2014, Andreas Herten (Institute for Nuclear Physics, Forschungszentrum Jülich, Germany) Enabling the Next Generation of Particle Physics Experiments: GPUs for Online Track Reconstruction
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world E=mc2
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world E=mc2
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world ✓ E=mc2
(HEP) in a nutshell: – 4 HEP Recipe 1. Accelerate particles (e, p,…) 2. Accelerate particles more! 3. Smash into each other 4. Look at resulting particles 5. Understand world ✓ – GPUs are interesting for HEP • Many events due to high collision rate • Events independent, dividable into subsets • Many features extractable (computational intensive) E=mc2
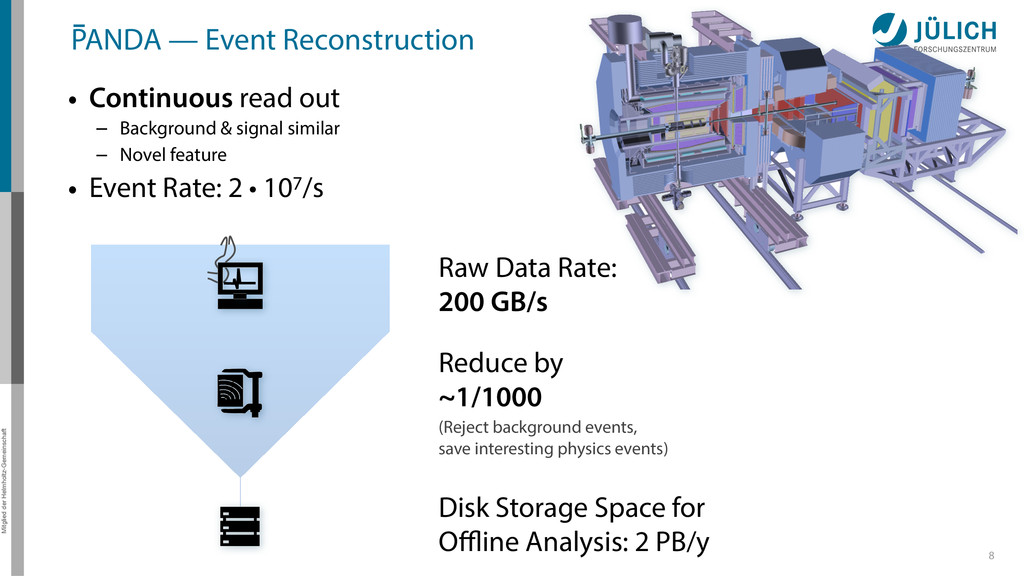
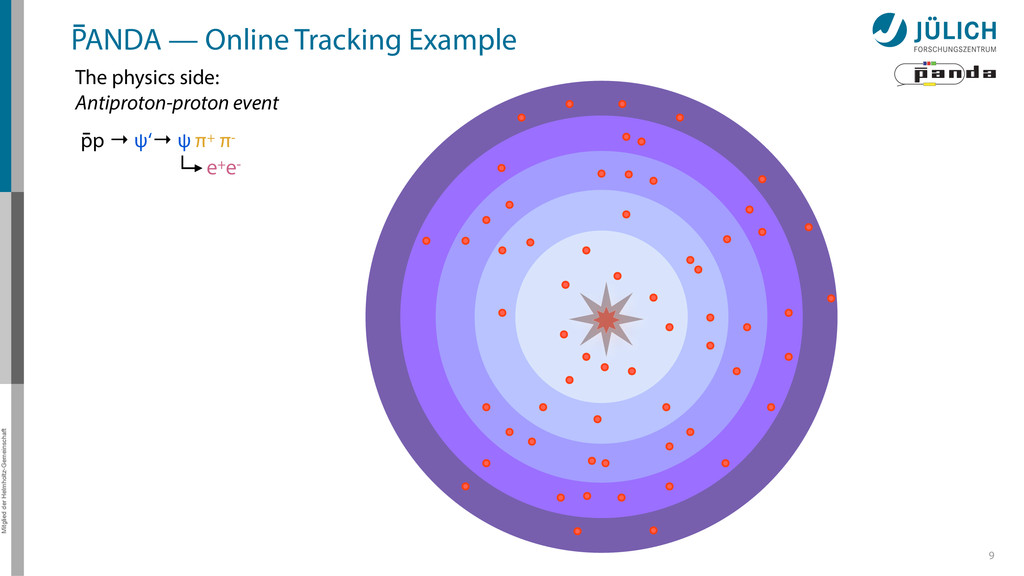
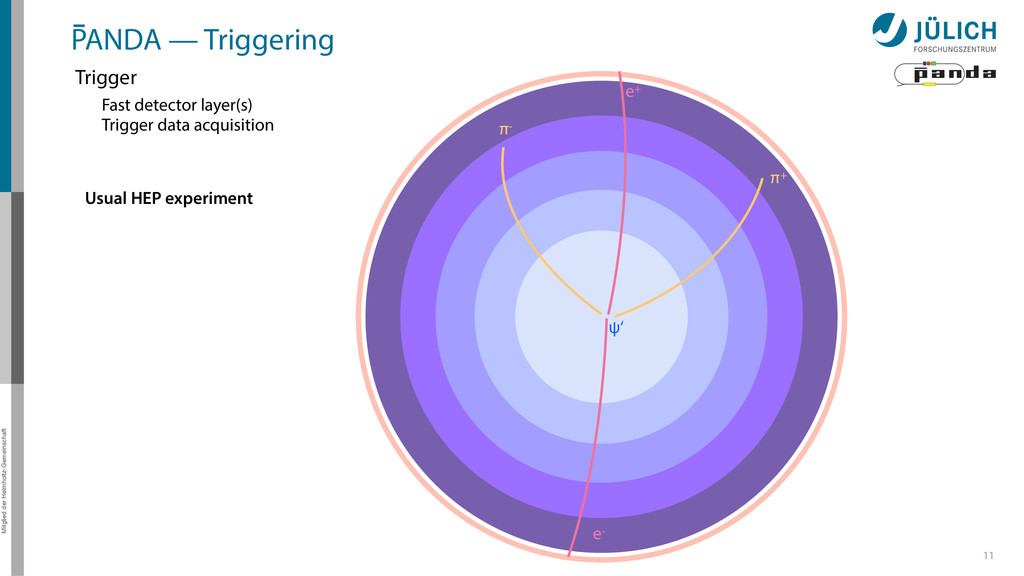
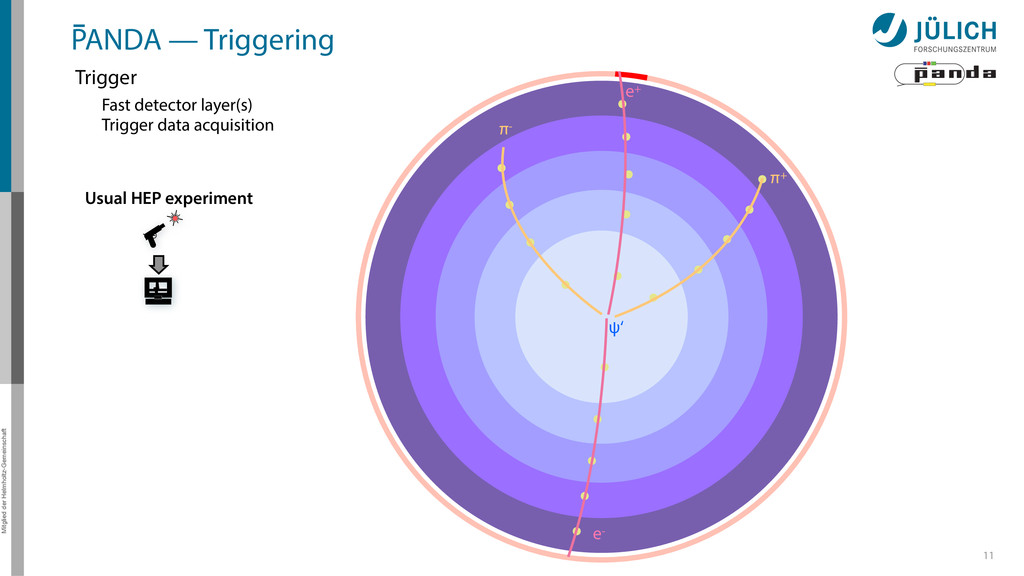
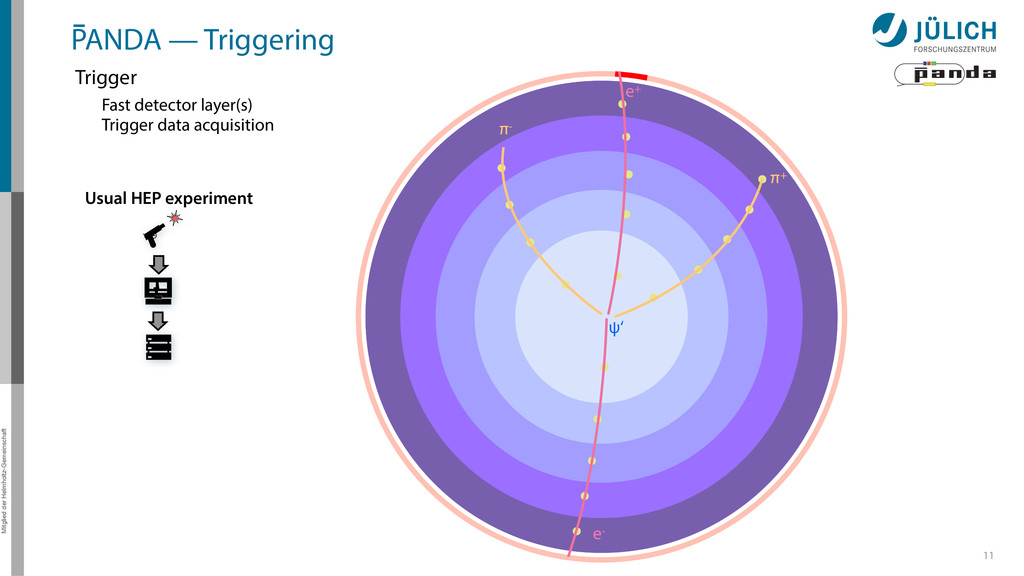
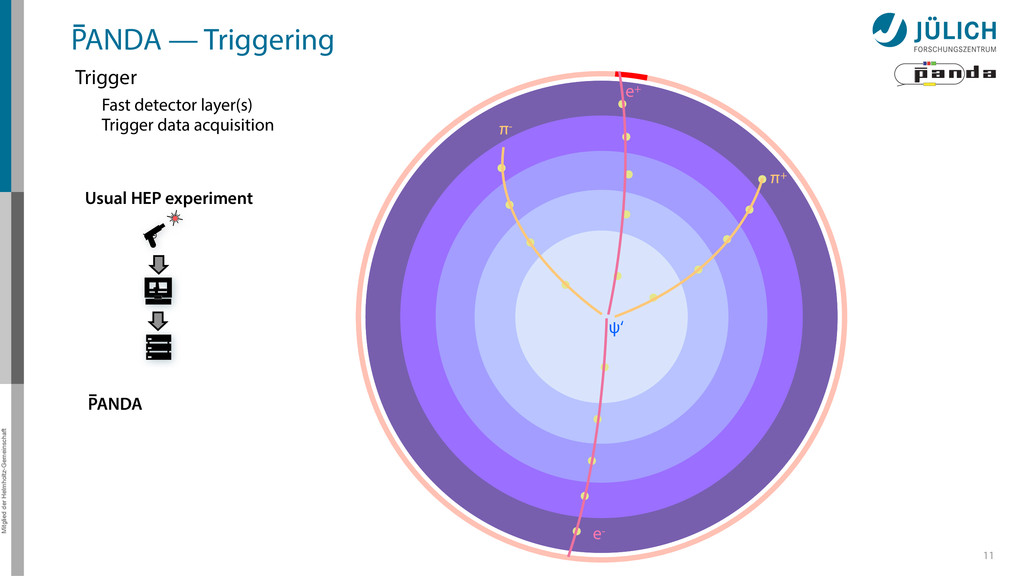
out – Background & signal similar – Novel feature • Event Rate: 2 • 107/s 8 Raw Data Rate: 200 GB/s Disk Storage Space for Offline Analysis: 2 PB/y Reduce by ~1/1000 (Reject background events, save interesting physics events)
