OVERVIEW You’ve got your cluster set up and configured well. You’ve written your MapReduce jobs. But they are just not as fast as you’d like How do you take your MapReduce jobs to the next level?
OVERVIEW You’ve got your cluster set up and configured well. You’ve written your MapReduce jobs. But they are just not as fast as you’d like How do you take your MapReduce jobs to the next level?
OVERVIEW You’ve got your cluster set up and configured well. You’ve written your MapReduce jobs. But they are just not as fast as you’d like How do you take your MapReduce jobs to the next level?
OVERVIEW You’ve got your cluster set up and configured well. You’ve written your MapReduce jobs. But they are just not as fast as you’d like How do you take your MapReduce jobs to the next level?
KNOW THYSELF Understand your data! Understand the current performance characteristics of your jobs! Understand how much harder you can push your cluster!
KNOW THYSELF Understand your data! Understand the current performance characteristics of your jobs! Understand how much harder you can push your cluster!
KNOW THYSELF Understand your data! Understand the current performance characteristics of your jobs! Understand how much harder you can push your cluster!
UNDERSTANDING YOUR MAPREDUCE JOBS You need to have some kind of monitoring in place (e.g. Ganglia) Your first task is to find out what is limiting the performance of your job. Watch resource utilization during the time the job is running; is it CPU, IO, or memory bound?
UNDERSTANDING YOUR MAPREDUCE JOBS You need to have some kind of monitoring in place (e.g. Ganglia) Your first task is to find out what is limiting the performance of your job. Watch resource utilization during the time the job is running; is it CPU, IO, or memory bound?
UNDERSTANDING YOUR MAPREDUCE JOBS You need to have some kind of monitoring in place (e.g. Ganglia) Your first task is to find out what is limiting the performance of your job. Watch resource utilization during the time the job is running; is it CPU, IO, or memory bound?
DISCLAIMER The algorithmic techniques in this presentation reduce network utilization at the cost of increased CPU and memory utilization in the map tasks. While trying them out, continue to monitor resource utilization. Bad things can happen if you don’t! I cannot guarantee that what I’m about to show you will actually improve the performance of your jobs. Treat implementing these techniques as a science experiment. That said, I’ve had good results with these techniques.
DISCLAIMER The algorithmic techniques in this presentation reduce network utilization at the cost of increased CPU and memory utilization in the map tasks. While trying them out, continue to monitor resource utilization. Bad things can happen if you don’t! I cannot guarantee that what I’m about to show you will actually improve the performance of your jobs. Treat implementing these techniques as a science experiment. That said, I’ve had good results with these techniques.
DISCLAIMER The algorithmic techniques in this presentation reduce network utilization at the cost of increased CPU and memory utilization in the map tasks. While trying them out, continue to monitor resource utilization. Bad things can happen if you don’t! I cannot guarantee that what I’m about to show you will actually improve the performance of your jobs. Treat implementing these techniques as a science experiment. That said, I’ve had good results with these techniques.
DISCLAIMER The algorithmic techniques in this presentation reduce network utilization at the cost of increased CPU and memory utilization in the map tasks. While trying them out, continue to monitor resource utilization. Bad things can happen if you don’t! I cannot guarantee that what I’m about to show you will actually improve the performance of your jobs. Treat implementing these techniques as a science experiment. That said, I’ve had good results with these techniques.
DISCLAIMER The algorithmic techniques in this presentation reduce network utilization at the cost of increased CPU and memory utilization in the map tasks. While trying them out, continue to monitor resource utilization. Bad things can happen if you don’t! I cannot guarantee that what I’m about to show you will actually improve the performance of your jobs. Treat implementing these techniques as a science experiment. That said, I’ve had good results with these techniques.
