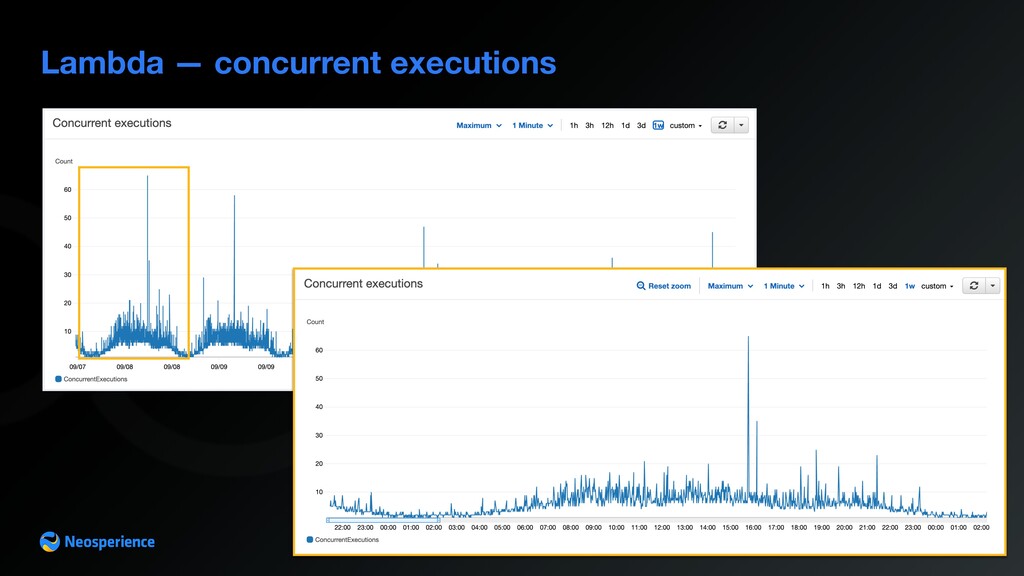
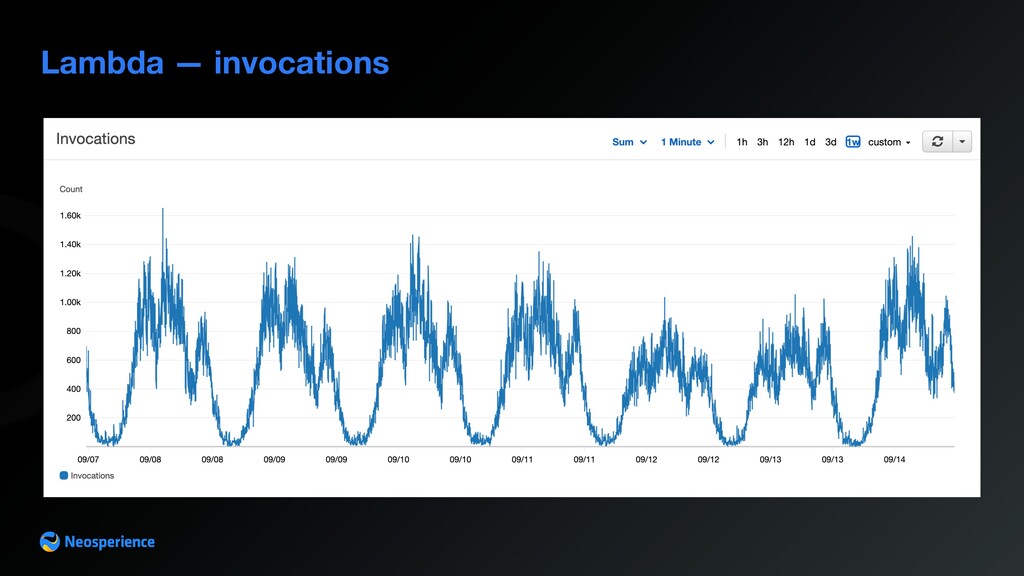
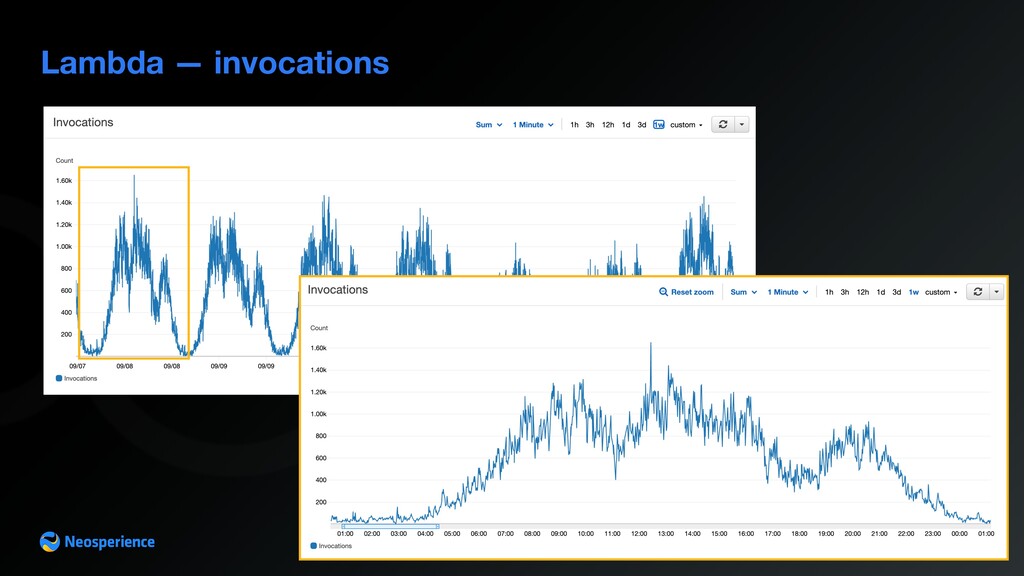
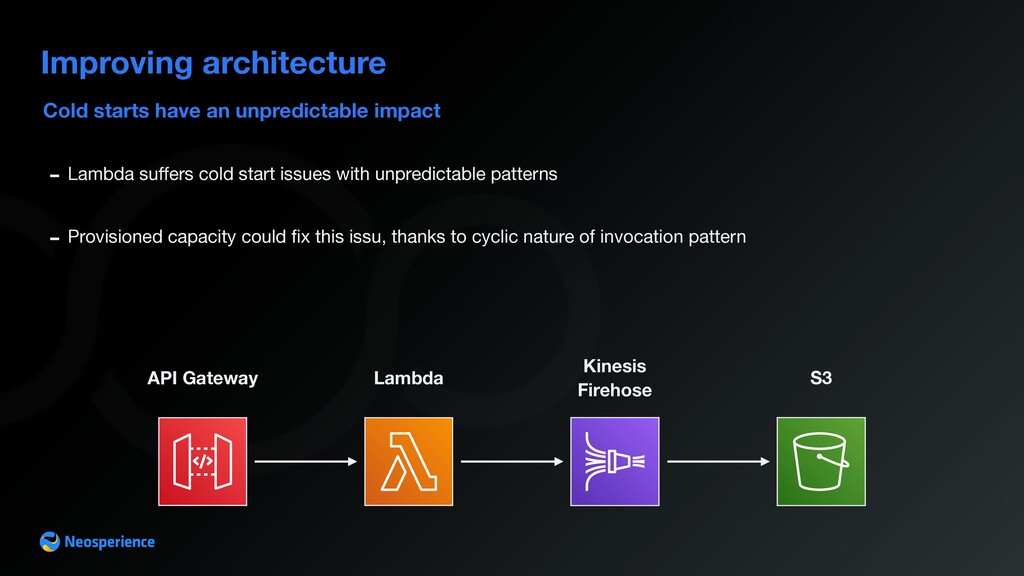
In recent years the amount of data generated by brands increased dramatically, thanks to affordable storage costs and faster internet connections. In this article, we explore the advantages serverless technologies offer when dealing with a large amount of data and common pitfalls of these architectures. We are going to outline tips everyone should figure out before starting your next big data project At Neosperience, building our SaaS cloud on AWS, we managed to leverage a number of AWS services. This talk is a deep dive of the choices we made and the reason behind them that made us evolve a standard pipeline with API Gateway + Lambda + DynamoDB into an architecture, able to process hundreds of events per second. In this journey we’ll discover some unexpected behavior, tips and hidden gems of AWS services and how to use them in a real life use case. Basic knowledge of AWS services is required.