out – Background & signal similar – Novel feature • Event Rate: 2 • 107/s 8 Raw Data Rate: 200 GB/s Disk Storage Space for Offline Analysis: 2 PB/y Reduce by ~1/1000 (Reject background events, save interesting physics events) GPUs
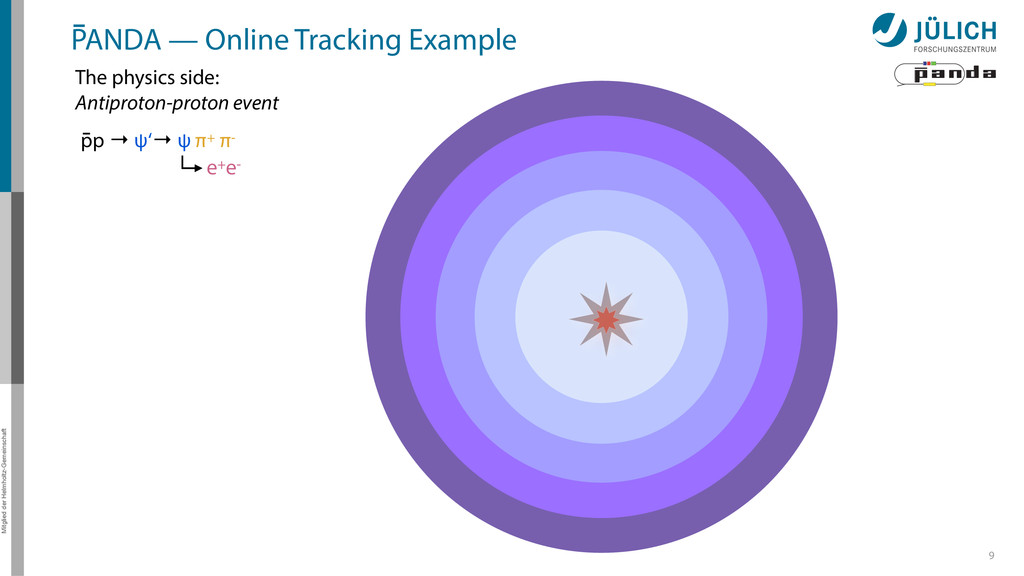
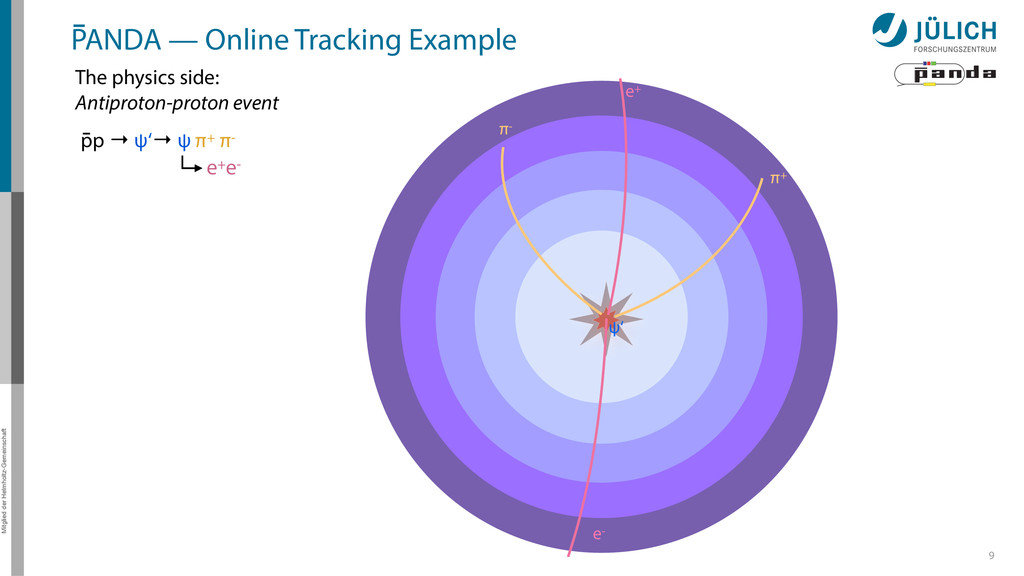
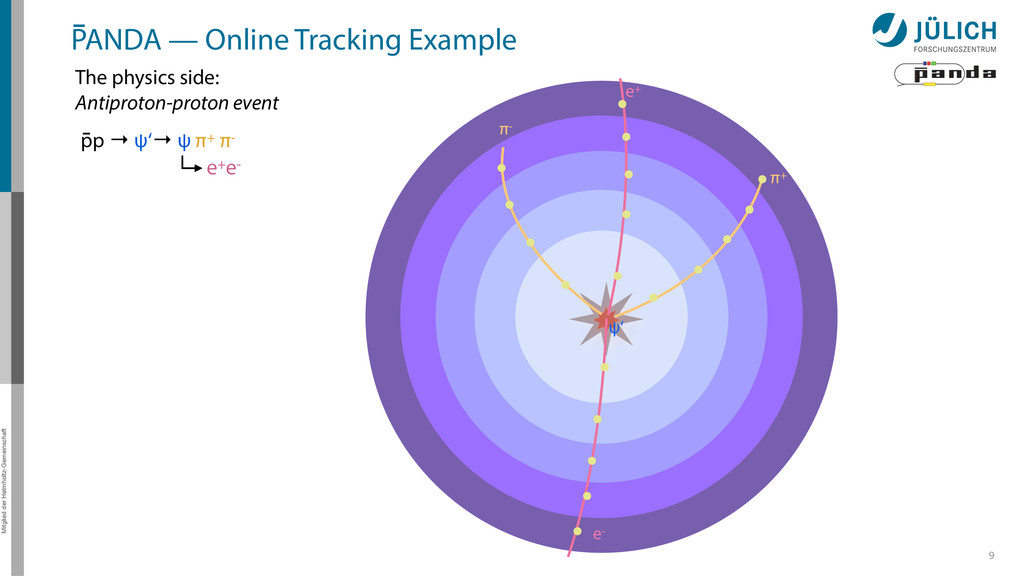
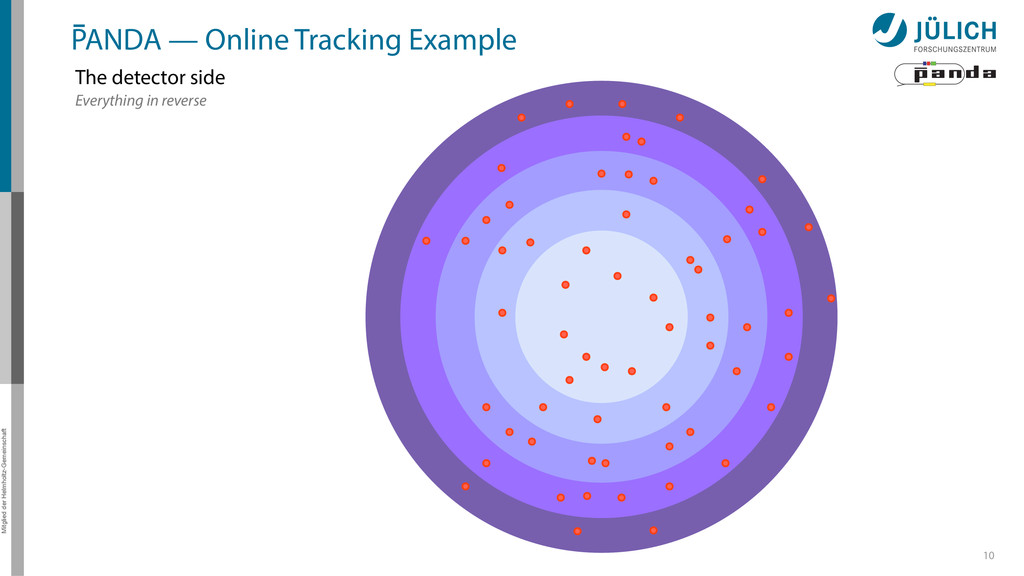
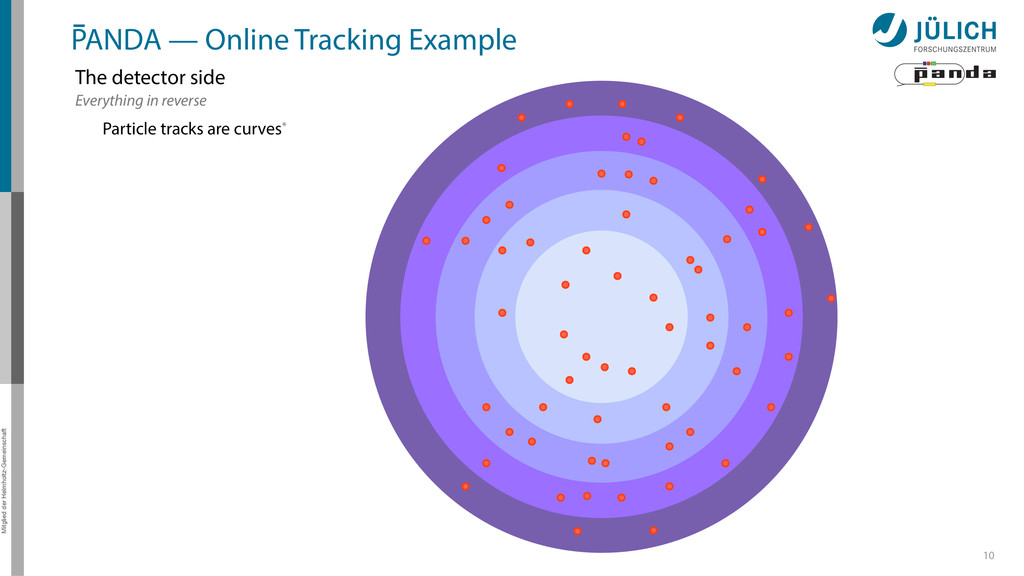
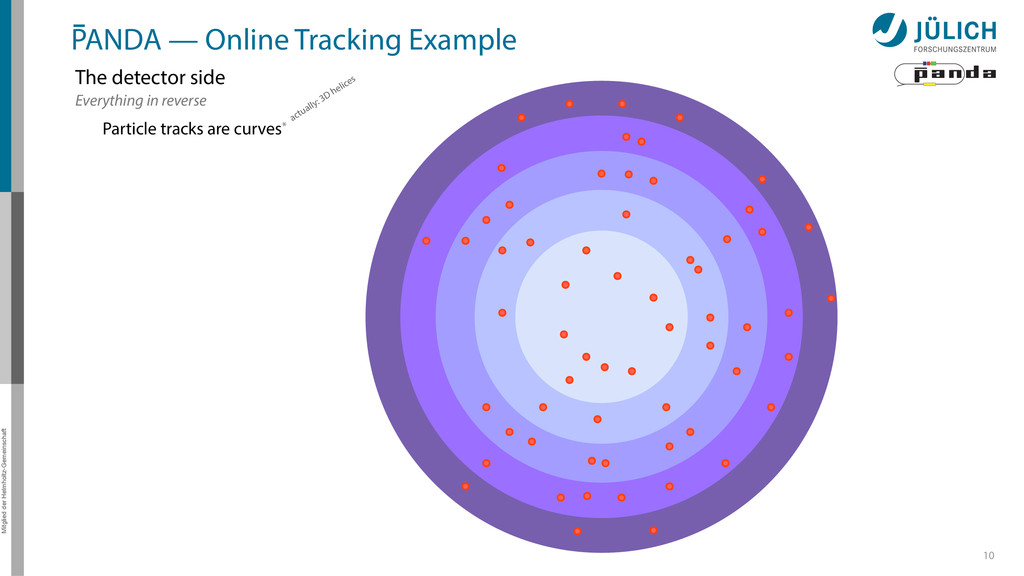
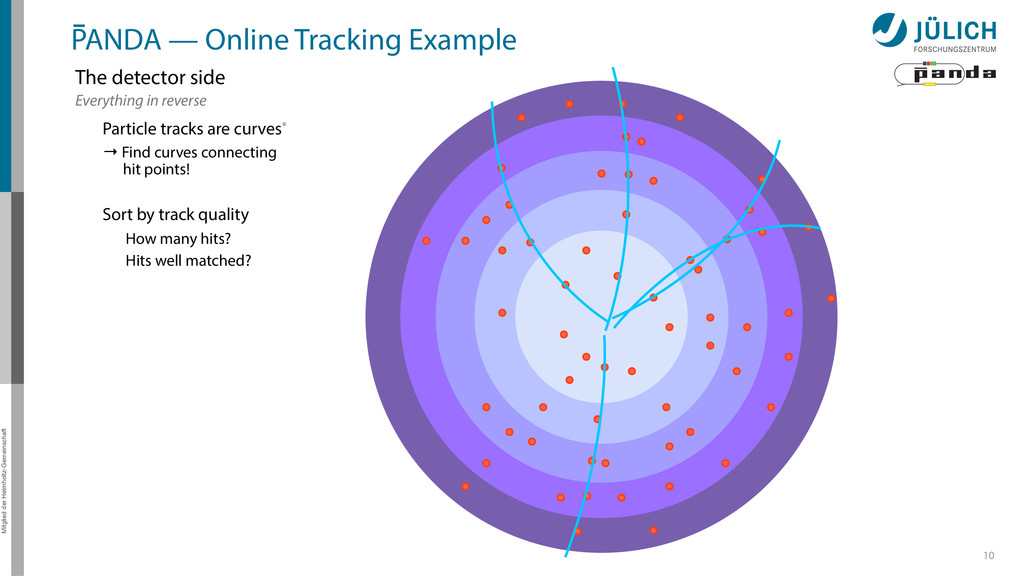
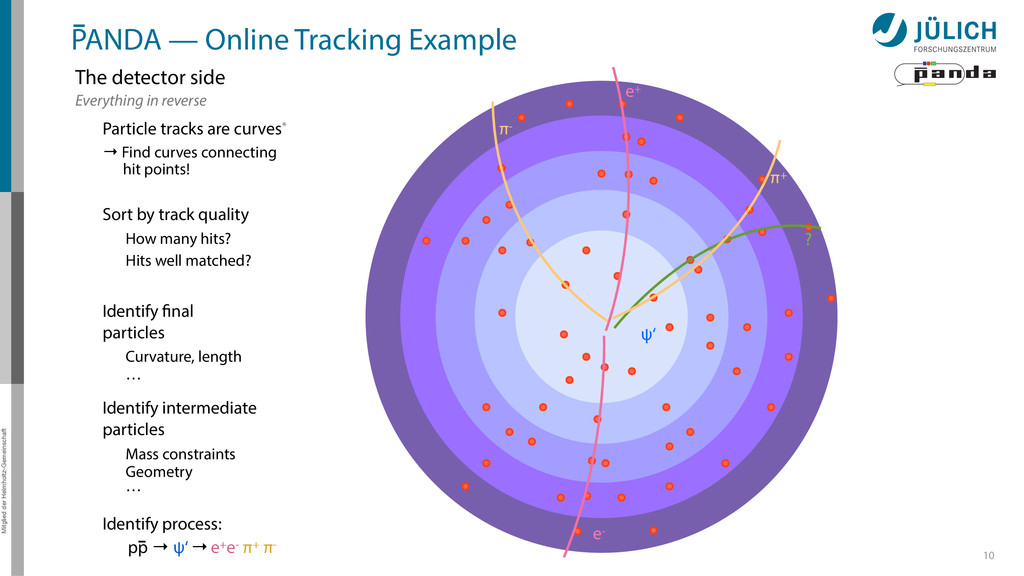
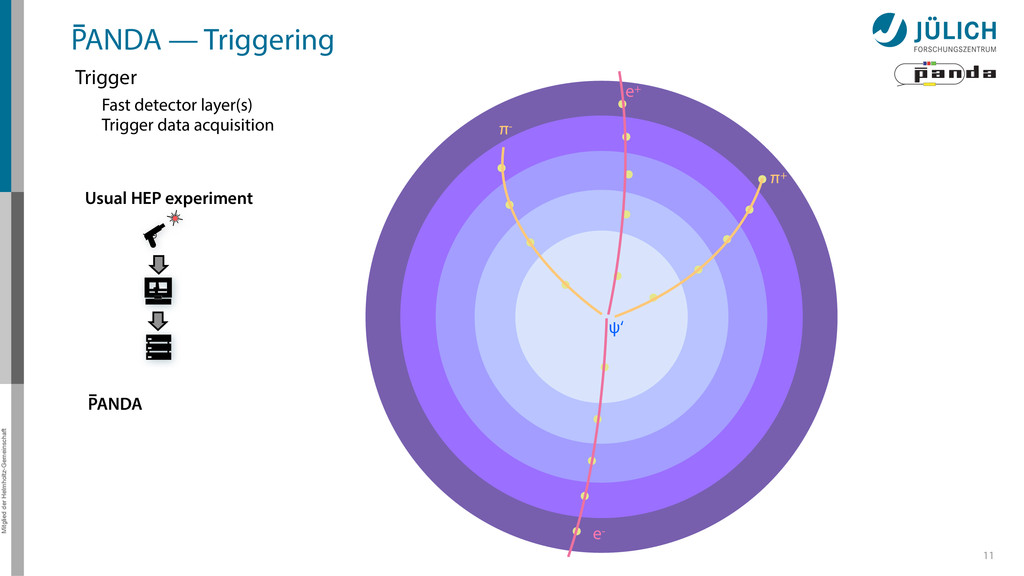
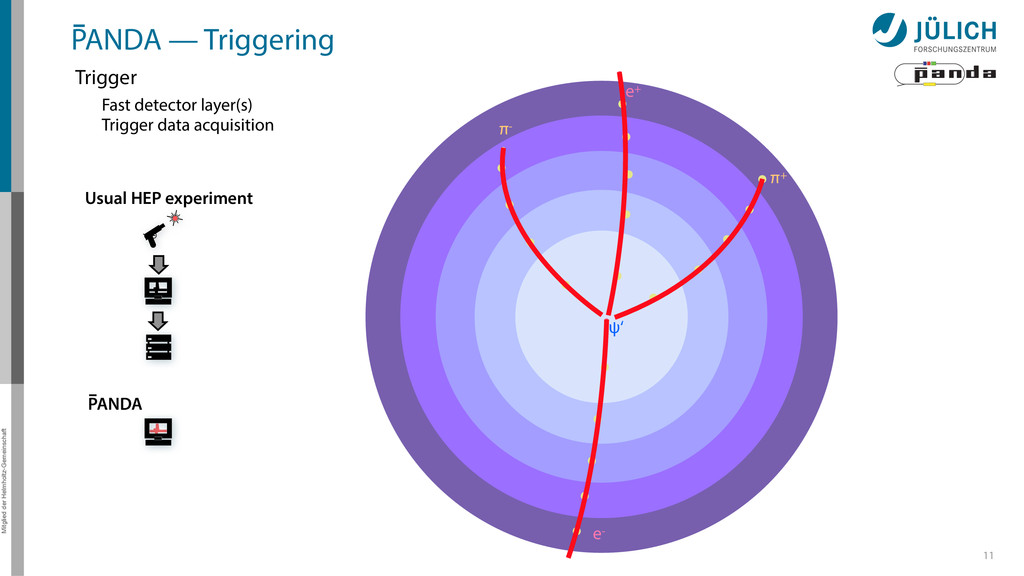
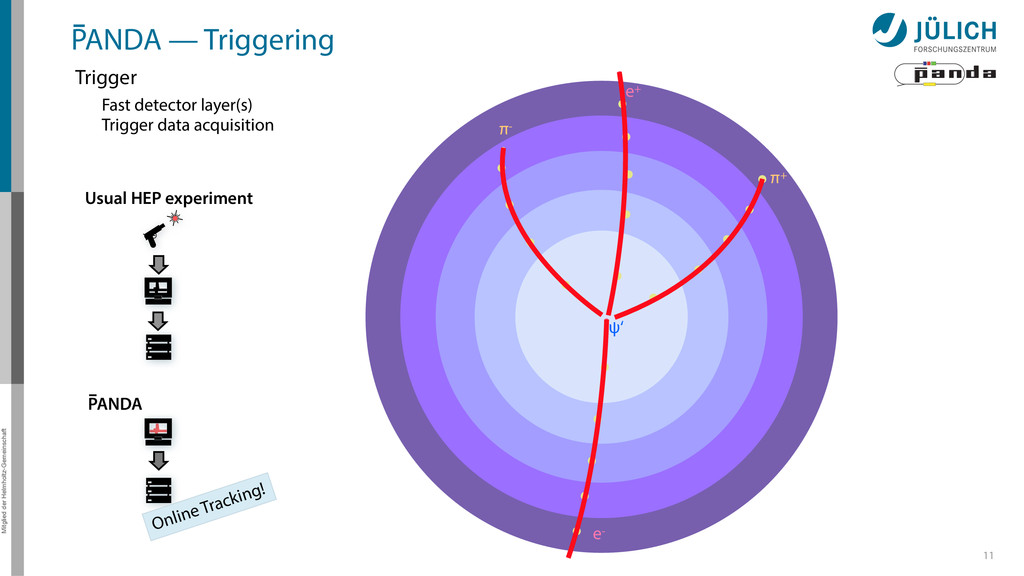
detector side Everything in reverse Particle tracks are curves* → Find curves connecting hit points! Sort by track quality Hits well matched? How many hits?
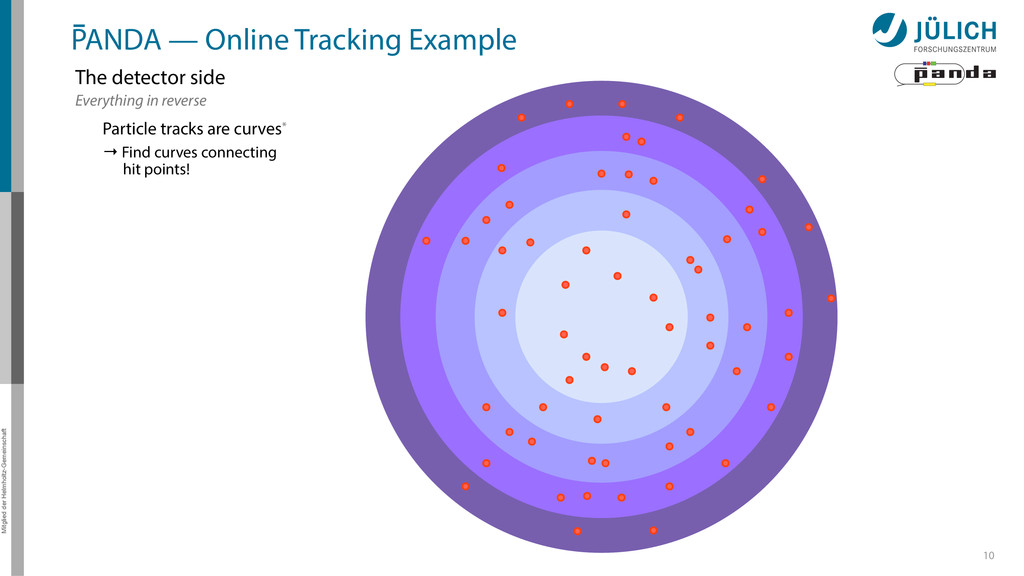
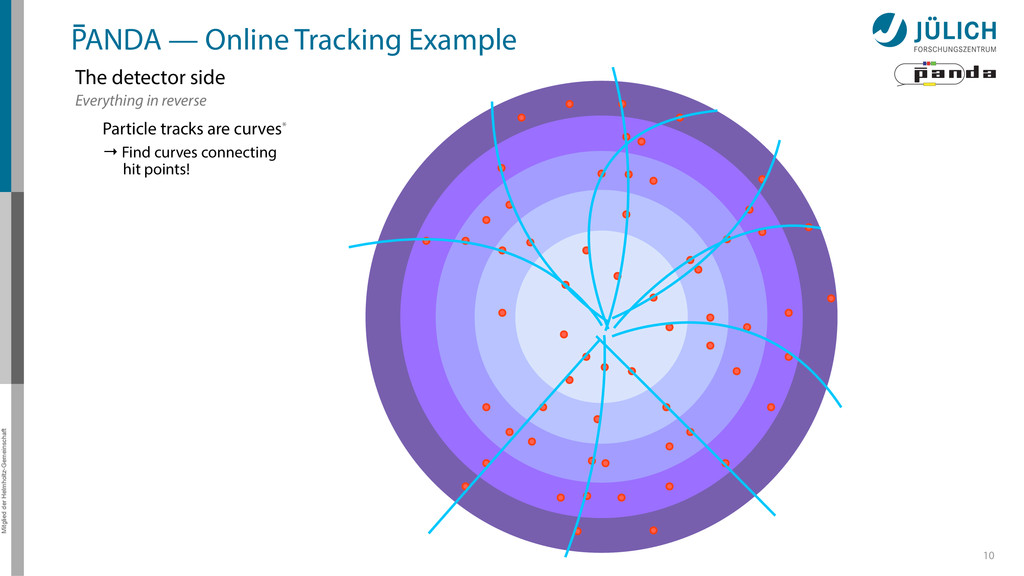
detector side Everything in reverse Particle tracks are curves* → Find curves connecting hit points! Sort by track quality Hits well matched? How many hits?
