Theseus is a composable, scalable, distributed high performance data analytics engine. This talk is about how the GPU accelerator native engine is now hardware agnostic, by leveraging Velox as a CPU backend.
William Malpica
Distinguished Engineer & Co-Founder at Voltron Data
Amin Aramoon, PhD
Software Developer at Voltron Data
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
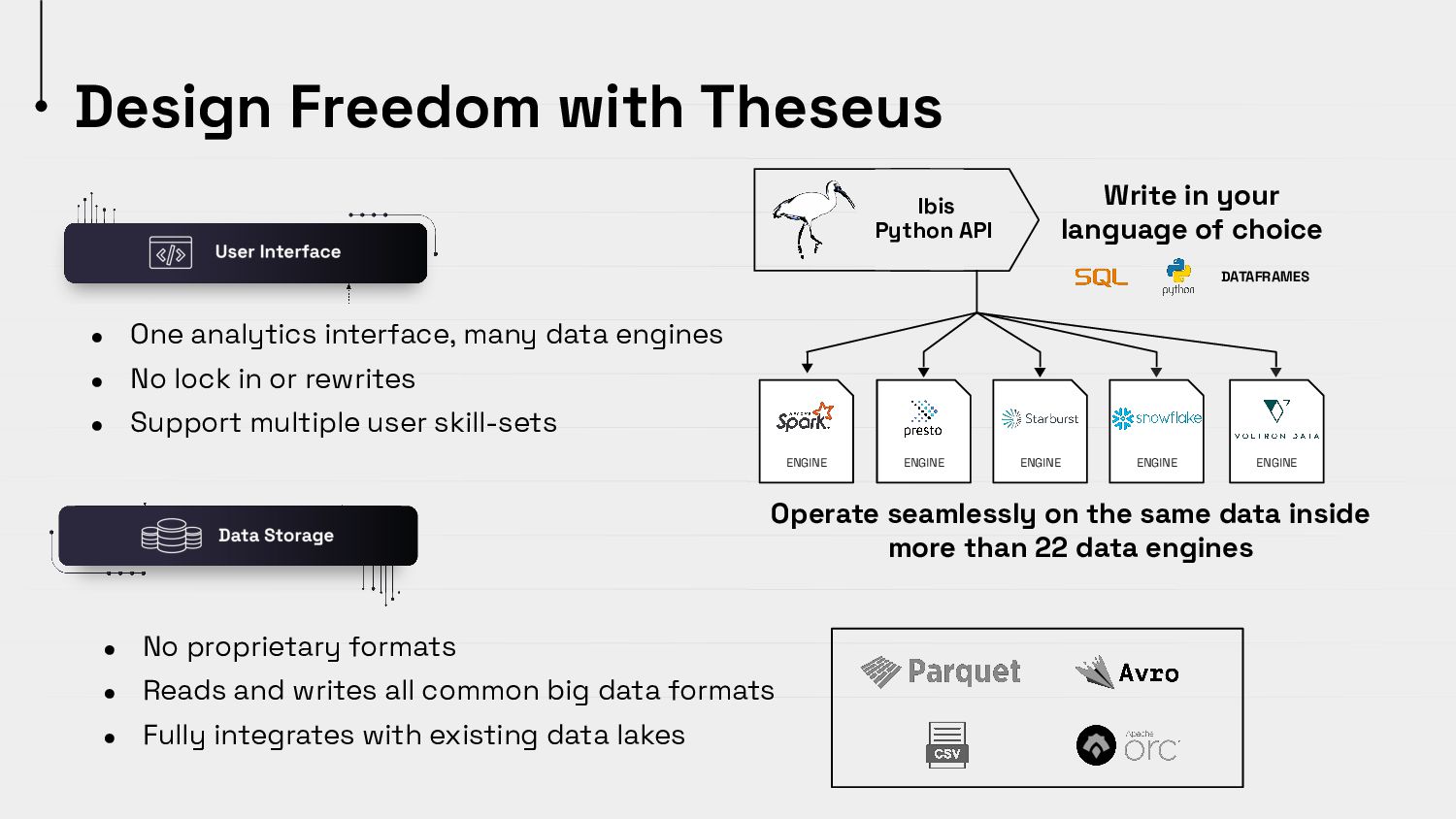{