![www.neosperience.com | blog.neosperience.com | [email protected] Neosperience Empathy in Technology Lessons](https://files.speakerdeck.com/presentations/aae31b4f0fa04b33b5856b041c98cbaf/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
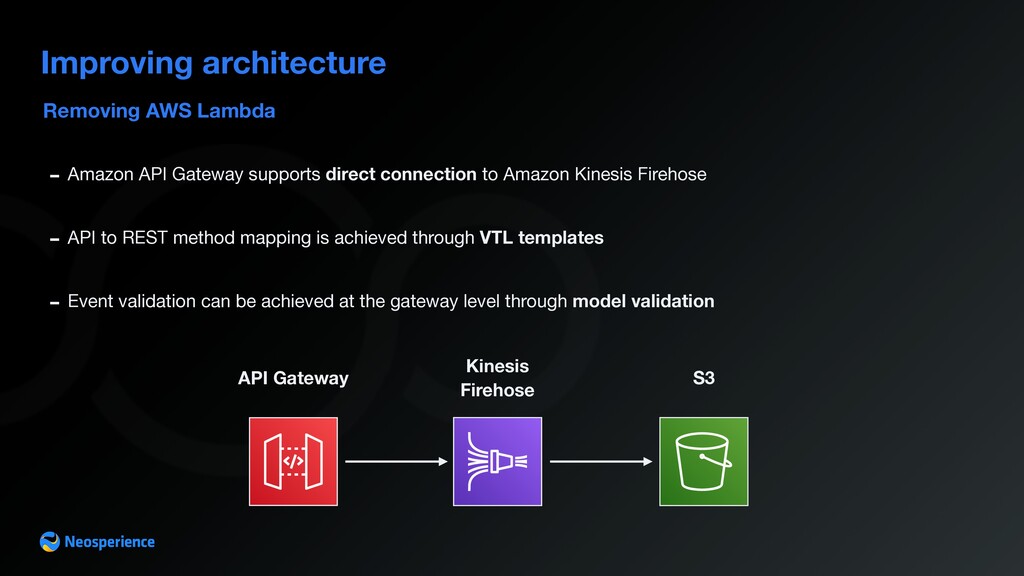{kind=link}