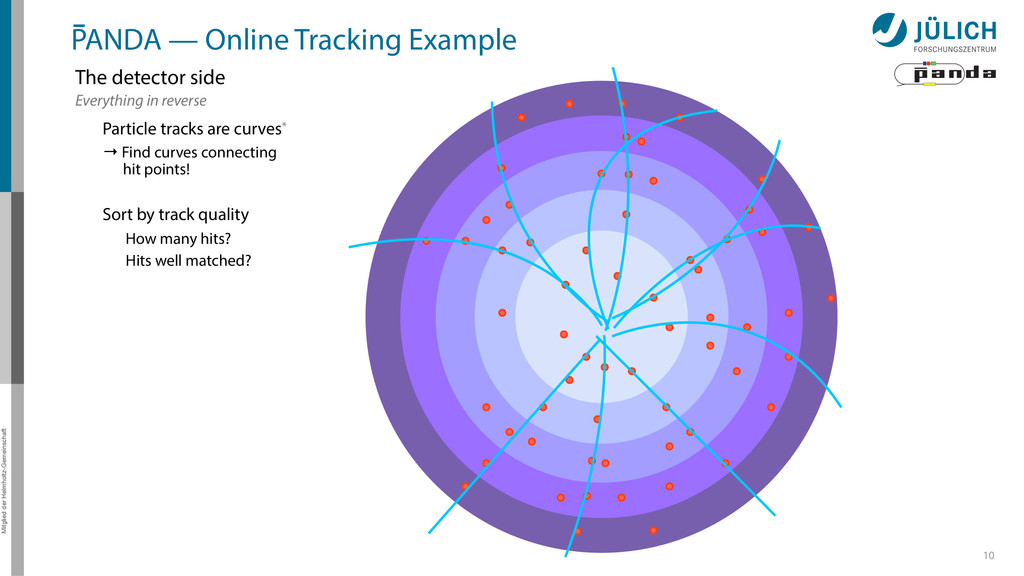
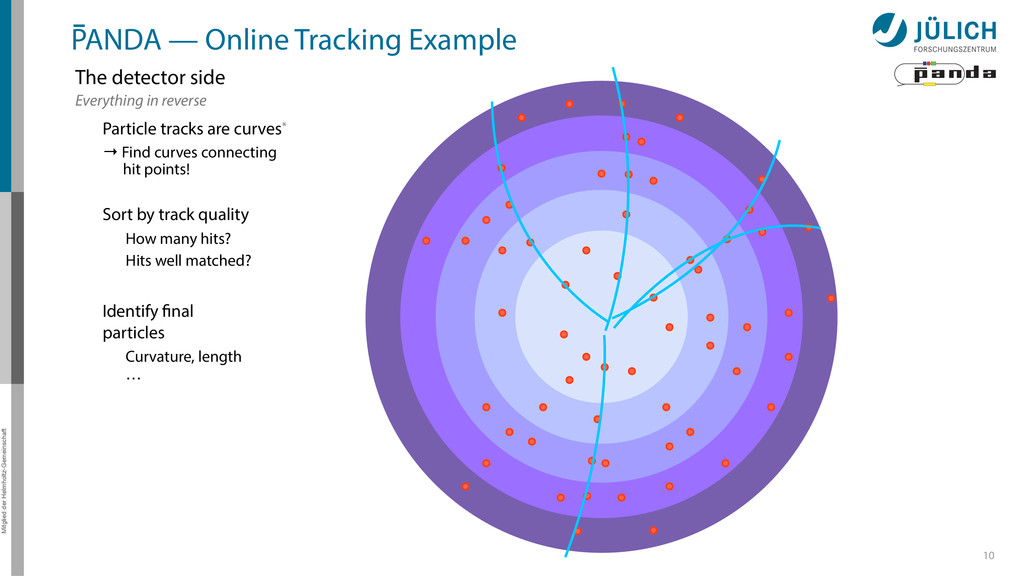
detector side Everything in reverse Particle tracks are curves* → Find curves connecting hit points! Sort by track quality Hits well matched? How many hits? Identify final particles Curvature, length …
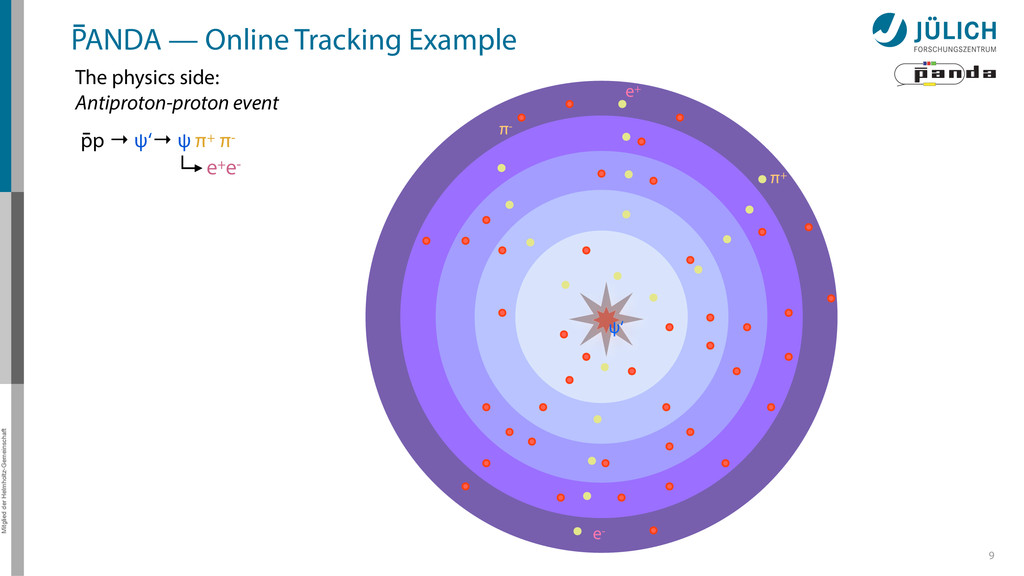
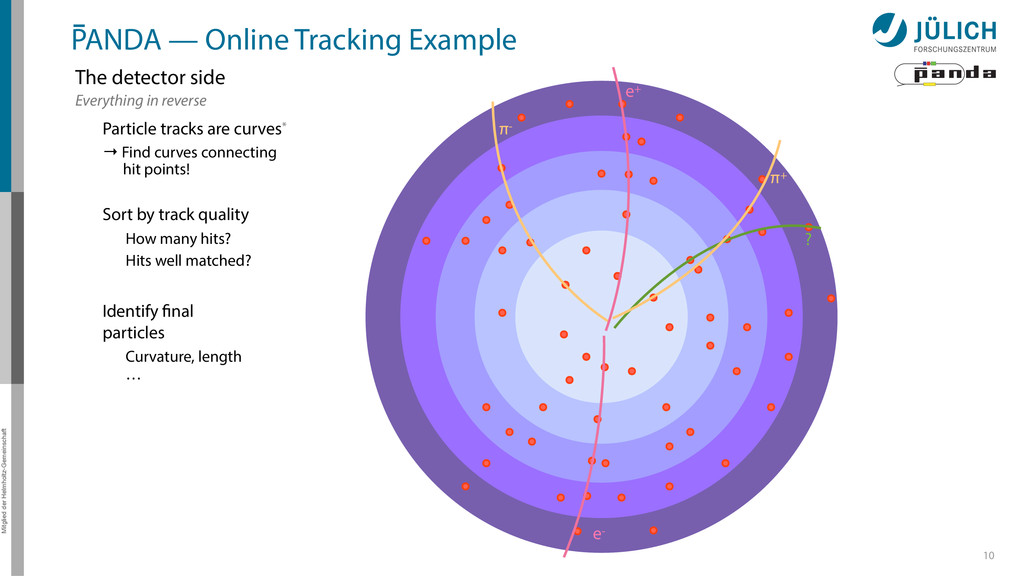
detector side Everything in reverse Particle tracks are curves* → Find curves connecting hit points! Sort by track quality Hits well matched? How many hits? Identify final particles Curvature, length … π+ π- e+ e- ?
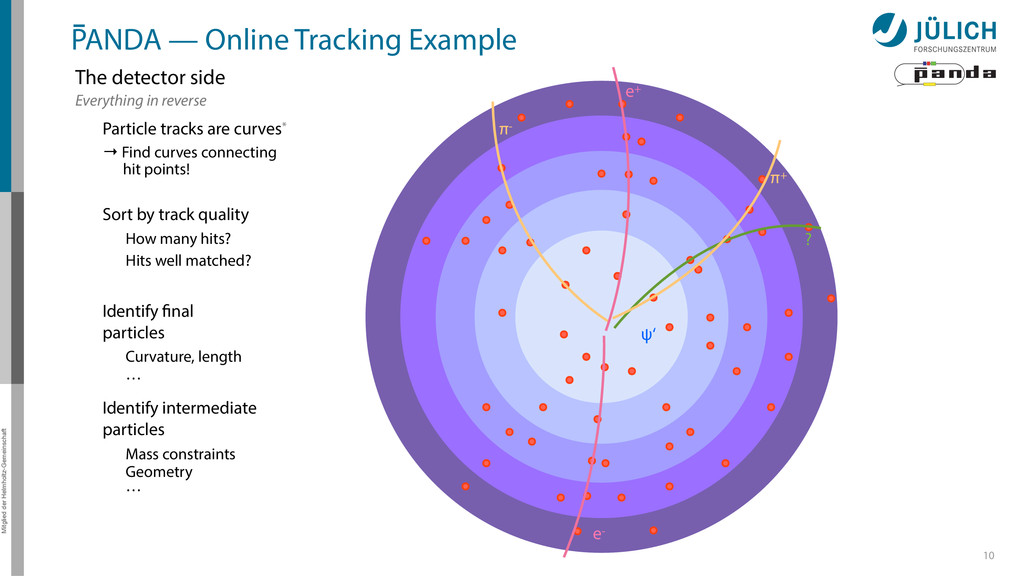
detector side Everything in reverse Particle tracks are curves* → Find curves connecting hit points! Sort by track quality Hits well matched? How many hits? Identify final particles Curvature, length … Identify intermediate particles Mass constraints Geometry … π+ π- e+ e- ? ψ‘
Port tracking algorithms to GPU – Serial → parallel – C++ → CUDA • Investigate suitability for online performance • But also: Find & invent tracking algorithms… • Under investigation: – Hough Transformation – Riemann Track Finder – Triplet Finder 13
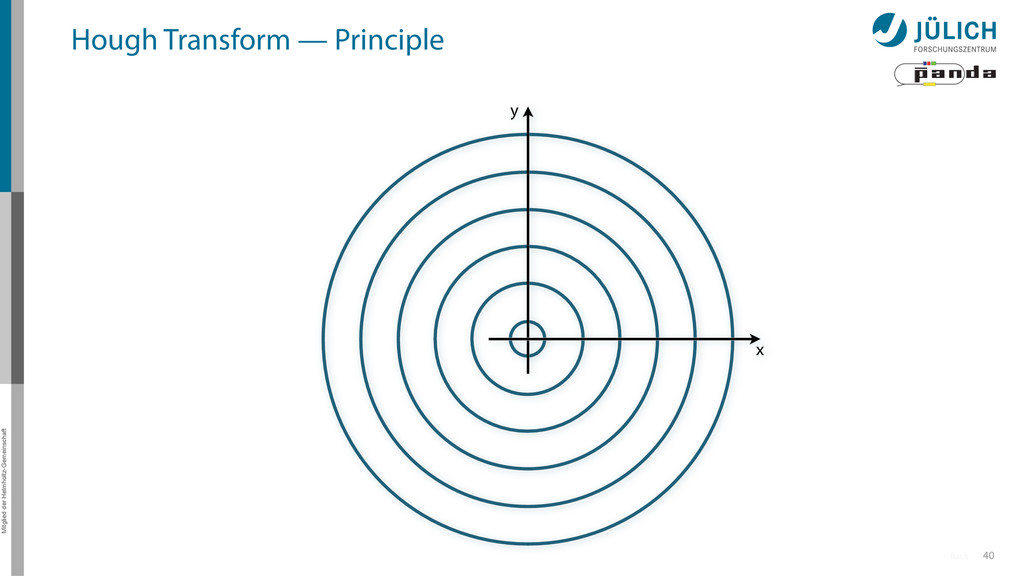
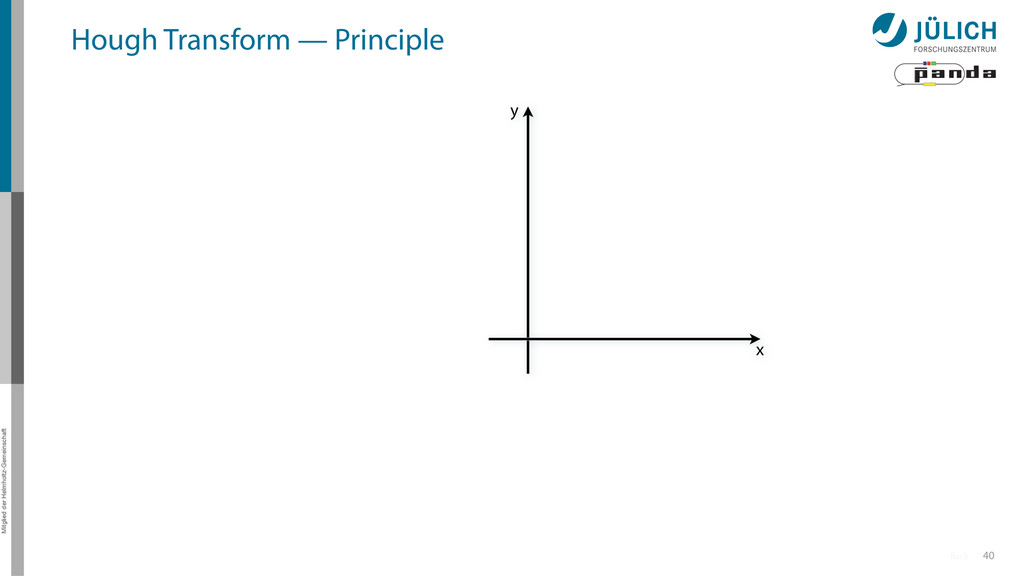
detection in images (from 1970s HEP experiments!) • New challenges for particle tracking algorithm – Only limited pixels per edge • Easily parallelizable method 15 Original algorithm by Hough, adapted by Duda & Hart
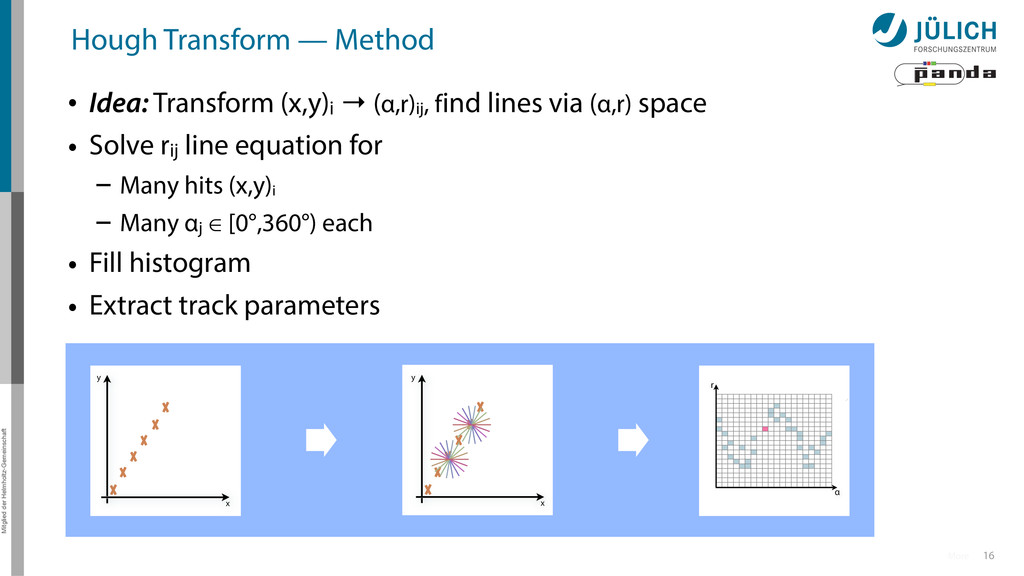
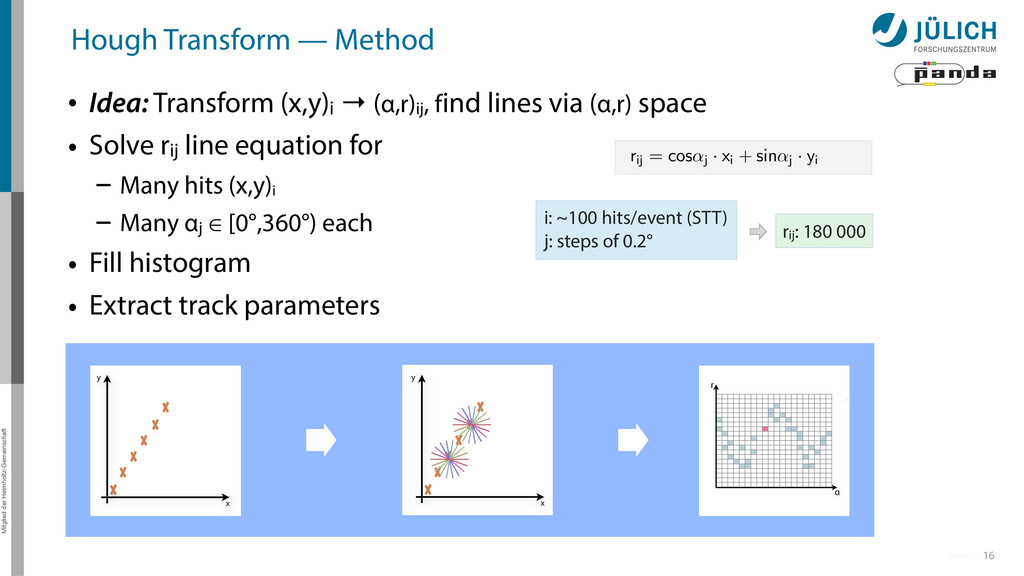
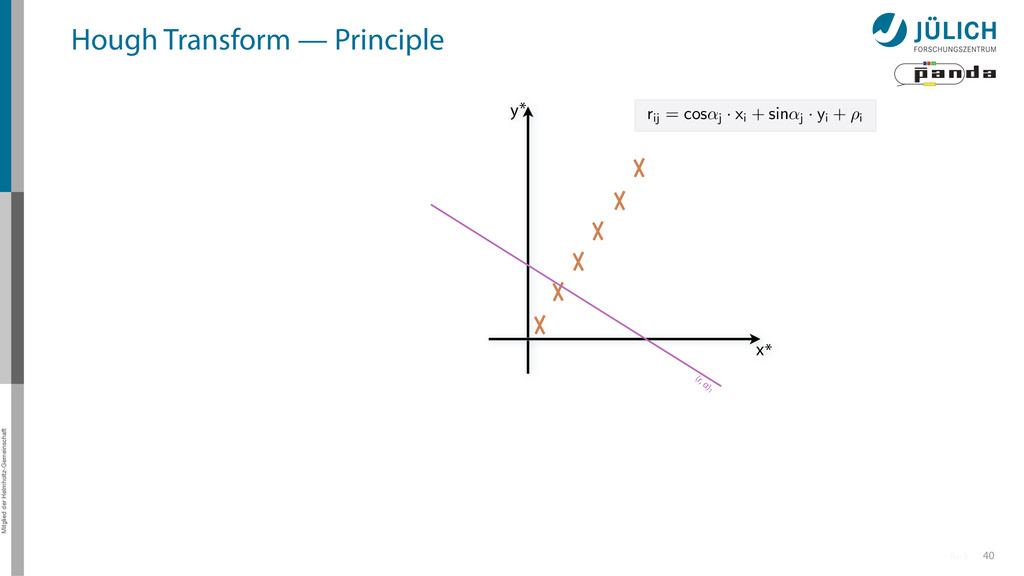
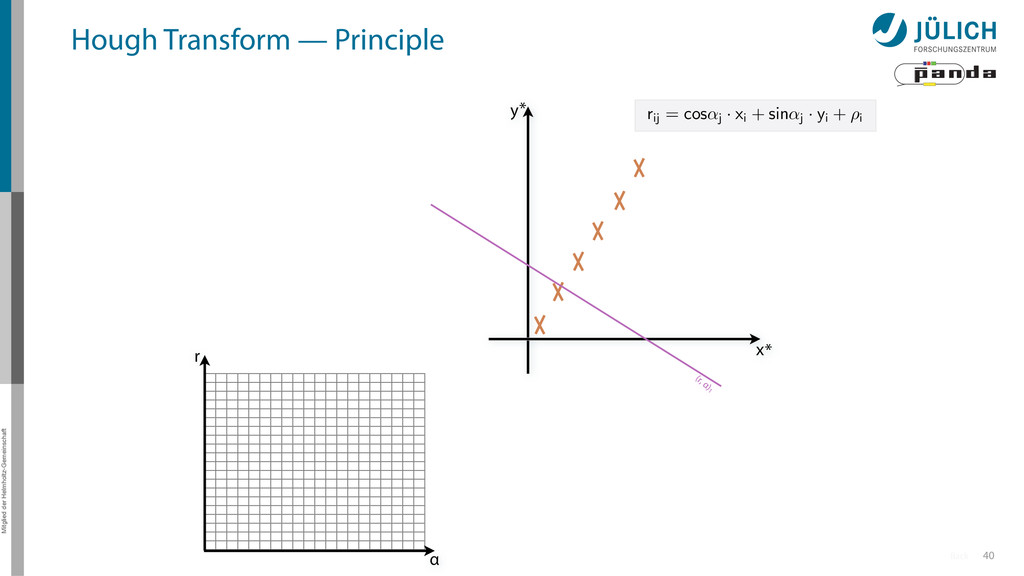
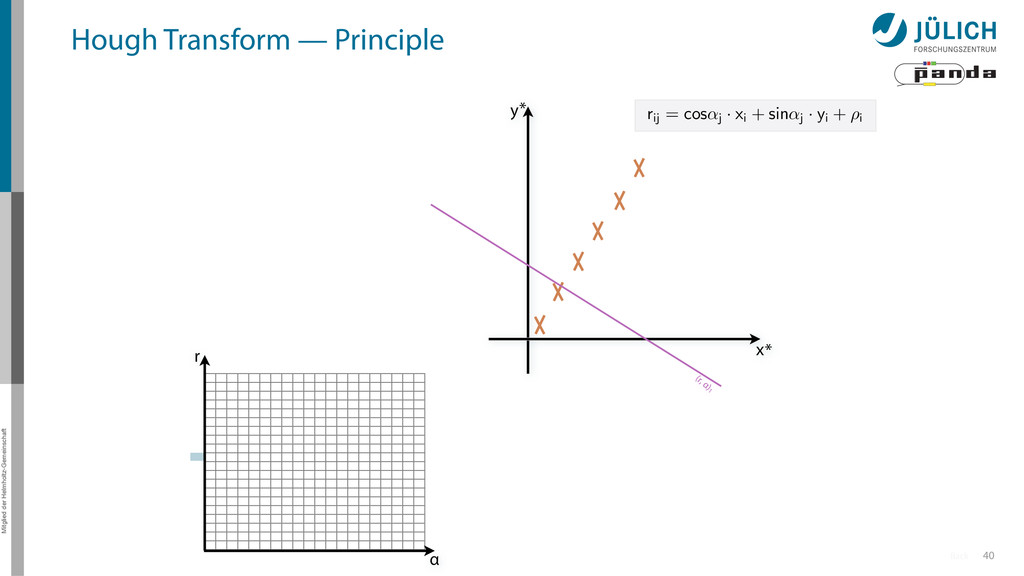
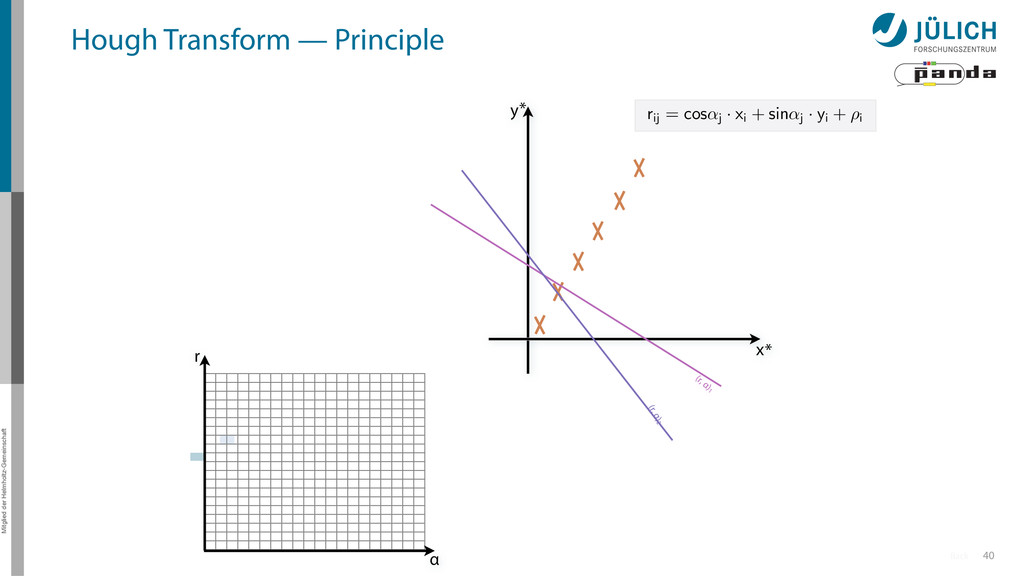
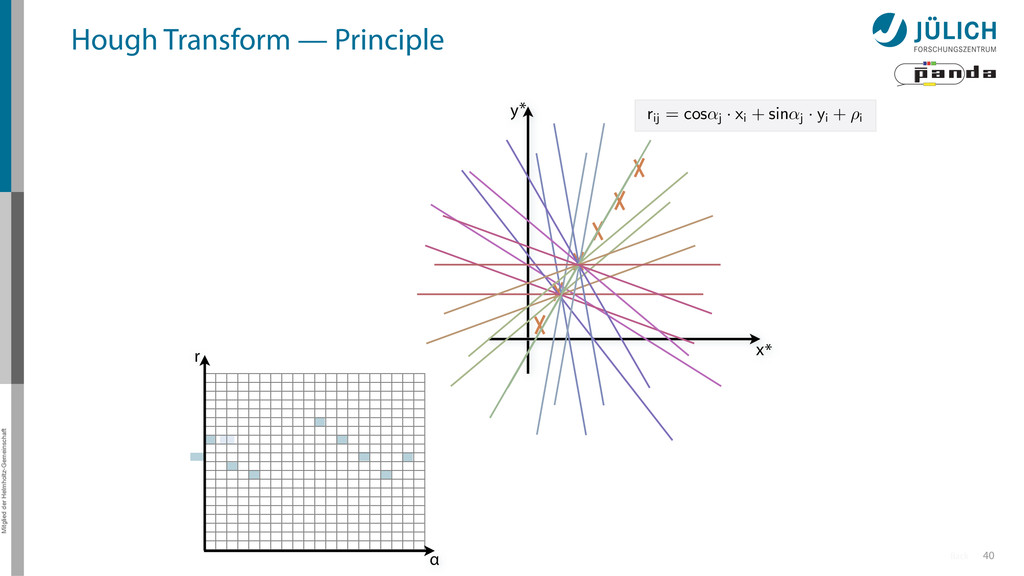
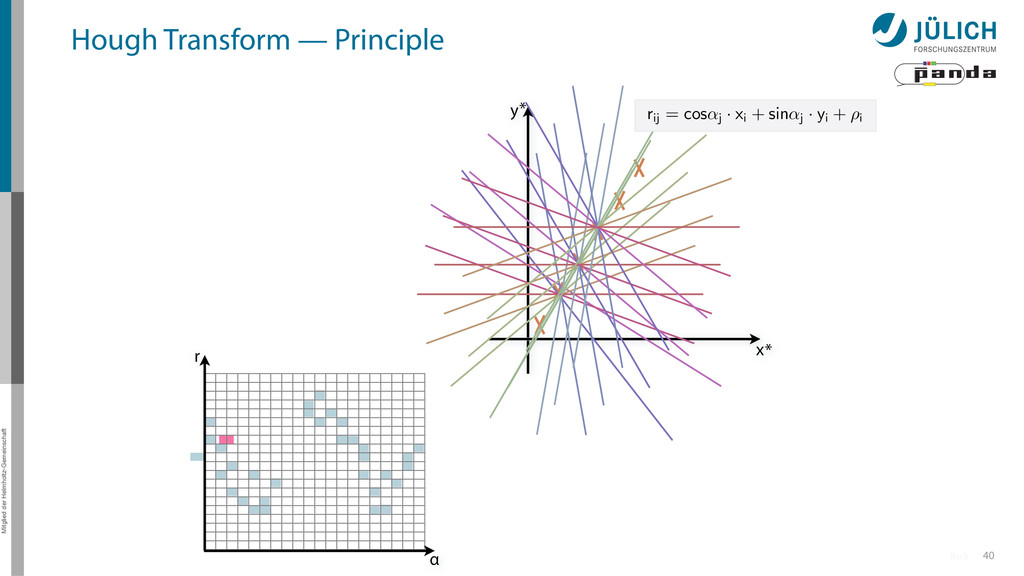
(x,y)i → (α,r)ij, find lines via (α,r) space • Solve rij line equation for – Many hits (x,y)i – Many αj ∈ [0°,360°) each • Fill histogram • Extract track parameters 16 x y x y Mitglied der Helmholtz-Gemeinschaft Hough Transform — Principle → Bin with highest multiplicity gives track parameters r α rij = cos ↵j · xi + sin ↵ More
