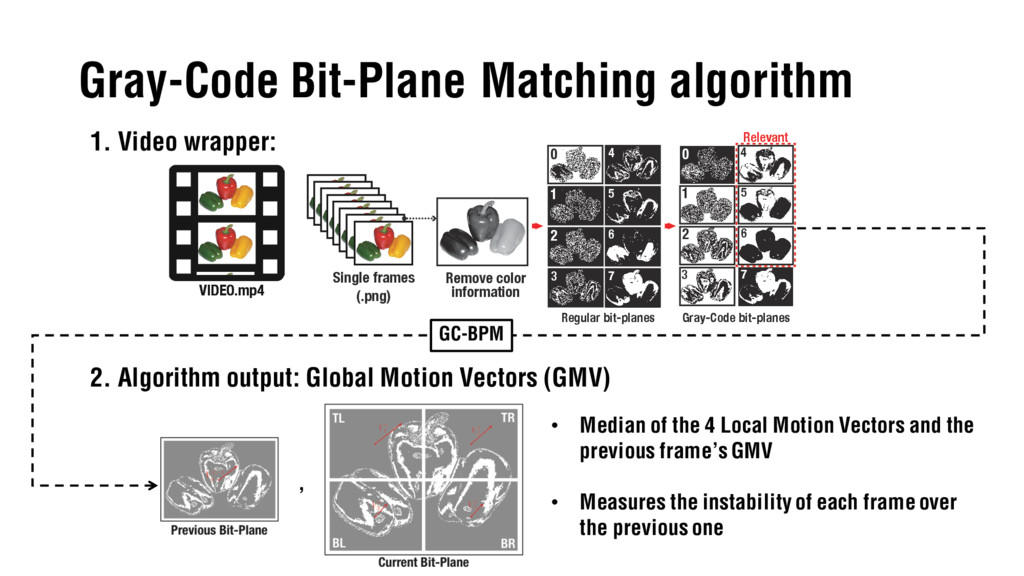
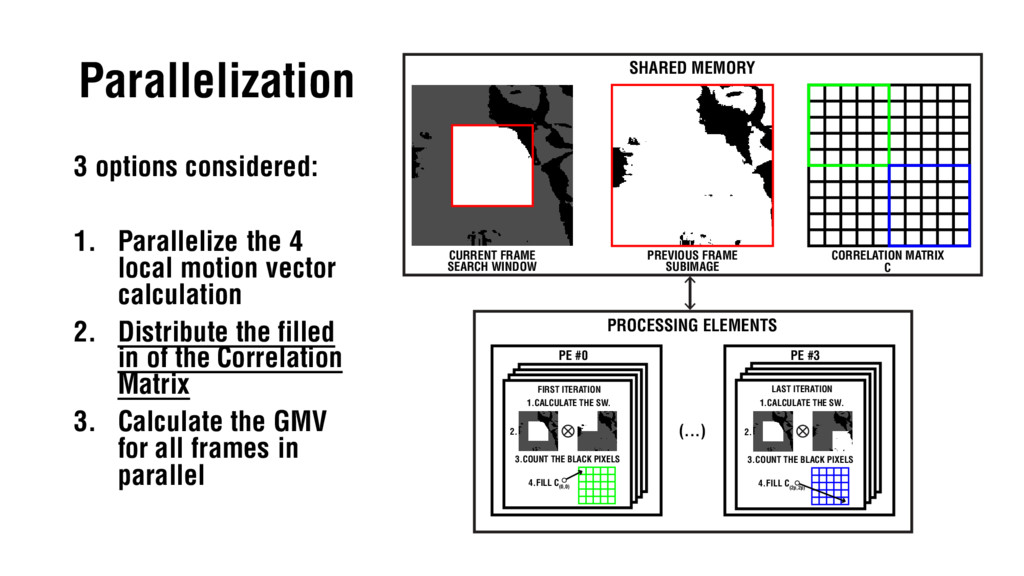
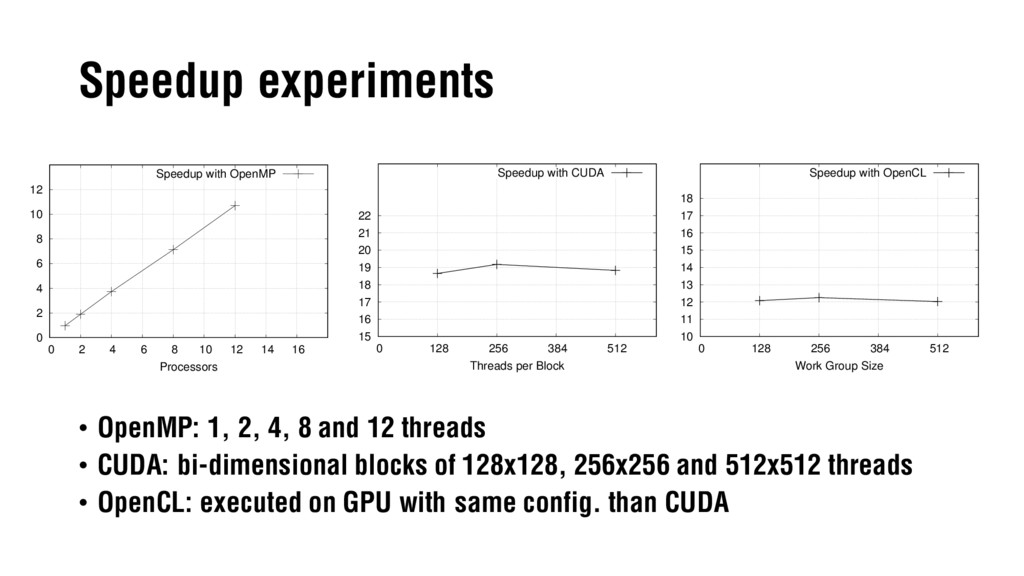
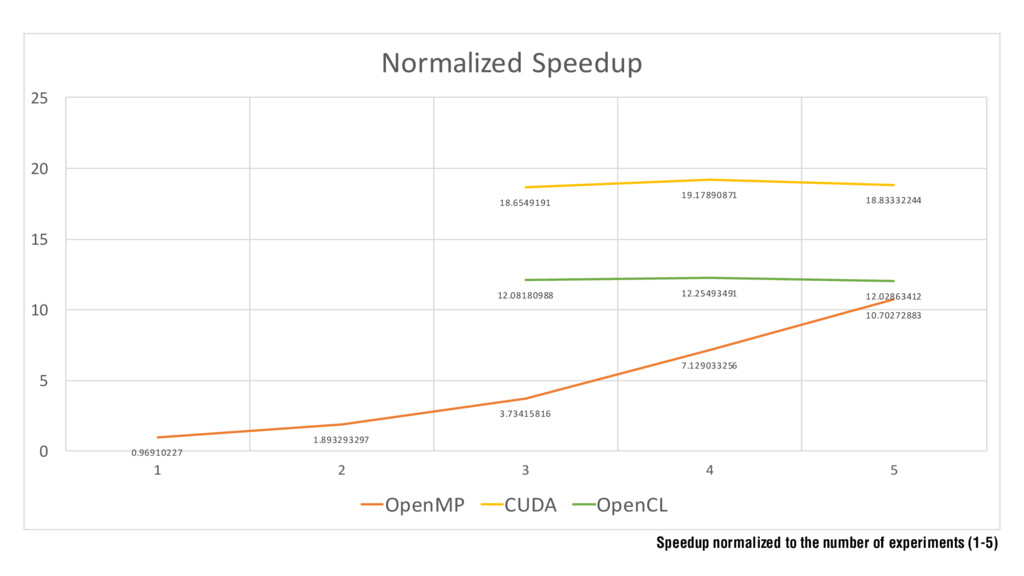
Slides for the defense of my BSc Thesis "Comparison of Parallel Programming APIs" on the Faculty of Information Technology (BUT). They present the work carried developing a video stabilization algorithm based on Gray-Code Bit Plane Matching and porting it to different parallel programming frameworks such as OpenMP, CUDA and OpenCL to compare the speedup results obtained.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}