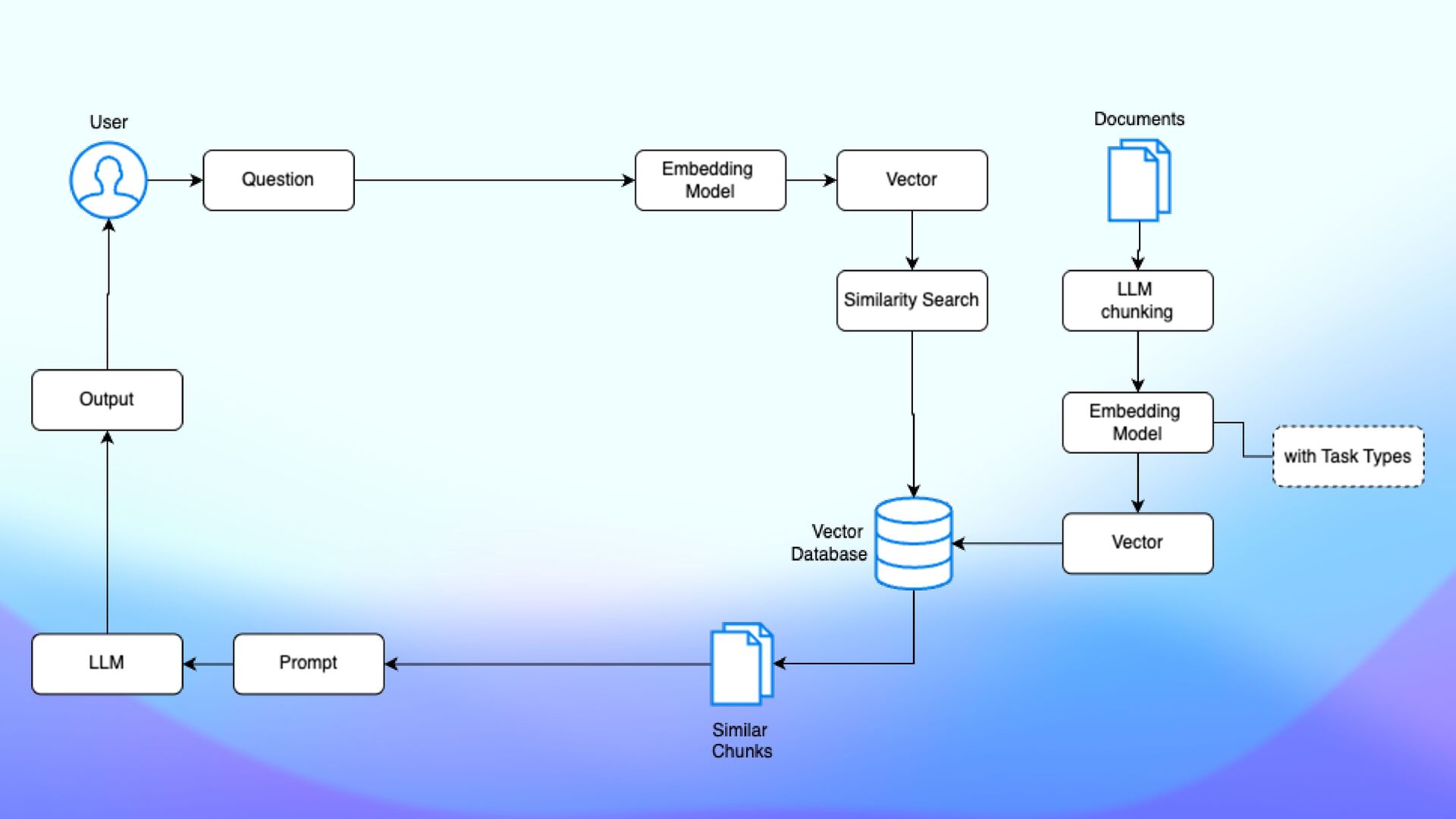
Provide relevant data to the application - Secure private data (compliance, con fi dentiality) - Gemini has 1M token context, so it’s all done? - 1M can still be short - the haystack e ff ect (https://arxiv.org/html/2407.01370v1)
