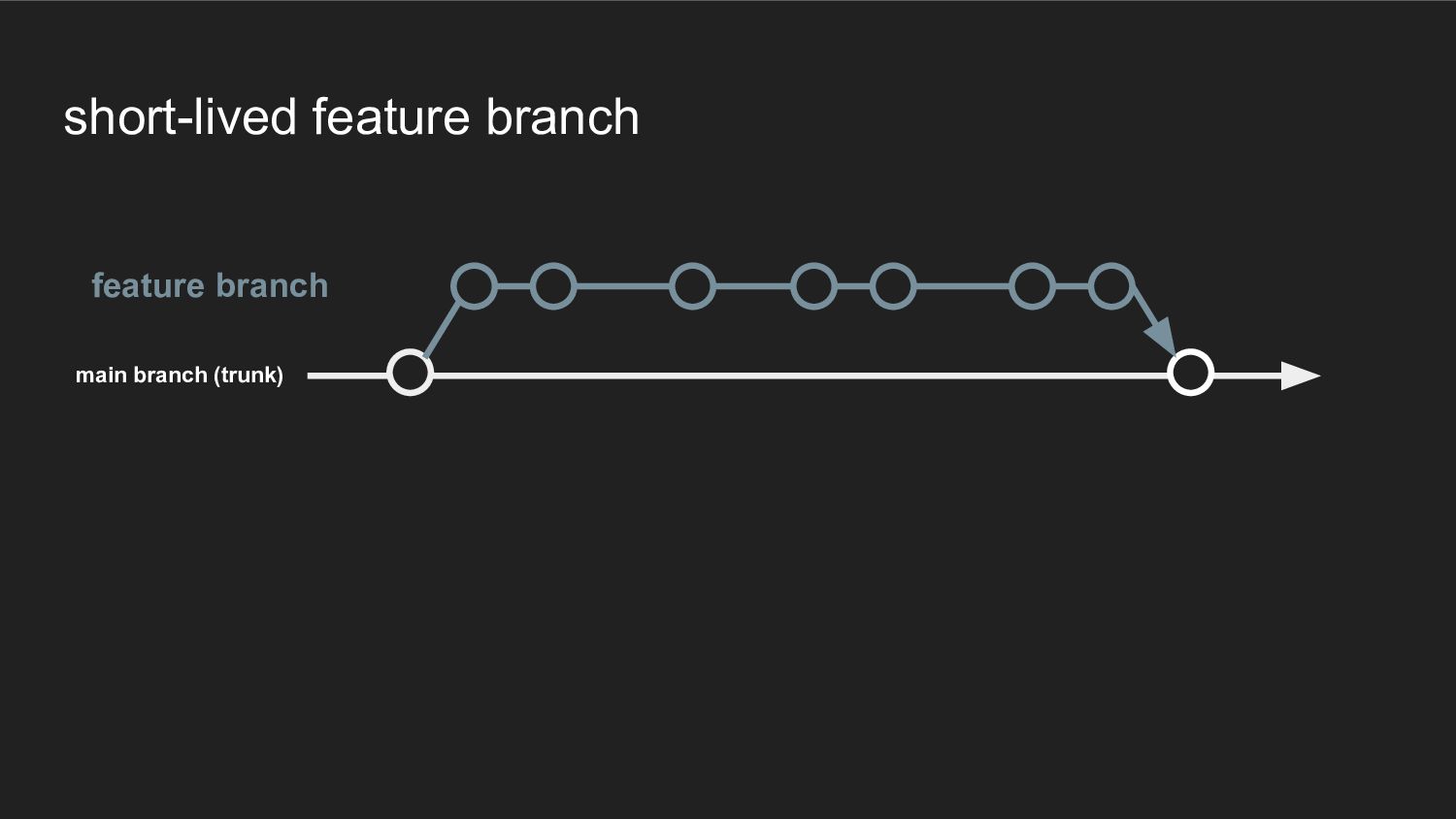
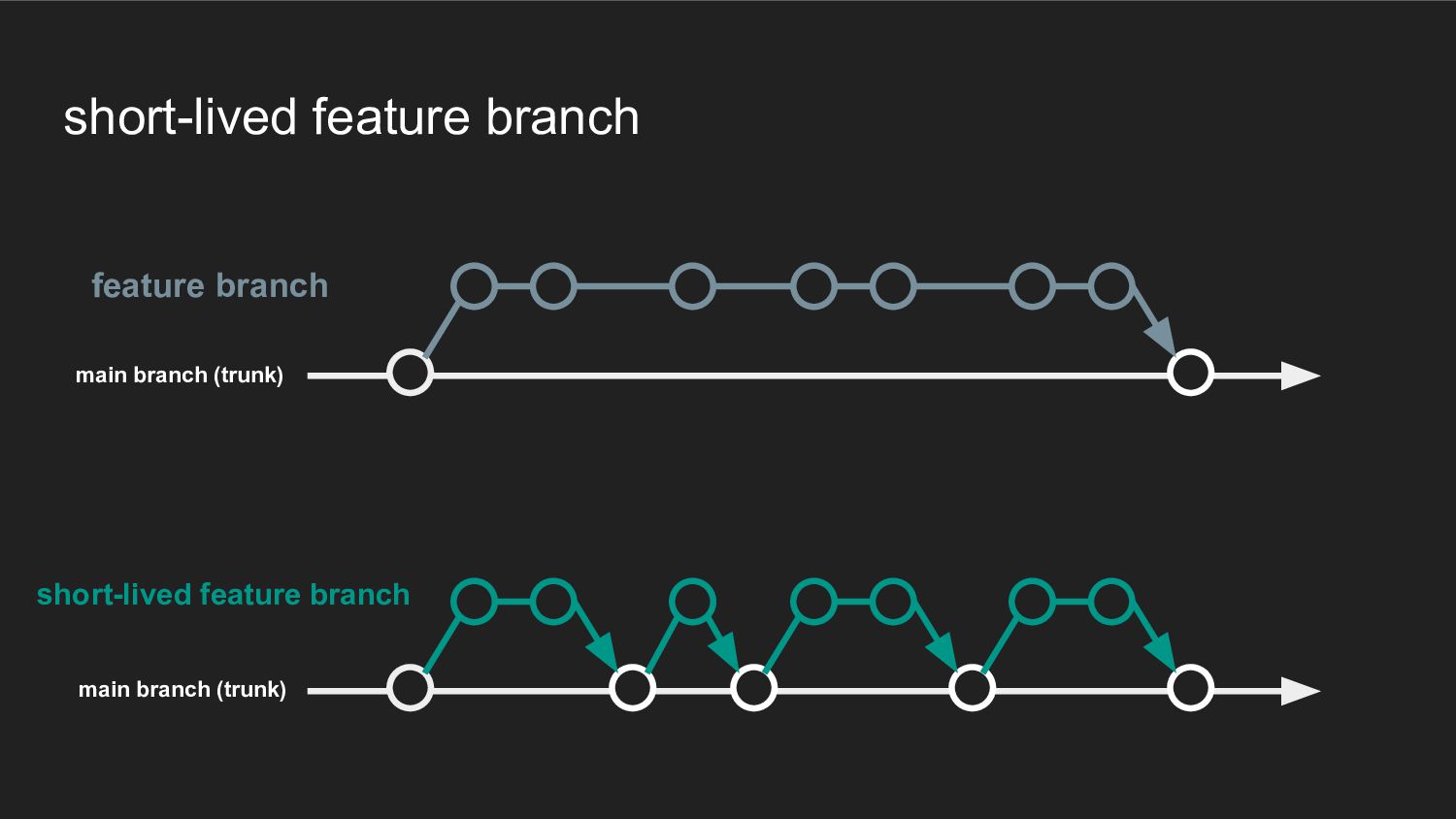
short-lived feature branch feature branch main branch (trunk)
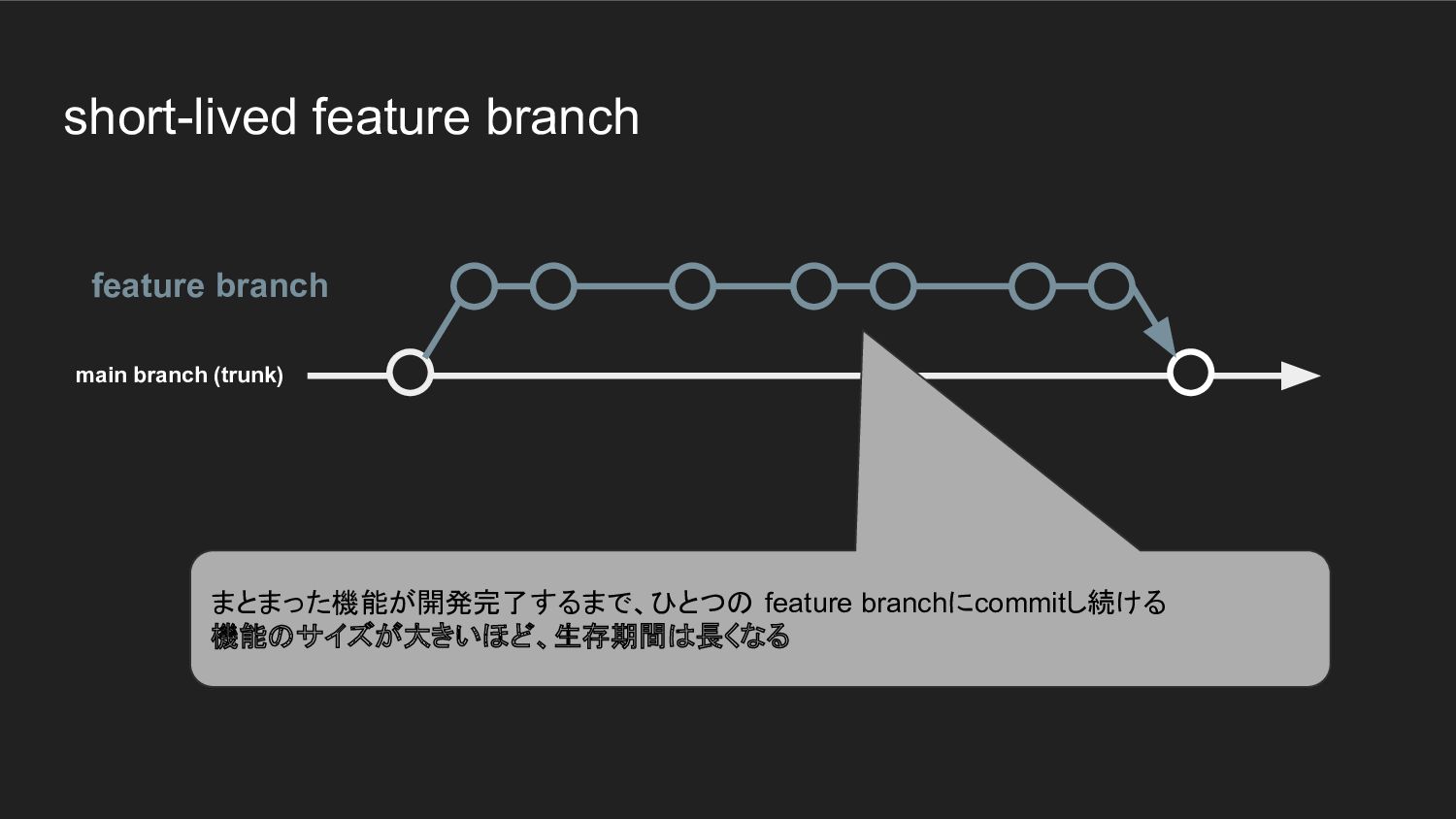
short-lived feature branch feature branch まとまった機能が開発完了するまで、ひとつの feature branchにcommitし続ける 機能のサイズが大きいほど、生存期間は長くなる main
branch (trunk)
short-lived feature branch short-lived feature branch feature branch main branch
(trunk) main branch (trunk)
short-lived feature branch short-lived feature branch feature branch 同じ機能を複数の小規模な short-lived
branchによって開発する 個々のbranchを数日以内にmergeすることで mergeのconflictリスクと解消コストを抑える main branch (trunk) main branch (trunk)
short-lived feature branchのルール • 作成後数日以内にmergeし、削除しなければならない ◦ trunkbaseddevelopment.com では2日以内を推奨している ◦ merge時点で必ずしも機能の開発が完了している必要はない
