-> akka -> ai -> couchbase Scala by the Bay (scala.bythebay.io) Nov 12, 2016 | 1355 Market Street, San Francisco, US (Twitter’s HQ) Adrian Mihai, co-founder/cto @dublin_io / engineering.opening.io
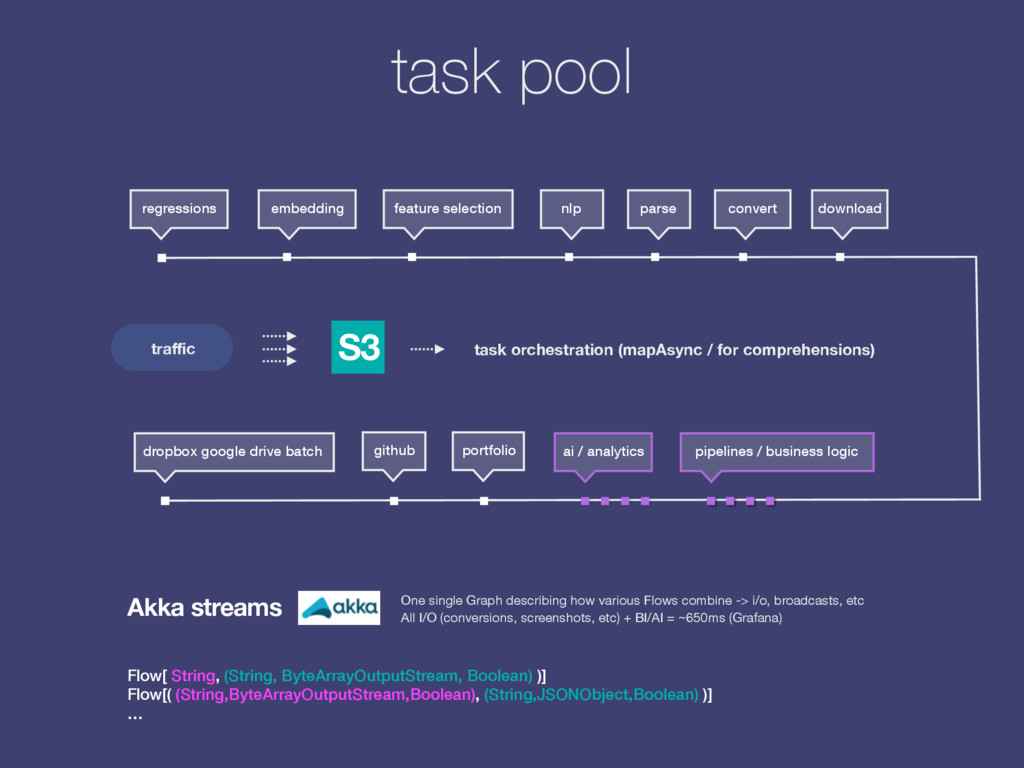
specialized, location transparent units of work (akka-camel actors) which gradually build a complete candidate profile out of each file. We ingest files from web or in batch via dedicated import processes (mail, cloud). 02 03 Information retrieval Identifying patterns within structure and phrasing of resumes in order to match them to suitable job descriptions automatically. We employ linguistics to cluster pools of similar candidates and job posts and tap into external sources of signal: GitHub, LinkedIn. Real-time analytics Salary recommendations / forecasts, similarity between candidates and/or job descriptions, rankings, search & extra business logic.