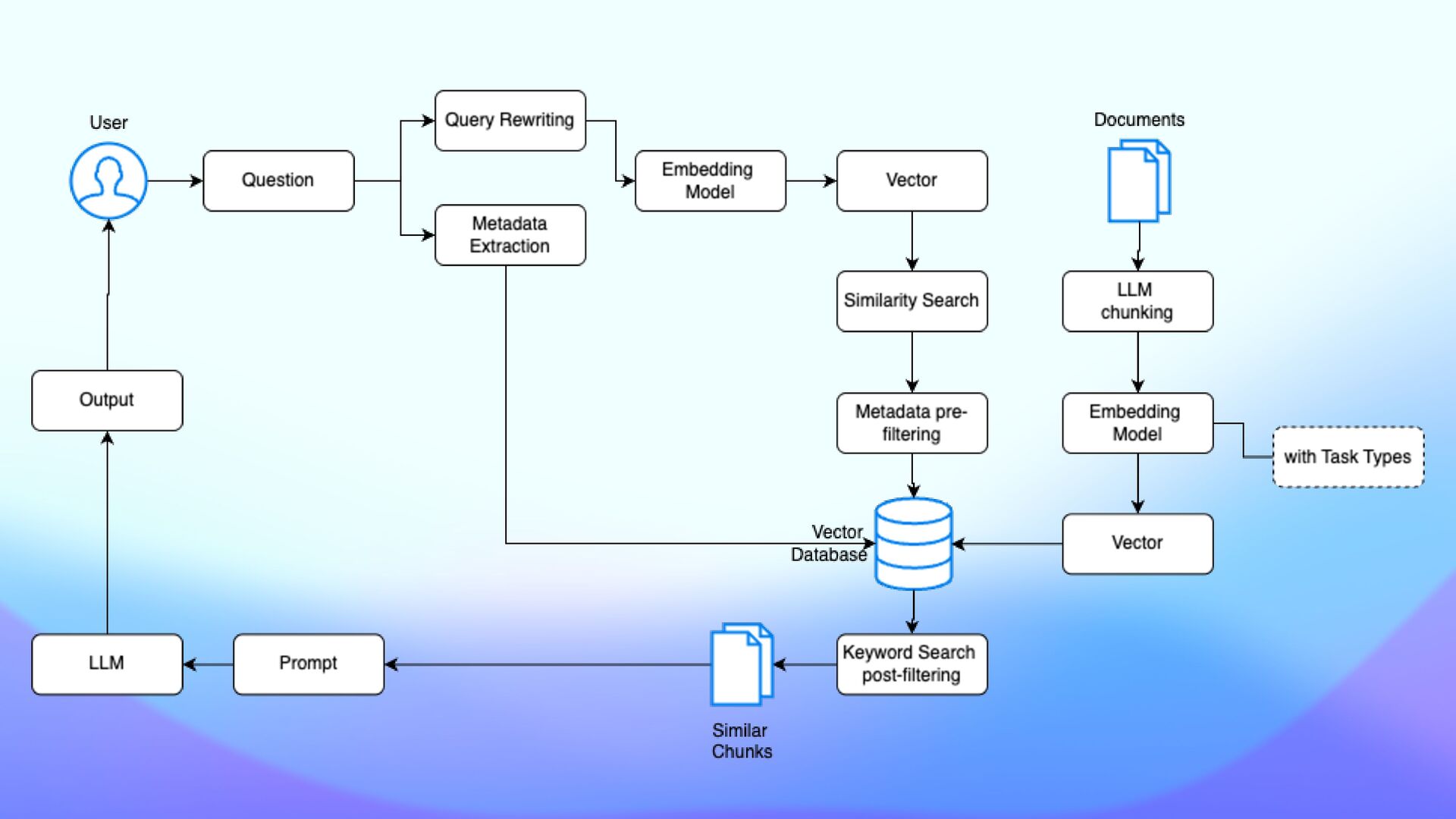
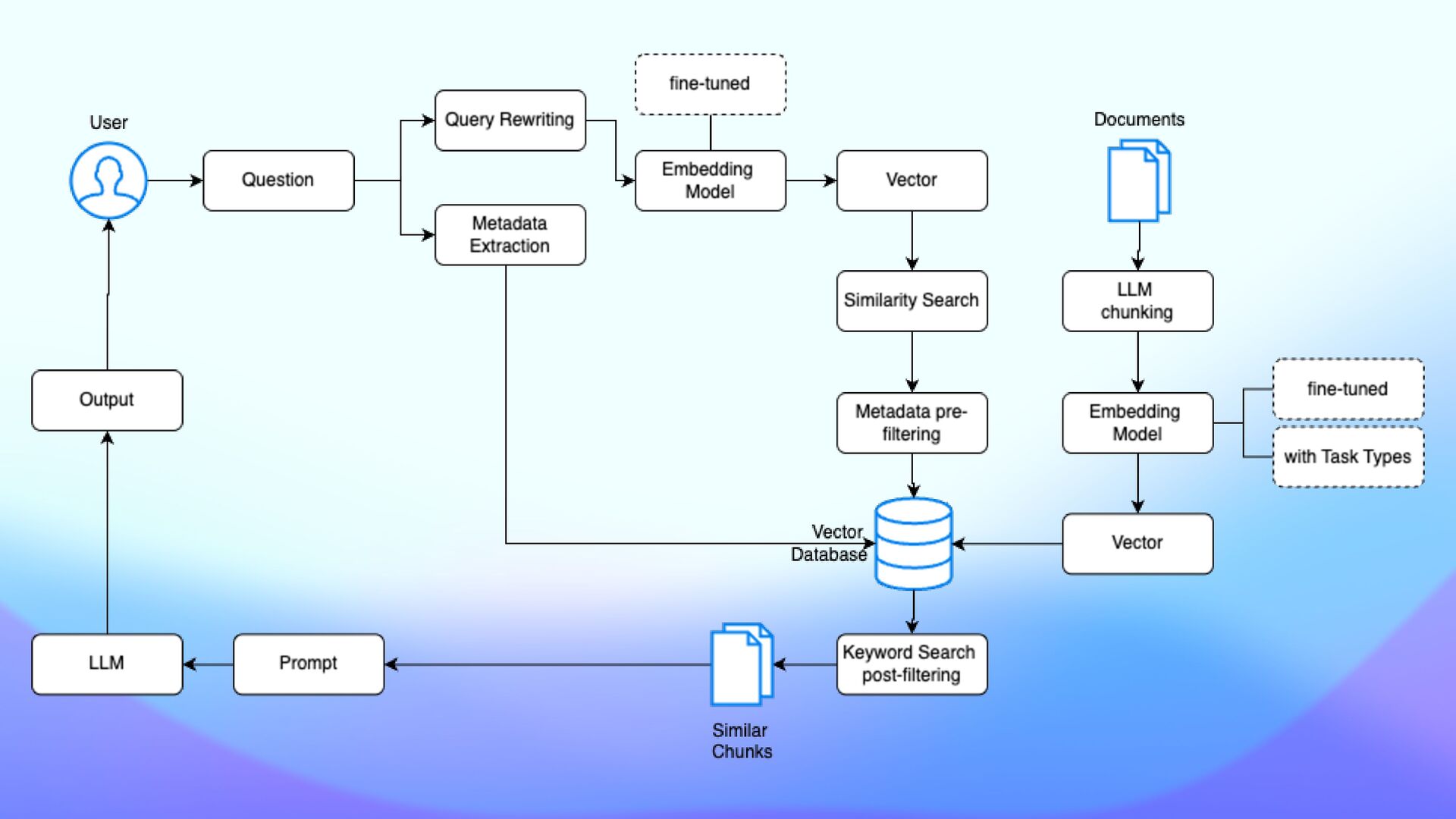
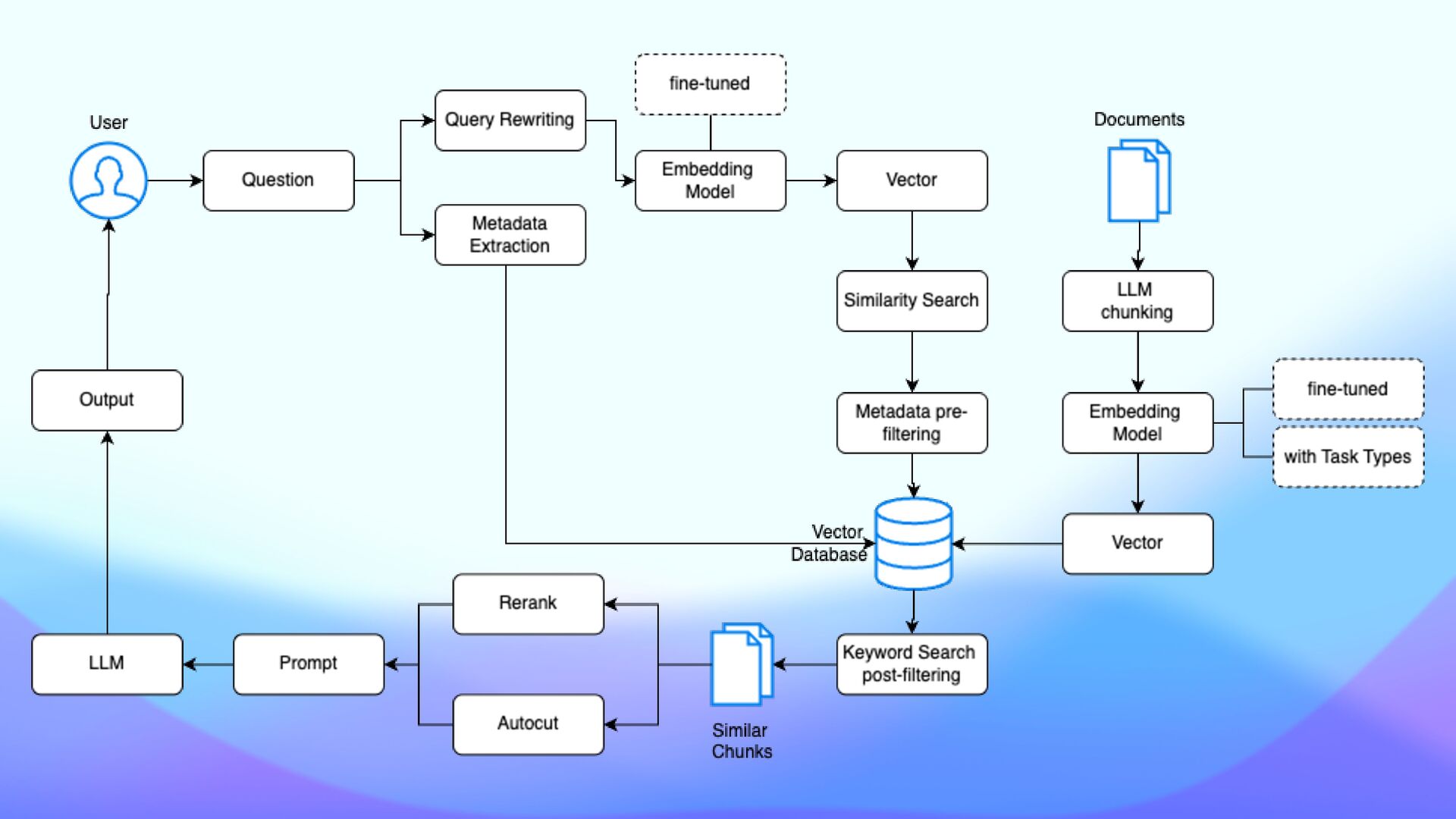
question and answer, and fact veri fi cation. Task types are labels that optimize the embeddings that the model generates based on your intended use case. - textembedding-gecko@003 - text-embedding-004 - text-multilingual-embedding-002 Task types can improve the quality of embeddings generated by an embeddings model. Task types
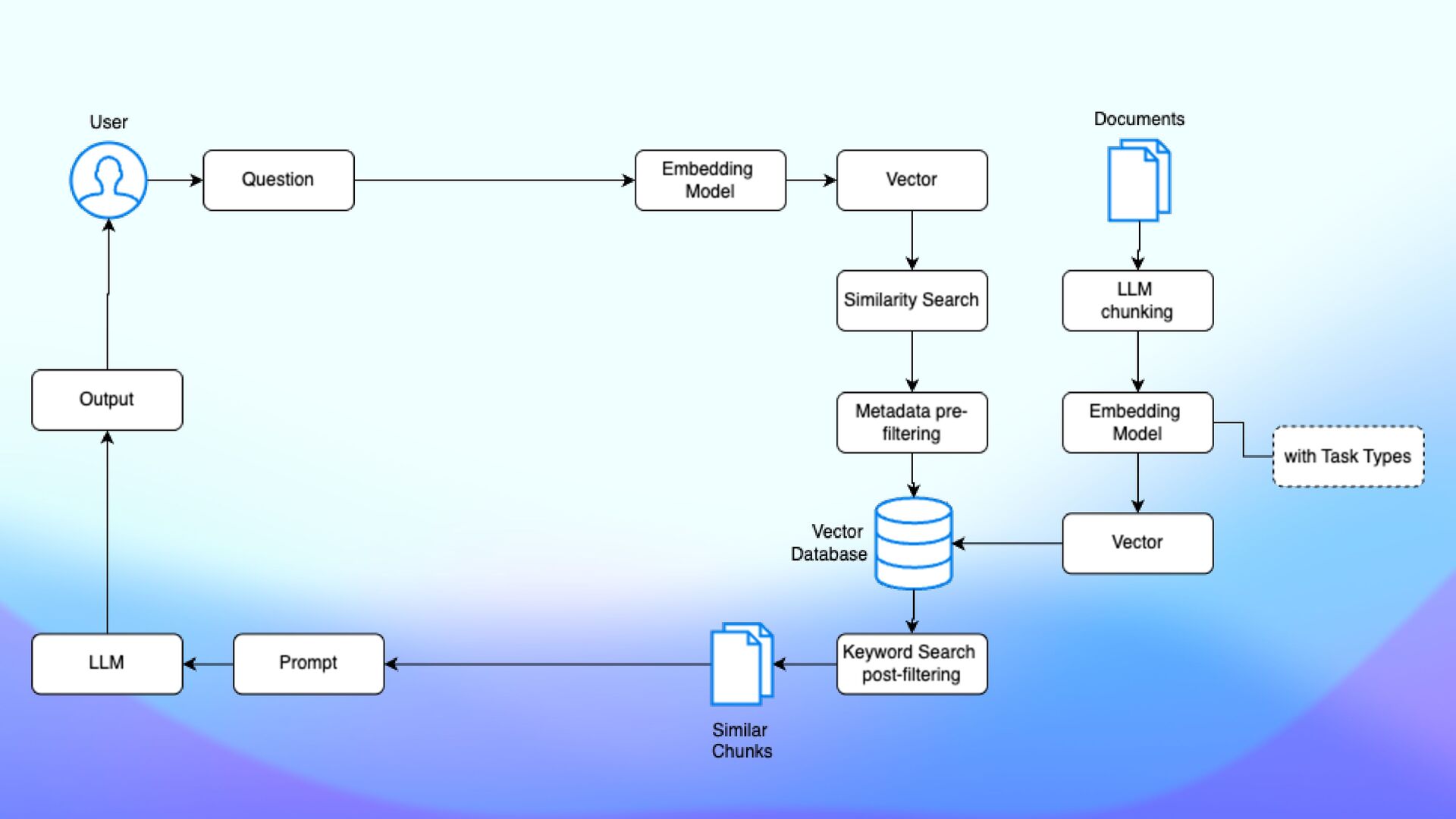
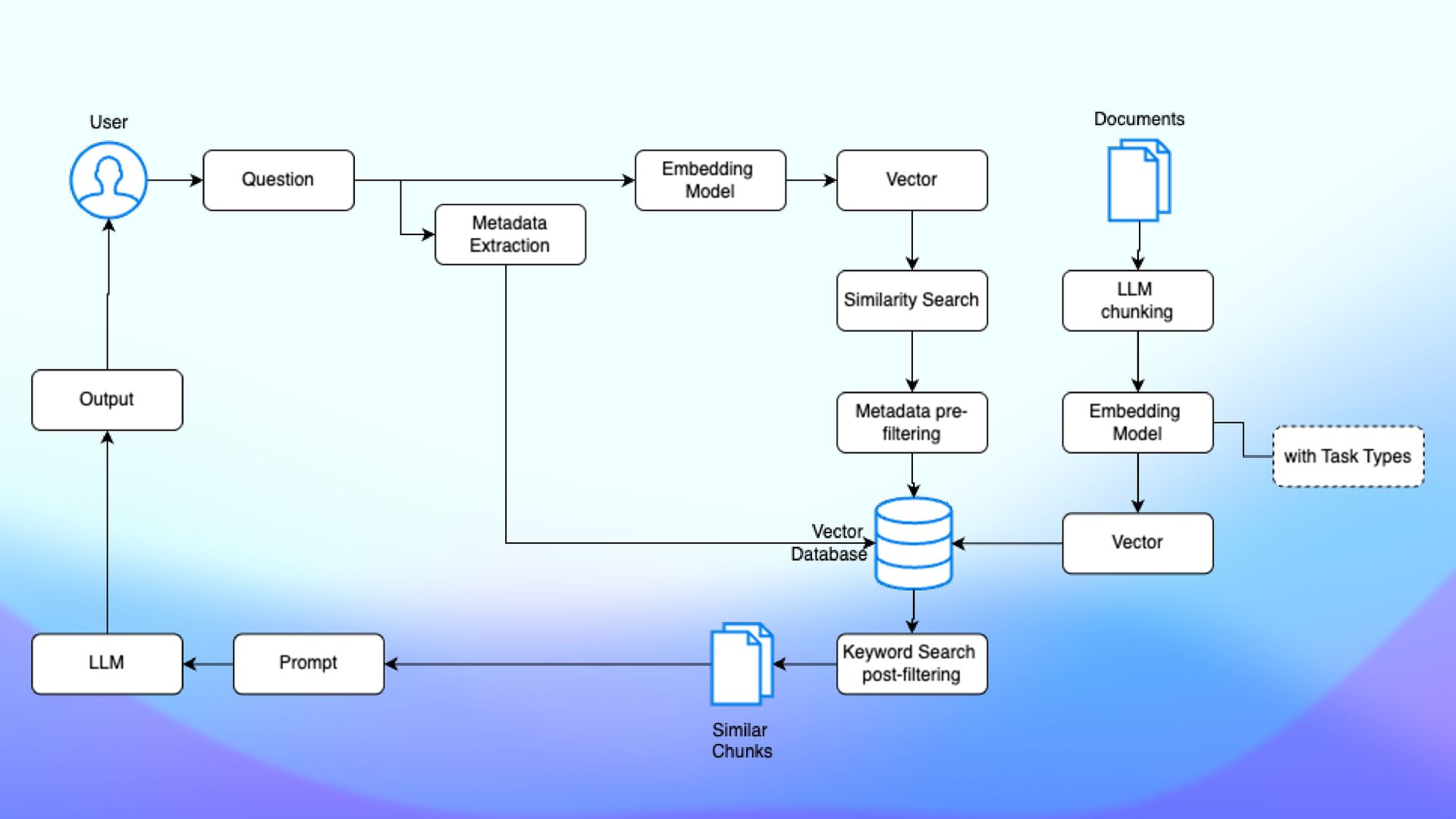
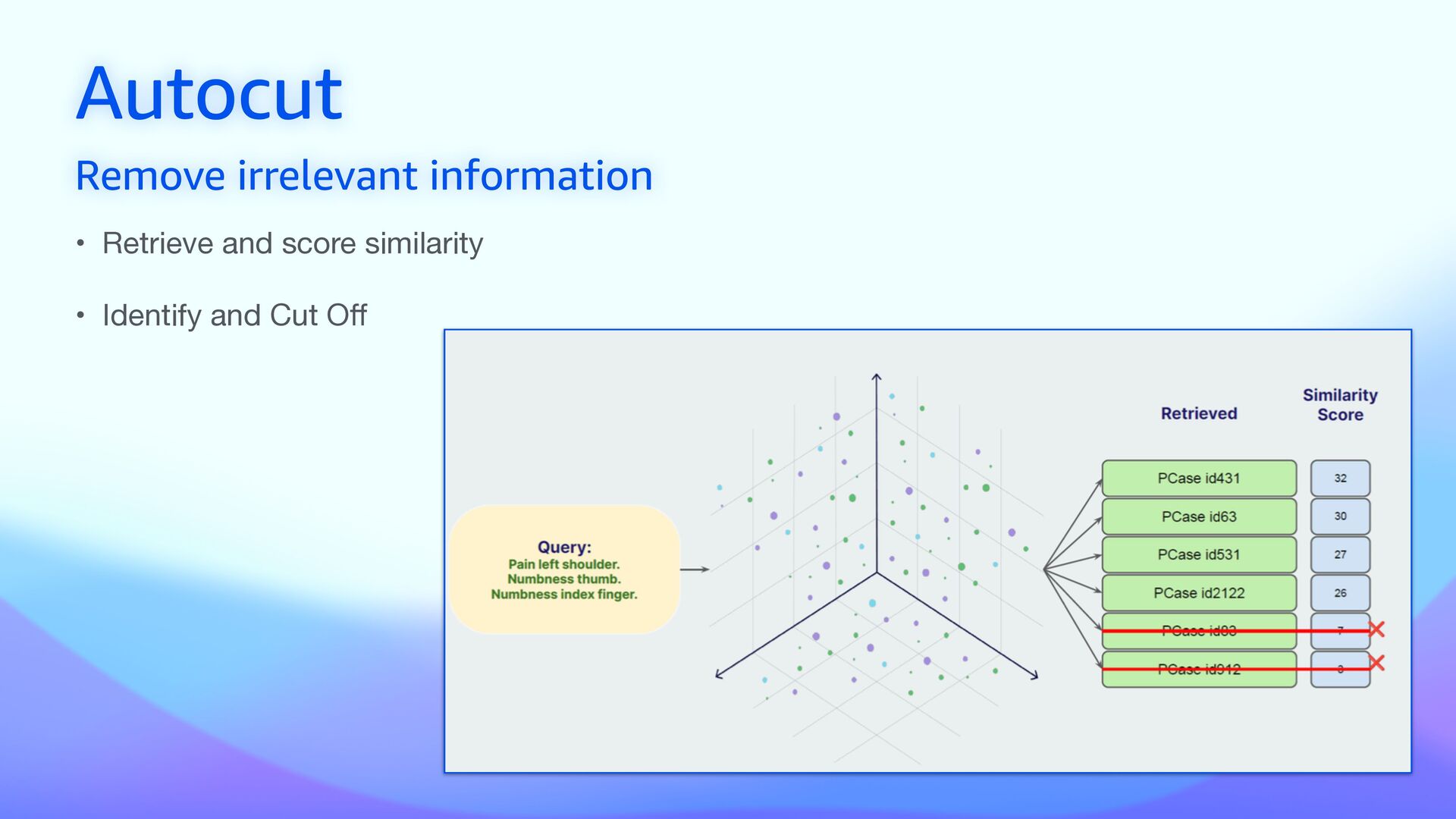
