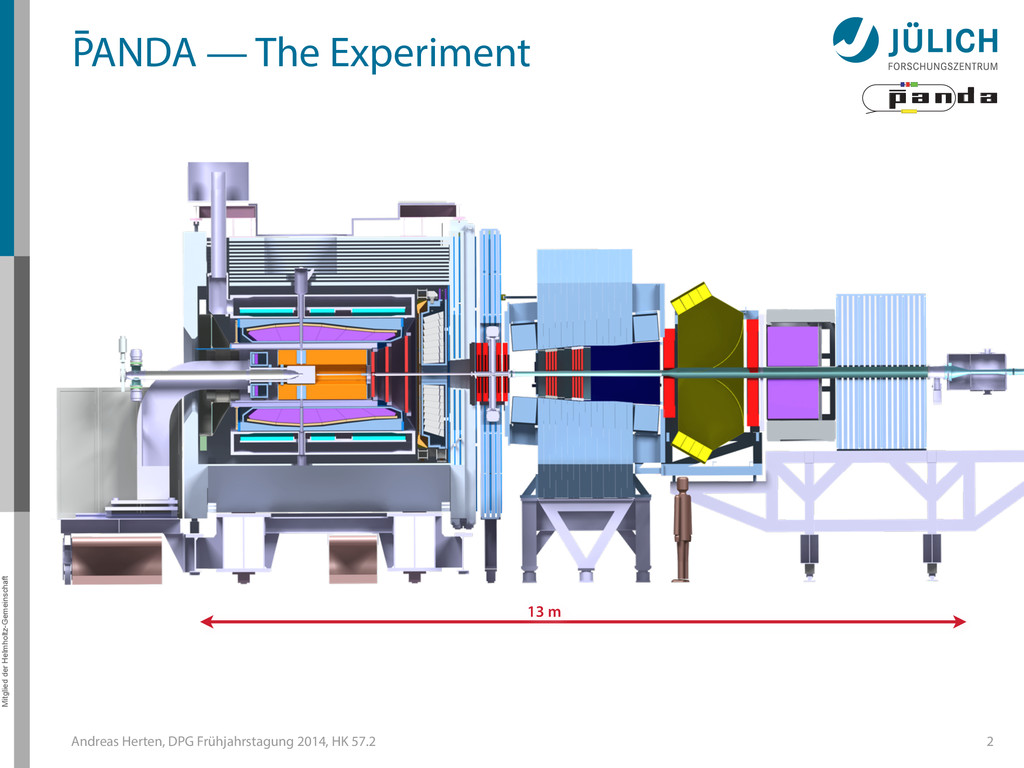
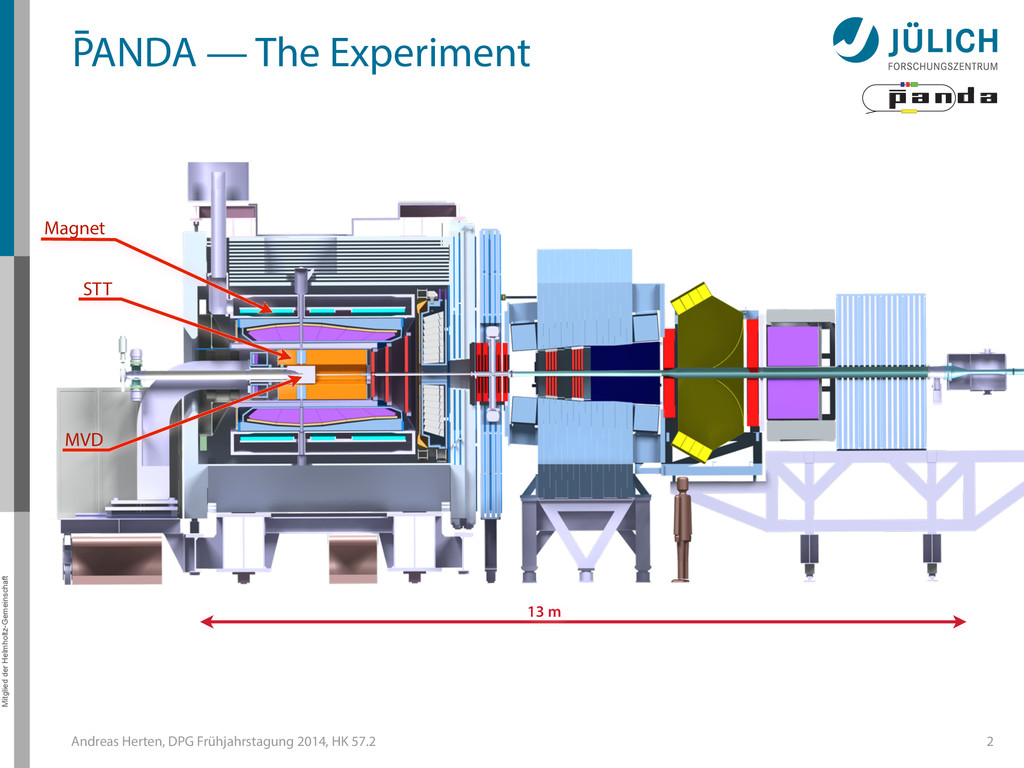
at PANDA 1 HK 57.2, DPG-Frühjahrstagung 2014, Frankfurt 21 March 2014, Andreas Herten (Institut für Kernphysik, Forschungszentrum Jülich) for the PANDA Collaboration
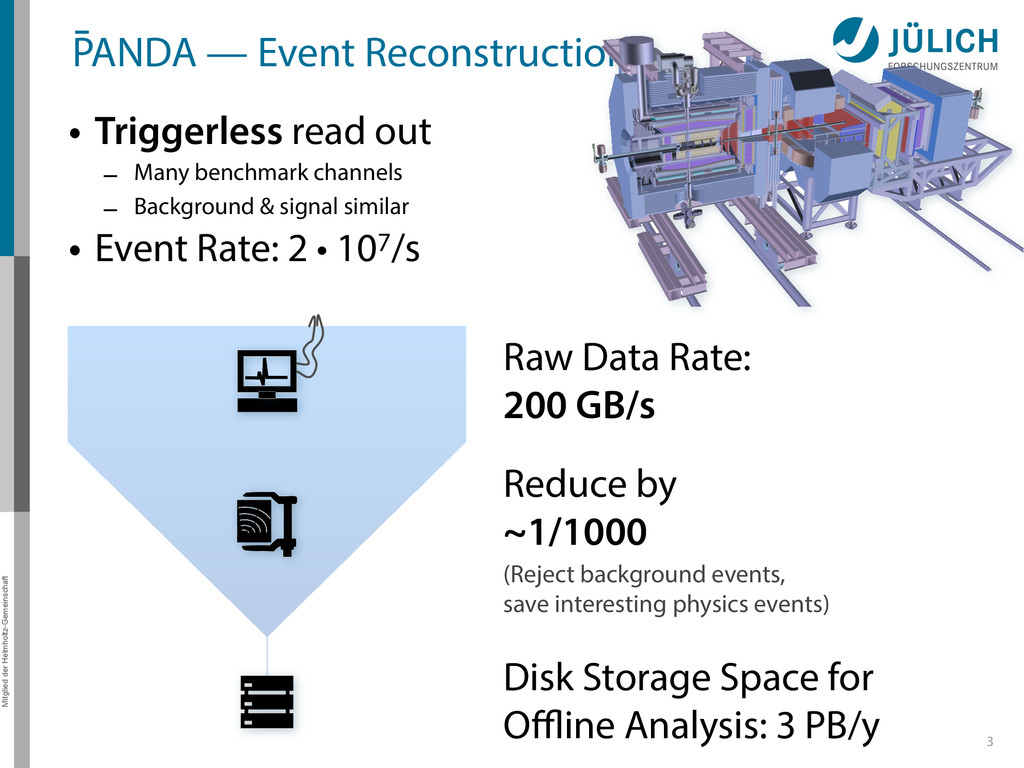
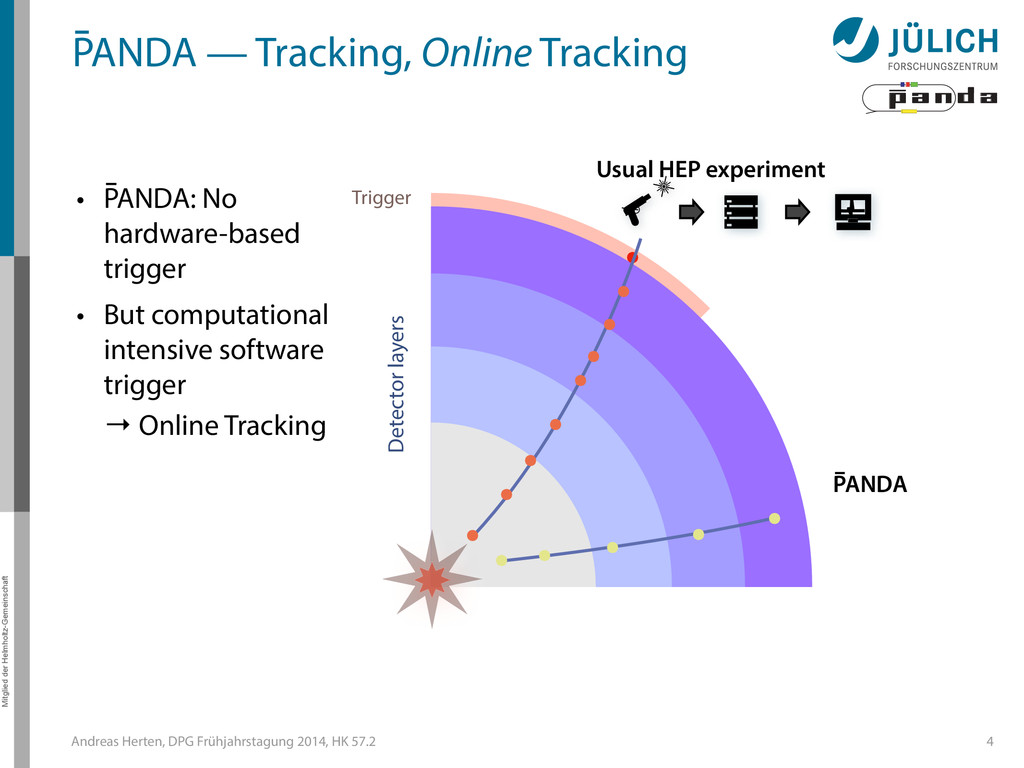
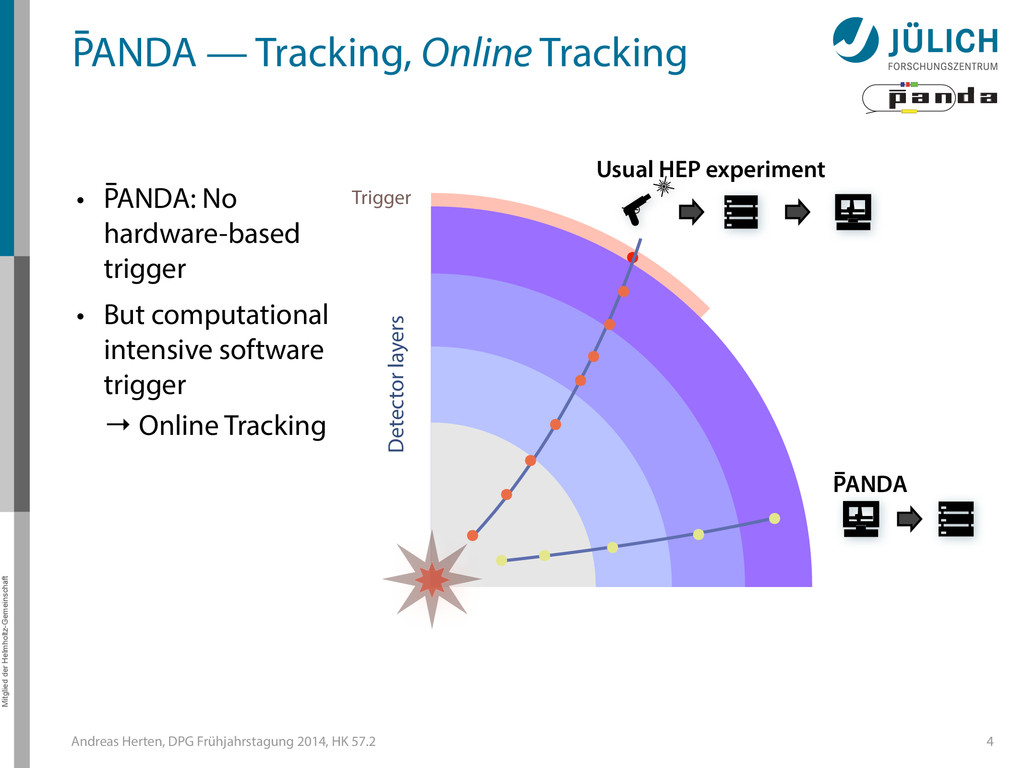
out – Many benchmark channels – Background & signal similar • Event Rate: 2 • 107/s 3 Raw Data Rate: 200 GB/s Disk Storage Space for Offline