into computational costs in different scenarios. Moreover, the best measure of an algorithm is its cost in term of time/computation in the worst case scenario. Computer science has developed a shorthand specifically for measuring algorithmic worst-case scenarios: it’s called “Big-O” notation. Big-O notation has a particular quirk, which is that it’s inexact by design. That is, rather than expressing an algorithm’s performance in minutes and seconds, Big-O notation provides a way to talk about the kind of relationship that holds between the size of the problem and the program’s running time.
a dinner party with n guests. The time required to clean the house for their arrival doesn’t depend on the number of guests at all. We can refer to this problem as O(1) complexity. Now, the time required to pass the roast around the table will be “Big-O of n,” written O(n), also known as “linear time”. What if, as the guests arrived, each one hugged the others in greeting? Your first guest hugs you; your second guest has two hugs to give; your third guest, three. How many hugs will there be in total? This turns out to be “Big-O of n-squared,” written O(n^2).
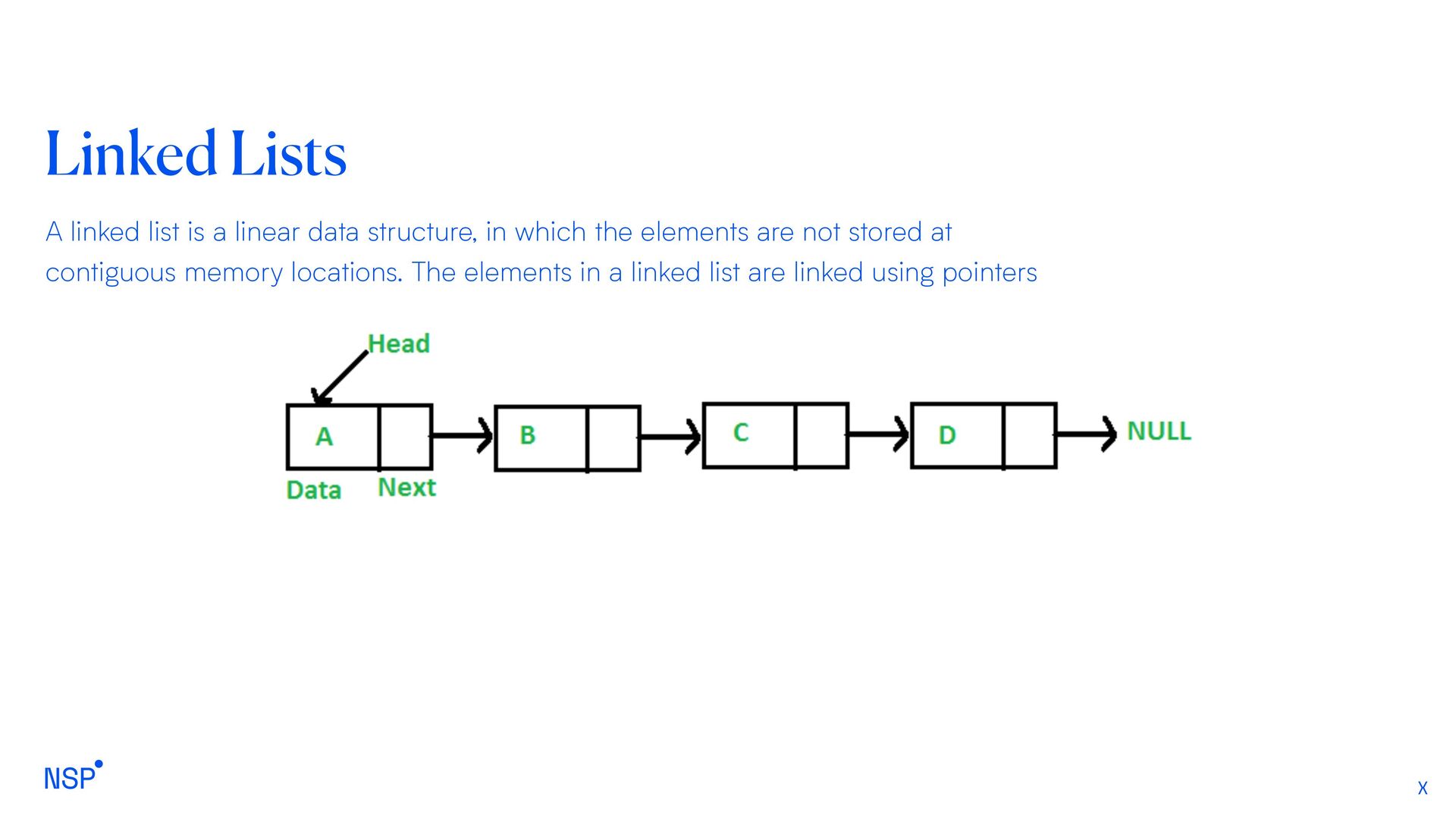
next images are linked, hence can be accessed by next and previous button. Previous and next page in web browser – We can access previous and next url searched in web browser by pressing back and next button since, they are linked as linked list. Music Player – Songs in music player are linked to previous and next song. you can play songs either from starting or ending of the list.
implement a list of operations to be followed in any direction (forward or backward) Most recently used – LinkedLists can be used to store most used functions or items within a website Jobs or Task Scheduling – First-Come-First-Served, Round Robin or other CPU job scheduling.
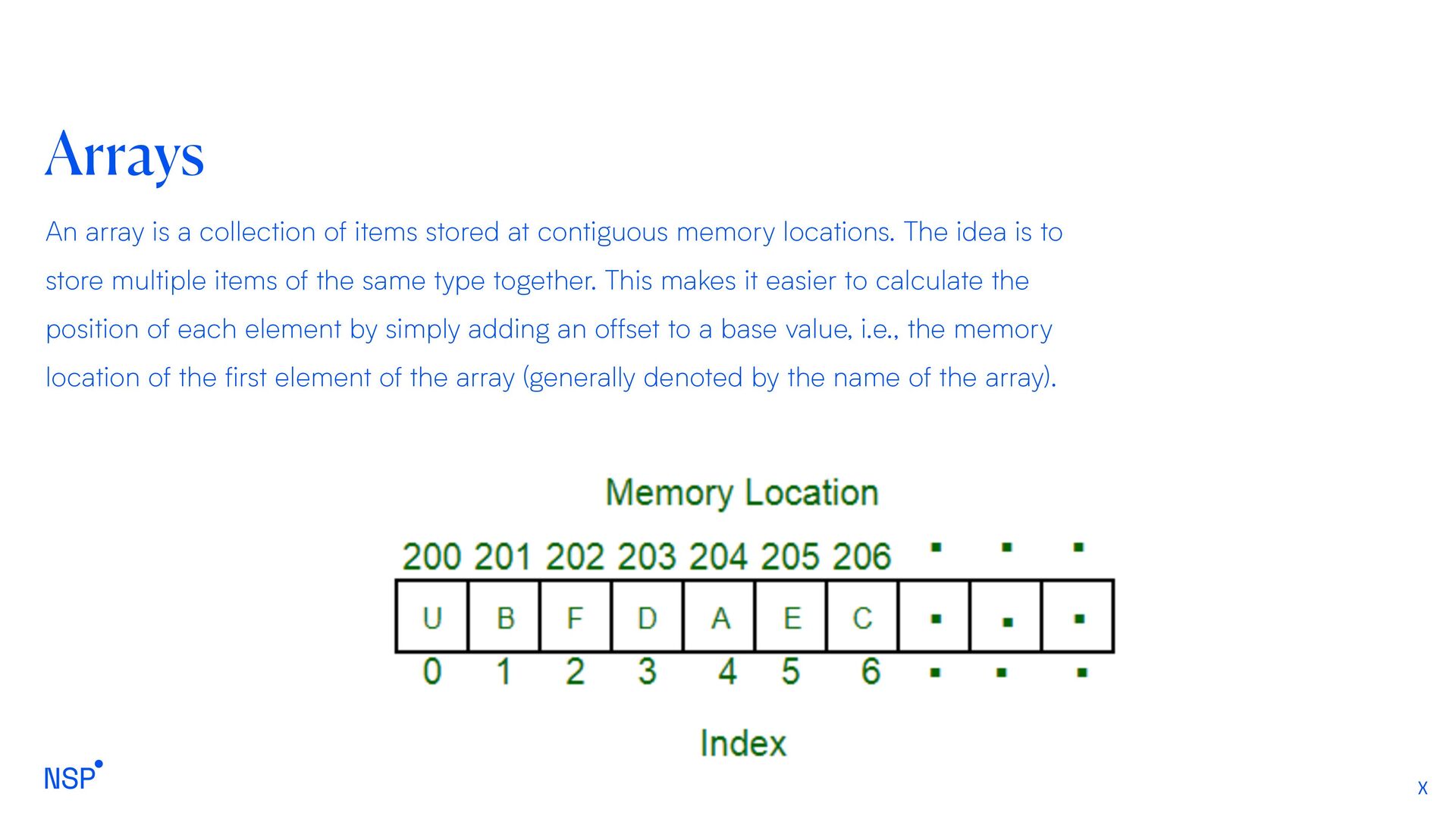
at contiguous memory locations. The idea is to store multiple items of the same type together. This makes it easier to calculate the position of each element by simply adding an offset to a base value, i.e., the memory location of the first element of the array (generally denoted by the name of the array).
