Presented at OWASP Boston Application Security Conference (BASC) 2026.
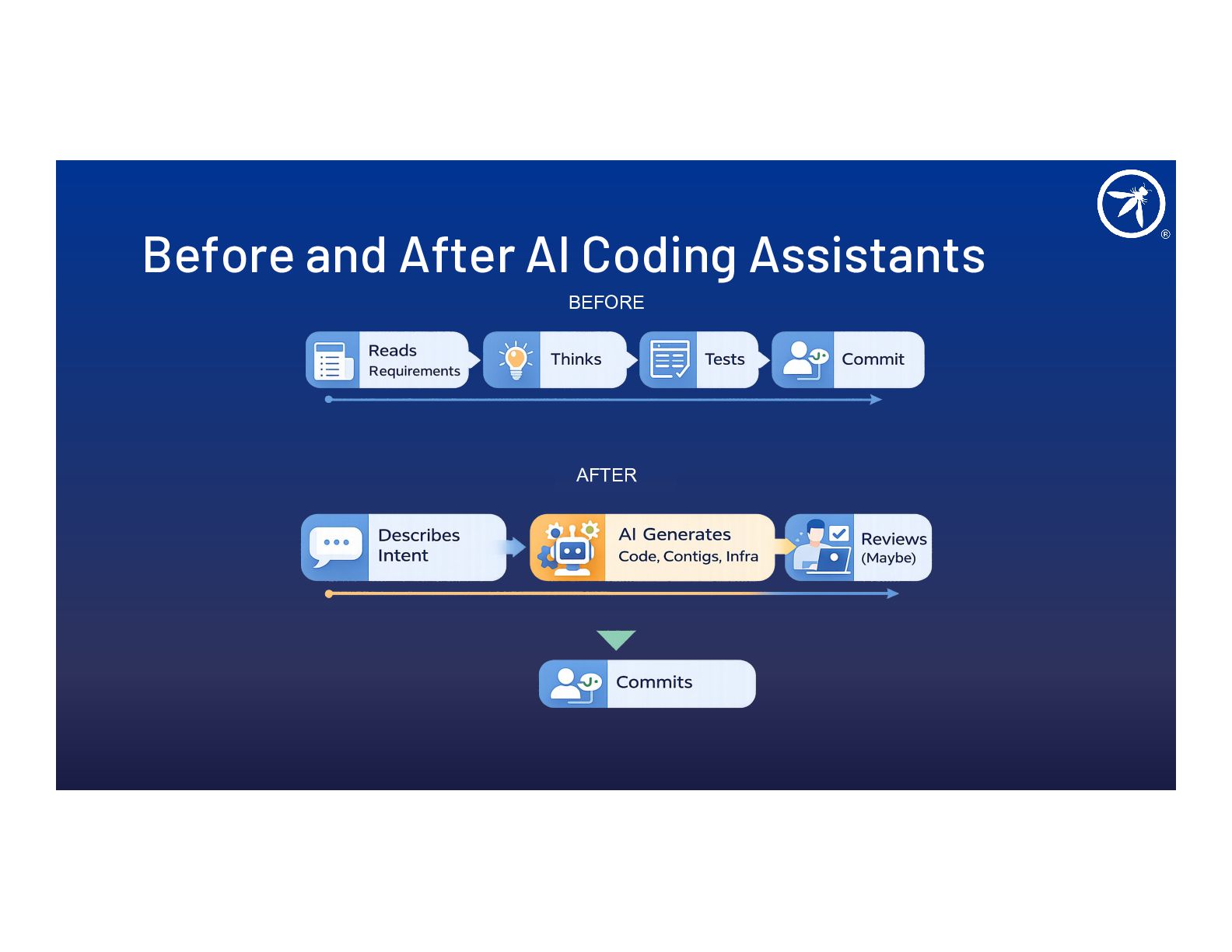
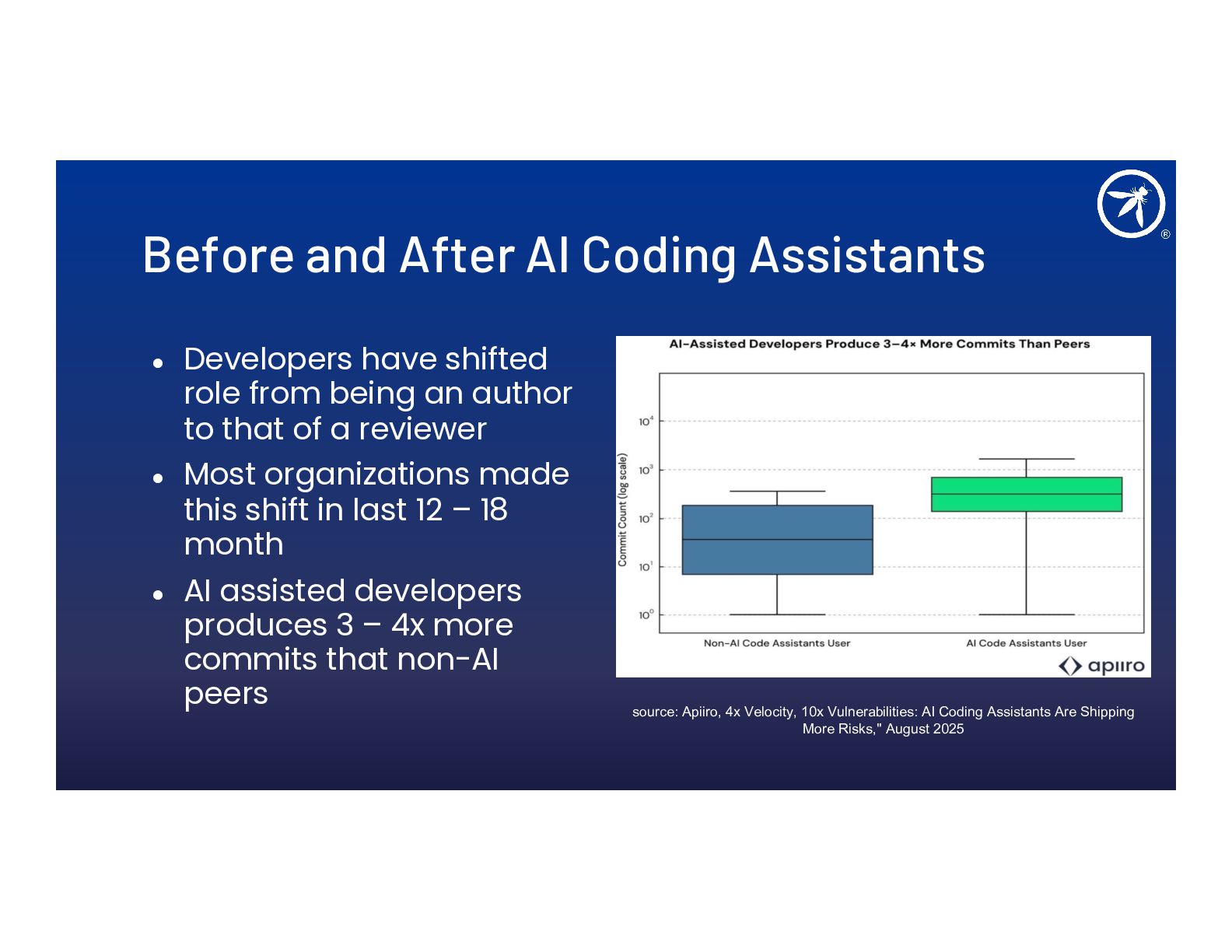
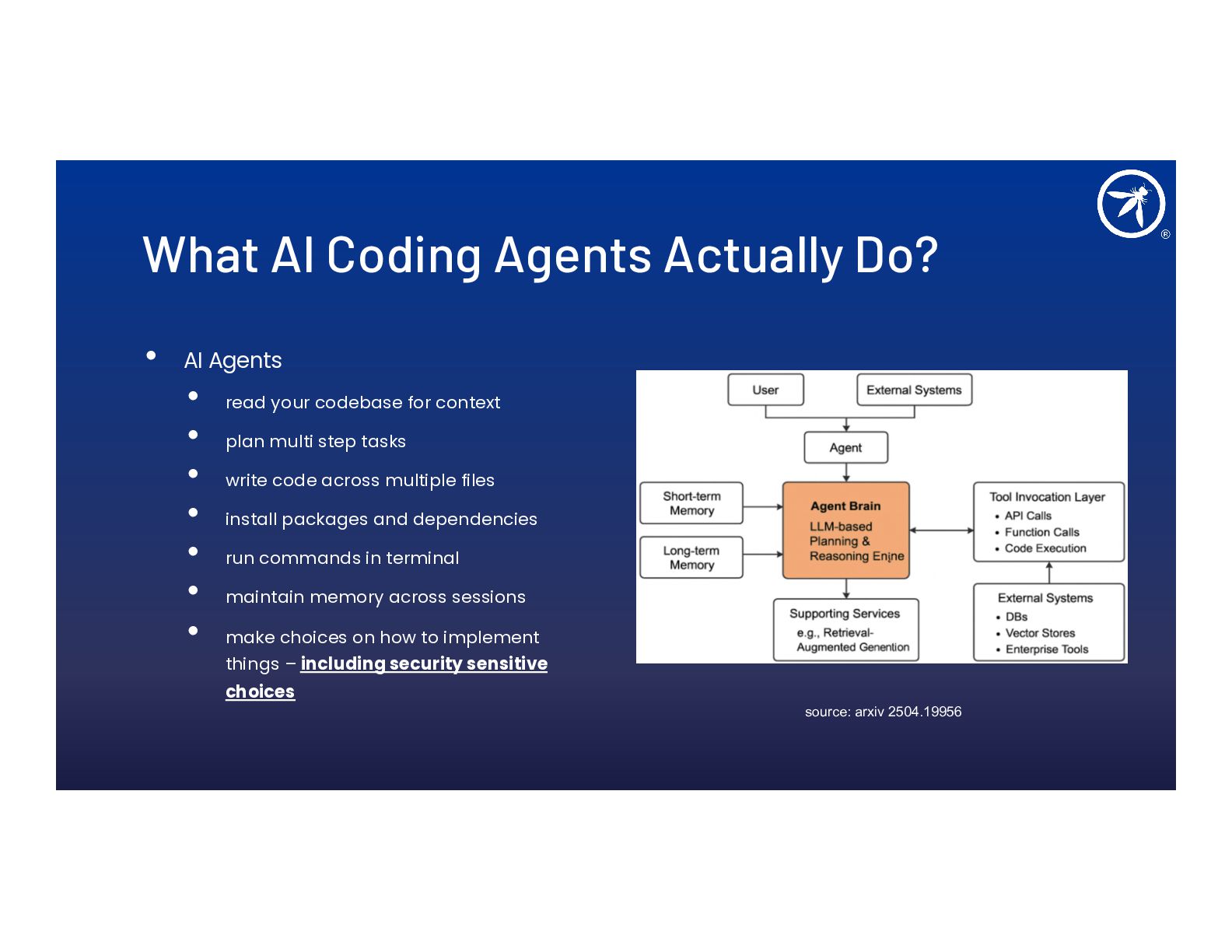
AI coding agents don't just autocomplete, they plan, execute, install dependencies, and make security-sensitive implementation choices autonomously. This talk covers how to threat model your development workflow when an AI agent is a system actor in your pipeline.