Analysis: 3 PB/y Reduce by ~1/1000 (Reject background events, save interesting physics events)
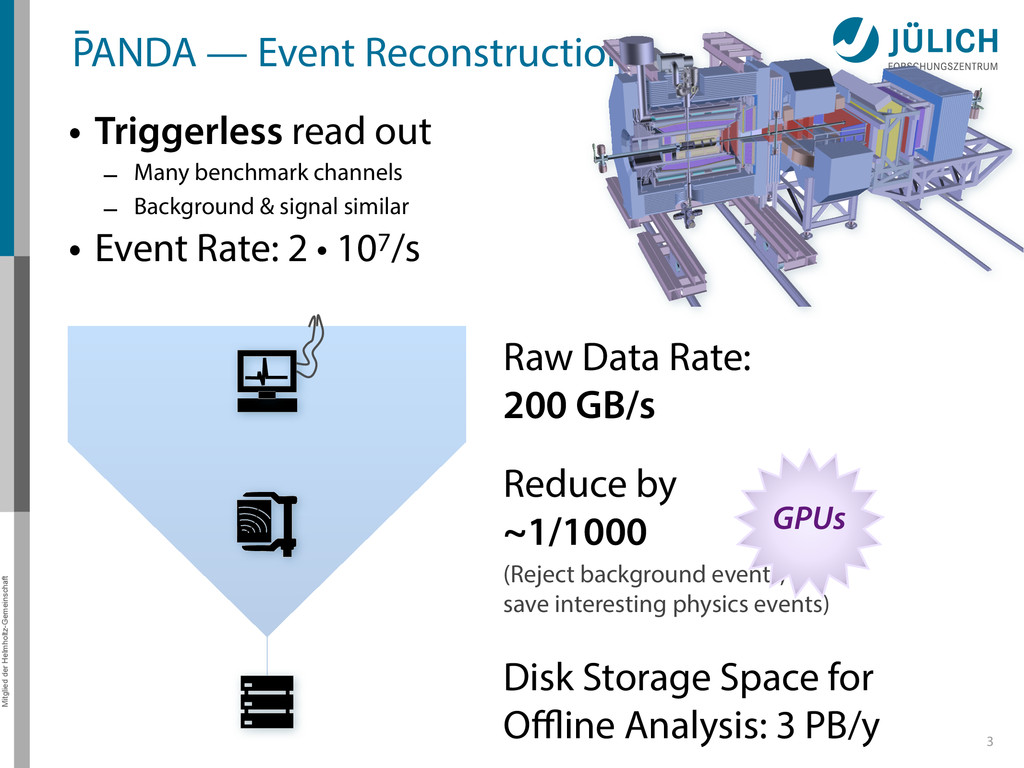
out – Many benchmark channels – Background & signal similar • Event Rate: 2 • 107/s 3 Raw Data Rate: 200 GB/s Disk Storage Space for Offline Analysis: 3 PB/y Reduce by ~1/1000 (Reject background events, save interesting physics events) GPUs
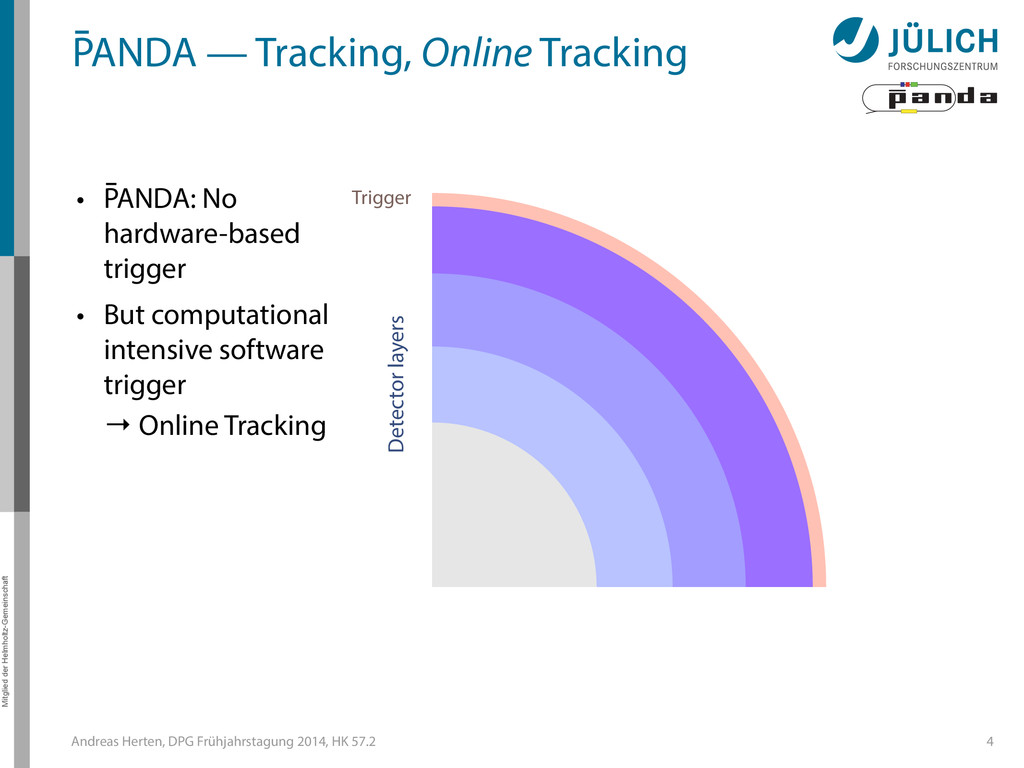
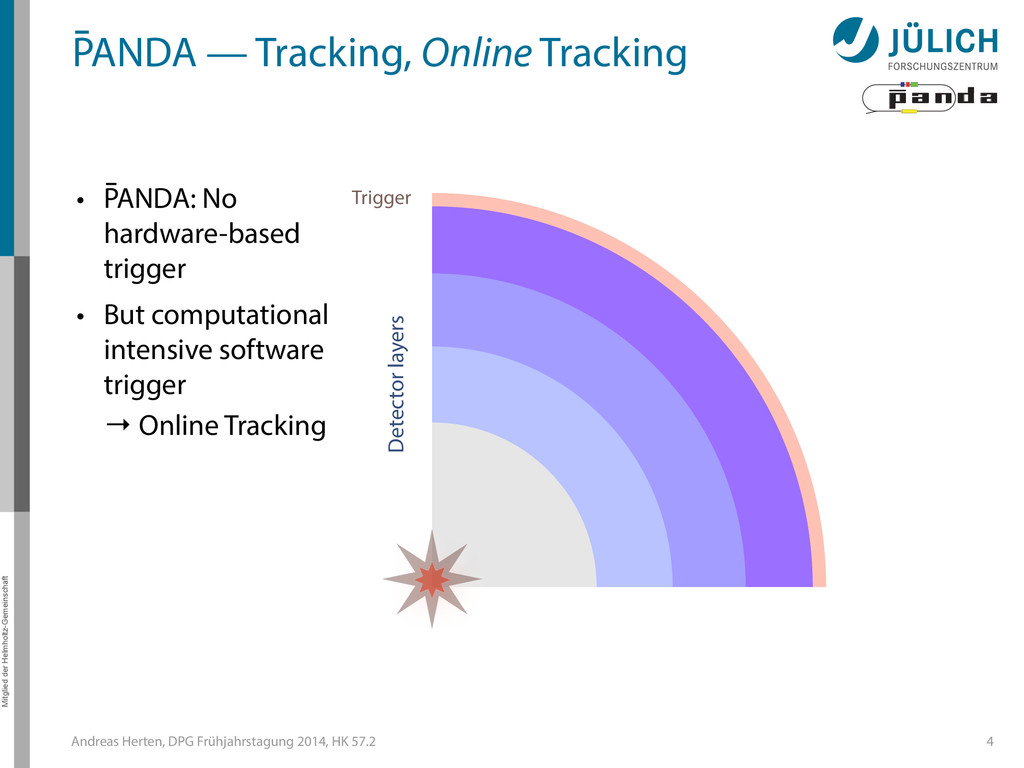
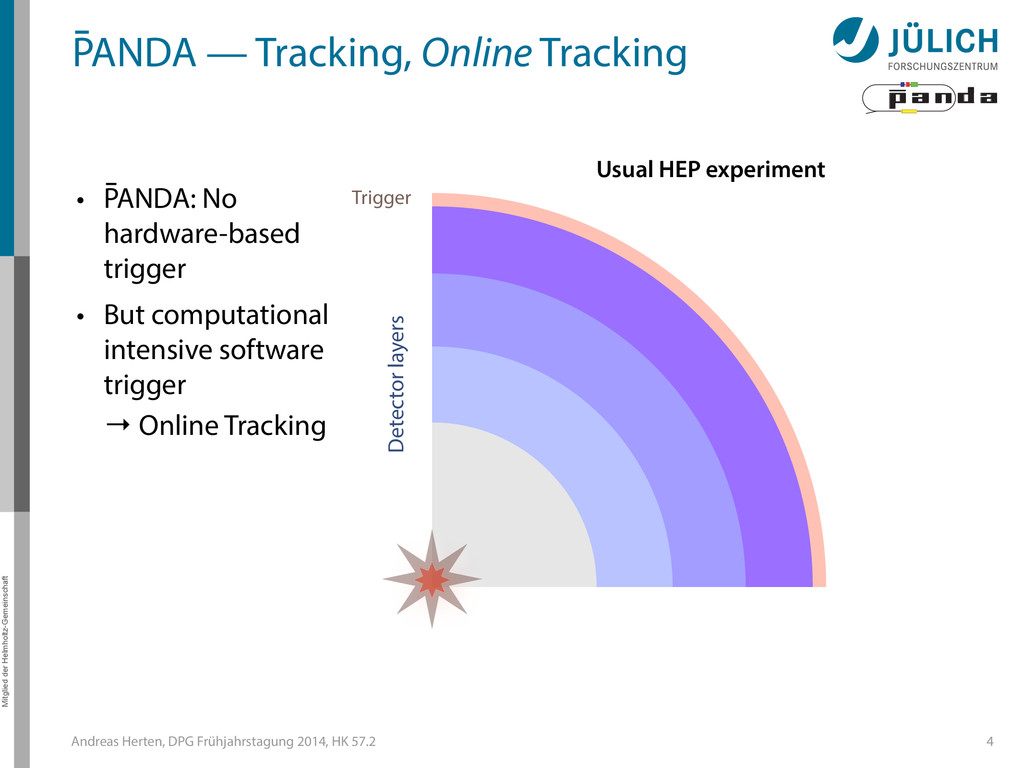
