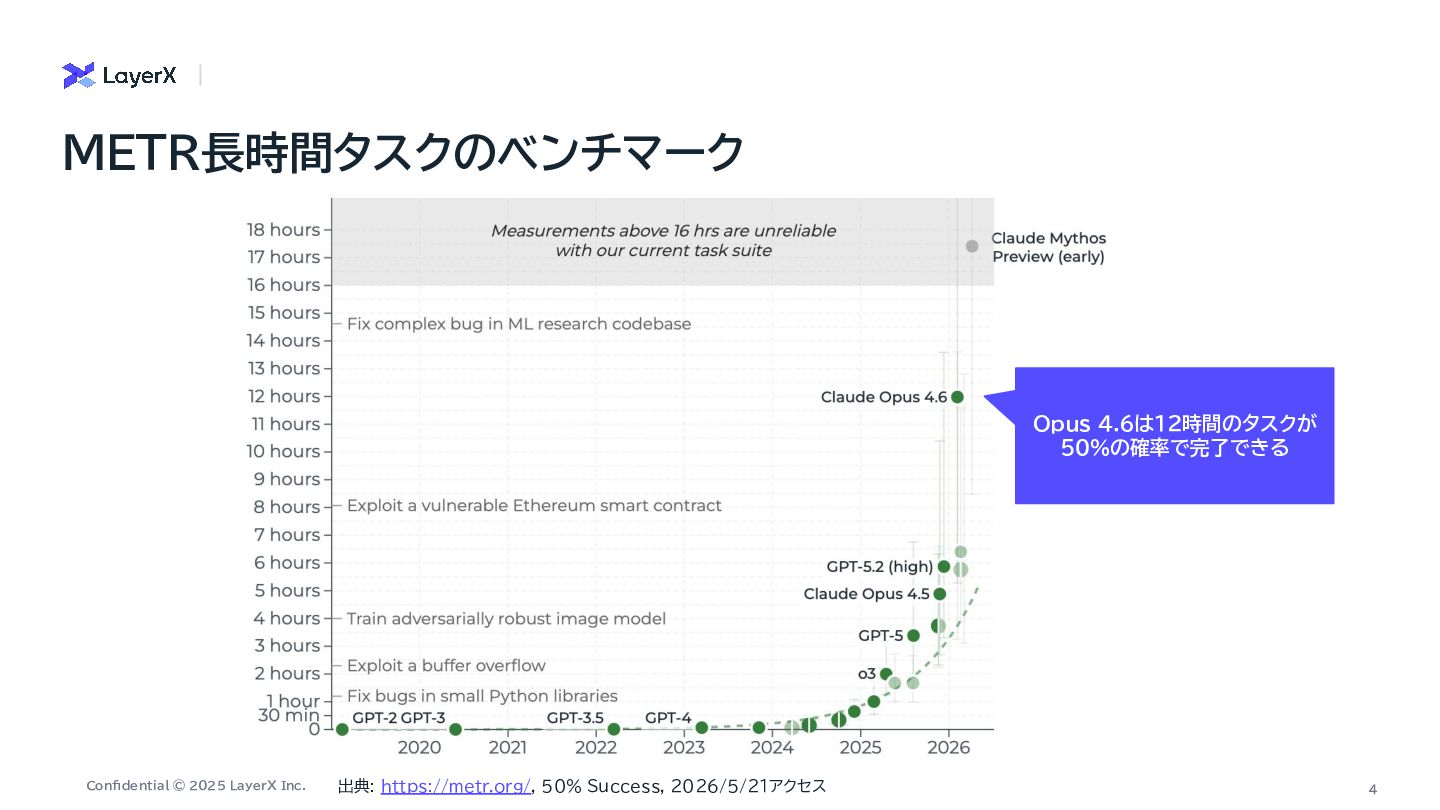
おもしろかった論文を紹介 Solving a Million-Step LLM Task with Zero Errors Elliot Meyerson et al. 2025/11 On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks Kaya Stechly