富士通 人工知能研究所の中川です。
我々は、画像符号化などで活用されている情報通信理論を起点として、VAEなどの生成的AIモデルの定量的な特徴の理論解析に世界で初めて成功しました。
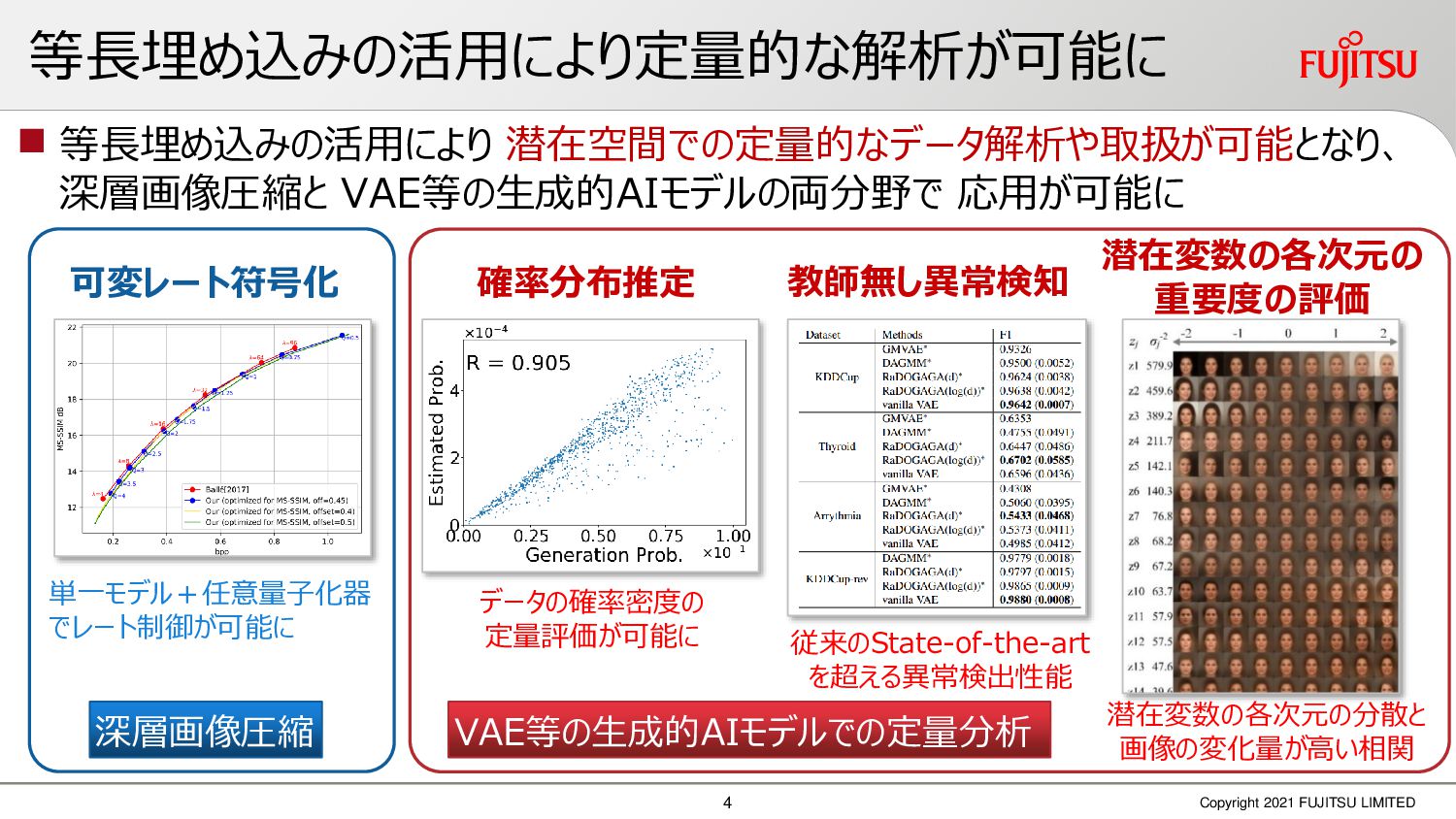
この理論を活用することで、従来の深層学習では困難だったデータの定量的な処理・分析が可能となります。
これらの研究成果は、AI分野のトップカンファレンスの一つ ICML 2020/2021で採択されています。