▪ feature branchを使わないトランクベース開発 (committing straight to the trunk) と同じ • main branch (trunk) 以外にmergeしてはいけない • branchを切った開発者、およびペアプログラミングでの共同作業者以外がcommit してはいけない ◦ あくまでmain branchを開発の中心とするべきである
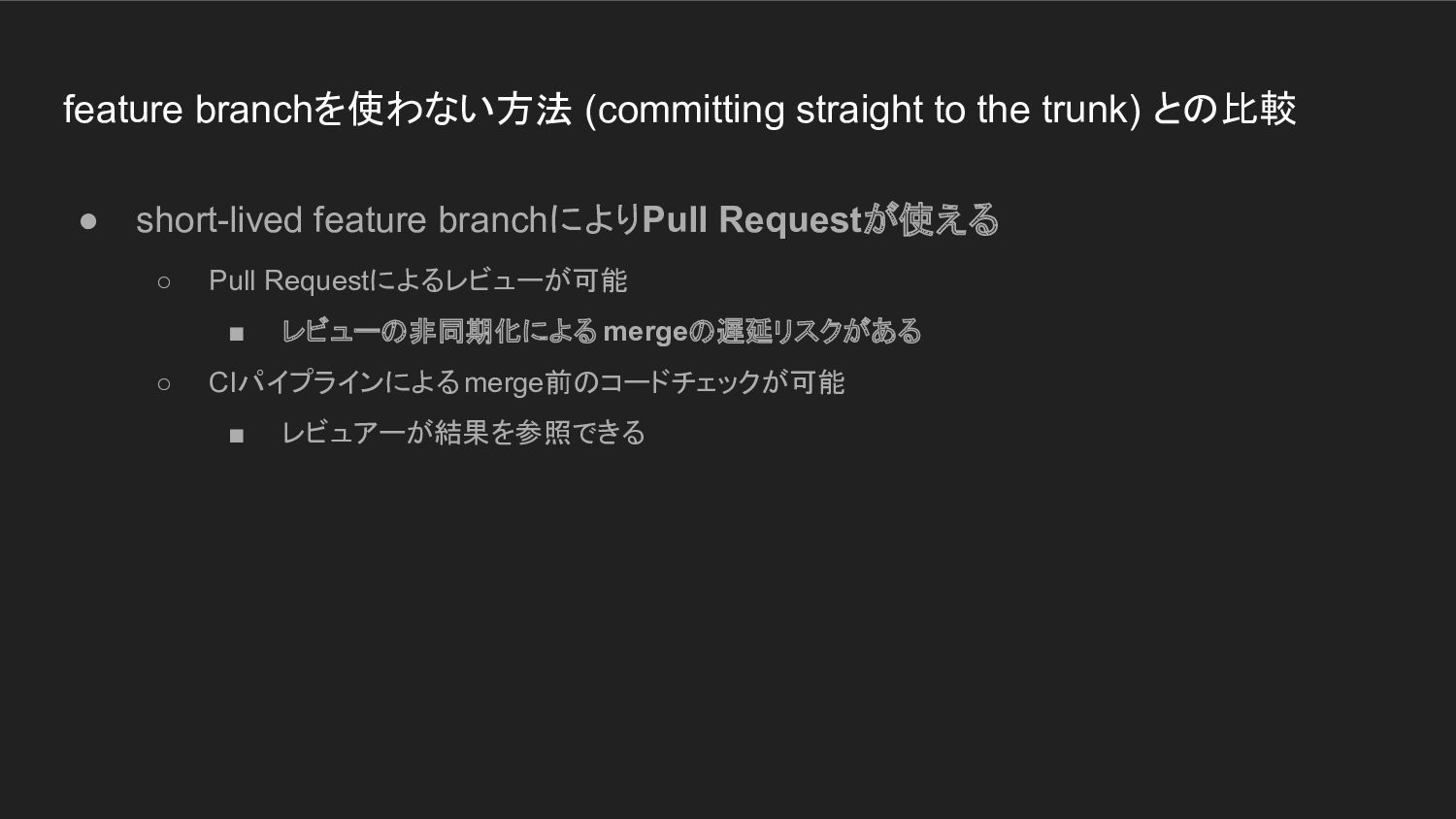
feature branchを使わない方法 (committing straight to the trunk) との比較 • short-lived
feature branchによりPull Requestが使える ◦ Pull Requestによるレビューが可能 ▪ レビューの非同期化による mergeの遅延リスクがある ◦ CIパイプラインによるmerge前のコードチェックが可能 ▪ レビュアーが結果を参照できる
どちらを選択するか? • feature branchを使わないほうが高い開発速度を得られる ◦ Pull Requestを作成する手間が省ける ◦ feature branchが肥大化するリスクをより減らすことができる
◦ 同期レビューを強制しやすい • (short-lived) feature branchを使った方が trunk (main branch) をバグから保護しやすい ◦ Pull Request に対してCI checkをかけられる
どうやってトランクベース開発を実践するか?
