study that gives the computer the ability to learn computer the ability to learn without being explicitly without being explicitly programmed. » programmed. » — Arthur Samuel (1959) — Arthur Samuel (1959)
: on cherche à produire automatiquement des règles à partir d'une base de données d'apprentissage contenant des exemples . Apprentissage Non-Supervisé (clustering) : Diviser un groupe hétérogène de données, en sous-groupes de manière à ce que les données considérées comme les plus similaires soient associées au sein d'un groupe commun. Apprentissage par renforcement : utilisé en Robotique
this link to win 100% free Cinema coupon. spam spam Hey George make sure to bring your coupon to the supermarket. ham George the supermarket is closed ! Ham spam ? Naive Bayes Naive Bayes
work?" "spam","You are a winner U have been specially selected 2 receive £1000 cash or a 4* holiday (flights inc) speak to a live operator 2 claim 0871277810810"
est, au cours d'une période donnée, la proportion de clients perdus ou ayant changé de produit et service de la même entreprise. - Abandon et résiliation - Passage à la concurence L'acquisition de nouveaux clients est 15 plus coûteuse que de conserver ceux existants.
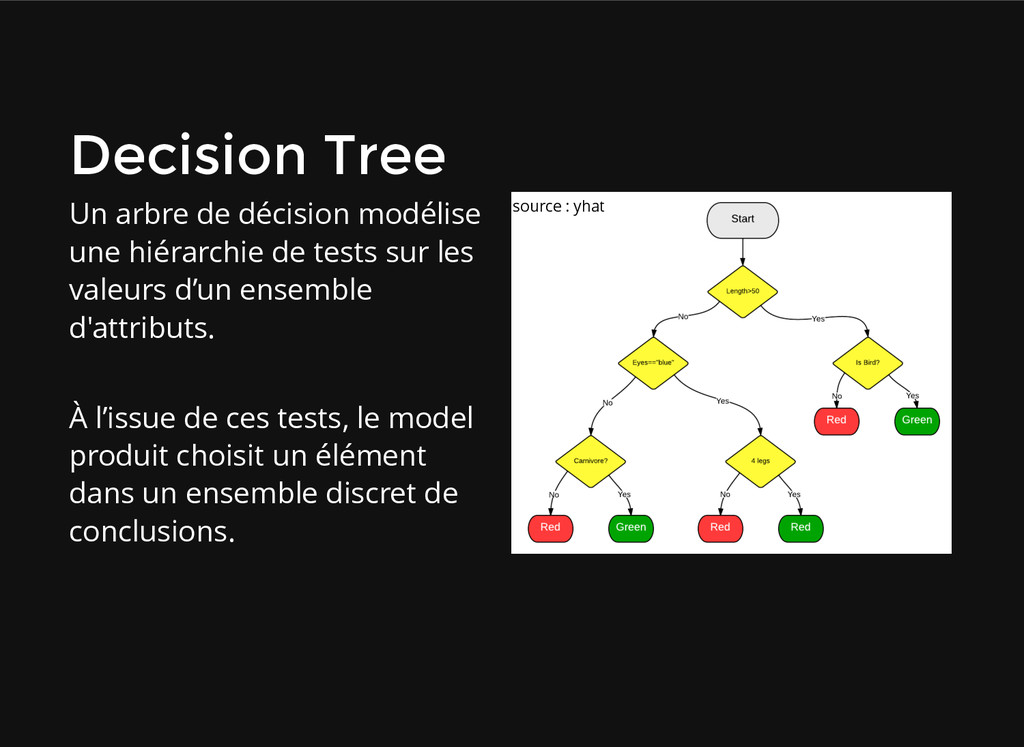
hiérarchie de tests sur les valeurs d’un ensemble d'attributs. À l’issue de ces tests, le model produit choisit un élément dans un ensemble discret de conclusions. source : yhat
sklearn.ensemble import RandomForestClassifier RF = RandomForestClassifier(n_estimators=10, n_jobs=5) RF.fit(X,y) Production de plusieurs arbres de décision , le résultat final est conclu par vote.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
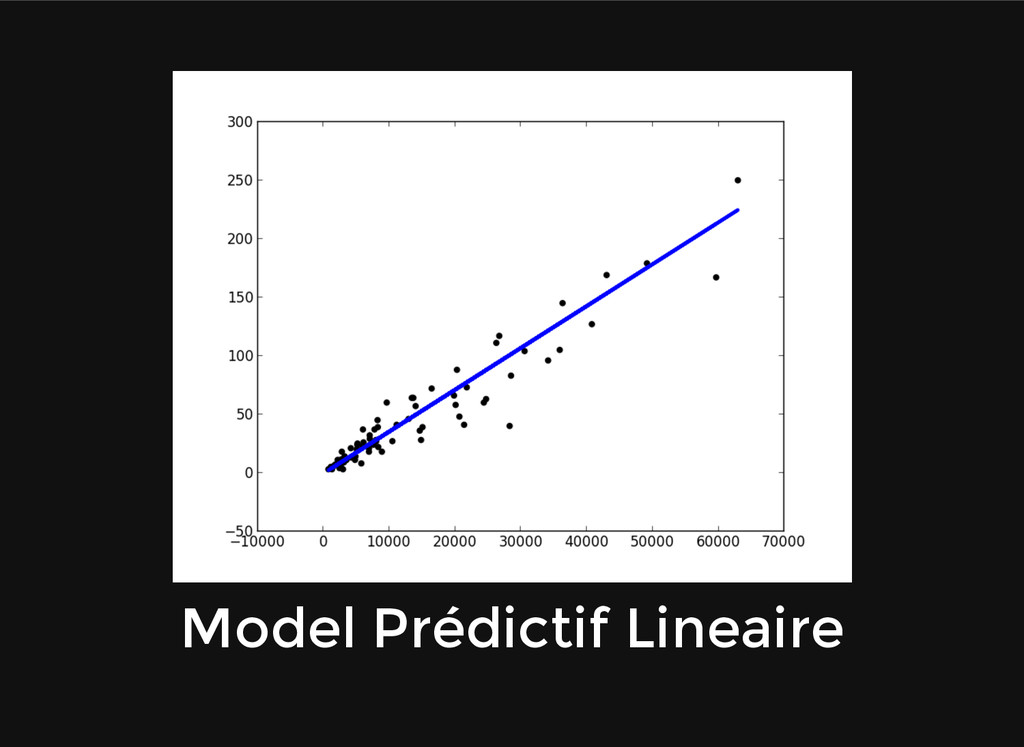{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}