{kind=link}
{kind=link}
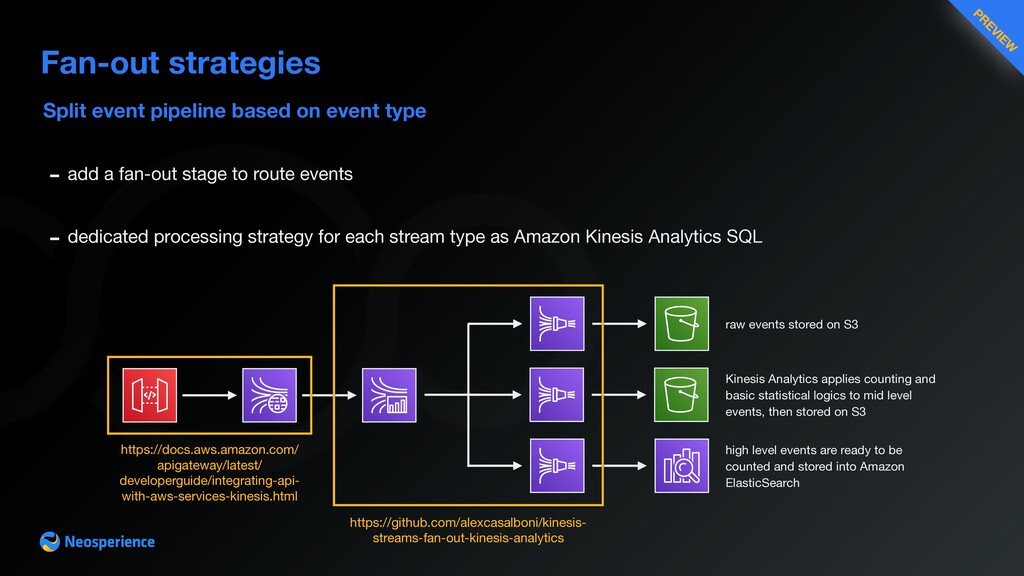{kind=link}
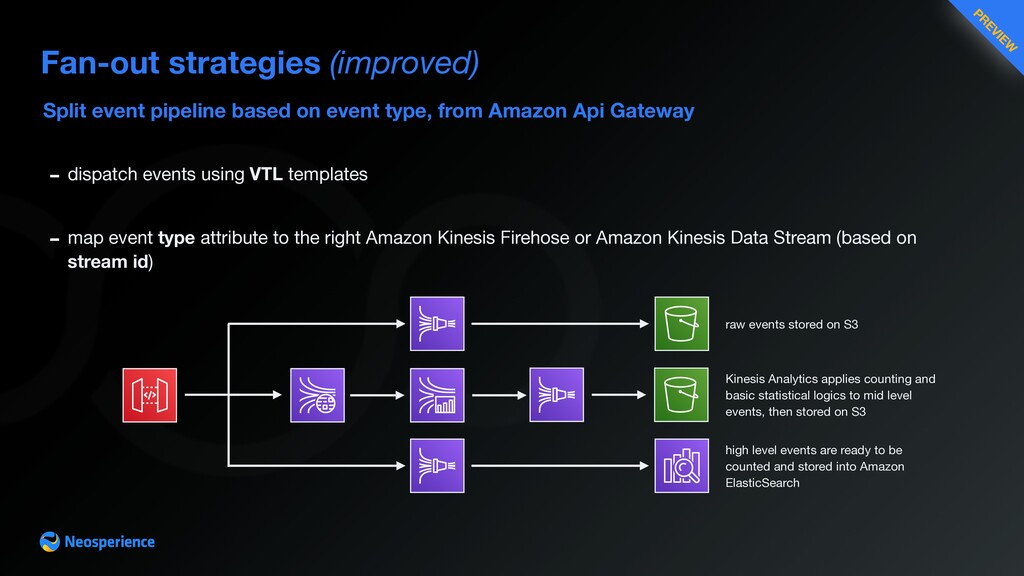{kind=link}
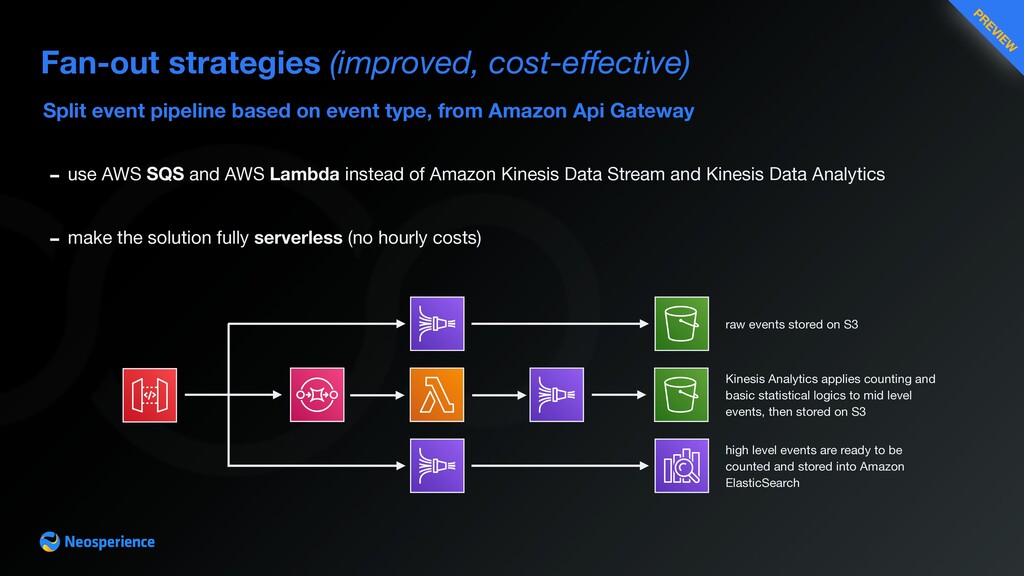{kind=link}
{kind=link}
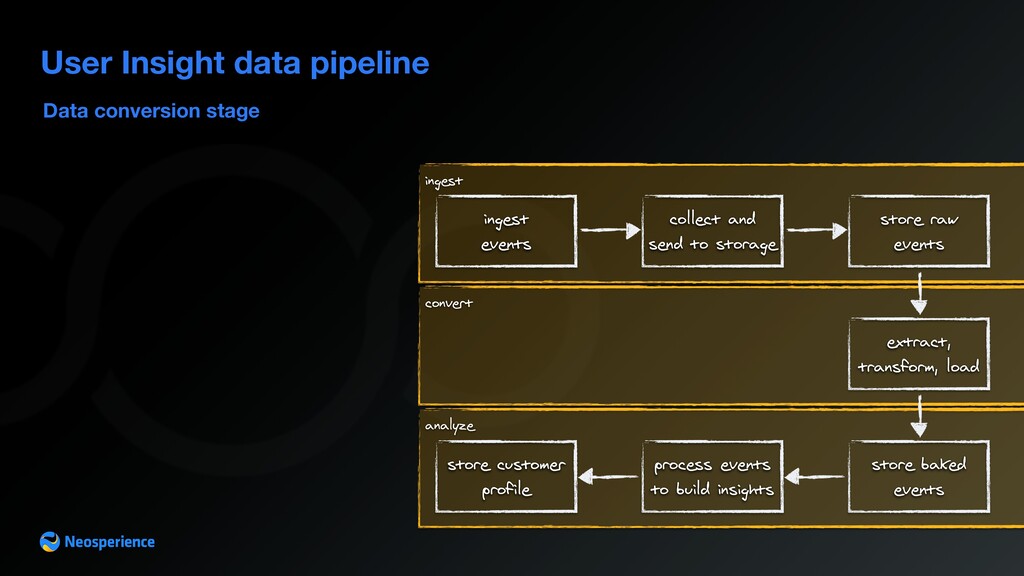{kind=link}
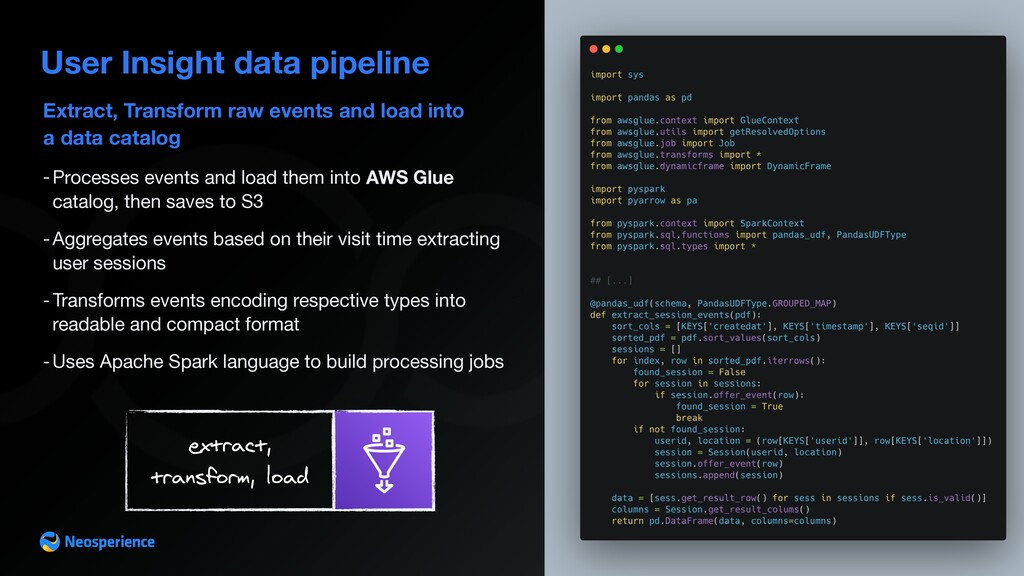{kind=link}
