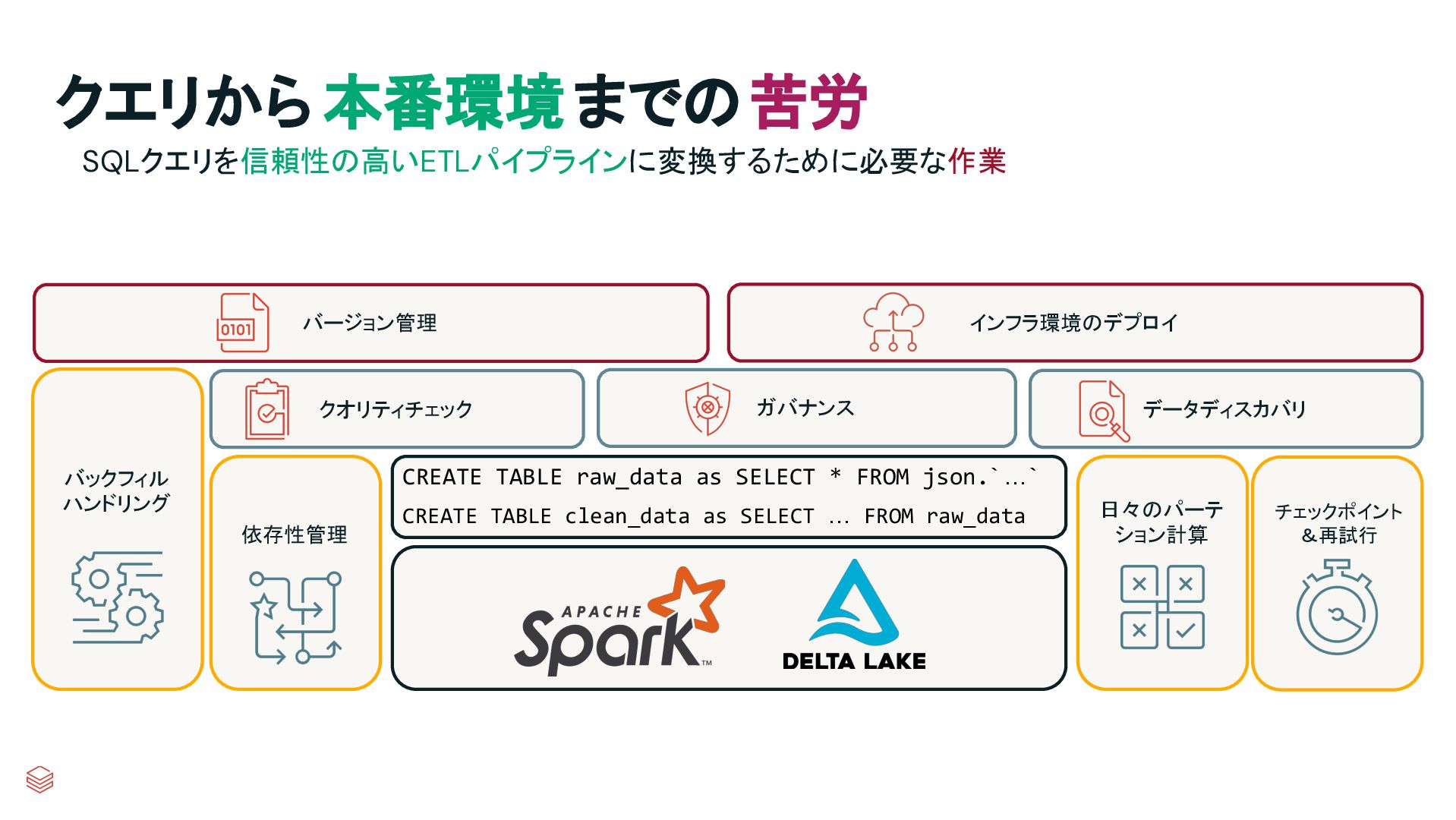
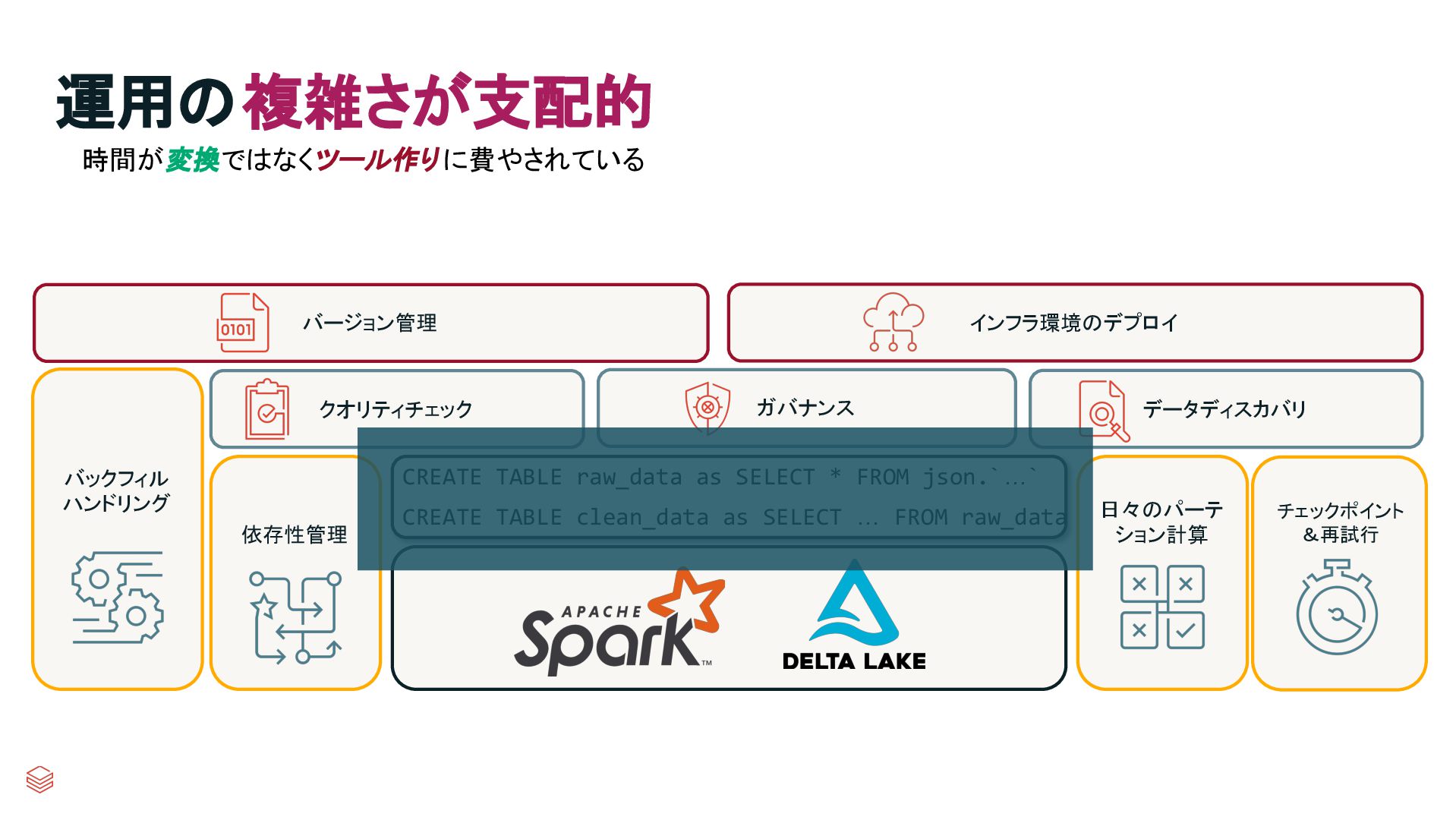
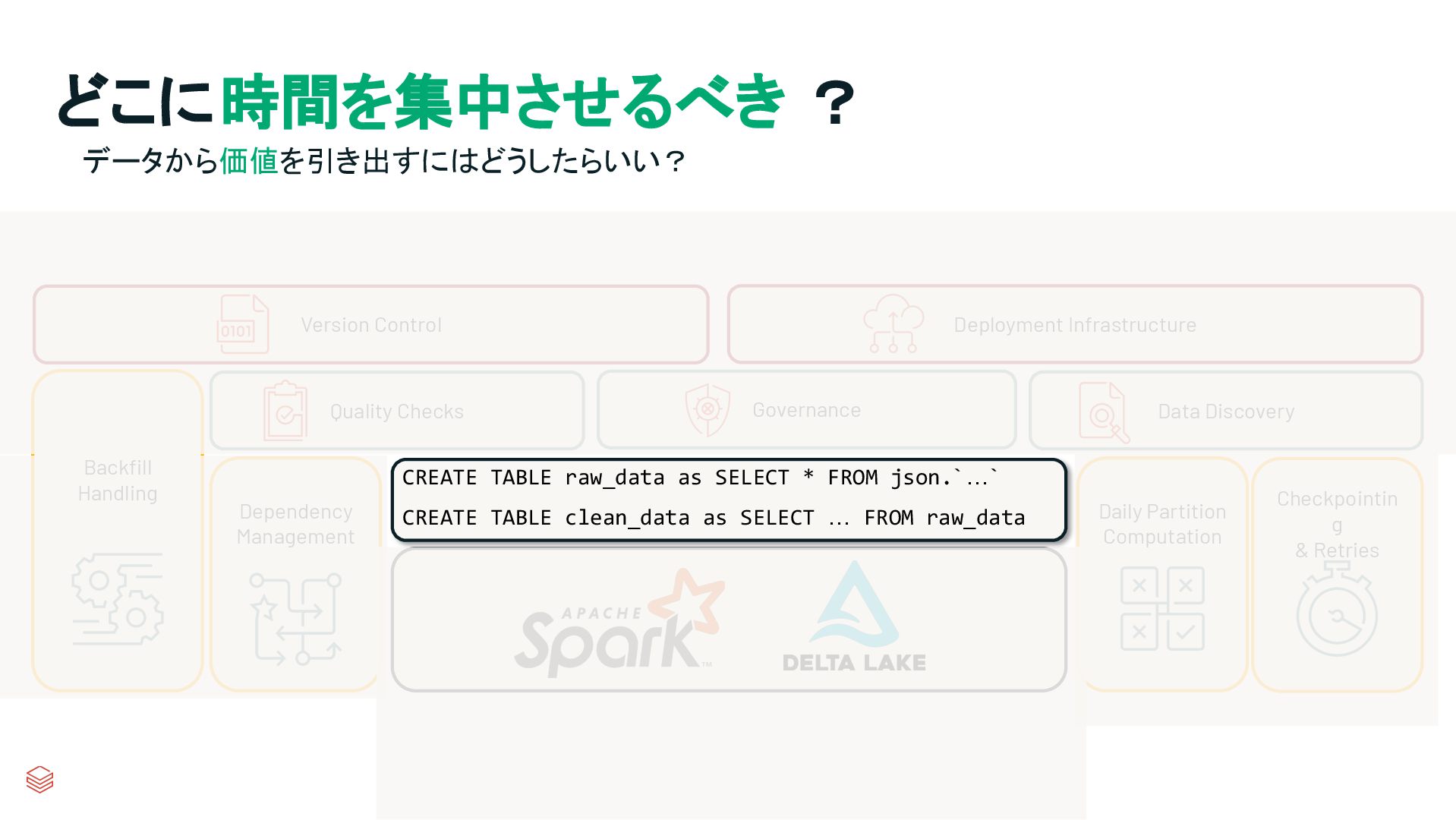
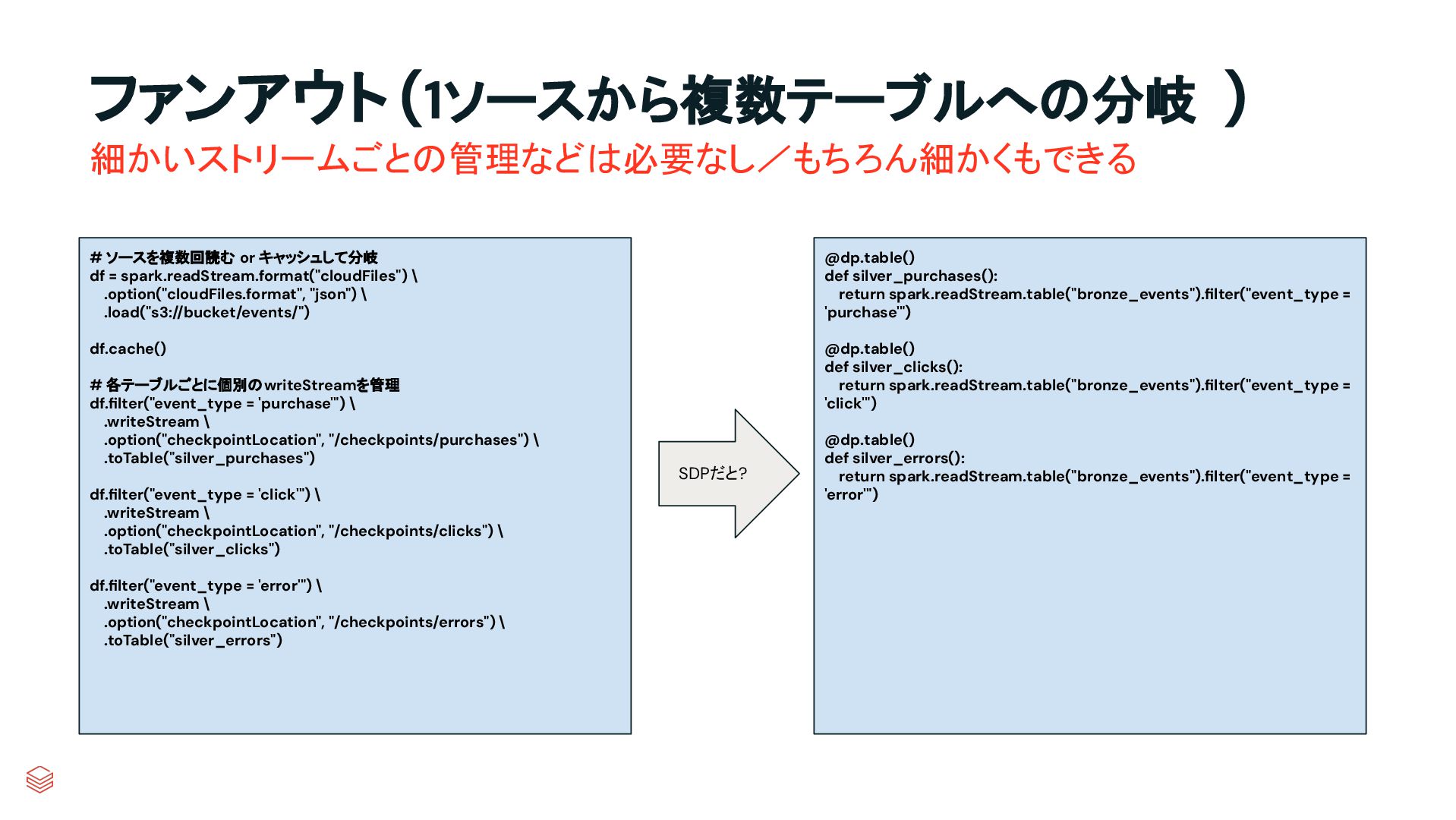
g & Retries Quality Checks Governance Data Discovery Backfill Handling Version Control Deployment Infrastructure CREATE TABLE raw_data as SELECT * FROM json.`…` CREATE TABLE clean_data as SELECT … FROM raw_data
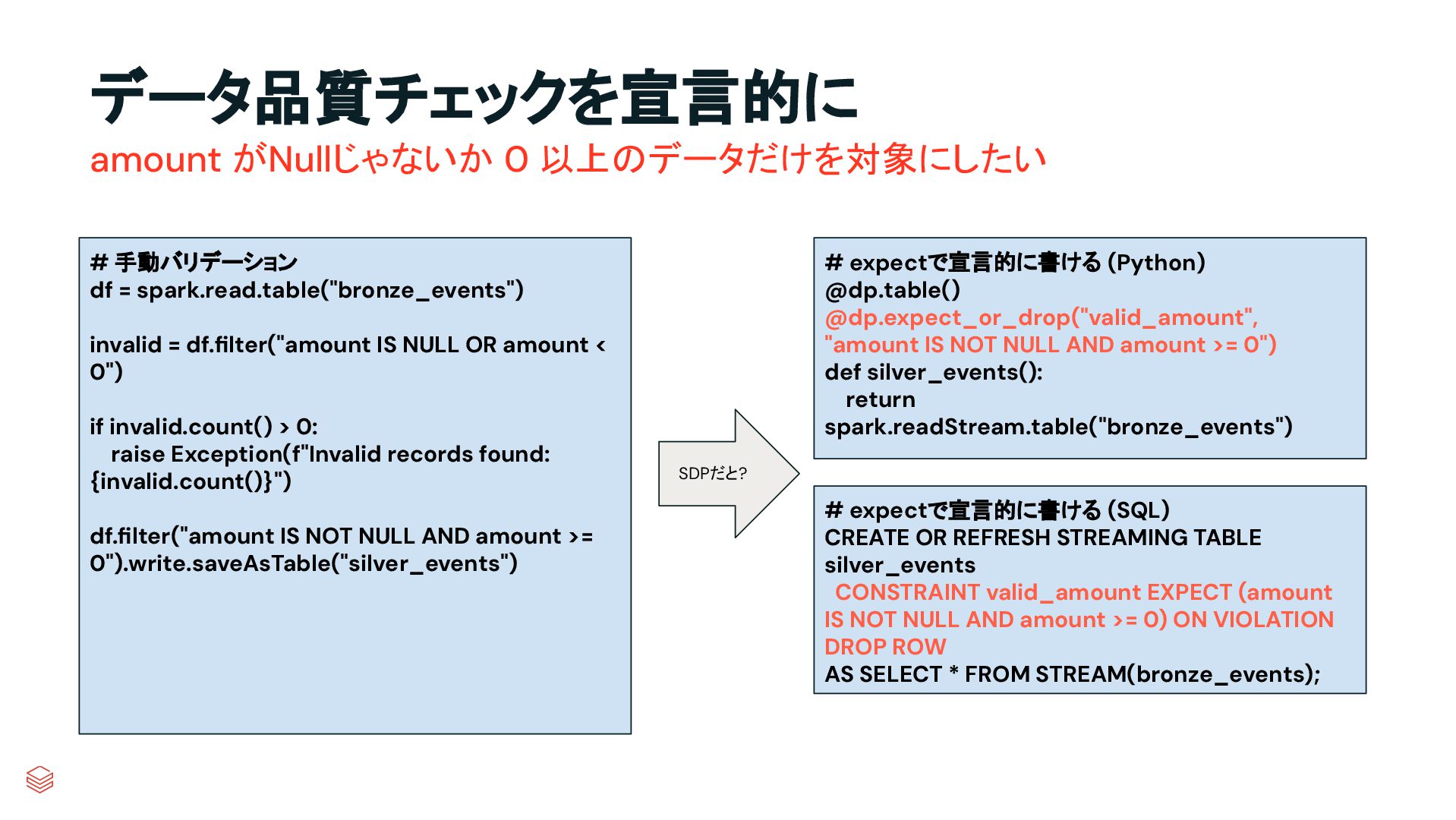
spark.read.table("bronze_events") invalid = df.filter("amount IS NULL OR amount < 0") if invalid.count() > 0: raise Exception(f"Invalid