Given a limited range array of size n containing elements between 1 and n-1 with one element repeating, find the duplicate number in it without using any extra space.
A naive solution would be to consider every subarray of size k and check for duplicates in it. The time complexity of this solution is O(n.k2) since there can be n subarrays of size k, and each subarray might take O(k2) time for checking duplicates.
hashing in O(n) time and O(n) extra space. The idea is to traverse the array and store each element and its index in a map, i.e., (element, index) as (key, value) pairs in a map. If any element is already found present on the map, check if that element repeats within the range of k using its previous occurrence information from the map.
so as to access them easily in later times. We apply sorting in our day to day life either knowingly or unknowingly in several instances. Our telephone directories, English Dictionaries are some examples in which names or words are arranged in alphabetical order. Ranks based on the scores is another common example. What is the advantage we can have from sorting the things. The biggest advantage is search and retrieval can happen much faster. Sorting is one fundamental operation done in computer databases.
do the laundry, then recovert a pair of socks. The naive approach is to pull a sock out of the clean laundry hamper, then a second sock, compare to find a match, and if it isn’t the right one, throw that back into the laundry and pull a new sock. With just 10 different pairs of socks, following this method will take on average 19 pulls merely to complete the first pair, and 17 more pulls to complete the second. In total, you can expect to go fishing in the hamper 110 times just to pair 20 socks.
to pair them, you first need to sort them. Pairing socks without sorting: N*N/2 comparisons Pairing socks after sorting: 0 comparisons. just taking every i*2 and i*2+1 sock together Do radix-sort with these as digits: • color • pattern of colors if exists • texture (cotton, silk, etc) • numbers • size Also eliminate any pairs found while in sorting phase.
for a “stored program” computer was a program for efficient sorting. By the 1960s, one study estimated that more than a quarter of the computing resources of the world were being spent on sorting. With sorting size does matter: complexity and computational costs grow with list size.
more efficient and hence faster. It does this by storing computation results in cache, and retrieving that same information from the cache the next time it's needed instead of computing it again. Memoization is a type of dynamic programming, since the results are not computed every time, but stored for subsequent usages.
