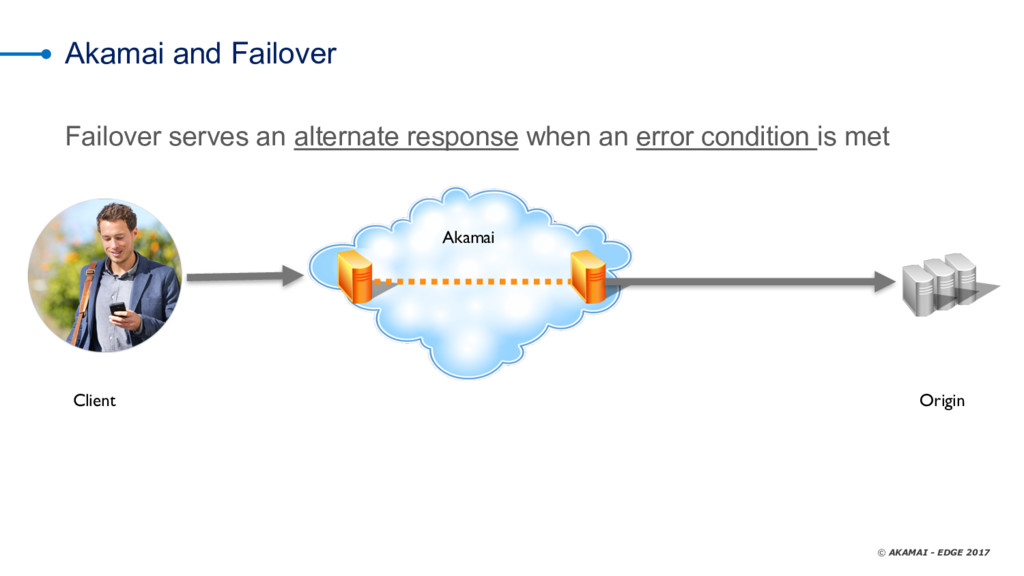
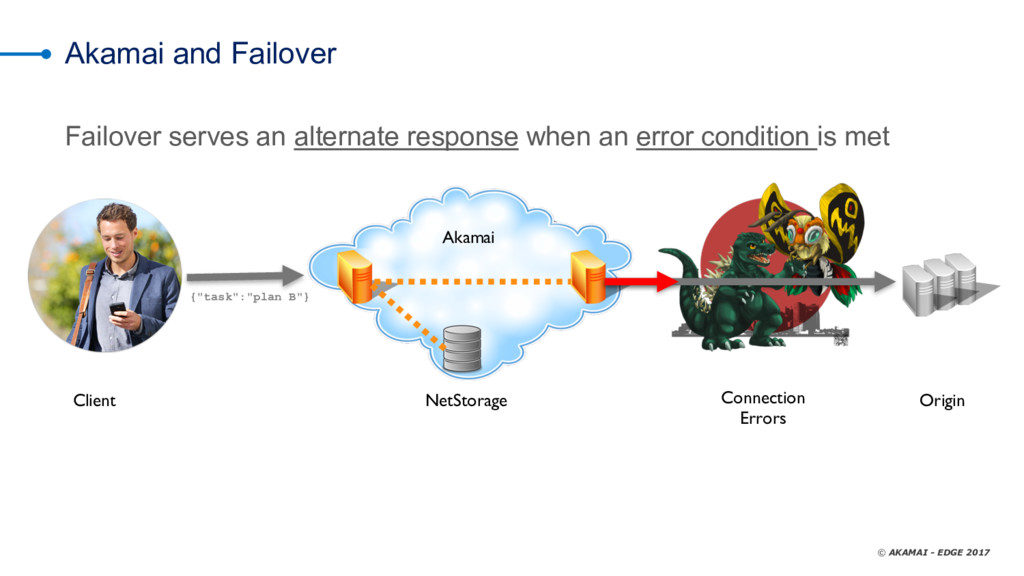
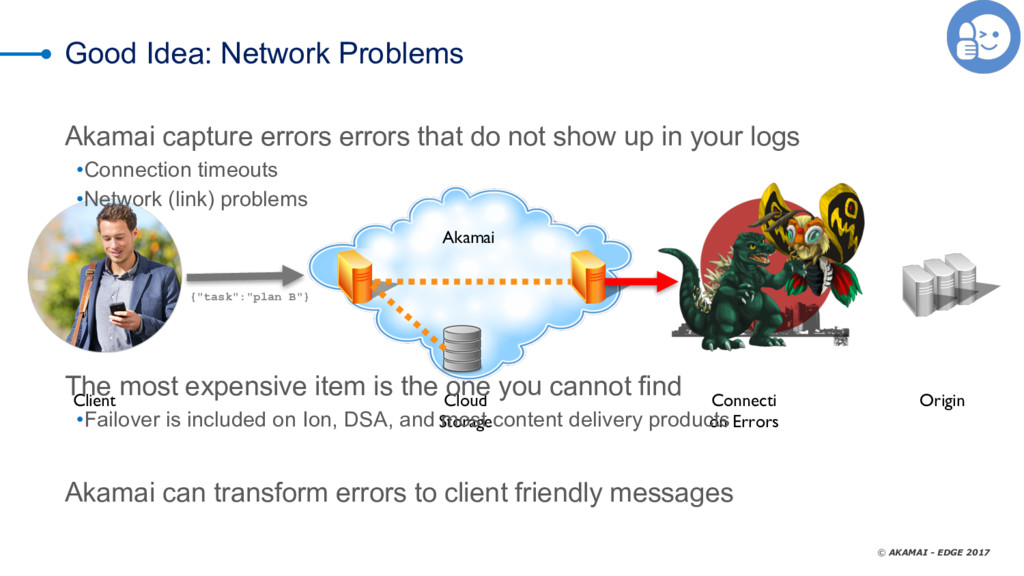
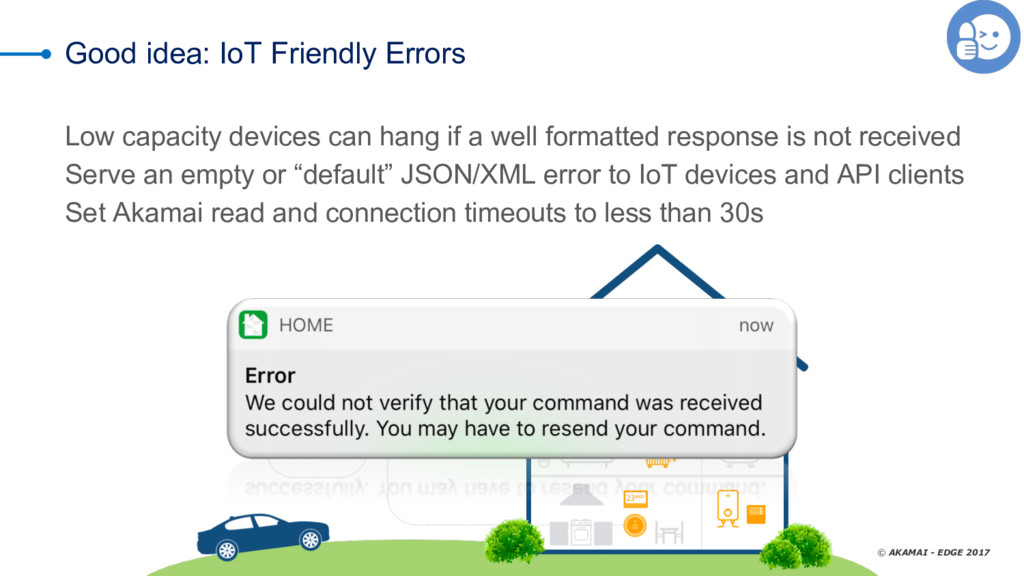
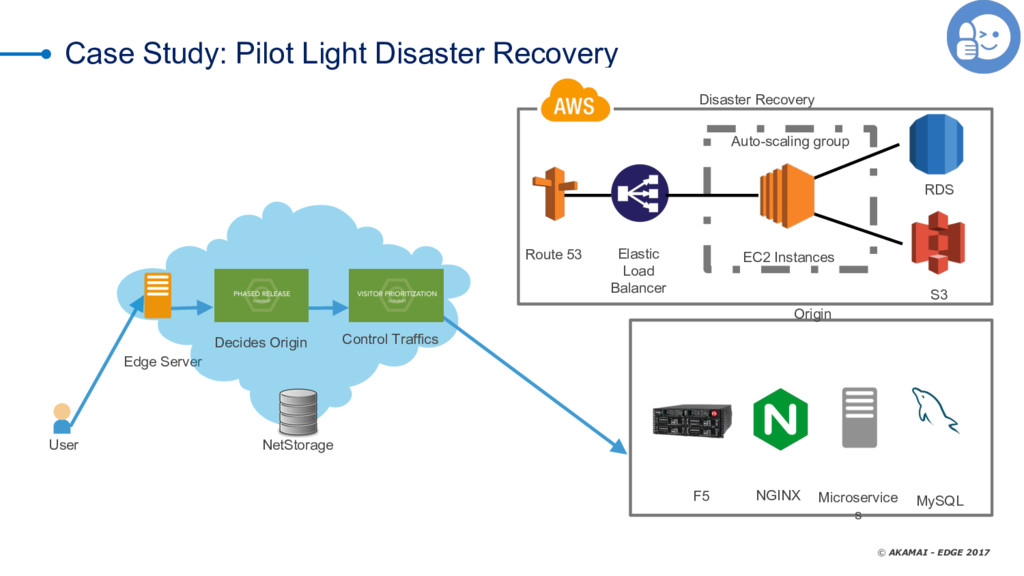
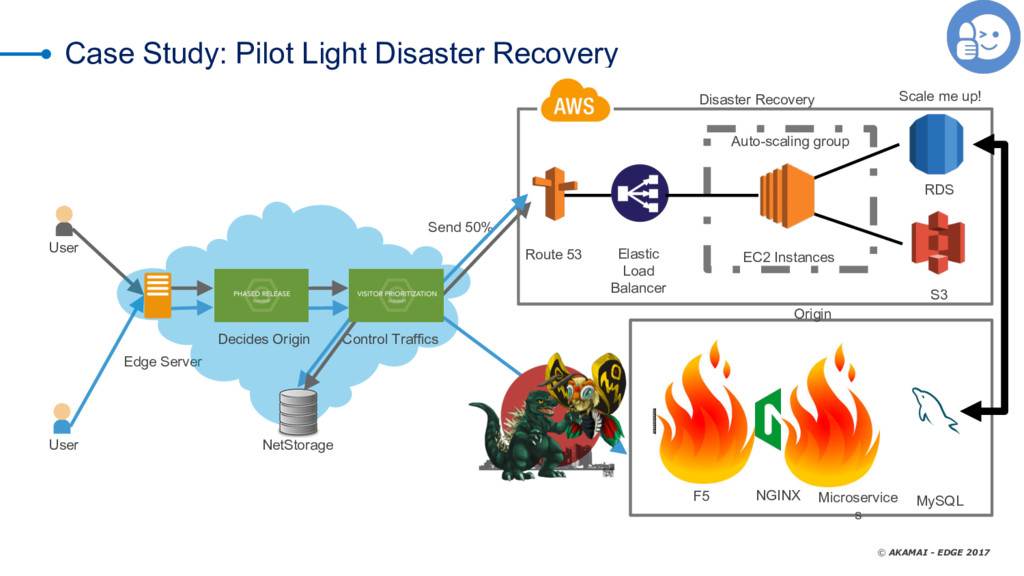
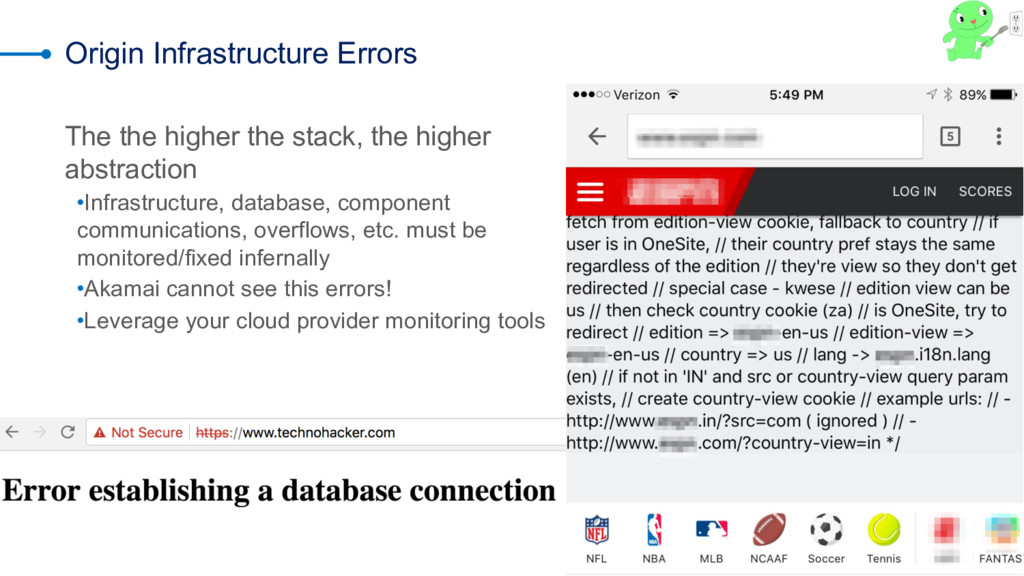
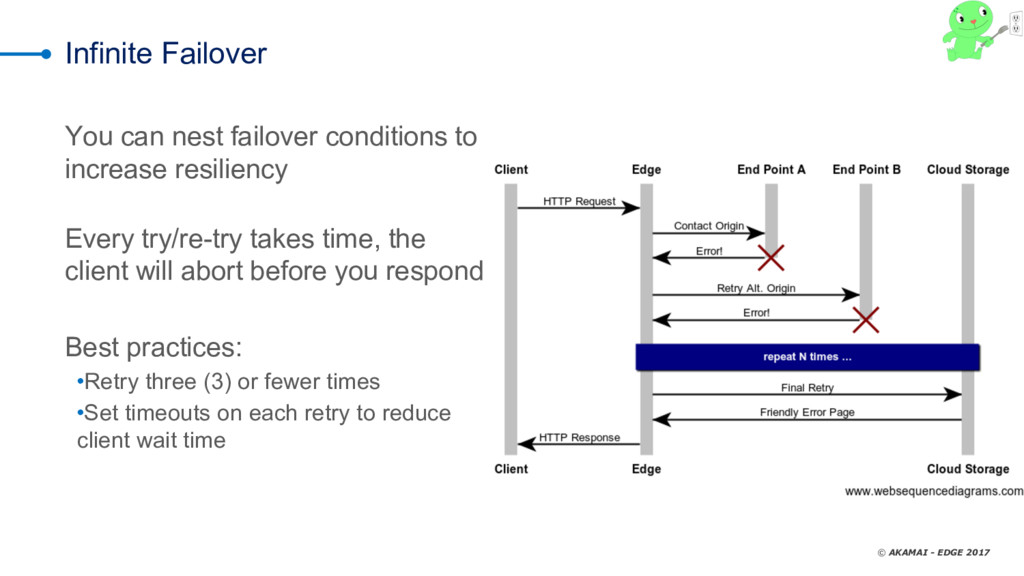
As we all know, you can put off filing your taxes all you like -- but they're going to happen no matter what. It's the same thing with data-center errors. too -- nobody watns to talk about them, but the reality is that we all deal with timeouts, slow databases, dropped responses, and the like. Not talking about it doesn't solve the problem; you need a solid risk-mitigation strategy that layers the most cost-efficient tactics to reduce or eliminate adverse effects when things don't go as expected. CDNs are an extension of your infrastructure. They give you control over the transport network (the Internet) and provide you cloud features that can be executed close to your clients to offload your infrastructure (whether cloud or on-premises). One of the features common to many CDNs is failover. Failover at this layer means serving an alternate response when a condition is met. Manuel Alvarez explores using the CDN as a failover tool, reviewing use cases and best practices and demonstrating how to decide whether to use a CDN by evaluating costs, benefits, operations, and time to mitigate.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}