records found: {invalid.count()}") df.filter("amount IS NOT NULL AND amount >= 0").write.saveAsTable("silver_events") # expectで宣言的に書ける (Python) @dp.table() @dp.expect_or_drop("valid_amount", "amount IS NOT NULL AND amount >= 0") def silver_events(): return spark.readStream.table("bronze_events") SDPだと? # expectで宣言的に書ける (SQL) CREATE OR REFRESH STREAMING TABLE silver_events CONSTRAINT valid_amount EXPECT (amount IS NOT NULL AND amount >= 0) ON VIOLATION DROP ROW AS SELECT * FROM STREAM(bronze_events);
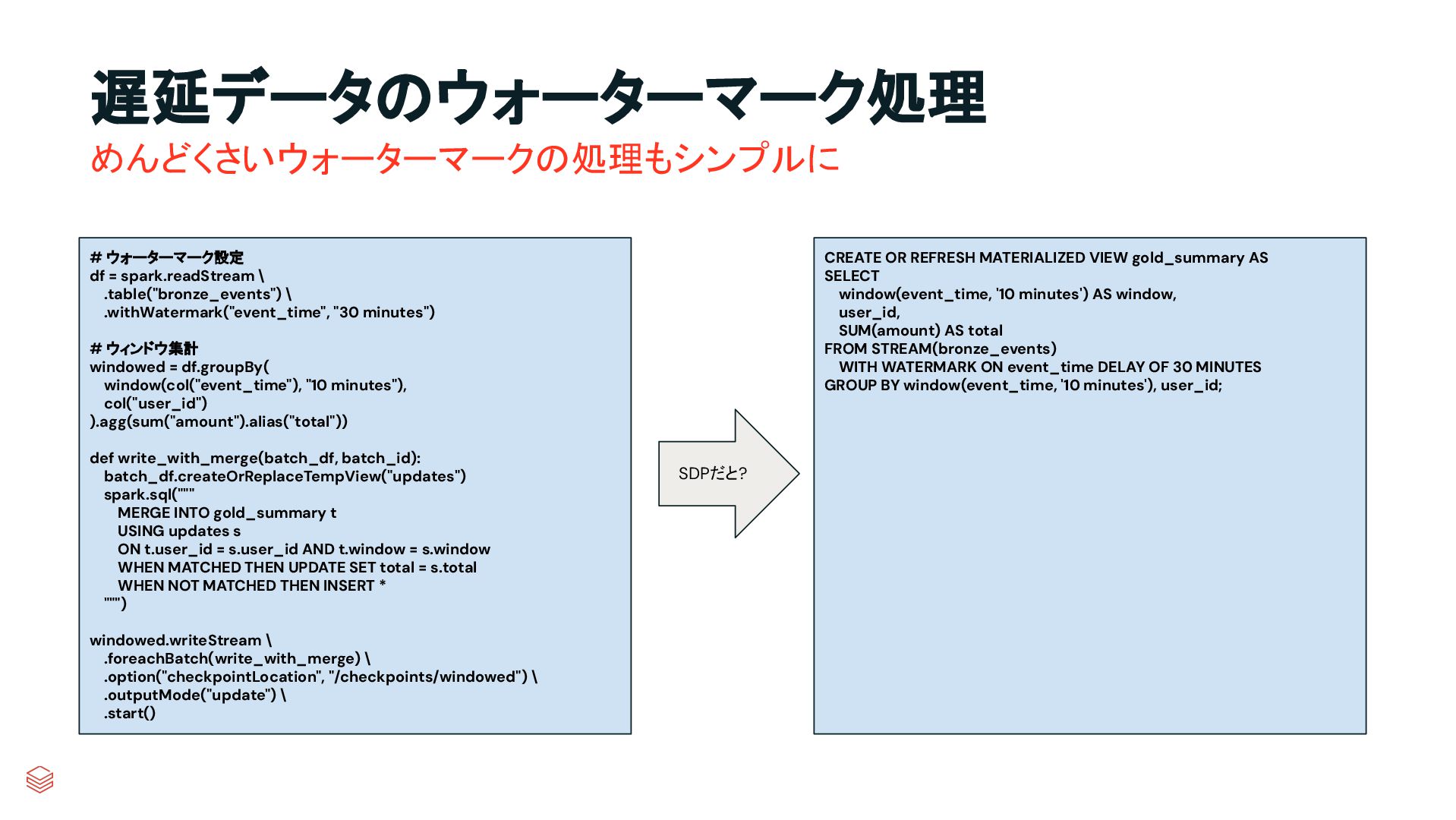
