Machine learning techniques are powerful, but building and deploying such models for production use require a lot of care and expertise.
A lot of books, articles, and best practices have been written and discussed on machine learning techniques and feature engineering, but putting those techniques into use on a production environment is usually forgotten and under- estimated , the aim of this talk is to shed some lights on current machine learning deployment practices, and go into details on how to deploy sustainable machine learning pipelines.
#sklearn #python #Flask
{kind=link}
{kind=link}
{kind=link}
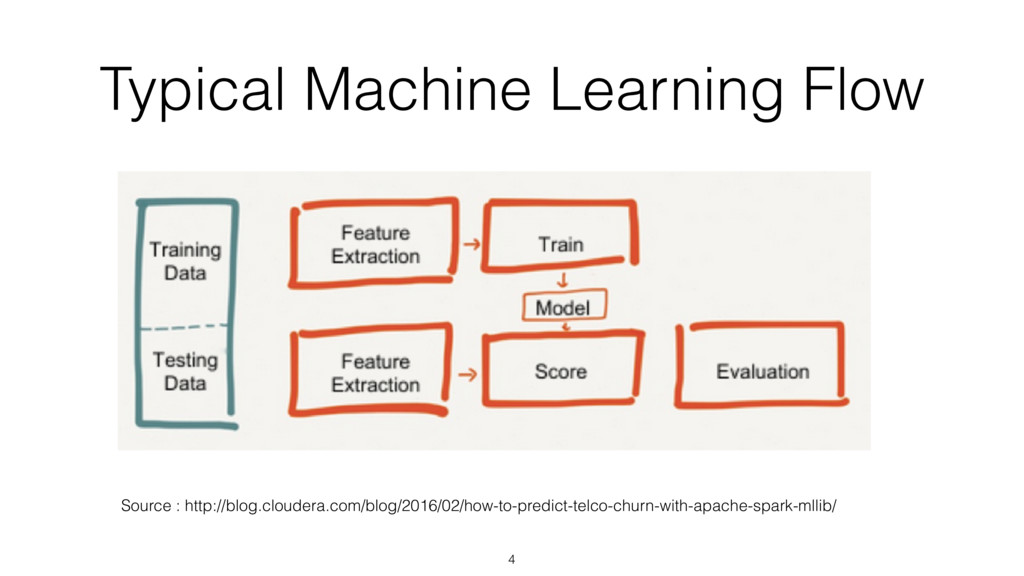{kind=link}
{kind=link}
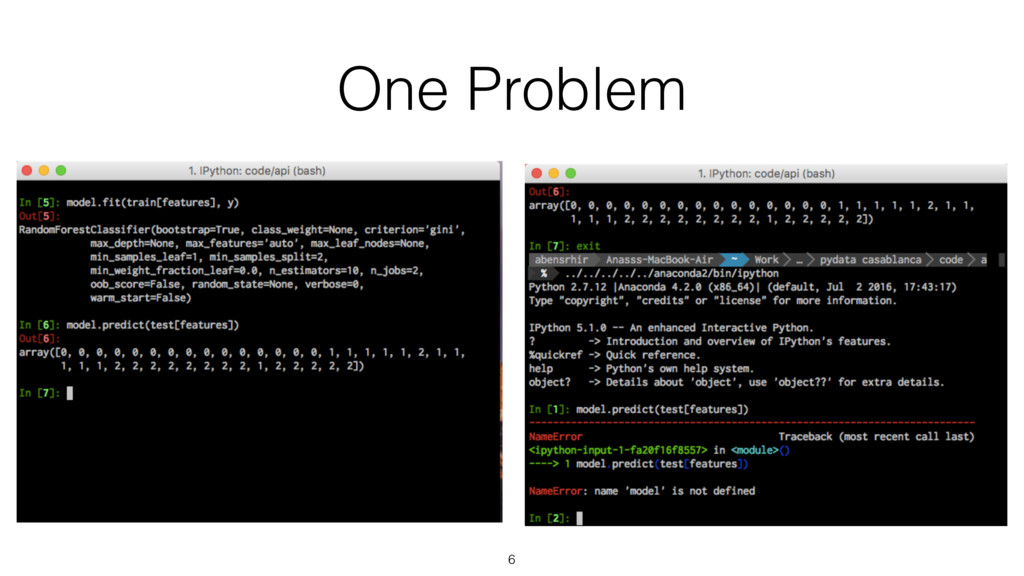{kind=link}
{kind=link}
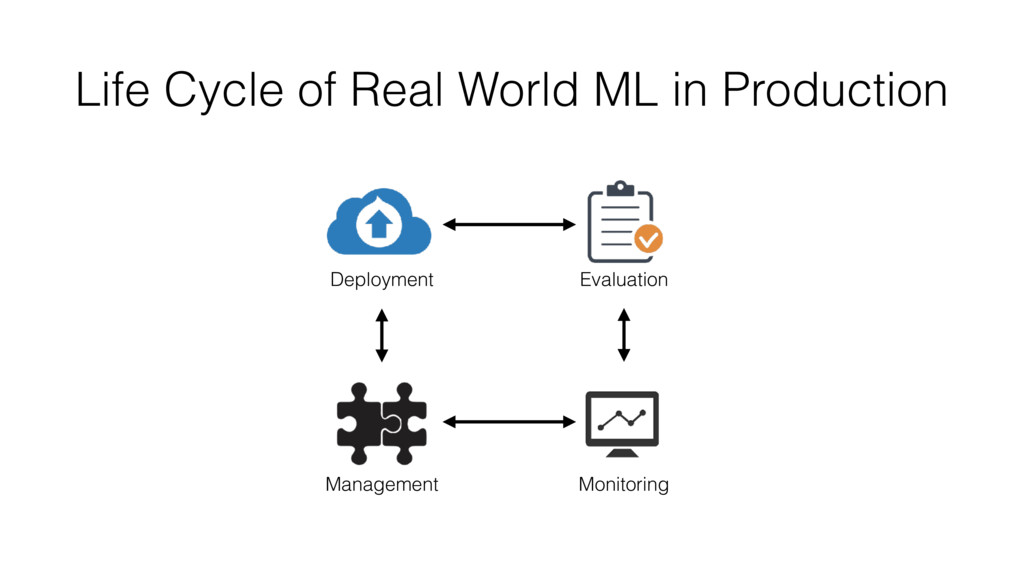{kind=link}
{kind=link}
{kind=link}
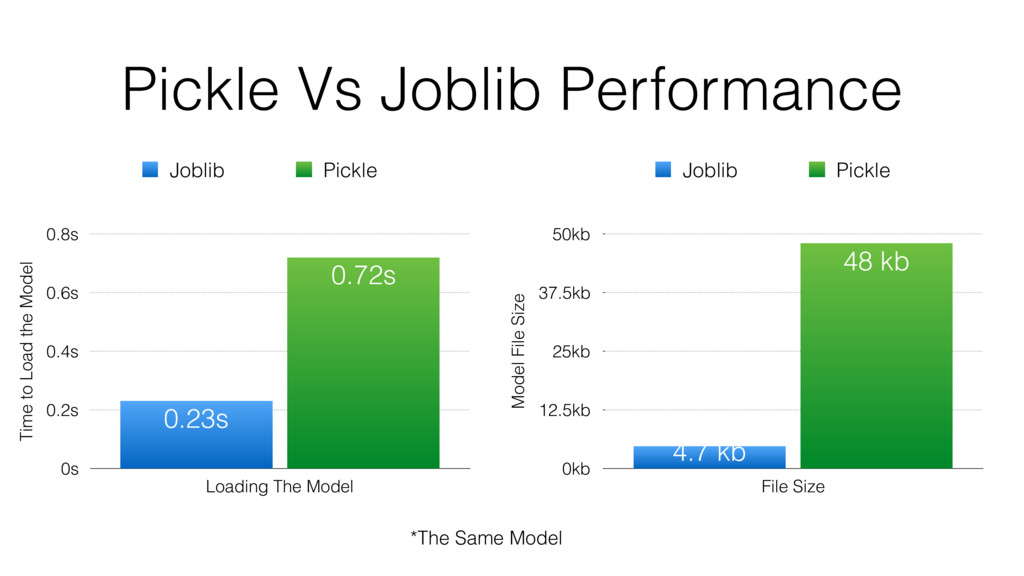{kind=link}
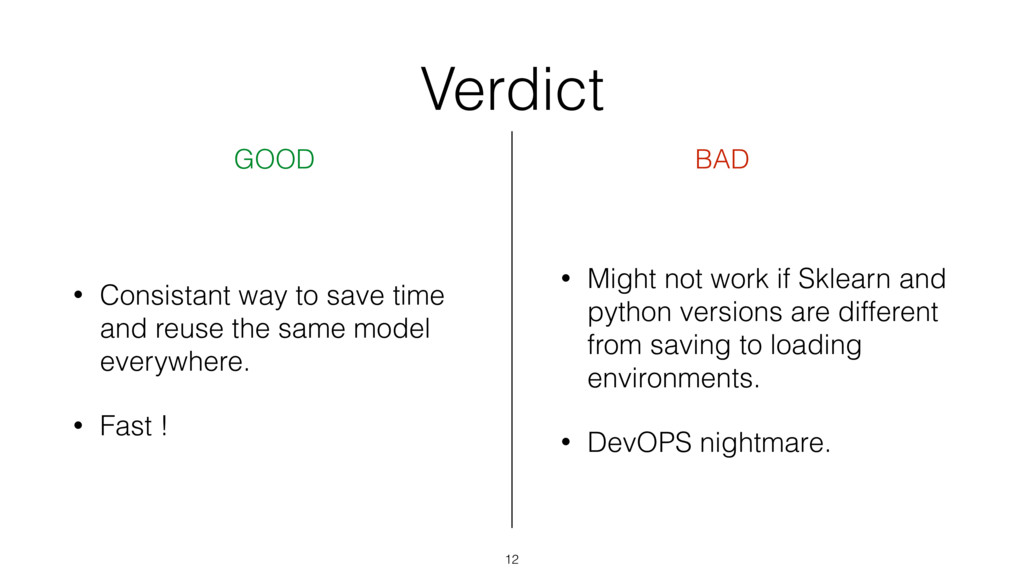{kind=link}
