Once beyond the very early stages of a Hadoop deployment, the flow of data through the system is complex. Data is coming into the cluster from multiple different sources and being processed through many analytics and data science pipelines. In the beginning these can be managed via cron and shell scripts, but this is not sufficiently robust and does not scale to larger teams. To handle complex data pipelines at scale, a workflow engine is necessary. A workflow engine allows the user to define and configure their data pipelines and then handles scheduling these pipelines. They also have mechanisms for monitoring the progress of the pipelines and for recovering from failure. Once the point where a workflow engine is needed is reached, how does one choose one from the many available?
This talk will cover the major workflow engines for Hadoop: Oozie, Airflow, Luigi, and Azkaban. It will cover the key features of each workflow engine and the major differences between them. Use cases where each engine does particularly well will be highlighted. Attendees will leave this talk with a better understanding of the landscape of workflow engines in the Hadoop ecosystem and guidance on how to select a workflow engine for their needs.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
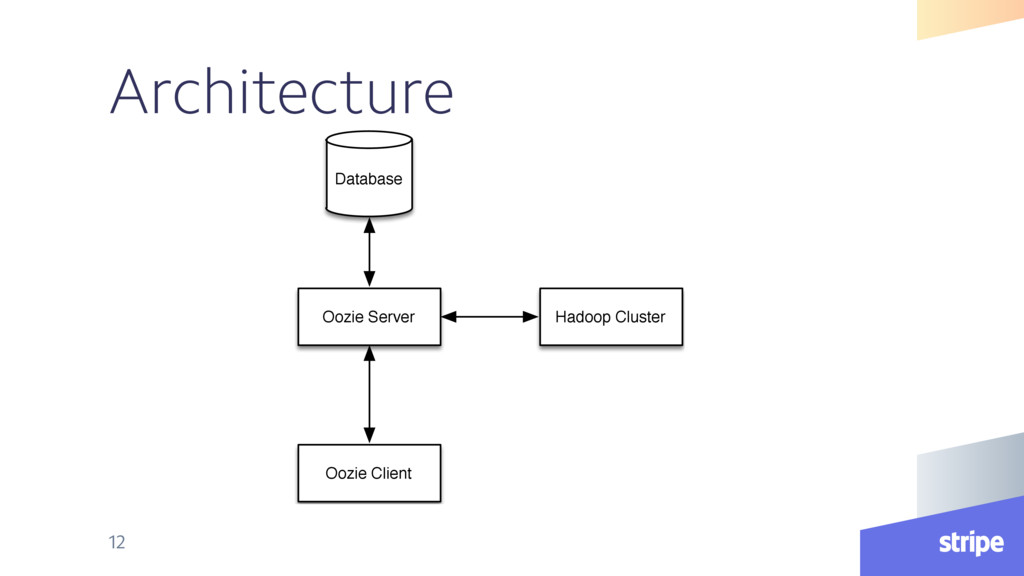{kind=link}
{kind=link}
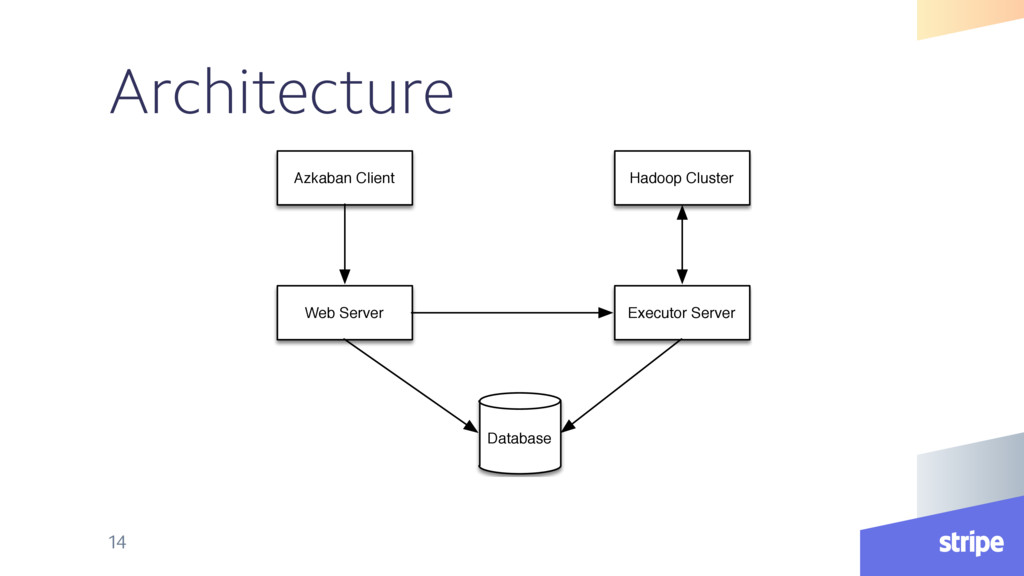{kind=link}
{kind=link}
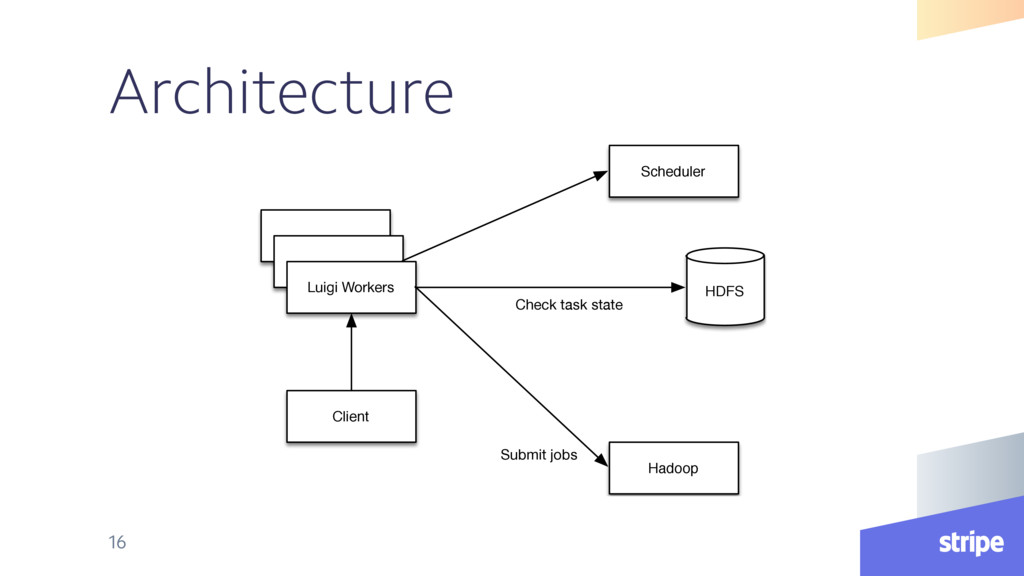{kind=link}
{kind=link}
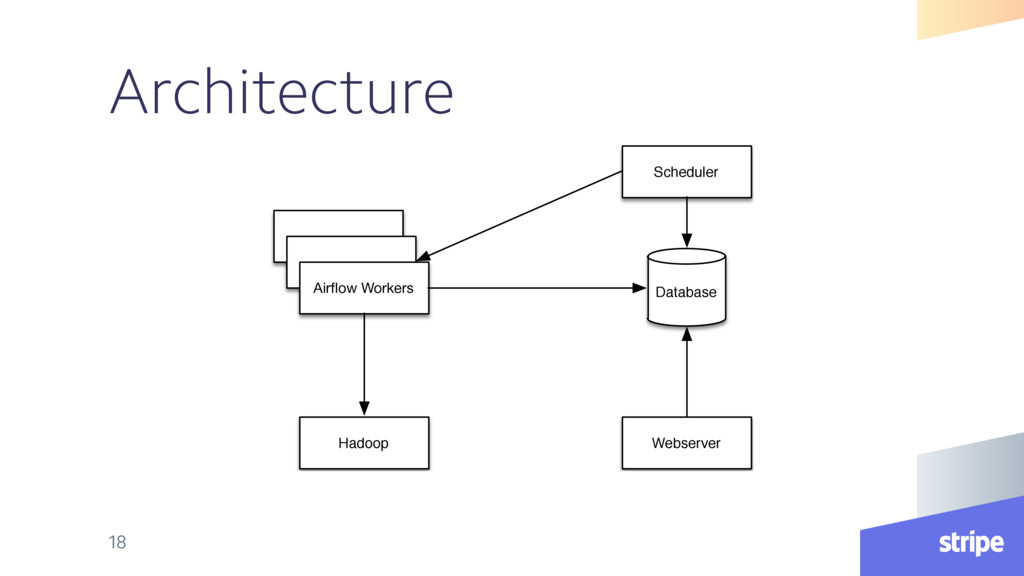{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}