et al. 2024/02 Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers Zhenting Qi et al. 2024/08
of Large Language Models on Reasoning and Planning Tasks 内容 • LLMによる自己批判と、信頼できる検証器によるフィードバックでLLMが再考すること の効果を検証 注意 • 対象モデルがGPT-4 Authors Kaya Stechly, Karthik Valmeekam, Subbarao Kambhampati published 2024/02
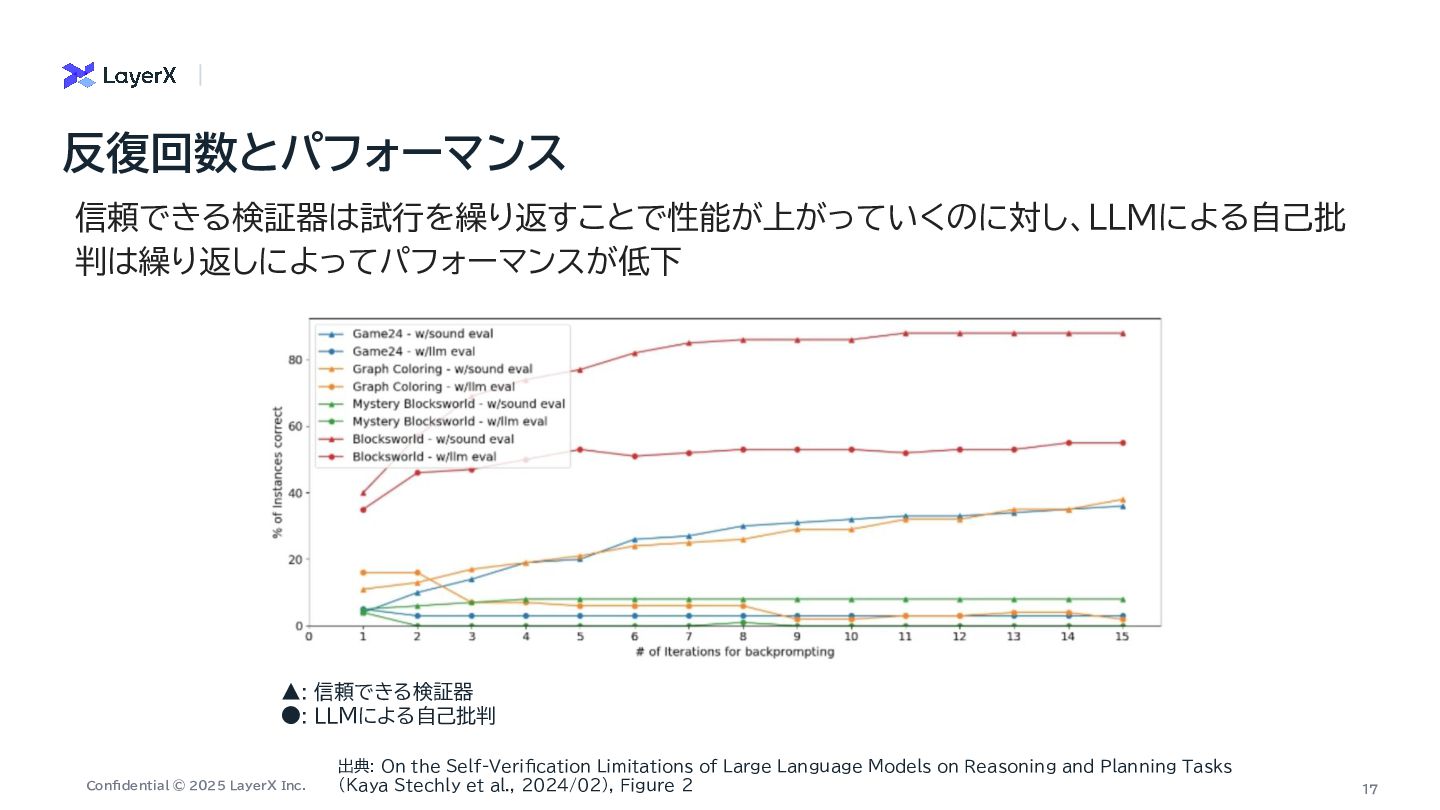
Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks (Kaya