we can use to display the first factorials up to n. The factorial is defined for an integer n, such that it is the product of that integer and all integers below it • 1! = 1, • 2! = 2*1= 2 • 3! = 3*2*1 = 6 Computing 10! is pretty neat. What about computing 5000! ?
find the shortest path between source and the series of destinations (one by one) out of the various available paths. • In networking to transfer data from a sender to various receivers in a sequential manner. • Document Distance Algorithms- to identify the extent of similarity between two text documents used by Search engines like Google, Wikipedia, Quora, and other websites • Edit distance algorithm used in spell checkers.
in memory: through dedicated cache tiers storing data to avoid DB access, web servers store common data like configuration that can be used across requests. Then multiple levels of caching in code abstractions within every single request that prevents fetching the same data multiple times and save CPU cycles by avoiding recomputation. Finally, caches within your browser or mobile phones that keep the data that doesn't need to be fetched from the server every time. • Git merge. Document diffing is one of the most prominent uses of LCS. • Dynamic programming is used in TeX's system of calculating the right amounts of hyphenations and justifications. • Genetic algorithms.
that is inspired by Charles Darwin’s theory of natural evolution. This algorithm reflects the process of natural selection where the fittest individuals are selected for reproduction in order to produce offspring of the next generation.
individuals which is called a Population. Each individual is a solution to the problem you want to solve. An individual is characterized by a set of parameters (variables) known as Genes. Genes are joined into a string to form a Chromosome (solution). In a genetic algorithm, the set of genes of an individual is represented using a string, in terms of an alphabet. Usually, binary values are used (string of 1s and 0s). We say that we encode the genes in a chromosome. The fitness function determines how fit an individual is (the ability of an individual to compete with other individuals). It gives a fitness score to each individual. The probability that an individual will be selected for reproduction is based on its fitness score. The idea of selection phase is to select the fittest individuals and let them pass their genes to the next generation.
trading systems in the financial sector • Portfolio optimization (what-if scenarios) • Design of anti-terrorism systems (https://www.researchgate.net/publication/ 23657202_Reducing_Risk_Through_Real_Options_in_Systems_Design_The_Case_of_Architecting_a_Maritime_Domain_Protection_System) • Marketing mix analysis • Design of particle accelerator beamlines (https://www.sciencedirect.com/science/article/pii/S0168900218302158)