僕が所属する マイクロサービスアーキテクトグループ 認証認可チーム での取り組みを紹介します
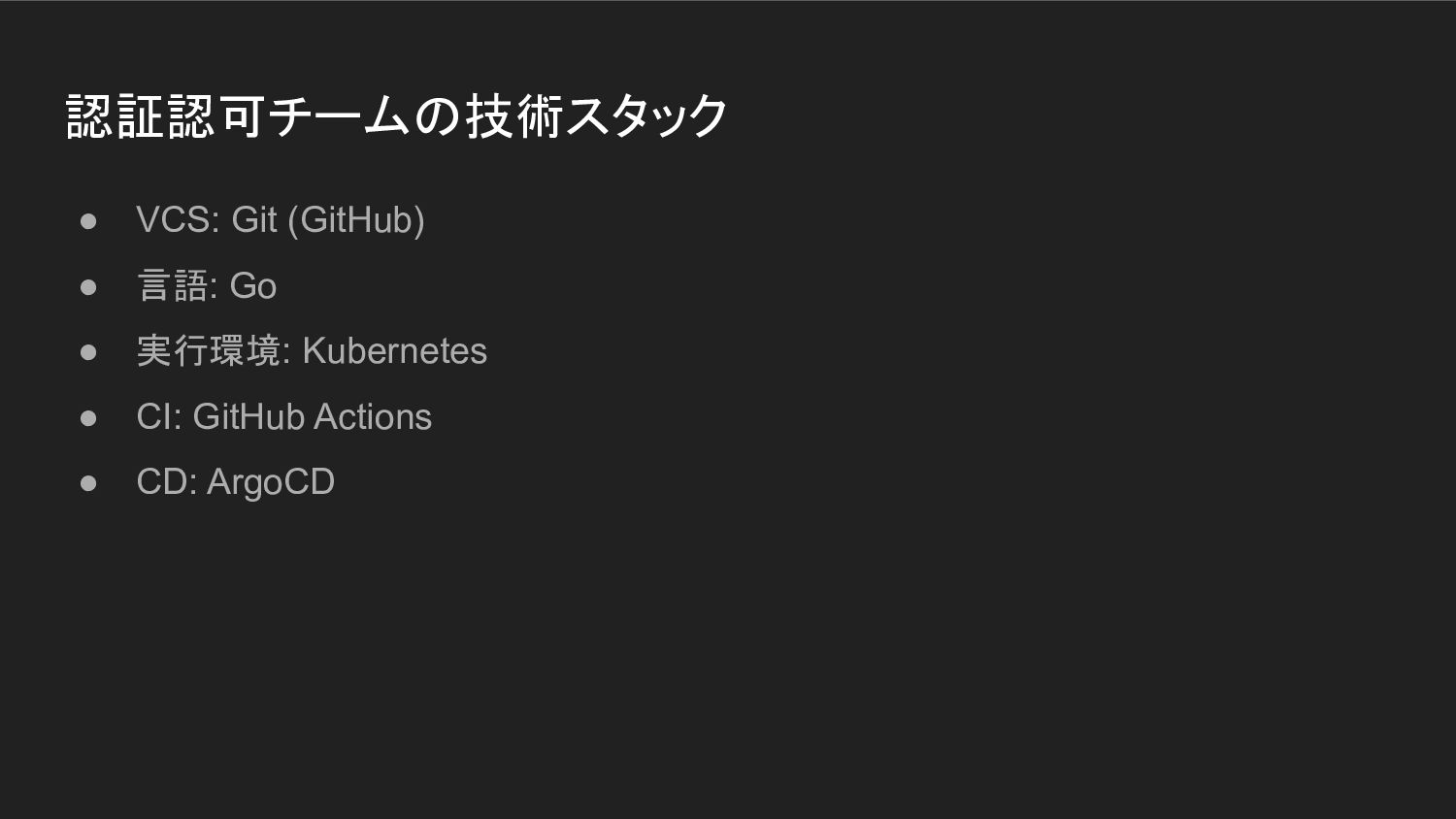
認証認可チームの技術スタック • VCS: Git (GitHub) • 言語: Go • 実行環境:
Kubernetes • CI: GitHub Actions • CD: ArgoCD
トランクベース開発の導入背景 • PFや全社のマイクロサービス化推進に伴い トランクベース開発の導入が検討された ◦ Two pizza rule ▪ マイクロサービスを運用するチームの人数は
2つのピザを分け合える程度が妥当 • 6-10人ぐらい、という説も : https://jasoncrawford.org/two-pizza-teams ▪ これだけの開発者がひとつのコードベースを積極的に保守する場合 conflictのリスクが現実的に避けられなさそう • マイクロサービスアーキテクトグループで 人柱 PoCを実施することとなった ◦ チーム発足後初めてのサービス開発において適用されることとなった
トランクベース導入にあたってやったこと • 開発フローの整備 • 効果の測定
トランクベース導入にあたってやったこと • 開発フローの整備 • 効果の測定
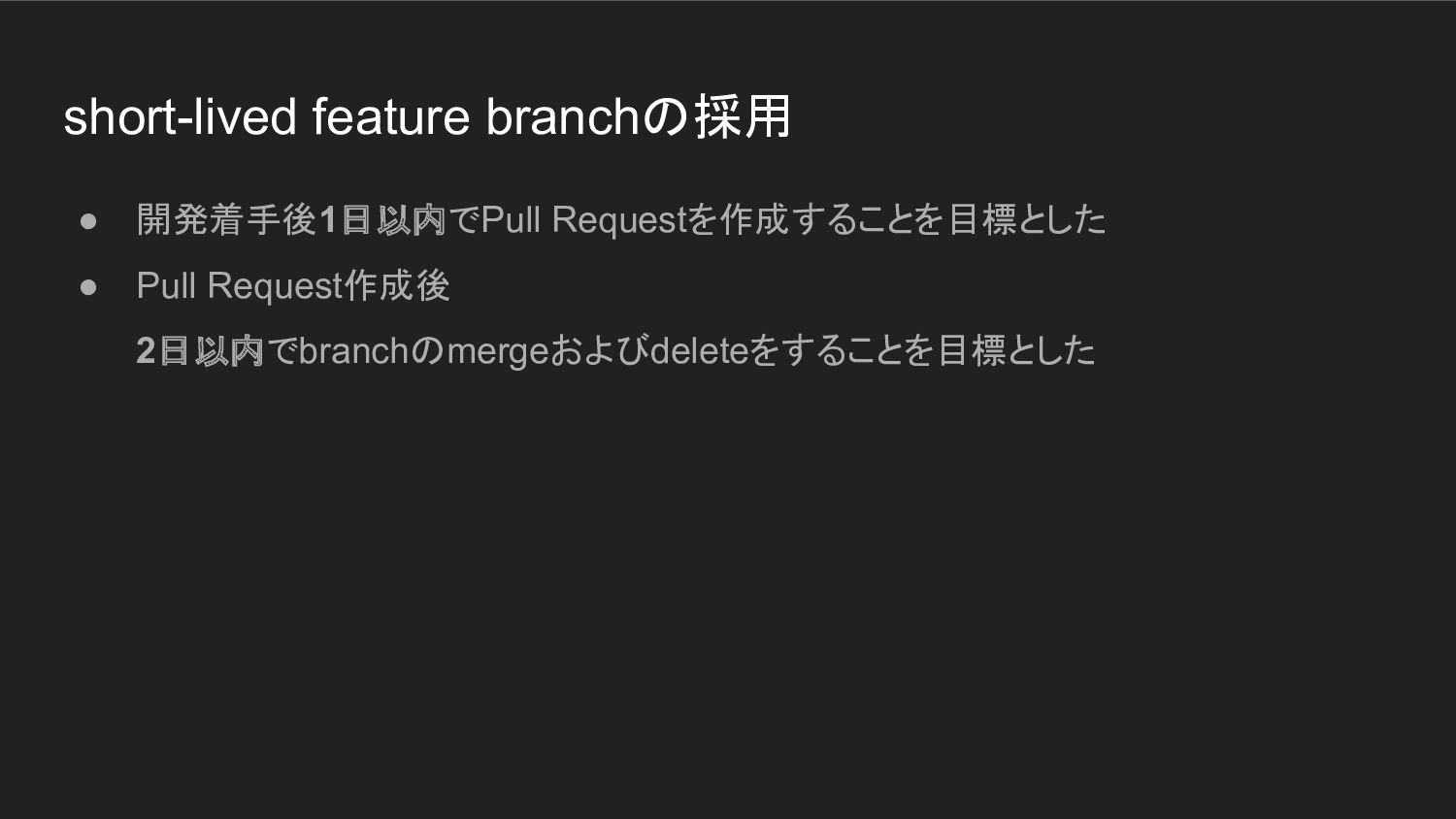