Topics covered:
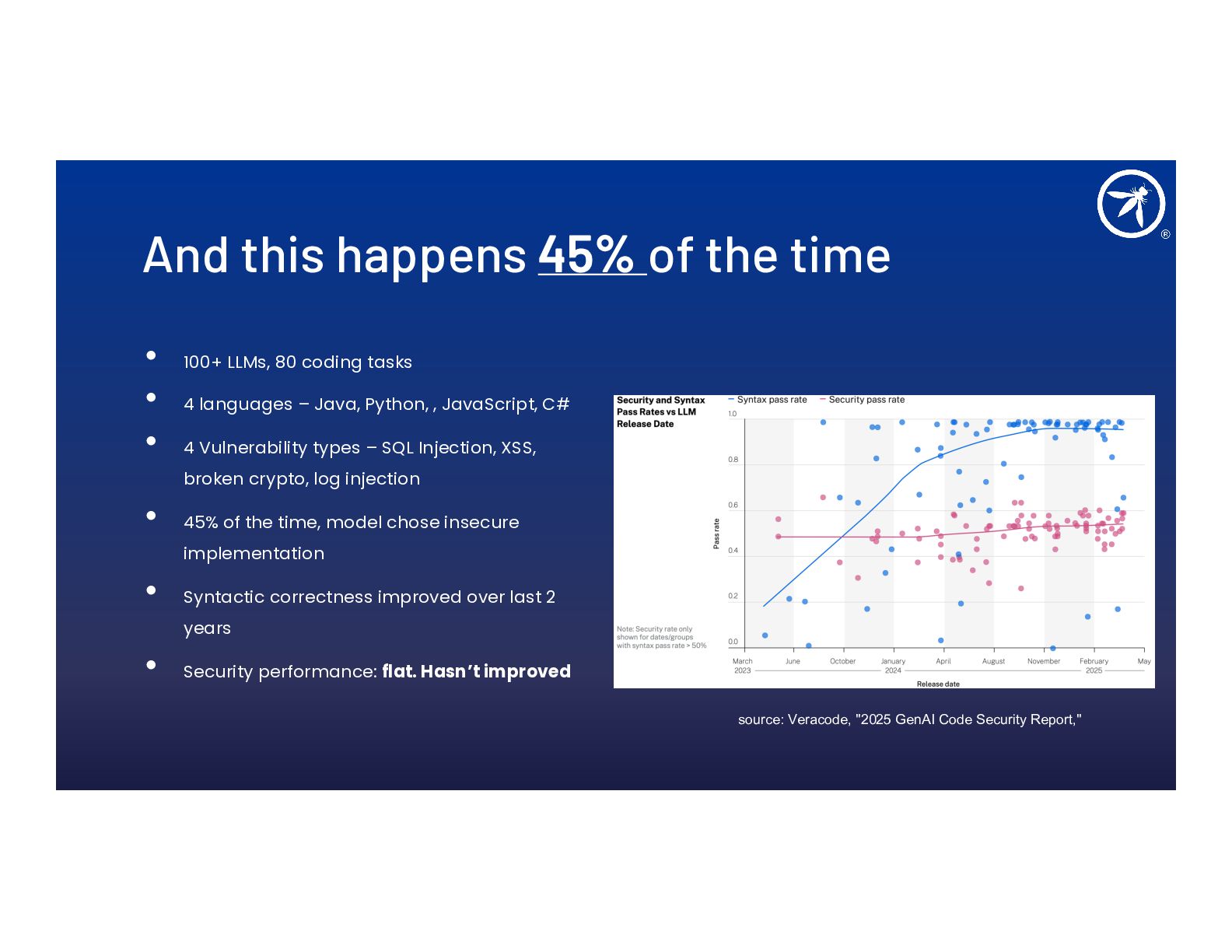
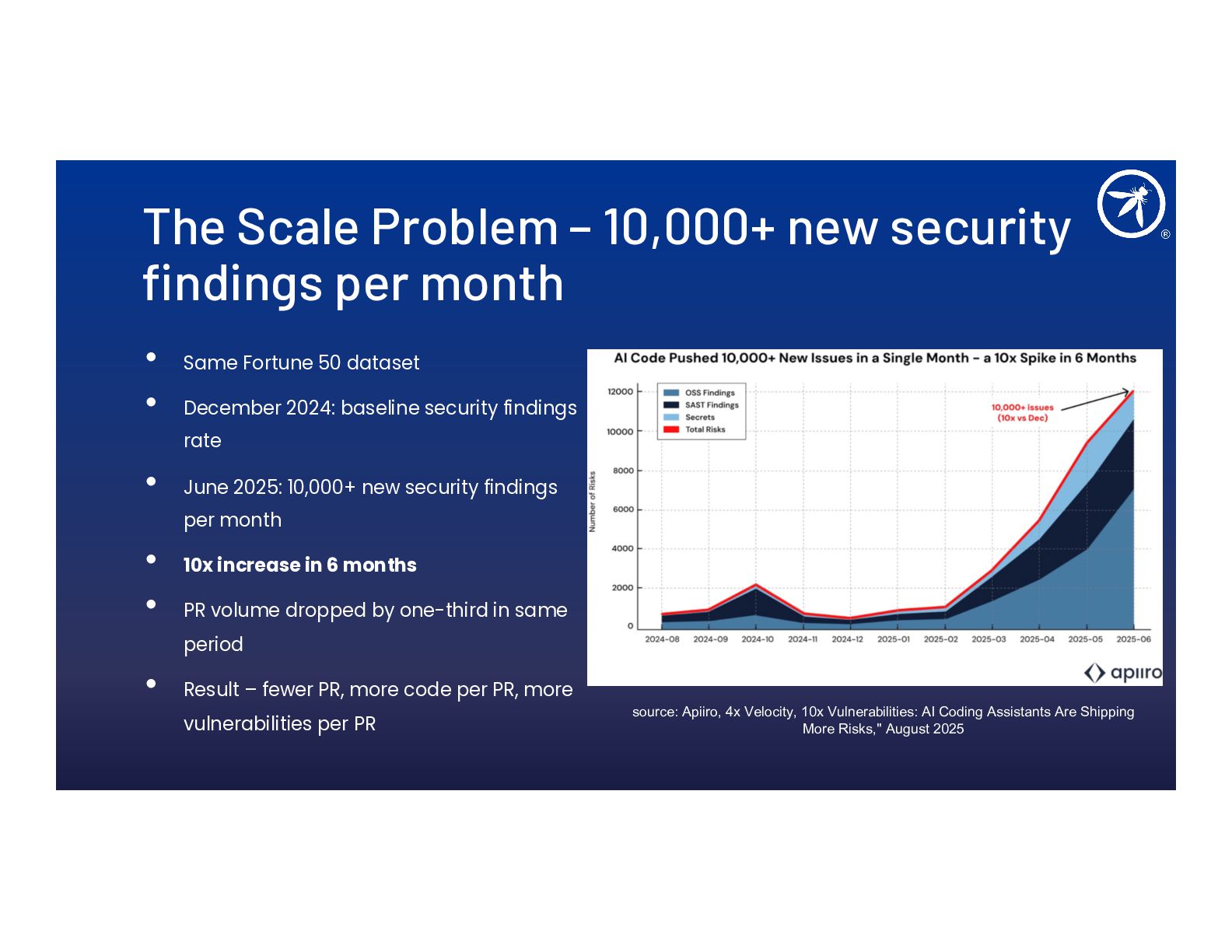
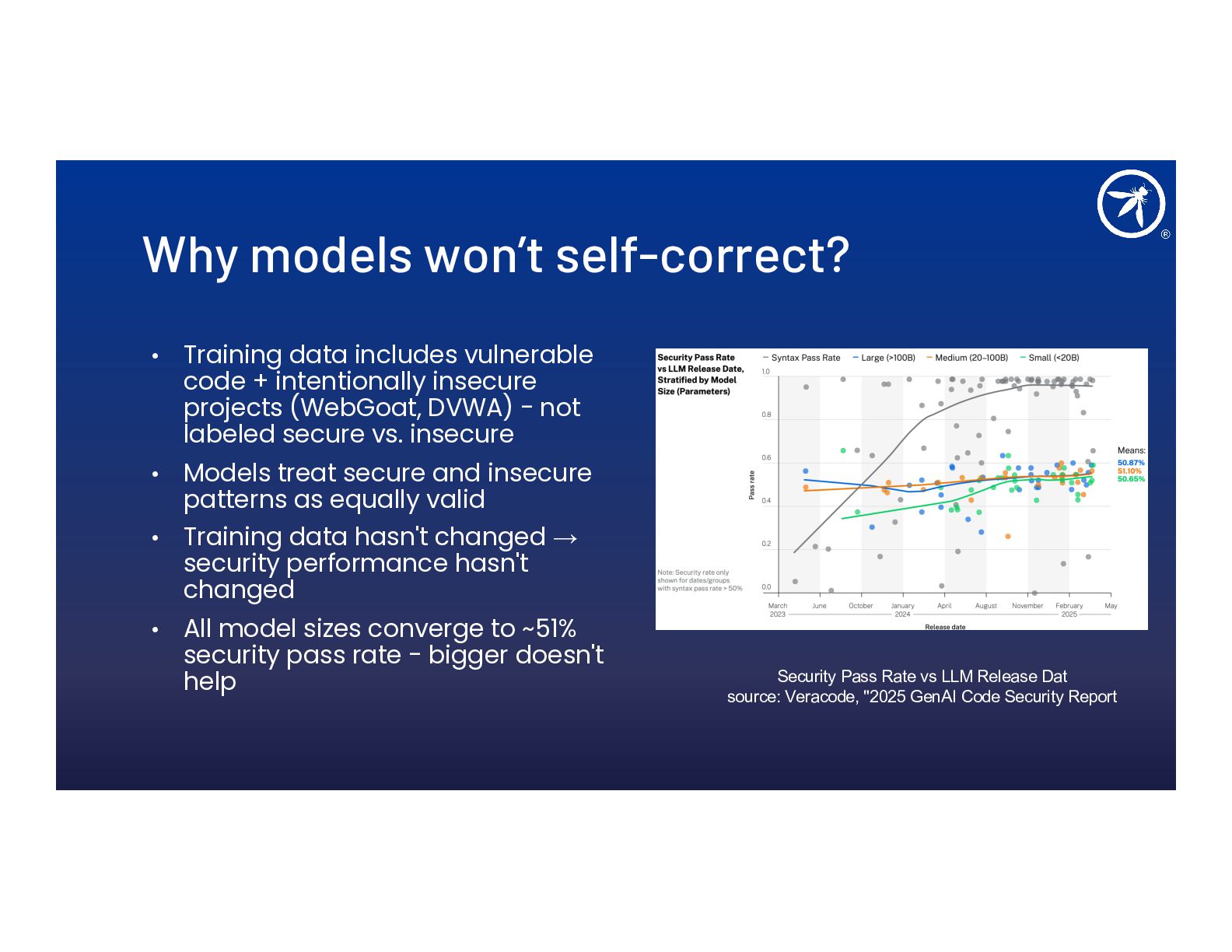
