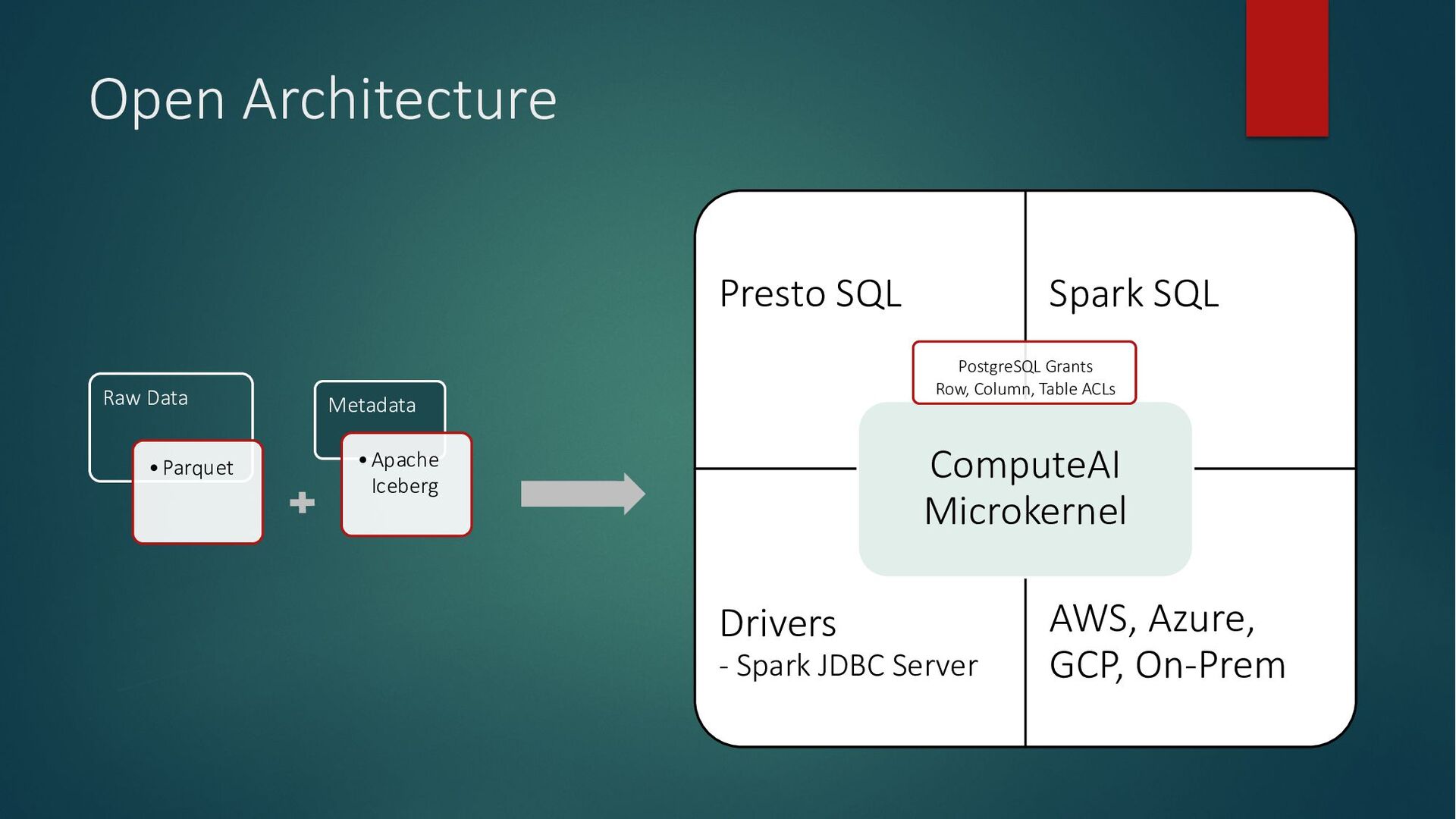
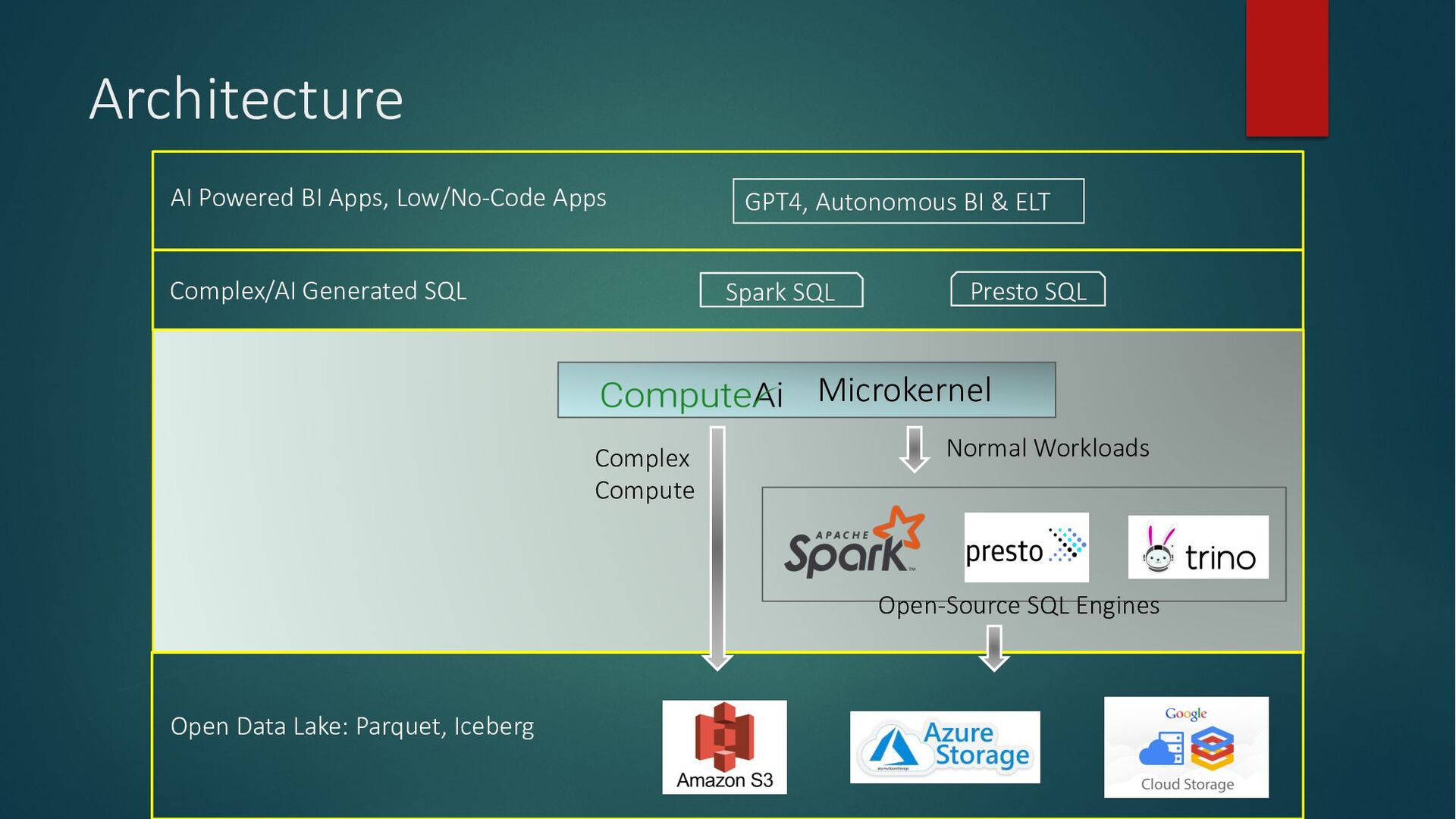
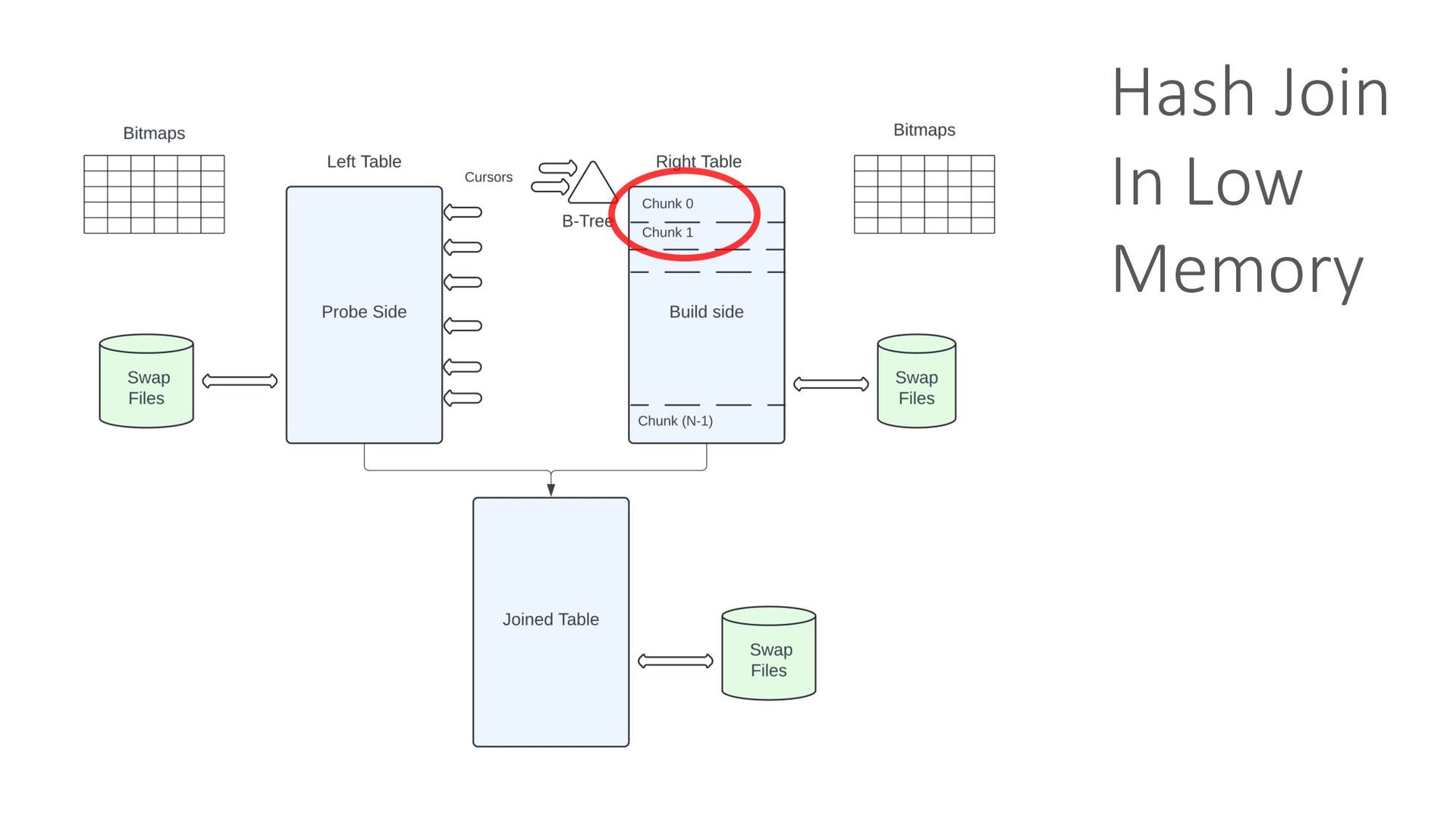
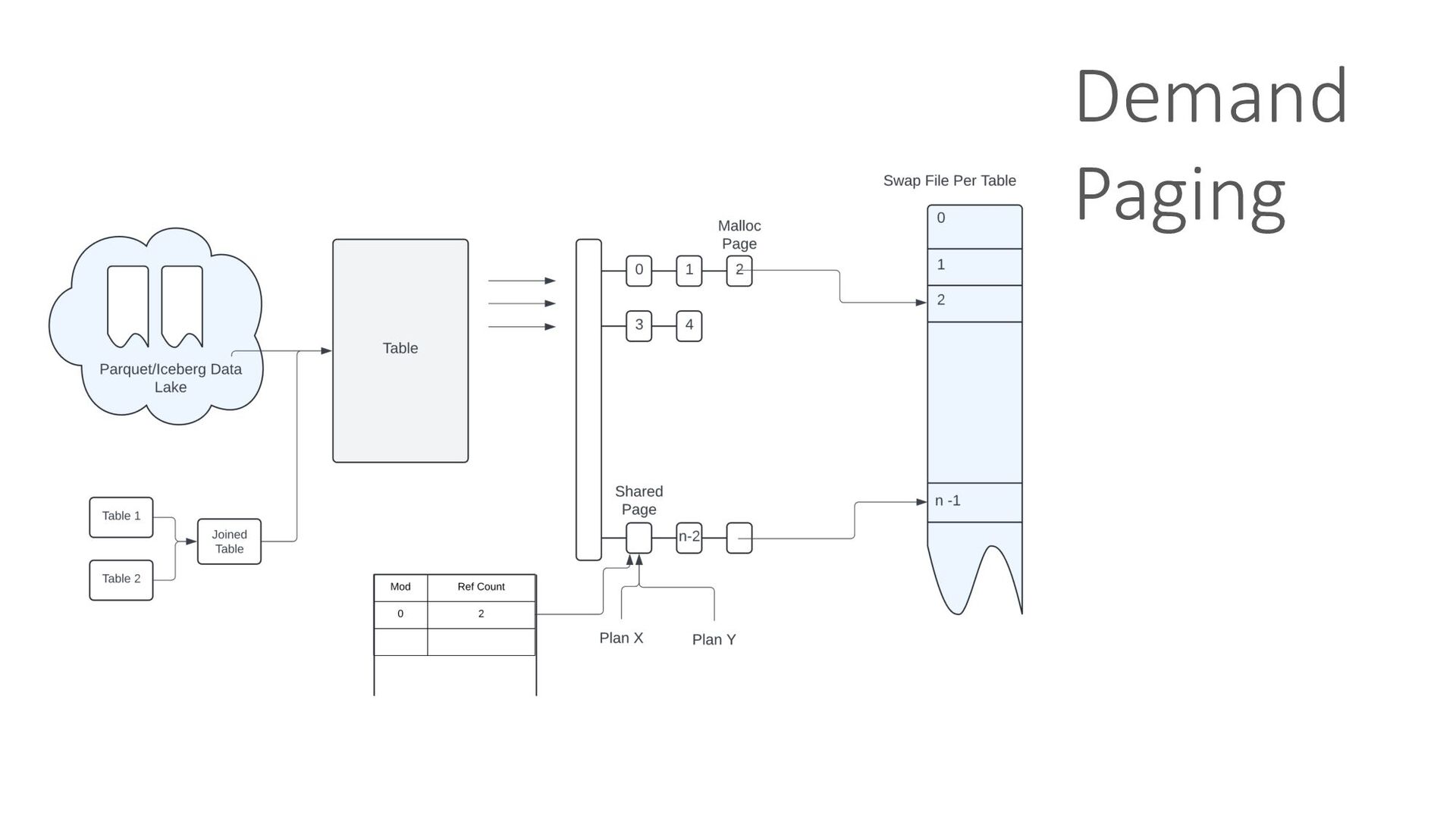