short-lived feature branchの採用 • 開発着手後1日以内でPull Requestを作成することを目標とした • Pull Request作成後 2日以内でbranchのmergeおよびdeleteをすることを目標とした
(同期 or 非同期) コードレビュー • 基本的には非同期なコードレビューを採用 ◦ Goのコードレビューを務められるレビュアーが 1人しかおらず 同期レビューのタイミングを確保することが困難
• PR作成後なるべく24時間以内にレビュー対応するようにした ◦ GitHubのSlack連携機能でアサインされたレビュワーに通知を送るようにした • 一部のレビュー観点についてはCIパイプラインで自動化した ◦ 単体テストの成否、Lintによるコーディングルール違反の検知、 etc
トランクベース導入にあたってやったこと • 開発フローの整備 • 効果の測定
測定指標: サイクルタイム • ここでは「feature branchにfirst commitされてからmain branchにmerge されるまでの期間」と定義 ◦ 変更をどれだけ早くmain
branchに取り込めたかを示す指標として採用 ◦ gitにおいて、branchの作成日時はそもそも記録されていない ため branchの生存期間を直接計測することはできない
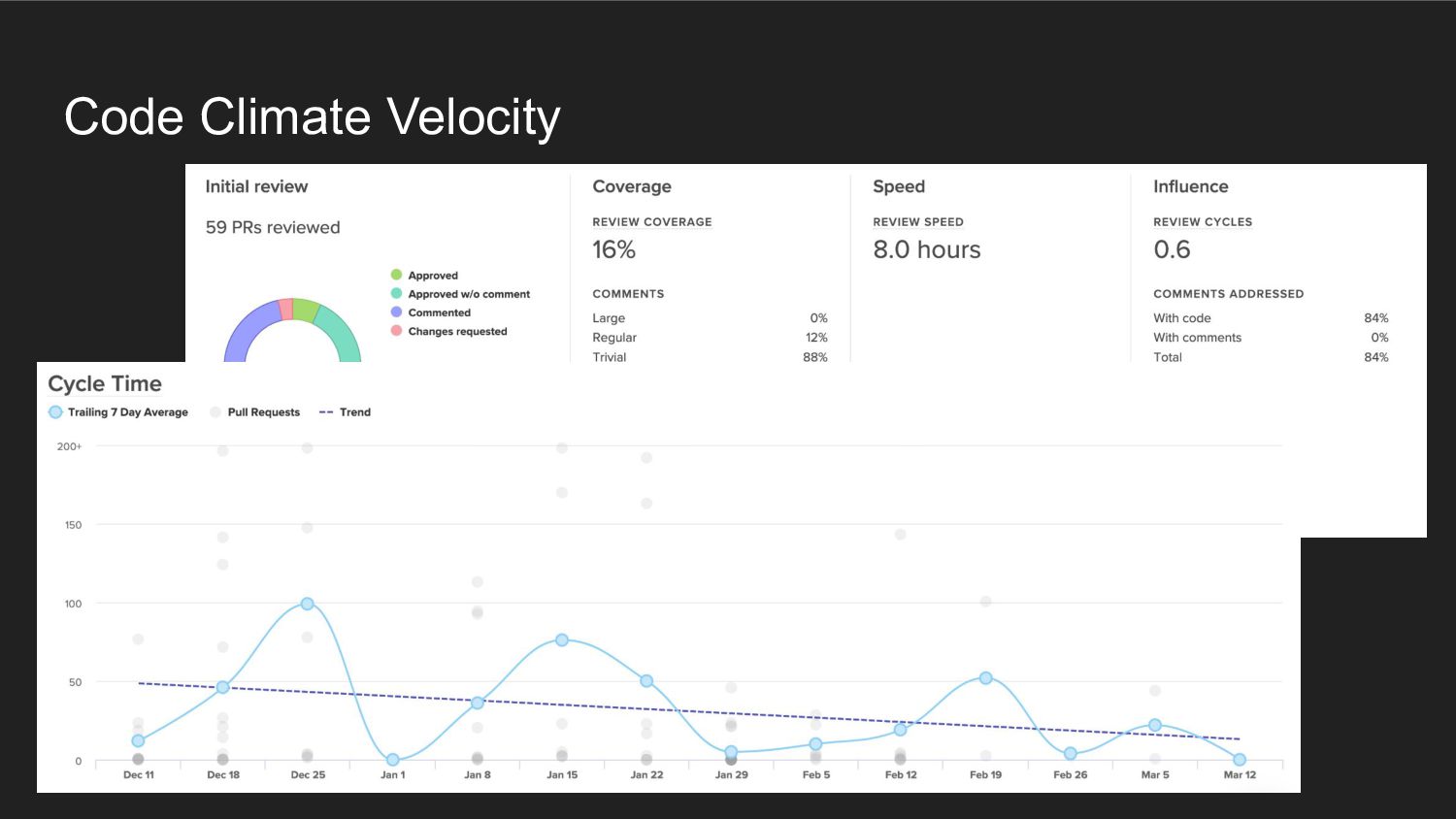
