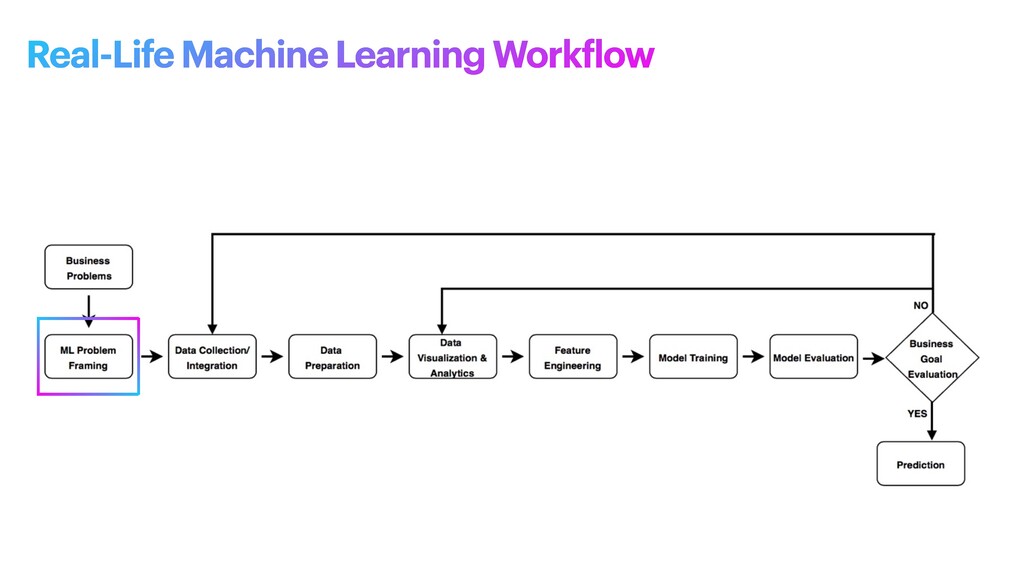
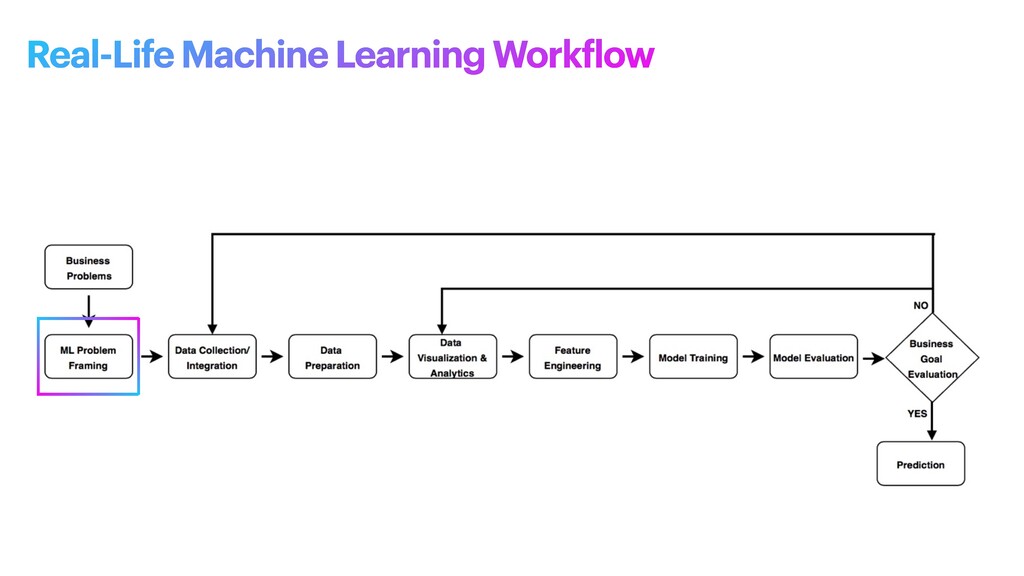
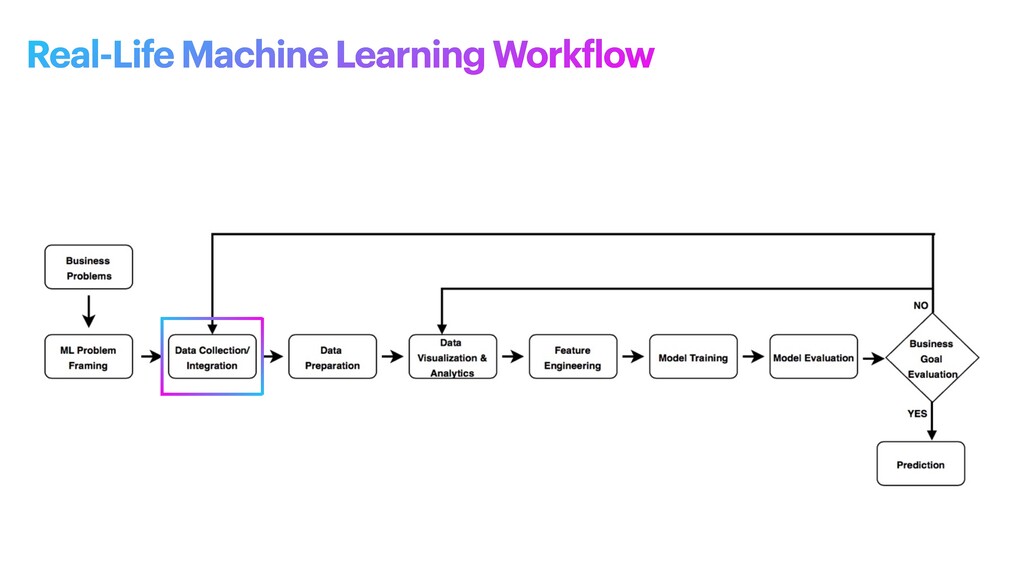
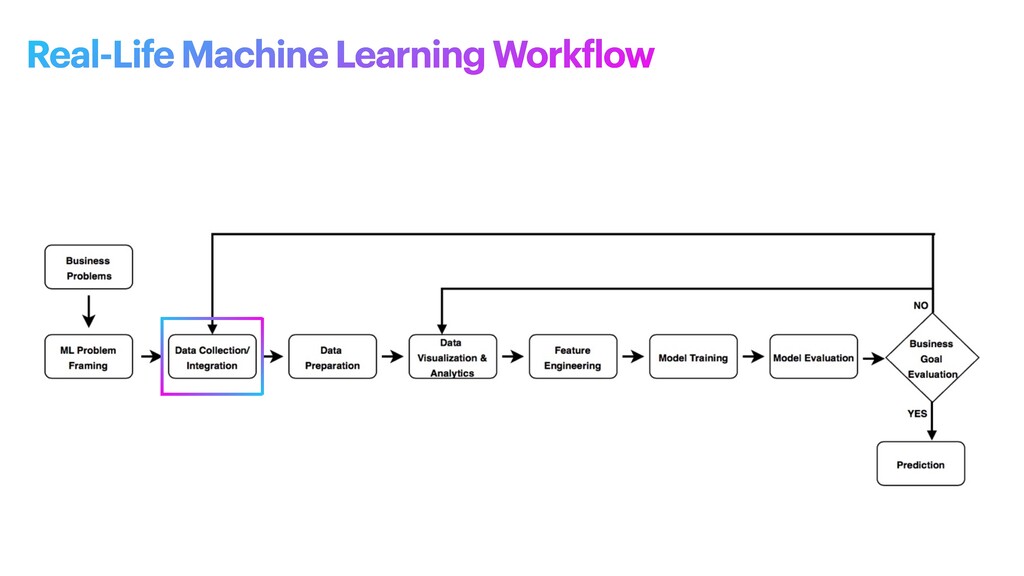
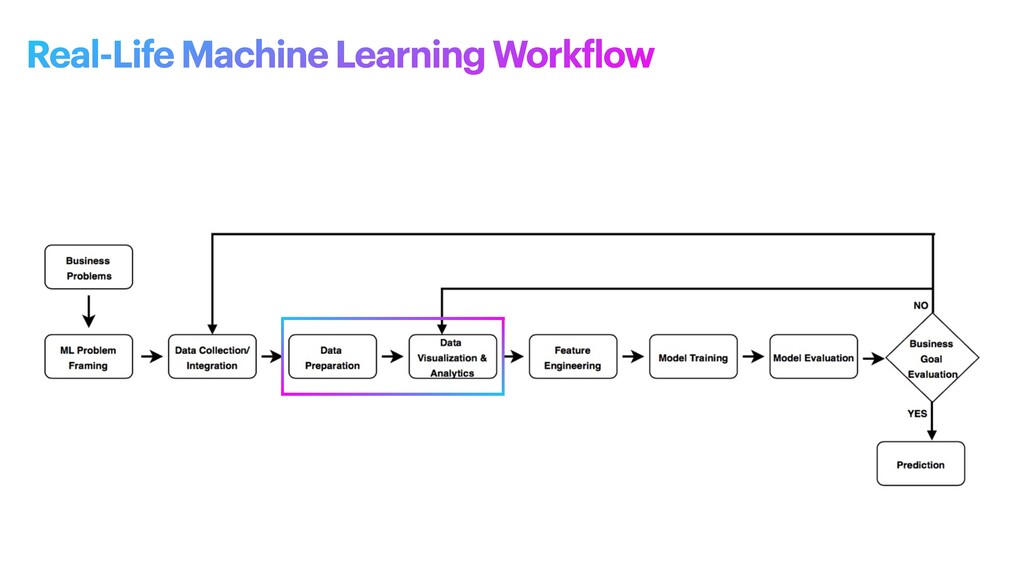
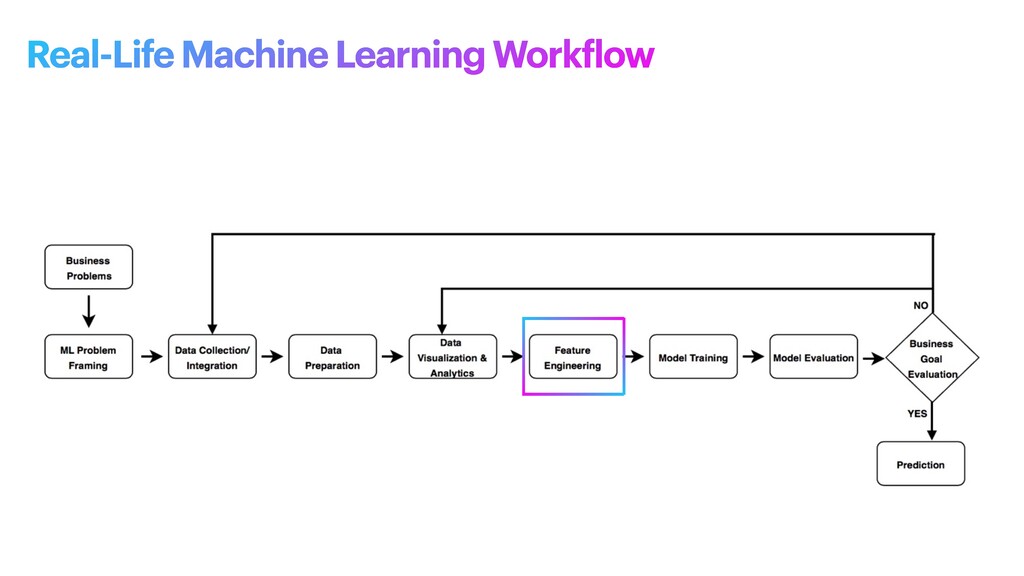
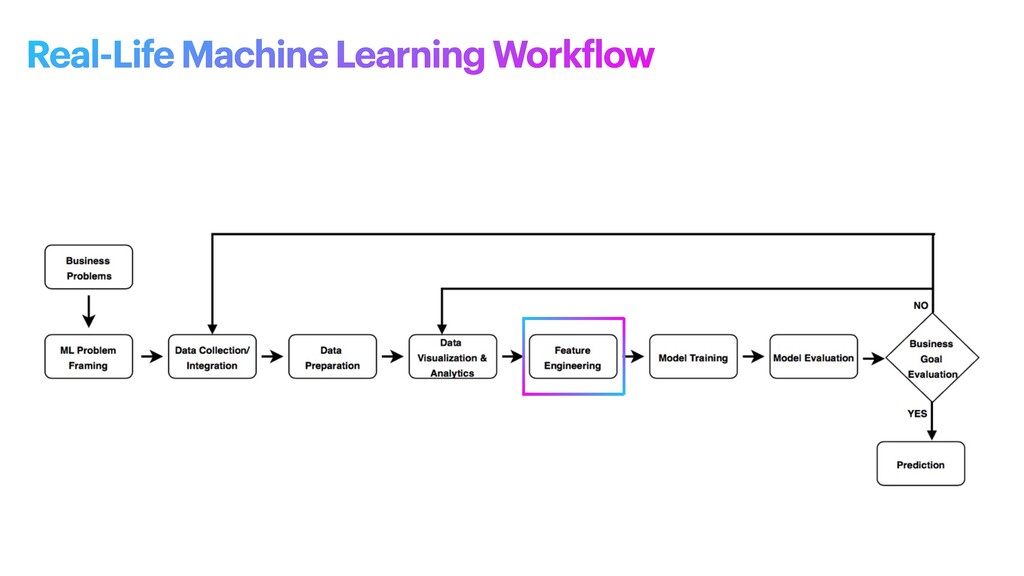
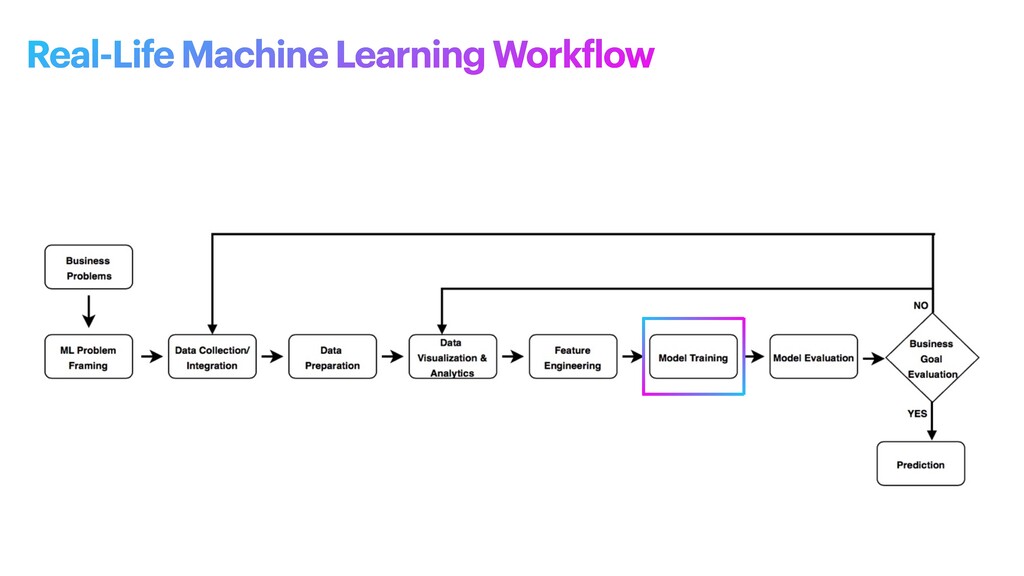
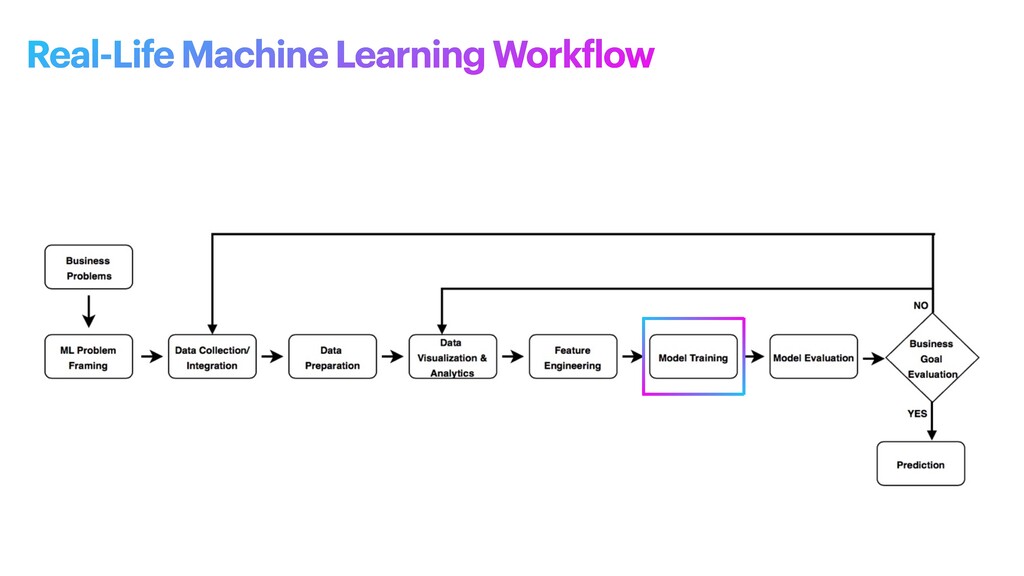
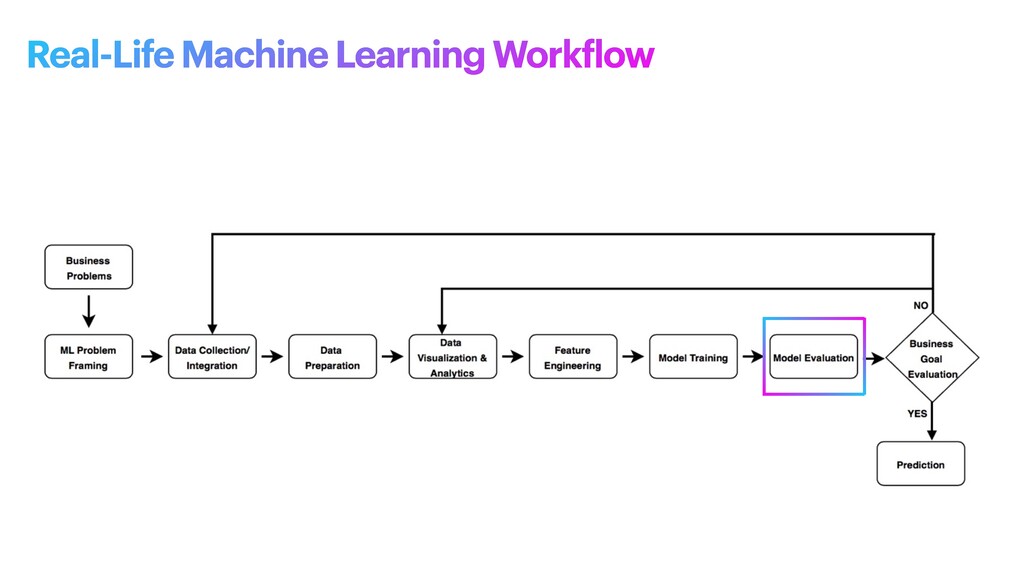
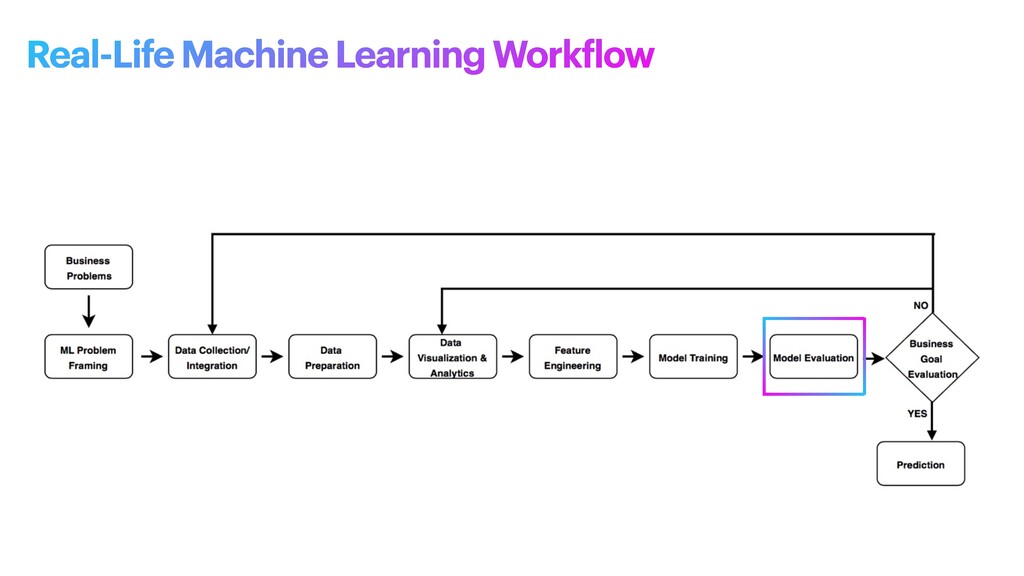
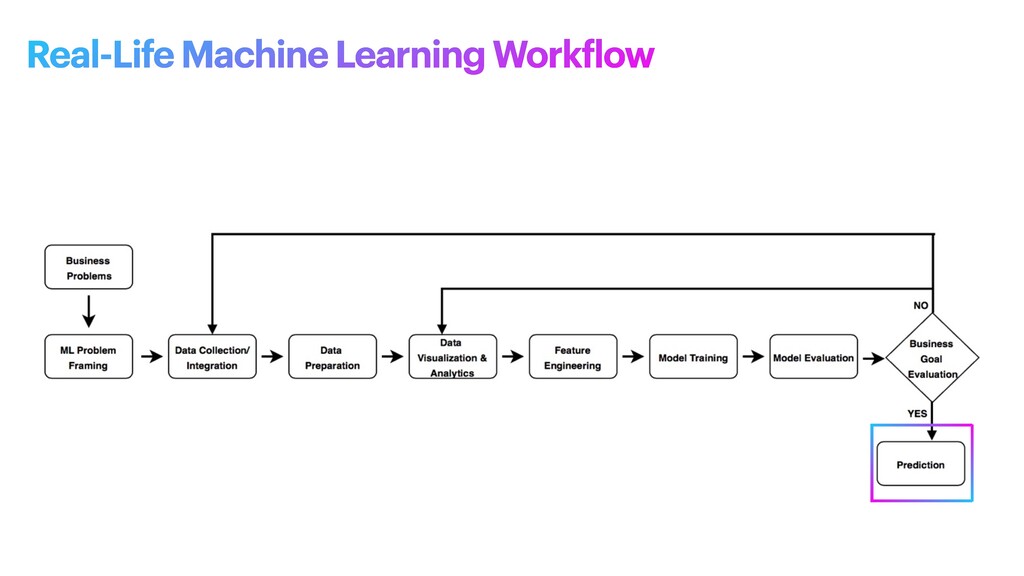