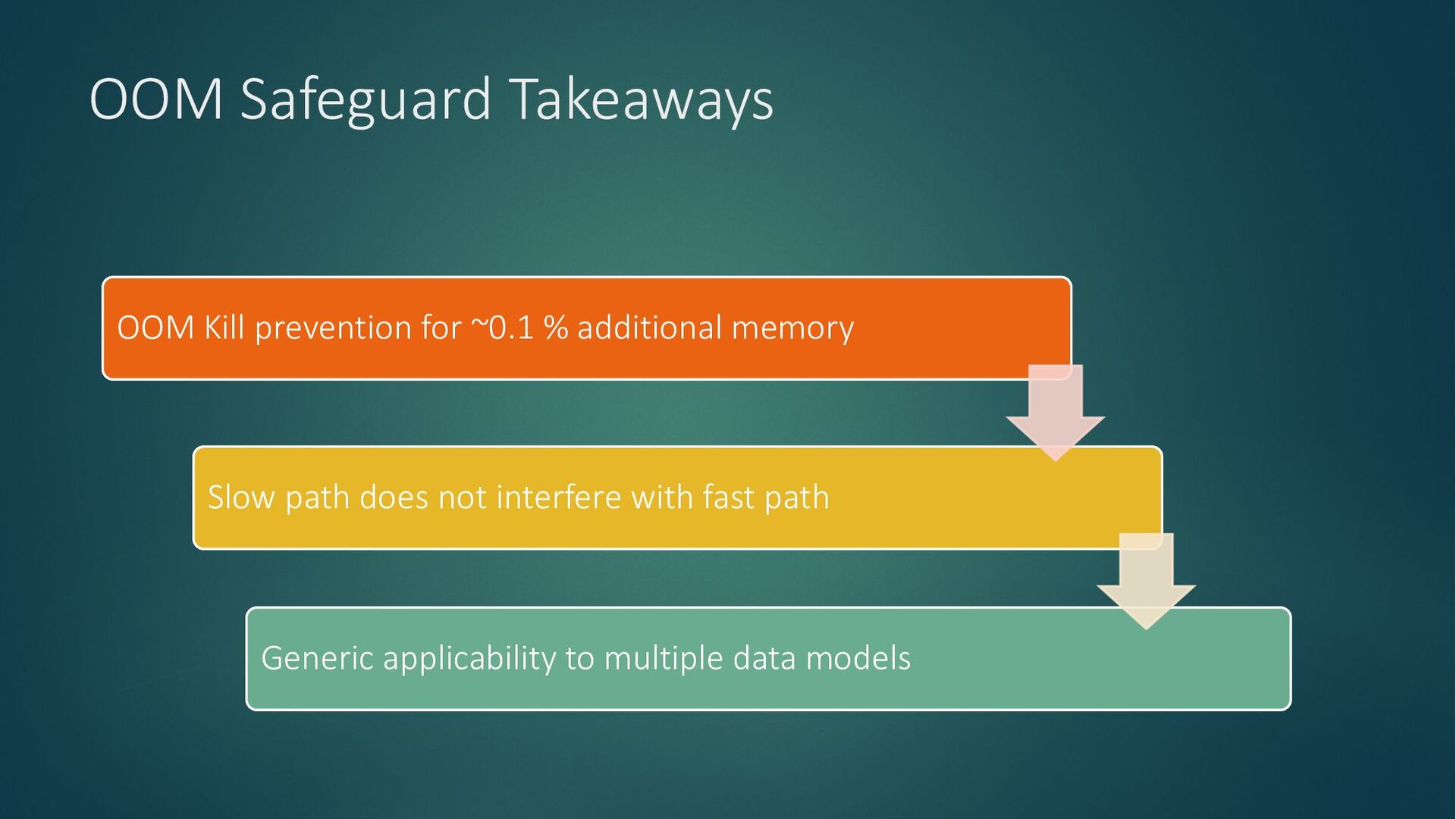
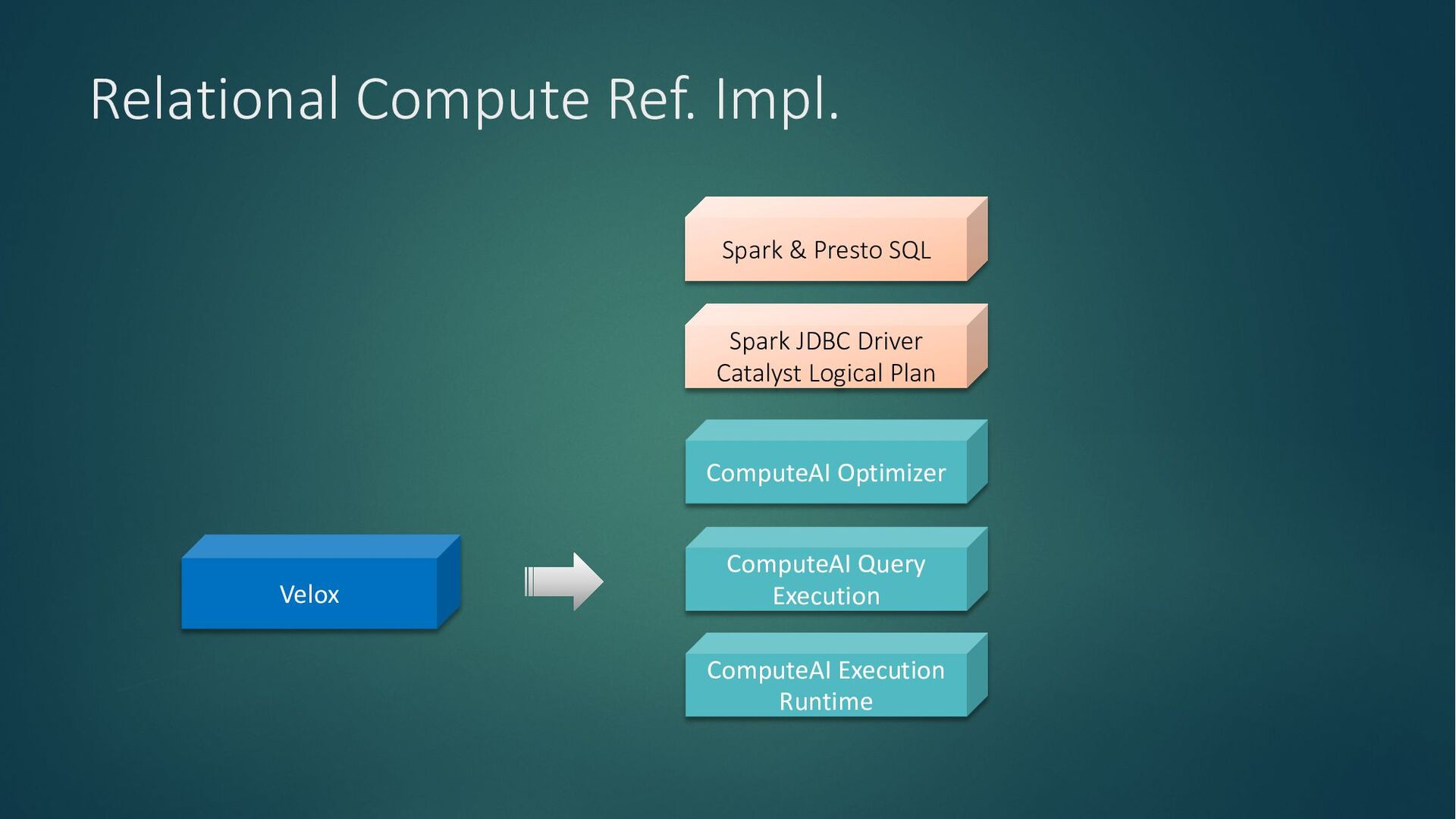
Compute resources becoming dear and the ever-increasing demand for efficiency necessitate a fundamental shift in how we approach computing. Our reliance on in-memory systems has led to an unsustainable practice: overprovisioning infrastructure to avoid memory-related crashes (OOM kills). To achieve truly scalable and cost-effective computing, we must unlock the full potential of underutilized CPUs and GPUs and build OOM-proof systems that are less memory-intensive, ultimately reducing our reliance on expensive infrastructure.
Vikram Joshi
Founder, President & CTO at ComputeAI
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}