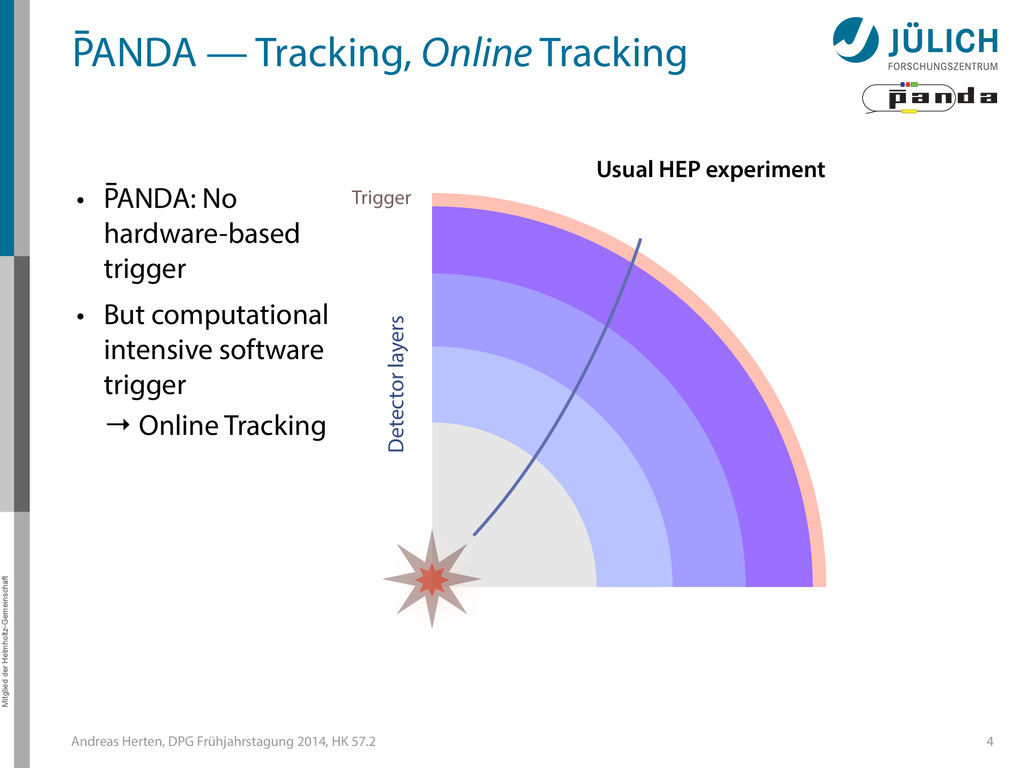
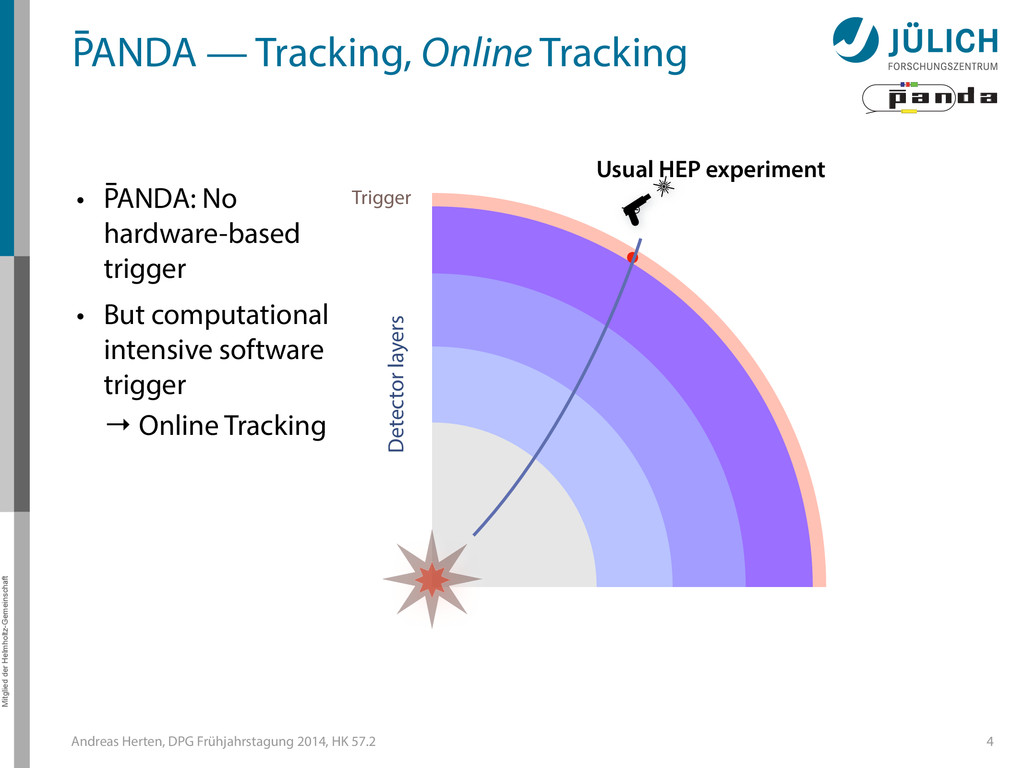
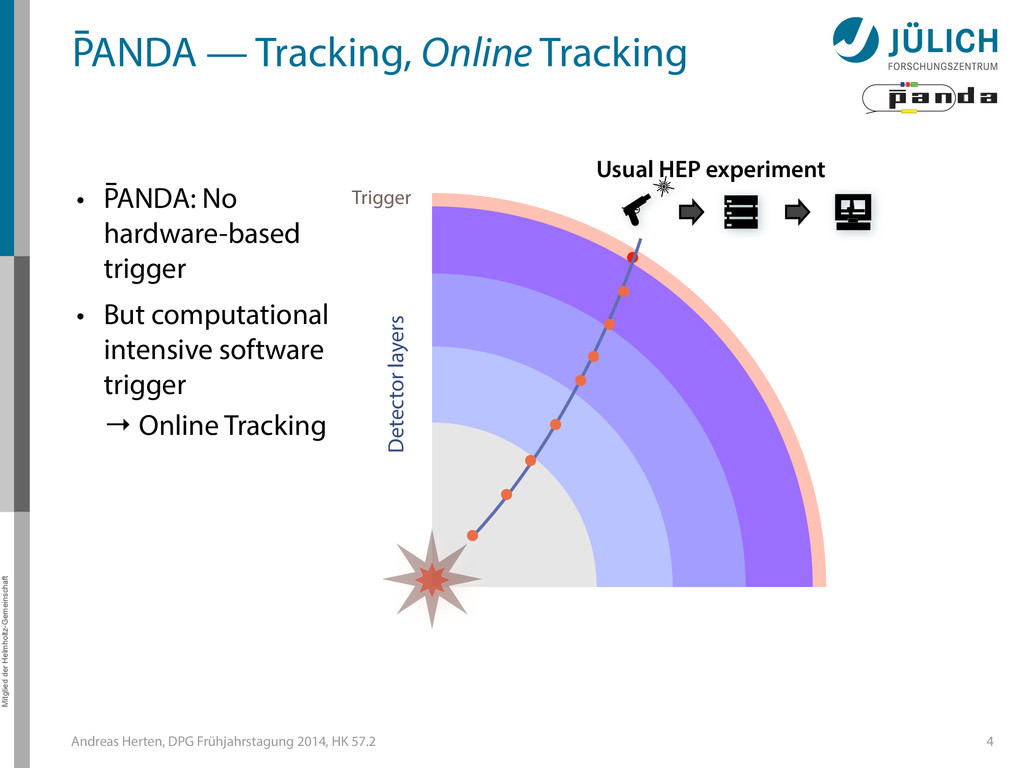
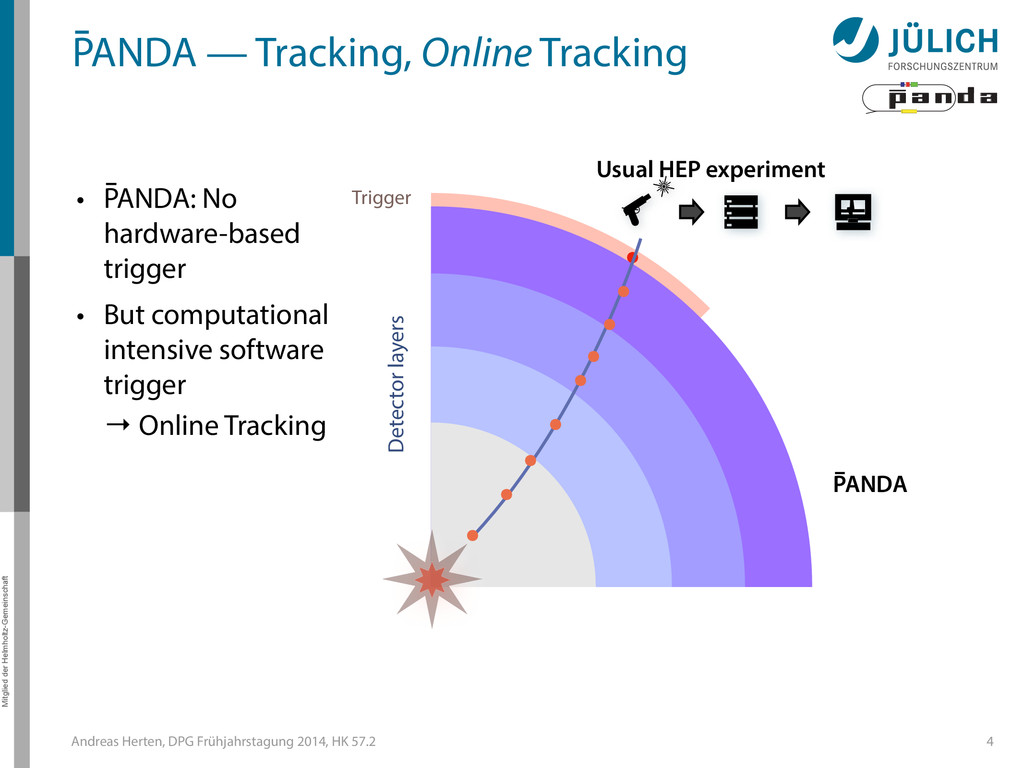
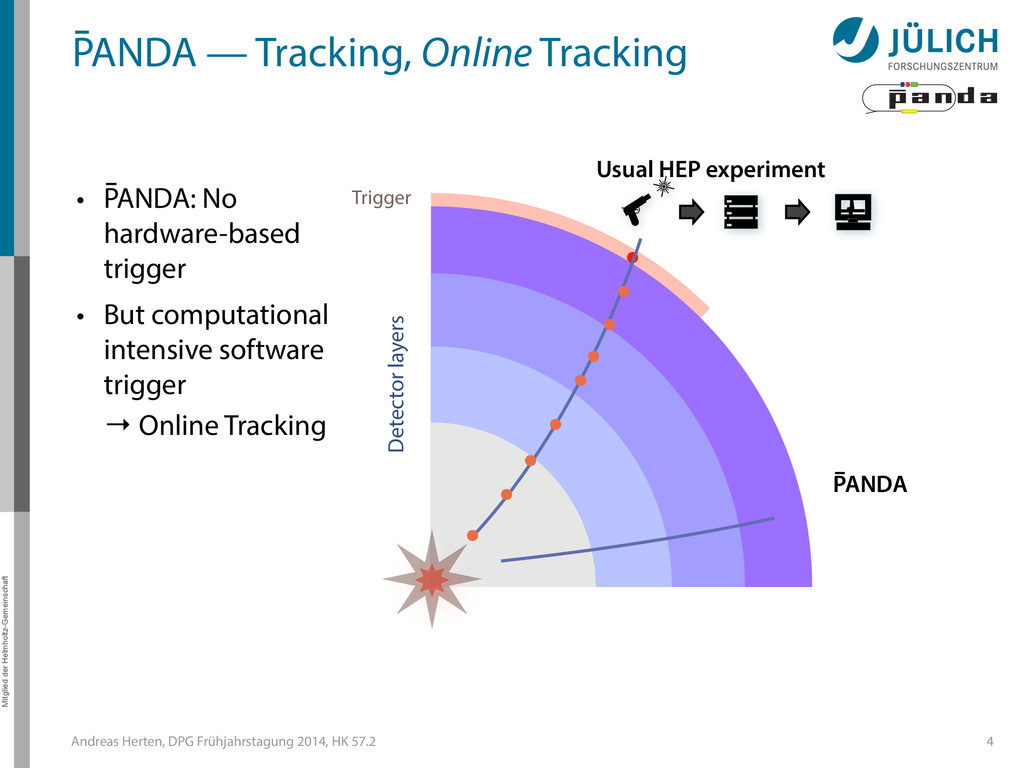
GPUs @ PANDA — Online Tracking • Port tracking algorithms to GPU – Serial → parallel – C++ → CUDA • Investigate suitability for online performance • But also: Find & invent tracking algorithms… • Under investigation: – Hough Transformation – Riemann Track Finder – Triplet Finder 5
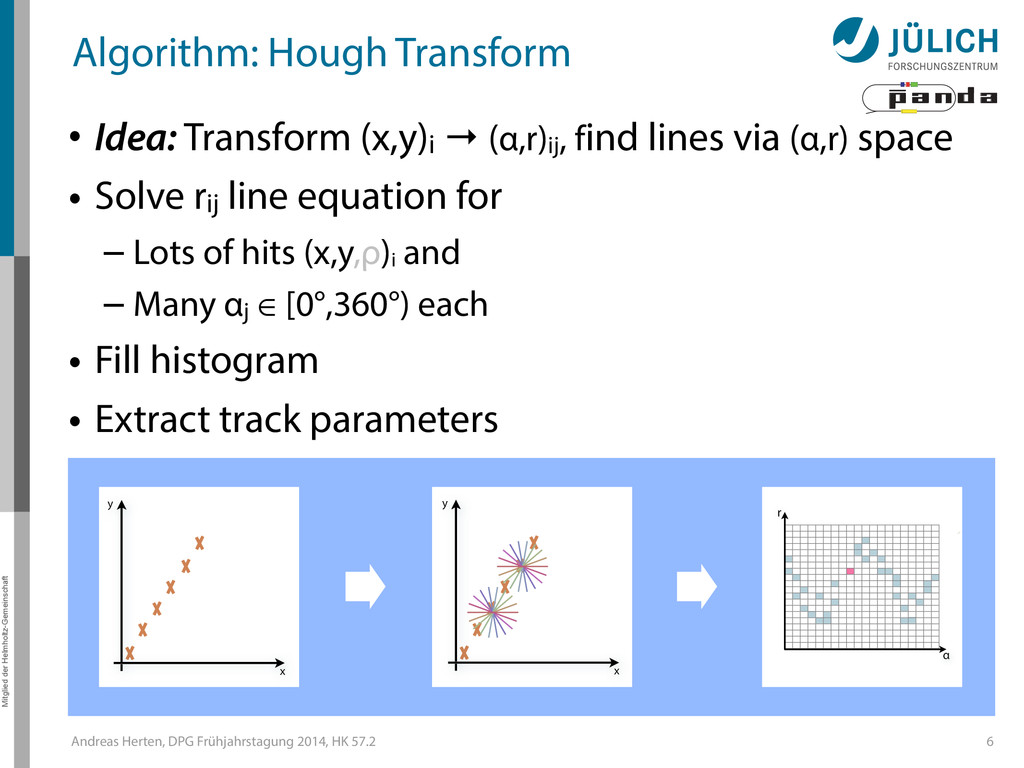