今回、これらの研究成果を、映像符号化&処理分野で長い歴史のあるシンポジウム PCSJ / IMPS 2021で講演させていただく機会を頂きました。本講演では、今回の研究成果の背景となる情報通信理論、特にレート歪理論と生成的AIを基礎から解説し、そして我々が導いた理論とその有用性を説明します。
概要は下記の通りです。
====================
本発表では、動画像符号化の基礎となる情報通信理論とVAE等の生成的AIモデルの密接な関連性を説明し、今後の研究の方向性について議論する。
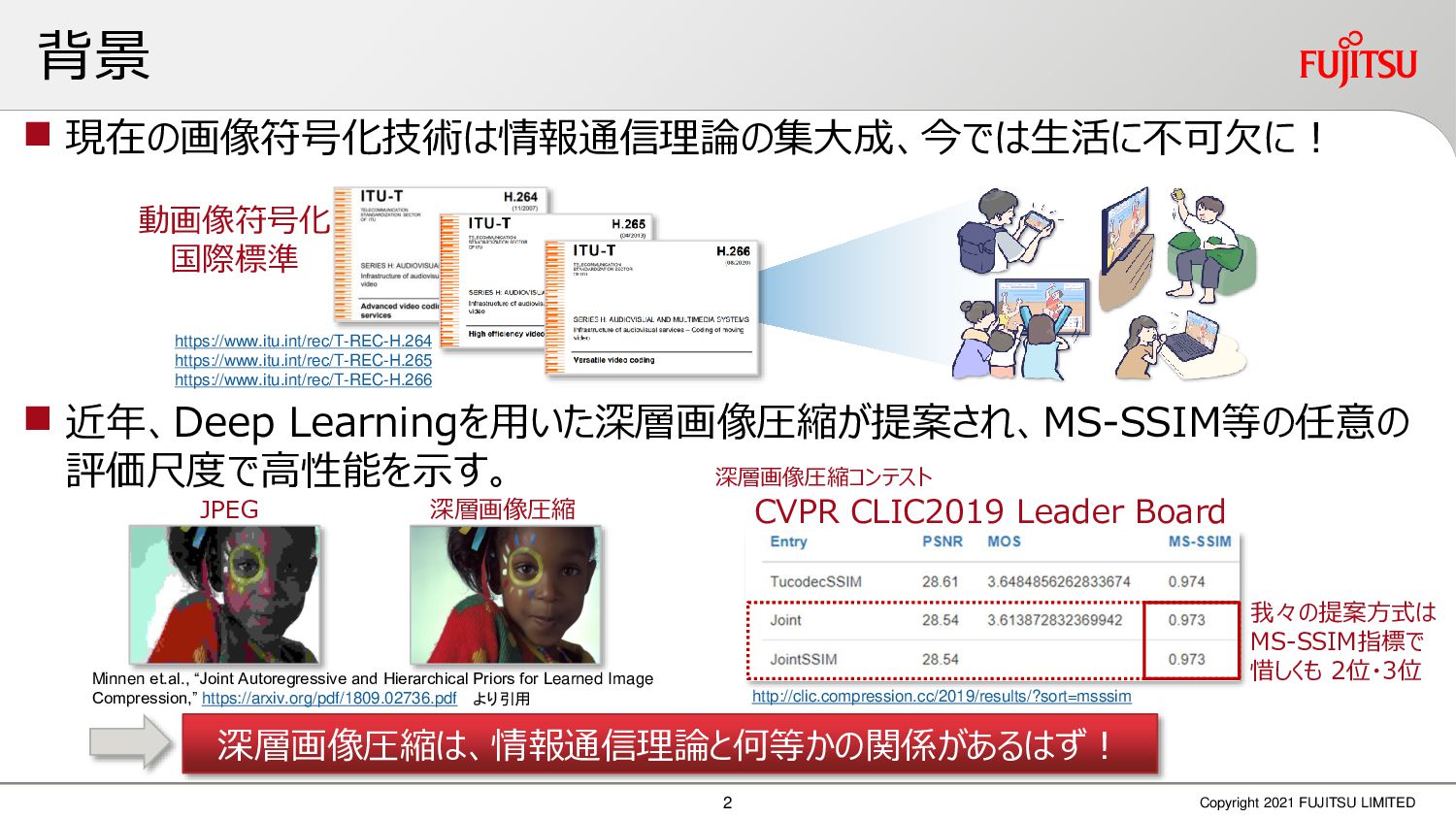
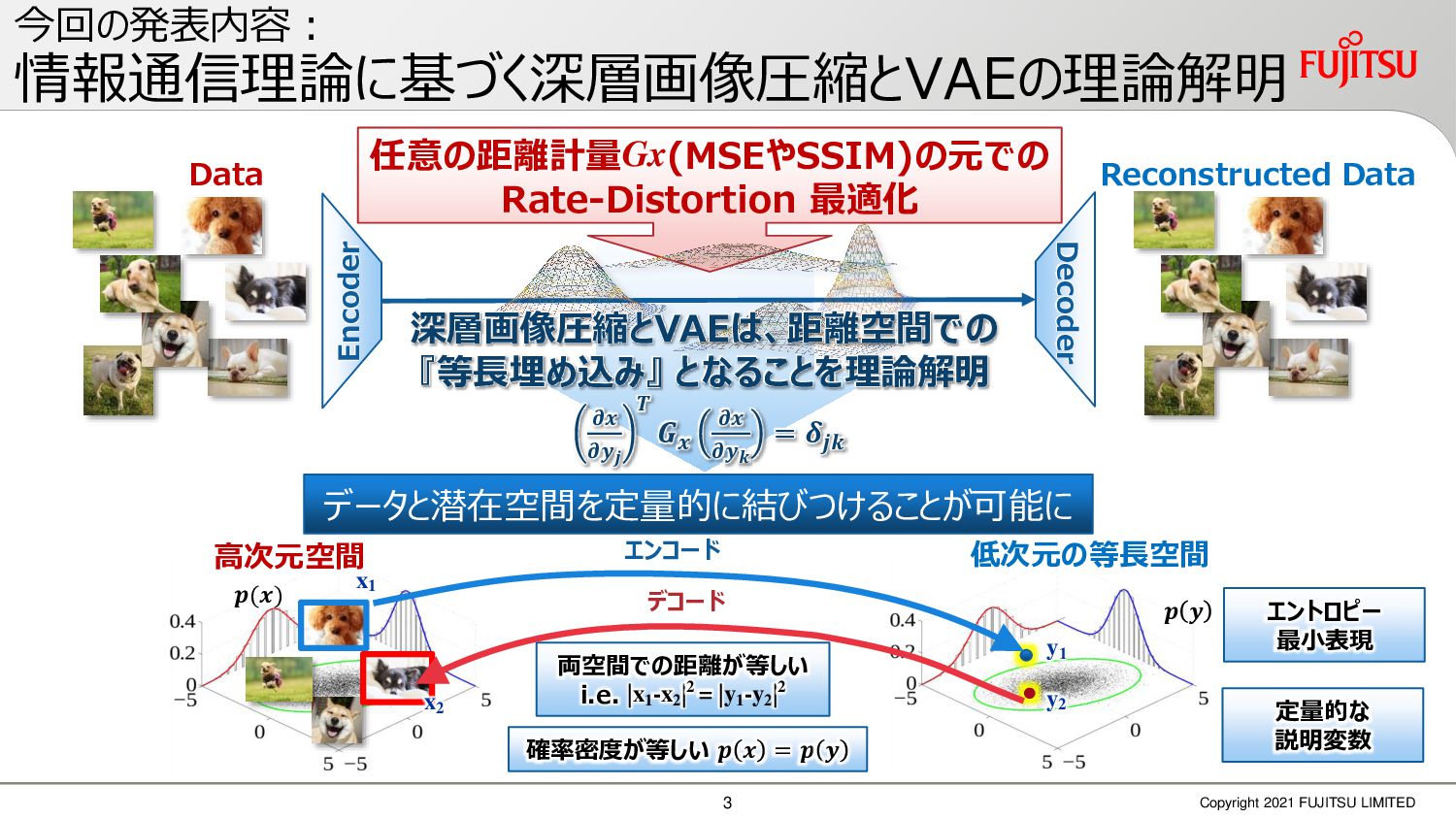