(x,y)i → (α,r)ij, find lines via (α,r) space • Solve rij line equation for – Many hits (x,y)i – Many αj ∈ [0°,360°) each • Fill histogram • Extract track parameters 16 x y x y Mitglied der Helmholtz-Gemeinschaft Hough Transform — Principle → Bin with highest multiplicity gives track parameters r α rij = cos ↵j · xi + sin ↵ More i: ~100 hits/event (STT) j: steps of 0.2° rij: 180 000 rij = cos ↵j · xi + sin ↵j · yi
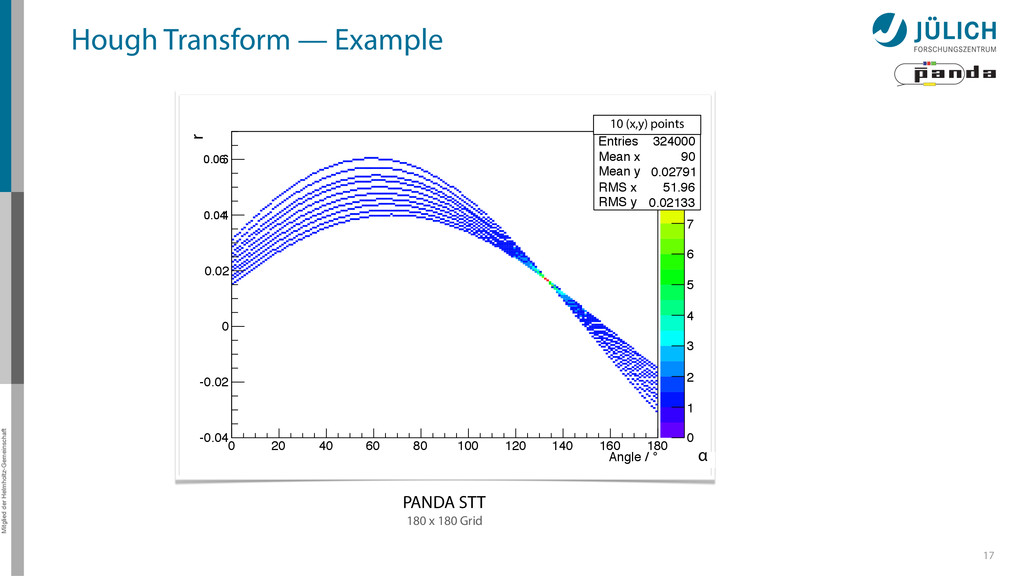
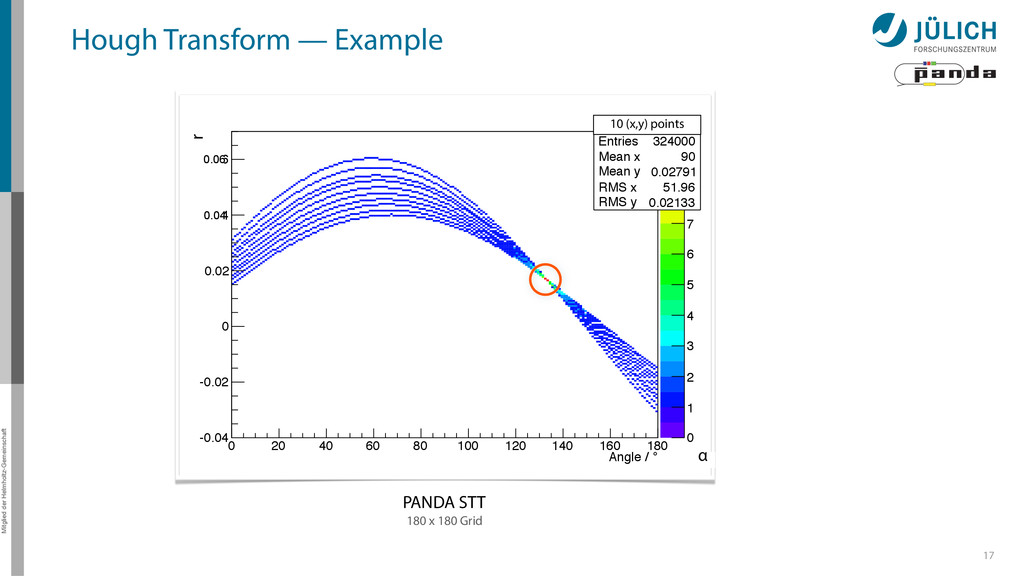
60 80 100 120 140 160 180 Hough transformed -0.04 -0.02 0 0.02 0.04 0.06 0 Entries 324000 Mean x 90 Mean y 0.02791 RMS x 51.96 RMS y 0.02133 0 1 2 3 4 5 6 7 8 9 10 0 Entries 324000 Mean x 90 Mean y 0.02791 RMS x 51.96 RMS y 0.02133 PANDA STT 180 x 180 Grid r 0.06 0.04 α Hough Transform — Example 10 (x,y) points
60 80 100 120 140 160 180 Hough transformed -0.04 -0.02 0 0.02 0.04 0.06 0 Entries 324000 Mean x 90 Mean y 0.02791 RMS x 51.96 RMS y 0.02133 0 1 2 3 4 5 6 7 8 9 10 0 Entries 324000 Mean x 90 Mean y 0.02791 RMS x 51.96 RMS y 0.02133 PANDA STT 180 x 180 Grid r 0.06 0.04 α Hough Transform — Example 10 (x,y) points
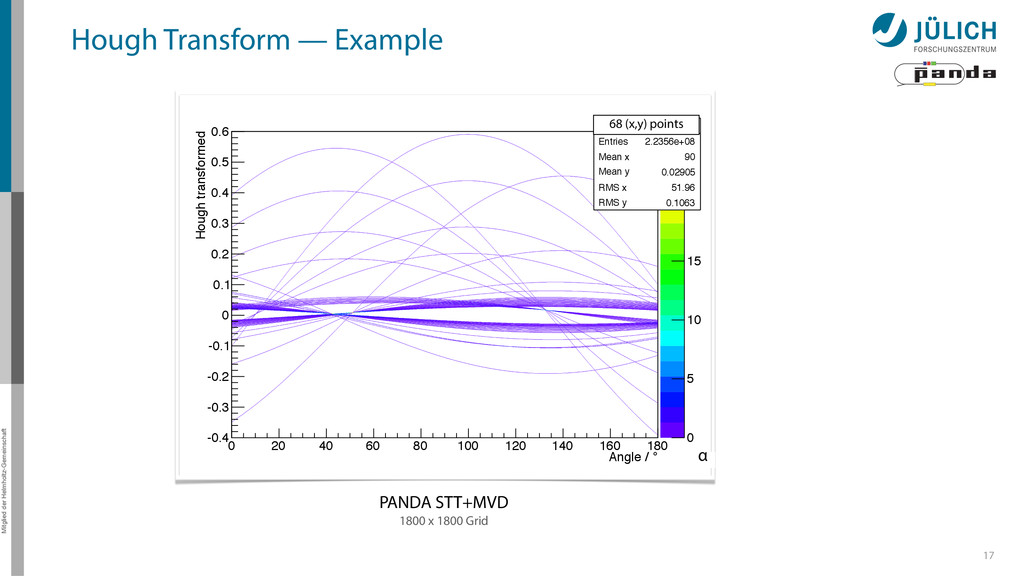
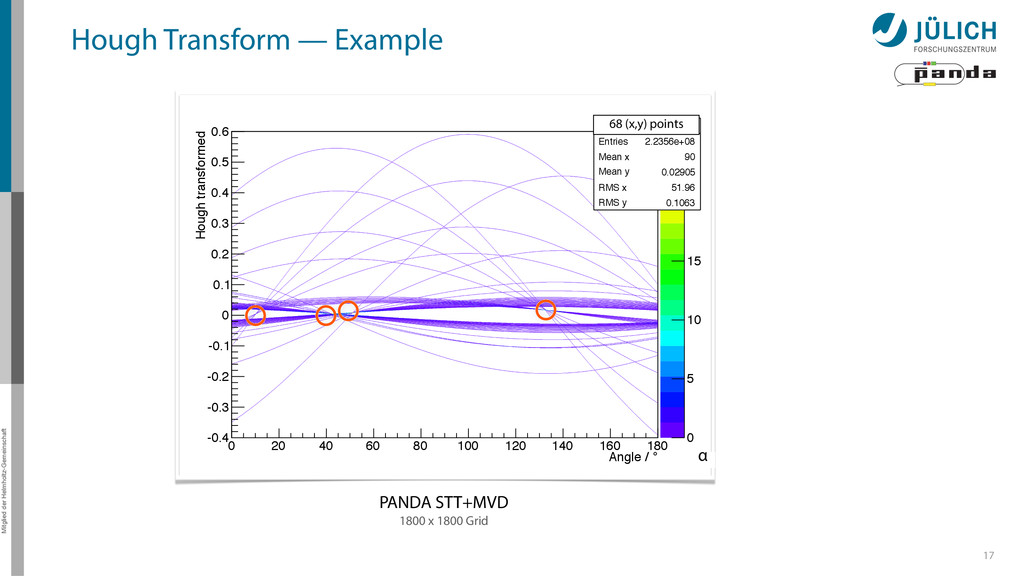
0 20 40 60 80 100 120 140 160 180 Hough transformed -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 0 5 10 15 20 25 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 1800 x 1800 Grid PANDA STT+MVD 68 (x,y) points α Hough Transform — Example
0 20 40 60 80 100 120 140 160 180 Hough transformed -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 0 5 10 15 20 25 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 1800 x 1800 Grid PANDA STT+MVD 68 (x,y) points α Hough Transform — Example
