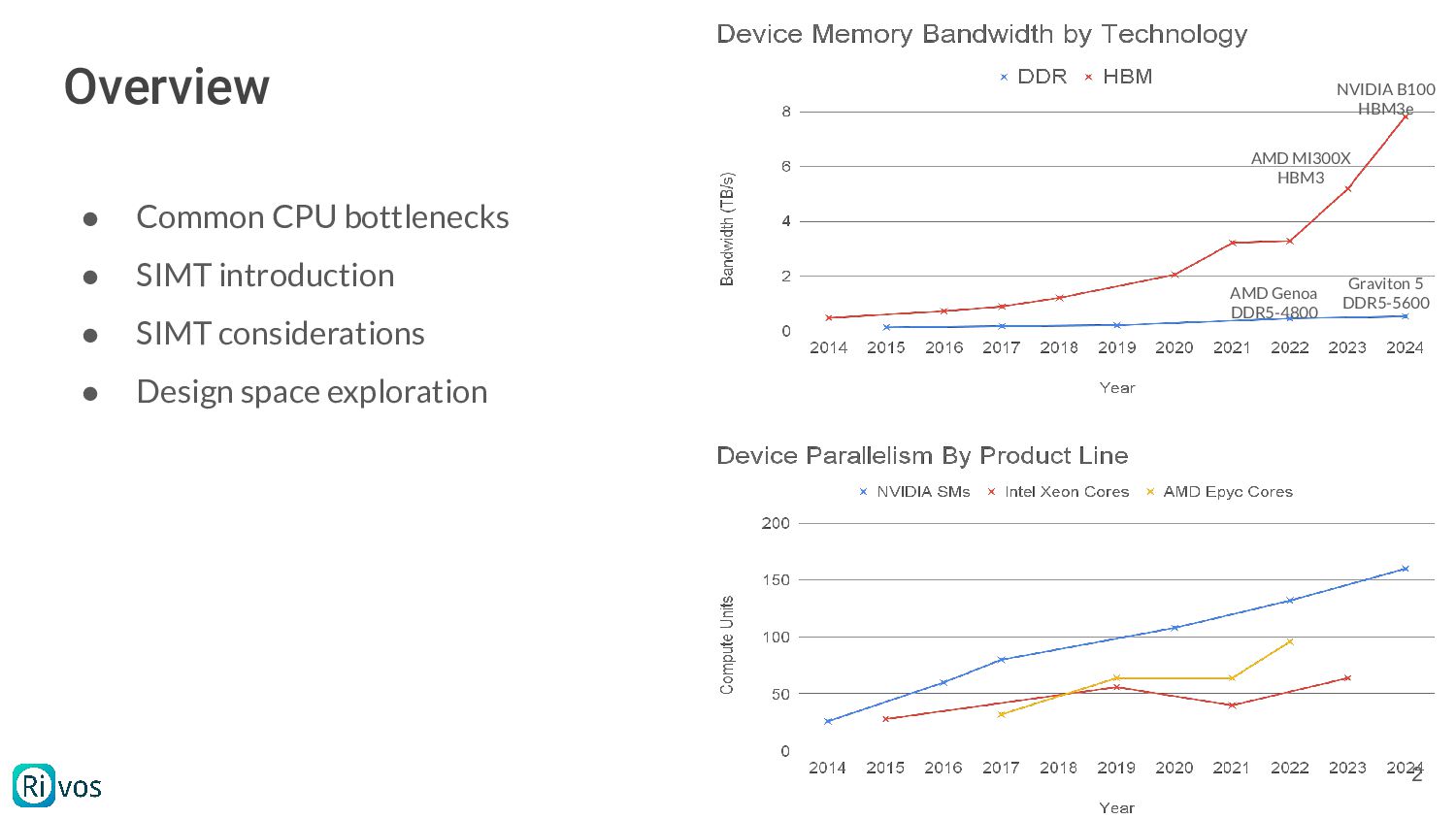
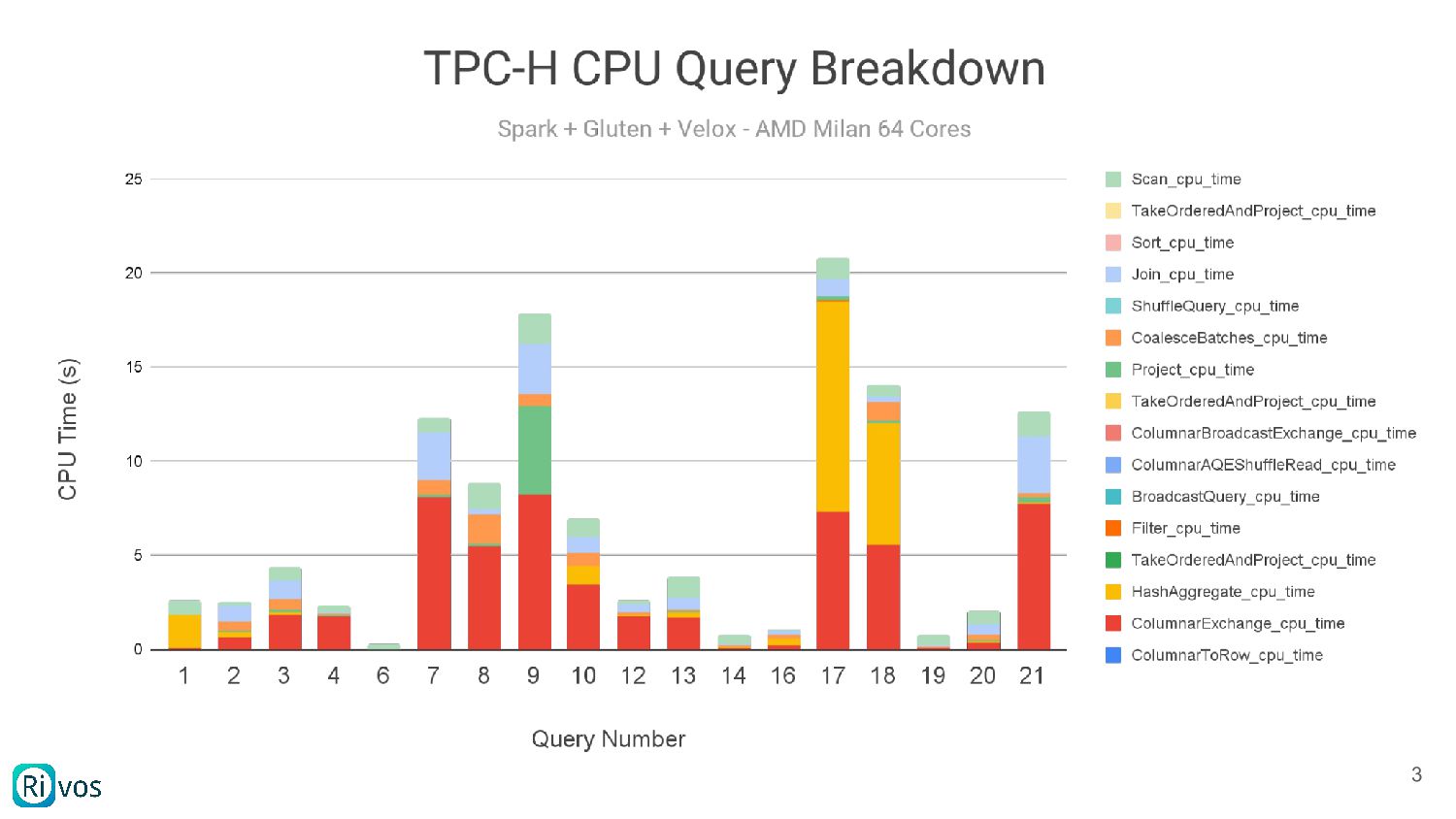
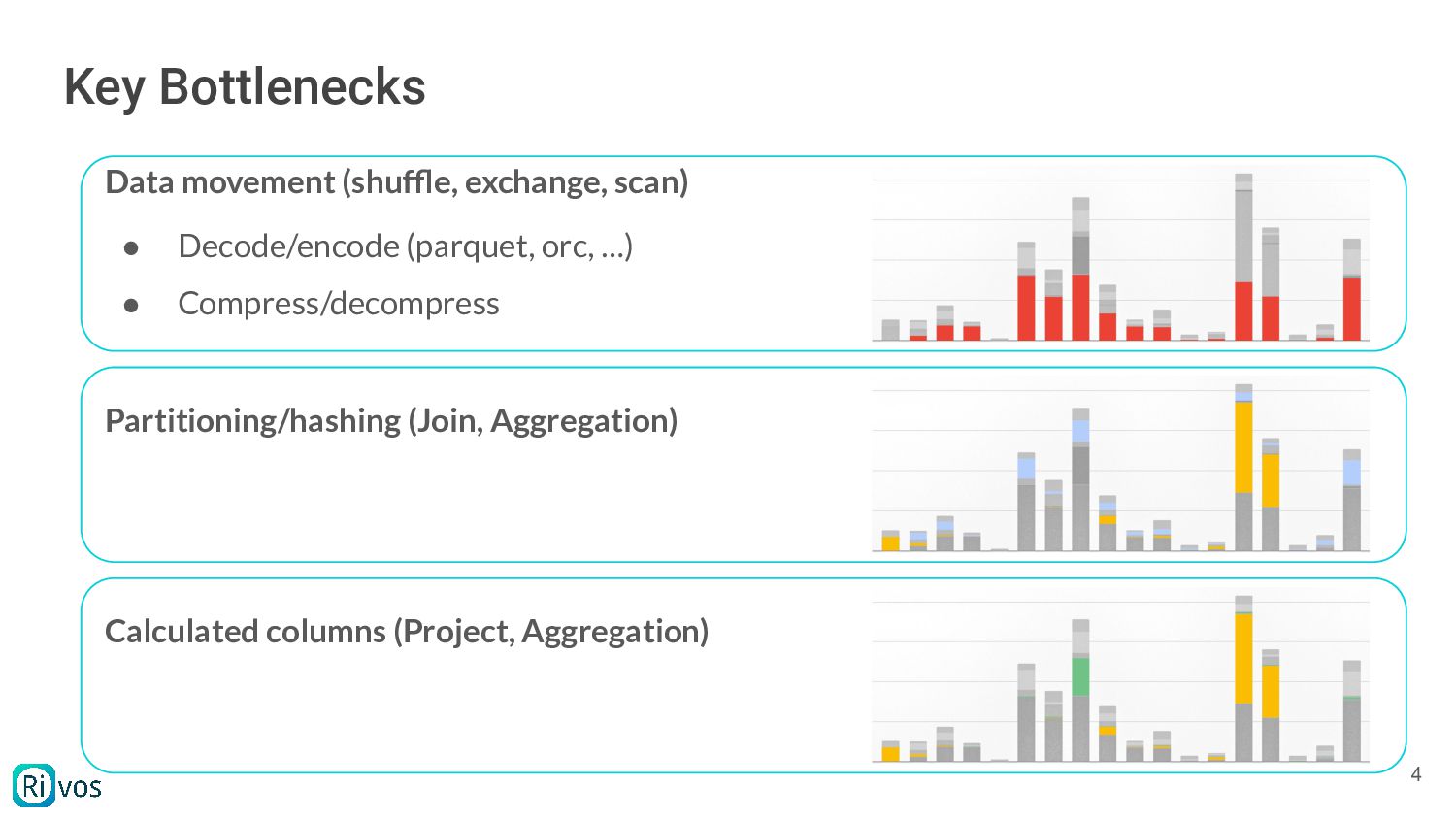
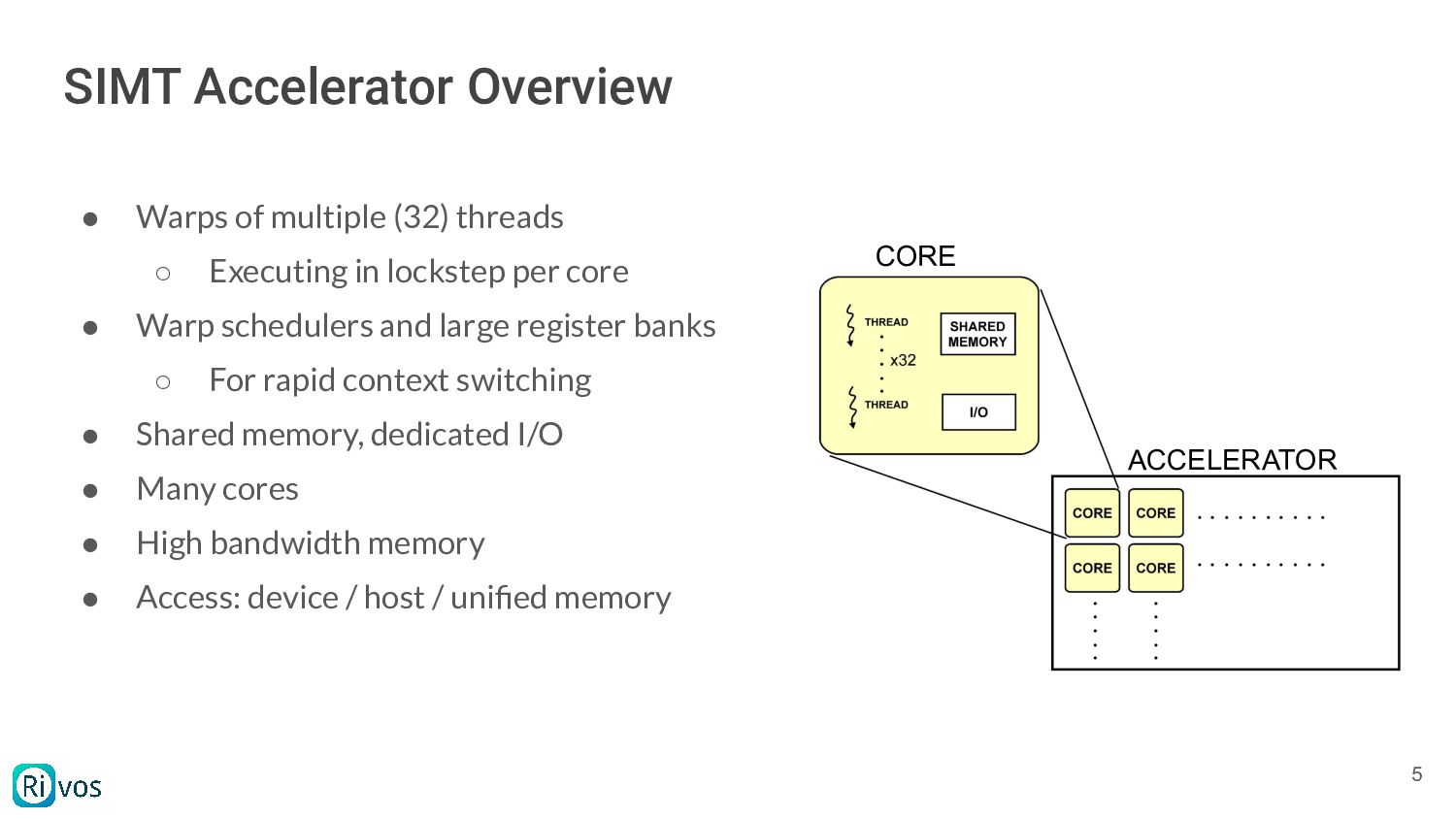
Velox pipeline performance is limited by the available compute. The talk provides an overview of common bottlenecks observed in benchmarks such as TPCH, briefly describes the kinds of parallelism accelerators are capable of, and provides a brief overview of ways an accelerator may be applied to help, as well as some of the challenges in this space.
Sergei Lewis
Principal Member of Technical Staff at Rivos
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}