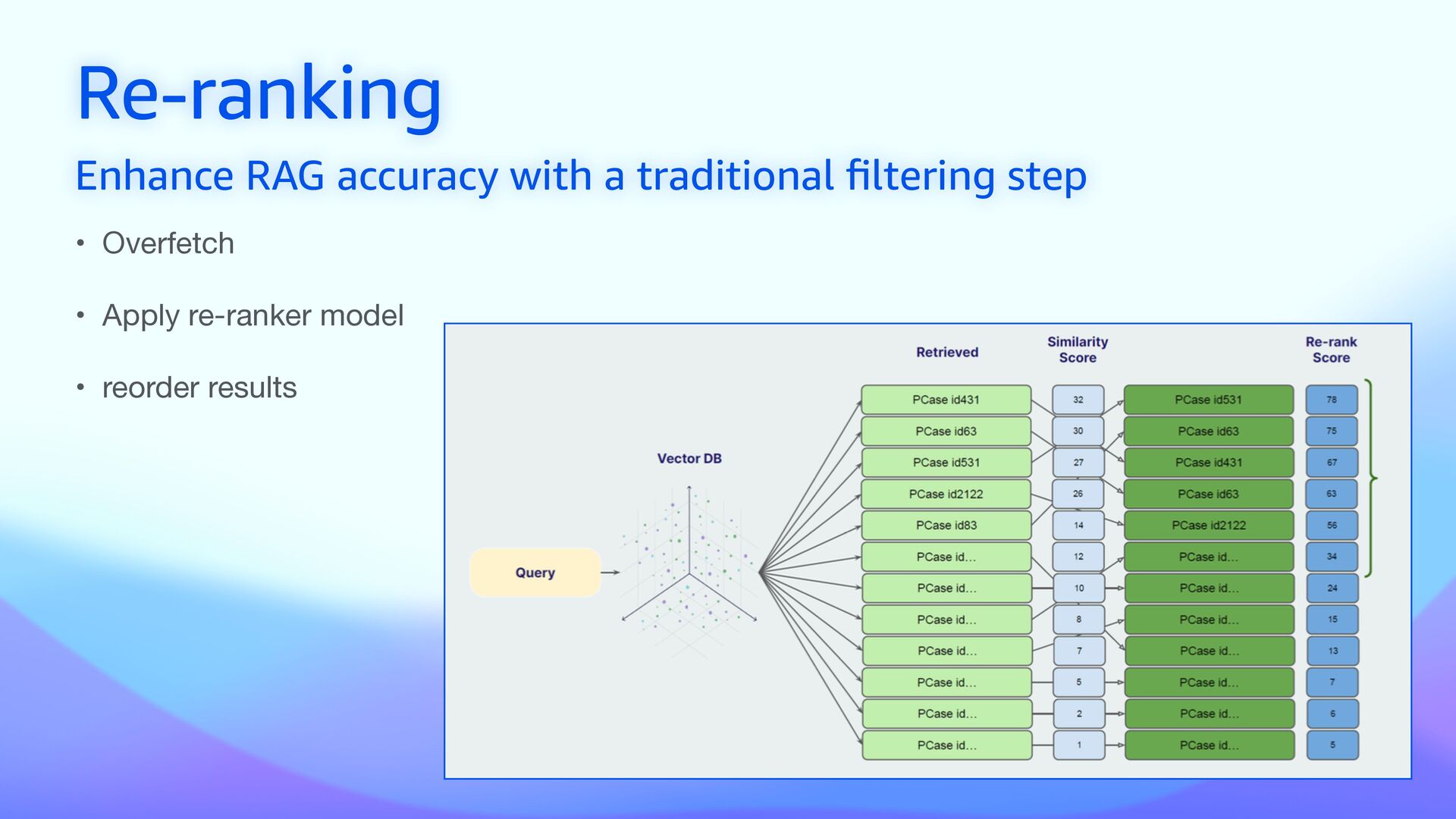
• Vector search captures the semantic meaning of the query • Keyword search identi fi es exact matches for speci fi c terms • Enhances RAG in domain-speci fi c applications (medicine, legal, …) • Improves accuracy of standard RAG increasing focus