where the addition of new items happens at one end. Queues are fundamental structures in computer science because enable a number of applications: • Producer / Consumer producer workers push data into a queue, and consumers pull it out for processing. Producers and consumers are decoupled. • Fan-in / Fan-out strategies queues are used to change a system throughput and slow down its requirements • Line management the most basic usage of queue is to manage a line for a capped or shared resource (i.e. CPU, GPU, tickets, toilet access, …)
search trees (like AVL and Red-Black Trees), it is assumed that everything is in main memory. What can be done when we have a huge amount of data that cannot fit in main memory? Disk access time is very high compared to the main memory access time.
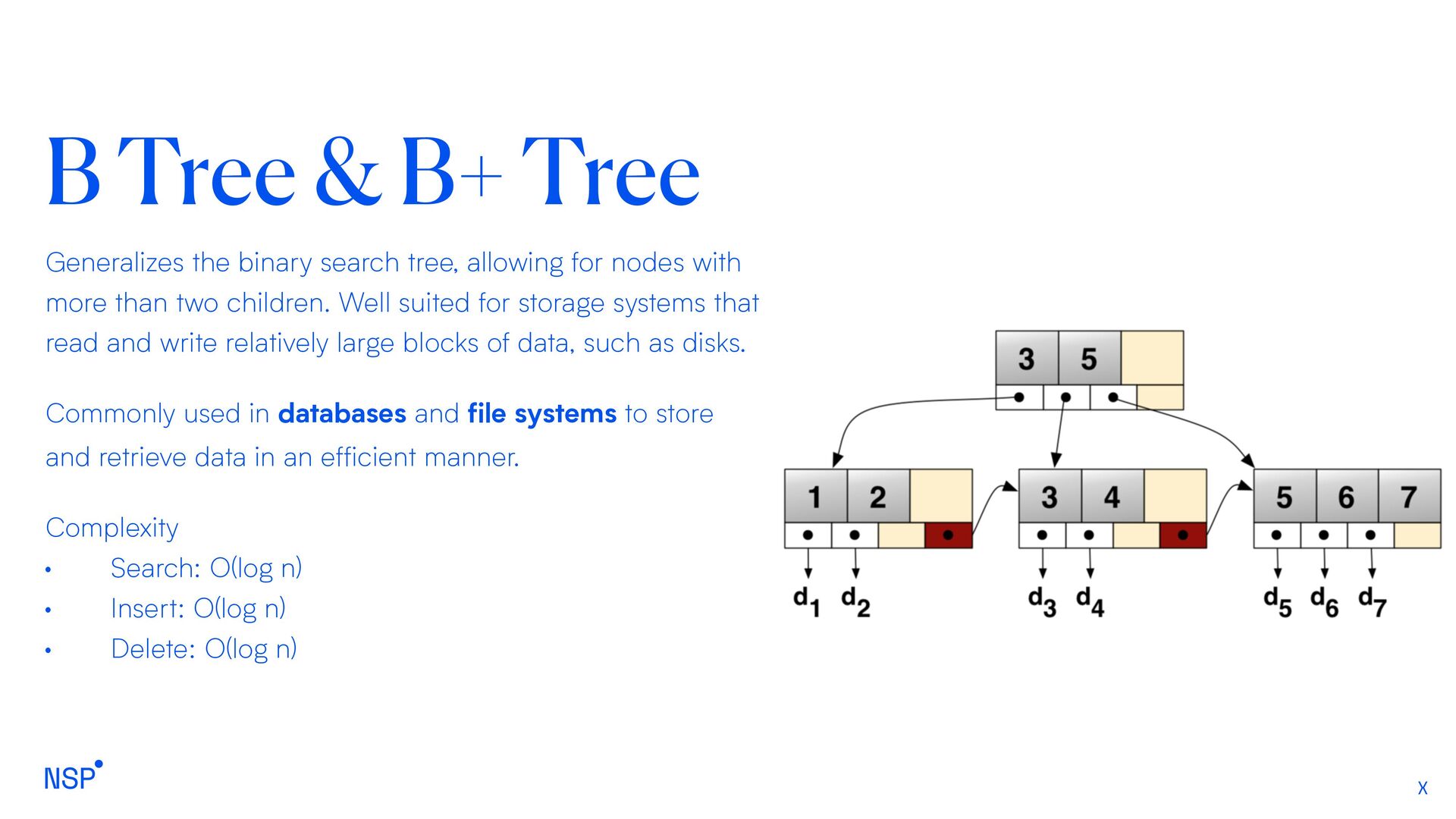
tree, allowing for nodes with more than two children. Well suited for storage systems that read and write relatively large blocks of data, such as disks. Commonly used in databases and file systems to store and retrieve data in an efficient manner. Complexity • Search: O(log n) • Insert: O(log n) • Delete: O(log n)
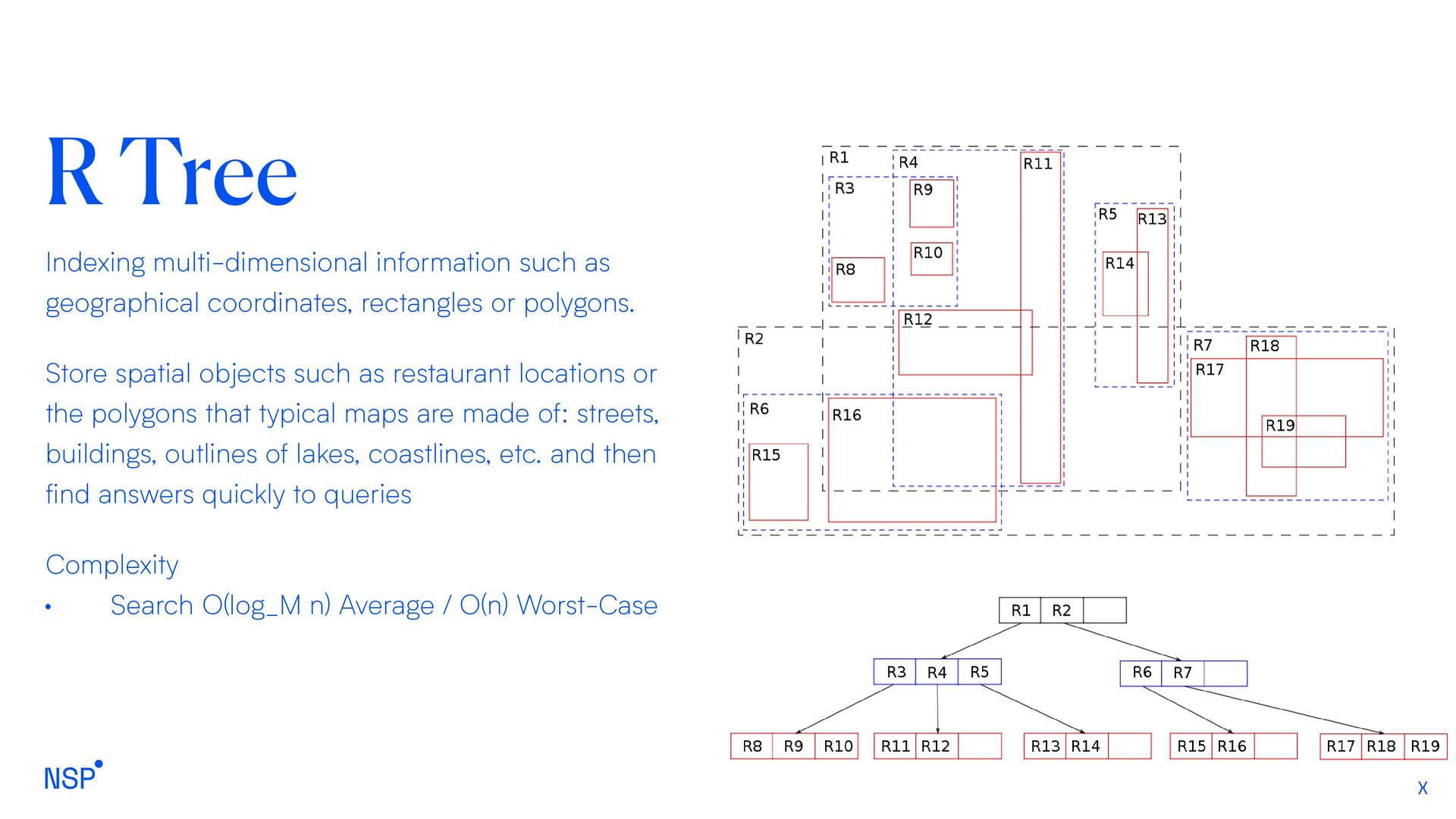
rectangles or polygons. Store spatial objects such as restaurant locations or the polygons that typical maps are made of: streets, buildings, outlines of lakes, coastlines, etc. and then find answers quickly to queries Complexity • Search O(log_M n) Average / O(n) Worst-Case
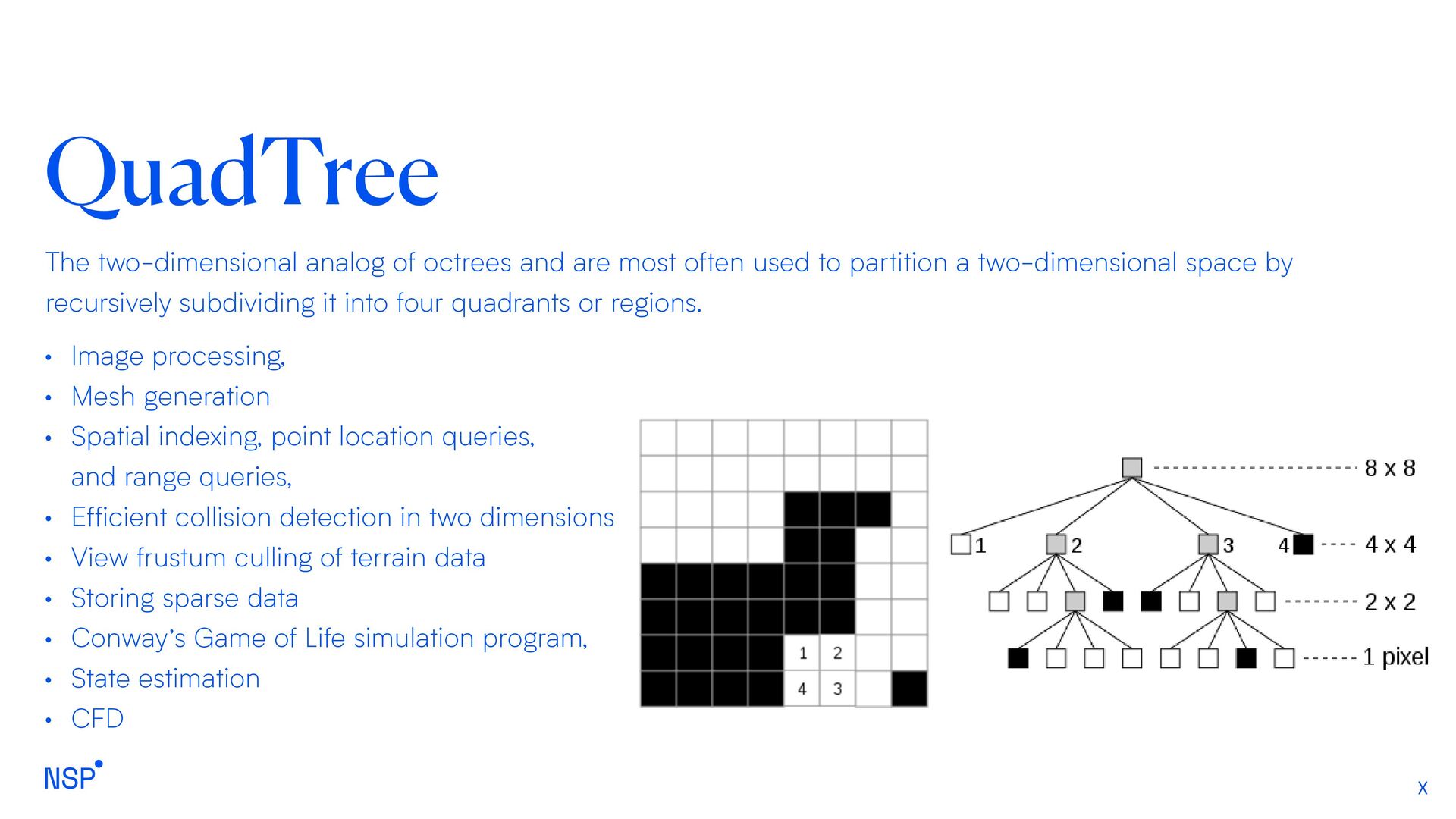
often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions. • Image processing, • Mesh generation • Spatial indexing, point location queries, and range queries, • Efficient collision detection in two dimensions • View frustum culling of terrain data • Storing sparse data • Conway’s Game of Life simulation program, • State estimation • CFD
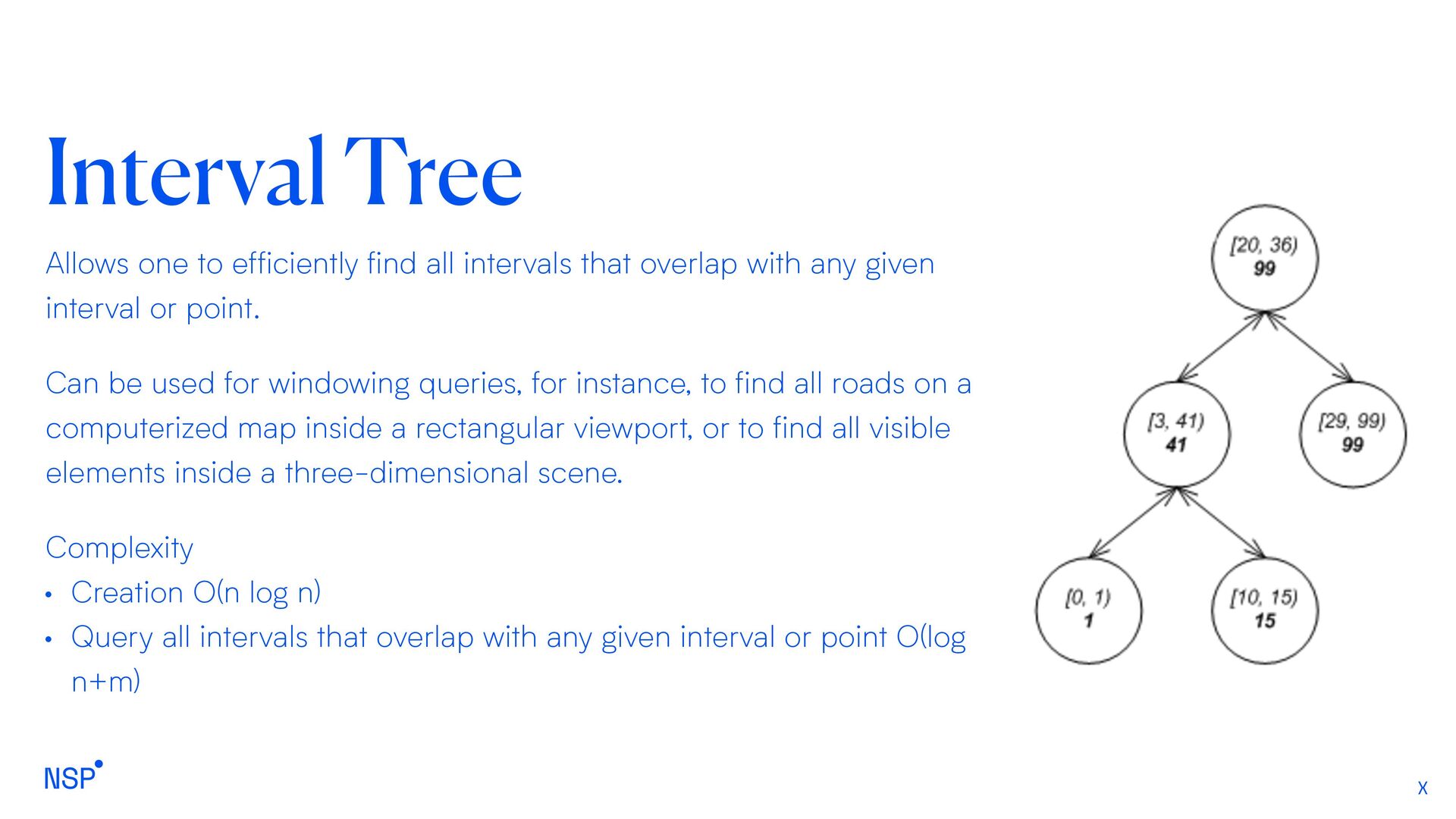
that overlap with any given interval or point. Can be used for windowing queries, for instance, to find all roads on a computerized map inside a rectangular viewport, or to find all visible elements inside a three-dimensional scene. Complexity • Creation O(n log n) • Query all intervals that overlap with any given interval or point O(log n+m)
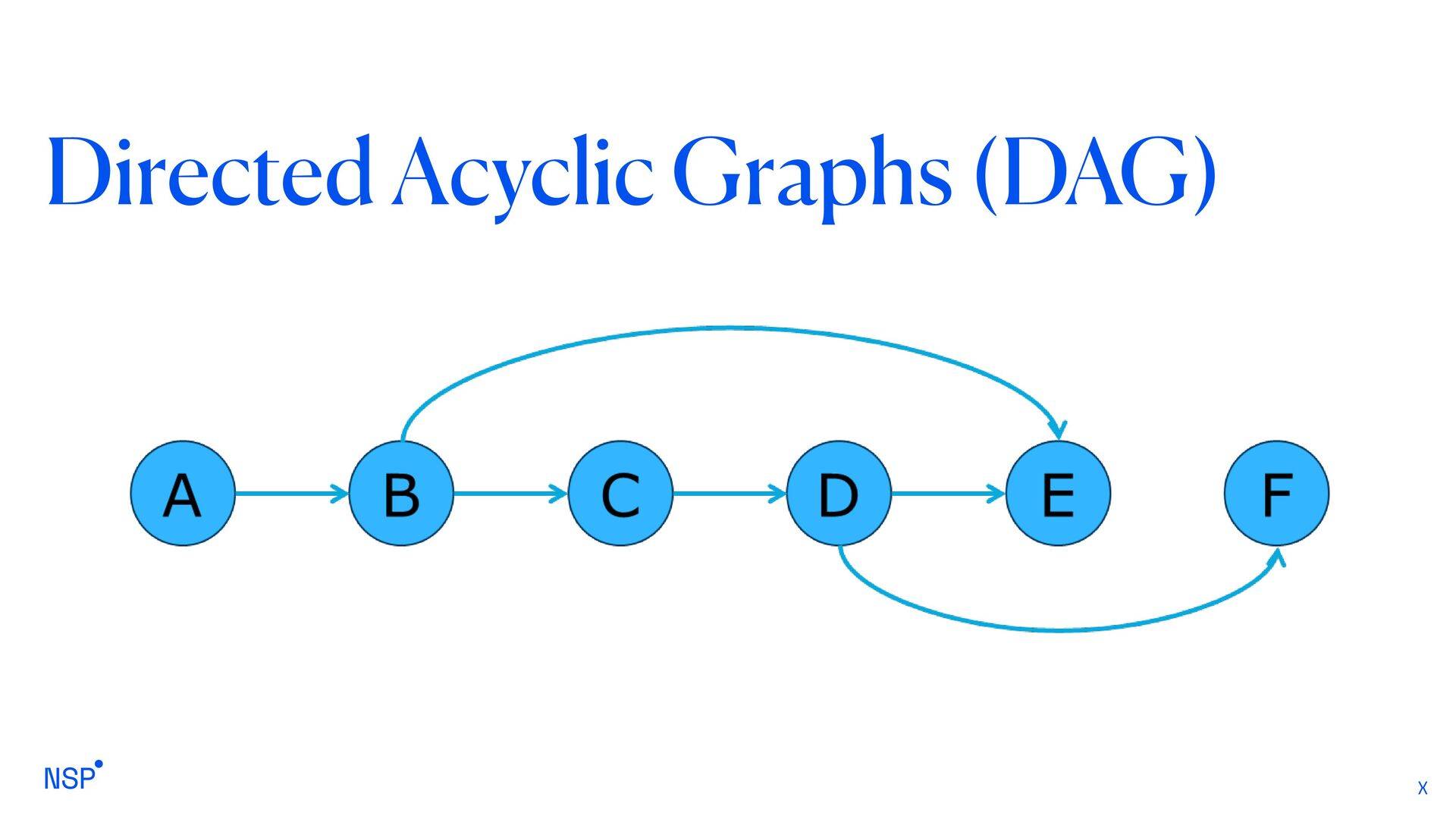
a graph that has cycles: moving from a node to the others you’ll find yourself back to the starting node. • A directed graph is made up of a set of vertices connected by directed edges often called arcs • A directed acyclic graph (DAG) is a directed graph with no directed cycles. • That is, it consists of vertices and edges (also called arcs), with each edge directed from one vertex to another, • Such that following those directions will never form a closed loop. • A directed graph is a DAG if and only if it can be topologically ordered, by arranging the vertices as a linear ordering that is consistent with all edge directions.