WORD COUNT Class Mapper Method Map(docid a, doc d) foreach term t ∈ doc d do Emit (term t, count 1) end end end Class Reducer Method Reduce(term t, counts [c1, c2, . . .]) sum ← 0 foreach count c ∈ counts [c1, c2, . . .] do sum ← sum + c end Emit (term t, count sum) end end
COMBINERS After monitoring this job, we want to improve its performance Why not try a combiner? No guarantee how often a combiner is called, if at all Using combiner still requires materializing all key-value pairs
COMBINERS After monitoring this job, we want to improve its performance Why not try a combiner? No guarantee how often a combiner is called, if at all Using combiner still requires materializing all key-value pairs
COMBINERS After monitoring this job, we want to improve its performance Why not try a combiner? No guarantee how often a combiner is called, if at all Using combiner still requires materializing all key-value pairs
COMBINERS After monitoring this job, we want to improve its performance Why not try a combiner? No guarantee how often a combiner is called, if at all Using combiner still requires materializing all key-value pairs
IN-MAPPER COMBINING Move the combiner functionality into the mapper Provides total control over how and when combining takes place Materialize the minimum number of key-value pairs
IN-MAPPER COMBINING Move the combiner functionality into the mapper Provides total control over how and when combining takes place Materialize the minimum number of key-value pairs
IN-MAPPER COMBINING Move the combiner functionality into the mapper Provides total control over how and when combining takes place Materialize the minimum number of key-value pairs
WORD COUNT The reducer is the same as before Class Mapper Method Setup H ← new Map<term → count> end Method Map(docid a, doc d) foreach term t ∈ doc d do H{t} ← H{t} + 1 end end Method Cleanup foreach term t ∈ H do Emit (term t, count H{t}) end end end
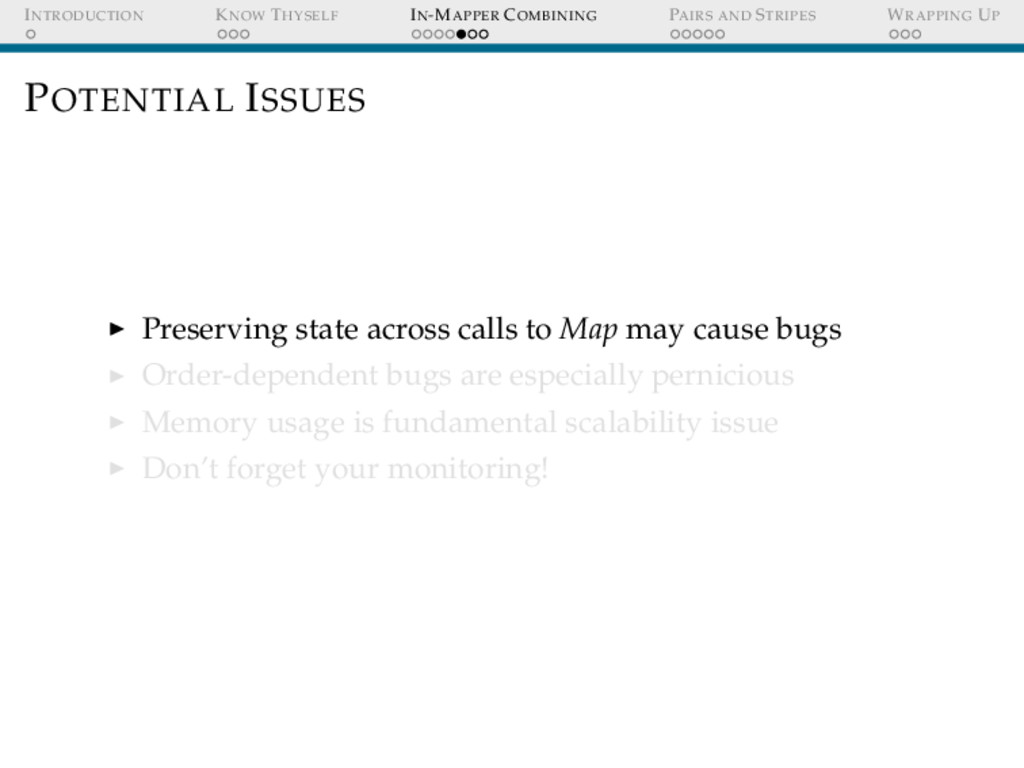
POTENTIAL ISSUES Preserving state across calls to Map may cause bugs Order-dependent bugs are especially pernicious Memory usage is fundamental scalability issue Don’t forget your monitoring!
POTENTIAL ISSUES Preserving state across calls to Map may cause bugs Order-dependent bugs are especially pernicious Memory usage is fundamental scalability issue Don’t forget your monitoring!
POTENTIAL ISSUES Preserving state across calls to Map may cause bugs Order-dependent bugs are especially pernicious Memory usage is fundamental scalability issue Don’t forget your monitoring!
POTENTIAL ISSUES Preserving state across calls to Map may cause bugs Order-dependent bugs are especially pernicious Memory usage is fundamental scalability issue Don’t forget your monitoring!