Stechly et al., 2024/02), Figure 2 ▲: 信頼できる検証器 •: LLMによる自己批判 信頼できる検証器は試行を繰り返すことで性能が上がっていくのに対し、LLMによる自己批 判は繰り返しによってパフォーマンスが低下
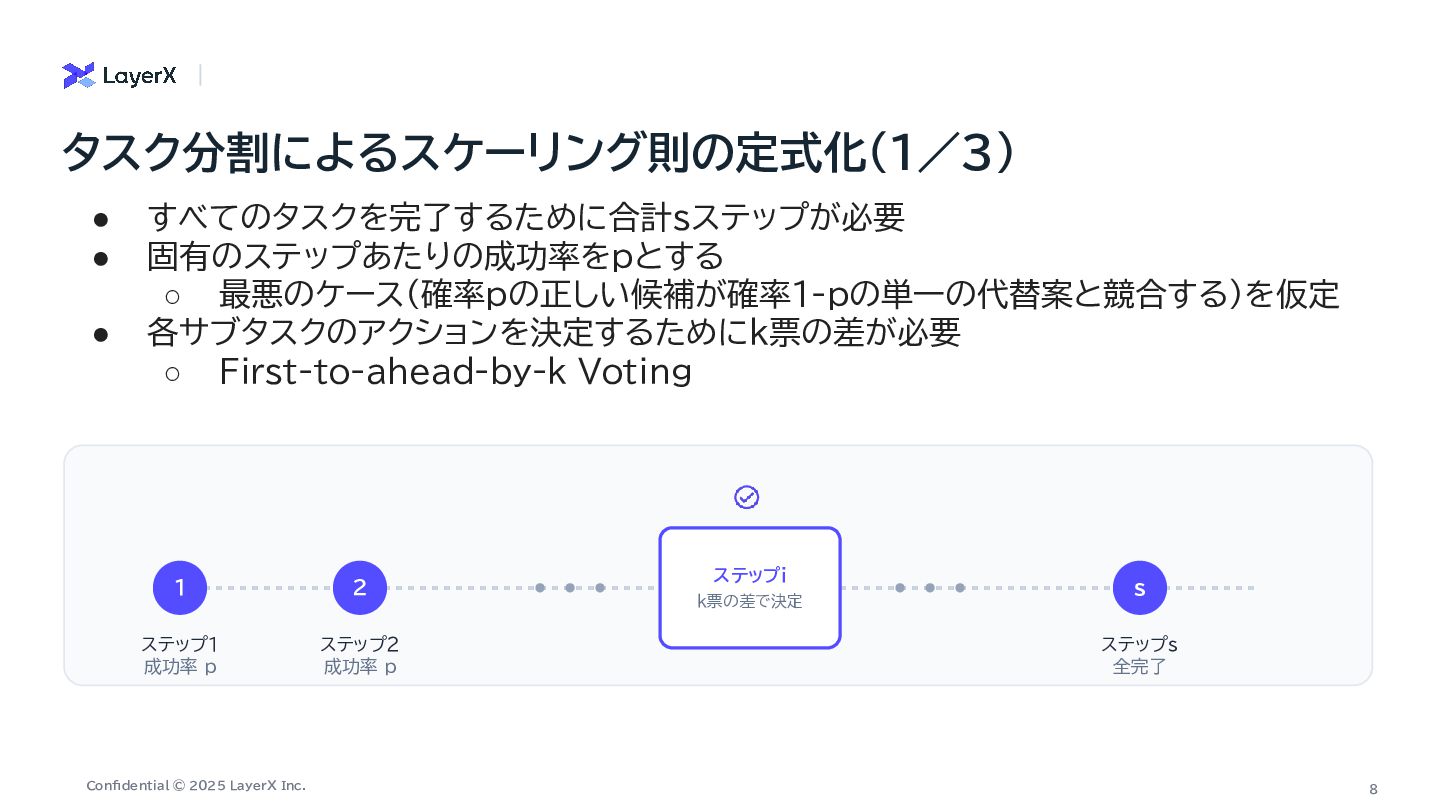
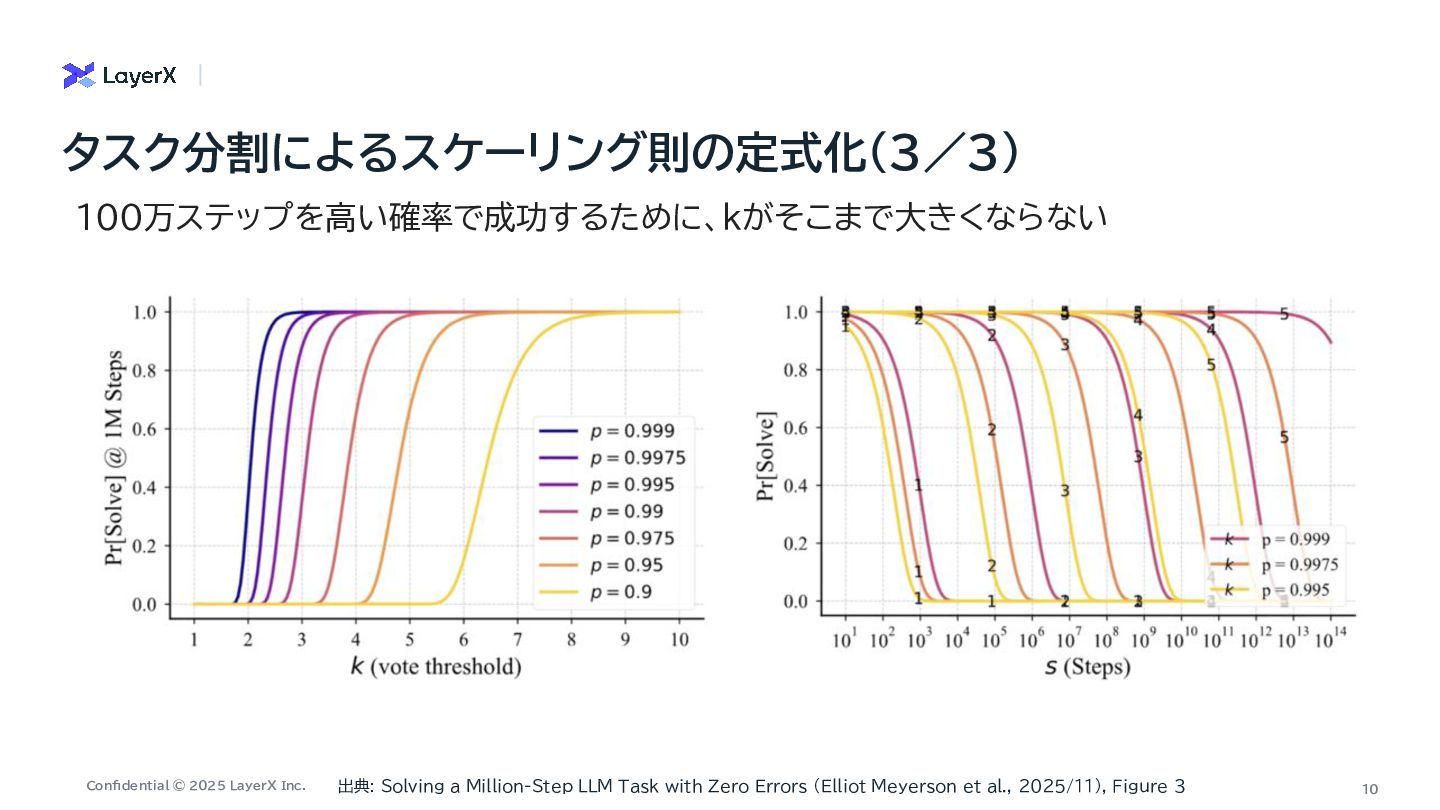