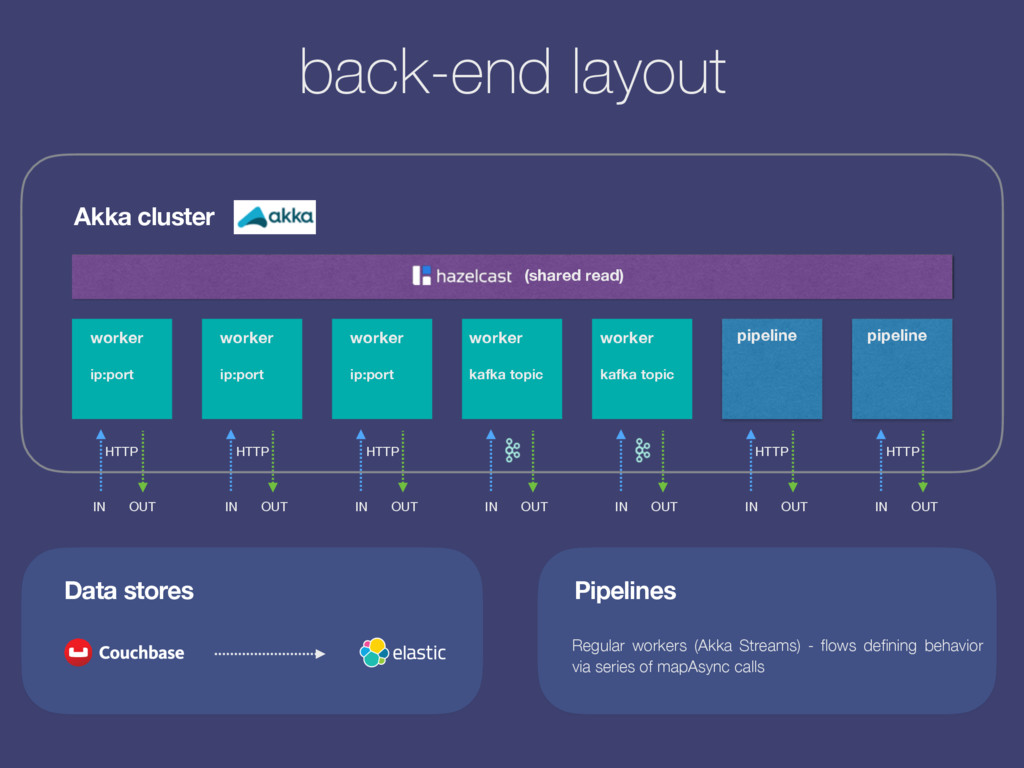
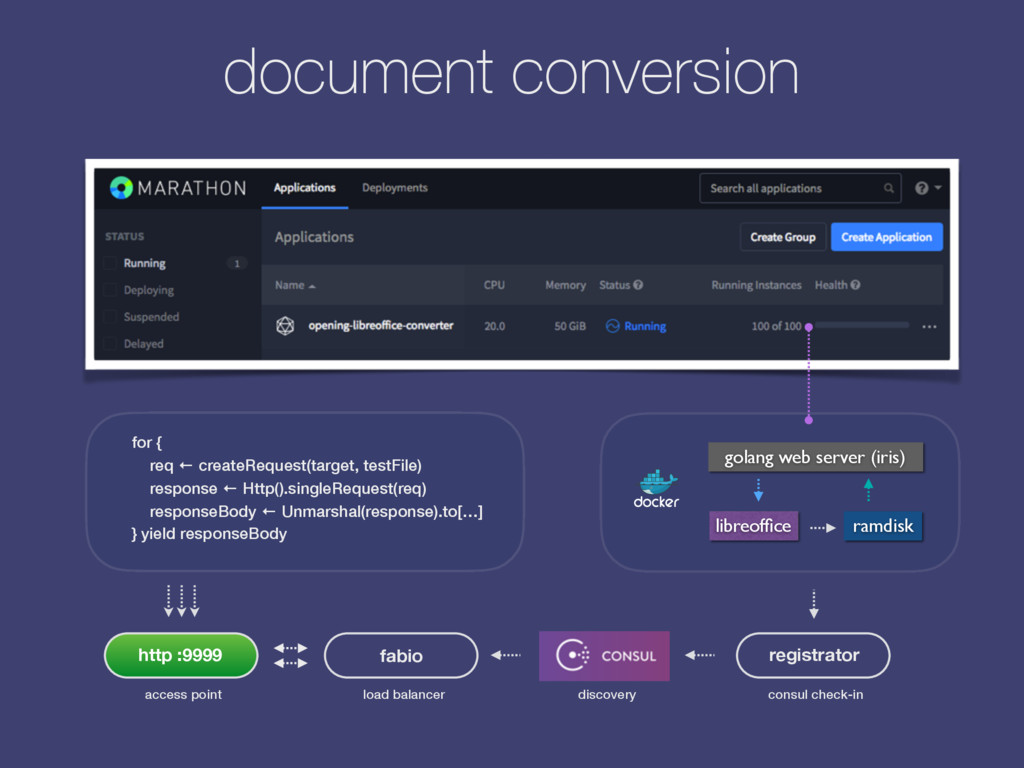
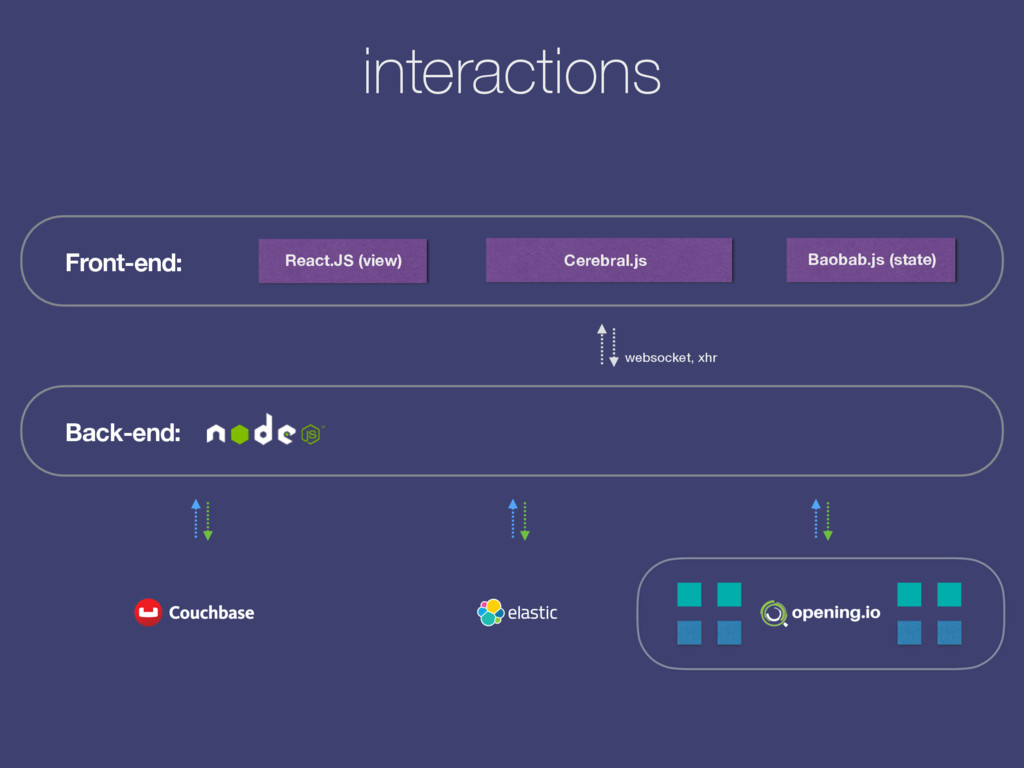
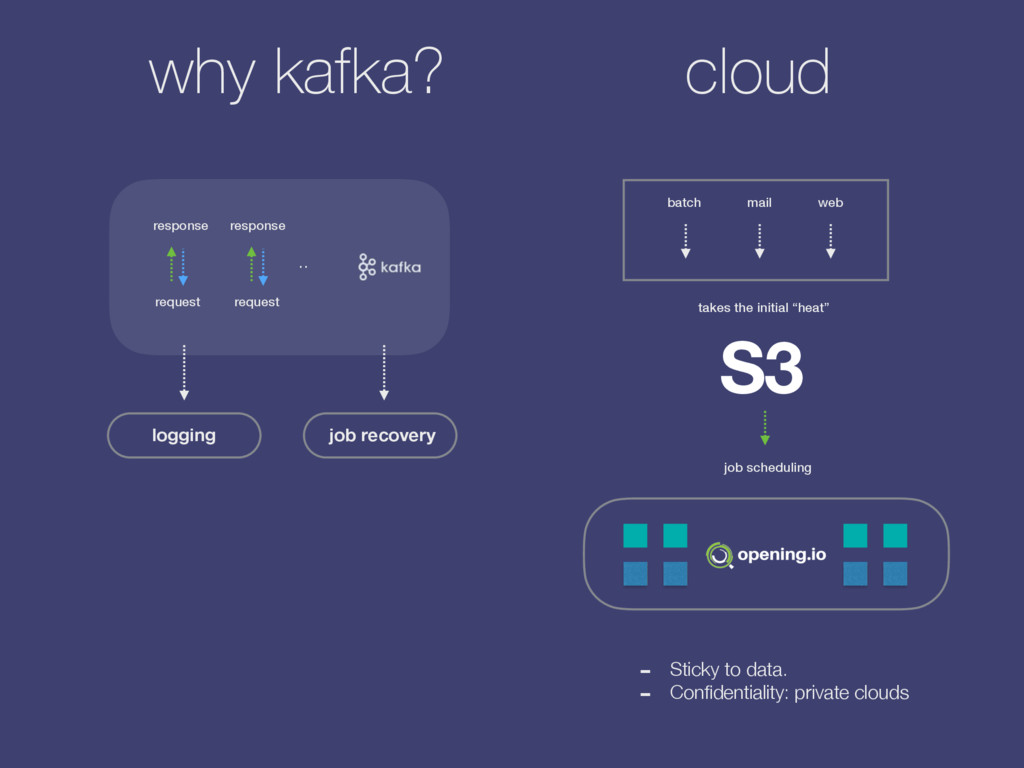
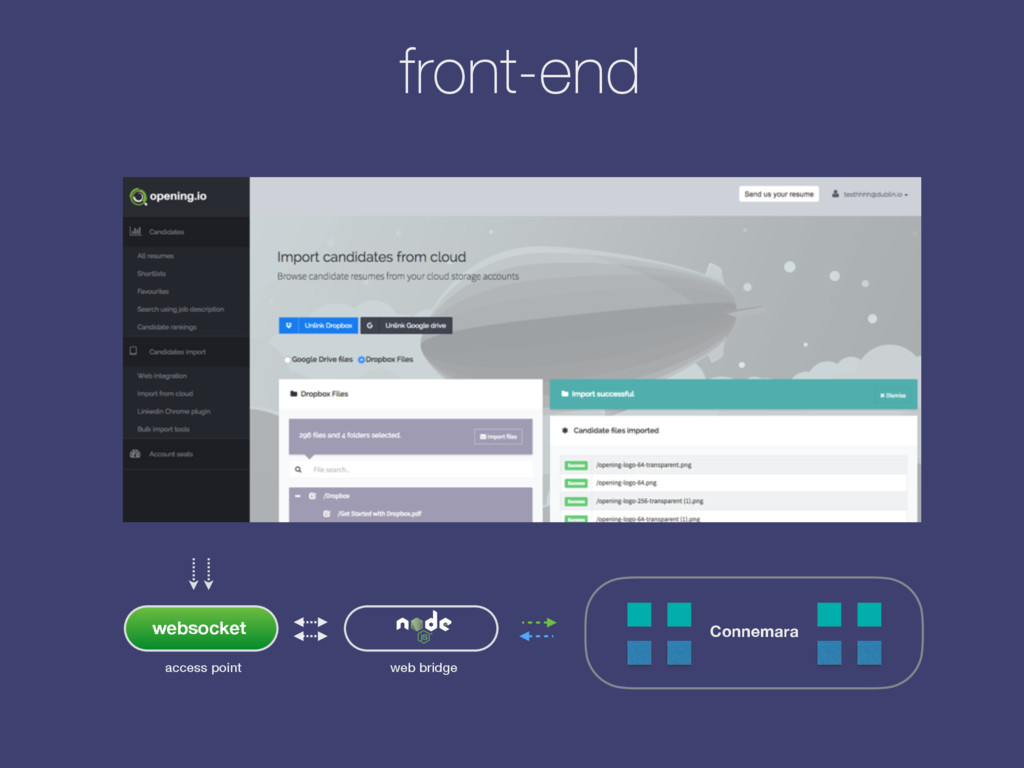
the web back-end we run a Scala/Java application: Connemara. web socket front-end back-end (node.js) kafka message, json topic: resume_upload_pipeline topic: results-resume_upload_pipeline Requests are getting fulfilled by pipelines, or chains of actions: s3_download, feature_extraction, salaries_for_skills, etc. Actions are JSON Kafka / HTTP requests sent to their respective topics while answers to these requests are decorating pipeline’s state tree in return. Once conditions met the pipeline returns an answer. Workers are actors within an Akka Cluster: Kafka consumers / HTTP Servers (receiving JSON queries) and producers (sending output). However, they are Camel context-aware (can switch transport from Kafka to http/websocket/gearman for instance via configuration) so that they could independently handle API requests for instance. For NLP tasks and document vectors we maintain Python workers too.