.table("bronze_events") \ .withWatermark("event_time", "30 minutes") # ウィンドウ集計 windowed = df.groupBy( window(col("event_time"), "10 minutes"), col("user_id") ).agg(sum("amount").alias("total")) def write_with_merge(batch_df, batch_id): batch_df.createOrReplaceTempView("updates") spark.sql(""" MERGE INTO gold_summary t USING updates s ON t.user_id = s.user_id AND t.window = s.window WHEN MATCHED THEN UPDATE SET total = s.total WHEN NOT MATCHED THEN INSERT * """) windowed.writeStream \ .foreachBatch(write_with_merge) \ .option("checkpointLocation", "/checkpoints/windowed") \ .outputMode("update") \ .start() CREATE OR REFRESH MATERIALIZED VIEW gold_summary AS SELECT window(event_time, '10 minutes') AS window, user_id, SUM(amount) AS total FROM STREAM(bronze_events) WITH WATERMARK ON event_time DELAY OF 30 MINUTES GROUP BY window(event_time, '10 minutes'), user_id; SDPだと?
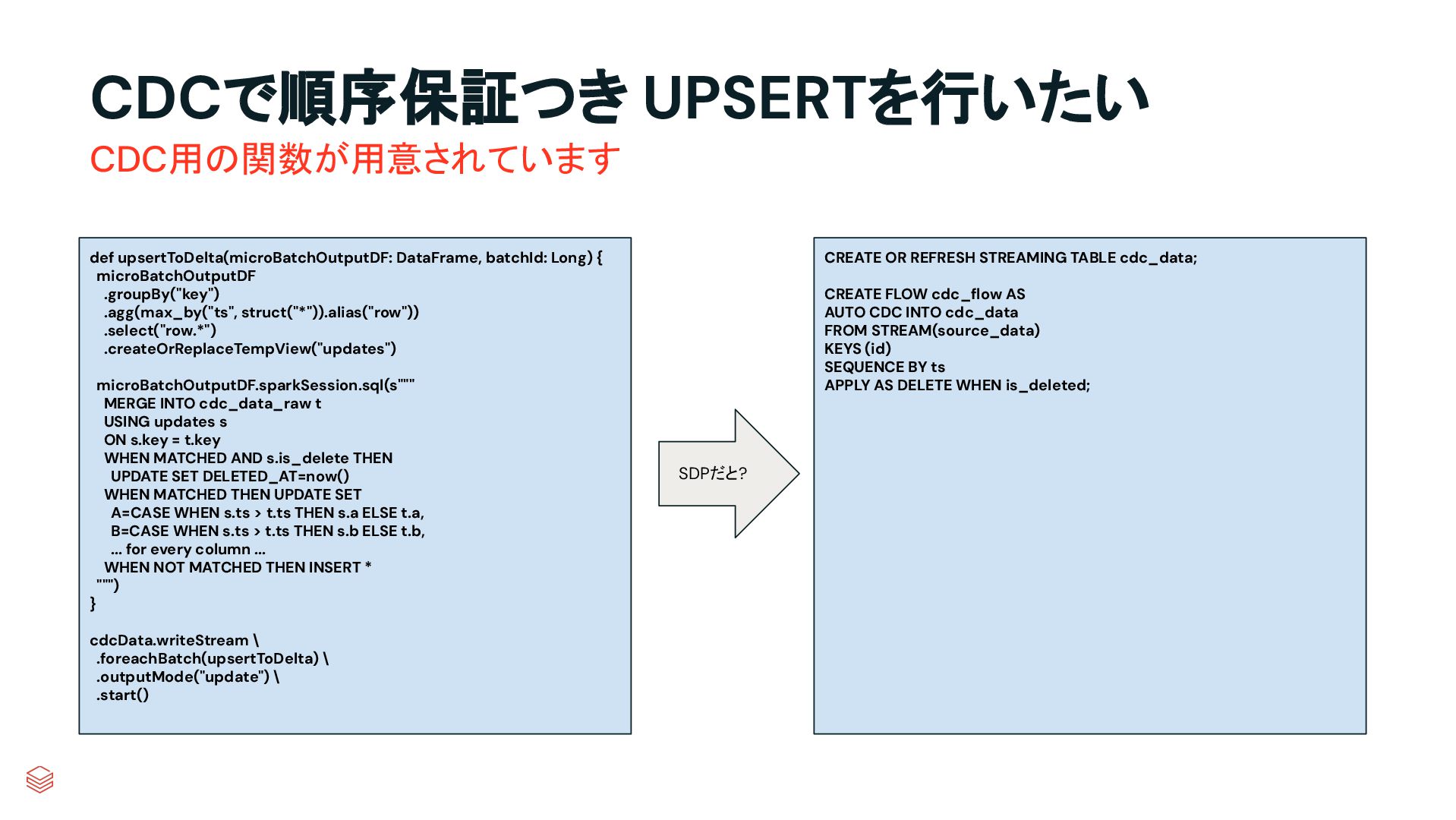
microBatchOutputDF .groupBy("key") .agg(max_by("ts", struct("*")).alias("row")) .select("row.*") .createOrReplaceTempView("updates") microBatchOutputDF.sparkSession.sql(s""" MERGE INTO cdc_data_raw t USING updates s ON s.key = t.key WHEN MATCHED AND s.is_delete THEN UPDATE SET DELETED_AT=now() WHEN MATCHED THEN UPDATE SET A=CASE WHEN s.ts > t.ts THEN s.a ELSE t.a, B=CASE WHEN s.ts > t.ts THEN s.b ELSE t.b, ... for every column ... WHEN NOT MATCHED THEN INSERT * """) } cdcData.writeStream \ .foreachBatch(upsertToDelta) \ .outputMode("update") \ .start() CREATE OR REFRESH STREAMING TABLE cdc_data; CREATE FLOW cdc_flow AS AUTO CDC INTO cdc_data FROM STREAM(source_data) KEYS (id) SEQUENCE BY ts APPLY AS DELETE WHEN is_deleted; SDPだと?