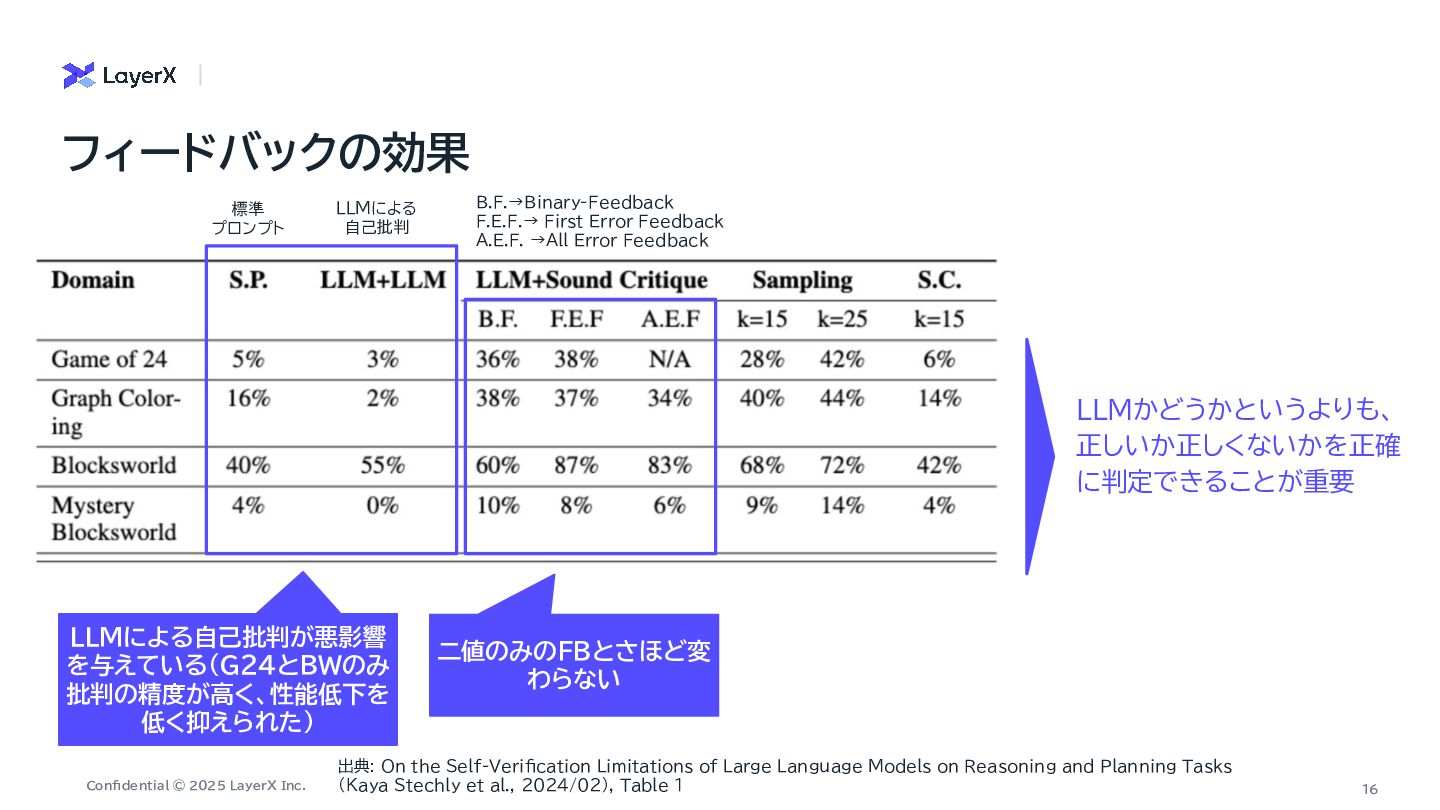
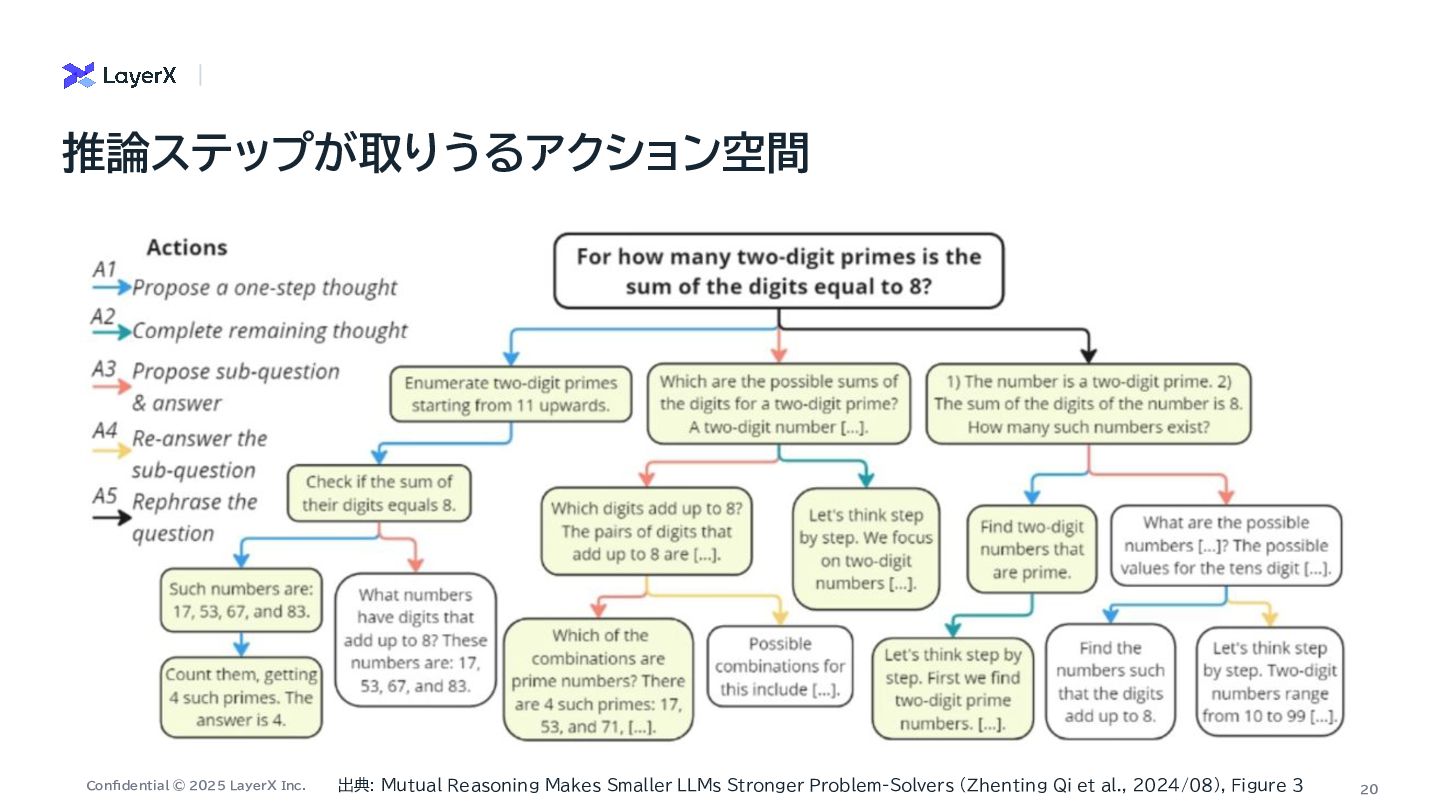
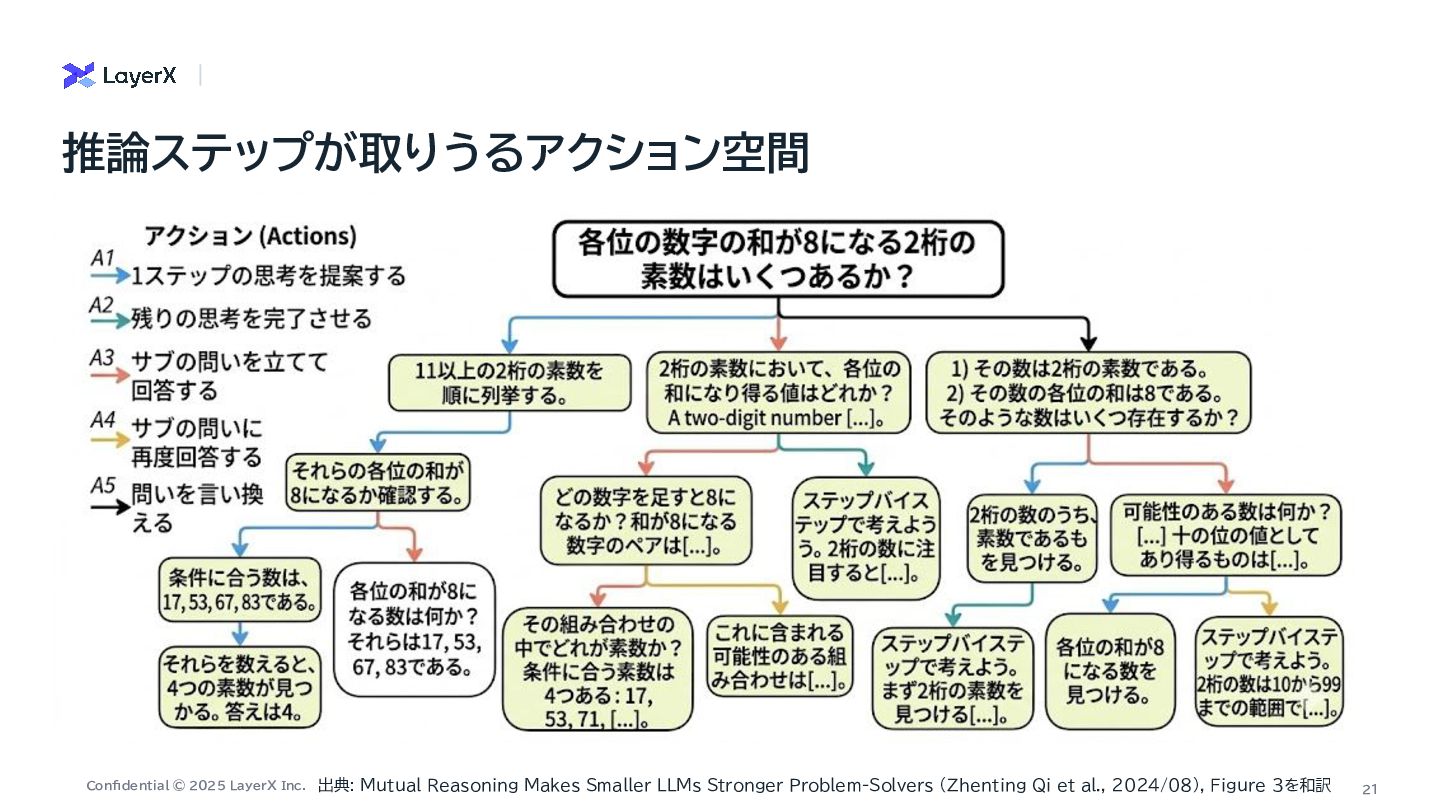
a Million-Step LLM Task with Zero Errors On the Self-Verification Limitations of Large Language Models on Reasoning and Planning Tasks Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers ・ First-to-ahead-by-k Voting のkは100万ステップでも1桁程度で 十分 ・LLM呼び出しコストも に スケール ・ 信頼性の低い兆候を使ったリトラ イ戦略 ・ 正しいか正しくないかを正確に判 定したフィードバックが重要 ・ エラーは全量であったり、詳細を出 すかもさほど二値フィードバックと変 わらない ・ フィードバックを繰り返す際にも正 確に判定できることが大事 ・ 複数のSLMが別の軌跡で導いた 回答が一致するのであれば、正解の 可能性が高いという直感を反映した 手法
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}