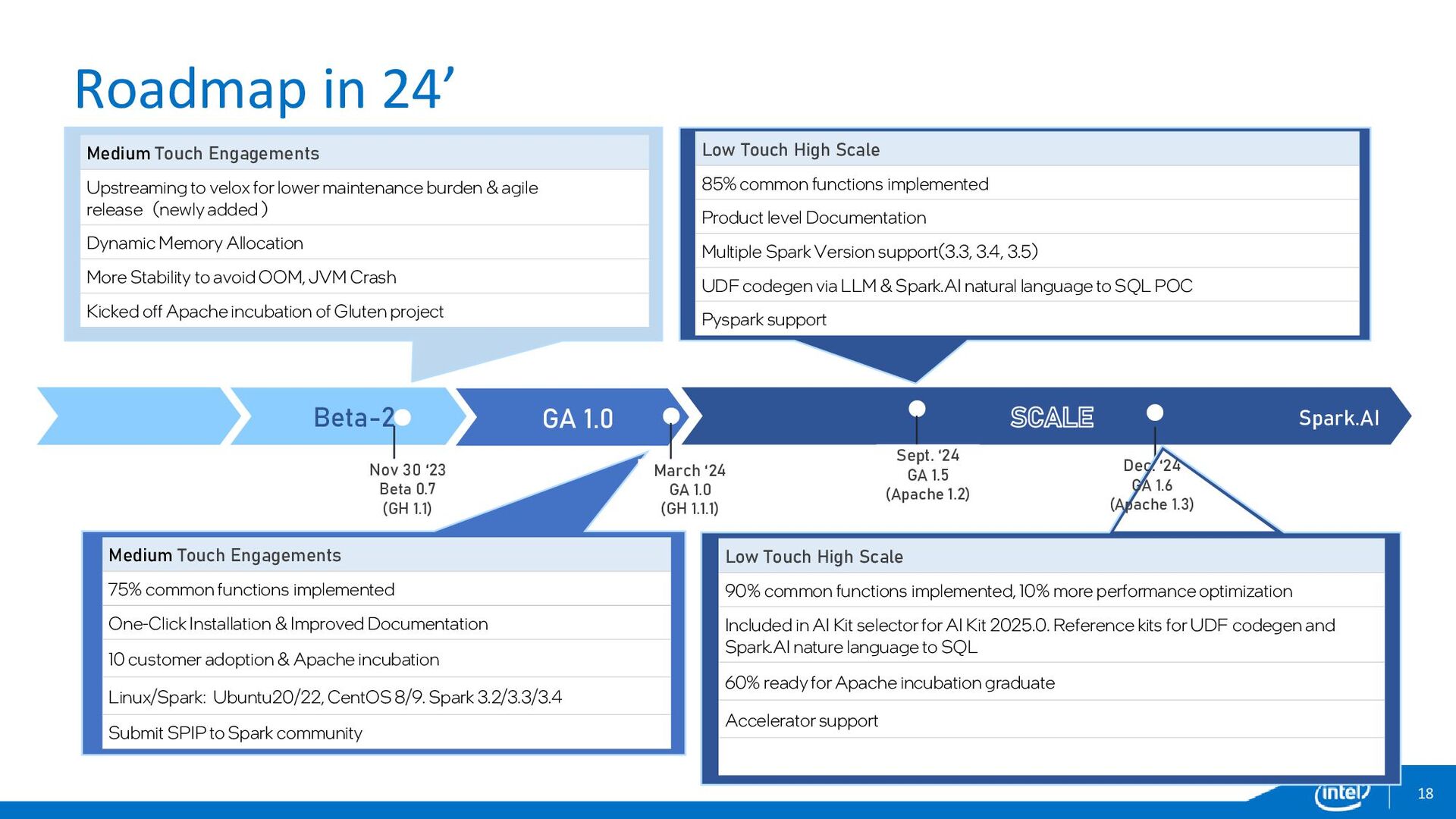
project Q1 Release: Mar(before contribute to Apache), Sep(Apache release), may add several minor releases Q1, Q2, Q3, Q4 Improve Quality by adding more tests(new CI/CD, pre-built docker image) Q1, Q2 Easier installation(pip, conda, docker, use static building