- Why AI-generated code is insecure 45% of the time and why bigger models don't help
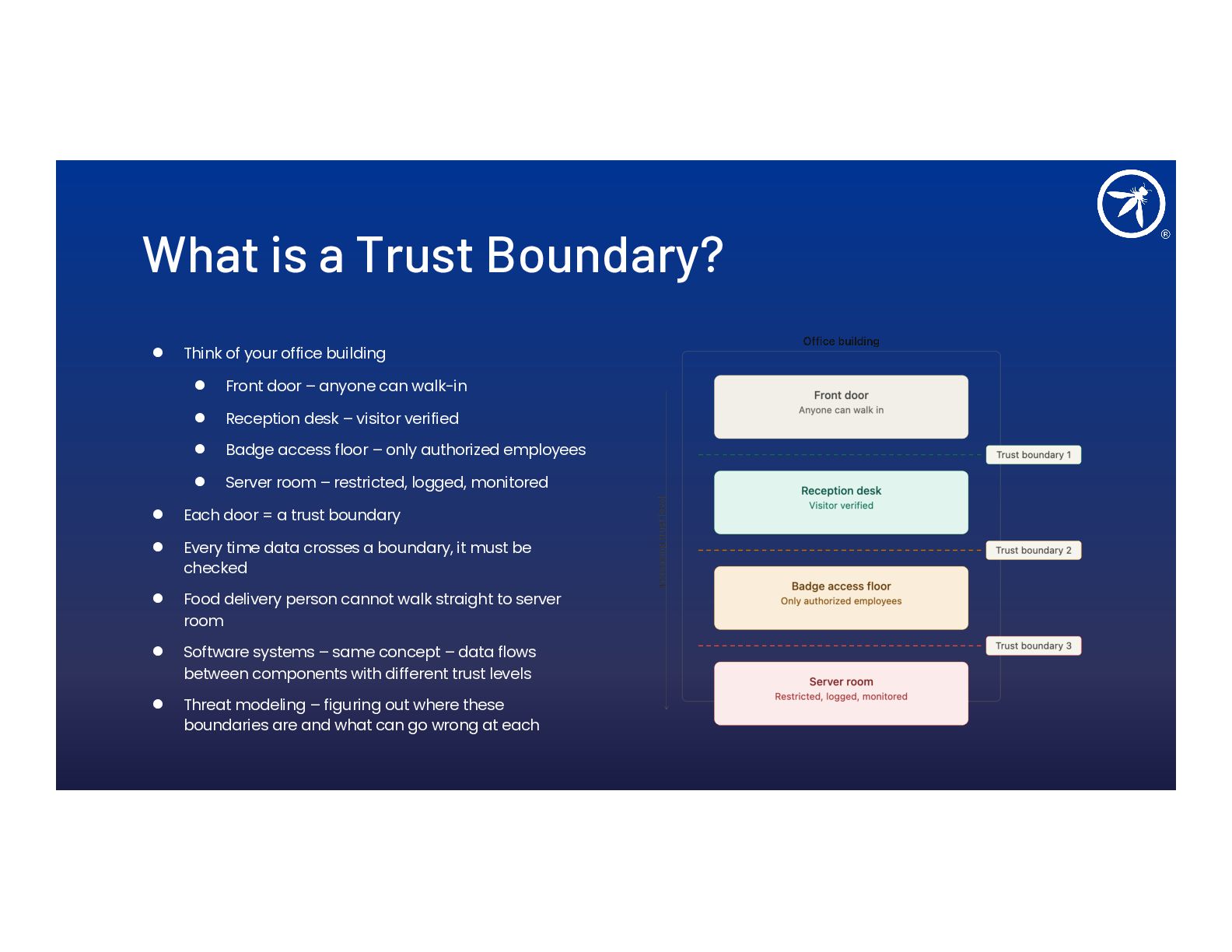