Thrust Plain CUDA • Performance: 3 ms/event – Independent of angular granularity – Reduced to set of standard routines • Fast (uses Thrust‘s optimized algorithms) • Inflexible (has it‘s limits, hard to customize) – No peakfinding included • Even possible? • Adds to time! • Performance: 0.5 ms/event – Built completely for this task • Fitting to every problem • Customizable • A bit more complicated at parts – Simple peakfinder implemented (threshold) • Using: Dynamic Parallelism, Shared Memory
use in PANDA‘s offline analysis framework for long time – Good results – Well-understood – Handling of uncertainties • Work by Jonathan Timcheck – Summer student at Jülich Based on work by Strandlie et al
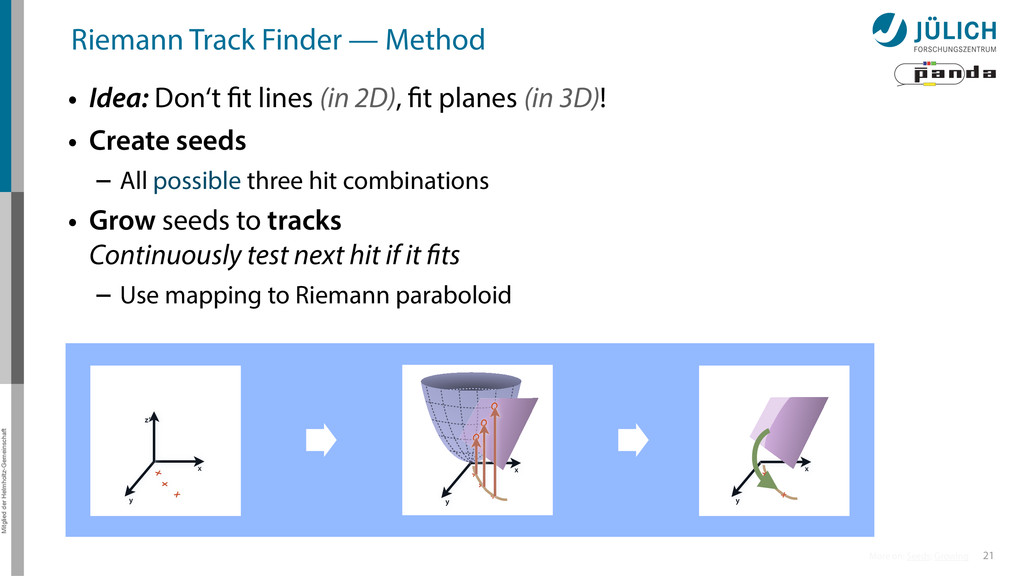
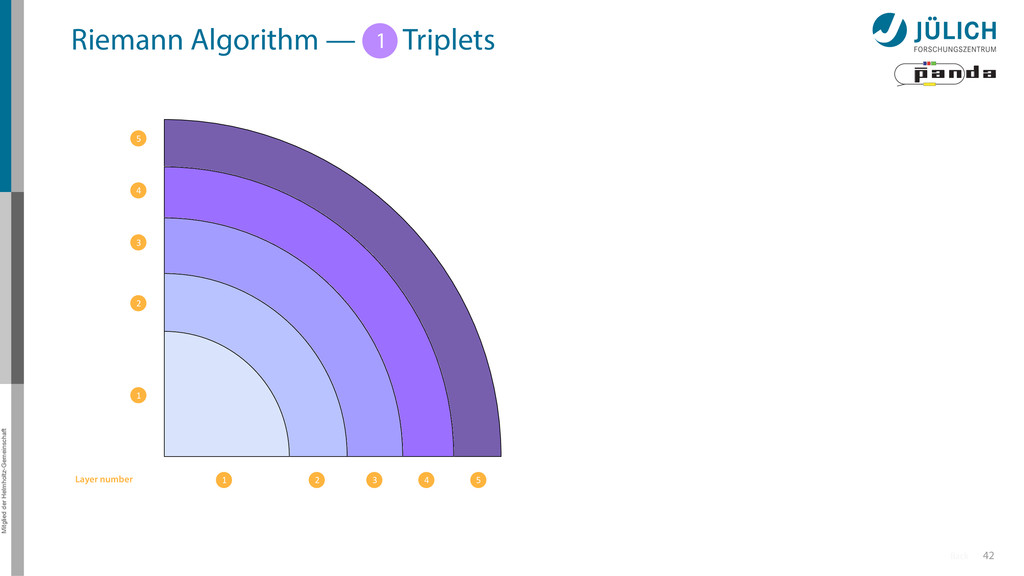
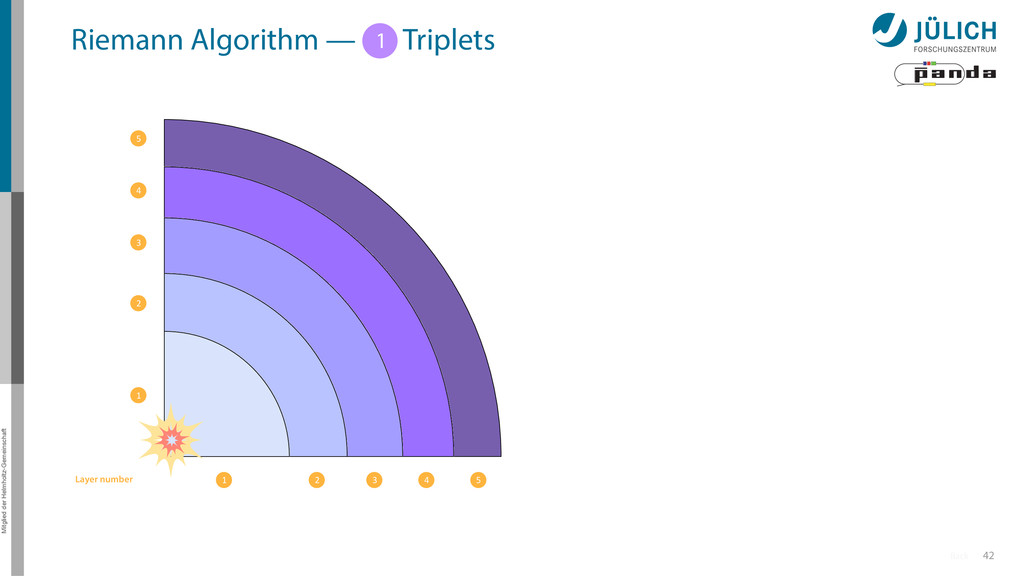
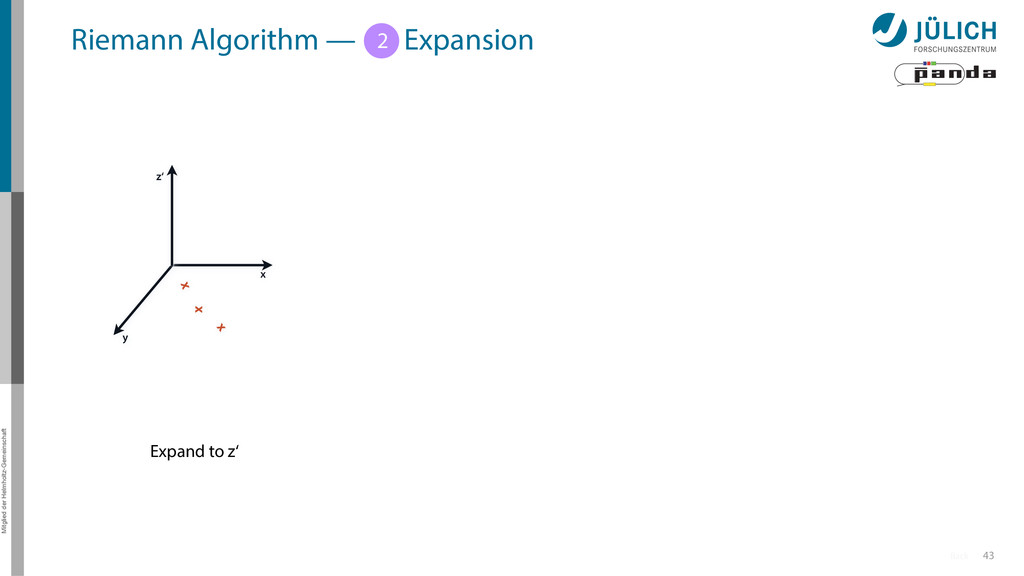
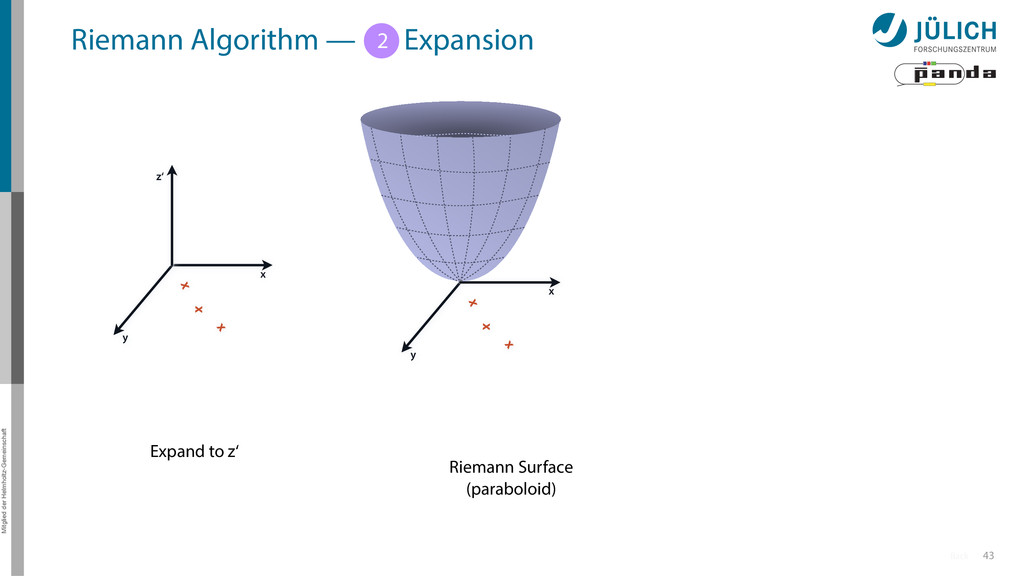
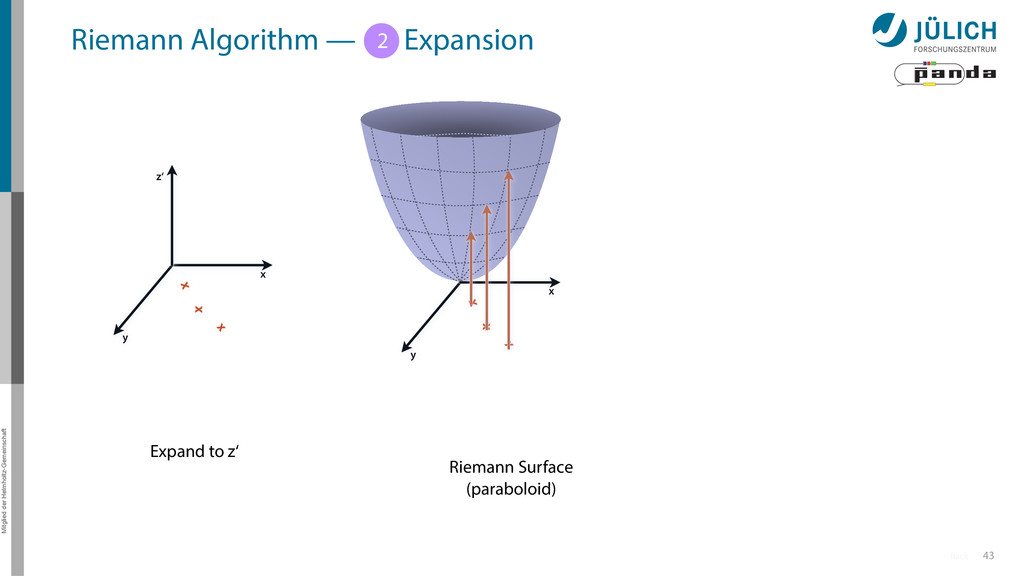
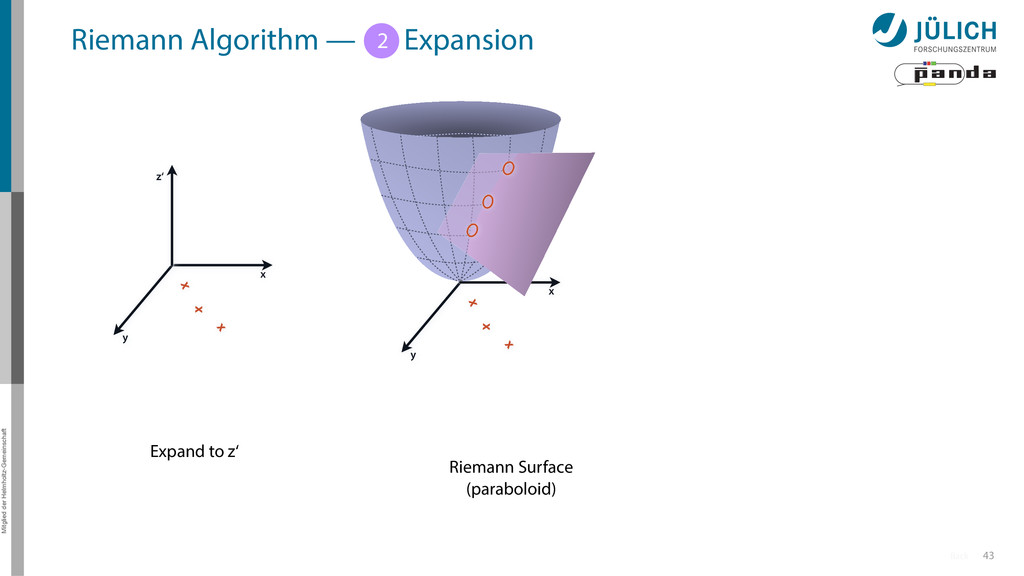
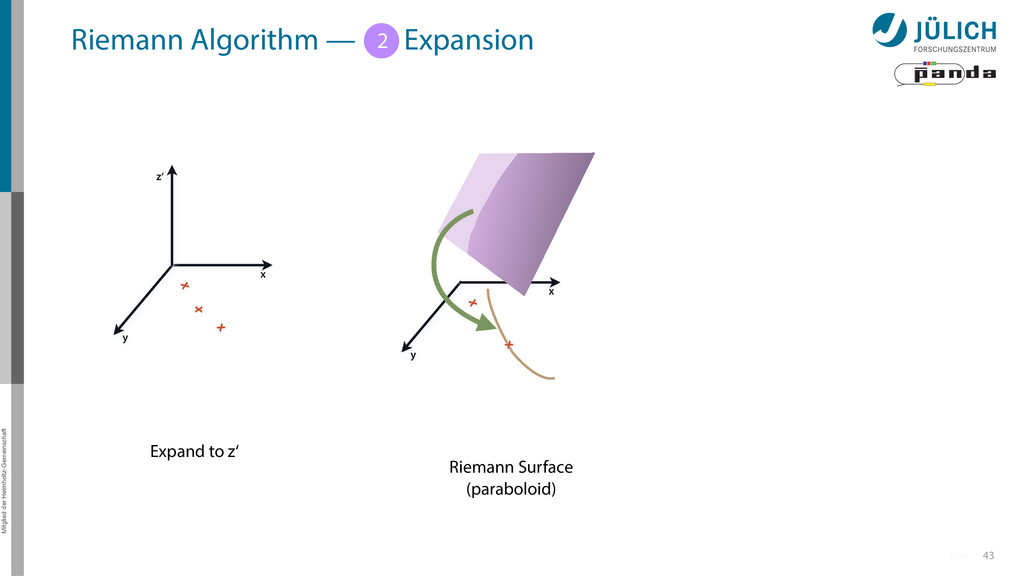
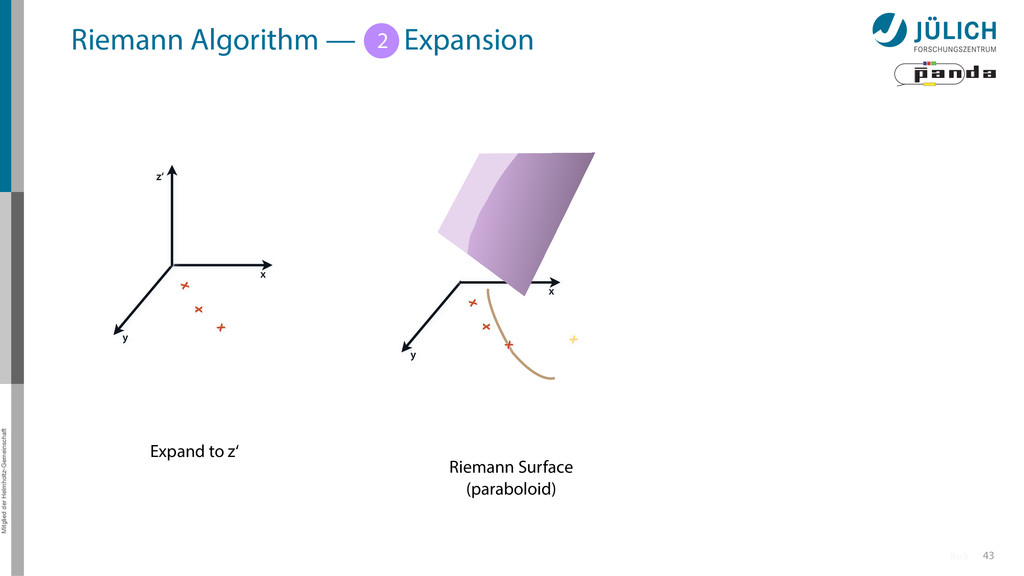
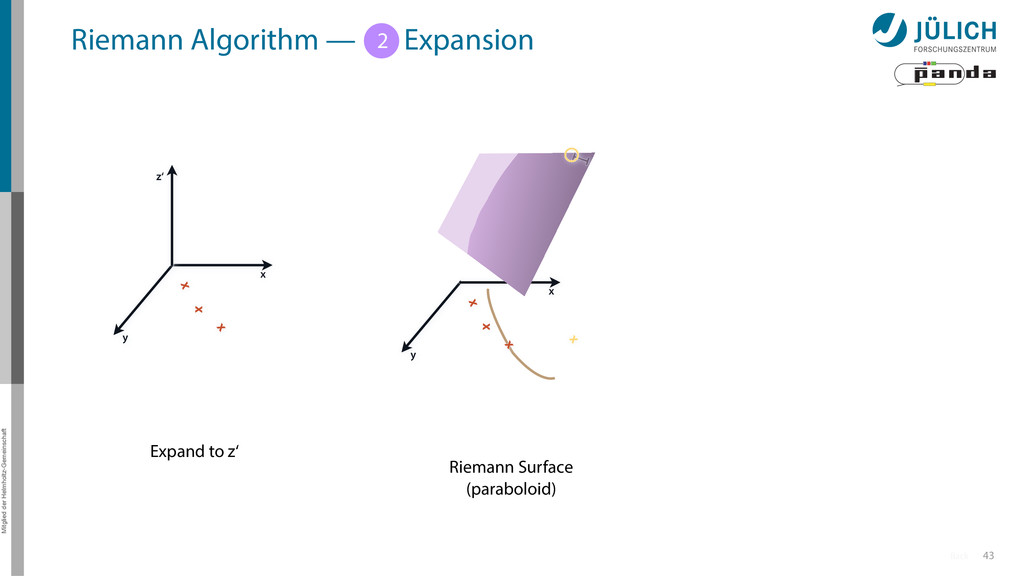
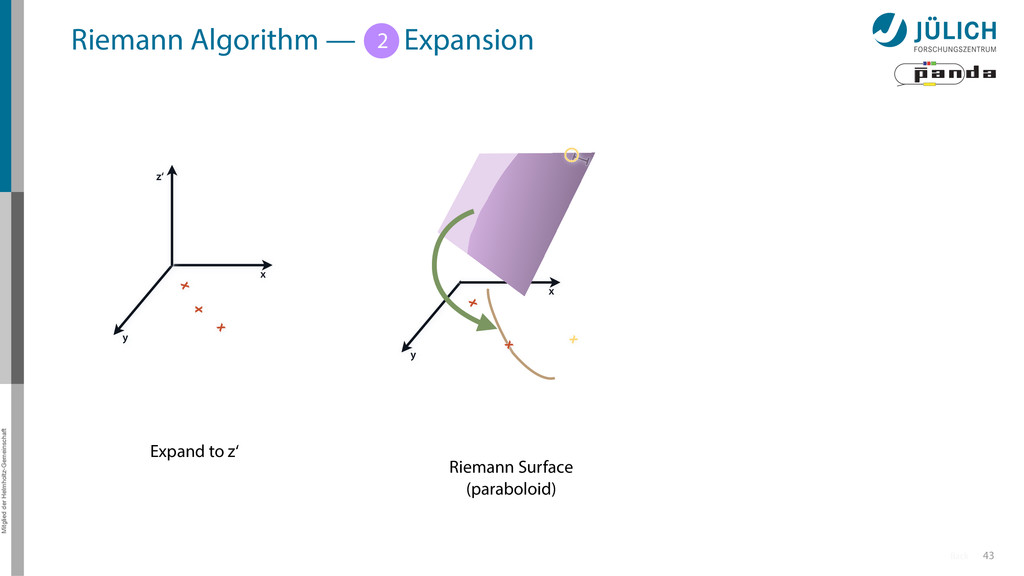
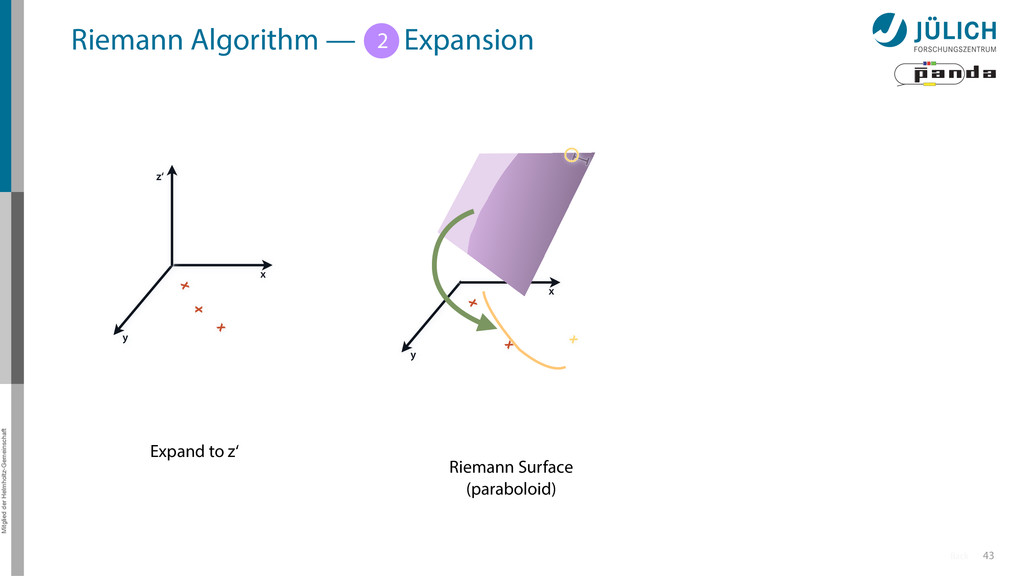
Idea: Don‘t fit lines (in 2D), fit planes (in 3D)! • Create seeds – All possible three hit combinations • Grow seeds to tracks Continuously test next hit if it fits – Use mapping to Riemann paraboloid x x x x y z‘ x x x y x x x x y x More on: Seeds; Growing
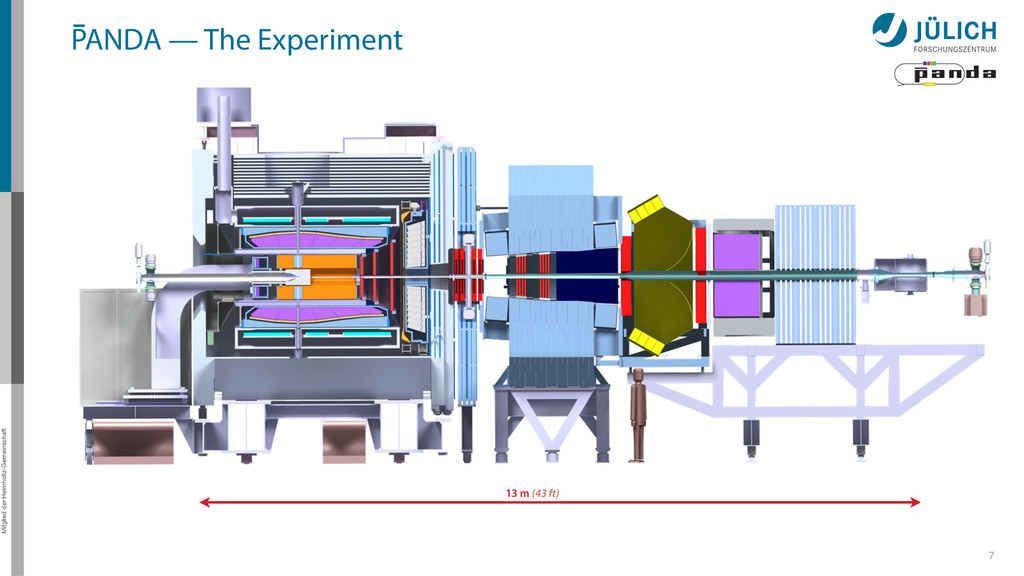
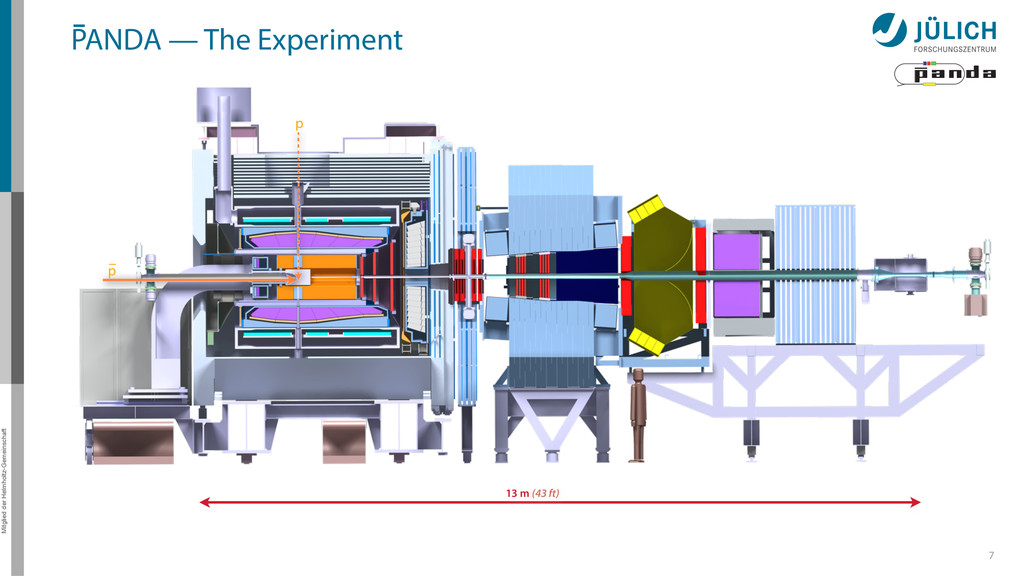
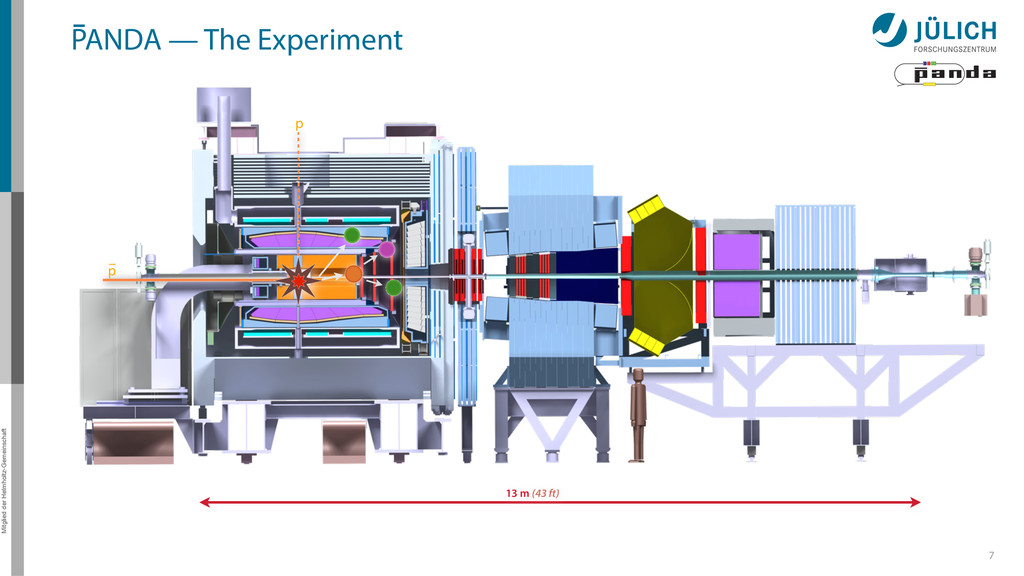
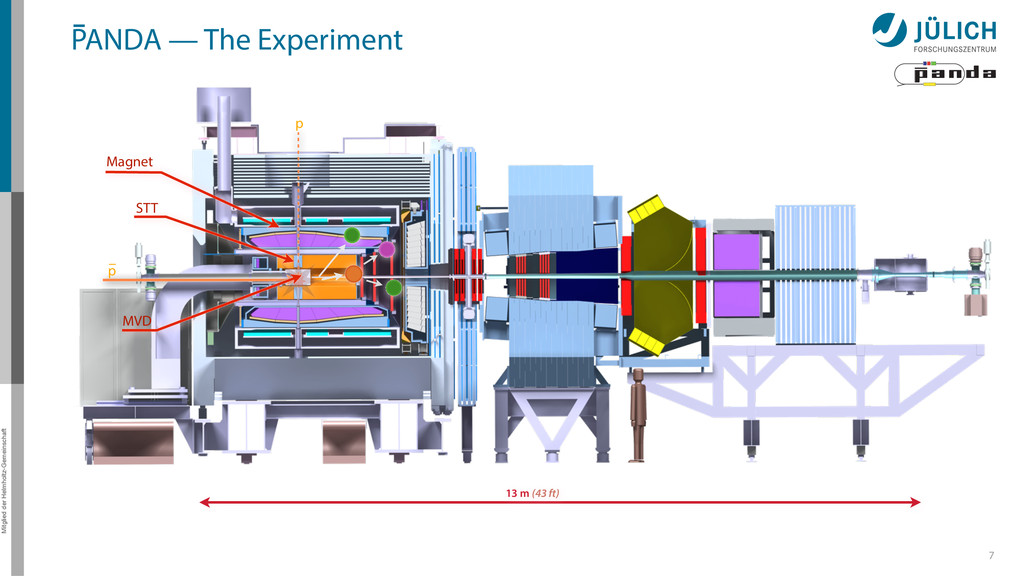
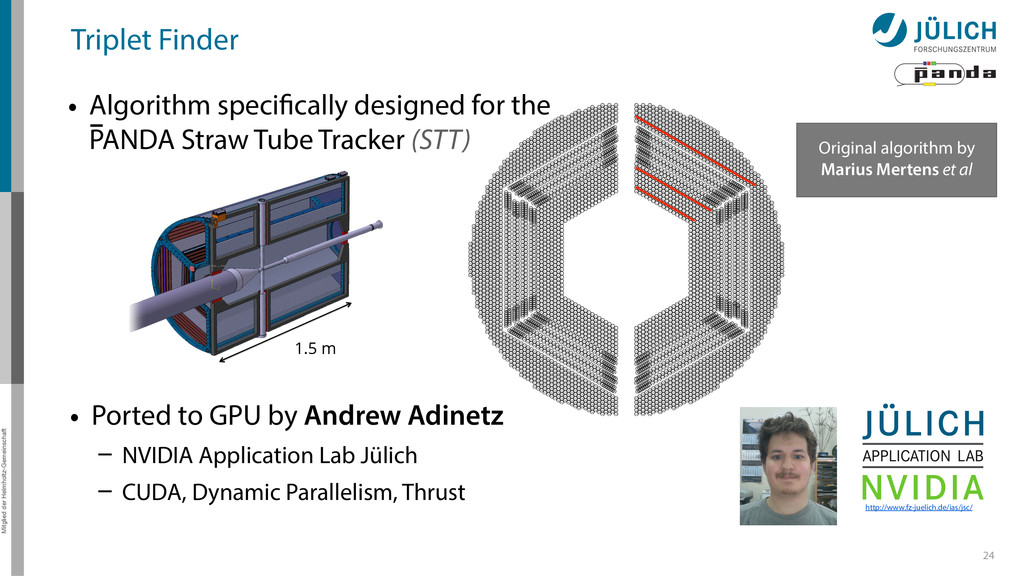
for the PANDA Straw Tube Tracker (STT) http://www.fz-juelich.de/ias/jsc/ Original algorithm by Marius Mertens et al 1.5 m • Ported to GPU by Andrew Adinetz – NVIDIA Application Lab Jülich – CUDA, Dynamic Parallelism, Thrust
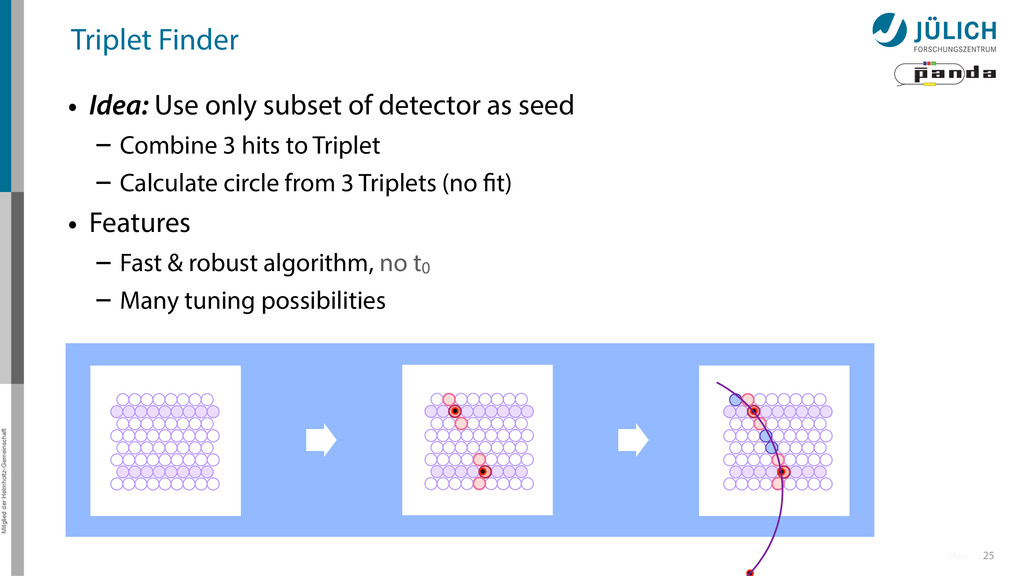
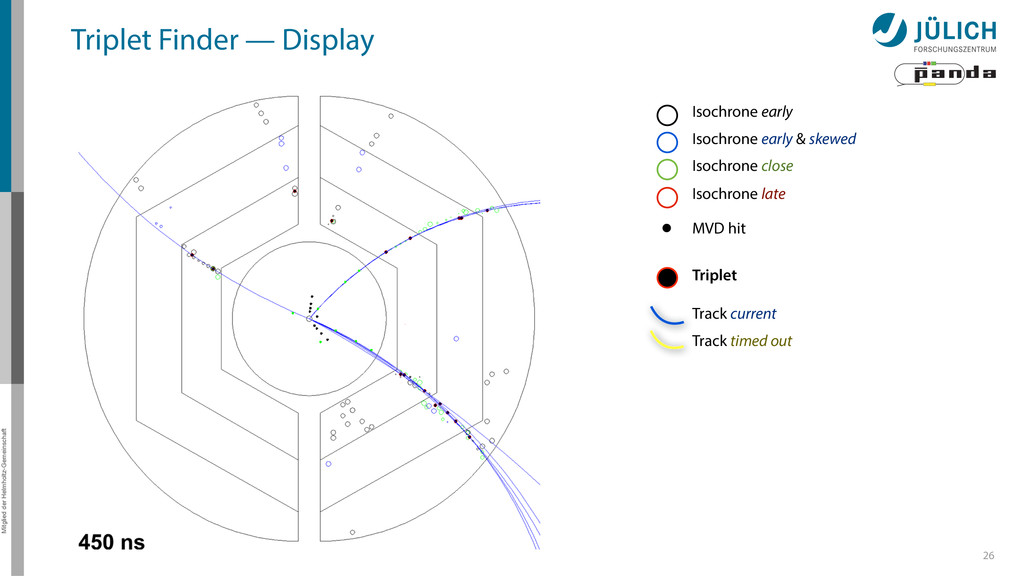
subset of detector as seed – Combine 3 hits to Triplet – Calculate circle from 3 Triplets (no fit) • Features – Fast & robust algorithm, no t0 – Many tuning possibilities More
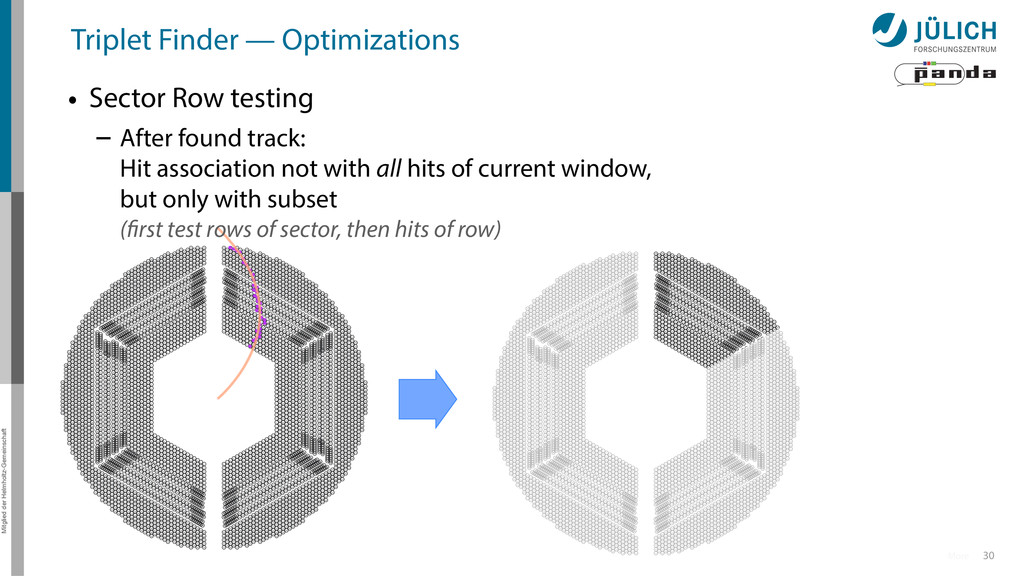
