Stripe • Previously at Etsy and Explorys • Airflow runs all of our automated data processes • ~6k jobs • Mixture of MapReduce, Scalding, Redshift, and miscellaneous processes 2
jobs and data pipelines • Ensures jobs are ordered correctly based on dependencies • Manage allocation of scarce resources • Provides mechanism for tracking the state of jobs and recovering from failure 3
Task instance - Individual run of some task • DAG - Group of tasks connected into a graph by dependency edges, runs on some frequency • DAG run - Individual run of some DAG 4
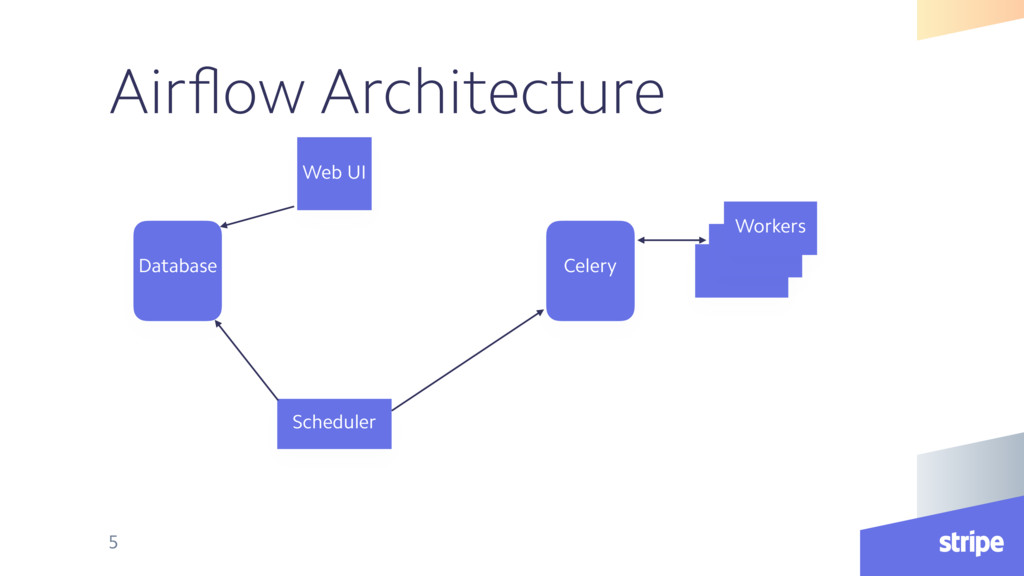
• Loads task and DAG definitions and loops to process tasks • Starts DAG runs at appropriate times • Task state is retrieved and updated from the database • Tasks are scheduled with Celery to run 6
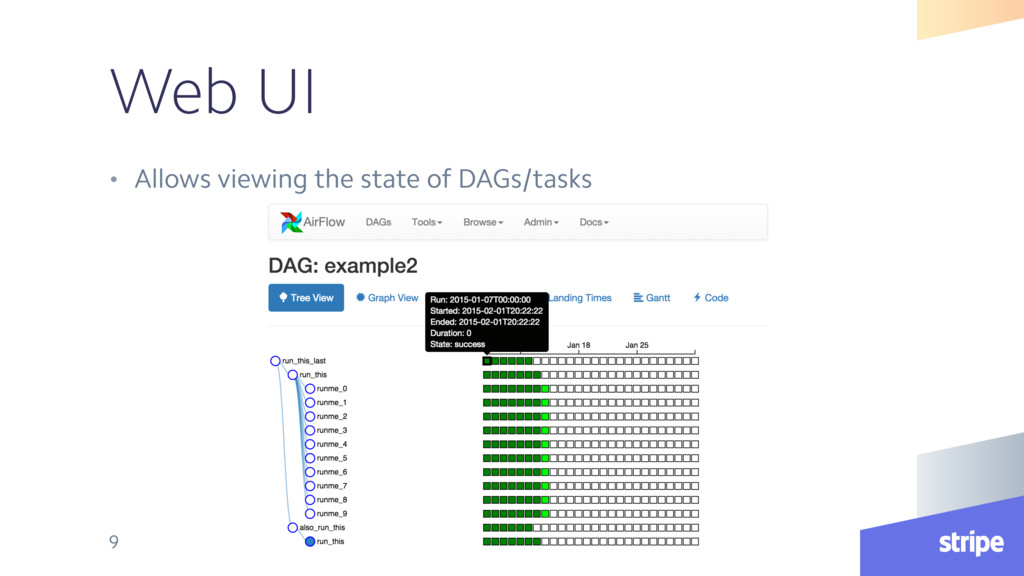
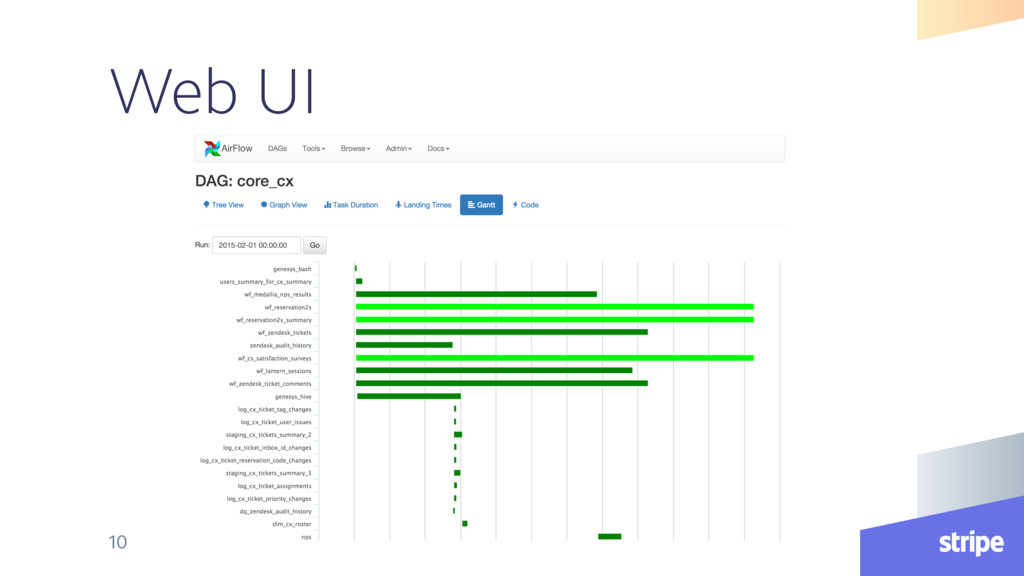
extensible • Simple primitives support building complex data pipelines • UI has many useful visualizations • Inspecting DAG structure is straightforward 14
been not great • Many users maintain forks • Visibility when things go wrong could be better • Large DAGs tend to break the UI • High-frequency (< hourly intervals) can be flaky 15
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}