As presented at the WebSummit in Lisbon 2018
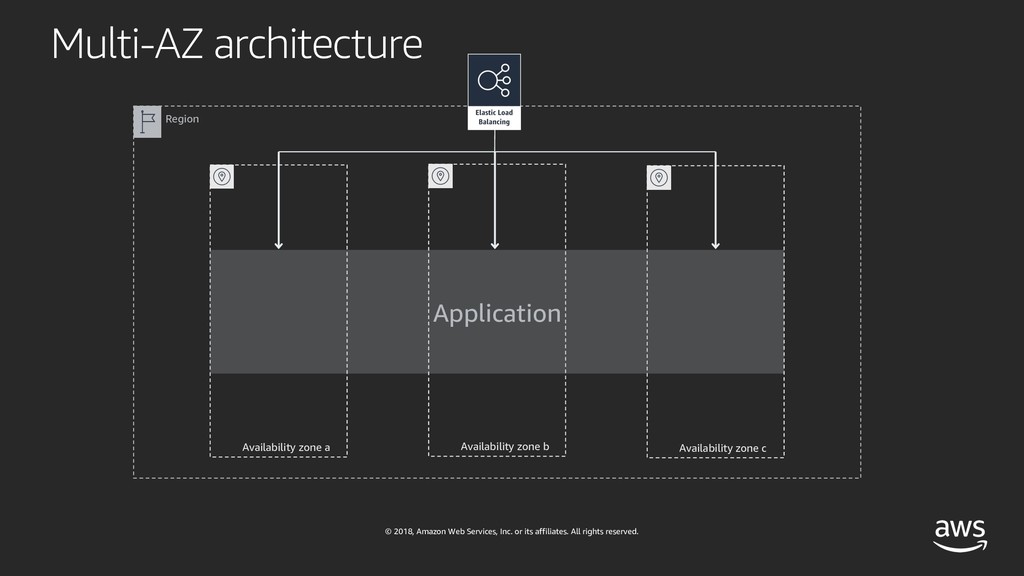
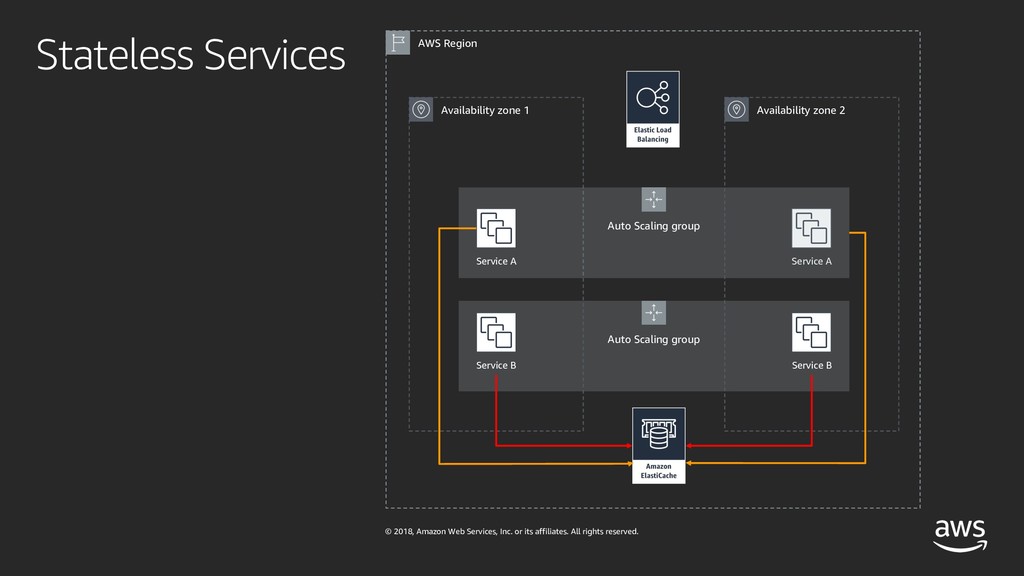
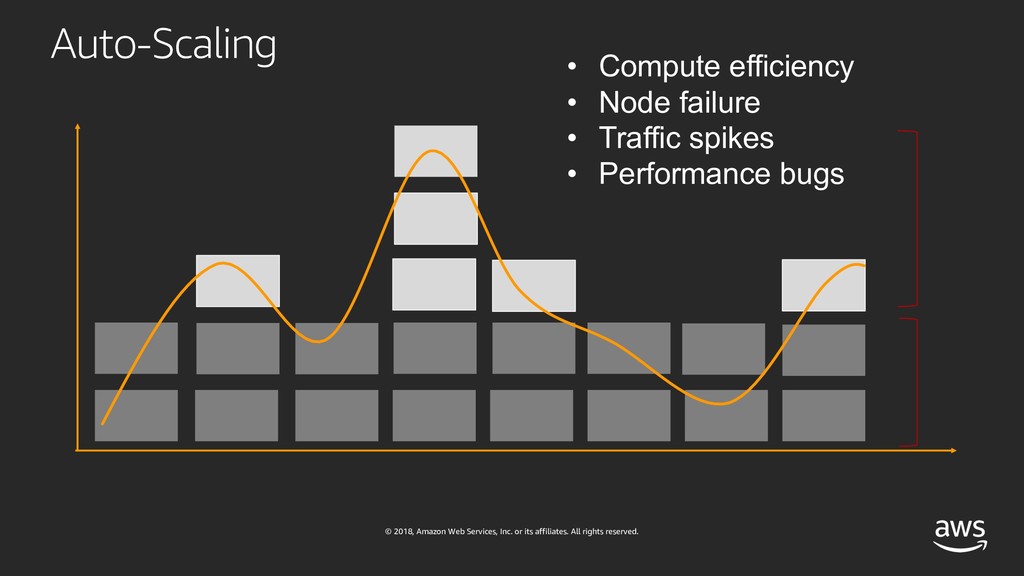
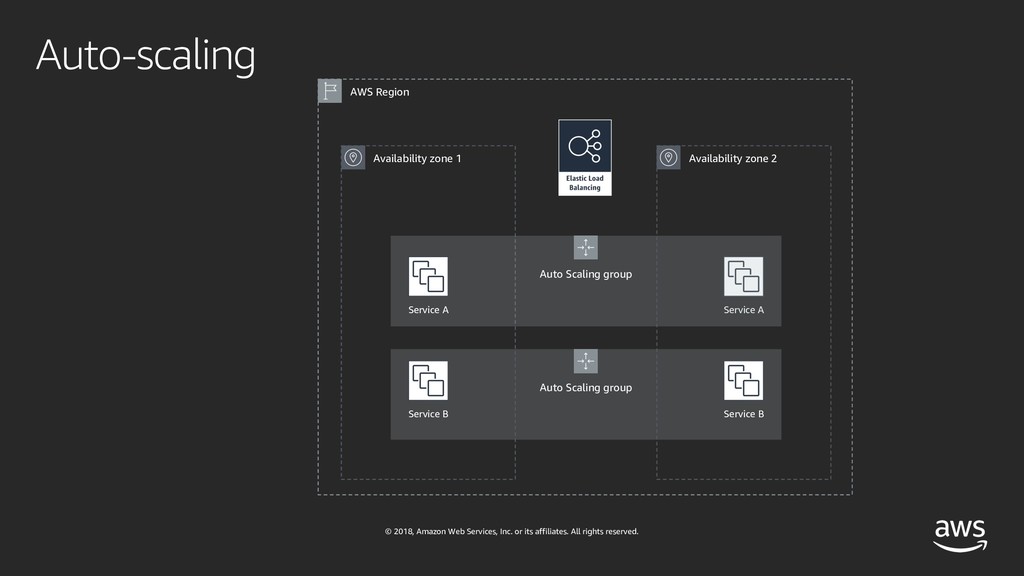
Ever wondered how companies delivering global services like Amazon or Netflix are architecting and testing their software systems? If you're curious and want to learn how they do it - this session is for you! With the rise of micro-services and large-scale distributed architectures, software systems have grown