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
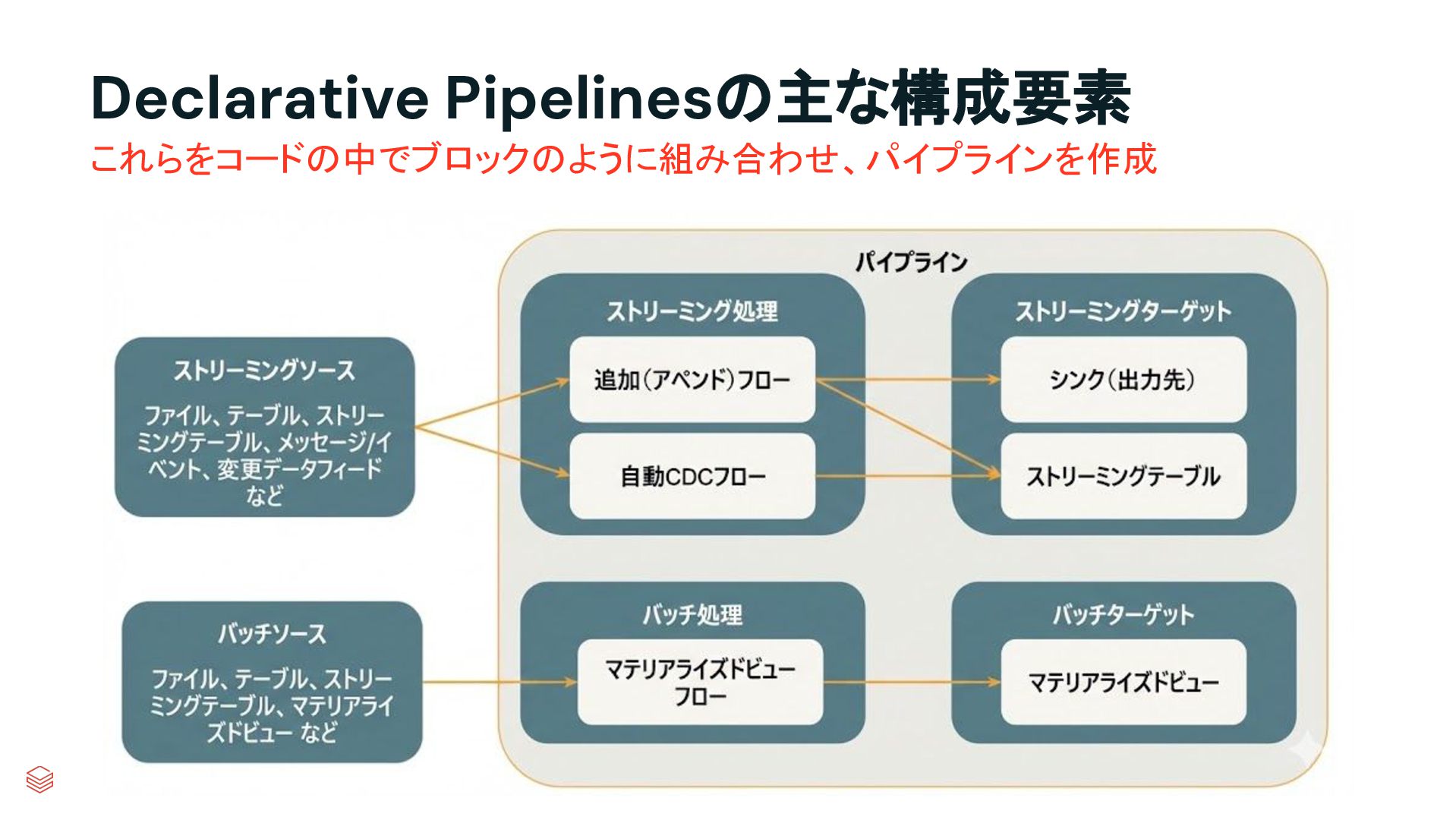{kind=link}
{kind=link}