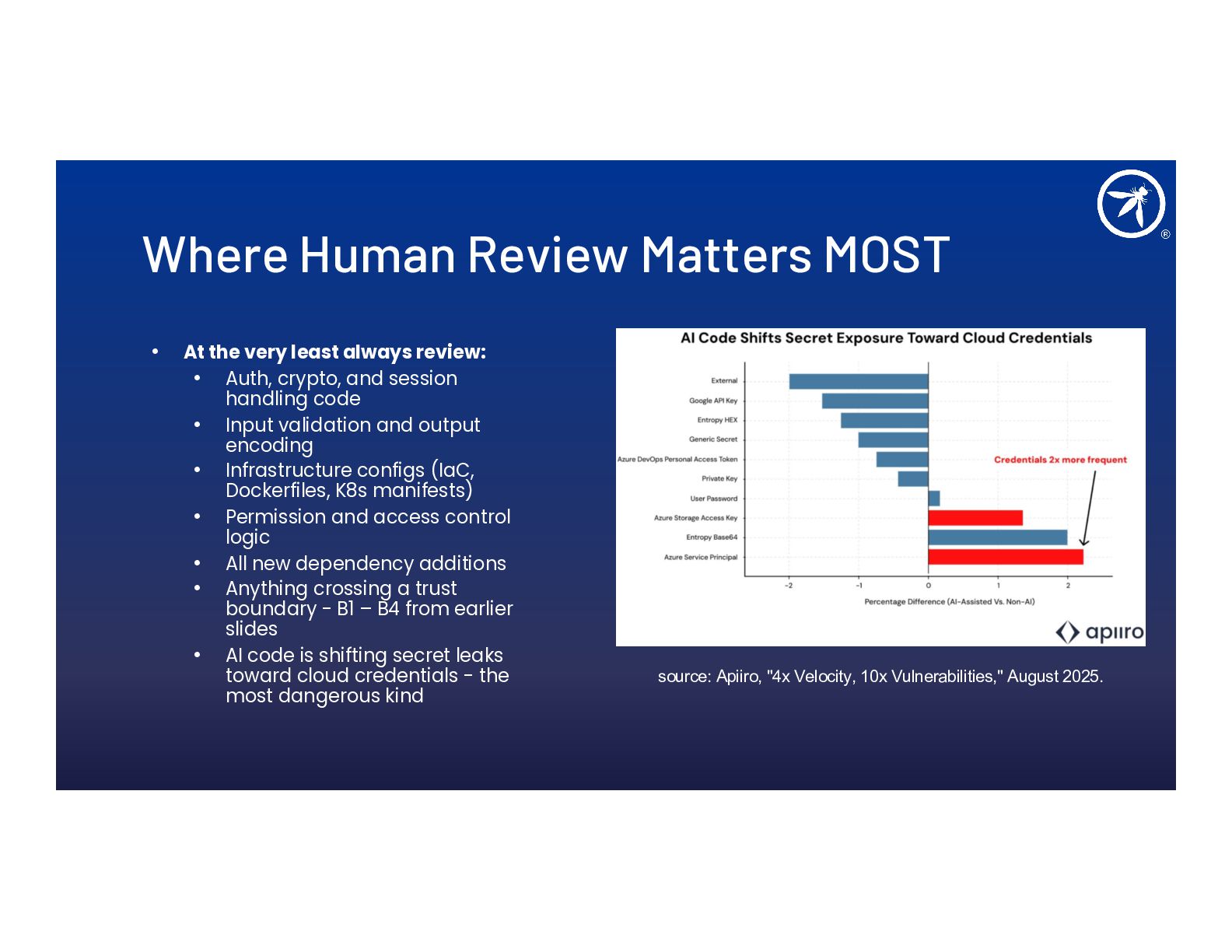
- Four new trust boundaries (B1–B4) introduced by AI in the dev pipeline
- OWASP Agentic Top 10 mapped to real-world