Algorithm: Hough Transform • Idea: Transform (x,y)i → (α,r)ij, find lines via (α,r) space • Solve rij line equation for – Lots of hits (x,y,ρ)i and – Many αj ∈ [0°,360°) each • Fill histogram • Extract track parameters 6 x y x y Mitglied der Helmholtz-Gemeinschaft Hough Transform — Princip → Bin giv r α
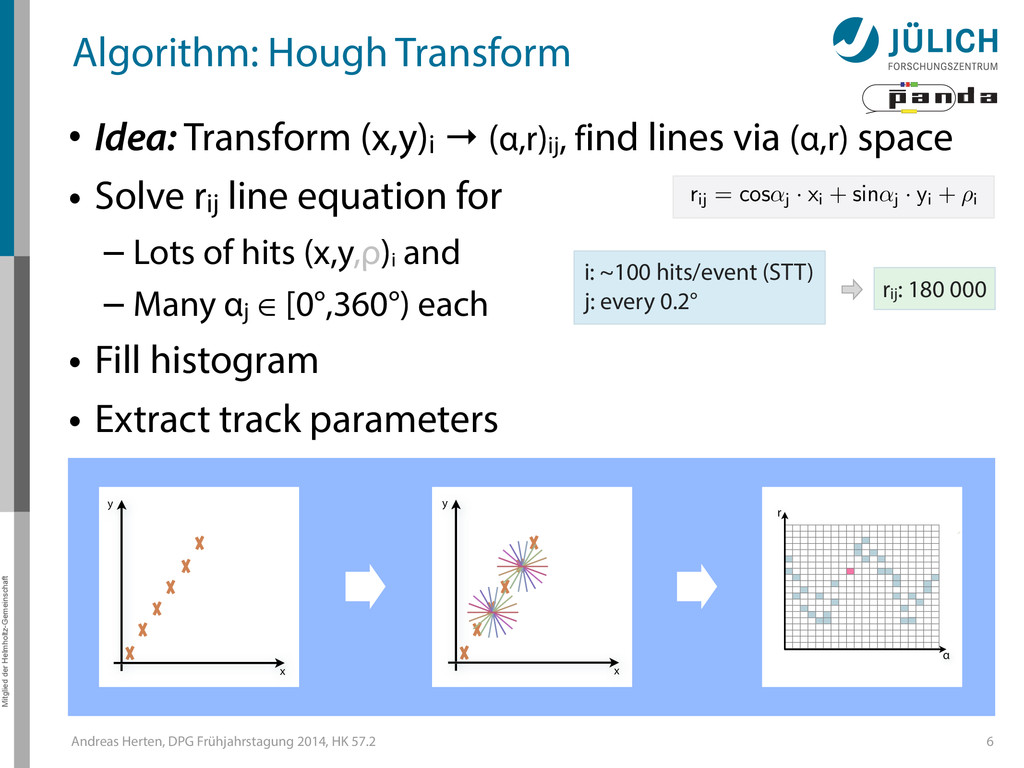
Algorithm: Hough Transform • Idea: Transform (x,y)i → (α,r)ij, find lines via (α,r) space • Solve rij line equation for – Lots of hits (x,y,ρ)i and – Many αj ∈ [0°,360°) each • Fill histogram • Extract track parameters 6 rij = cos ↵j · xi + sin ↵j · yi + ⇢i i: ~100 hits/event (STT) j: every 0.2° rij: 180 000 x y x y Mitglied der Helmholtz-Gemeinschaft Hough Transform — Princip → Bin giv r α
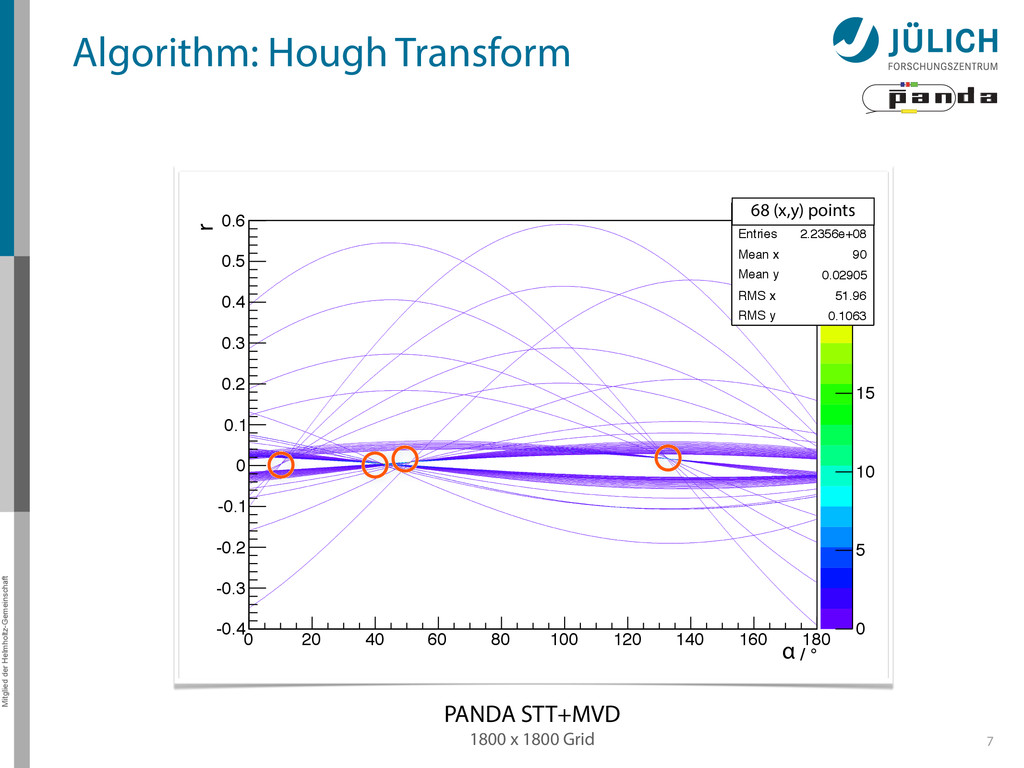
140 160 180 Hough transformed -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 0 5 10 15 20 25 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 1800 x 1800 Grid PANDA STT+MVD Mitglied der Helmholtz-Gemeinschaft 7 68 (x,y) points r α Algorithm: Hough Transform