machine learning problem: what is observed and what should be predicted (known as a label or target variable). Determining what to predict and how performance and error metrics need to be optimized is a key step in ML. For example, imagine a scenario where a manufacturing company wants to identify which products will maximize pro f its. Reaching this business goal partially depends on determining the right number of products to produce. In this scenario, you want to predict the future sales of the product, based on past and current sales. Predicting future sales becomes the problem to solve, and using ML is one approach that can be used to solve it. ML problem framing
the project • Establish an observable and quanti f iable performance metric for the project, such as accuracy, prediction latency, or minimizing inventory value • Formulate the ML question in terms of inputs, desired outputs, and the performance metric to be optimized • Evaluate whether ML is a feasible and appropriate approach • Create a data sourcing and data annotation objective, and a strategy to achieve it • Start with a simple model that is easy to interpret, and which makes debugging more manageable ML problem framing
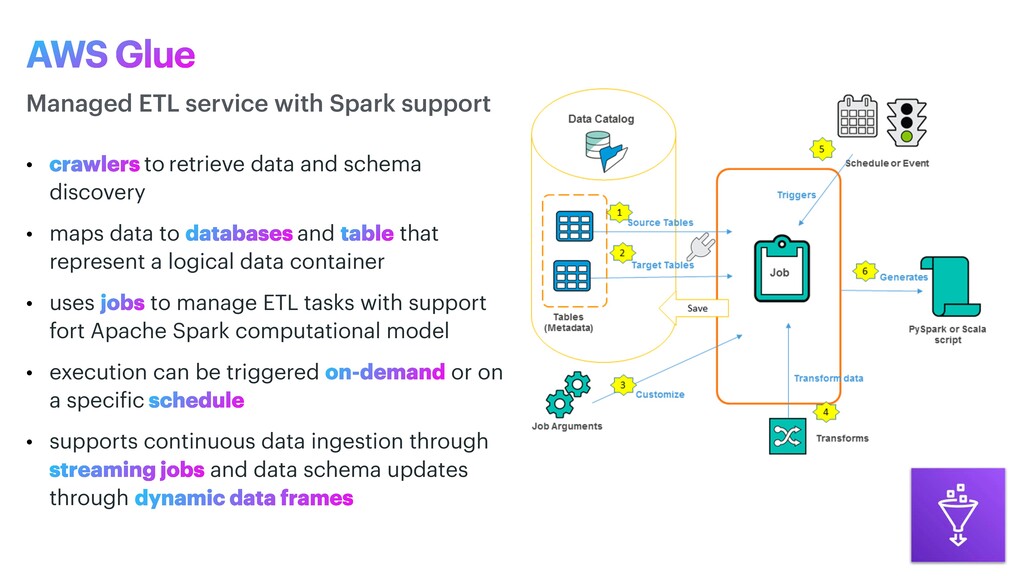
data to databases and table that represent a logical data container • uses jobs to manage ETL tasks with support fort Apache Spark computational model • execution can be triggered on-demand or on a speci f ic schedule • supports continuous data ingestion through streaming jobs and data schema updates through dynamic data frames Managed ETL service with Spark support AWS Glue
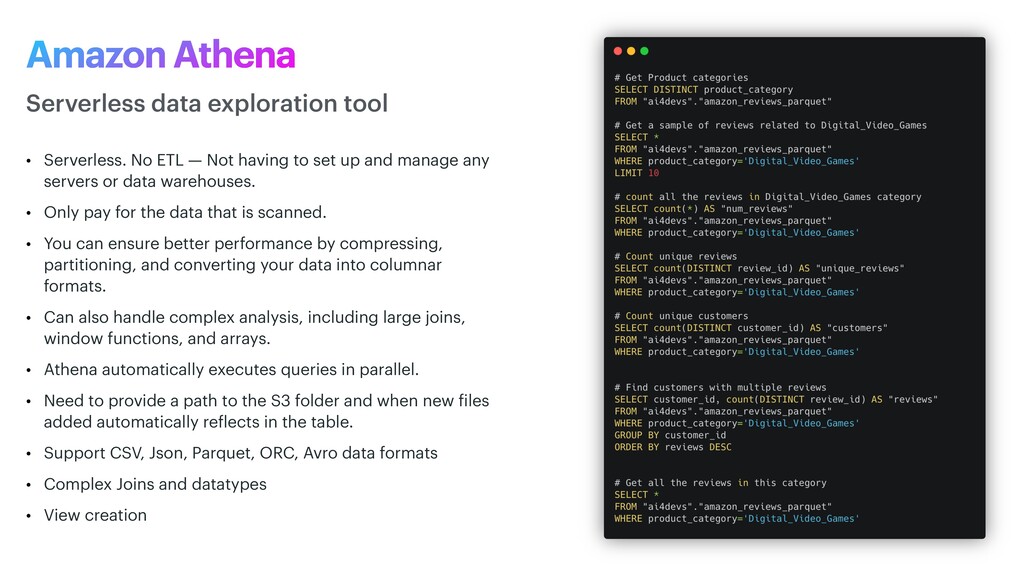