Code Climate Velocity
Code Climate Velocity • エンジニア組織のパフォーマンス可視化ツール ◦ サイクルタイムの計測や、 PRレビューまでの待機時間を可視化 ◦ 現在はFindy
Teamsも並行運用中 • 週次の保守運用定例でチェック ◦ 目標を達成できなかった場合、その原因を考える
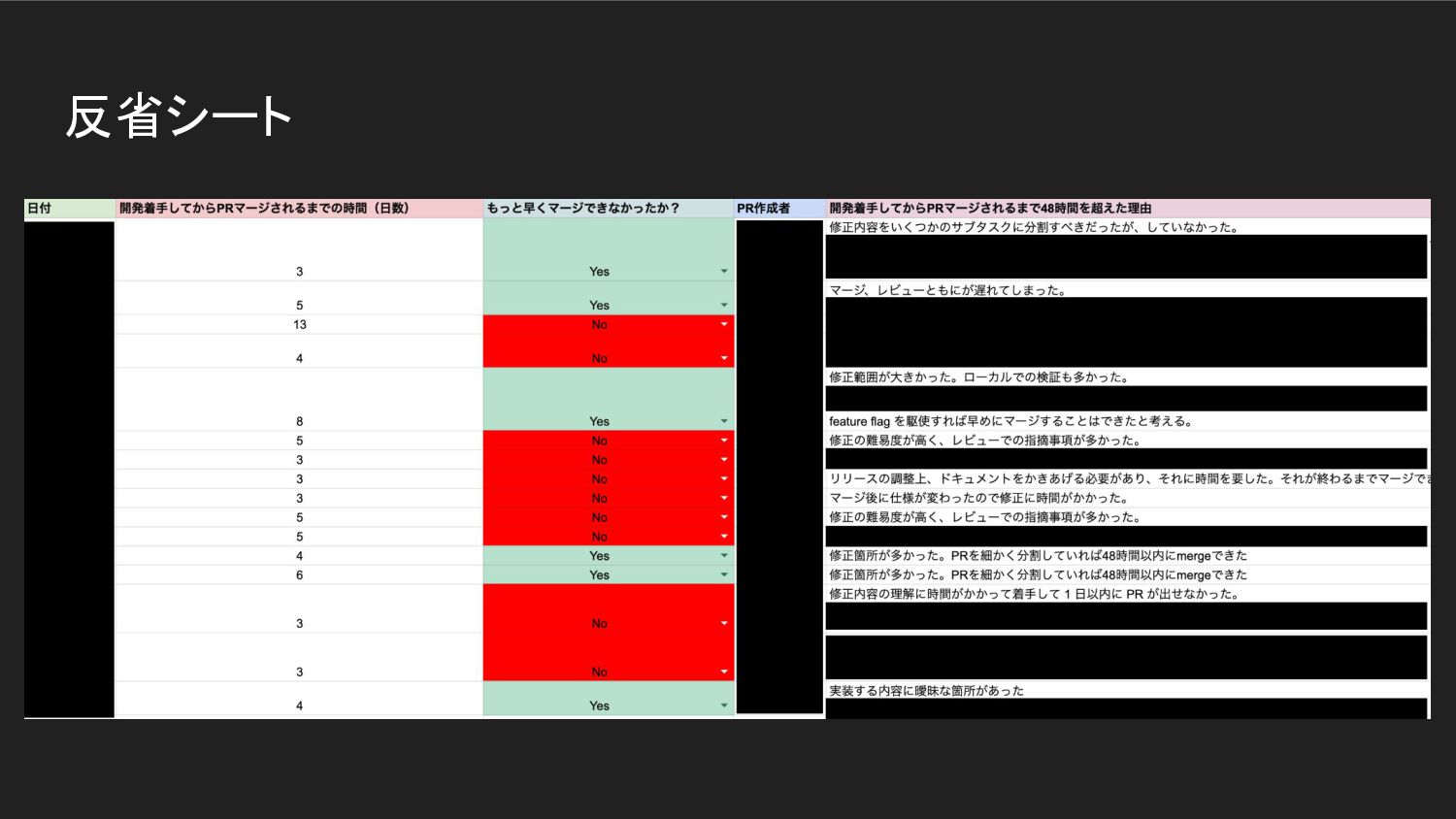
反省シート •
反省シート • トランクベース開発のルール (1日以内にPR作成、2日以内にmerge) を 守れなかった場合、その反省を行い、スプレッドシートに記載 ◦ 週次の保守運用定例で確認・記入 • ルールや仕組みの改善につながる意見の抽出を目指す
◦ 「頑張りが足りませんでした」「注意が足りませんでした」は禁止
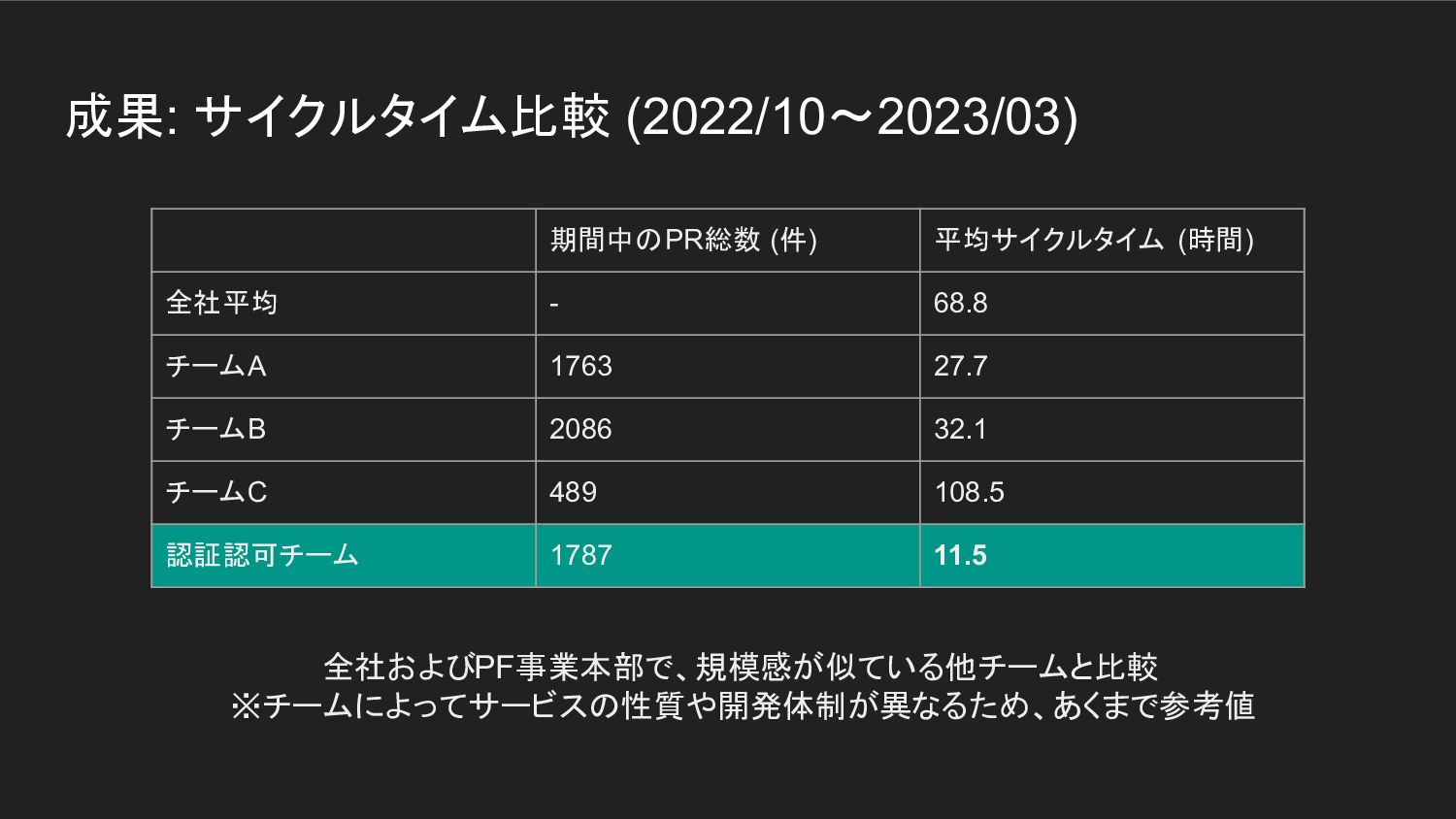
成果: サイクルタイム比較 (2022/10〜2023/03) 期間中のPR総数 (件) 平均サイクルタイム (時間) 全社平均 - 68.8
チームA 1763 27.7 チームB 2086 32.1 チームC 489 108.5 認証認可チーム 1787 11.5 全社およびPF事業本部で、規模感が似ている他チームと比較 ※チームによってサービスの性質や開発体制が異なるため、あくまで参考値
開発フローをどのように改善していったか?