{kind=link}
{kind=link}
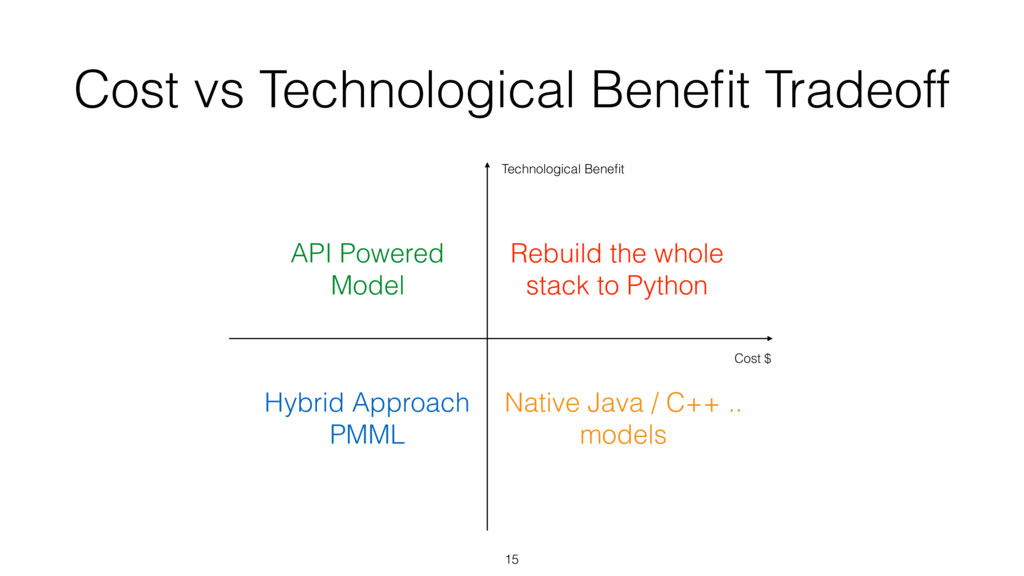{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
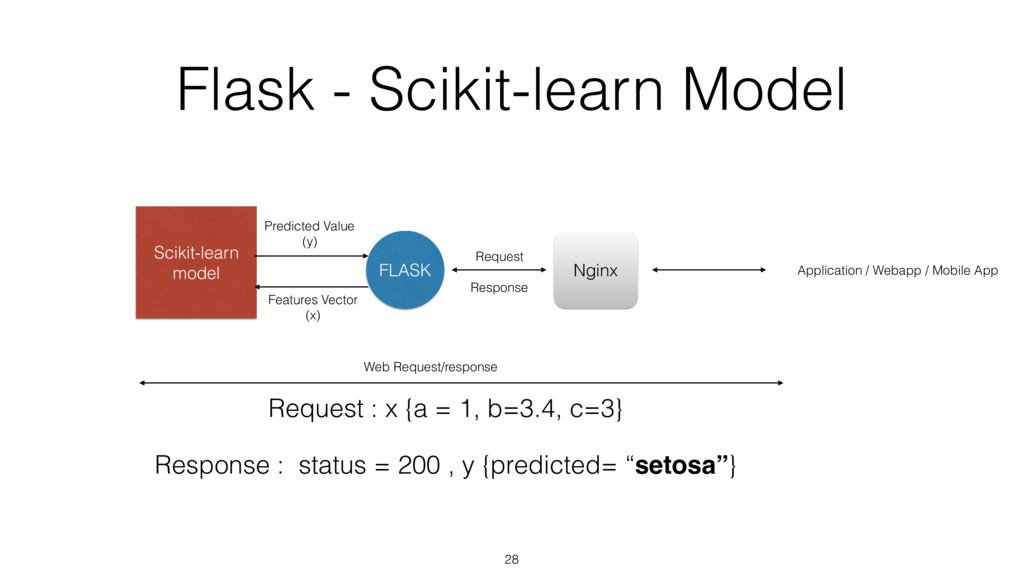{kind=link}
{kind=link}
{kind=link}
{kind=link}
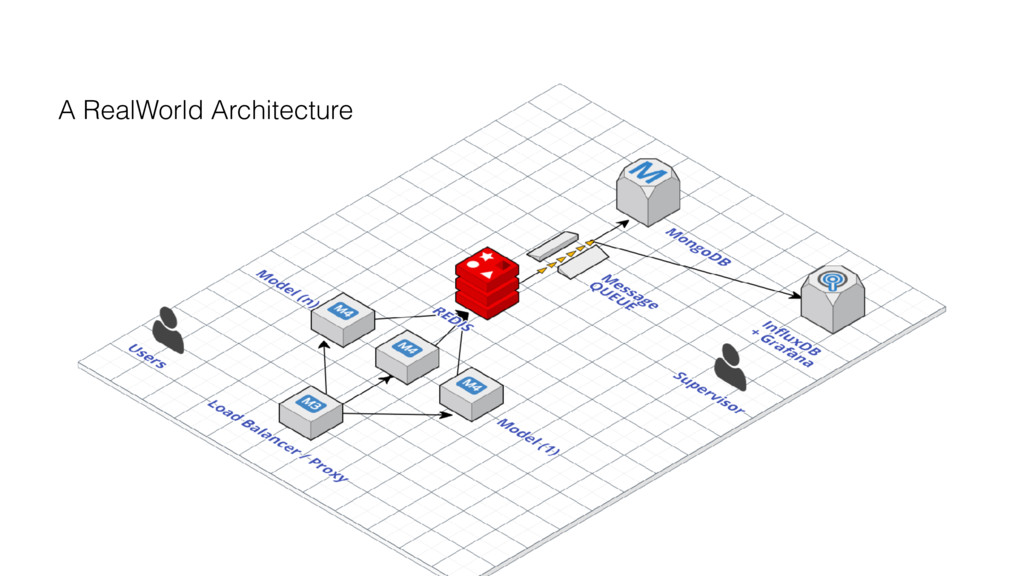{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}