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
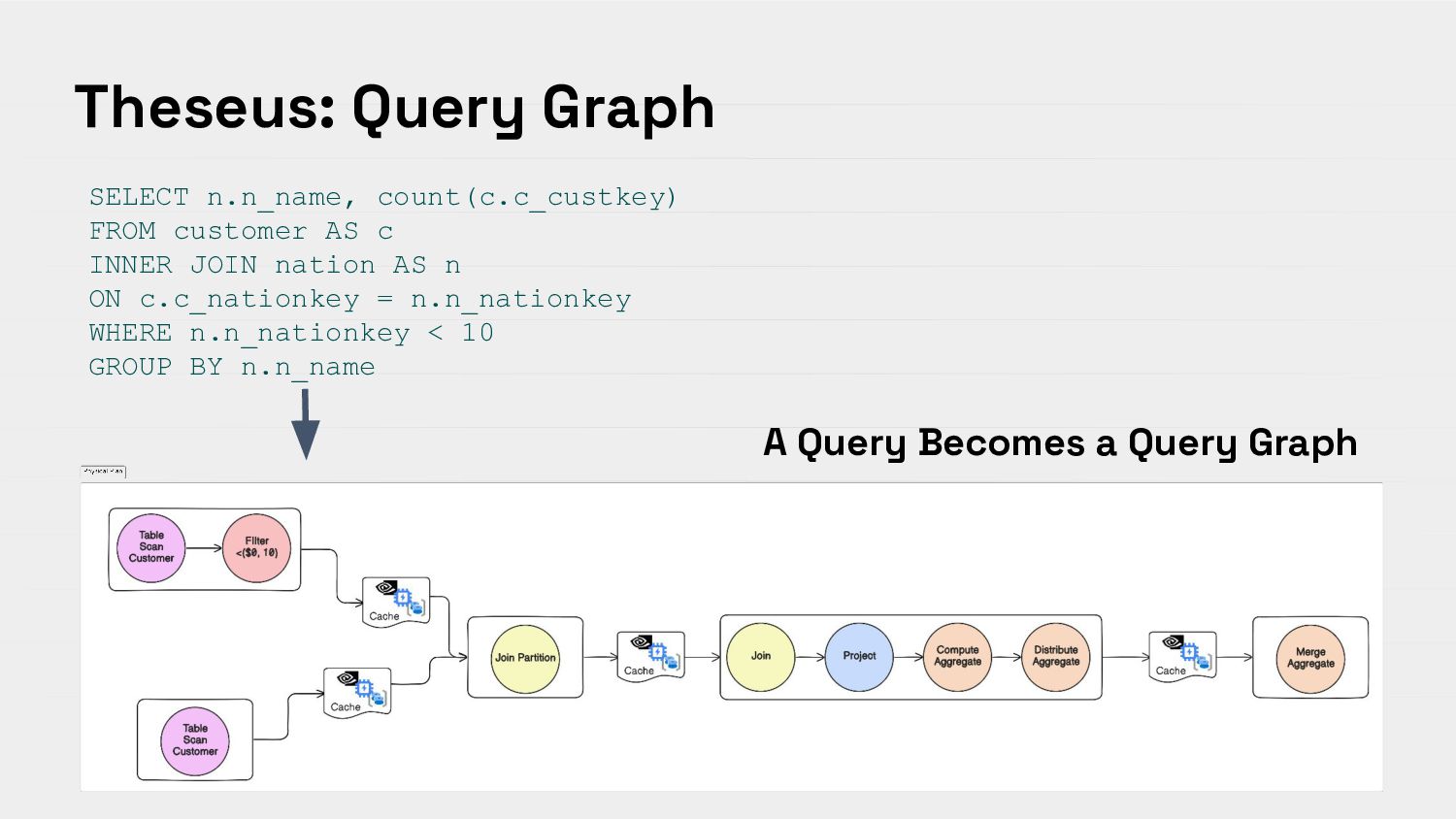{kind=link}