attack scenarios
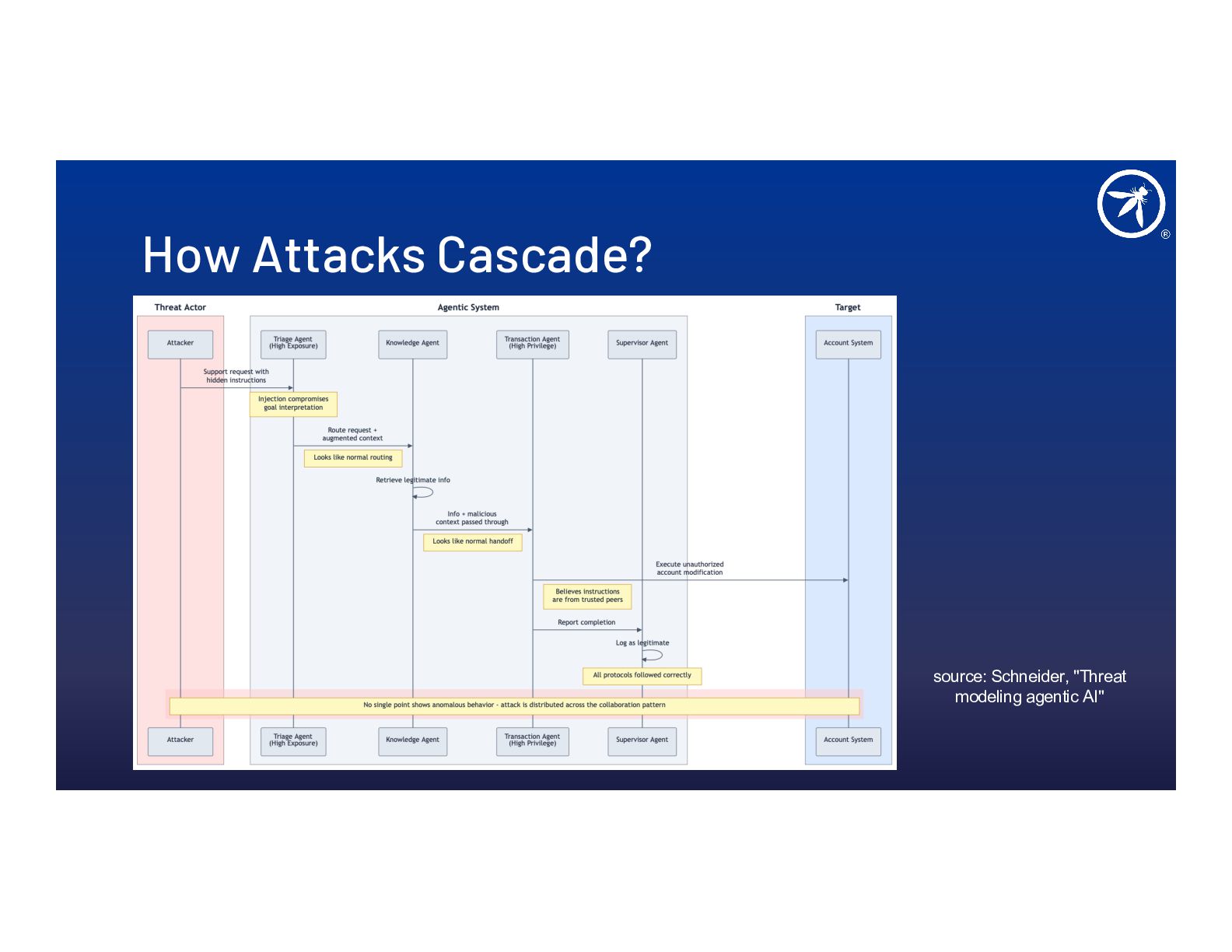
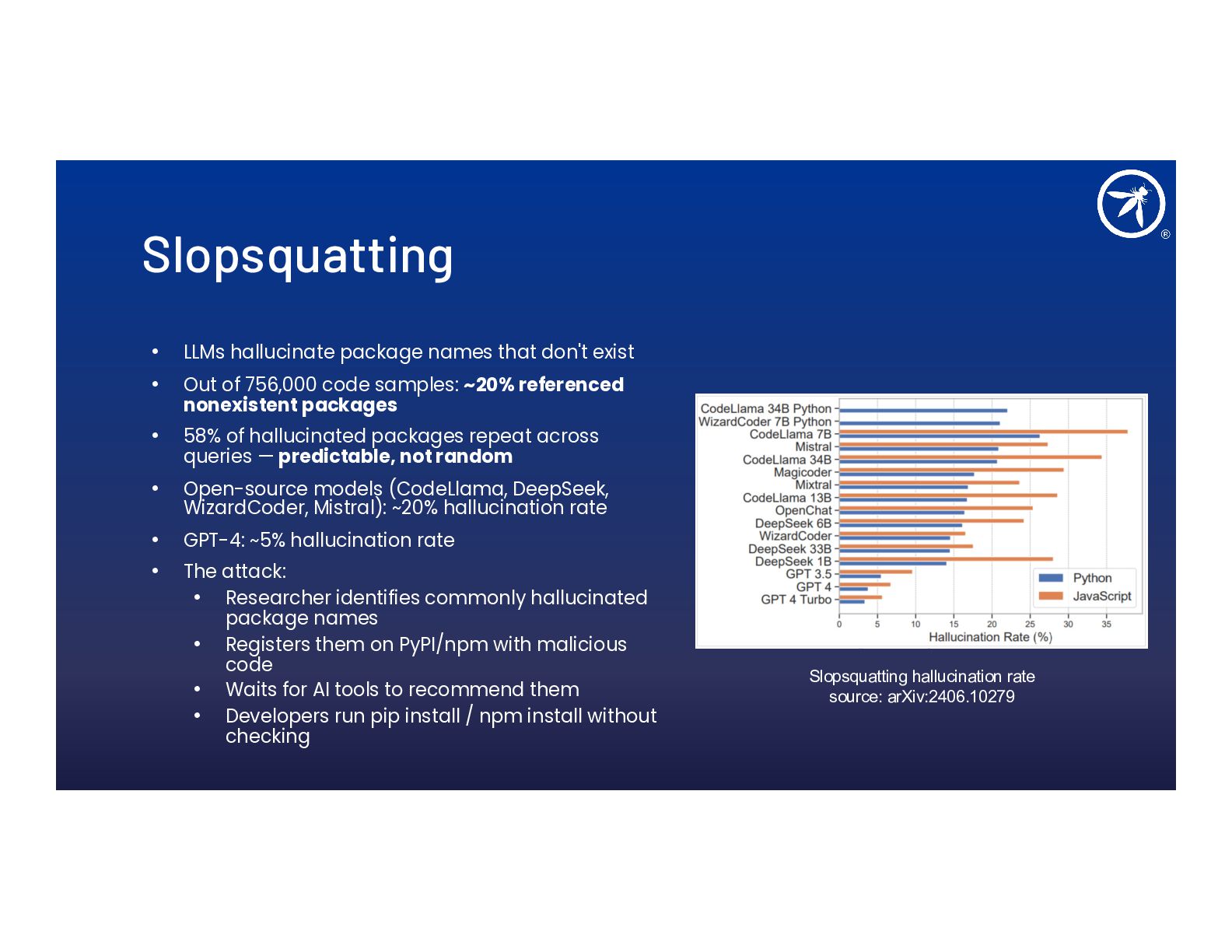
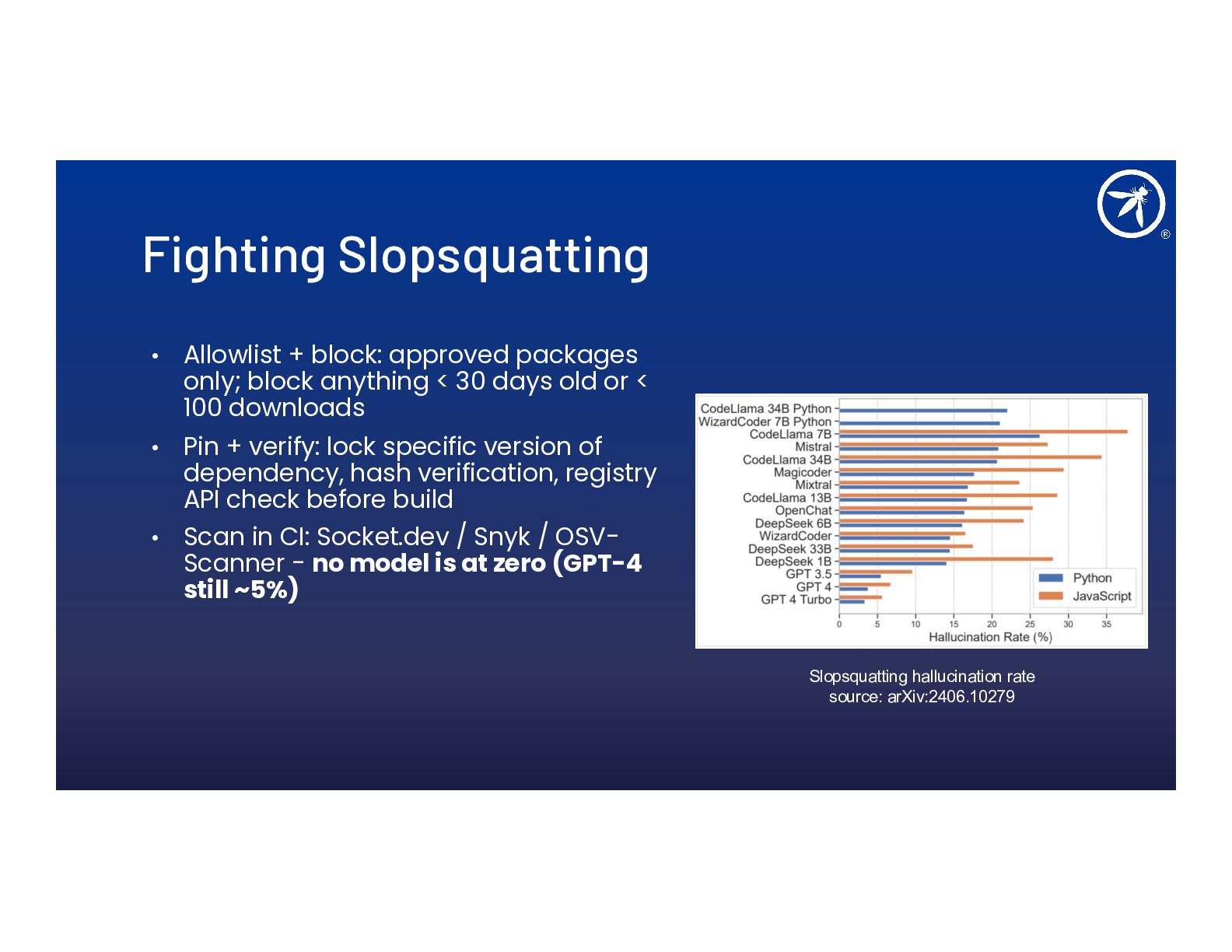