increasingly complex and hard to understand. Adding to that complexity, the velocity of software delivery has also dramatically increased, resulting in failures being harder to predict and contain. While the cloud allows for high availability, redundancy and fault-tolerance, no single component can guarantee 100% uptime. Therefore, we have to understand availability but especially learn how to design architectures with failure in mind. And since failures have become more and more chaotic in nature, we must turn to chaos engineering in order to identify failures before they become outages. In this talk, I'll deep dive into availability, reliability and large-scale architectures and make an introduction to chaos engineering, a discipline that promotes breaking things on purpose in order to learn how to build more resilient systems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
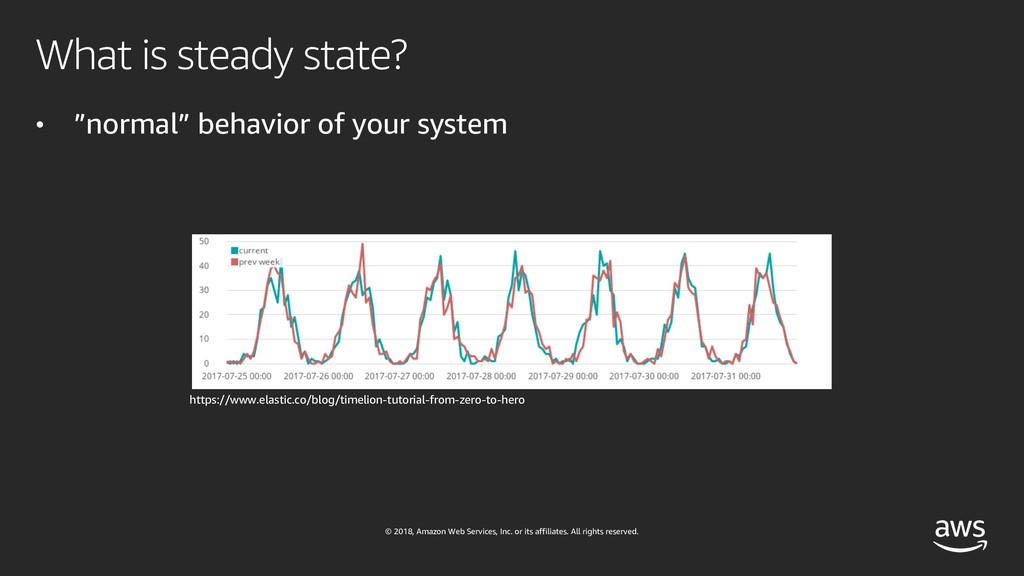{kind=link}
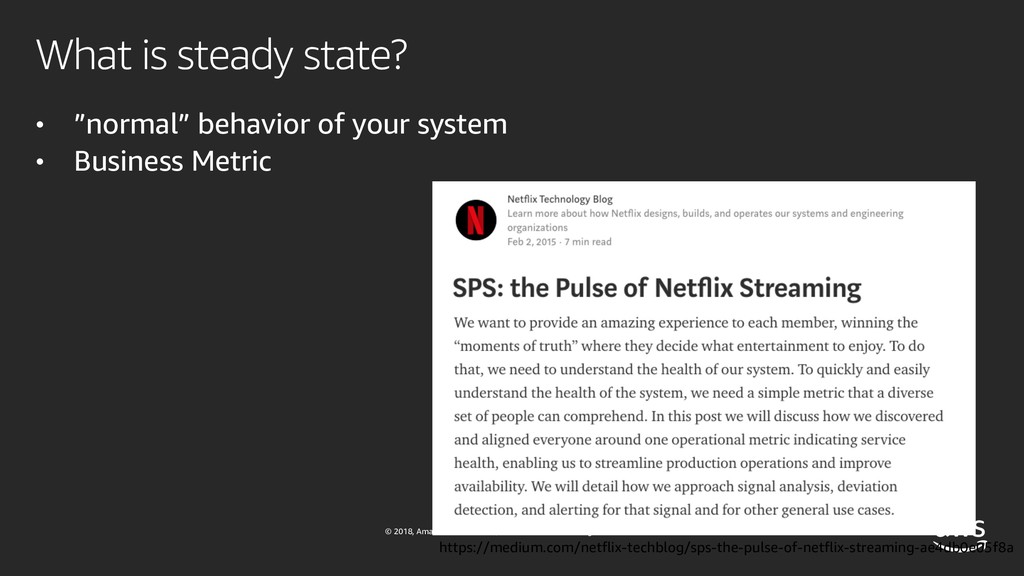{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}