and manage any servers or data warehouses. • Only pay for the data that is scanned. • You can ensure better performance by compressing, partitioning, and converting your data into columnar formats. • Can also handle complex analysis, including large joins, window functions, and arrays. • Athena automatically executes queries in parallel. • Need to provide a path to the S3 folder and when new f iles added automatically re f lects in the table. • Support CSV, Json, Parquet, ORC, Avro data formats • Complex Joins and datatypes • View creation Serverless data exploration tool Amazon Athena
centralized feature store. Everybody I talk to really wants to build or even buy a feature store…… if an organization had a feature store, the ramp-up period for Data Scientists can be much faster.”
share machine learning (ML) features in S3. • online feature set to support inference tasks • Data Wrangler pushes engineered features into a feature store • both online and o ff line stores can be ingested via separate Engineering Pipeline via SDK • Streaming sources can directly ingest features to the online feature store for inference or feature creation • Feature Store automatically builds an Amazon Glue Data Catalog when Feature Groups are created Create, share, and manage features for machine learning (ML) development Amazon SageMaker FeatureStore
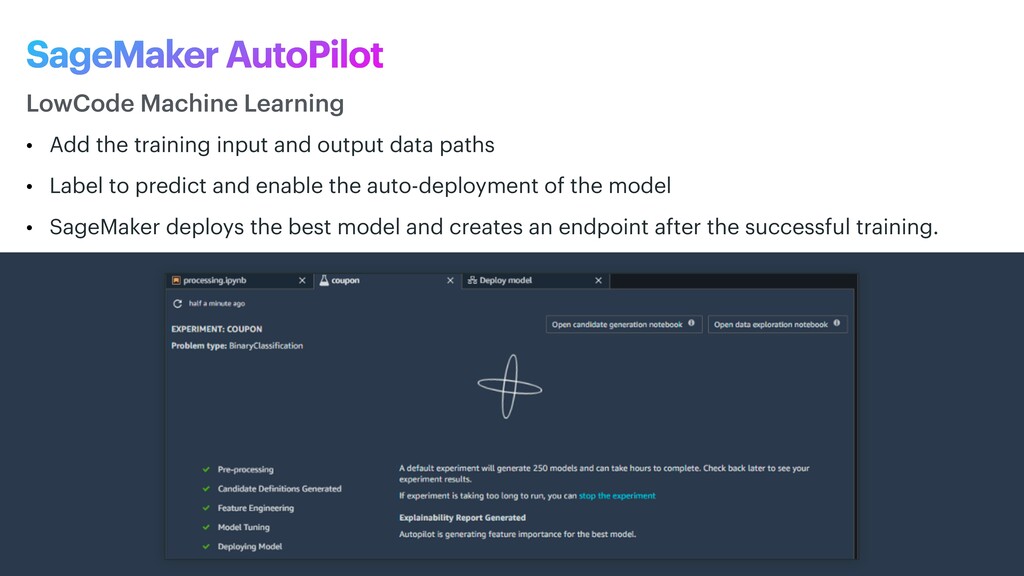
Label to predict and enable the auto-deployment of the model • SageMaker deploys the best model and creates an endpoint after the successful training. LowCode Machine Learning SageMaker AutoPilot
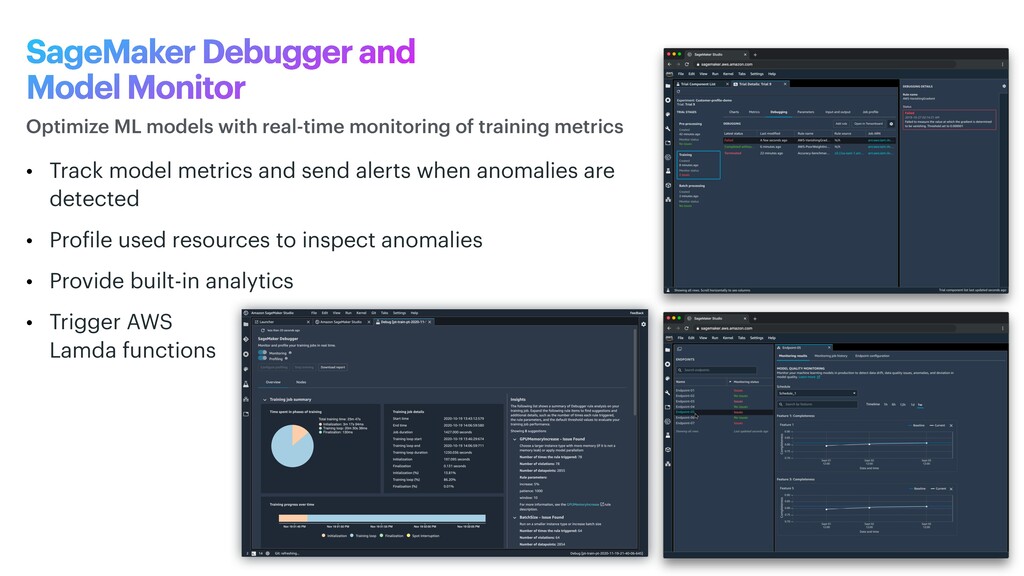