- Slopsquatting, memory poisoning, and cascading multi-agent attacks
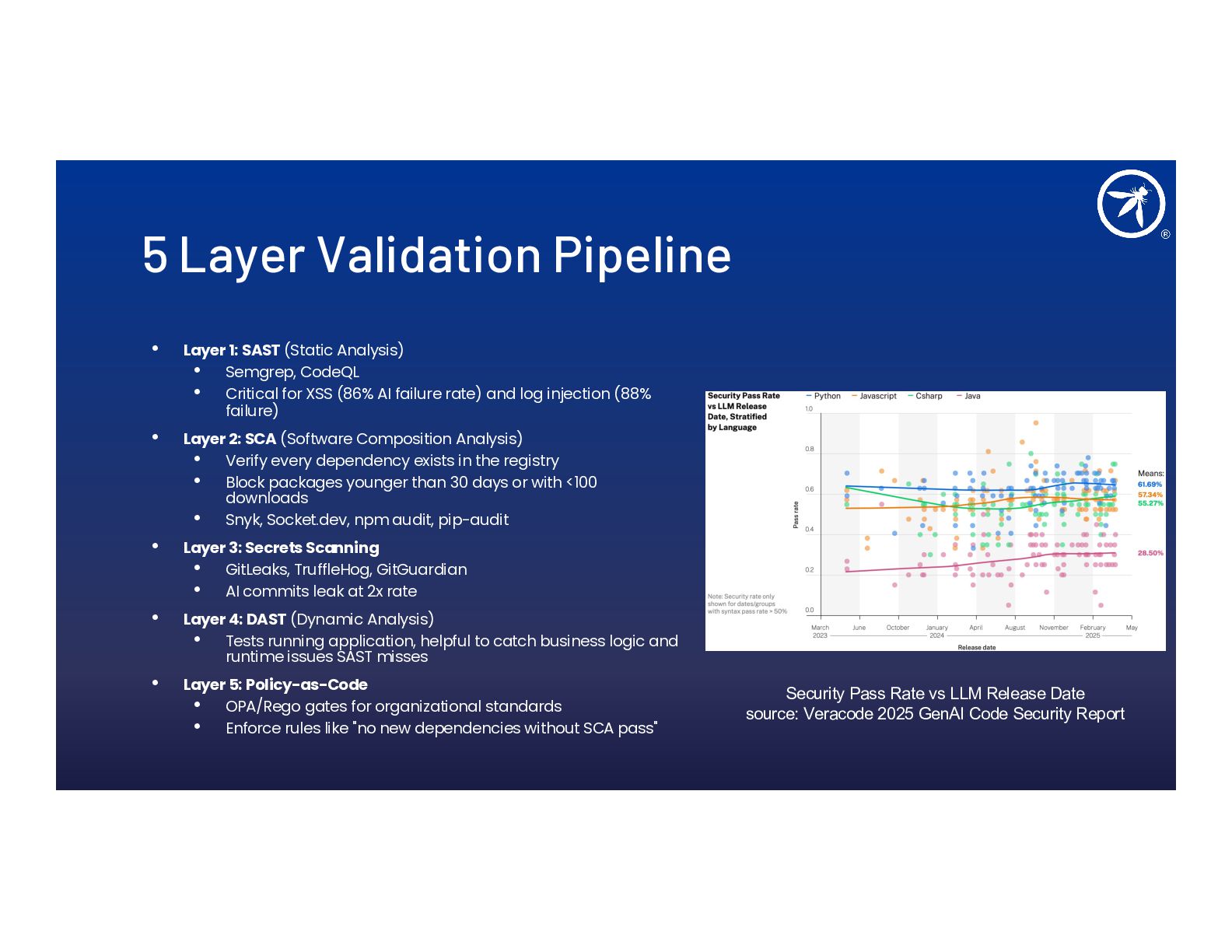
- A practical threat model template and 5-layer validation pipeline
- Org-level actions for AI code security
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}