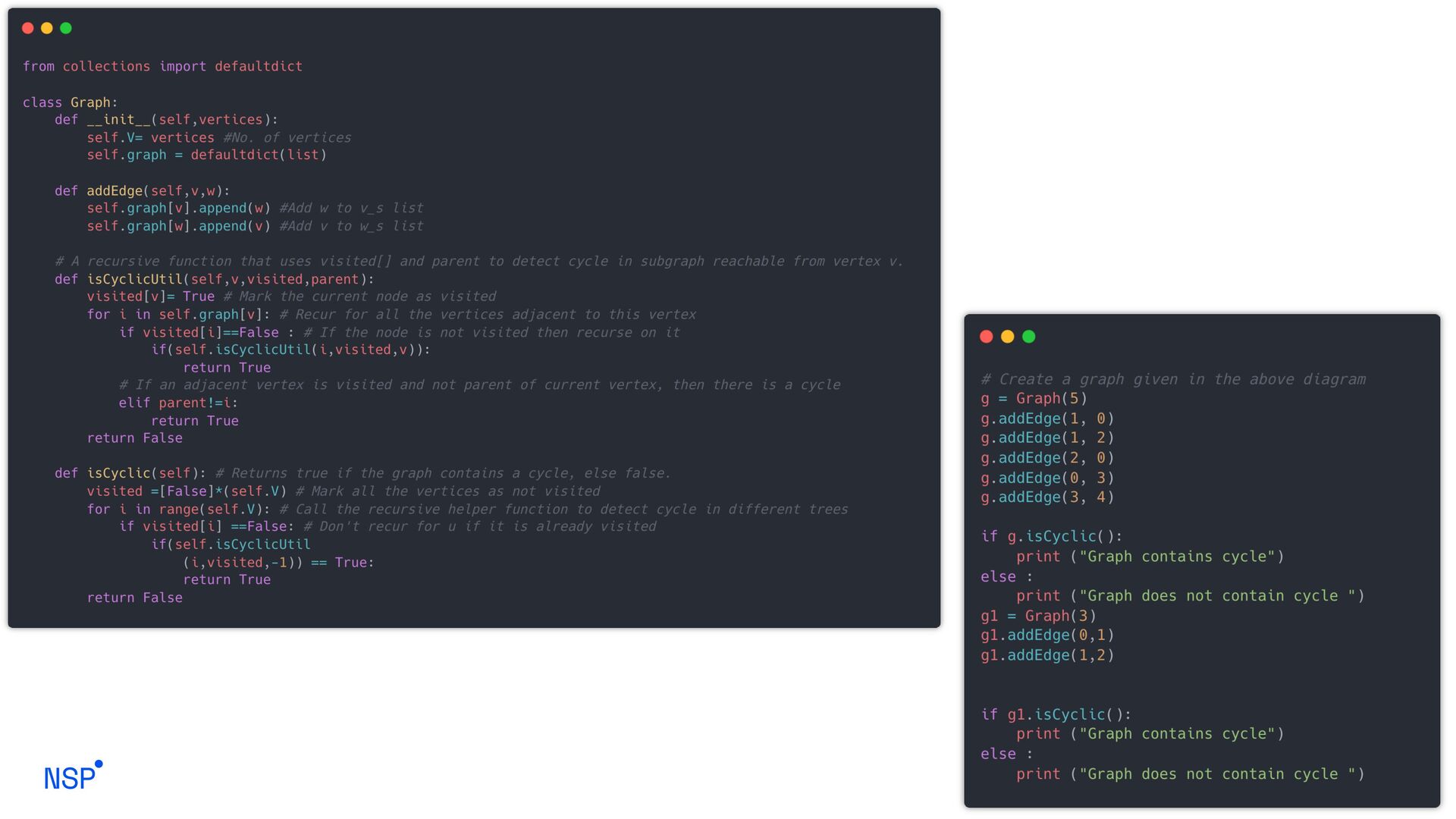
can be used to detect a cycle in a Graph. DFS for a connected graph produces a tree. There is a cycle in a graph only if there is a back edge present in the graph. A back edge is an edge that is joining a node to itself (self- loop) or one of its ancestor in the tree produced by DFS. To find the back edge to any of its ancestors keep a visited array and if there is a back edge to any visited node then there is a loop and return true.
the given number of edges and vertices. 2. Create a recursive function that have current index or vertex, visited array and parent node. 3. Mark the current node as visited . 4. Find all the vertices which are not visited and are adjacent to the current node. Recursively call the function for those vertices, If the recursive function returns true return true. 5. If the adjacent node is not parent and already visited then return true. 6. Create a wrapper class, that calls the recursive function for all the vertices and if any function returns true, return true. 7. Else if for all vertices the function returns false return false.
graph in which it is not possible to find at least one cyclic path. a DAG is a graph in which all the edges are directed, such that it is impossible to find a node and follow a sequence of edges that eventually loops back to the same node