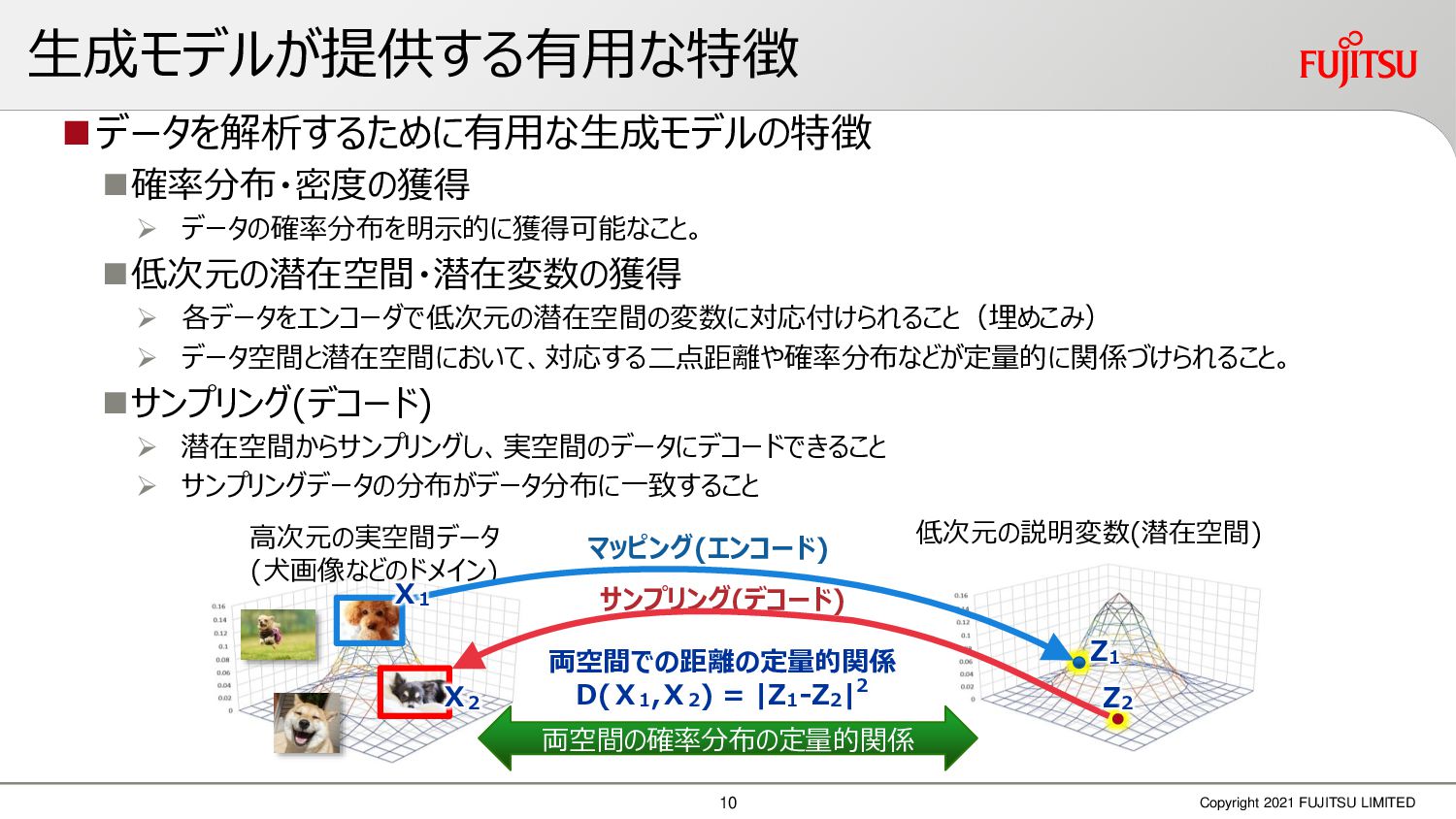
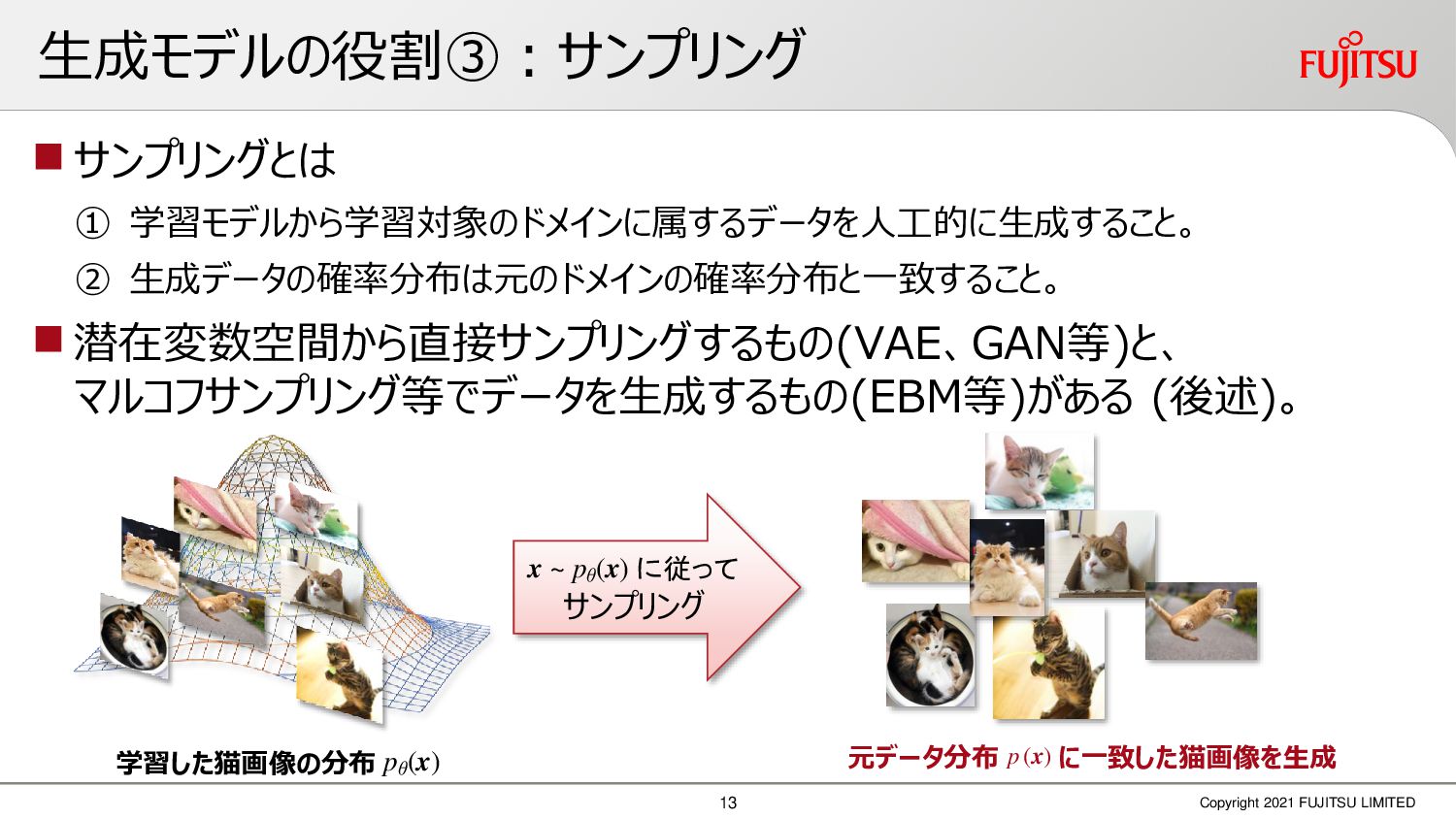
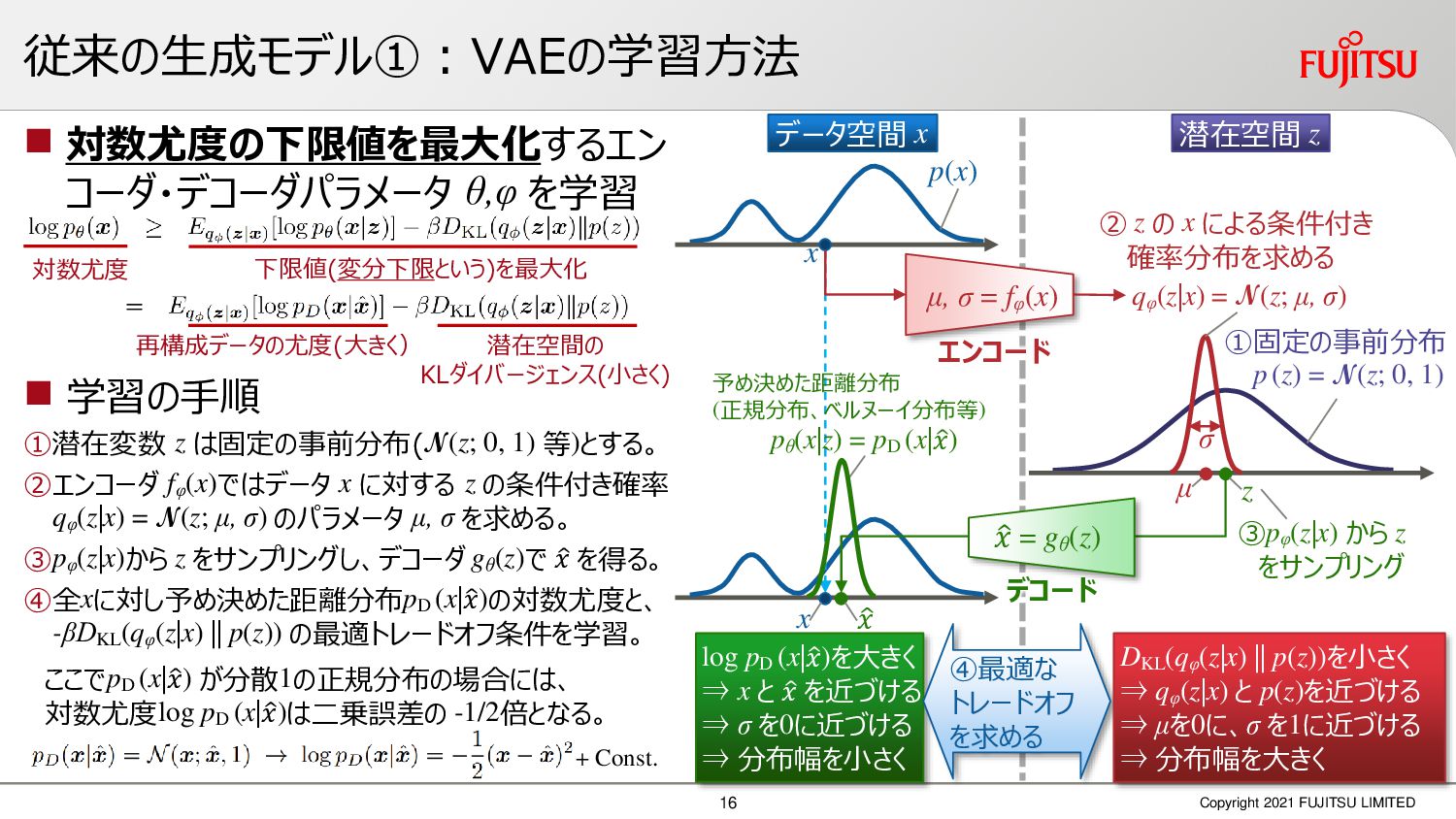
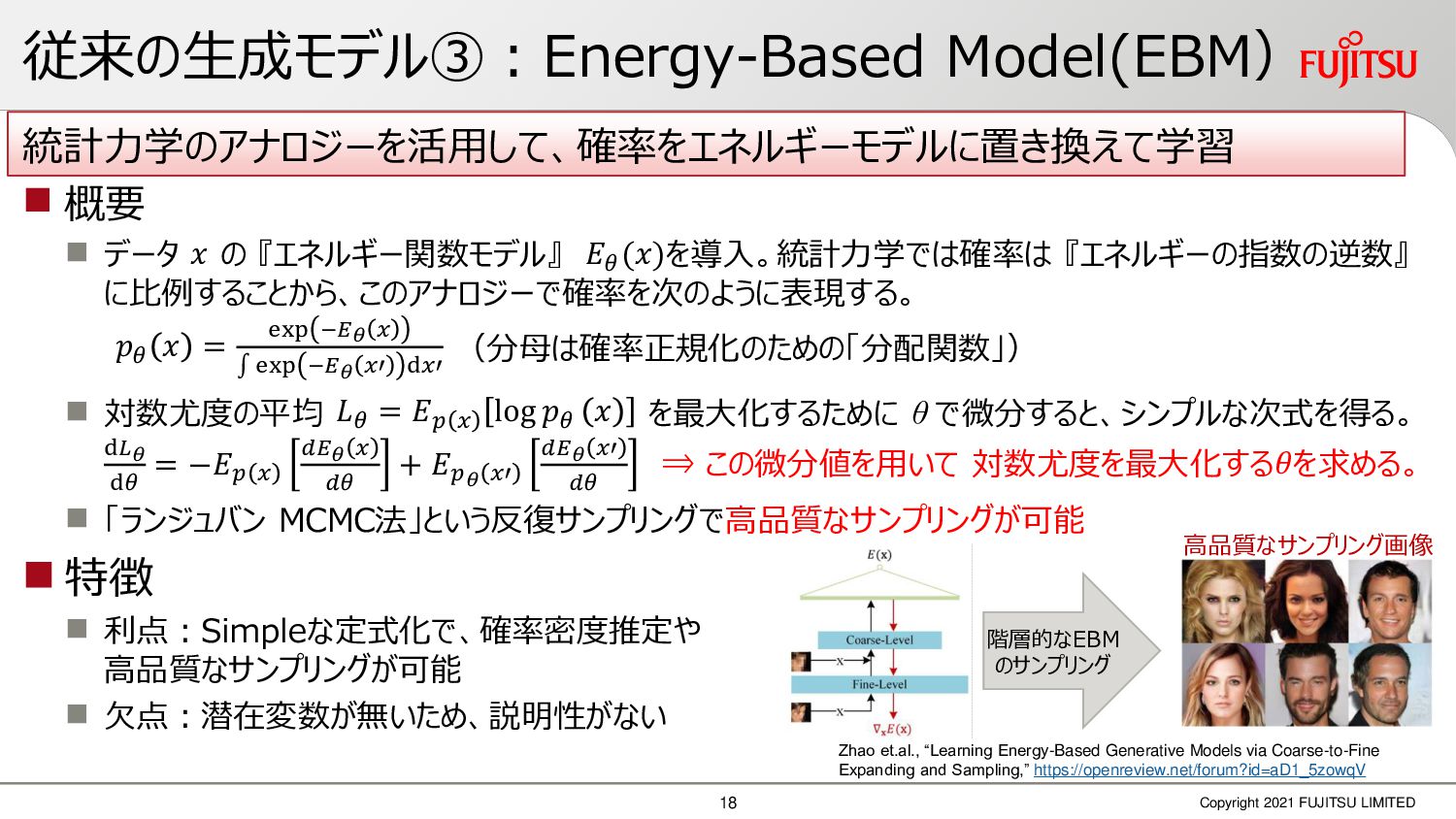
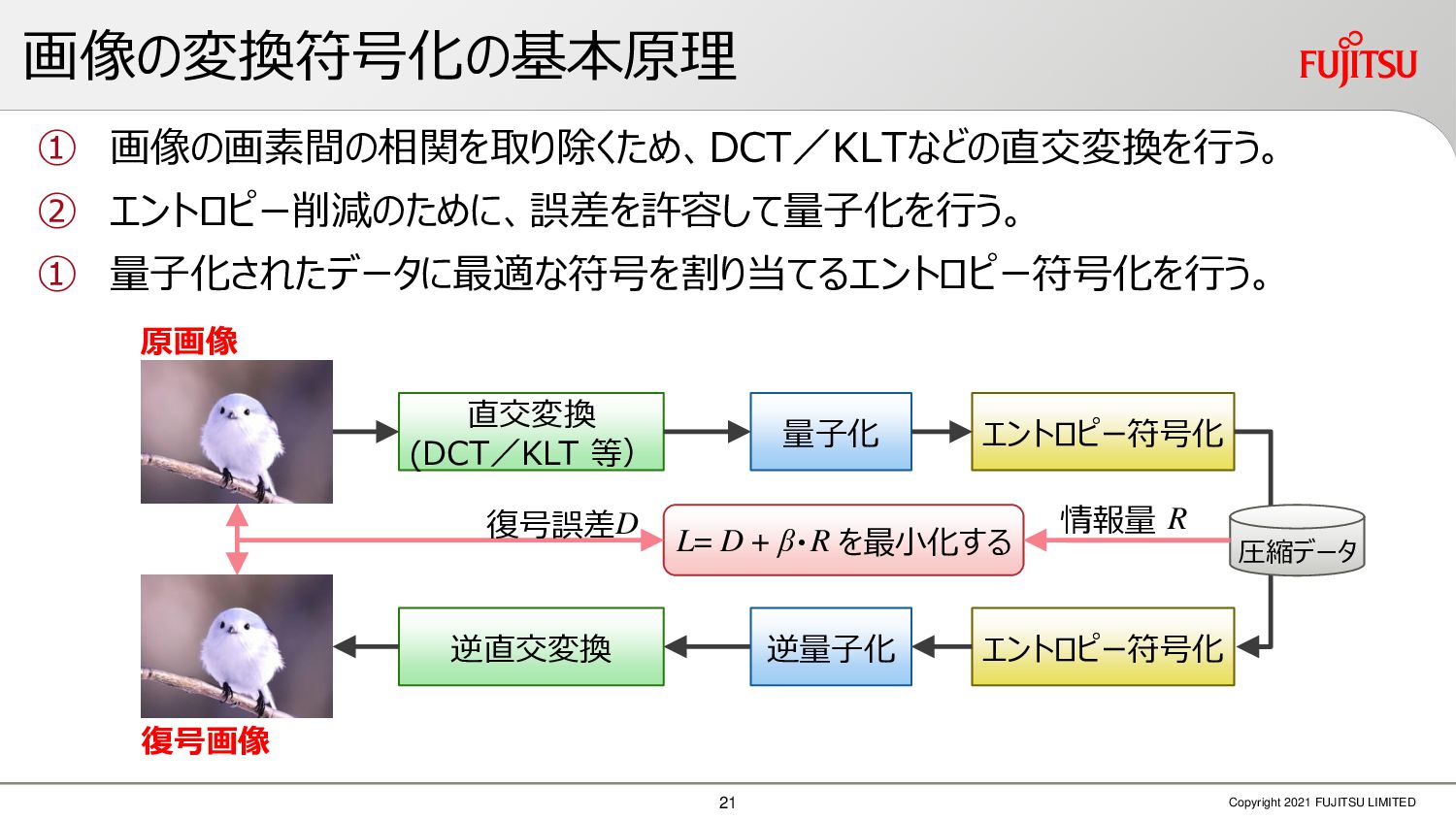
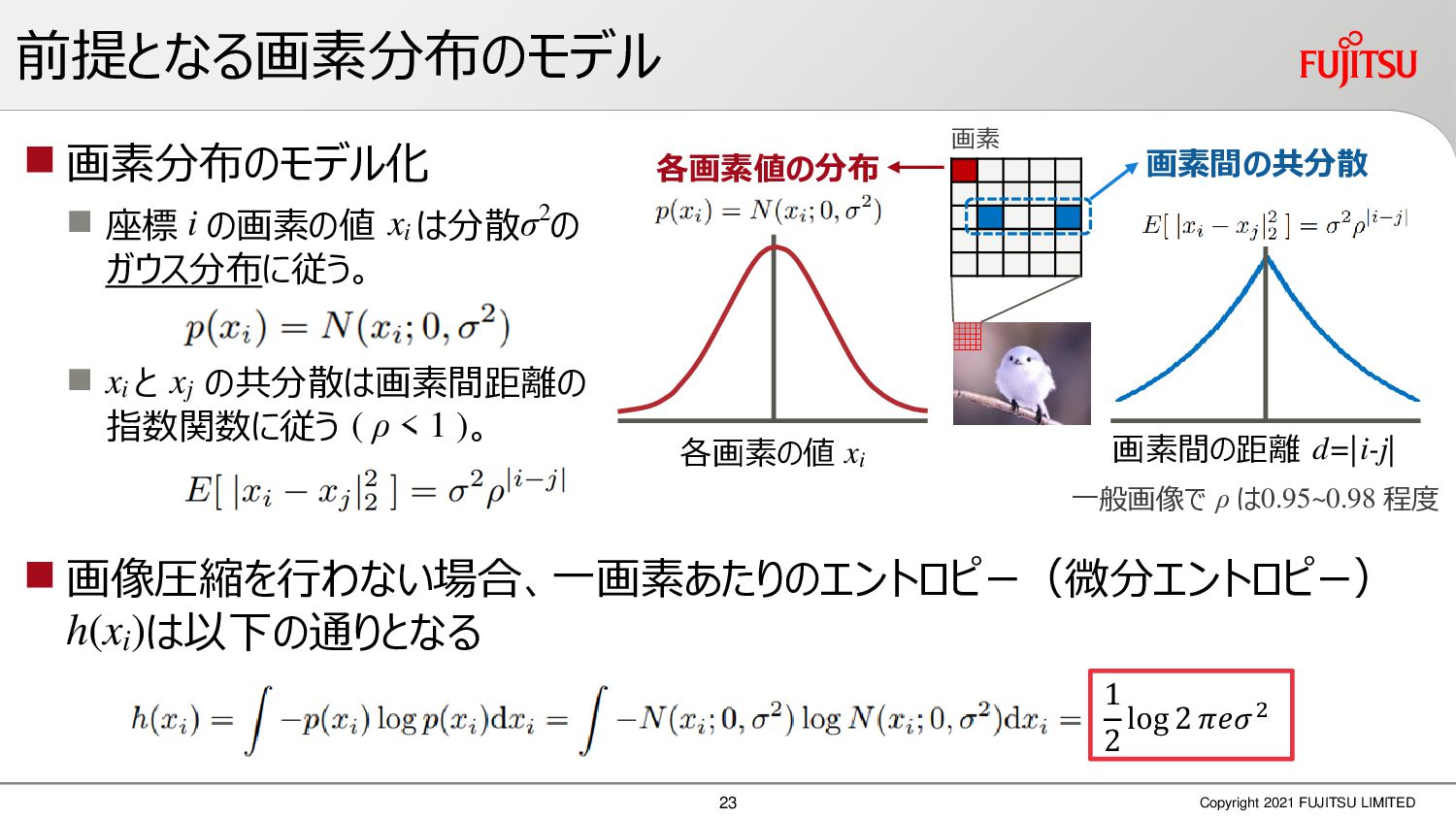