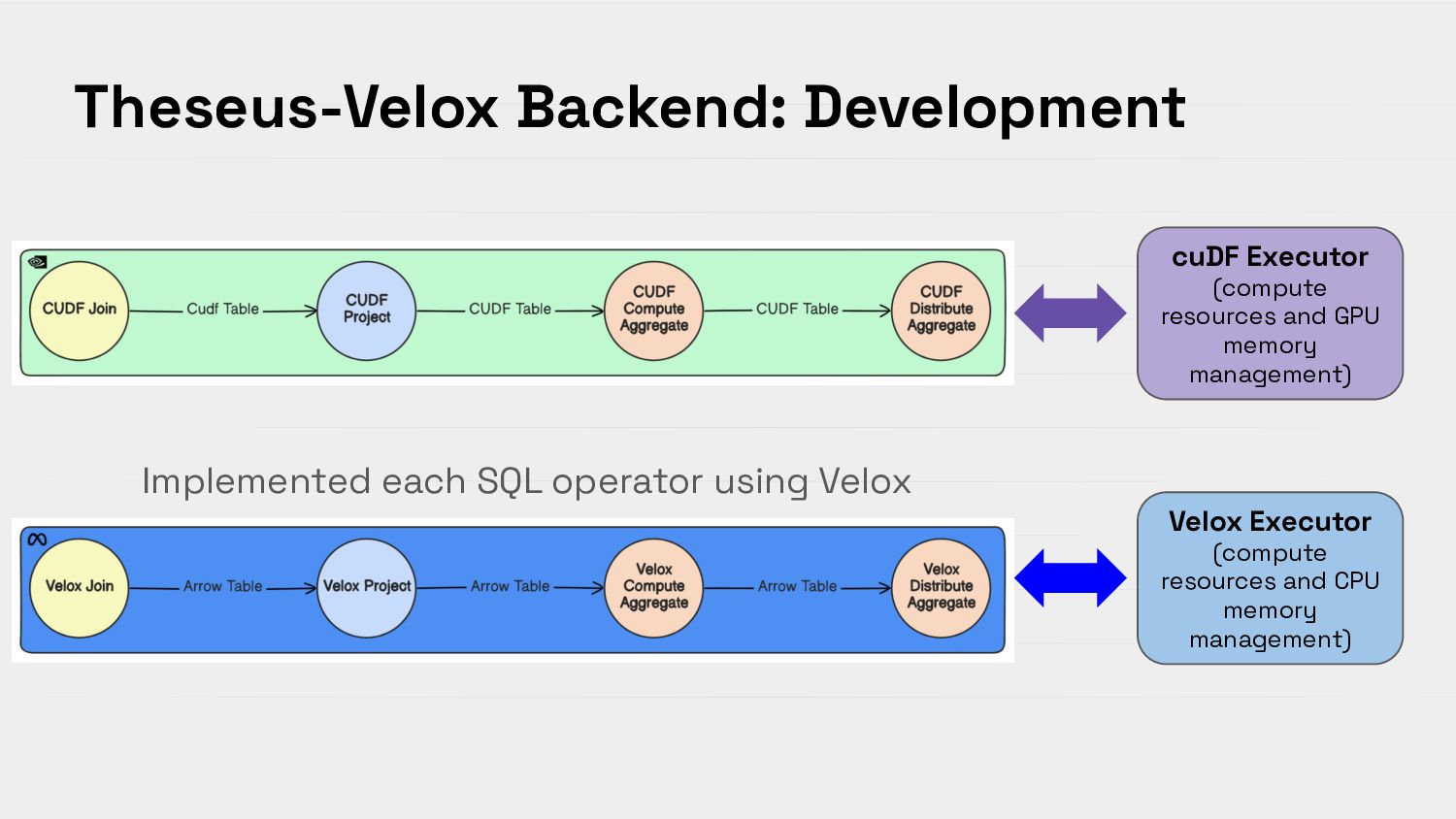{kind=link}
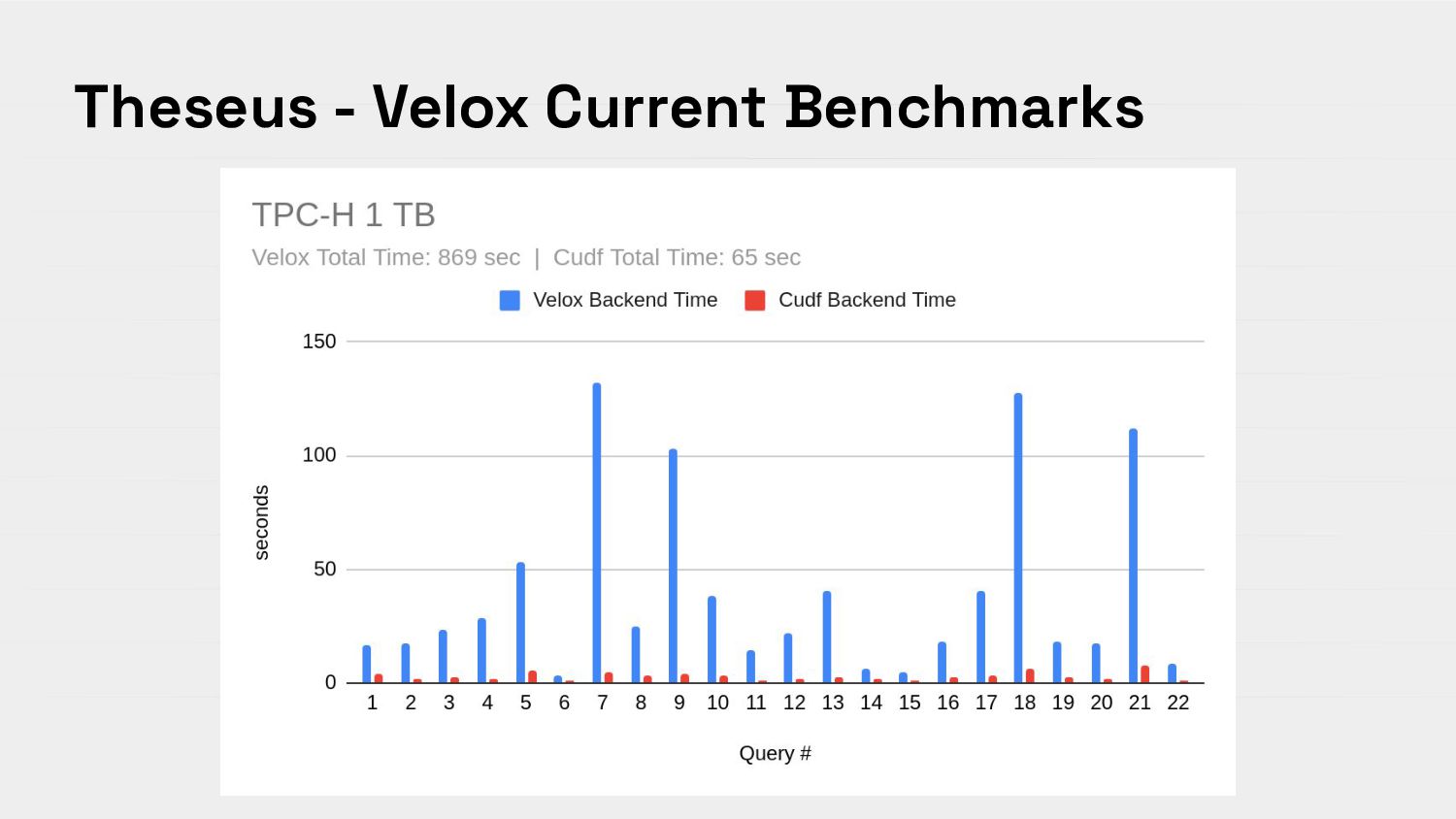{kind=link}
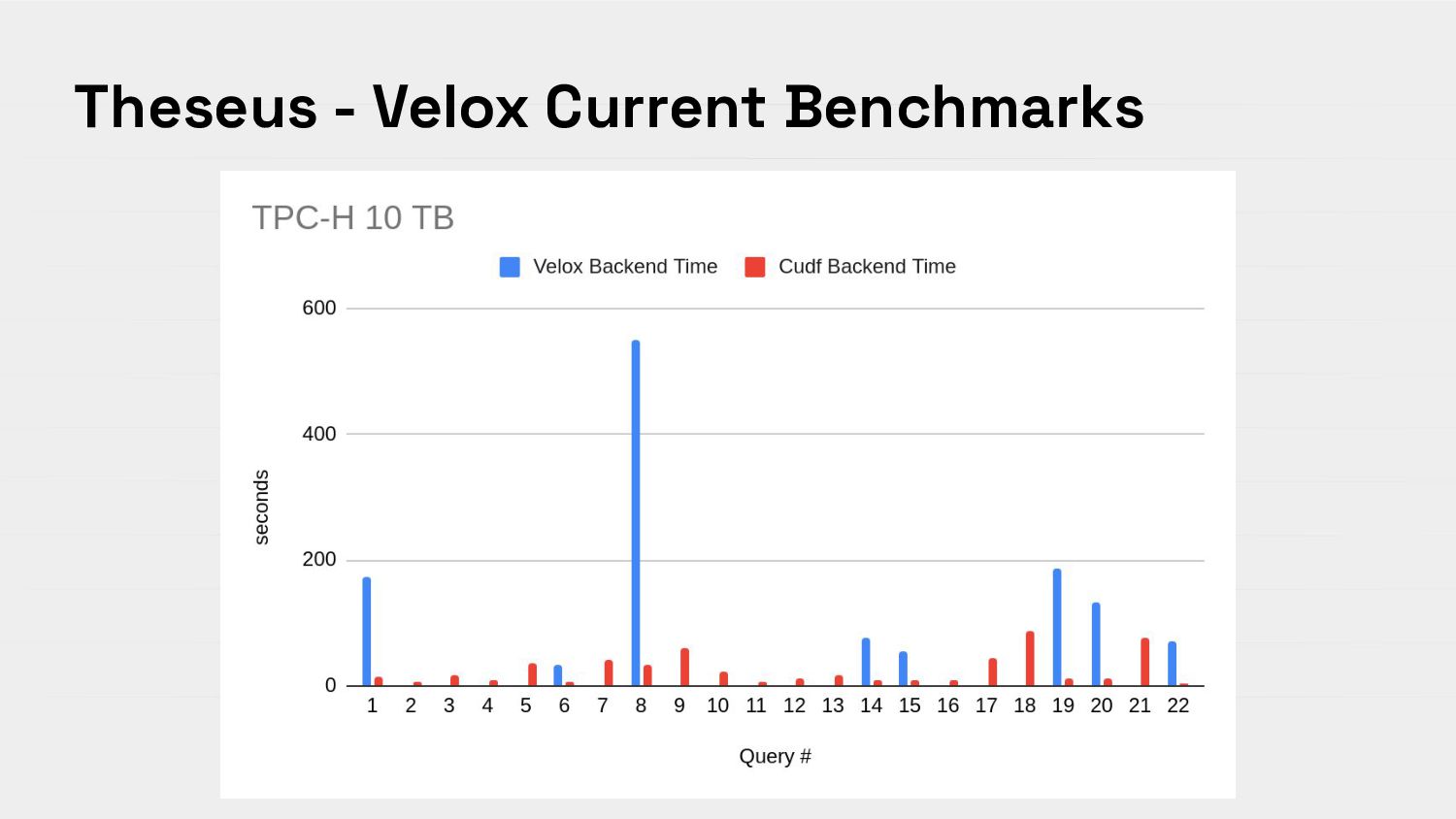