{kind=link}
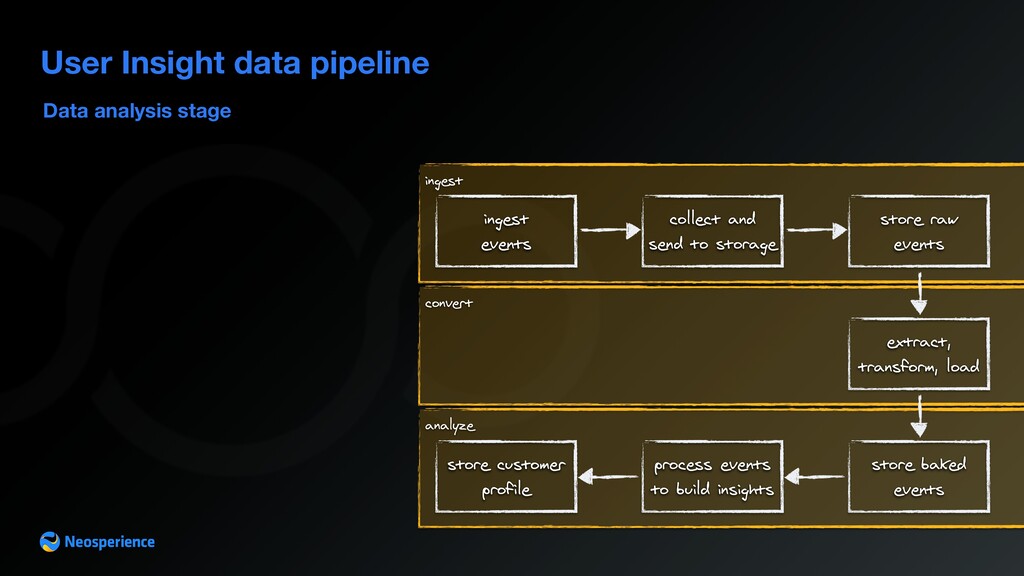{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![www.neosperience.com | blog.neosperience.com | [email protected]](https://files.speakerdeck.com/presentations/aae31b4f0fa04b33b5856b041c98cbaf/slide_48.jpg){kind=link}