{kind=link}
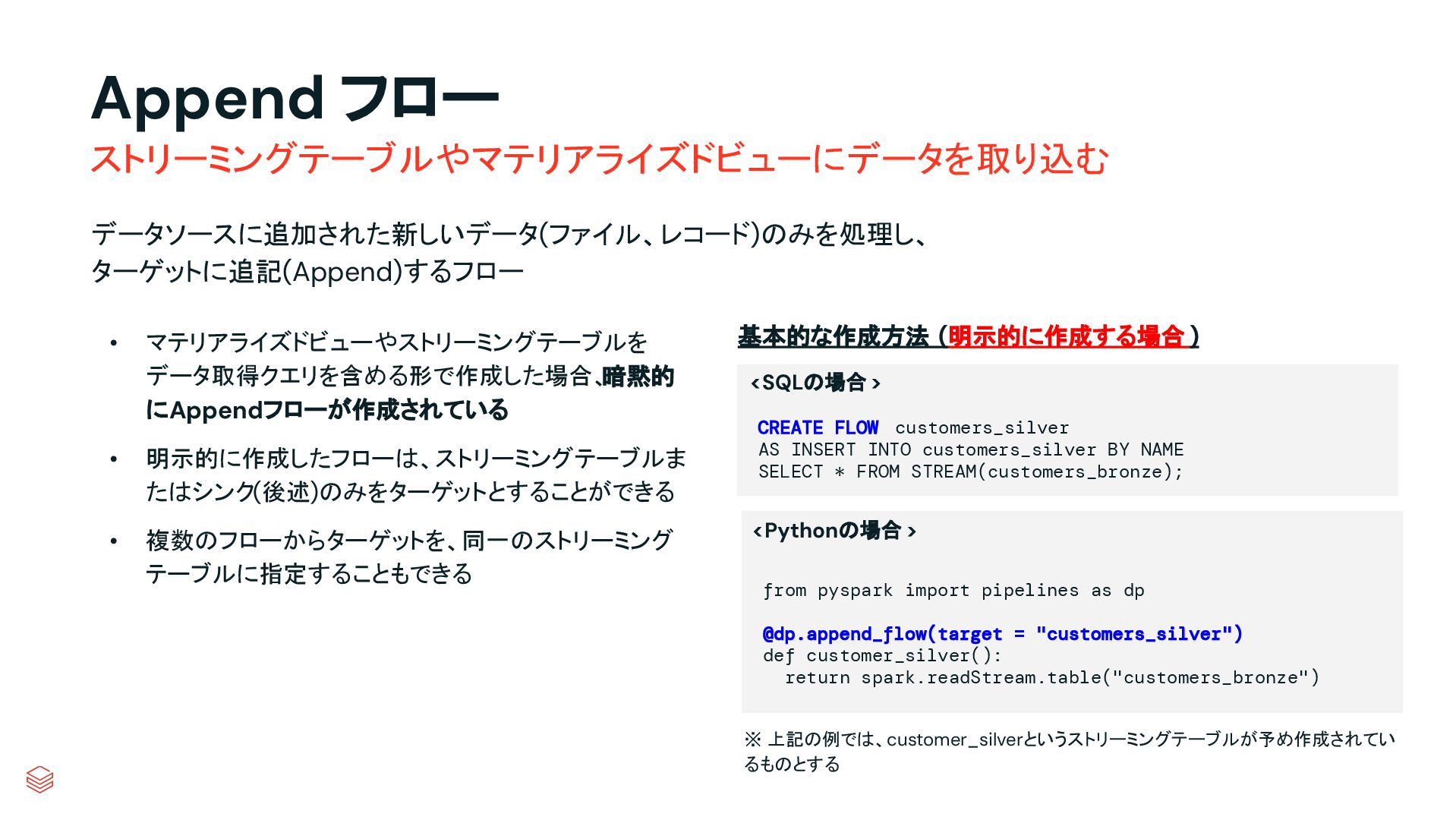{kind=link}
{kind=link}
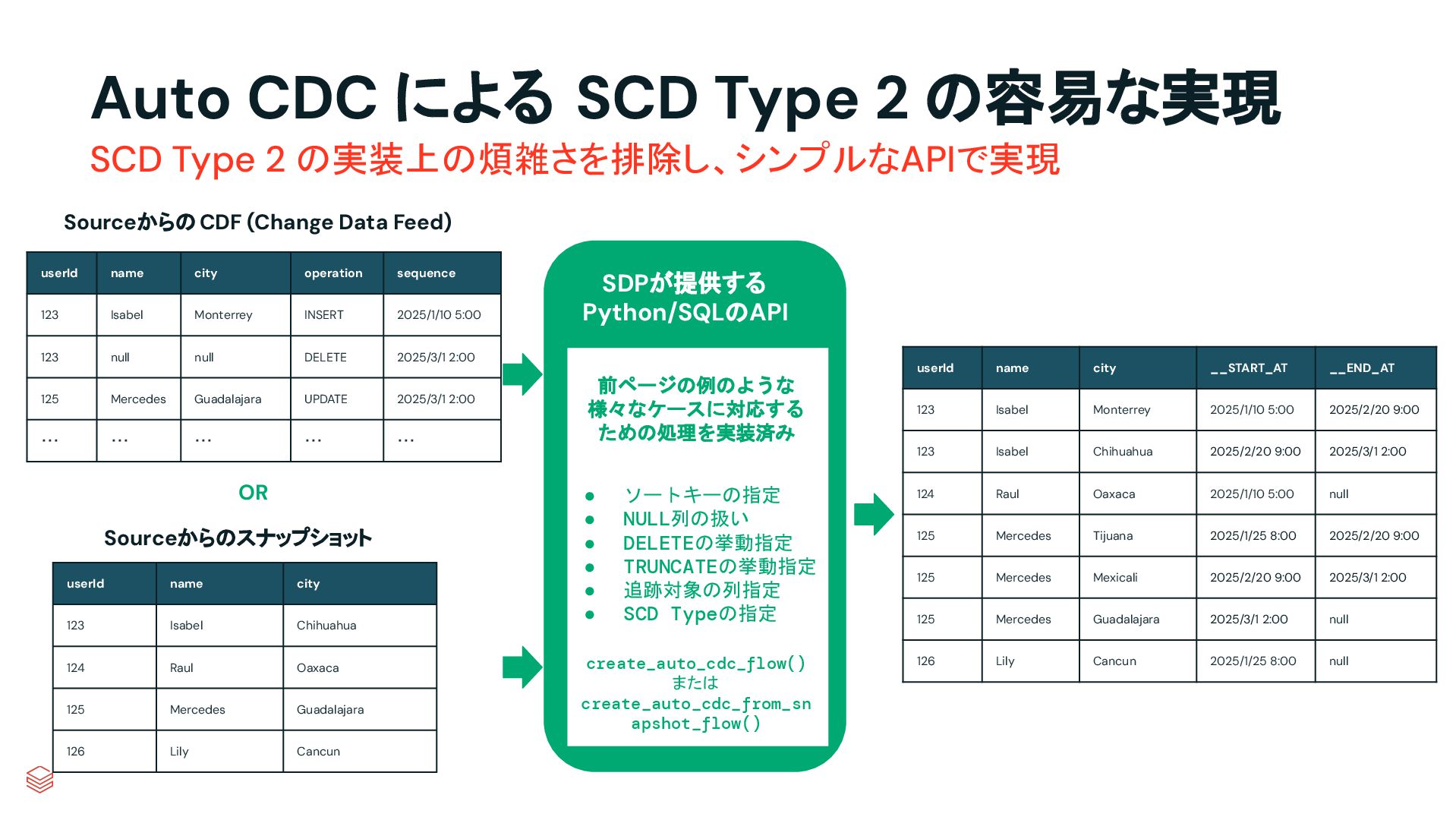{kind=link}