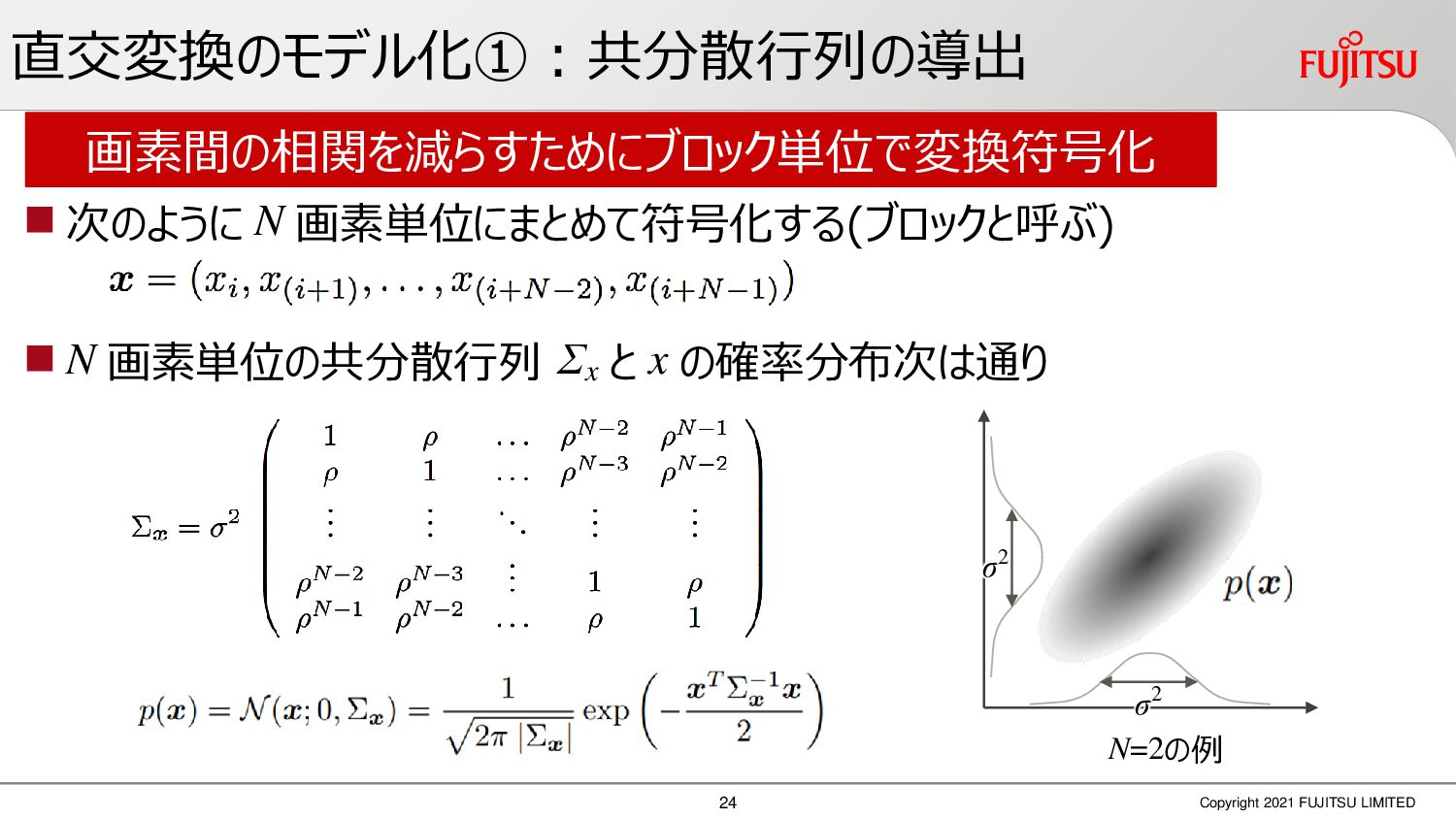
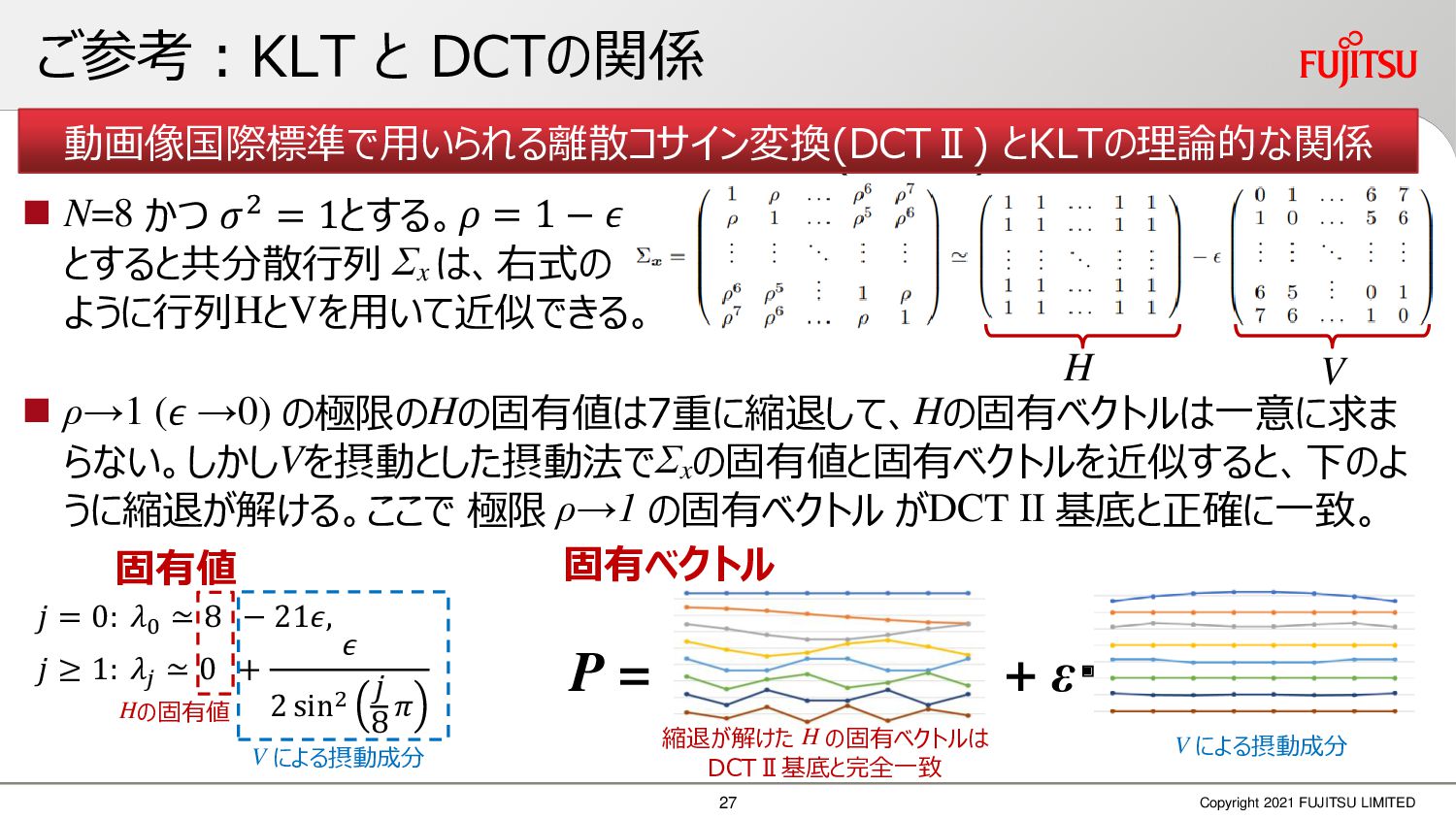
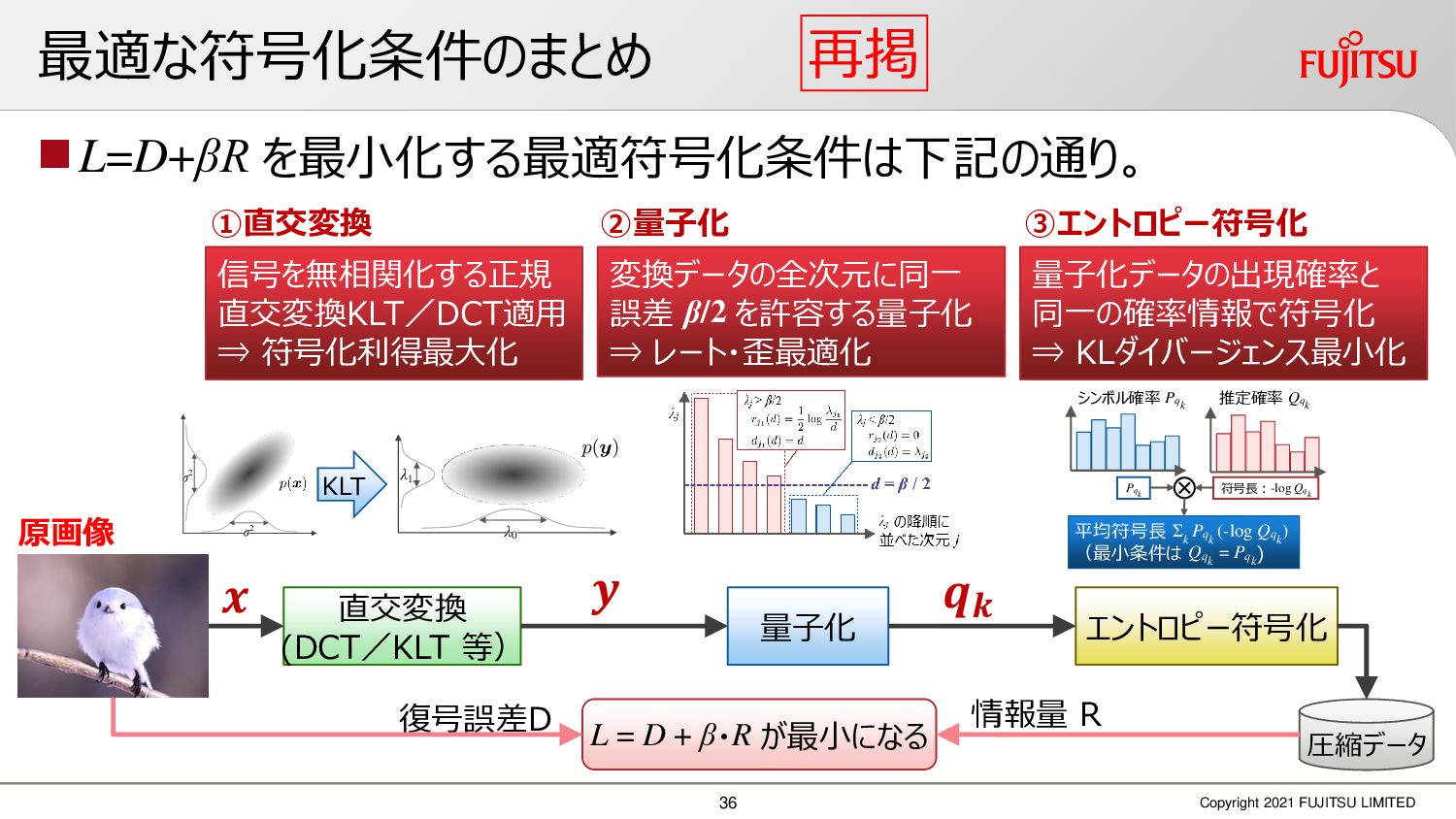
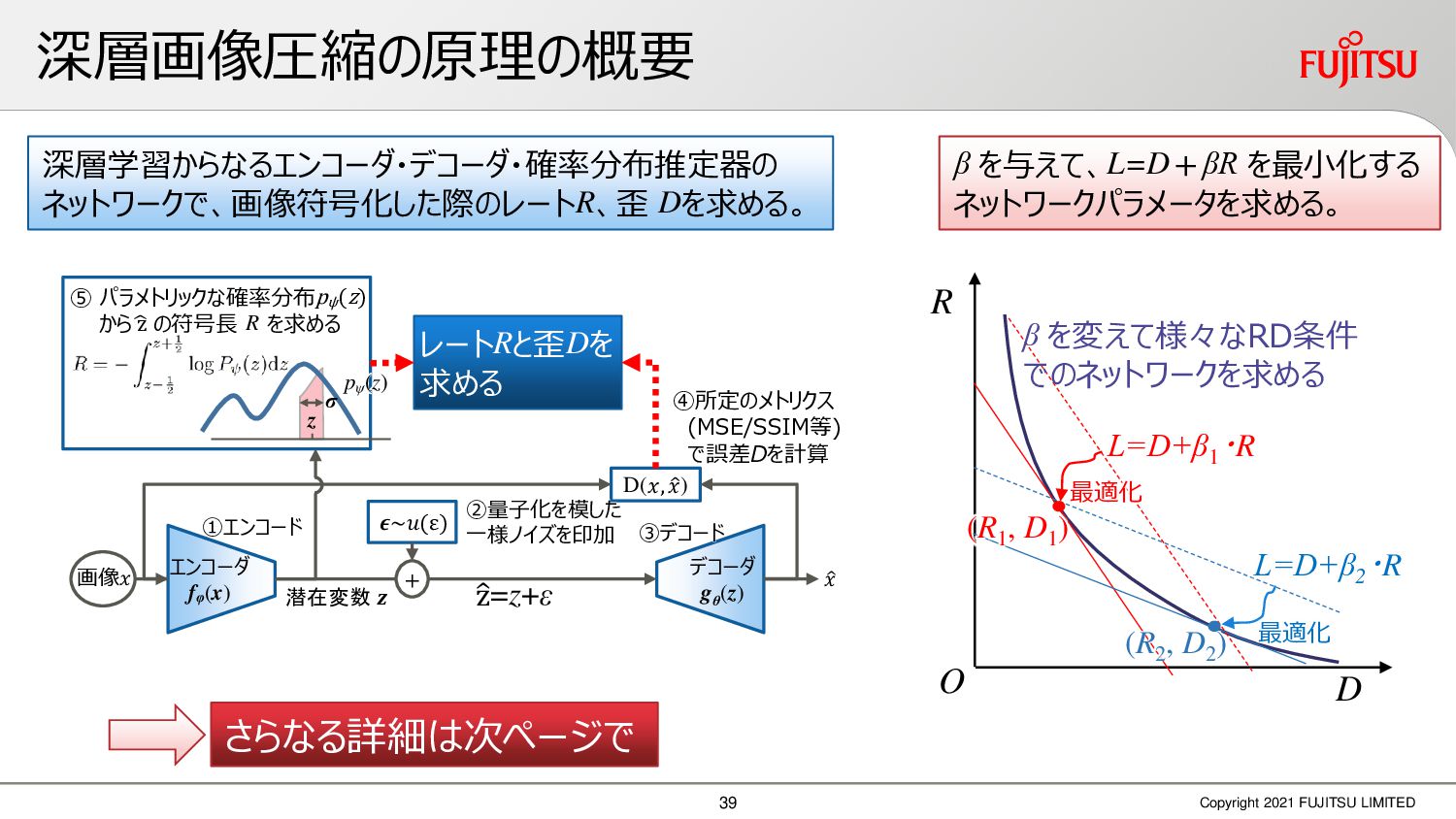
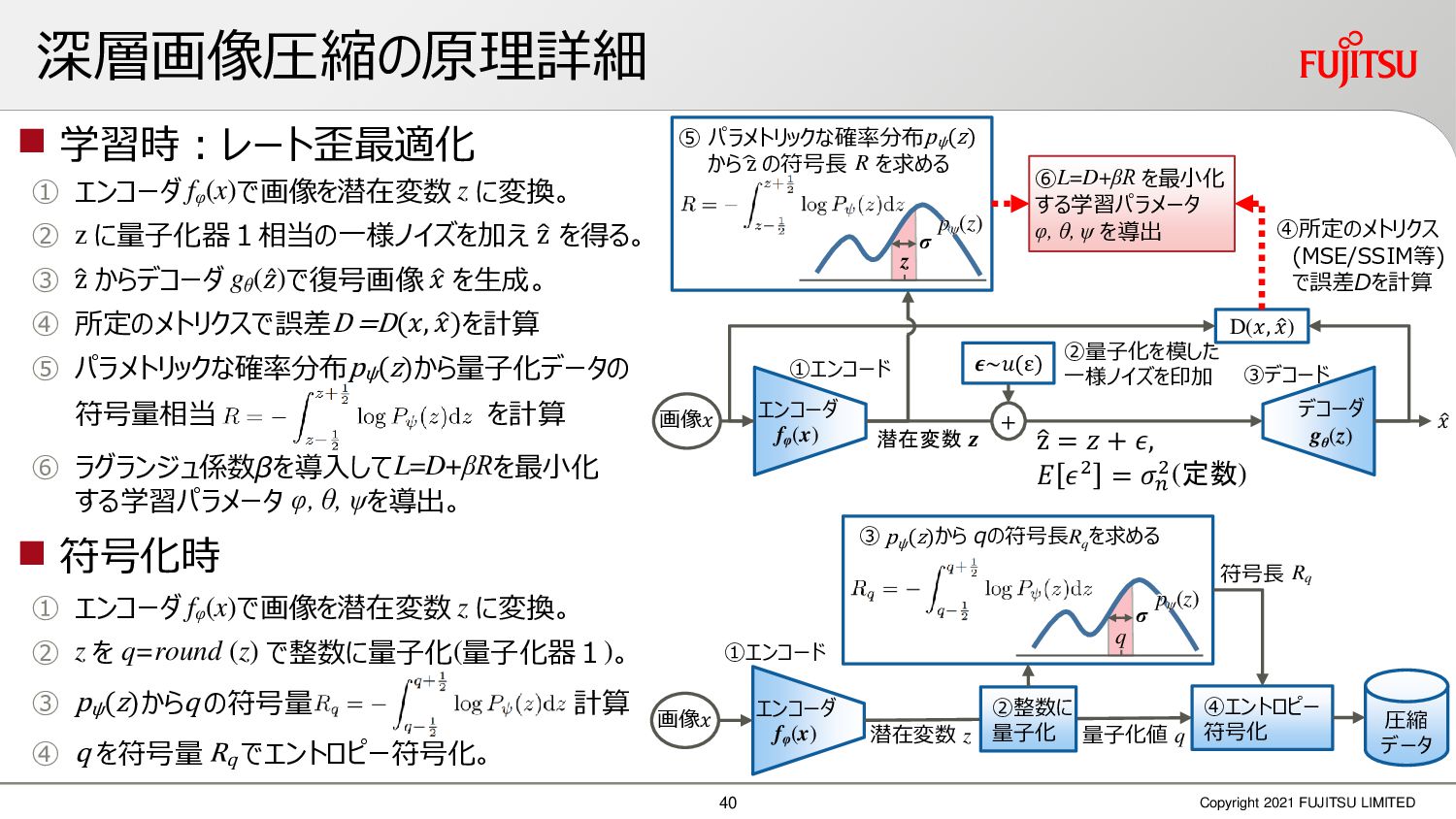
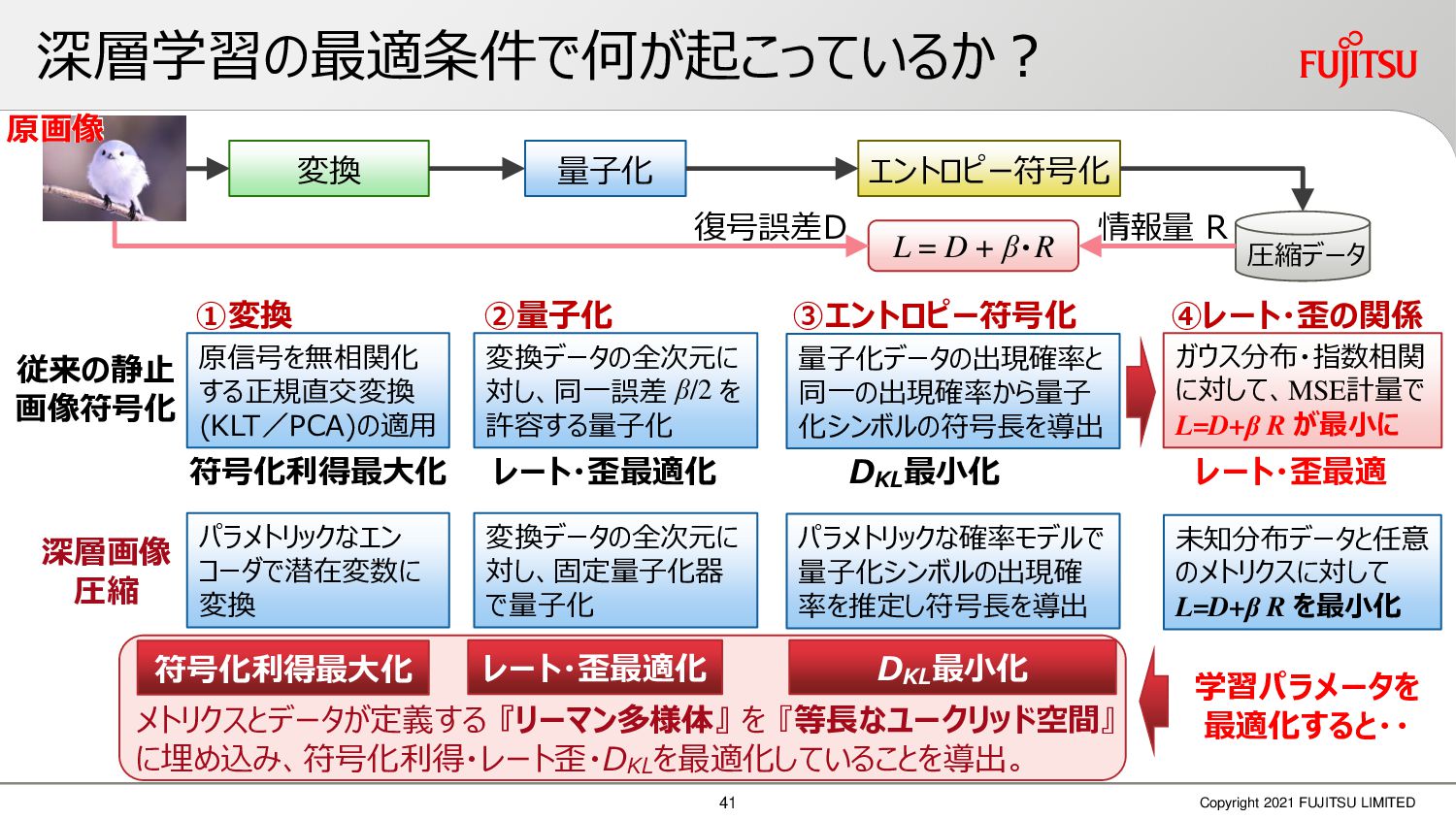
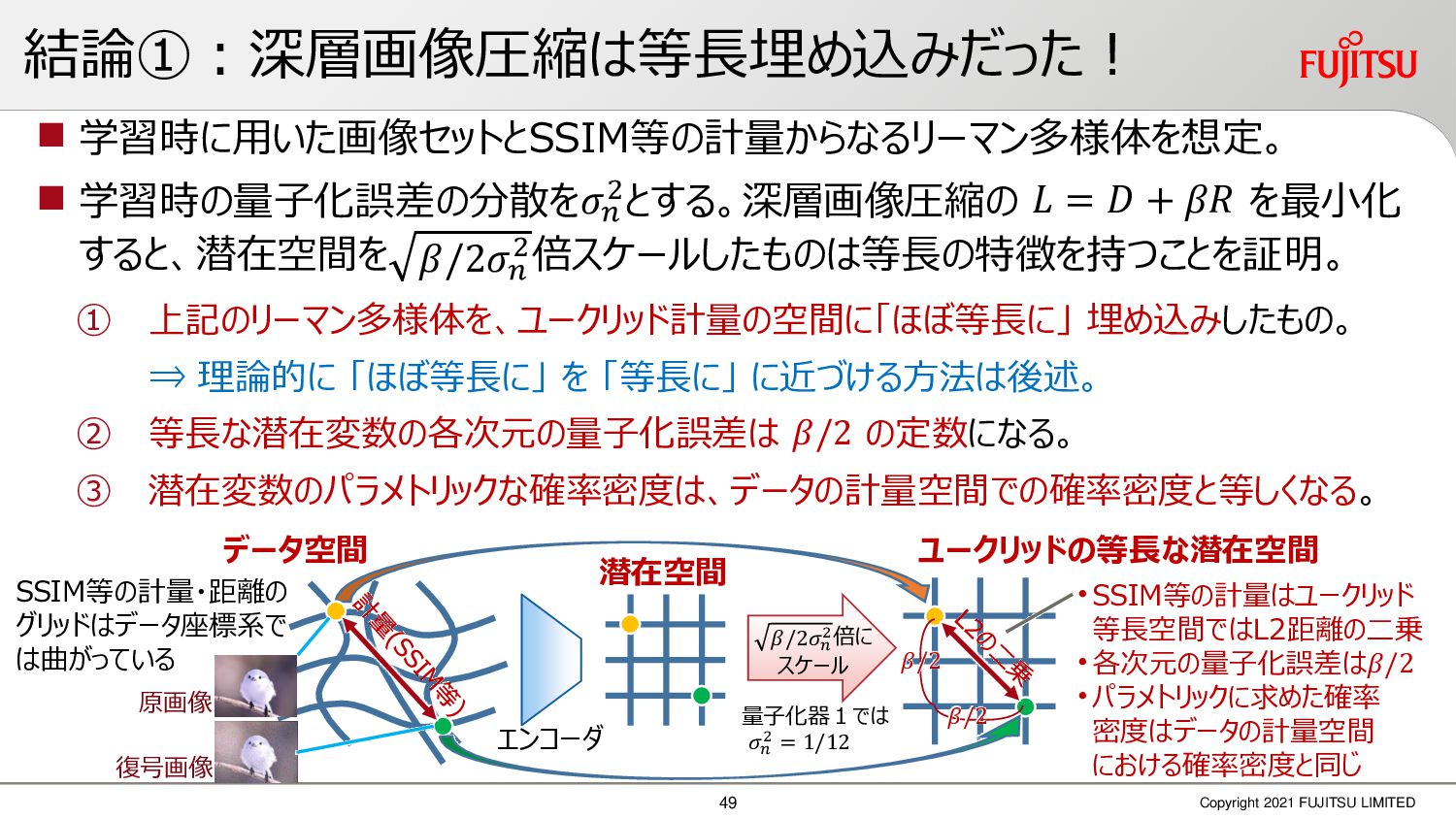