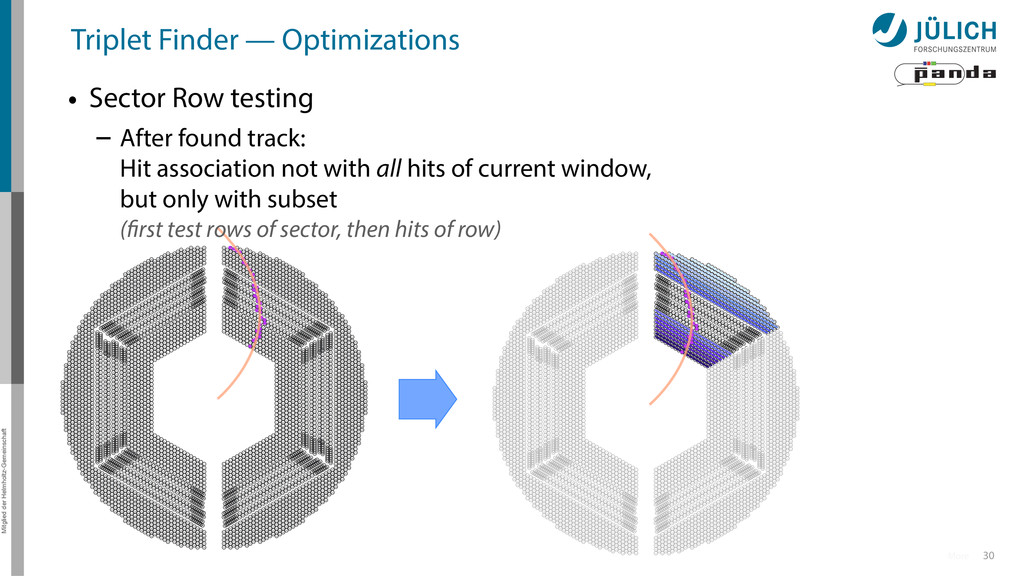
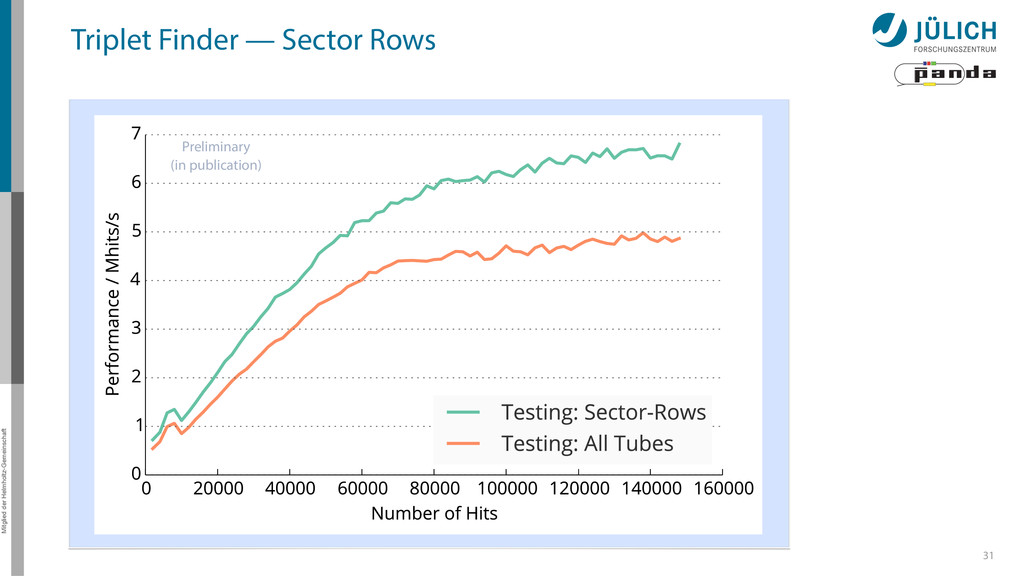
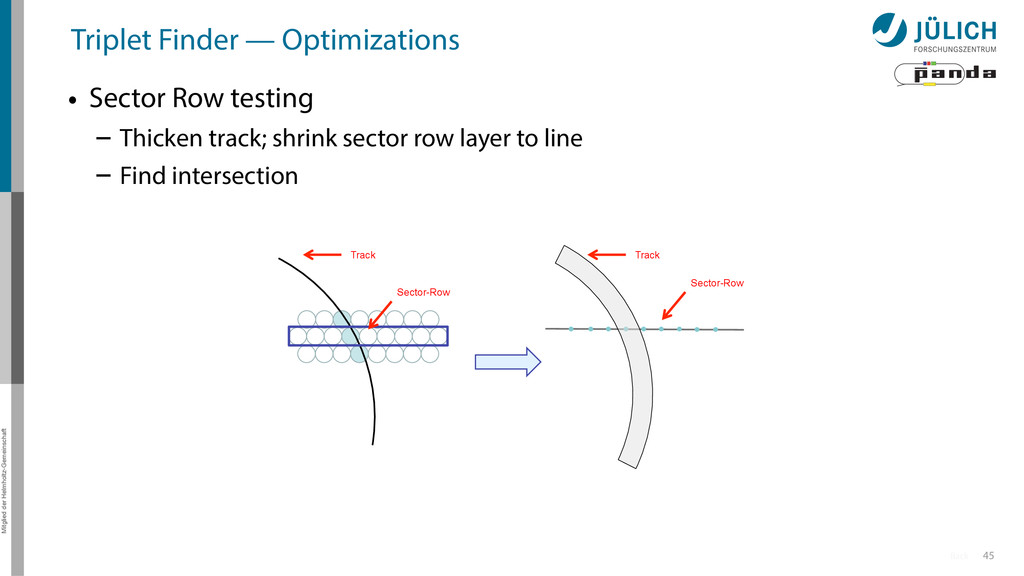
Sector Row testing – After found track: Hit association not with all hits of current window, but only with subset (first test rows of sector, then hits of row)
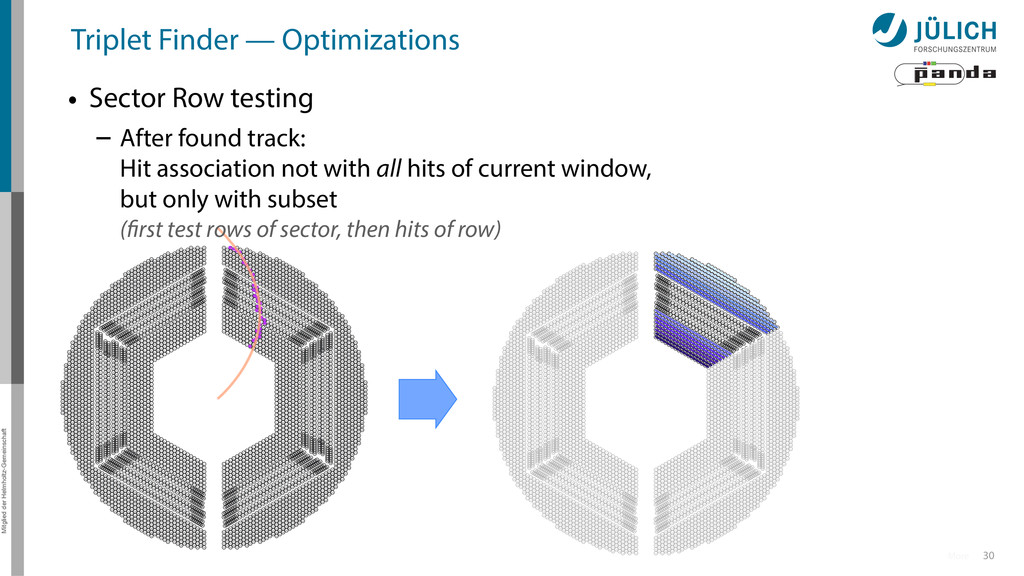
Sector Row testing – After found track: Hit association not with all hits of current window, but only with subset (first test rows of sector, then hits of row)
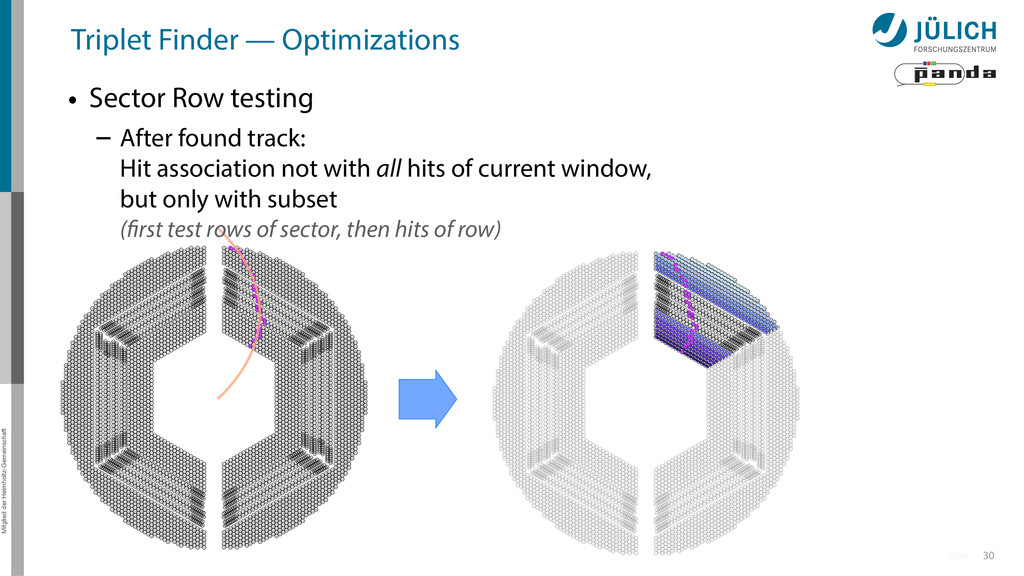
Sector Row testing – After found track: Hit association not with all hits of current window, but only with subset (first test rows of sector, then hits of row)
Sector Row testing – After found track: Hit association not with all hits of current window, but only with subset (first test rows of sector, then hits of row)
Sector Row testing – After found track: Hit association not with all hits of current window, but only with subset (first test rows of sector, then hits of row)
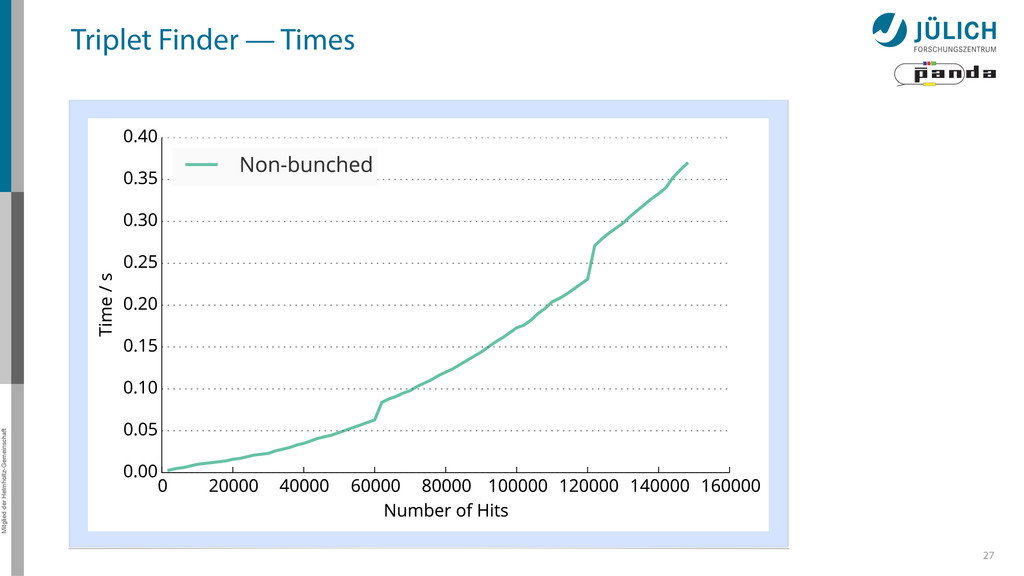
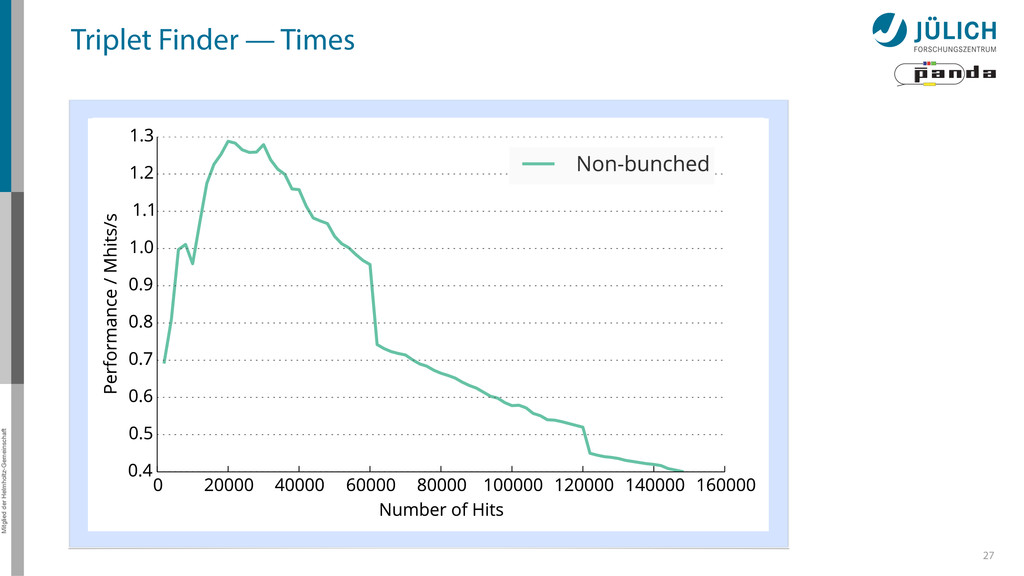
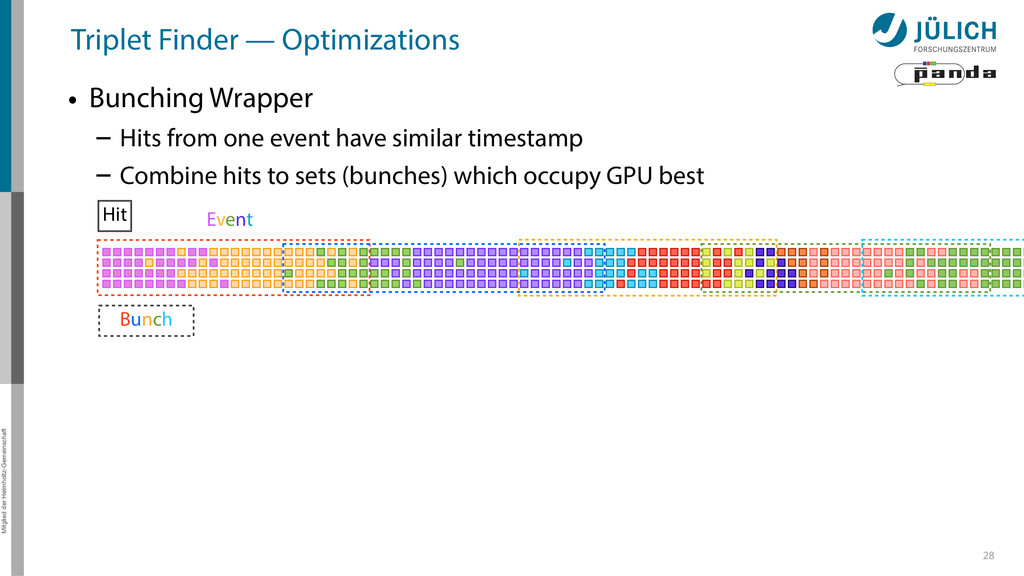
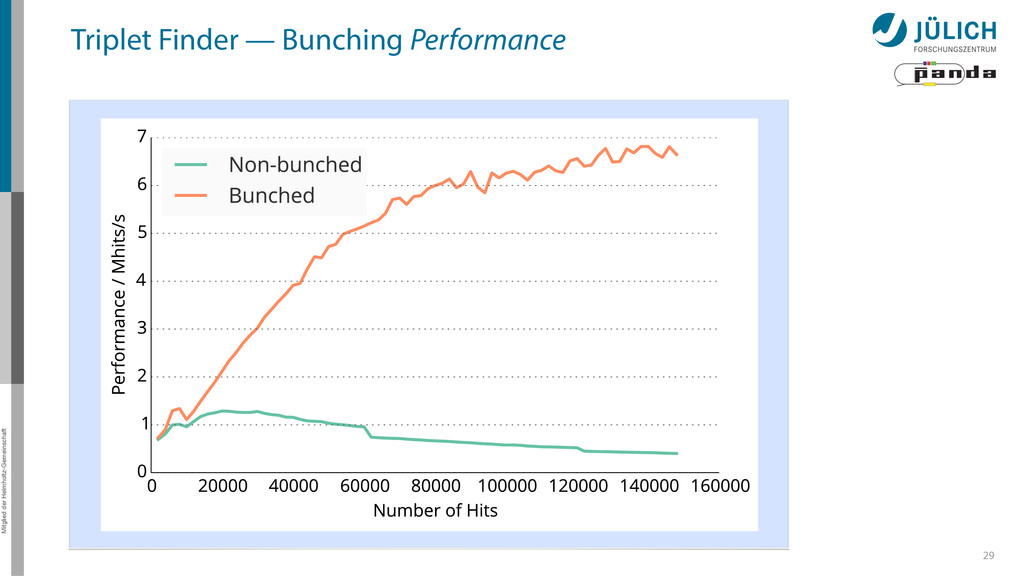
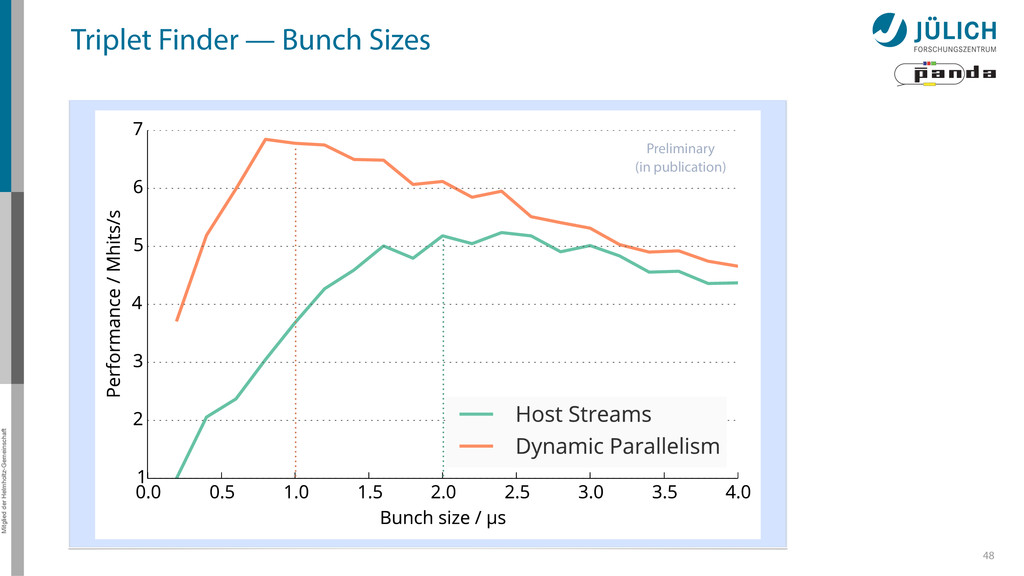
possible – Most important: Bunching wrapper – More float less double-cards à la K10 a viable alternative • Best performance: 20 µs/event → Online Tracking a feasible technique for PANDA – Multi GPU system needed – (100) GPUs 36
HEP • PANDA investigates GPUs as central element in experiment‘s design • Algorithms in active evaluation and optimization • Collaboration with NVIDIA Application Lab 37
Summary • GPUs are very interesting for HEP • PANDA investigates GPUs as central element in experiment‘s design • Algorithms in active evaluation and optimization • Collaboration with NVIDIA Application Lab 37