is that they have what is known as a “topological ordering”, which means that the nodes of a DAG can be put into a linear sequence with the nodes given an “ordering”, specifically nodes at the beginning of the sequence have a “lower value” than nodes at the end of the sequence. This topological ordering property, as well as other key properties, make DAGs very efficient at a number of tasks (such as finding the shortest path from one node to another) and are the reason DAGs have a wide range of use-cases.
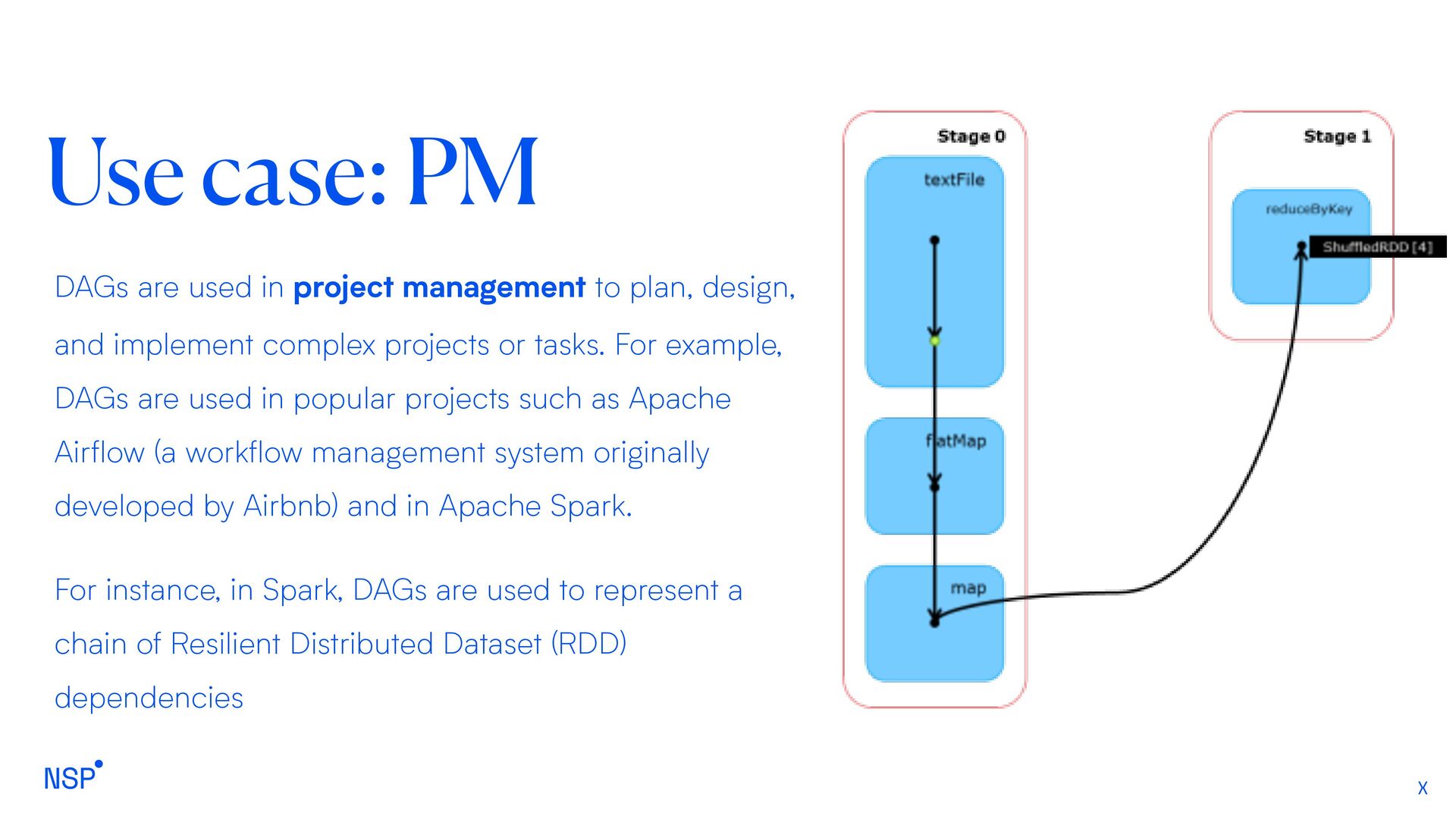
to plan, design, and implement complex projects or tasks. For example, DAGs are used in popular projects such as Apache Airflow (a workflow management system originally developed by Airbnb) and in Apache Spark. For instance, in Spark, DAGs are used to represent a chain of Resilient Distributed Dataset (RDD) dependencies
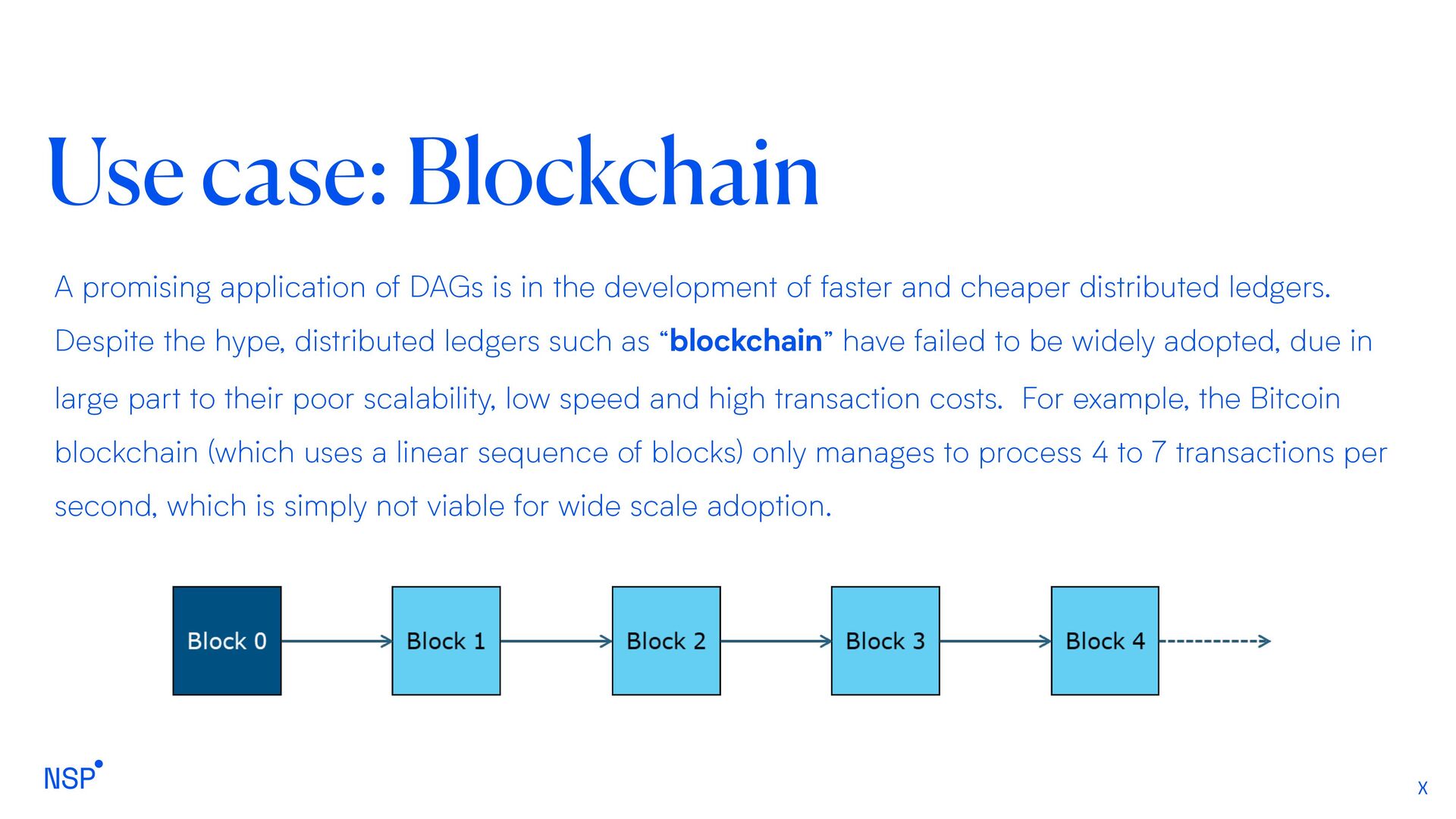
in the development of faster and cheaper distributed ledgers. Despite the hype, distributed ledgers such as “blockchain” have failed to be widely adopted, due in large part to their poor scalability, low speed and high transaction costs. For example, the Bitcoin blockchain (which uses a linear sequence of blocks) only manages to process 4 to 7 transactions per second, which is simply not viable for wide scale adoption.
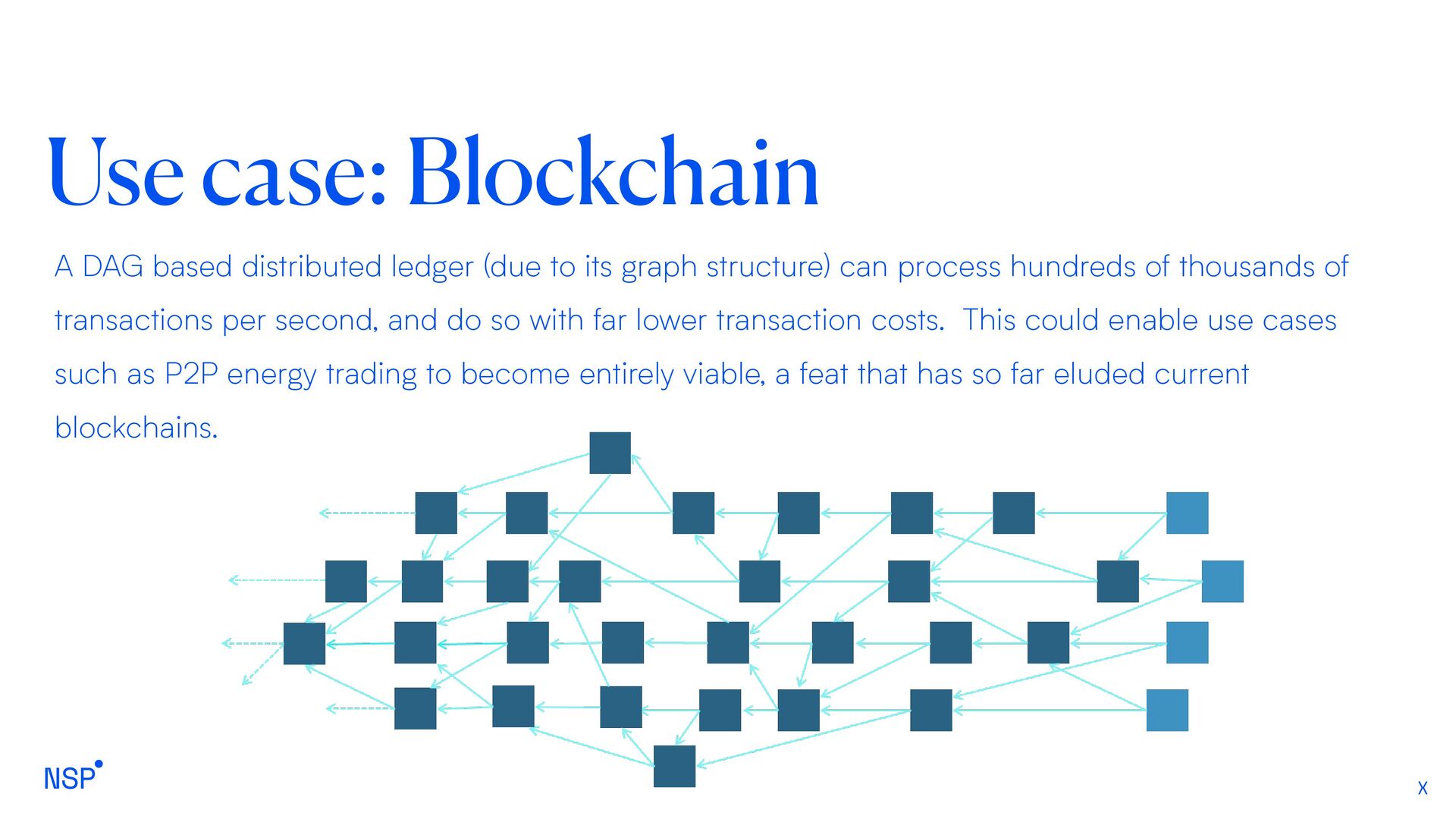
to its graph structure) can process hundreds of thousands of transactions per second, and do so with far lower transaction costs. This could enable use cases such as P2P energy trading to become entirely viable, a feat that has so far eluded current blockchains.