to support more OS) Q1, Q2, Q3, Q4 More Spark version support(spark 3.4/3.5/4.0) Q1, Q2, Q3, Q4 Increase coverage for Spark functions/operators(90% on common functions, 100% on common operators) Q1, Q2, Q3, Q4 PySpark support(PyArrow UDF, ML workloads) Q1, Q2, Q3, Q4 Enhance spill support(sort, hash join, hash aggregation) Q1, Q2, Q3, Q4 Support more file formats(CSV, JSON, HIVE Text) Q1, Q2, Q3, Q4 Datalake support(iceberg, delta lake, hudi) Q1, Q2, Q3, Q4 Remote shuffle service support(Apache Uniffle) Q1 Columnar shuffle improvement(sort-based shuffle, performance improvement) Q1, Q2 More data source connectors(abfs, gcs, hdfs viewfs/federation, Alluxio) Q1, Q2, Q3 POC for more accelerators(GPU, FPGA) Q1, Q2, Q3, Q4 Gluten-indicator: tools to check potential benefits from Gluten vs. vanilla Spark && auto turning on Spark configurations Q1, Q2, Q3, Q4
{kind=link}
{kind=link}
{kind=link}
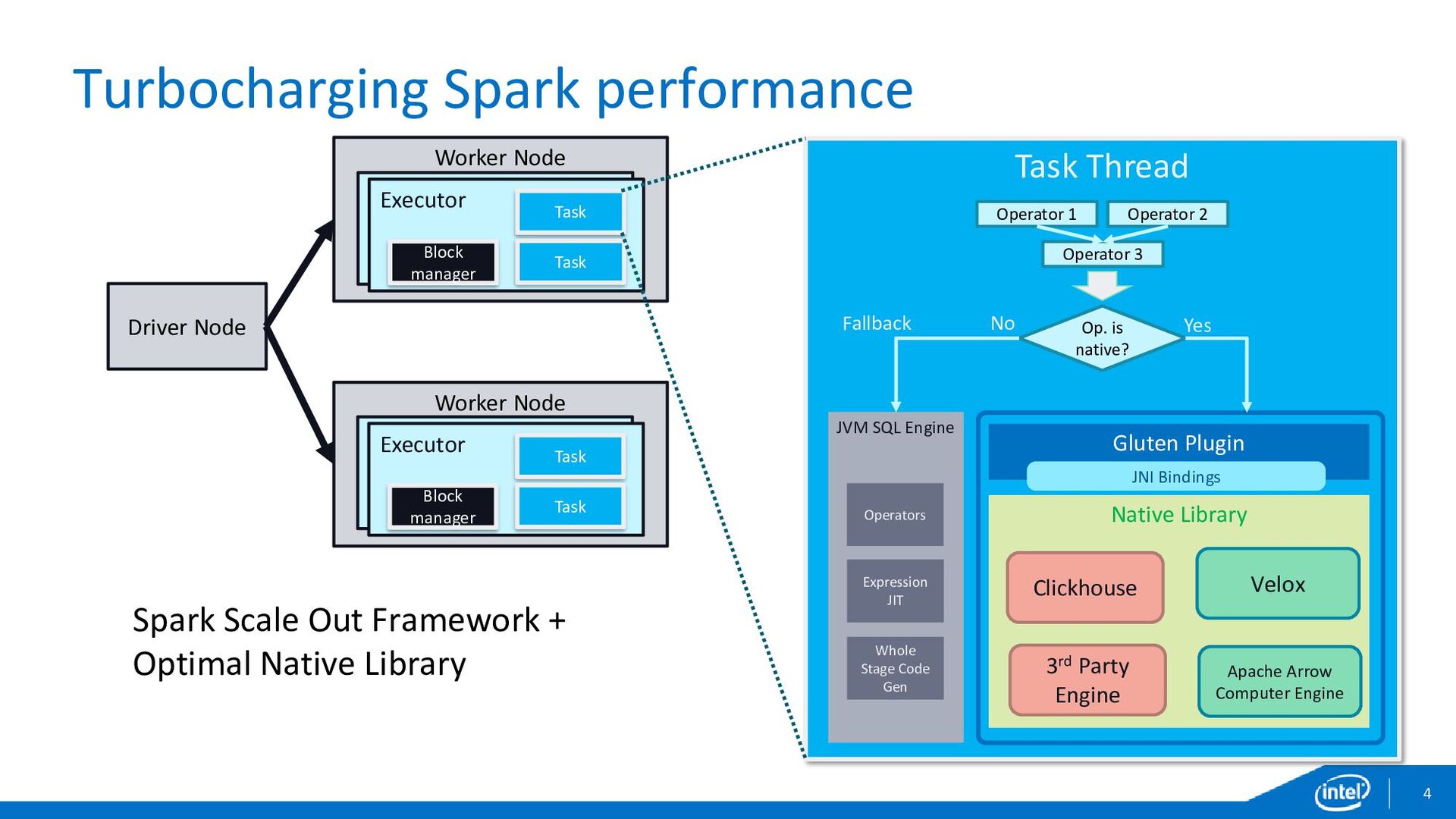{kind=link}
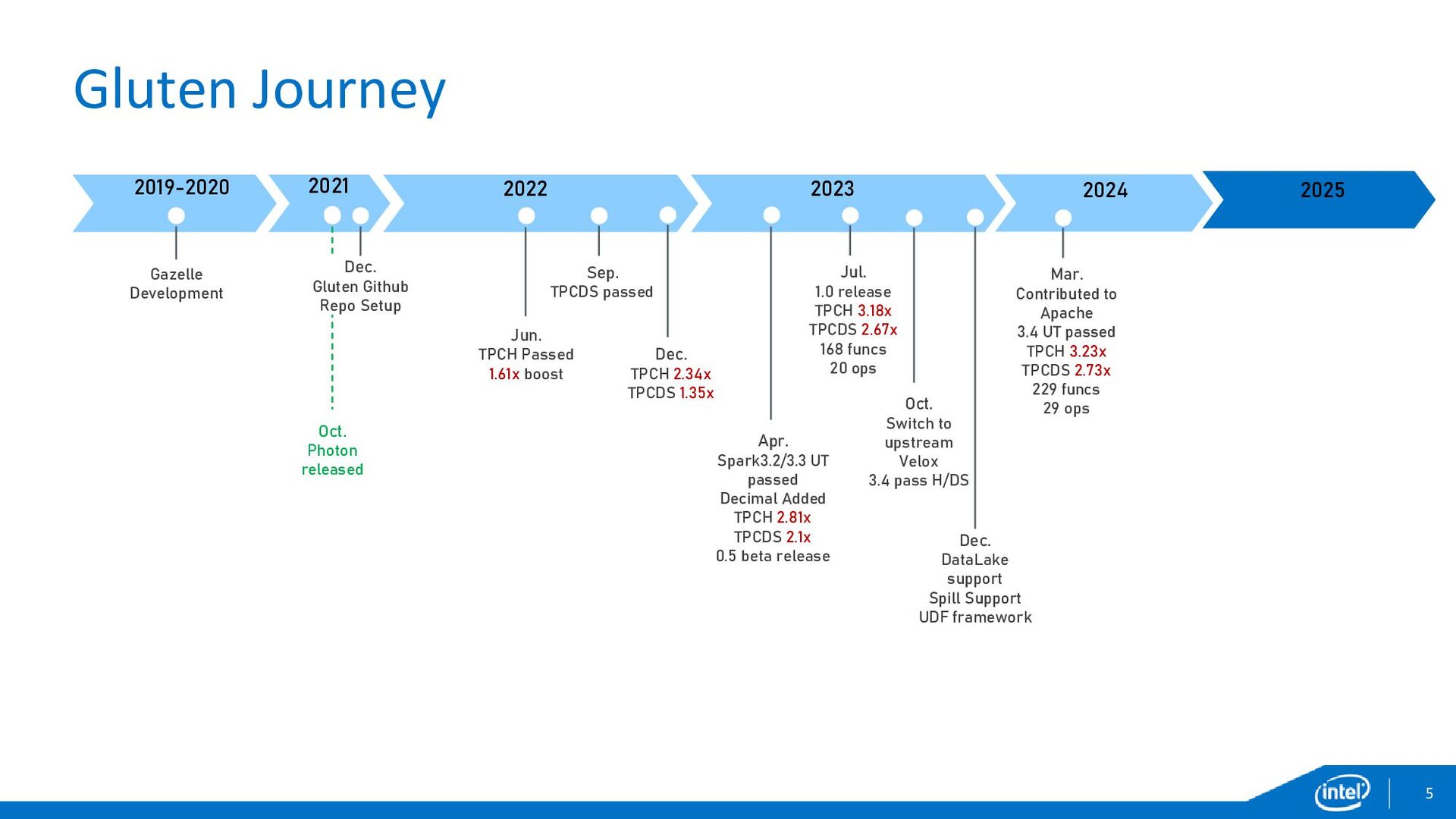{kind=link}
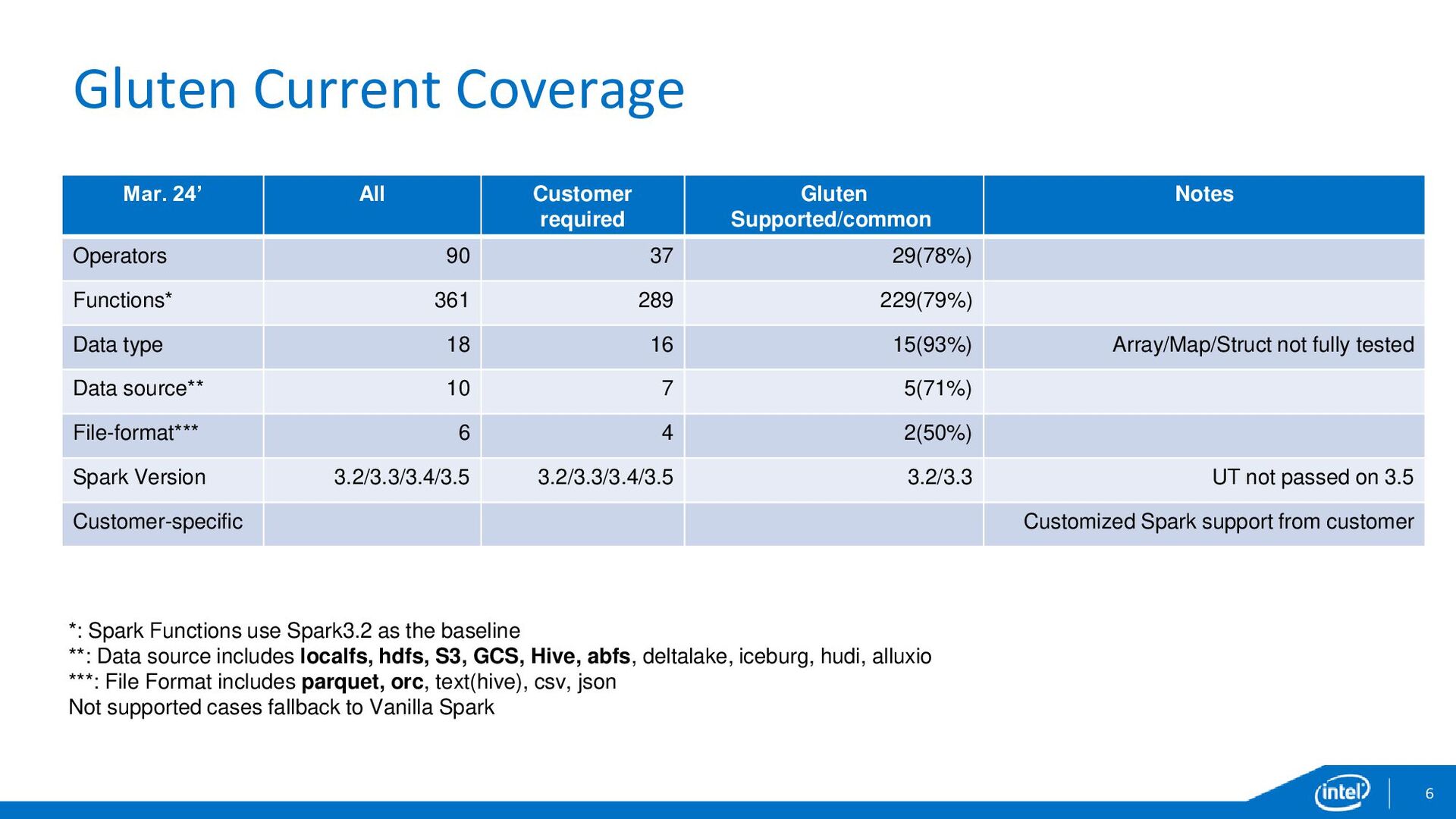{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
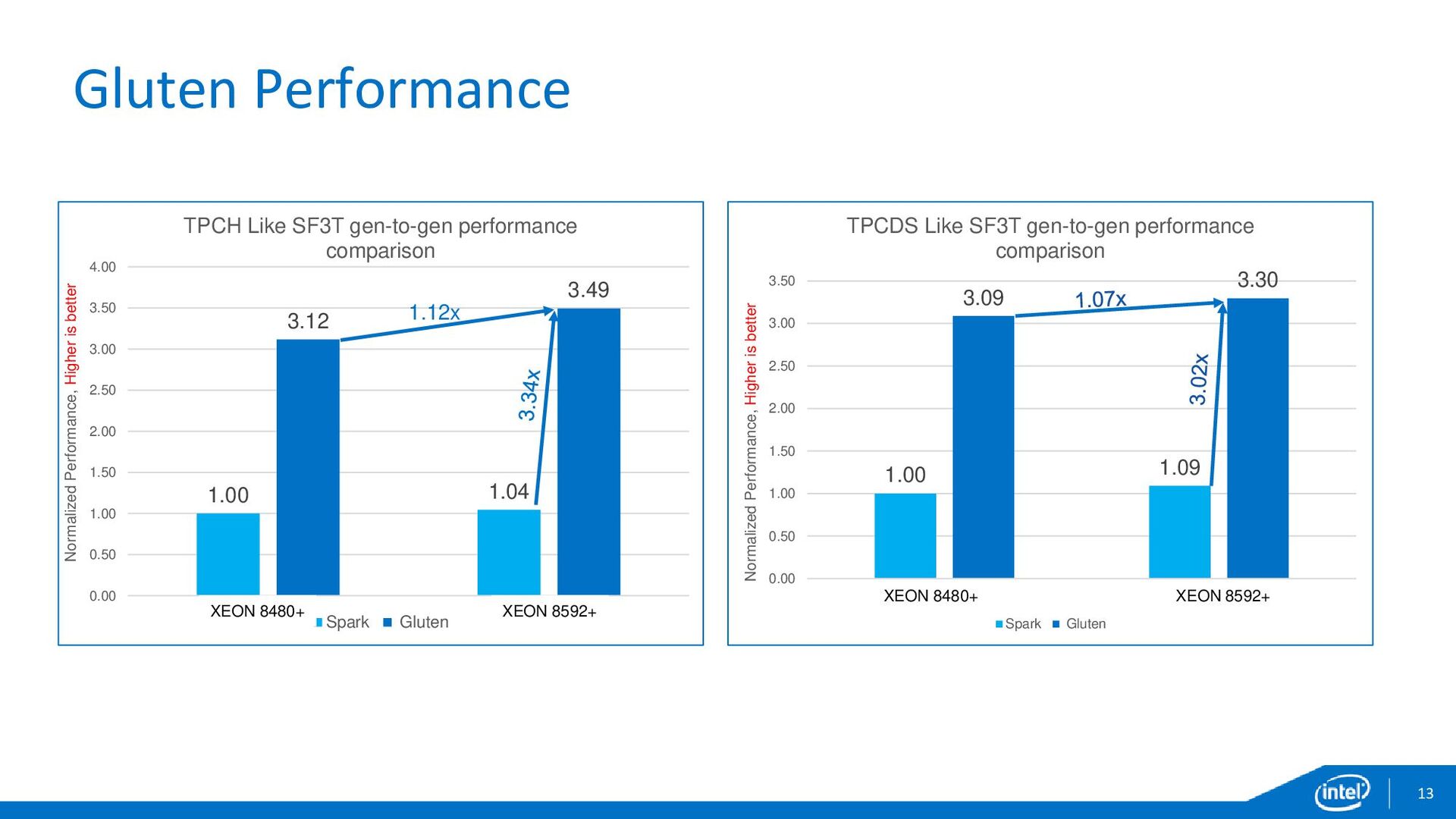{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}