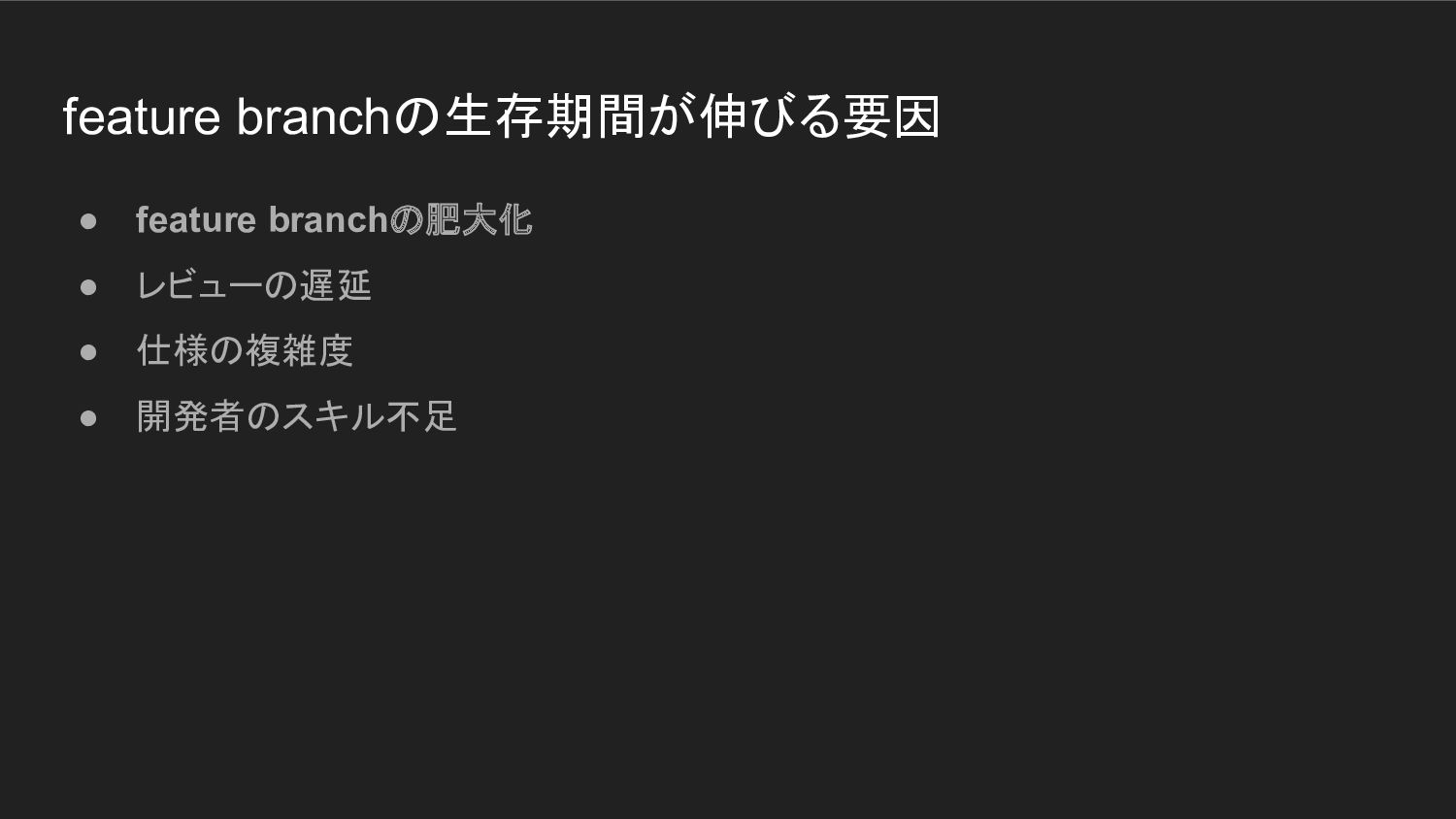
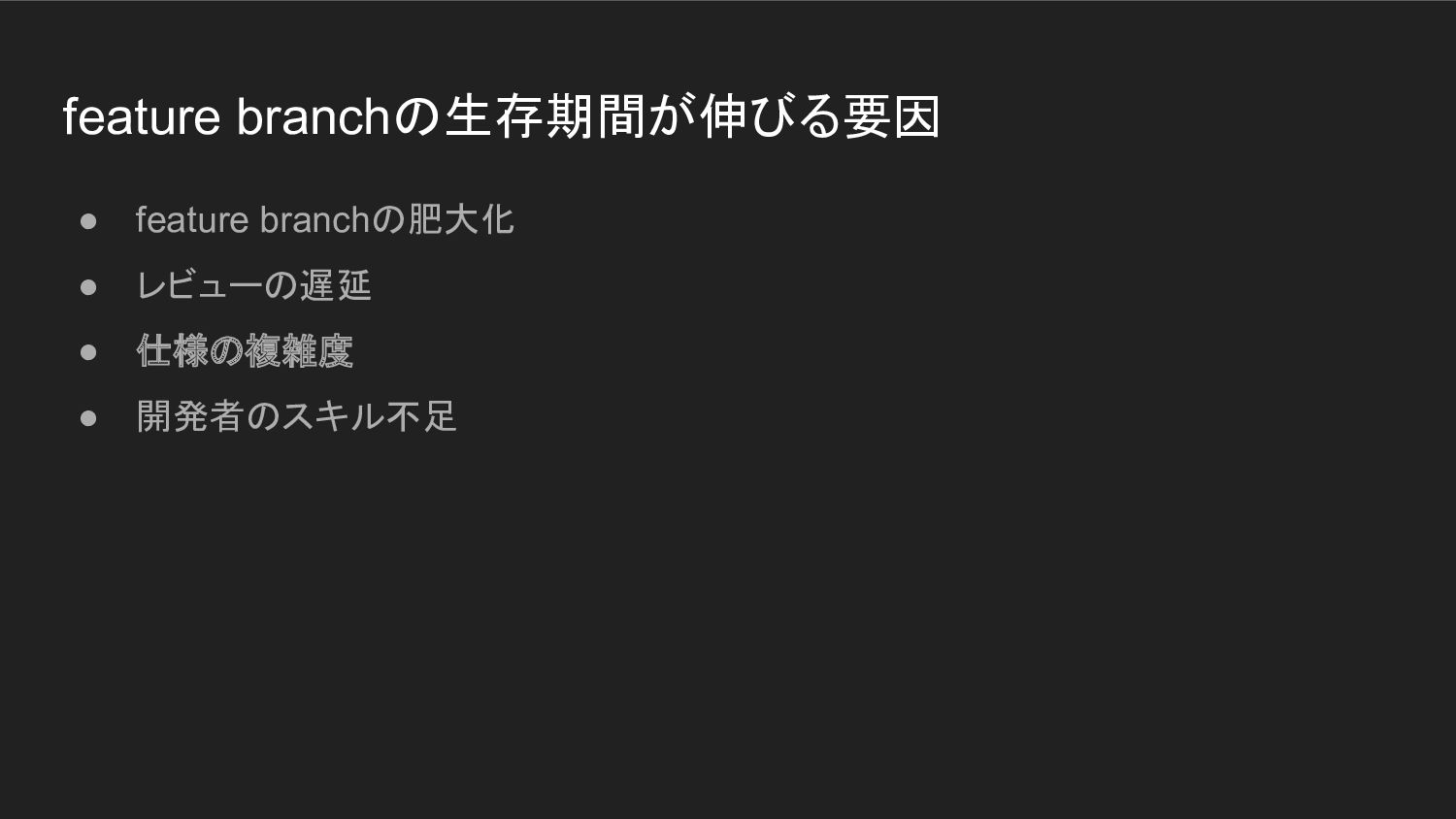
トランクベース開発実践の中で直面した課題 • short-lived feature branchの実現が難しい ◦ 「気をつける」だけでは無理 ◦ branchの生存期間が伸びるのには、 構造的な要因がある
feature branchの生存期間が伸びる要因 • feature branchの肥大化 • レビューの遅延 • 仕様の複雑度 •
開発者のスキル不足
feature branchの肥大化 • feature branchのサイズ (feature branchに含まれるコードの変更行数) が 多ければ多いほど、mergeまでにかかる時間が伸びる •
認証認可チームでは 変更行が600行以上あるPull Requestは原則rejectしている ◦ 問答無用でCI checkを落とす ▪ https://github.com/CodelyTV/pr-size-labeler ◦ 閾値は過去の事例をみて判断した
feature branchのサイズが大きくなる要因 • ひとつのfeature branchで全てを実装しようとしてしまう • 例: サービスにWebAPIを新規追加する ◦ ハンドラーの追加、ドメインモデルの追加、
DBや外部APIとの通信などの実装を すべての一つのfeature branchの中で完結させる必要はない ◦ ハンドラーを後で実装するなり、 feature flagsを使うなりすれば 開発中の機能をクライアントから隠蔽することができる
feature branchのサイズを小さく保つために • タスク整理 (Planning) の段階で個々のタスクの粒度を確認する ◦ 目標を具体的にイメージできる粒度にまでタスクを分解する ▪ ex.