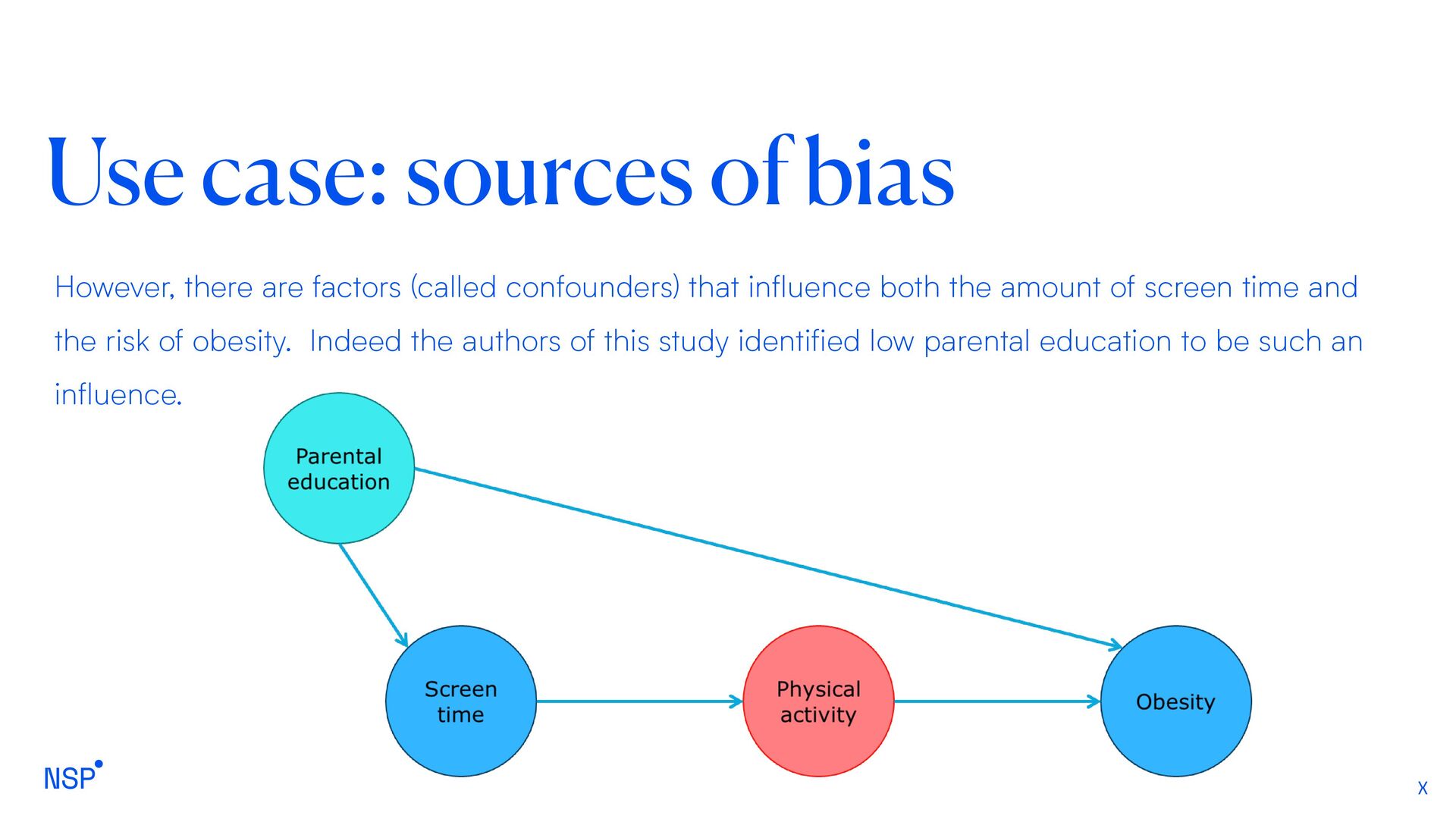
to identify confounding and sources of bias, which is particularly important in medical and clinical studies. For example, consider a clinical study with the objective of identifying the relationships between “screen time” and “childhood obesity”. It might seem reasonable to hypothesize that more screen time may lead to an increased risk of childhood obesity
to identify confounding and sources of bias, which is particularly important in medical and clinical studies. For example, consider a clinical study with the objective of identifying the relationships between “screen time” and “childhood obesity”. It might seem reasonable to hypothesize that more screen time may lead to an increased risk of childhood obesity
probably doesn’t cause obesity directly – it is more likely there is an intermediate process (being a reduction in physical activity) that is responsible for weight gain.
(called confounders) that influence both the amount of screen time and the risk of obesity. Indeed the authors of this study identified low parental education to be such an influence.
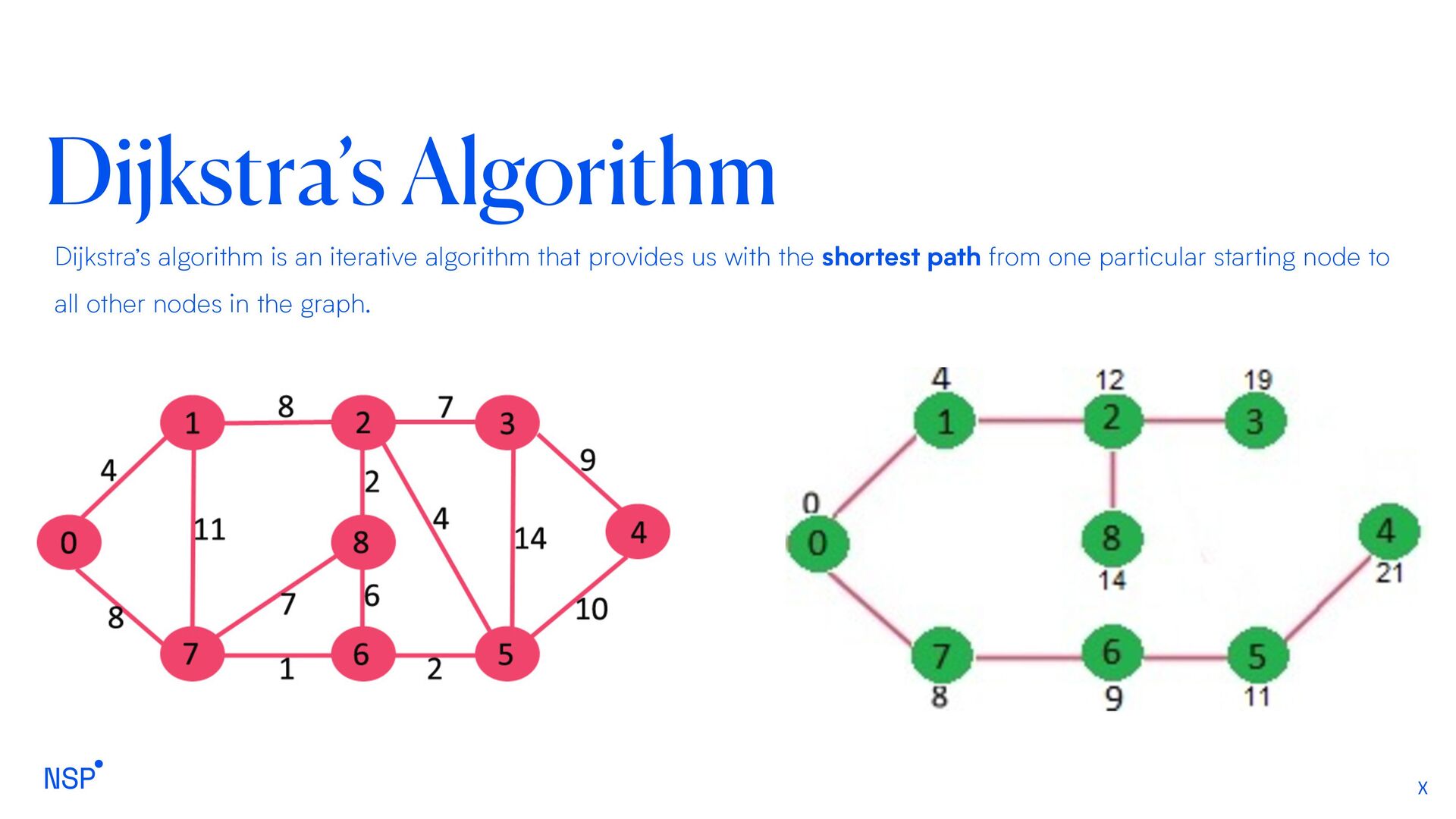
a best-first search, meaning that it is formulated in terms of weighted graphs: starting from a specific starting node of a graph, it aims to find a path to the given goal node having the smallest cost (least distance travelled, shortest time, etc.). It does this by maintaining a tree of paths originating at the start node and extending those paths one edge at a time until its termination criterion is satisfied. Compared to Dijkstra's algorithm, the A* algorithm only finds the shortest path from a specified source to a specified goal, and not the shortest-path tree from a specified source to all possible goals
without being aware of it. For example, when you search for words in a dictionary, you don’t review all the words; you just check one word in the middle and thus narrow down the set of remaining words to check. A Self-Balancing Binary Search Tree is used to maintain sorted stream of data. For example, suppose we are getting online orders placed and we want to maintain the live data (in RAM) in sorted order of prices. For example, we wish to know number of items purchased at cost below a given cost at any moment. Or we wish to know number of items purchased at higher cost than given cost.