topic pipeline pipeline (shared read) Data stores Pipelines Regular workers (Akka Streams) - flows defining behavior via series of mapAsync calls IN OUT IN OUT IN OUT IN OUT IN OUT IN OUT IN OUT HTTP HTTP HTTP worker ip:port worker ip:port HTTP HTTP worker kafka topic
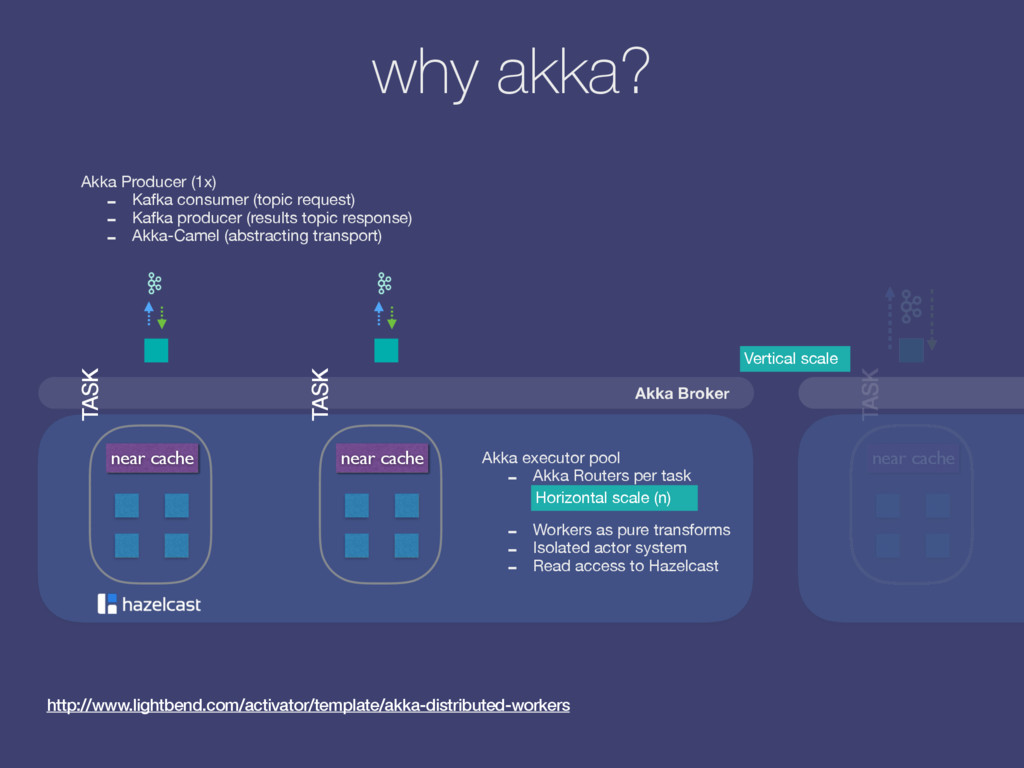
request) - Kafka producer (results topic response) - Akka-Camel (abstracting transport) TASK Akka Broker Akka executor pool - Akka Routers per task - Workers as pure transforms - Isolated actor system - Read access to Hazelcast TASK TASK Vertical scale Horizontal scale (n) near cache near cache near cache
