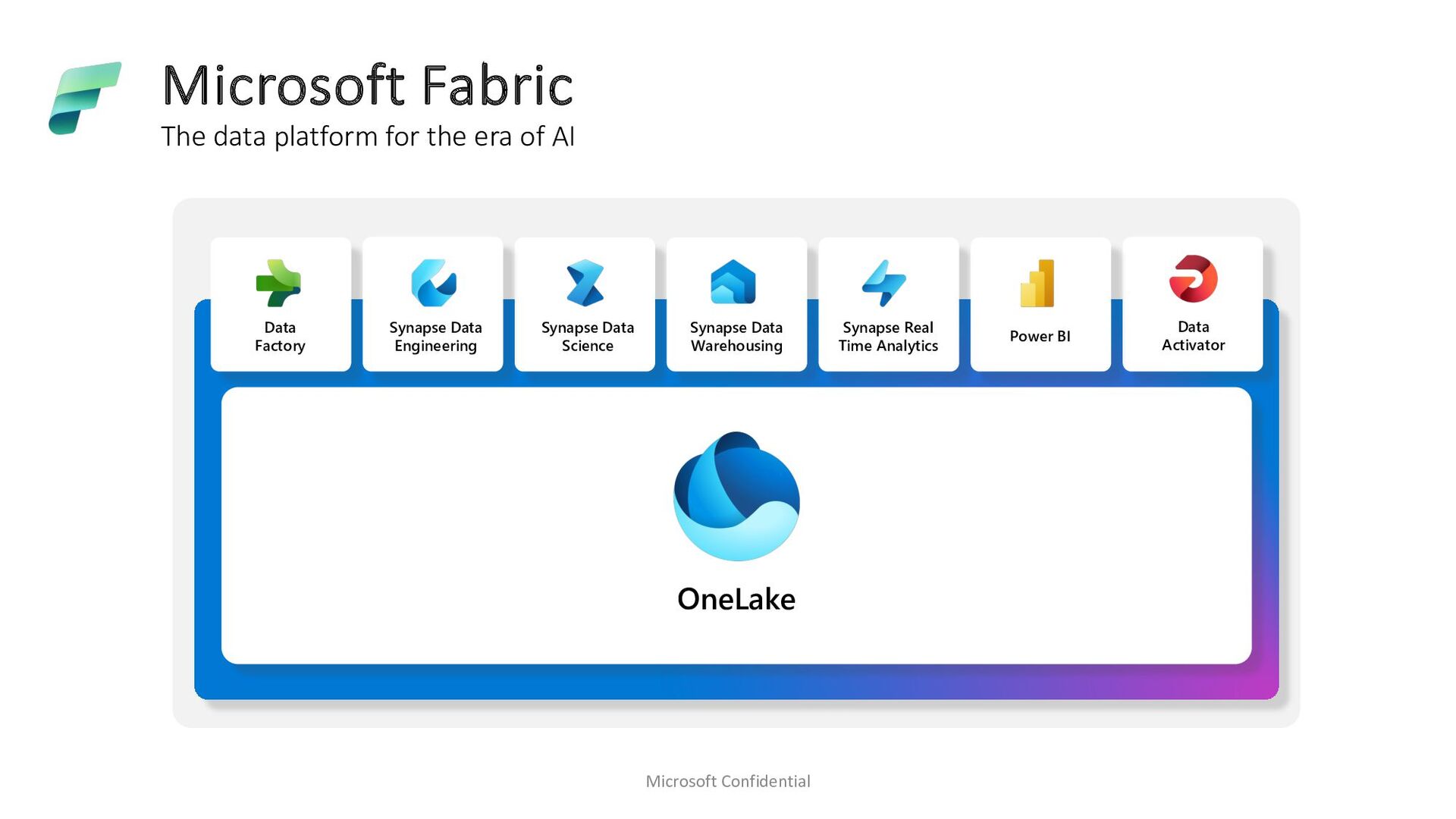
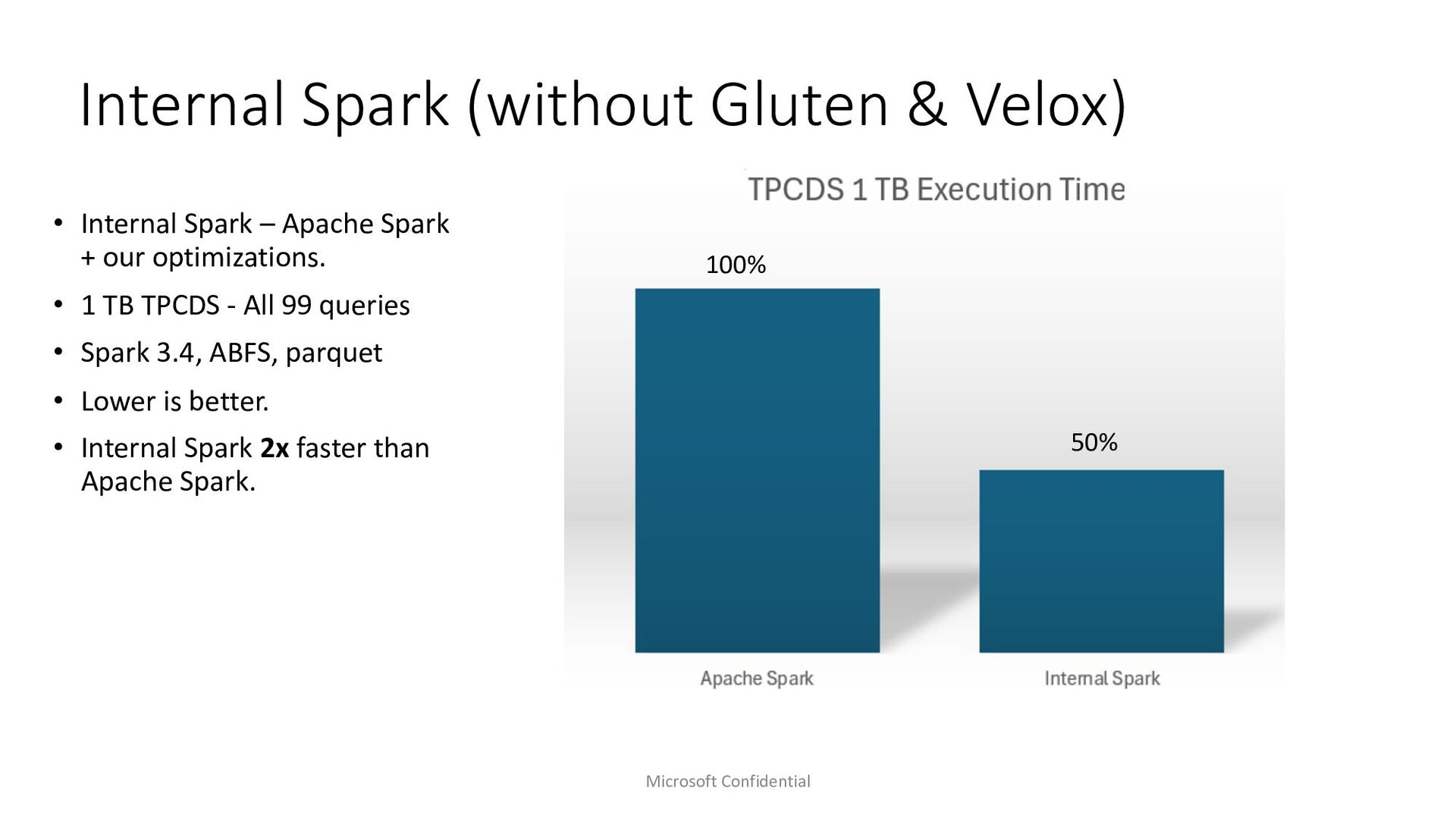
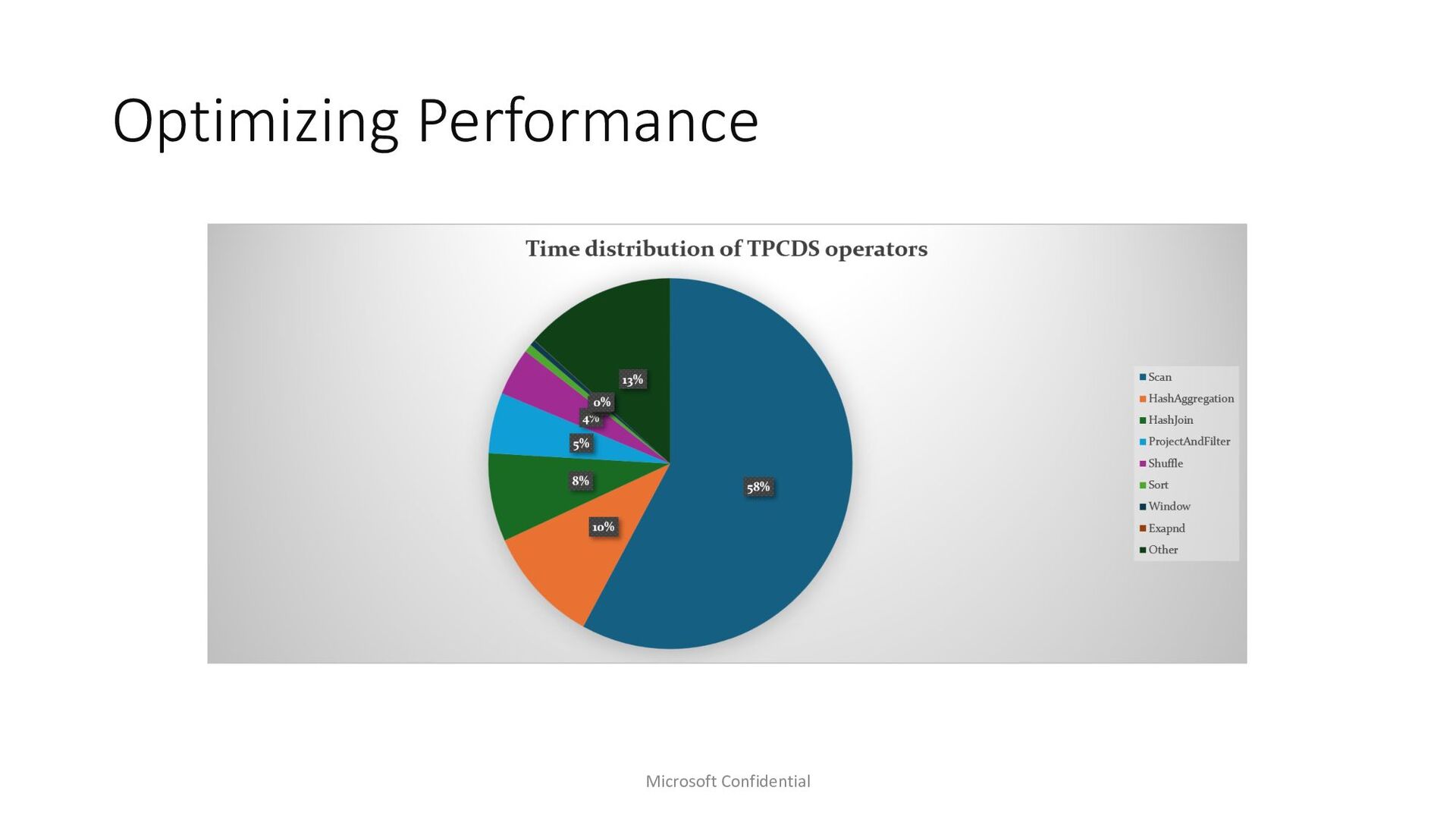
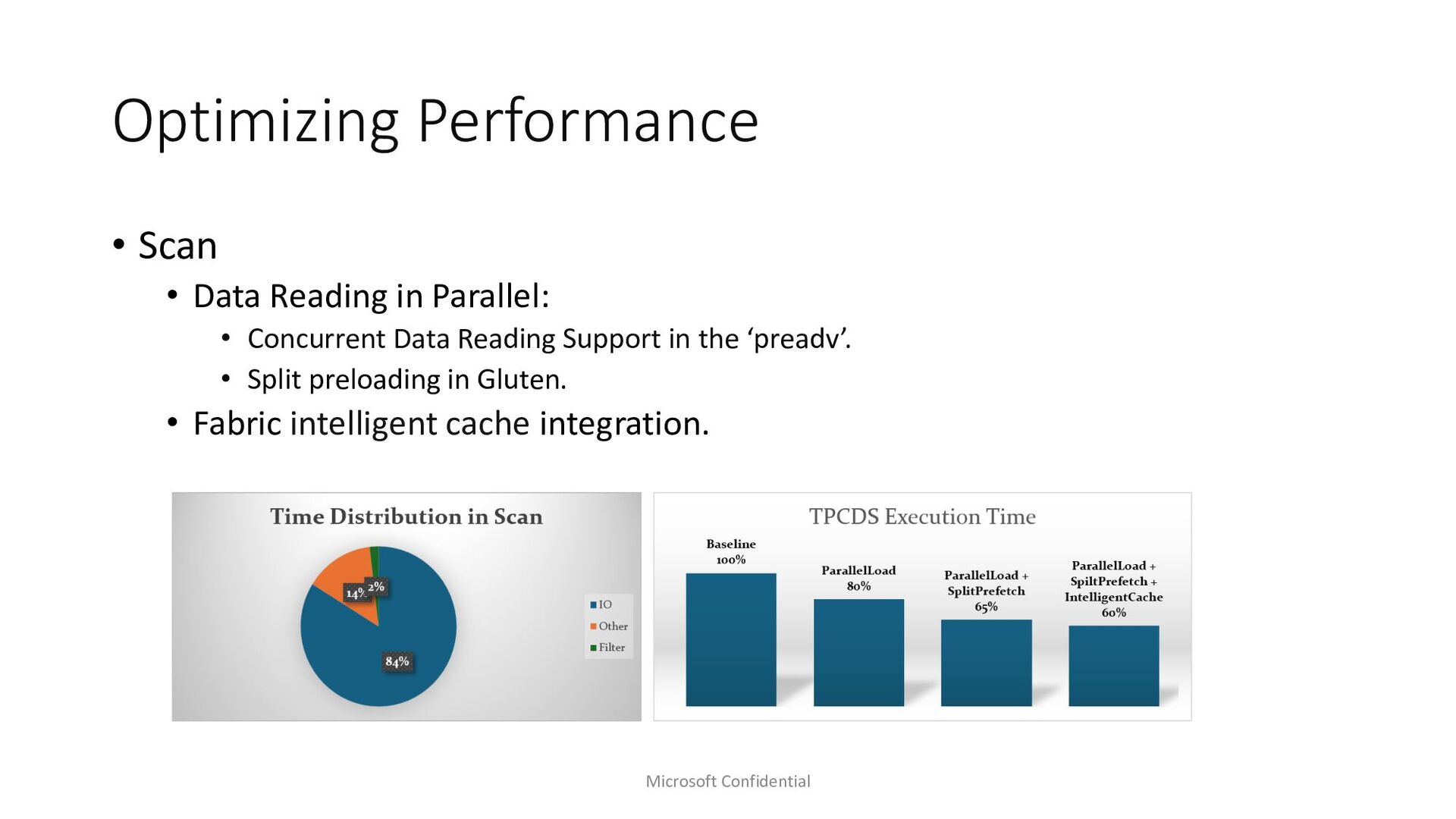
Microsoft Fabric emerges as a cornerstone big data solution, proficient in executing Spark workloads. In our quest to enhance Spark performance, we’ve made substantial investments in query optimization and execution to cater to our customers’ needs. Amidst exploring avenues for faster query execution engines, we delved into existing solutions such as Weld. In this presentation, we aim to elucidate our decision of adopting Velox and Gluten stack as our native query execution engine for Spark. We’ll delve into the intricacies of integrating it seamlessly within the Azure Fabric ecosystem, including features like ABFS support and integration with read cache. Our efforts have yielded remarkable results, with performance gains reaching up to 2x faster TPCDS benchmarks. The gains are not limited to just industry benchmarks rather are evident from customer testing done with internal customers as well. Join us as we share insights, lessons learned, and the transformative impact of leveraging Velox and Gluten stack within the Microsoft Fabric environment.
Zhen Li
Software Engineer at Microsoft
Swinky Mann
Software Engineer at Microsoft
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}