WebAPIを新規作成するために必要なサブタスクを事前にリストアップする • ハンドラーの追加, ドメインモデルの追加 , DBや外部APIとの通信, etc ▪ 分解できないようなら、まず調査タスクを切る ◦ 細分化されたひとつのタスクにつき、一個以上の feature branchを切る • 途中で必要なタスクに気づいても、そのbranchの中ではやらない ◦ TODOコメントをつけておいて、一旦その branchはmergeしてしまう ◦ あとで新たにfeature branchを切って対応する
タスクの分解にかかる難しさ • コーディングの前に必要な実装タスクを洗い出すことの難しさ ◦ コーディングしながら考えるのよりも難しい • 細分化されたPull Requestをみて変更の妥当性を 検証することの難しさ ◦
全体像を把握しにくい
タスクの分解にかかる難しさ • コーディングの前に必要な実装タスクを洗い出すことの難しさ ◦ コーディングしながら考えるのよりも難しい • 細分化されたPull Requestをみて変更の妥当性を 検証することの難しさ ◦
全体像を把握しにくい → ふつうの開発よりも難易度は上がる (難易度の高さとconflictリスク・解消コストとのトレードオフ)
feature branchの生存期間が伸びる要因 • feature branchの肥大化 • レビューの遅延 • 仕様の複雑度 •
開発者のスキル不足
レビューの遅延 • 非同期レビューは後回しになりがちである ◦ (大抵チームをリードするポジションにある)レビュアーは普段から忙しかったりする • レビュアーを増やすことができればいいが、現実的には難しい ◦ チームの中にレビューできるだけの知識とスキルをもったエンジニアがそう何人もいるわけではな い
なるべくレビューのコストを下げる • Pull Request (feature branch) のサイズを小さくする ◦ ひとつのPull Requestに対するレビュー所要時間を短縮できる
→スキマ時間でレビューができる →スケジュールの融通が効く • 時間を確保して同期レビューする ◦ コードを書いた人に直接説明してもらうのが一番早い ◦ 僕自身、ぱっと見で指摘事項が多くなりそうな時や レビュー→修正が一巡してもなお修正点が残っている場合は同期レビューに切り替える
それでもレビューに時間がかかる場合 • 時間をかけてPull Requestの完成度を追求している間に main branchがどんどん更新されていく ◦ conflictのリスクが高まる • 途中で区切りをつけてmergeしてしまうのも手
◦ ビルドやテストが通れば一旦 OK、でもよい • TODOコメントをつけておいて、後で直す ◦ TODOコメントからGitHub Issuesを作成 ▪ https://github.com/alstr/todo-to-issue-action ▪ main branchへのpushにフックさせて実行している ◦ 切ったIssueはDaily standupで拾って修正スケジュールを組む
feature branchの生存期間が伸びる要因 • feature branchの肥大化 • レビューの遅延 • 仕様の複雑度 •
開発者のスキル不足