icon by Francesco Paleari from The Noun Project • #4: Einstein icon by Roman Rusinov from The Noun Project • #6: FAIR vector logo from official FAIR website • #6: FAIR rendering from official website • #11: Flare Gun icon by Jop van der Kroef from The Noun Project • #27: STT event animation by Marius C. Mertens • #35: Graphics cards images by NVIDIA promotion • #35: GPU Specifications – Tesla K20X Specifications: http://www.nvidia.com/content/PDF/kepler/Tesla-K20X-BD-06397-001- v07.pdf – Tesla K40 Specifications: http://www.nvidia.com/content/PDF/kepler/Tesla-K40-Active-Board-Spec- BD-06949-001_v03.pdf – Tesla Familiy Overview: http://www.nvidia.com/content/tesla/pdf/NVIDIA-Tesla-Kepler-Family- Datasheet.pdf 38
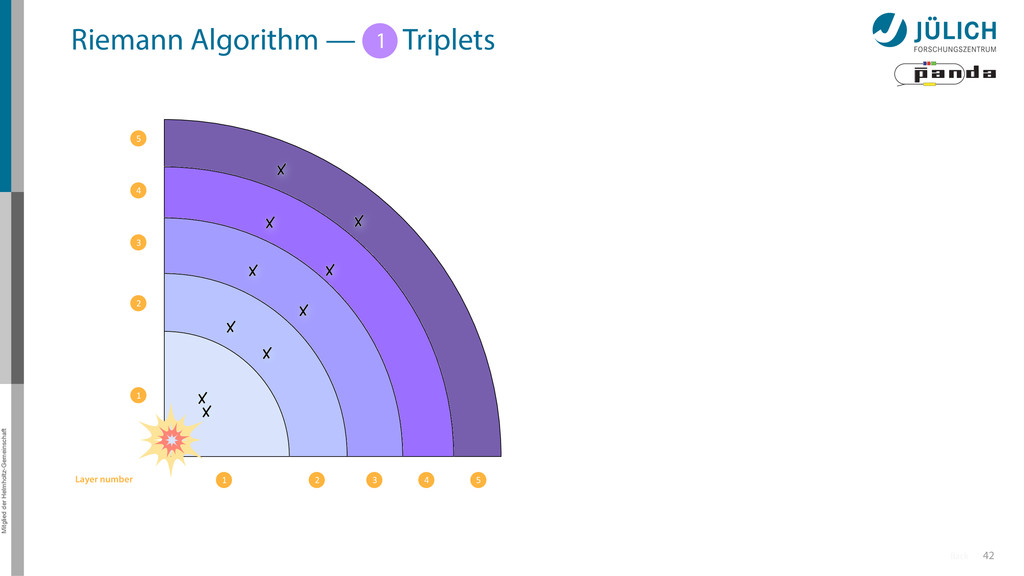
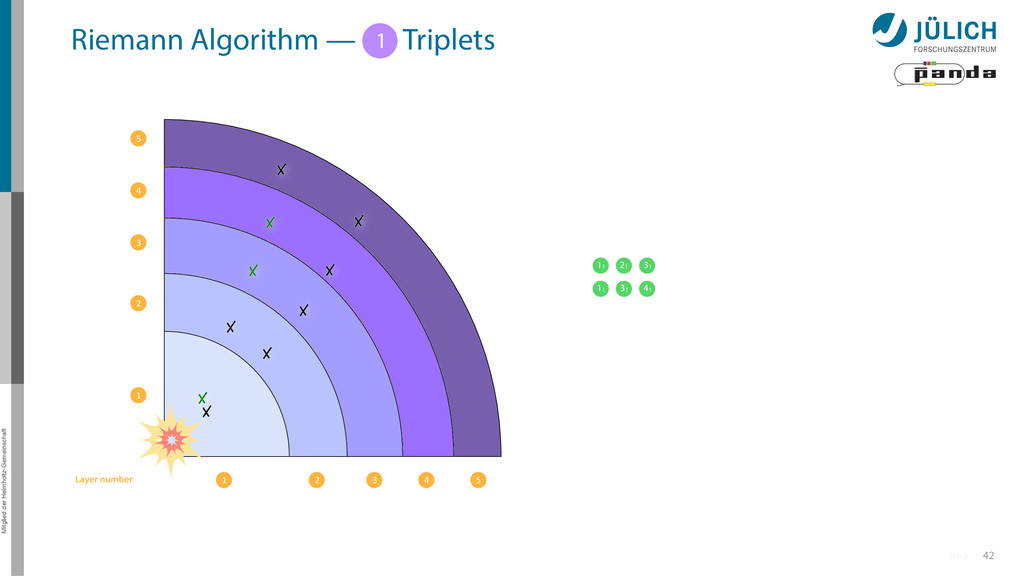
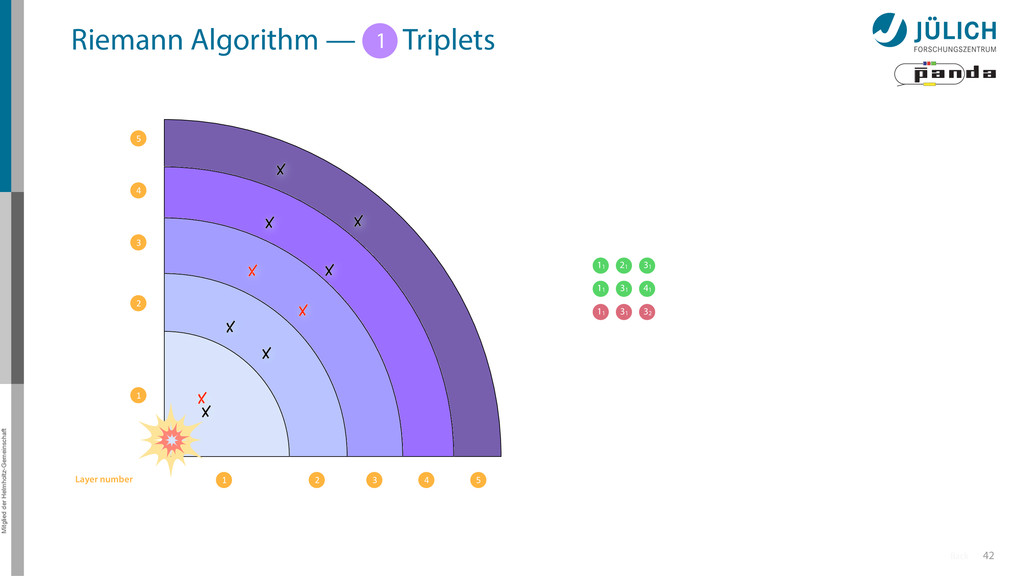
triplet of hit points – All possible three hit combinations need to become triplets • Grow triplets to tracks: Continuously test next hit if it fits to triplet track – Use Riemann paraboloid to circle fit track • Test closeness of new hit: good → add hit; bad → dismiss hit • Continue with next hit – Helix fit: arc length s vs. z position 1 2
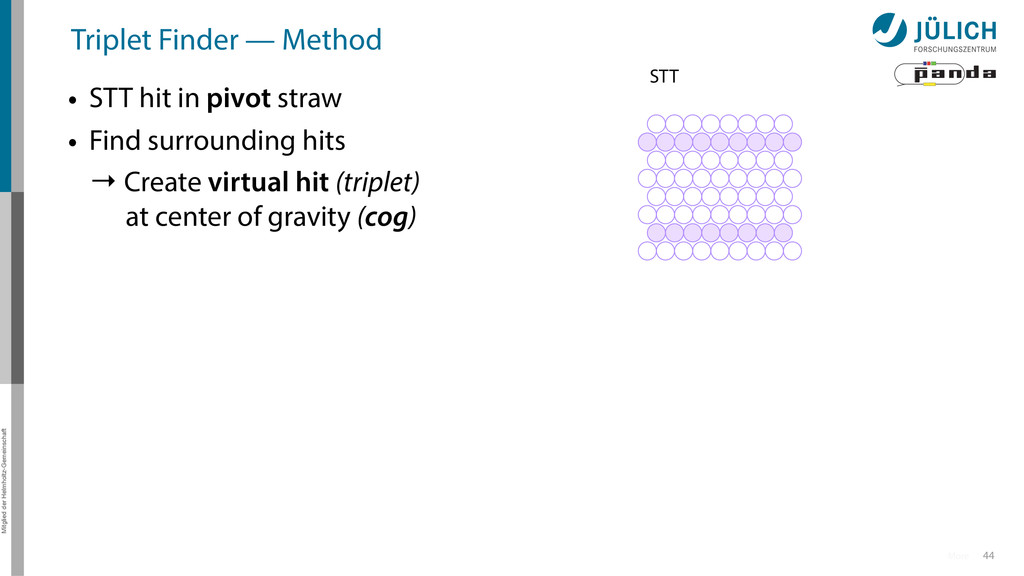
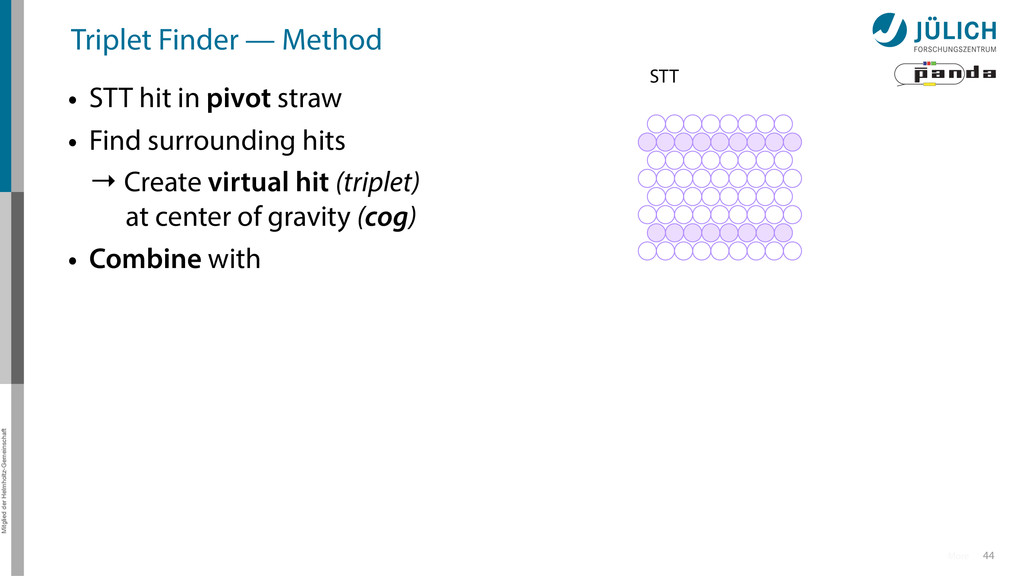
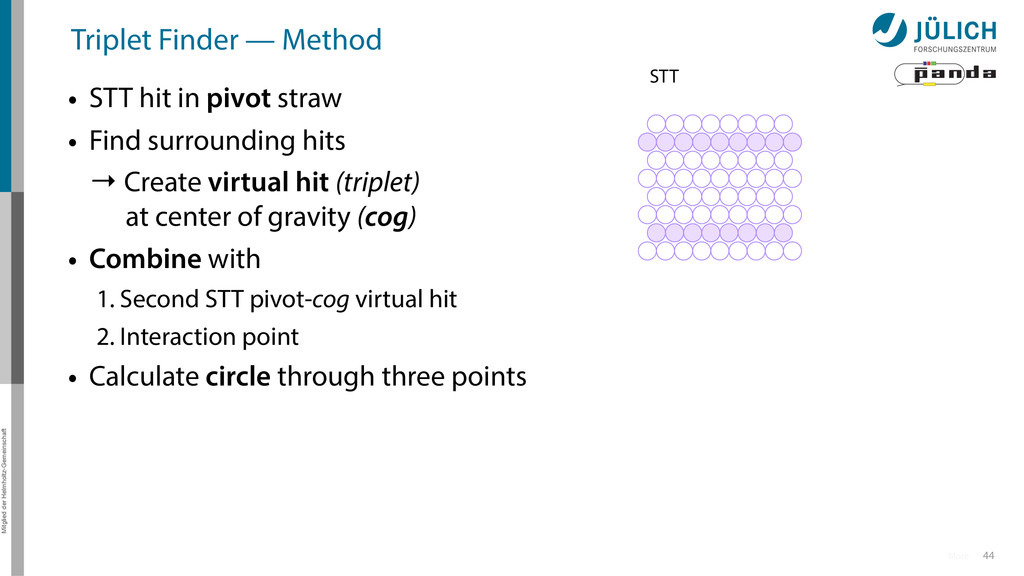
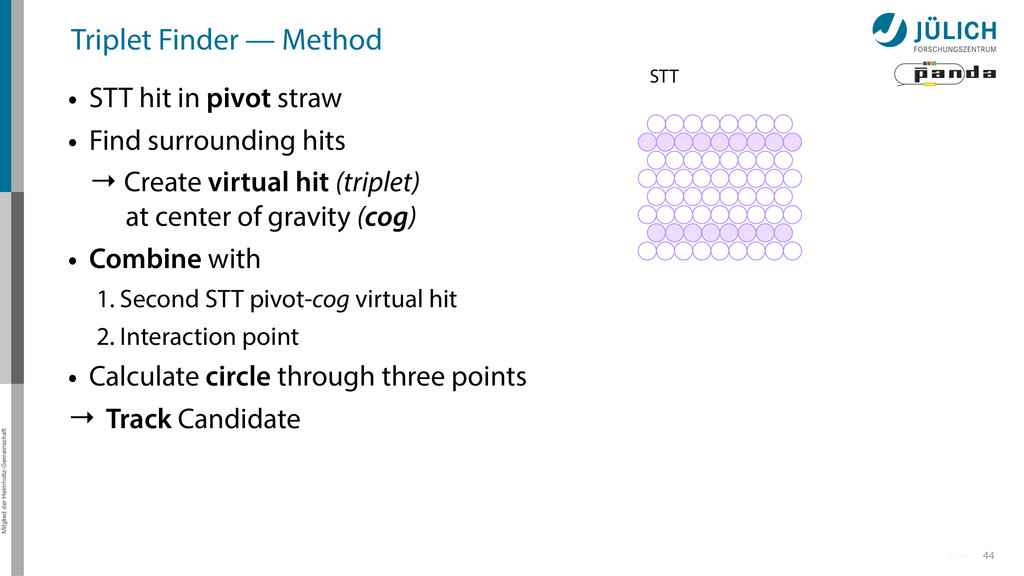
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 44 More STT
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point 44 More STT
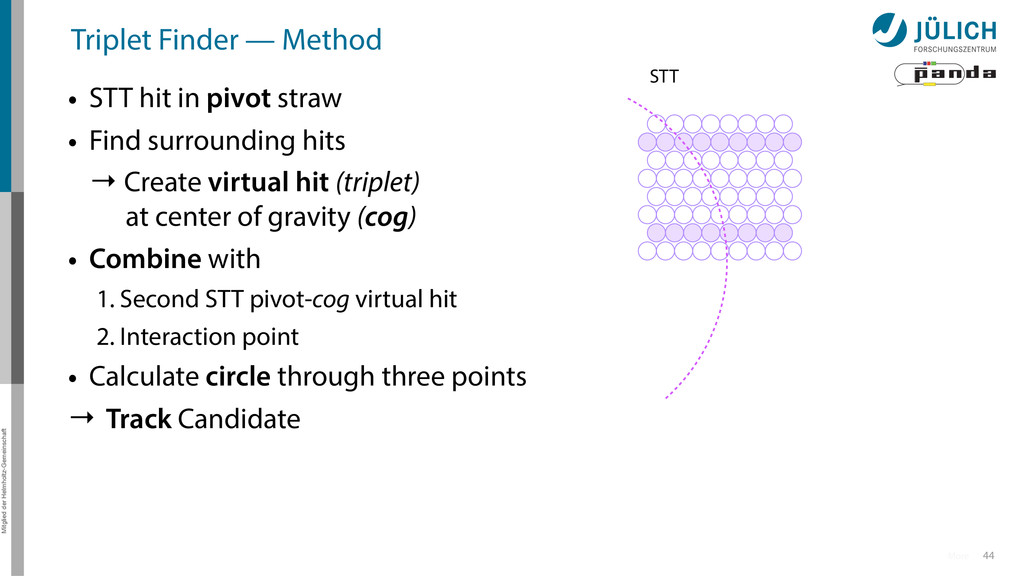
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point • Calculate circle through three points 44 More STT
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point • Calculate circle through three points → Track Candidate 44 More STT
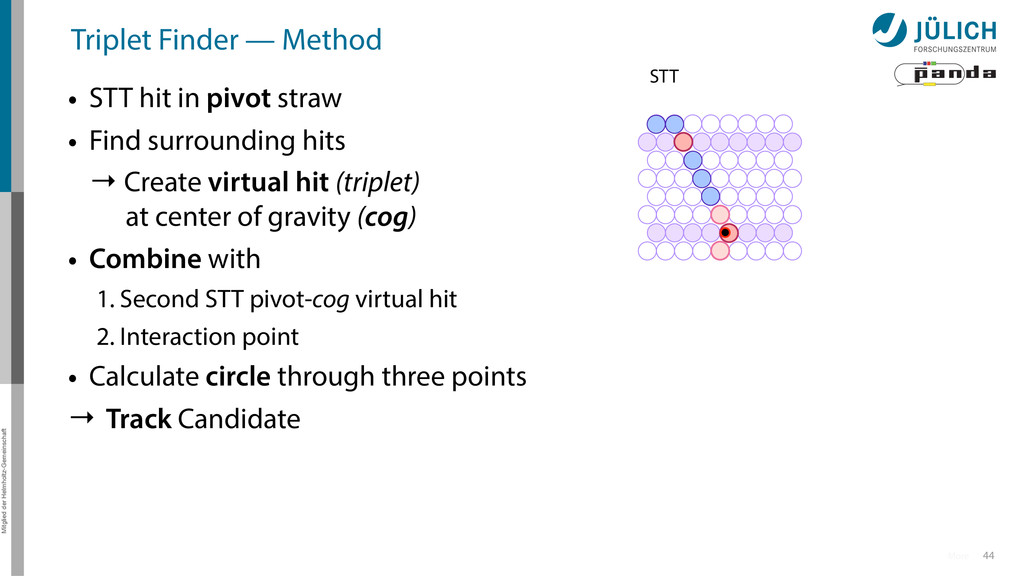
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point • Calculate circle through three points → Track Candidate 44 More STT
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point • Calculate circle through three points → Track Candidate 44 More STT
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point • Calculate circle through three points → Track Candidate 44 More STT