detected • Pro f ile used resources to inspect anomalies • Provide built-in analytics • Trigger AWS Lamda functions Optimize ML models with real-time monitoring of training metrics SageMaker Debugger and Model Monitor
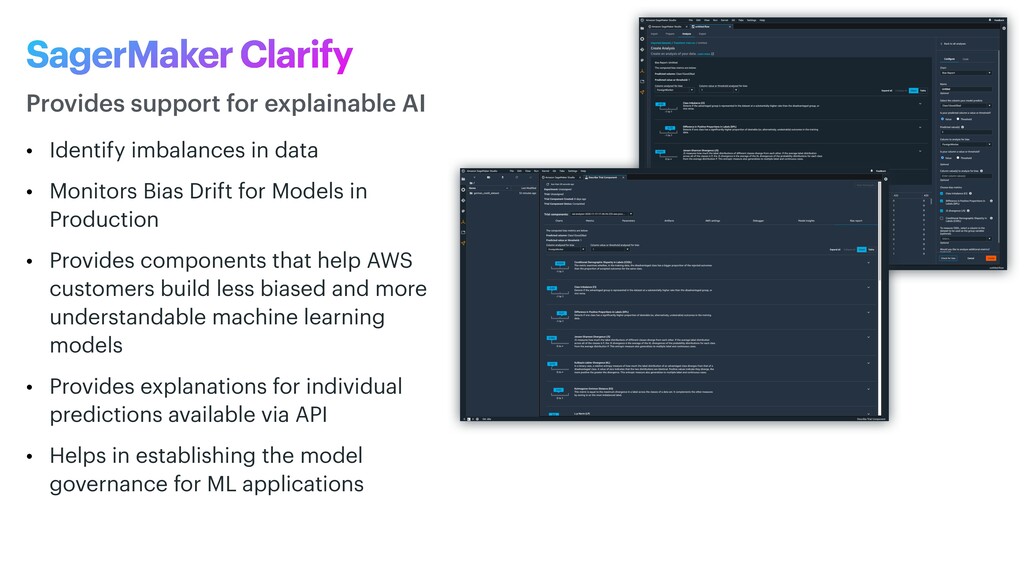
Models in Production • Provides components that help AWS customers build less biased and more understandable machine learning models • Provides explanations for individual predictions available via API • Helps in establishing the model governance for ML applications Provides support for explainable AI SagerMaker Clarify
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}