仕様の複雑度 • 複雑な仕様を実装したコードは、どうしても複雑になってしまう ◦ 実装にもレビューにも時間がかかる • レビュアーとの認識違いにより、手戻りが発生するリスクがある • 仕様を単純にできるなら、それに越したことはない ◦
要件定義に介入する ◦ 込み入った仕様も、課題を分割して小さい単純な仕様に落とし込めるかもしれない • それがダメなら、仕様や実装方針について レビュアーと事前にすり合わせておく
feature branchの生存期間が伸びる要因 • feature branchの肥大化 • レビューの遅延 • 仕様の複雑度 •
開発者のスキル不足
開発者のスキル不足 • そもそも開発経験に乏しかったり、ドメイン知識が不足しているメンバーが 妥当性のあるコードを書くのは難しい ◦ チームに入って間もないエンジニアなど • 知識をキャッチアップしてもらうしかない ◦ オンボーディングとして簡単なタスクを与える
◦ ペアプログラミングで密にコミュニケーションをとる • 既存メンバーをメンターとしてアサインする ◦ わからないことがあれば即質問してもらう
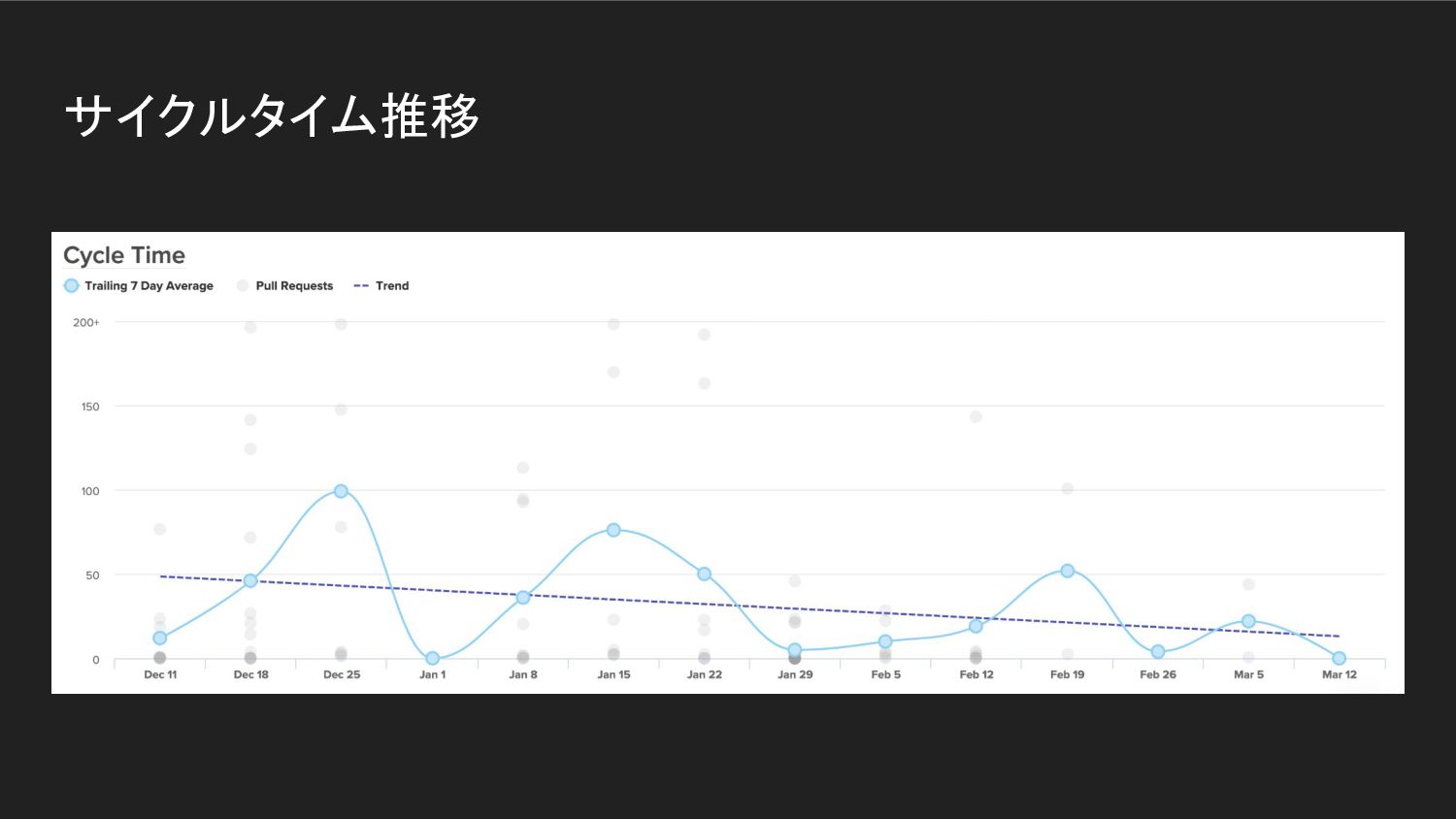
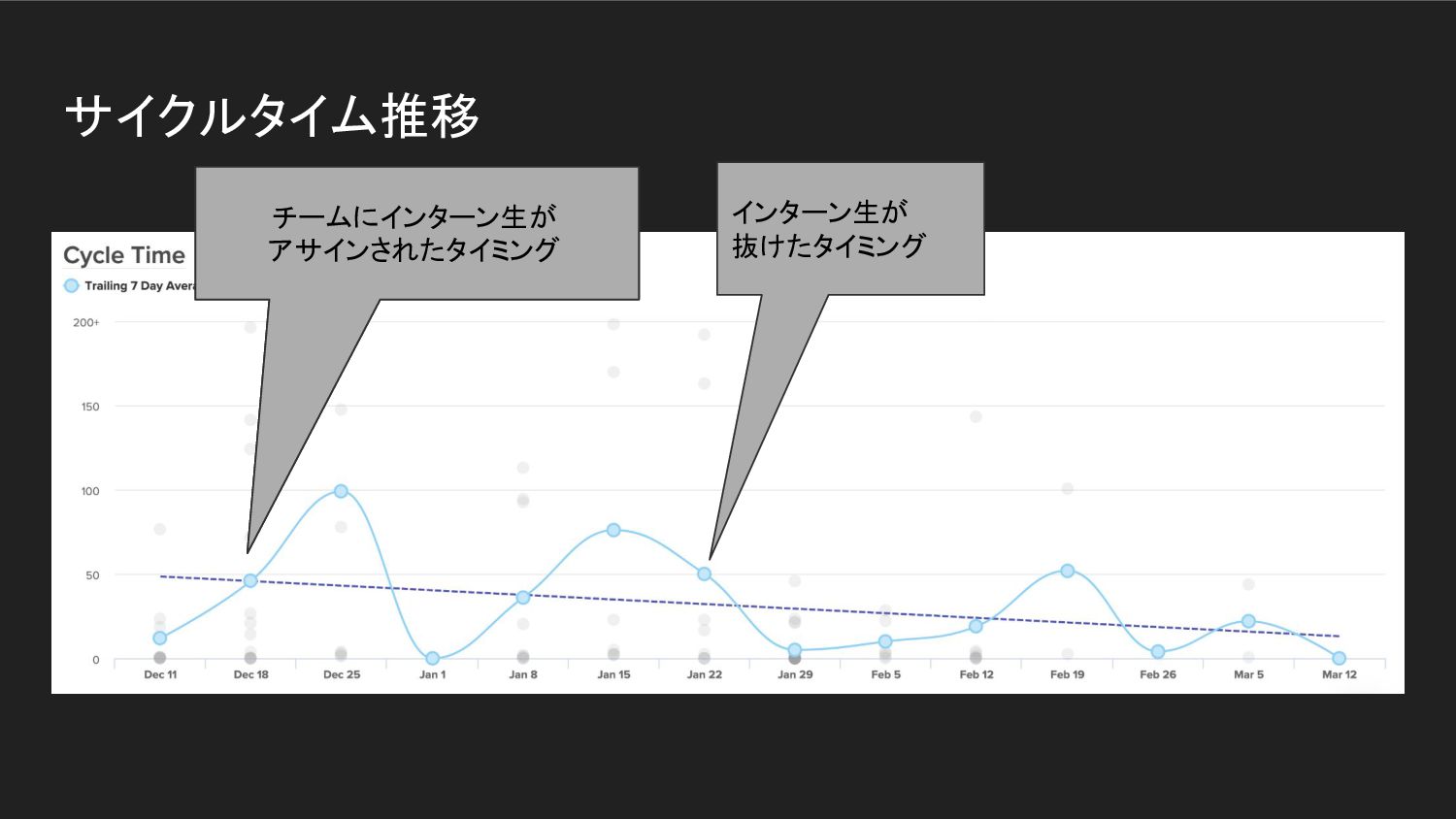
サイクルタイムの不安定化 • チームとしてのサイクルタイムはチームの状況によって大きく左右される ◦ チームに新規メンバーが参入したとき ◦ (特にジュニアな) エンジニアにチャレンジングなタスクがアサインされたとき
サイクルタイム推移
サイクルタイム推移 チームに新規メンバーが アサインされたタイミング チームにインターン生が アサインされたタイミング インターン生が 抜けたタイミング
まとめ
トランクベース開発を導入してよかったこと • サイクルタイムを短く保つことで、開発速度を維持することができた • 開発着手から1日以内でPull Request作成、2日以内でmergeという 明確な目標のおかげで、開発速度改善に向けた建設的な議論ができた • チーム内のノウハウを用いて、他チームの開発速度を改善することもできた ◦
Developers Summit 2023でチームメンバーが発表 ▪ DMMプラットフォームでプルリクエストのマージ時間を 250時間から50時間に減らした話 ▪ https://speakerdeck.com/juve534/improve-development-efficiency-with-dmm-platform
課題 • 現状計測しているサイクルタイムは 個々のfeature branchの生存期間を示しているに過ぎない ◦ 本質的には、個々の機能やそれによる価値を どれだけ早くユーザーにデリバリーできたか を測る必要がある ▪
変更のリードタイムそのもの をみなければいけない • 計測を試みているが、まだできていないポイント ◦ (トランクベース開発自体の課題ではないが …)
採用 合同会社DMM.comマイクロサービスアーキテクトグループ認証認可チームではエンジ ニアを募集しています! マネージャーのpospomeによる カジュアル面談も実施しています ご興味のある方は是非 https://dmm-corp.com/recruit/engineer/2/
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}