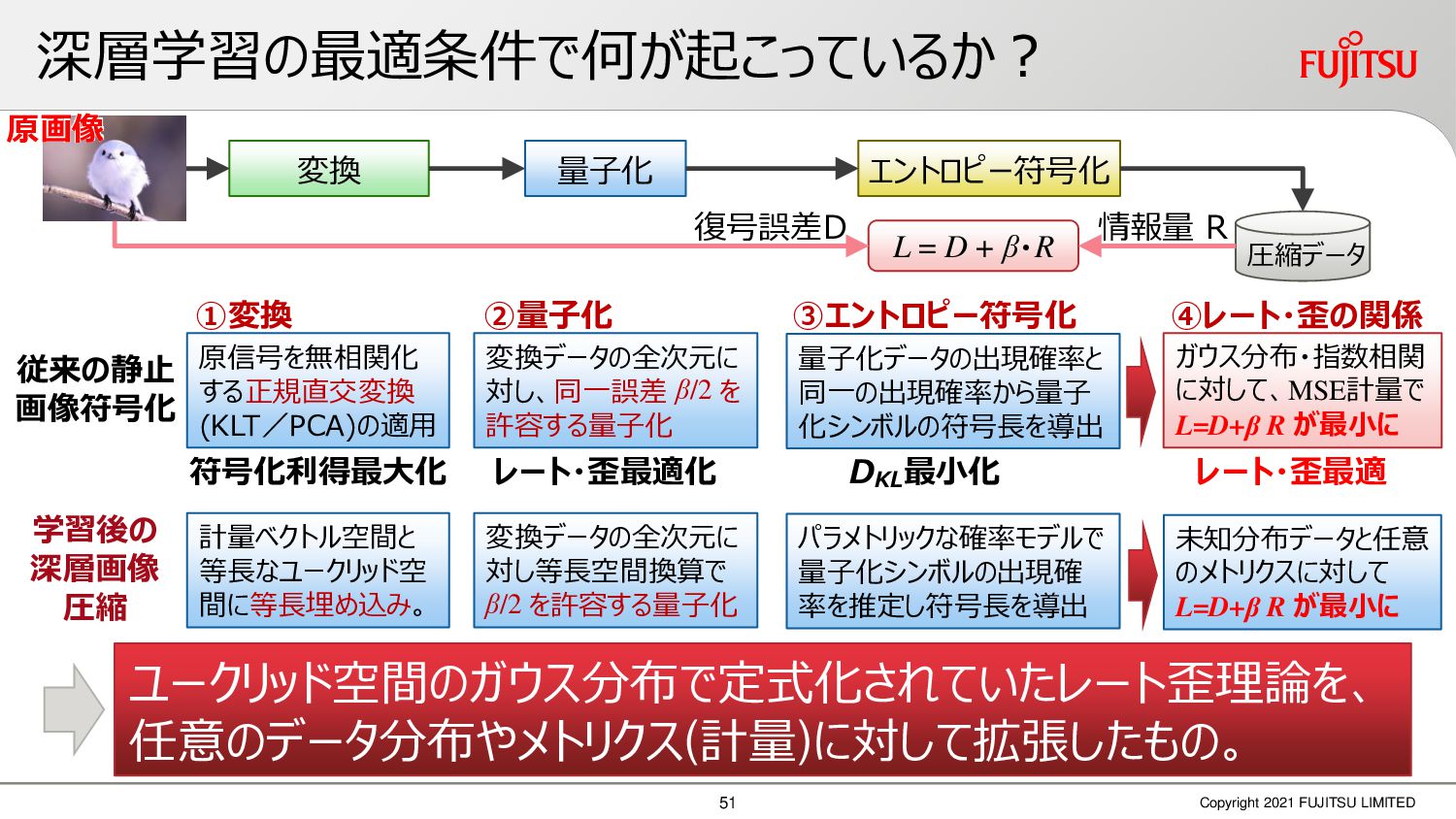
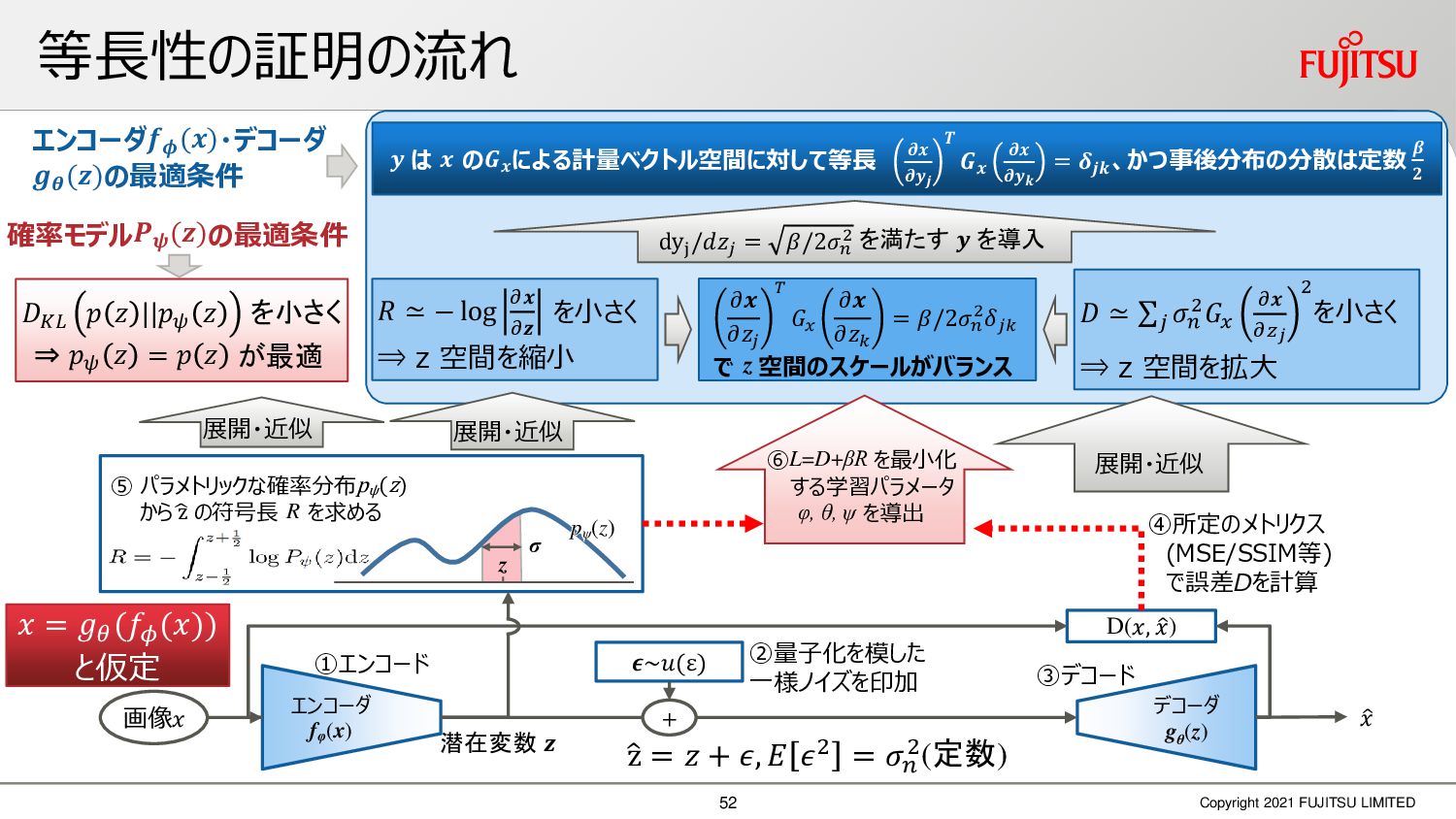
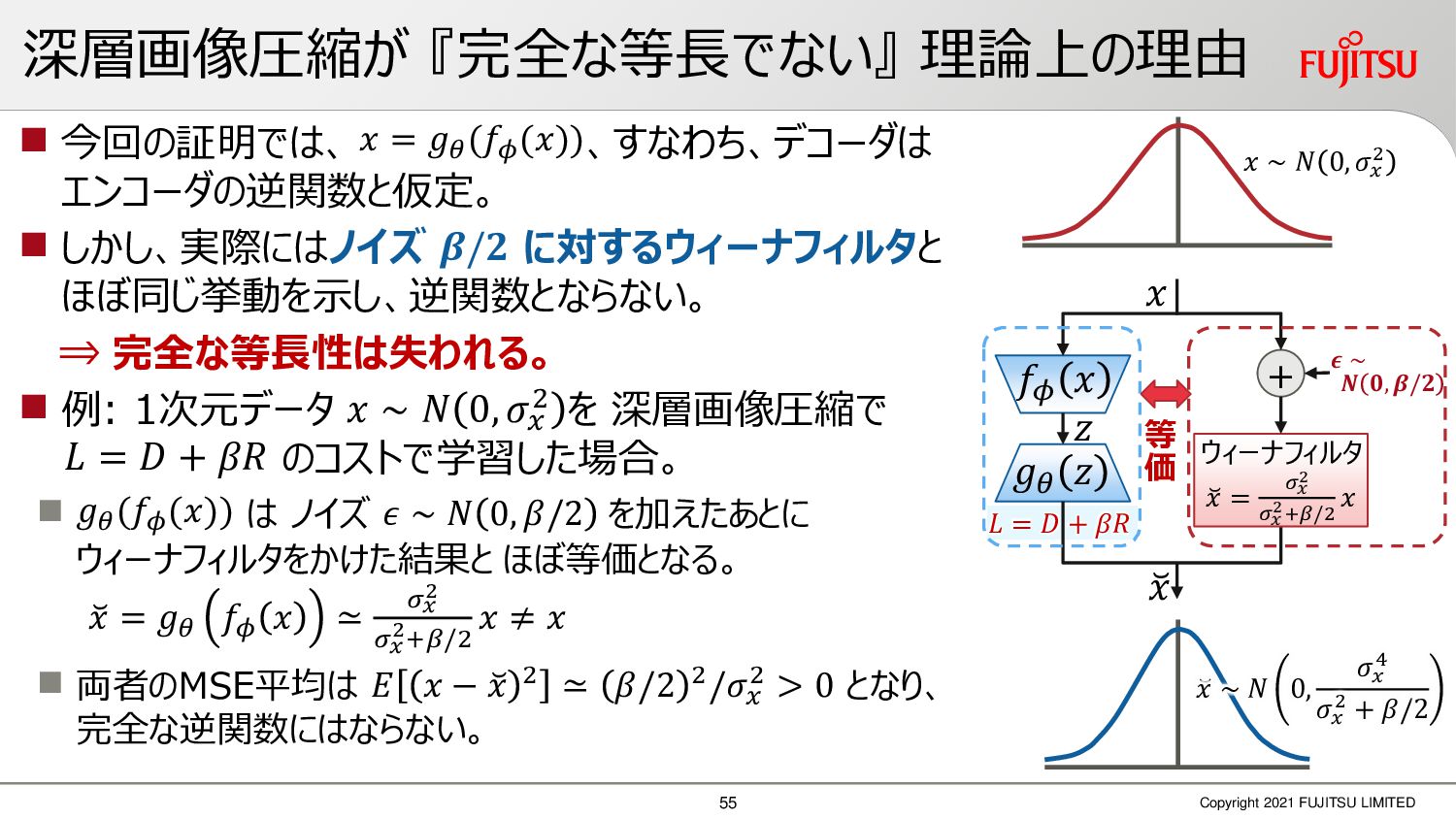
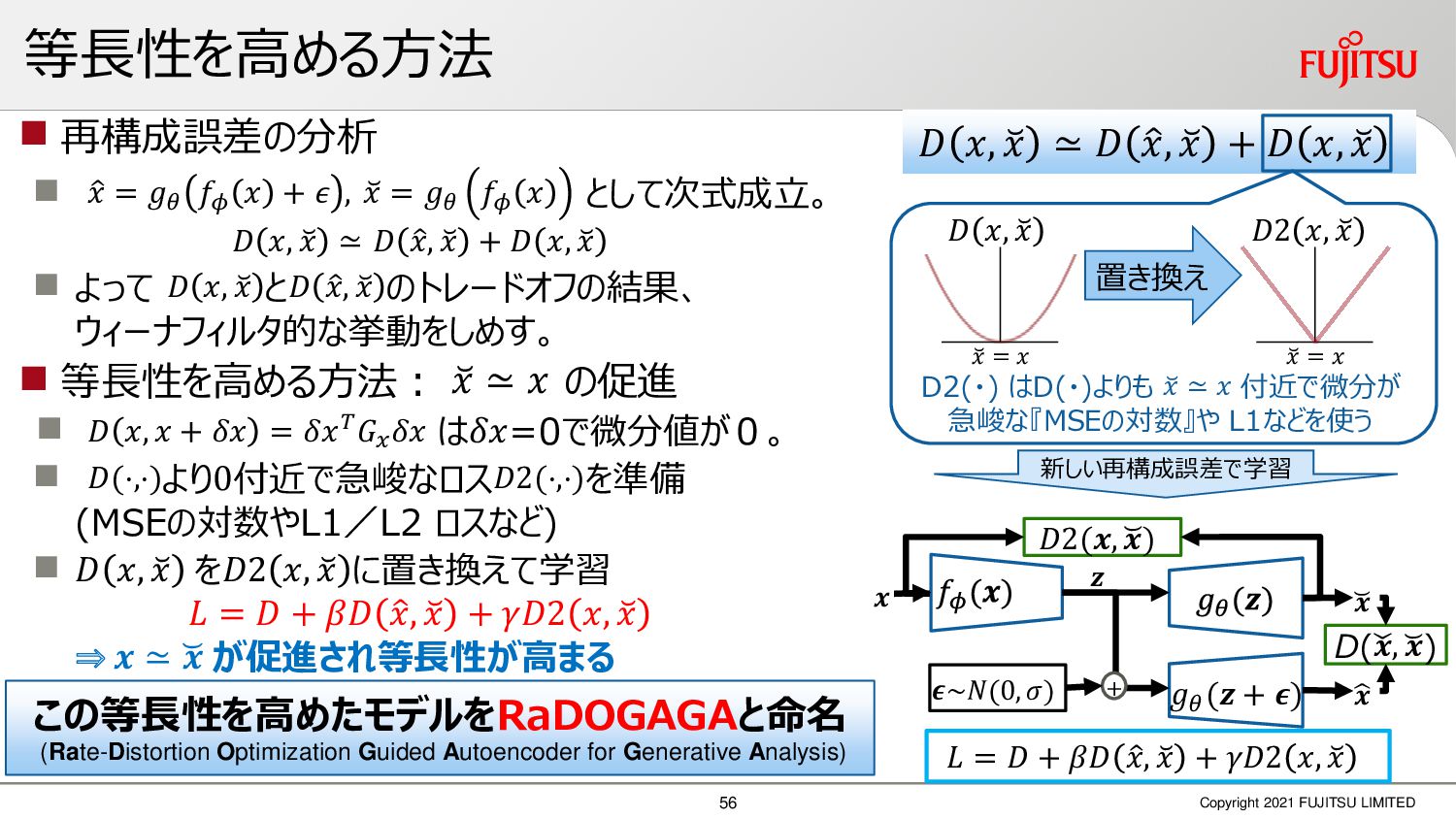
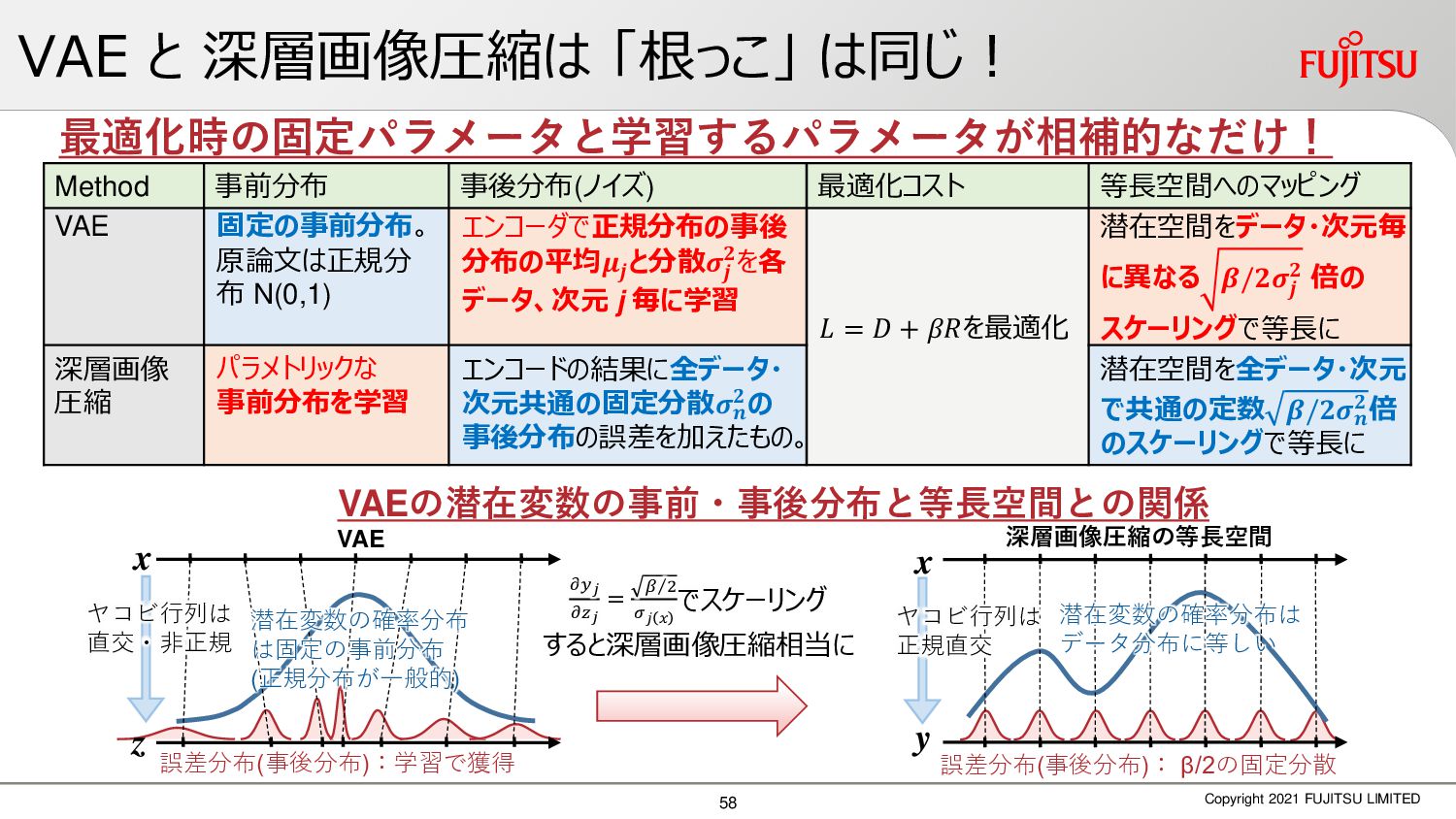
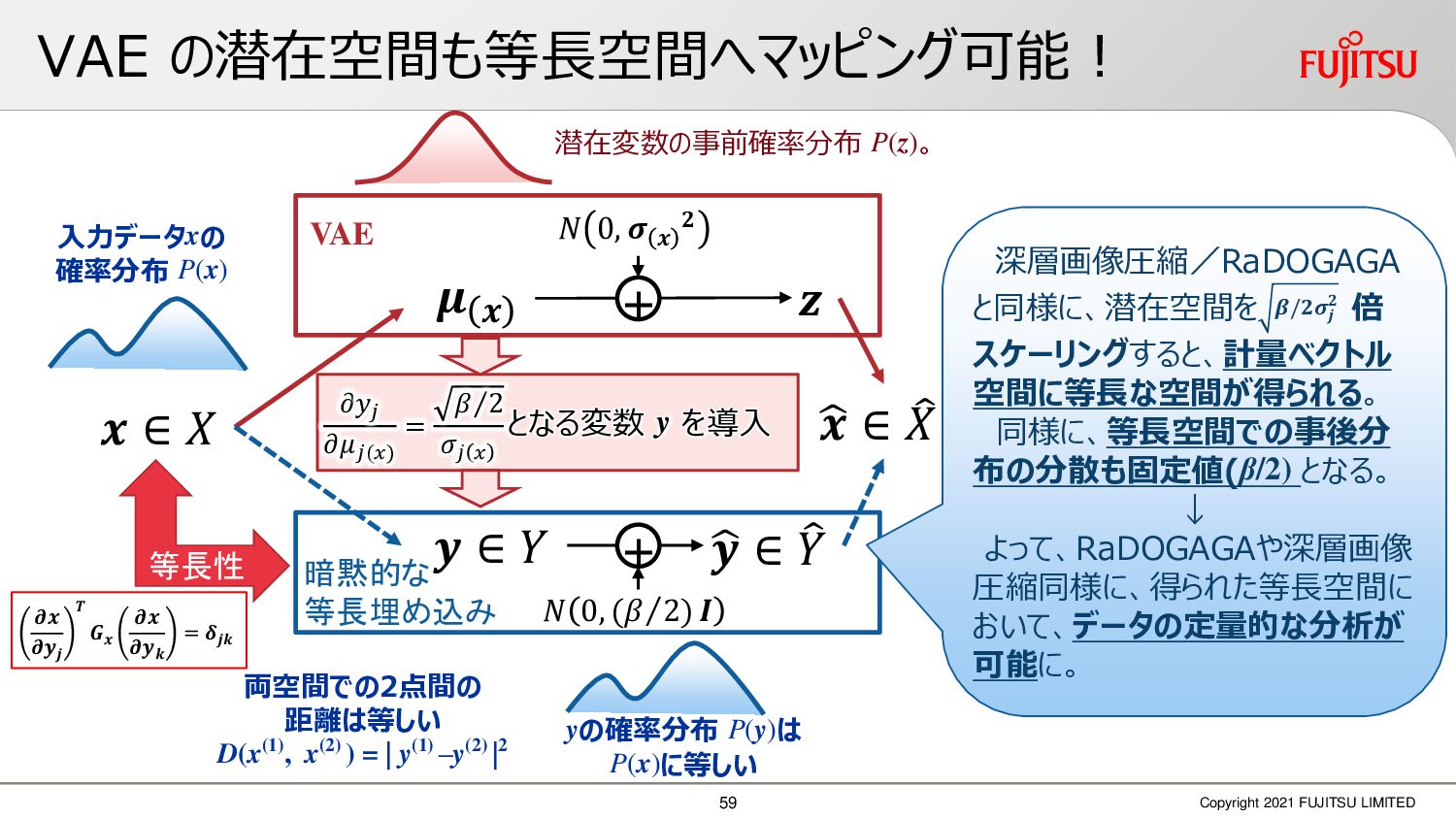
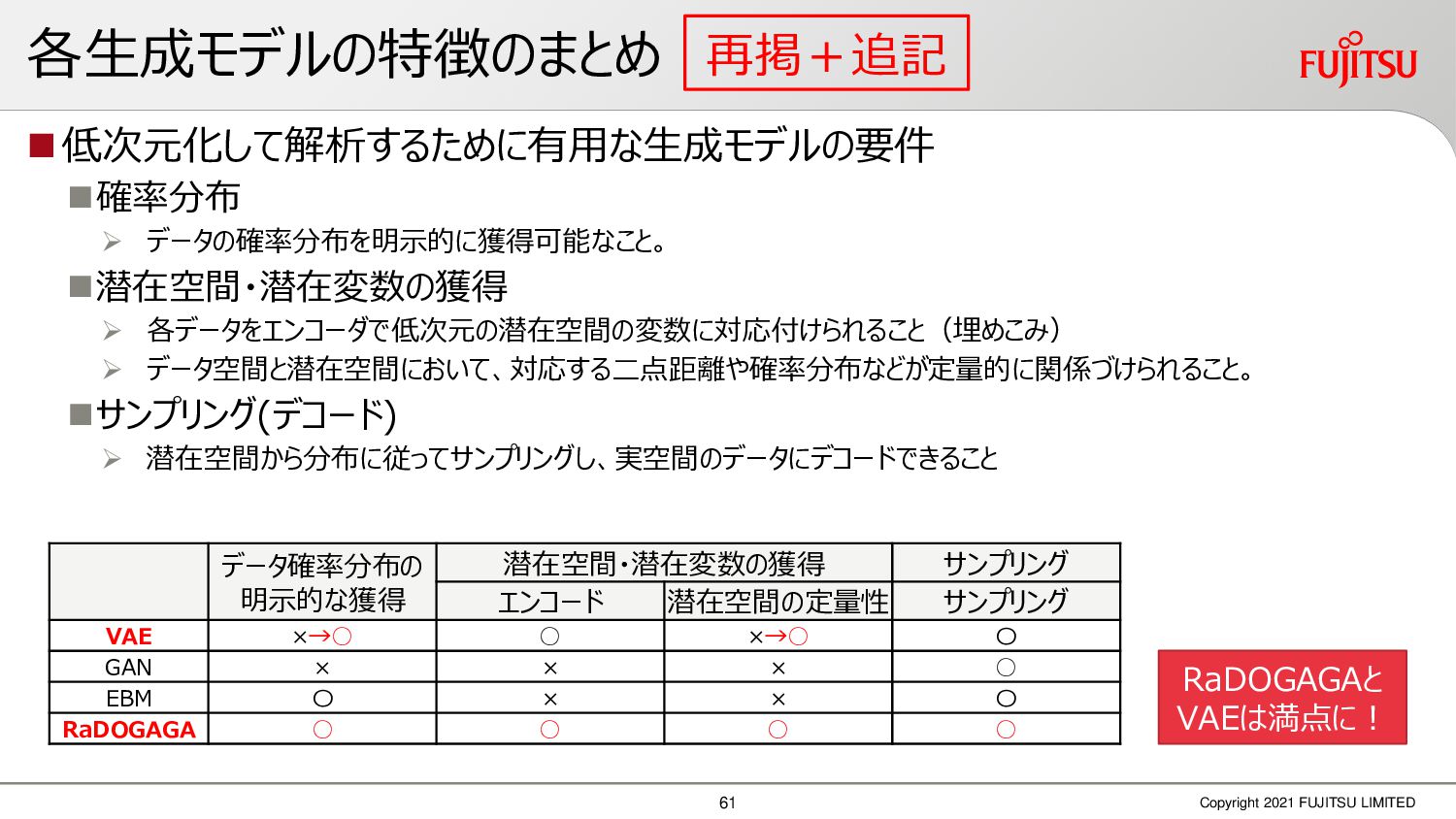