Uni fi ed Query Interface • Store vector embeddings alongside the original data and metadata in Atlas • Instant synchronization • Data isolation by design within the same organization
Atlas Vector Search Index on embeddings fi eld • Store vector embeddings in MongoDB Atlas • Supports popular frameworks: • LangChain • LlamaIndex • Semantic Kernel • Haystack • Spring AI • Use pipelines to build complex queries • $vectorSearch must be the fi rst stage of any pipeline where it appears.
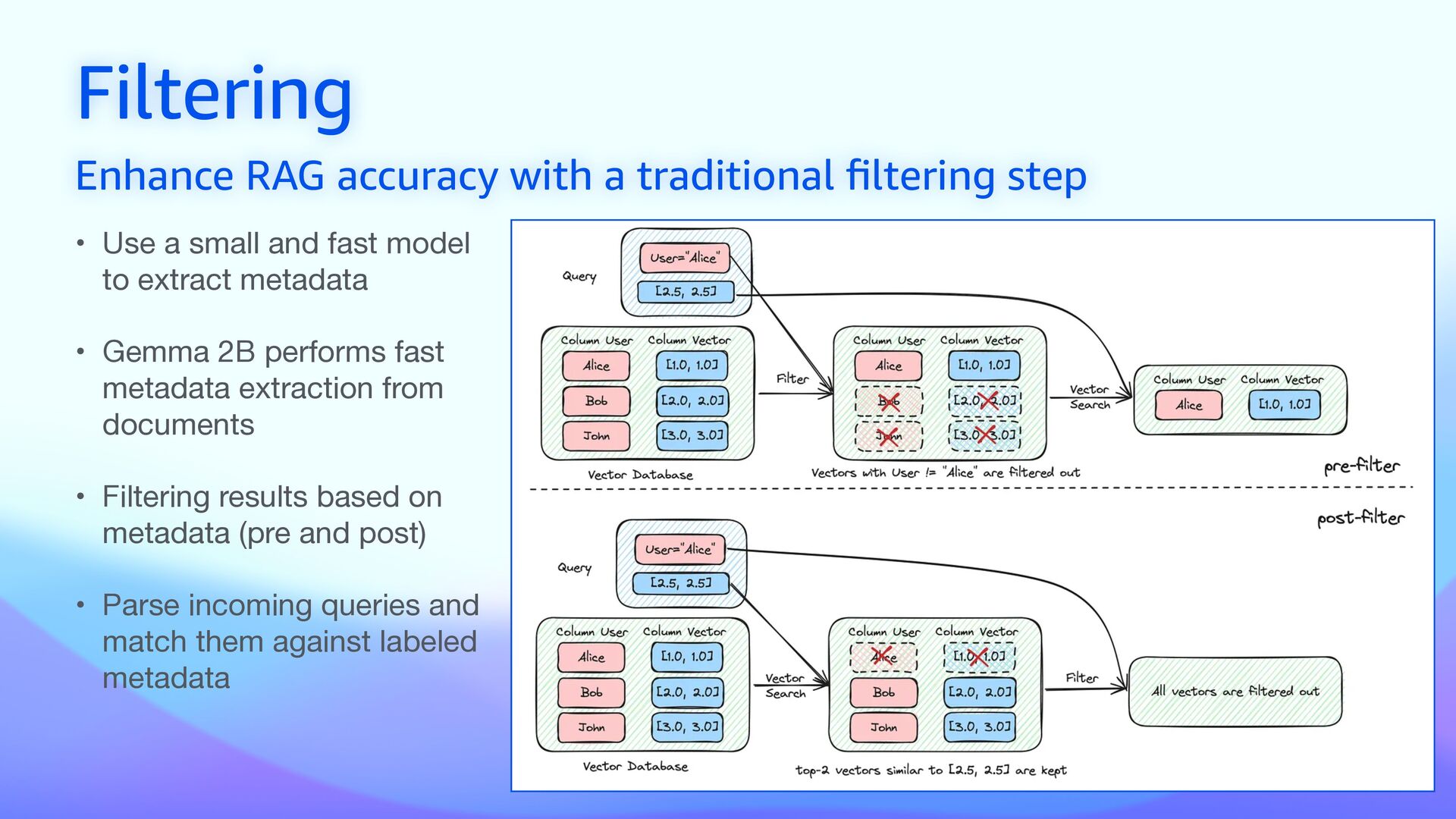
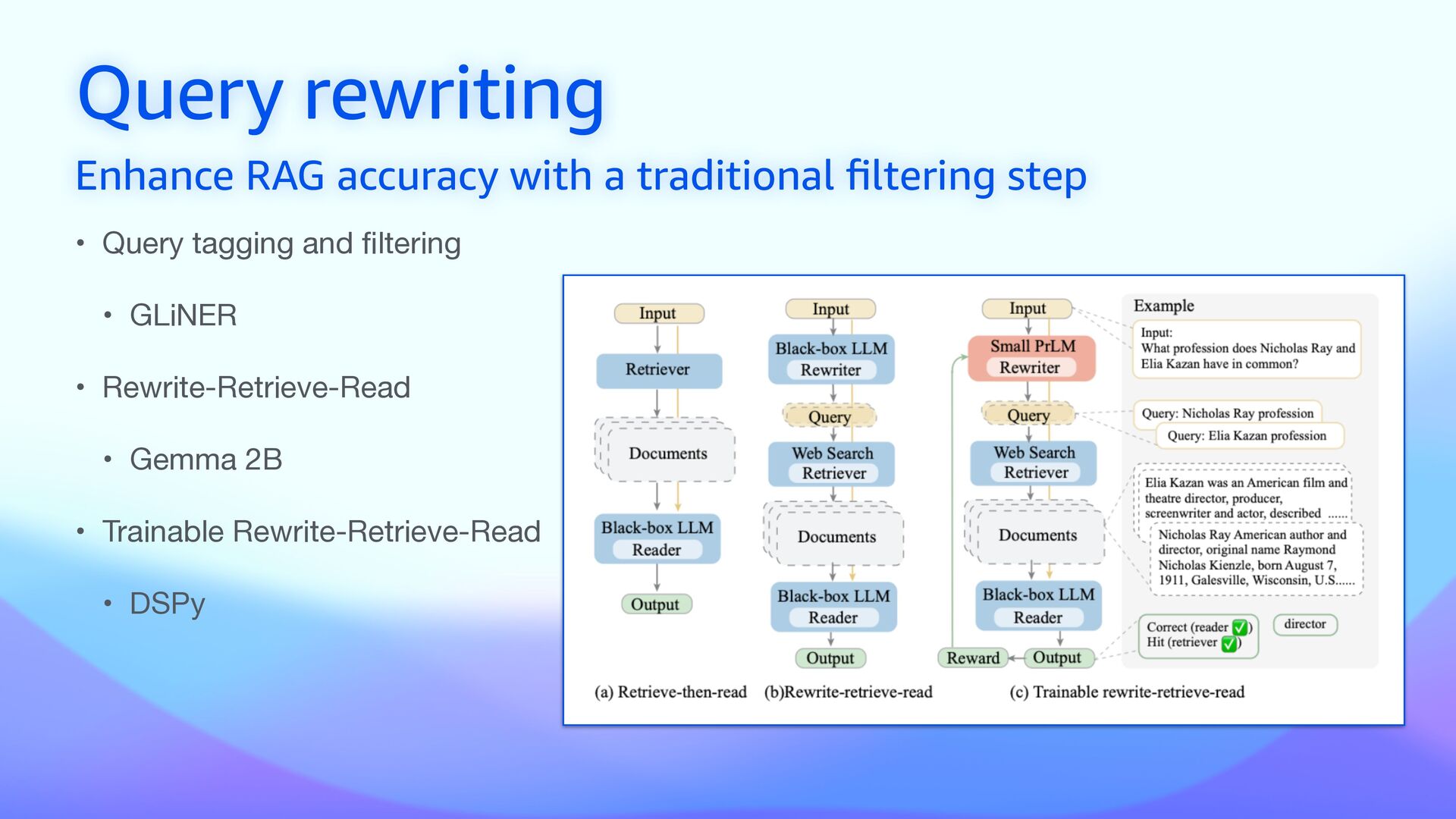
• Use a small and fast model to extract metadata • Gemma 2B performs fast metadata extraction from documents • Filtering results based on metadata (pre and post) • Parse incoming queries and match them against labeled metadata
GLiNER Generalized Linear Named Entity Recognizer) to tag and label chunks to either label and fi lter out not relevant tokens (not-matching chunks are not generated) • Leverage Gemini 1.5 Pro capabilities • build a document summary • multi-modal processing to map spatial meaning
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}