{kind=link}
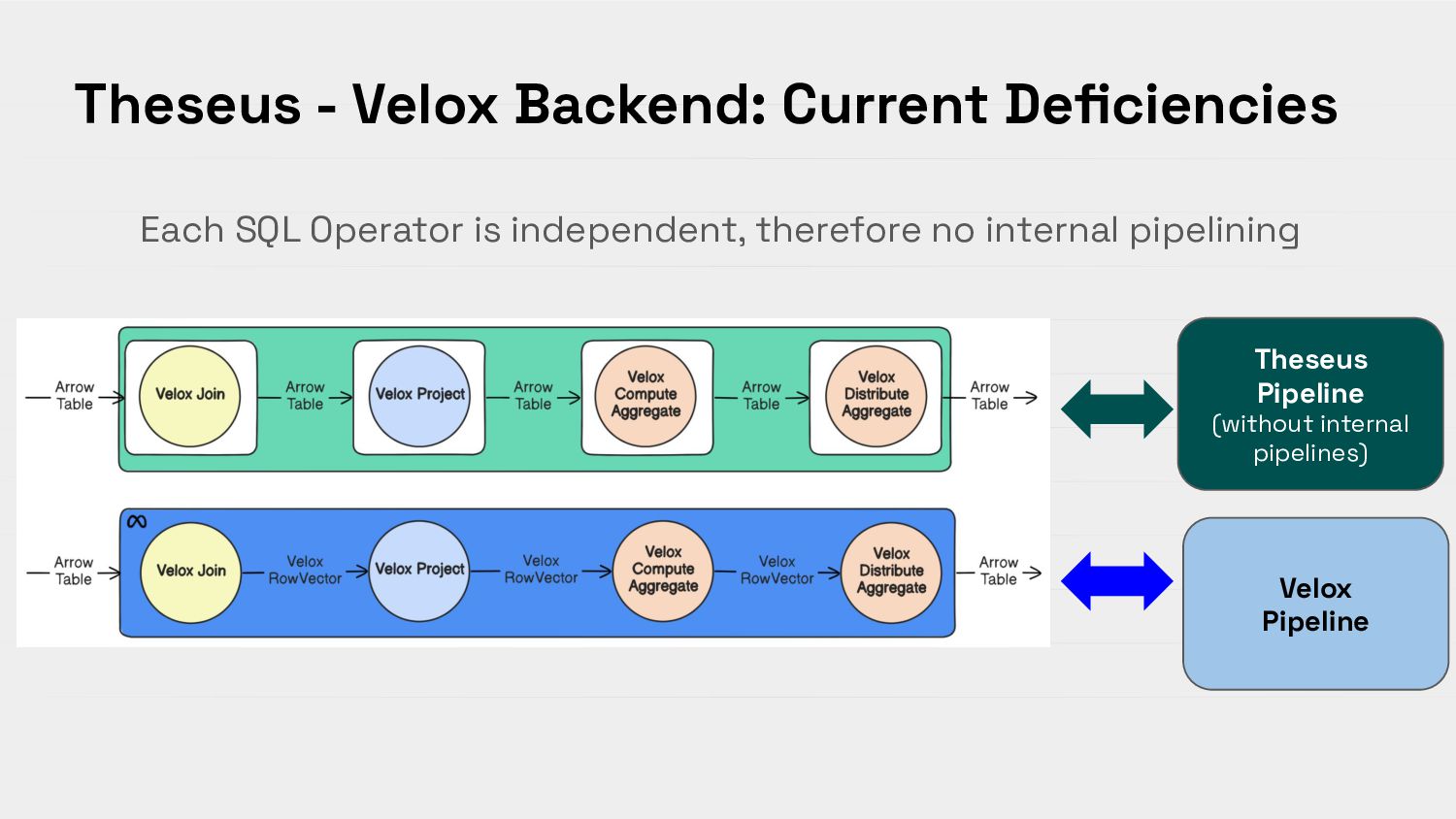{kind=link}
{kind=link}