within an image, track them across many different frames, and segment pixels into meaningful areas. Leverages the following algorithms: • unique detection —> hashing • tracking —> dynamic programming • segmentation —> trees
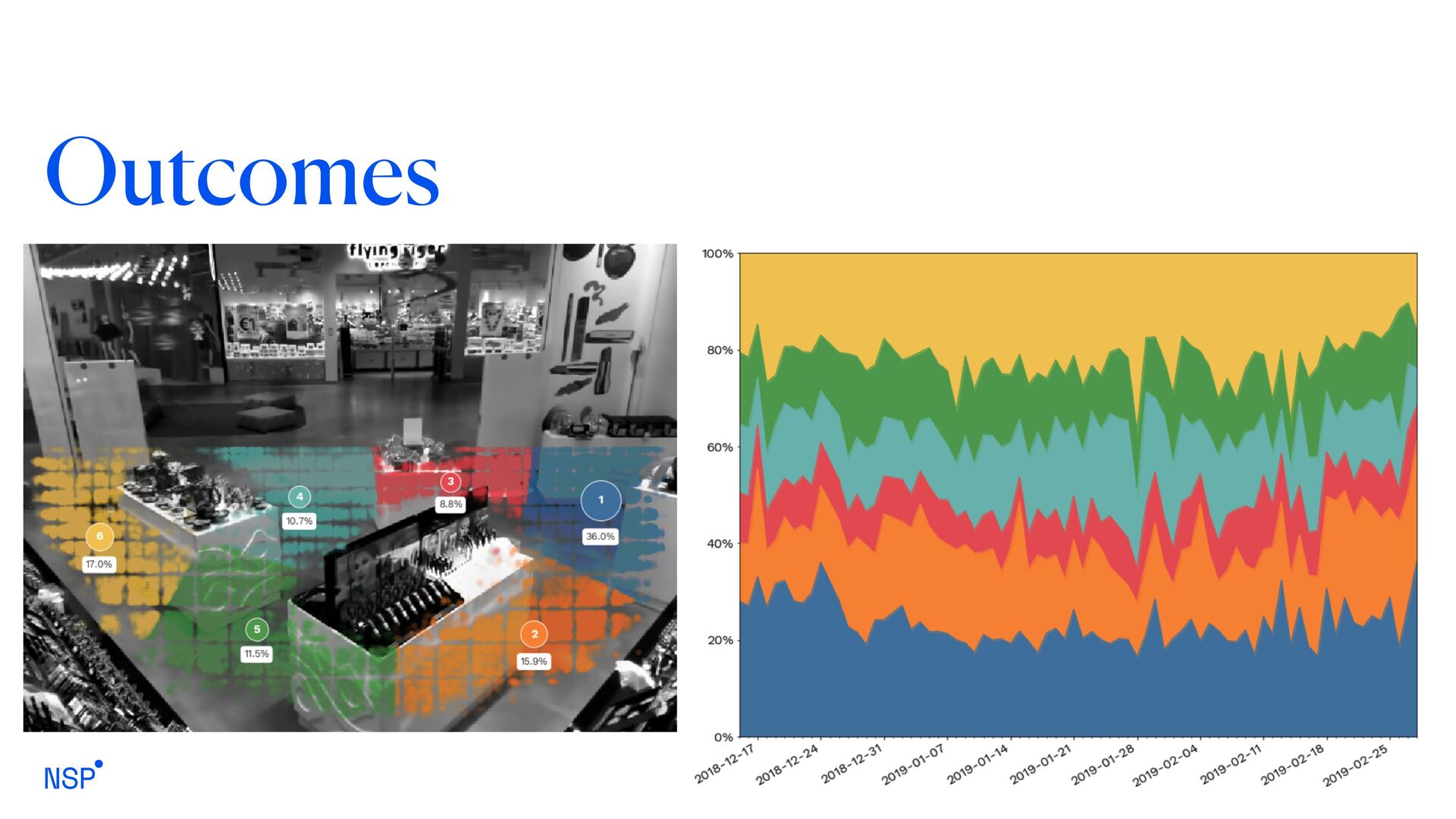
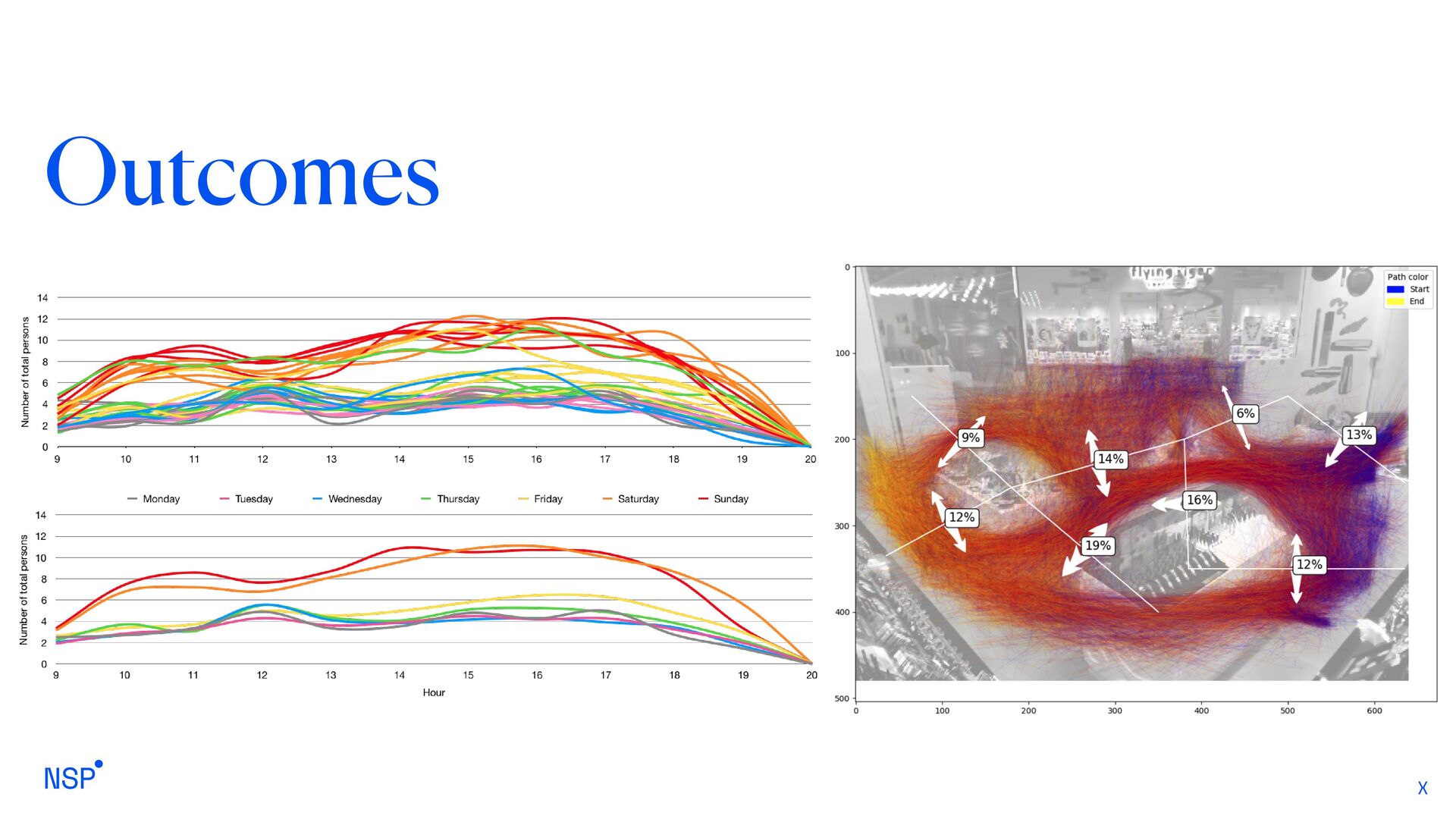
their movements in front of a camera leds to interesting results not only related to people counting Store managers can obtain a clear view of the preferred areas inside a store And event the overall amount of people that do not enter the store Store Analytics over delivered about store understanding, delivering a different but more meaningful metric
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}