DEALING WITH MEMORY USAGE Know your data and your grid! Memory usage may not be a problem Periodically flush intermediate key-value pairs Empirically discover balance between memory usage and network utilization
DEALING WITH MEMORY USAGE Know your data and your grid! Memory usage may not be a problem Periodically flush intermediate key-value pairs Empirically discover balance between memory usage and network utilization
DEALING WITH MEMORY USAGE Know your data and your grid! Memory usage may not be a problem Periodically flush intermediate key-value pairs Empirically discover balance between memory usage and network utilization
DEALING WITH MEMORY USAGE Know your data and your grid! Memory usage may not be a problem Periodically flush intermediate key-value pairs Empirically discover balance between memory usage and network utilization
WORD COUNT Class Mapper Method Setup H ← new Map<term → count> BufferSize ← n end Method Flush foreach term t ∈ H do Emit (term t, count H{t}) end Clear (H) end Method Map(docid a, doc d) foreach term t ∈ doc d do H{t} ← H{t} + 1 end if Size (H) ≥ BufferSize then Flush end end Method Cleanup Flush end end
PAIRS APPROACH TO WORD CO-OCCURRENCE Class Mapper Method Map(docid a, doc d) foreach term w ∈ doc d do foreach term u ∈ Neighbors (w) do Emit (pair (w,u), count 1) end end end end Class Reducer Method Reduce(pair p, counts [c1 , c2 , . . .]) sum ← 0 foreach count c ∈ counts [c1 , c2 , . . .] do sum ← sum + c end Emit (pair p, count sum) end end
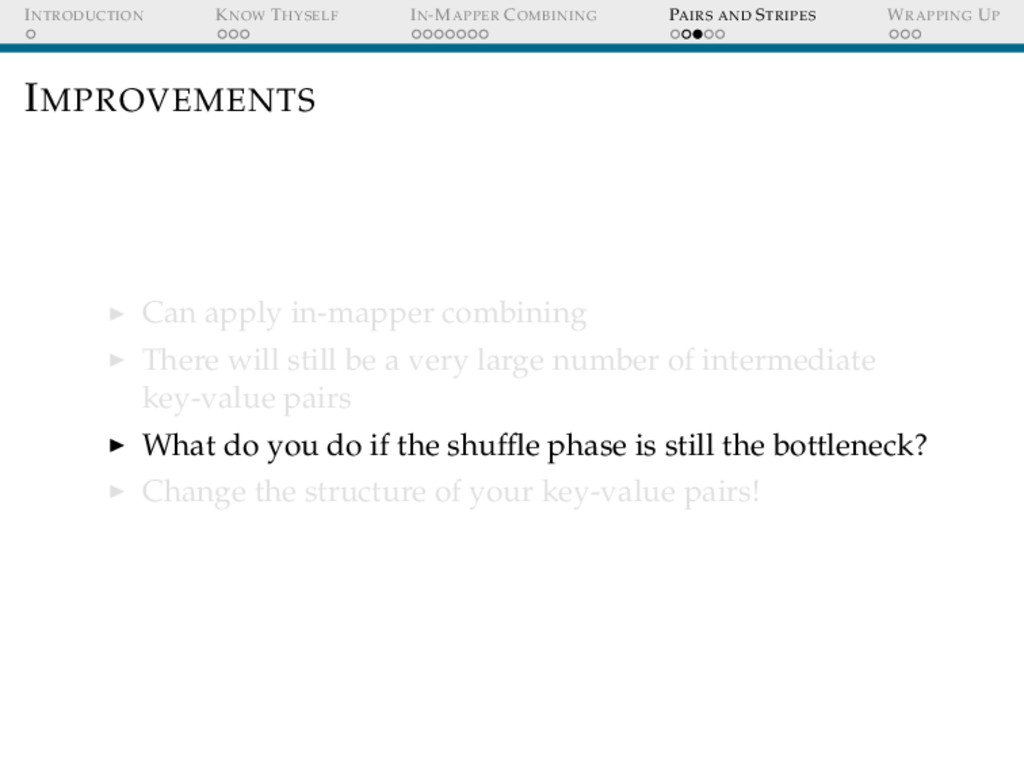
IMPROVEMENTS Can apply in-mapper combining There will still be a very large number of intermediate key-value pairs What do you do if the shuffle phase is still the bottleneck? Change the structure of your key-value pairs!
IMPROVEMENTS Can apply in-mapper combining There will still be a very large number of intermediate key-value pairs What do you do if the shuffle phase is still the bottleneck? Change the structure of your key-value pairs!