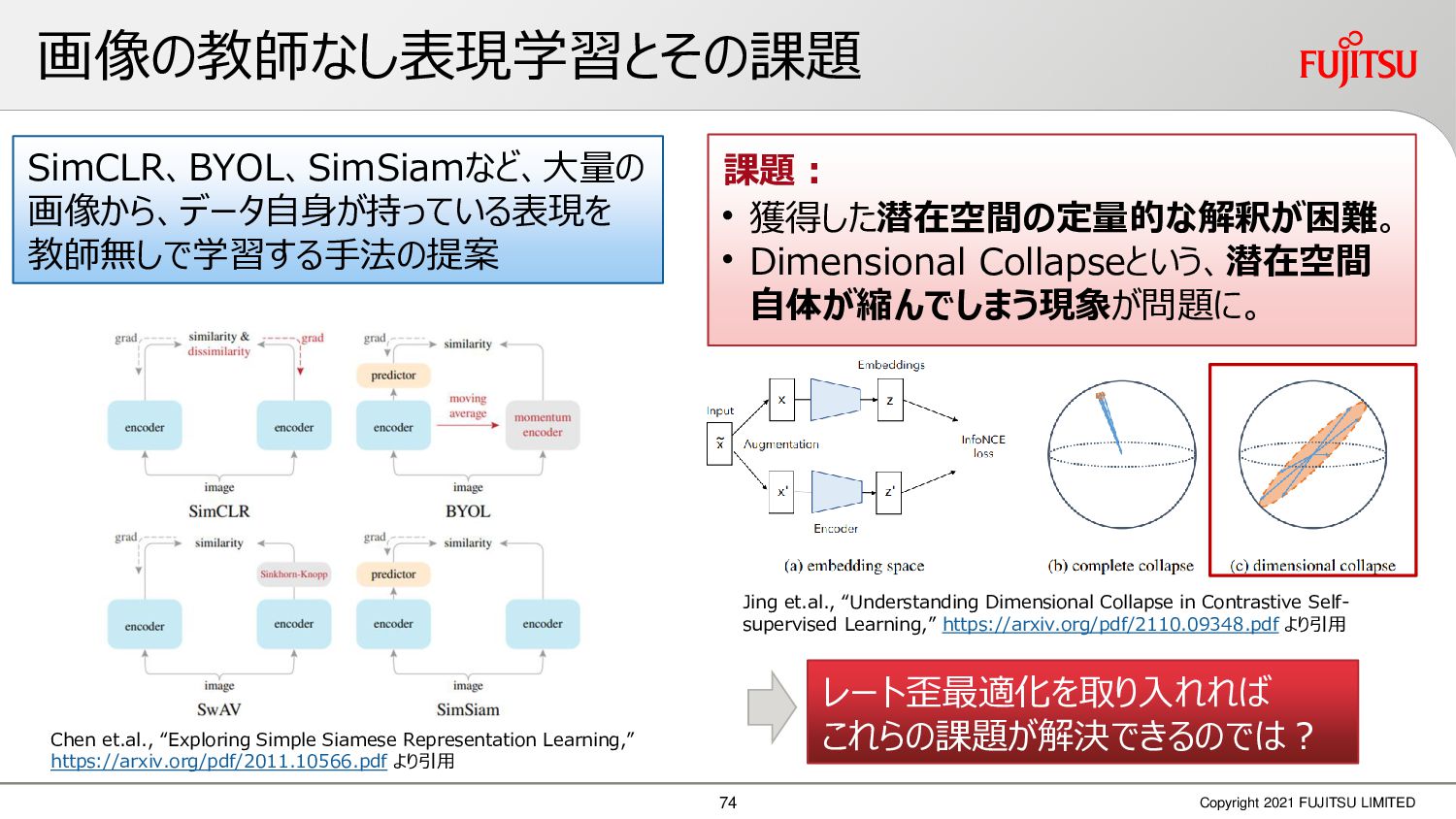
深層画像圧縮はSSIMなどの任意の距離尺度で、従来の変換符号化を超える高い性能を実現することが可能である。また、生成的AIモデルの一つであるVAEはサンプリング等などで幅広く用いられている。その一方で、深層画像圧縮やVAE等は、その定量的な理論解析が進んでいない。我々はレート歪理論と微分幾何学の枠組みを用いることで、深層画像圧縮及びVAEが同一の枠組みで説明できることを証明した。任意の分布をもつデータに対し、任意の距離尺度でレート歪最適化により獲得された潜在変数空間が、その距離尺度に対応した計量空間に対して等長の関係(正規直交性が全空間に滑らかにつながった状態)となり、かつ計量空間における潜在変数のエントロピーは最小となる。すなわち、従来はガウス分布とL2距離で定式化されていたレート歪理論の、任意の分布・距離に対する拡張である。この結果により、情報通信理論と微分幾何の観点から、モデルが獲得した潜在変数と元データの定量的な関係が導きだせ、各潜在変数の重要度や元データの確率分布推定などの定量解析が可能となる。
そして、最後に、1980年代に情報通信の方向性として提唱された「知的通信・符号化」と本理論に基づく生成的AIの関係性の観点から、今後のAI研究の方向性を議論する。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you Copyright 2021 FUJITSU LIMITED 誤り等のご指摘やご質問は 下記アドレスにお願いします。 deeptwin [at]](https://files.speakerdeck.com/presentations/0eea6c1bf87e4a24b365f7f1de15cd19/slide_76.jpg){kind=link}
{kind=link}