this: an industry-specific topic vector, values are series of regressions And also like this: (a document vector pointing to a direction within a high-dimensional - in our case 300 - semantic space) Web design & E-Commerce: 0.95 Software Development: 0.86 …. We looked at probability distributions too (LDA/HDP) but we actually like how well regression works here. tsne tsne kohonen
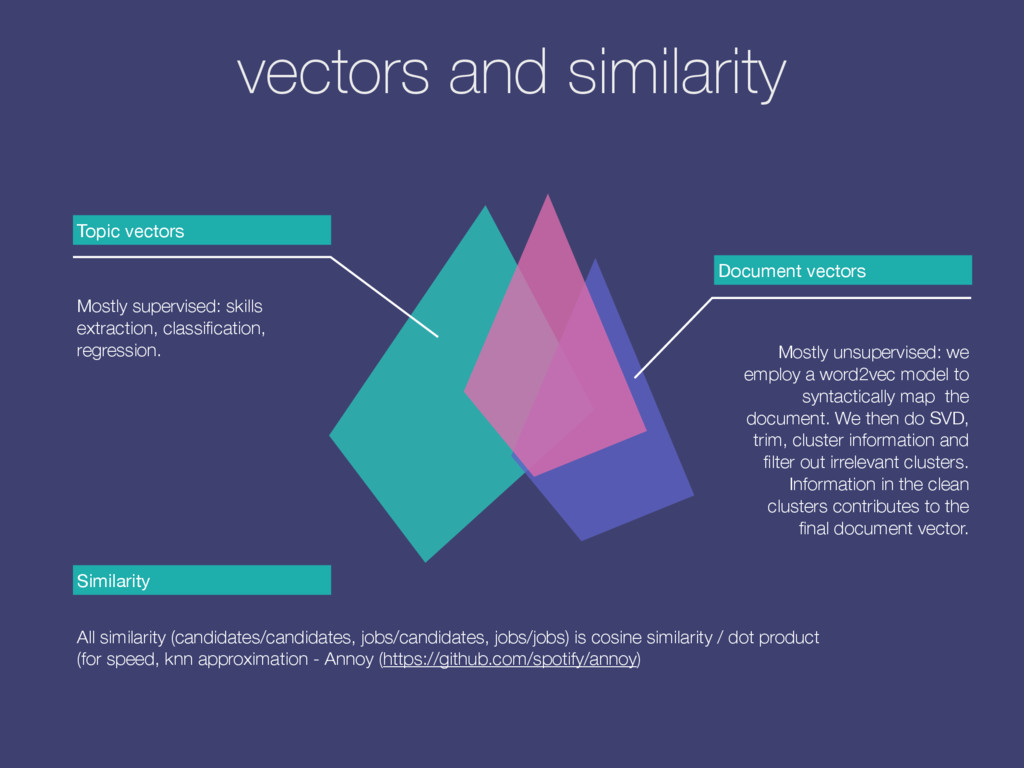
Mostly unsupervised: we employ a word2vec model to syntactically map the document. We then do SVD, trim, cluster information and filter out irrelevant clusters. Information in the clean clusters contributes to the final document vector. vectors and similarity Similarity All similarity (candidates/candidates, jobs/candidates, jobs/jobs) is cosine similarity / dot product (for speed, knn approximation - Annoy (https://github.com/spotify/annoy)
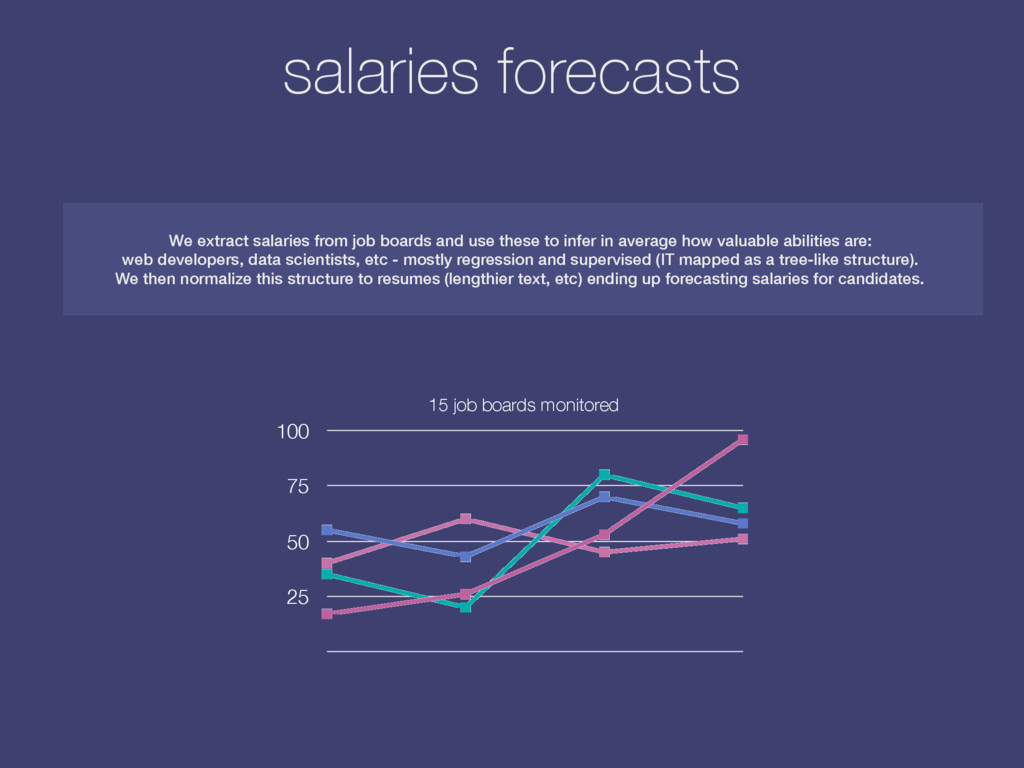
and use these to infer in average how valuable abilities are: web developers, data scientists, etc - mostly regression and supervised (IT mapped as a tree-like structure). We then normalize this structure to resumes (lengthier text, etc) ending up forecasting salaries for candidates. salaries forecasts 15 job boards monitored
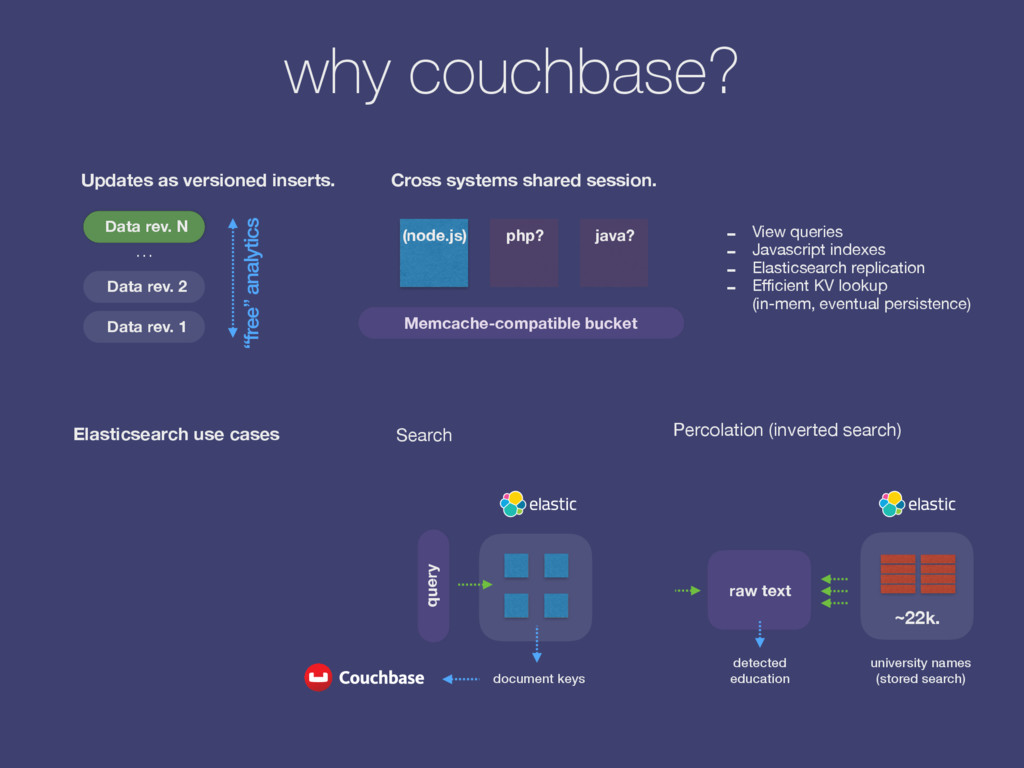
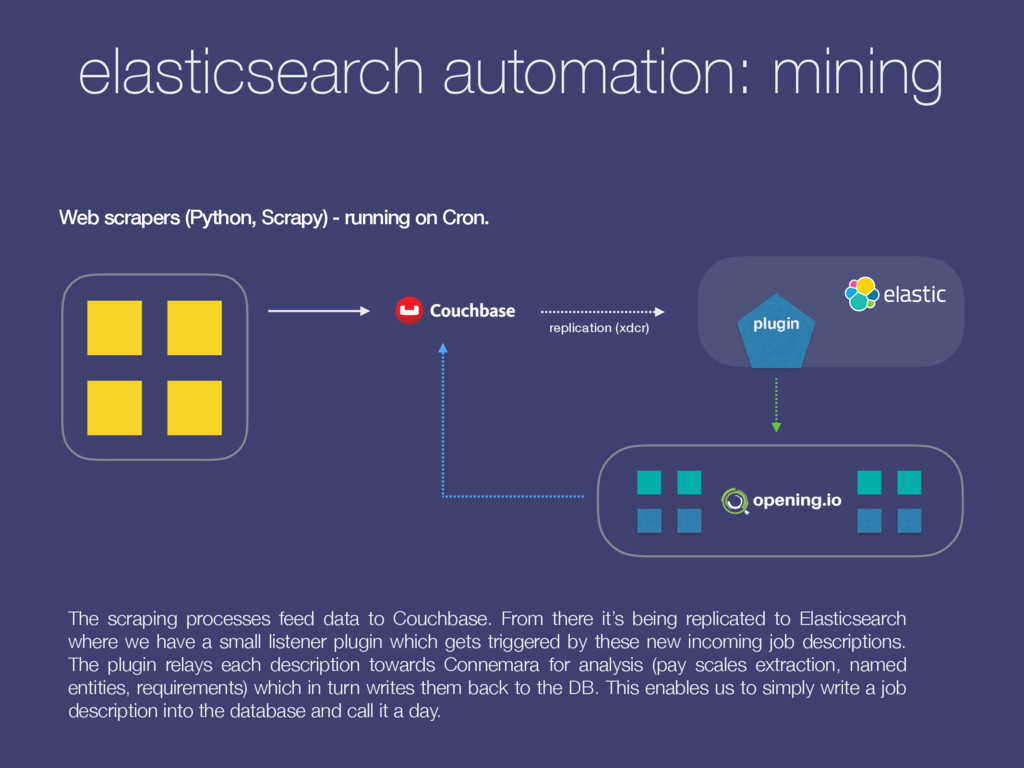
Cron. replication (xdcr) plugin The scraping processes feed data to Couchbase. From there it’s being replicated to Elasticsearch where we have a small listener plugin which gets triggered by these new incoming job descriptions. The plugin relays each description towards Connemara for analysis (pay scales extraction, named entities, requirements) which in turn writes them back to the DB. This enables us to simply write a job description into the database and call it a day.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![a simplified pipeline Services as pure actors Future[Json] parsedResume =](https://files.speakerdeck.com/presentations/69085c3b1f9745768a05282799482ba4/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}