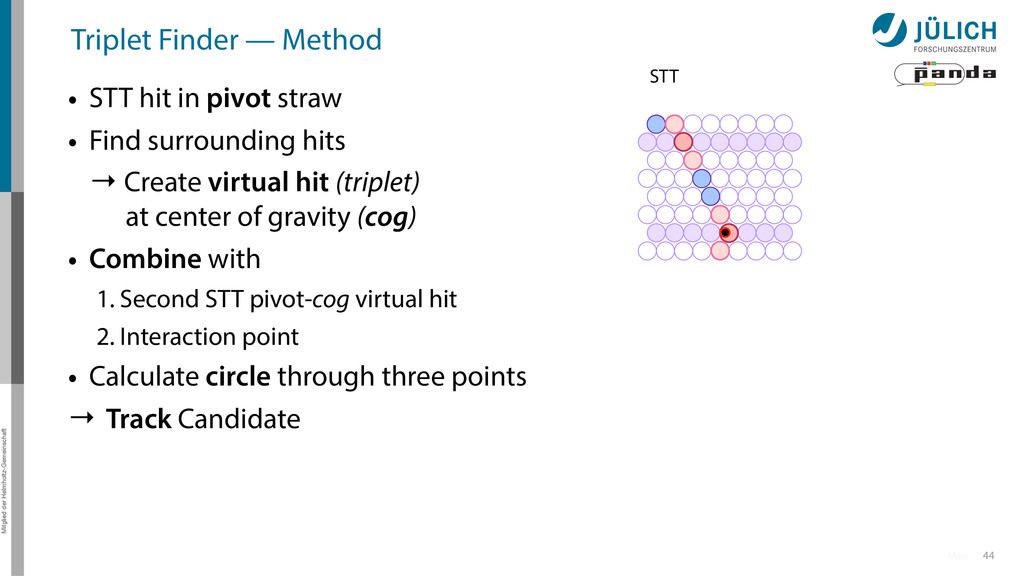
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point • Calculate circle through three points → Track Candidate 44 More STT
in pivot straw • Find surrounding hits → Create virtual hit (triplet) at center of gravity (cog) • Combine with 1. Second STT pivot-cog virtual hit 2. Interaction point • Calculate circle through three points → Track Candidate 44 More Interaction Point STT
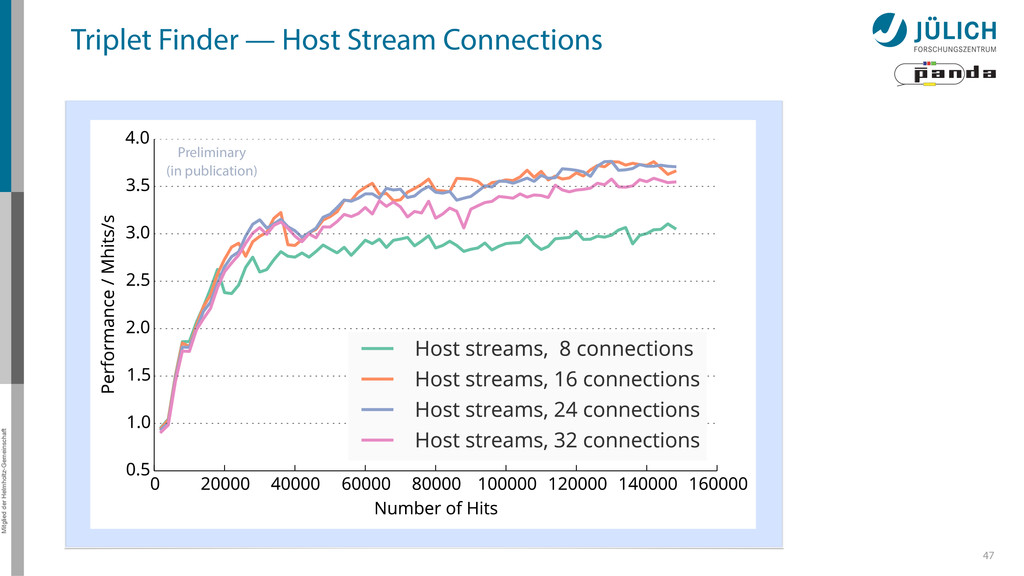
Joined Kernel (JK): slowest – High # registers → low occupancy • Dynamic Parallelism (DP) / Host Streams (HS): comparable performance – Performance • HS faster for small # processed hits, DP faster for > 45000 hits • HS stagnates there, while DP continues rising – Limiting factor • High # of required kernel calls • Kernel launch latency • Memcopy – HS more affected by this, because • More PCI-E transfers (launch configurations for kernels) • Less launch throughput, kernel launch latency gets more important • False dependencies of launched kernels – Single CPU thread handles all CUDA streams (Multi-thread possible, but synchronization overhead too high for good performance) – Grid scheduling done on hardware (Grid Management Unit) (DP: software) » False dependencies when N(streams) > N(device connections)=323.5 46 Back Back
& Me • Research Center – *1956; Federal center Budget: 730 Mio. USD/year – 5300 employees • Thereof 1700 scientists (600 PhD students) – Topics: Health, Energy, Environment Physics; Supercomputing Many large-scale facilities • Me – Diploma in physics from RWTH Aachen University (CMS experiment) – PhD researcher since 2011: GPU Online Tracking for PANDA
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thank you! Andreas Herten [email protected] @AndiH #GTC14 Mitglied der Helmholtz-Gemeinschaft](https://files.speakerdeck.com/presentations/e1e78980adb6013183623ab2b4f1ac72/slide_94.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}