IMPROVEMENTS Can apply in-mapper combining There will still be a very large number of intermediate key-value pairs What do you do if the shuffle phase is still the bottleneck? Change the structure of your key-value pairs!
IMPROVEMENTS Can apply in-mapper combining There will still be a very large number of intermediate key-value pairs What do you do if the shuffle phase is still the bottleneck? Change the structure of your key-value pairs!
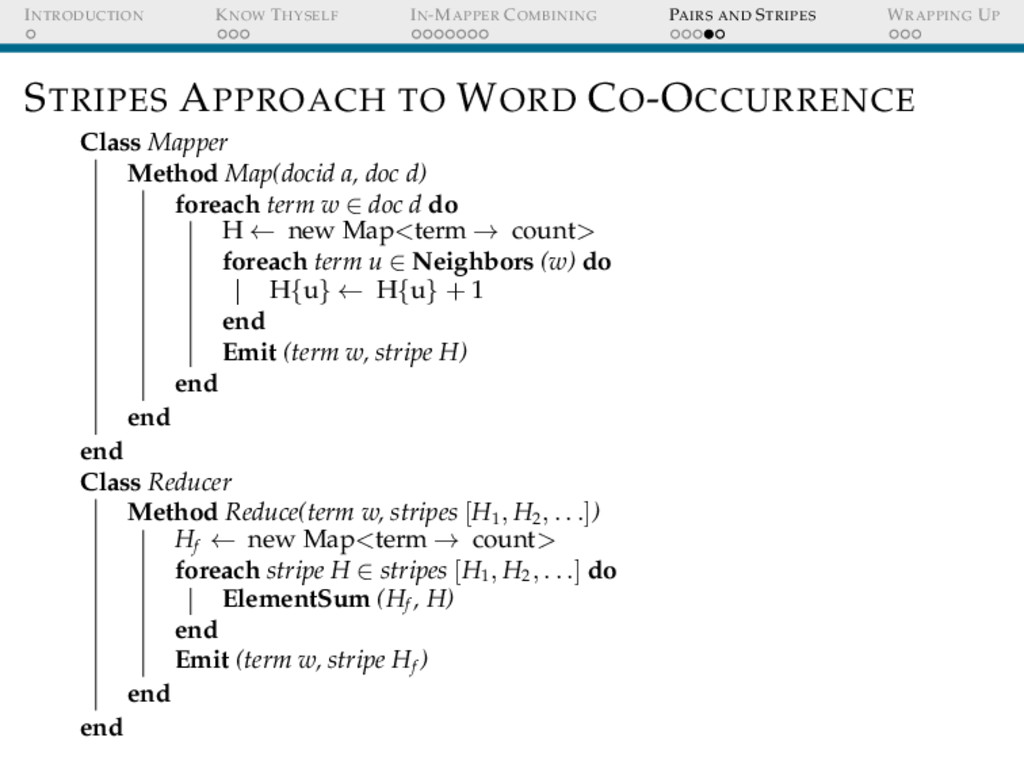
STRIPES APPROACH TO WORD CO-OCCURRENCE Class Mapper Method Map(docid a, doc d) foreach term w ∈ doc d do H ← new Map<term → count> foreach term u ∈ Neighbors (w) do H{u} ← H{u} + 1 end Emit (term w, stripe H) end end end Class Reducer Method Reduce(term w, stripes [H1 , H2 , . . .]) Hf ← new Map<term → count> foreach stripe H ∈ stripes [H1 , H2 , . . .] do ElementSum (Hf , H) end Emit (term w, stripe Hf ) end end
POTENTIAL ISSUES Memory and CPU utilization will increase Emit less intermediate data at the cost of more expensive serialization Don’t forget your monitoring! In-mapper combining and the flush technique may be used with the stripes approach
POTENTIAL ISSUES Memory and CPU utilization will increase Emit less intermediate data at the cost of more expensive serialization Don’t forget your monitoring! In-mapper combining and the flush technique may be used with the stripes approach
POTENTIAL ISSUES Memory and CPU utilization will increase Emit less intermediate data at the cost of more expensive serialization Don’t forget your monitoring! In-mapper combining and the flush technique may be used with the stripes approach
POTENTIAL ISSUES Memory and CPU utilization will increase Emit less intermediate data at the cost of more expensive serialization Don’t forget your monitoring! In-mapper combining and the flush technique may be used with the stripes approach
CONTACT INFORMATION E-mail: [email protected] Slides are available at my website http://andrewjamesjohnson.com/talks/ and on GitHub (https://github.com/ajsquared/hadoop-slides)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}