{kind=link}
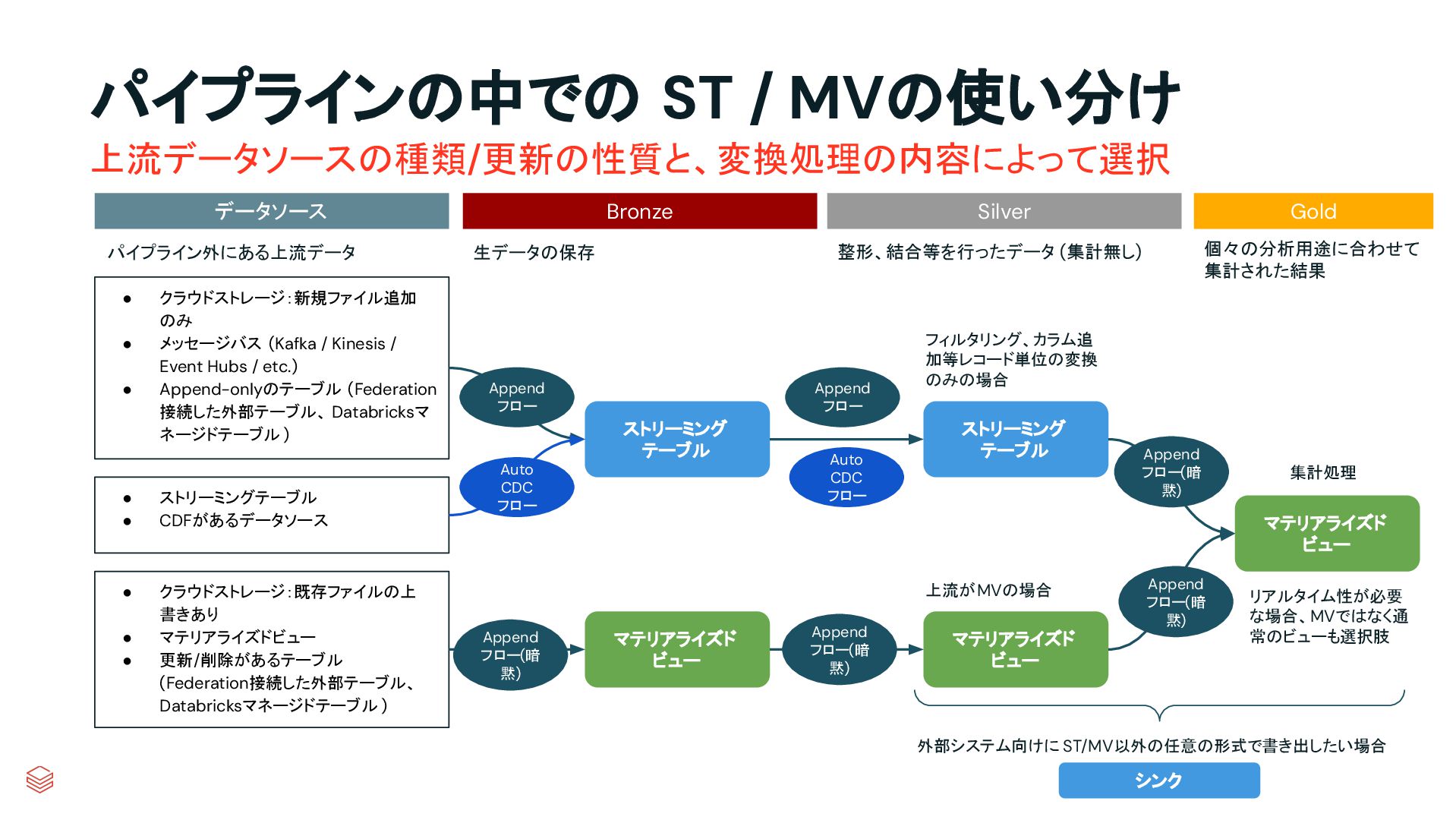{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}