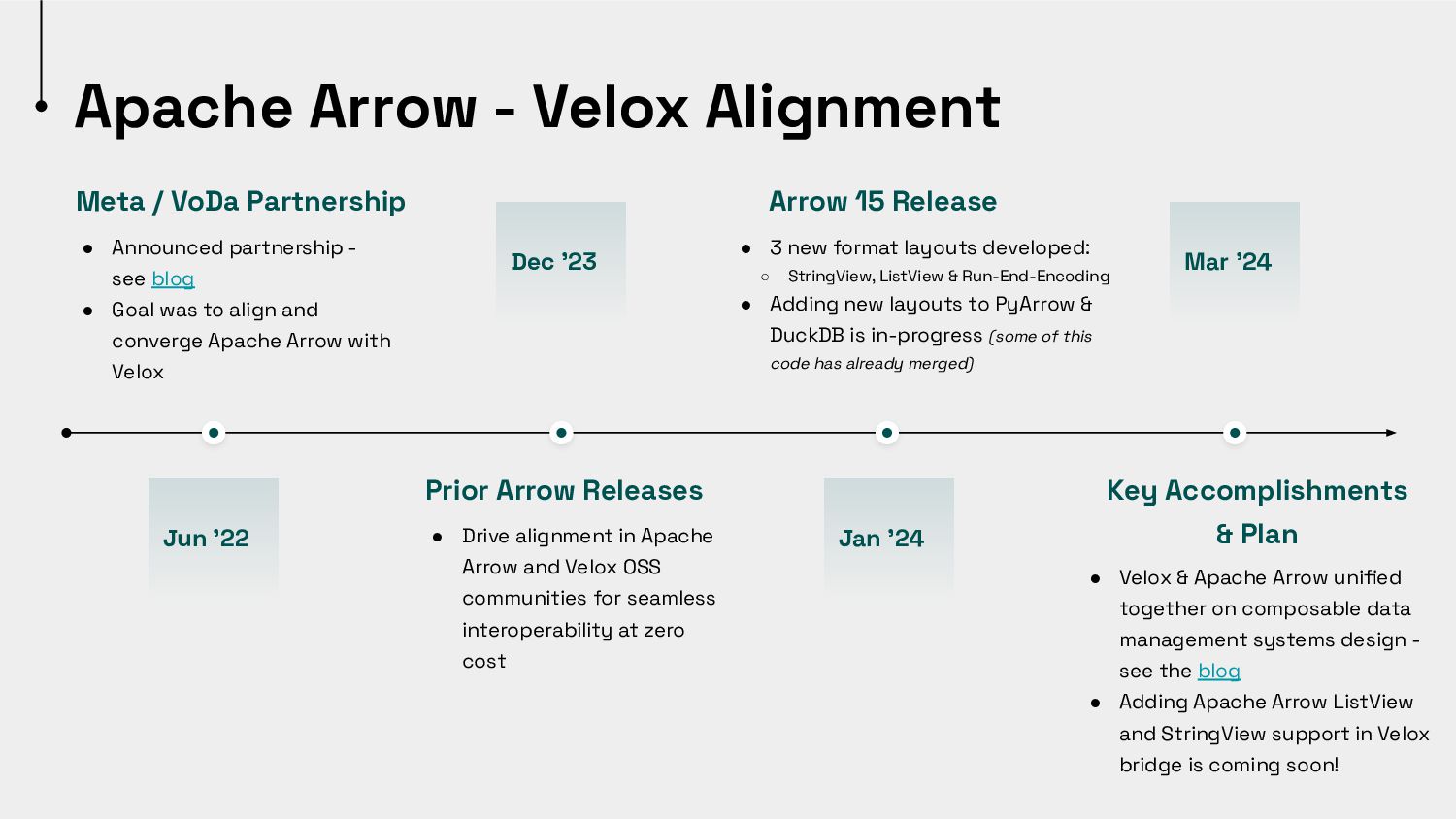{kind=link}
{kind=link}
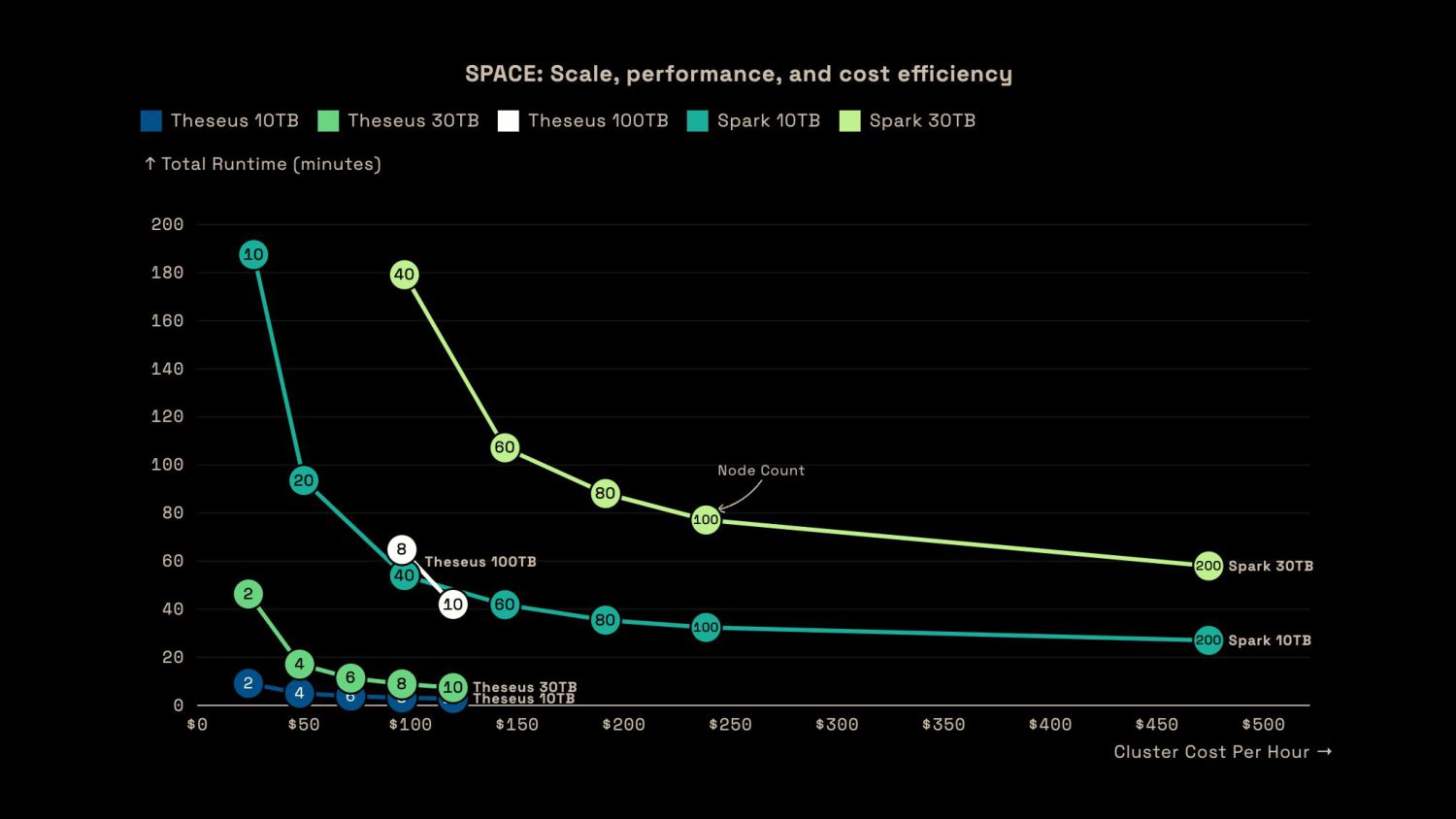{kind=link}
{kind=link}