140 160 180 Hough transformed -0.4 -0.3 -0.2 -0.1 0 0.1 0.2 0.3 0.4 0.5 0.6 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 0 5 10 15 20 25 0 Entries 2.2356e+08 Mean x 90 Mean y 0.02905 RMS x 51.96 RMS y 0.1063 1800 x 1800 Grid PANDA STT+MVD Mitglied der Helmholtz-Gemeinschaft 7 68 (x,y) points r α Algorithm: Hough Transform
Algorithm: Hough Transform 8 Thrust Plain CUDA • Performance: 3 ms/event – Independent of α granularity – Reduced to set of standard routines • Fast (uses Thrust‘s optimized algorithms) • Inflexible (has it‘s limits, hard to customize) – No peakfinding included • Even possible? • Adds to time! • Performance: 0.5 ms/event – Built completely for this task • Fitting to every problem • Customizable • A bit more complicated at parts – Simple peakfinder implemented (threshold) • Using: Dynamic Parallelism, Shared Memory Two Implementations
9 • Idea: Don‘t fit lines (in 2D), fit planes (in 3D)! • Create seeds – All possible three hit combinations • Grow seeds to tracks Continuously test next hit if it fits – Use mapping to Riemann paraboloid • Summer student project (J. Timcheck) x x x x y z‘ x x x y x x x x y x Algorithm: Riemann Track Finder
pos ( nLayerx ) = 3 pp 3 p 243x2 1 + 27x 32 / 3 + 1 3 p 3 3 pp 3 p 243x2 1 + 27x 1 Mitglied der Helmholtz-Gemeinschaft 10 Algorithm: Riemann Track Finder int ijk = threadIdx.x + blockIdx.x * blockDim.x; for () {for () {for () {}}} • GPU Optimization: Unfolding loops → 100 × faster than CPU version • Time for one event (Tesla K20X): ~0.6 ms
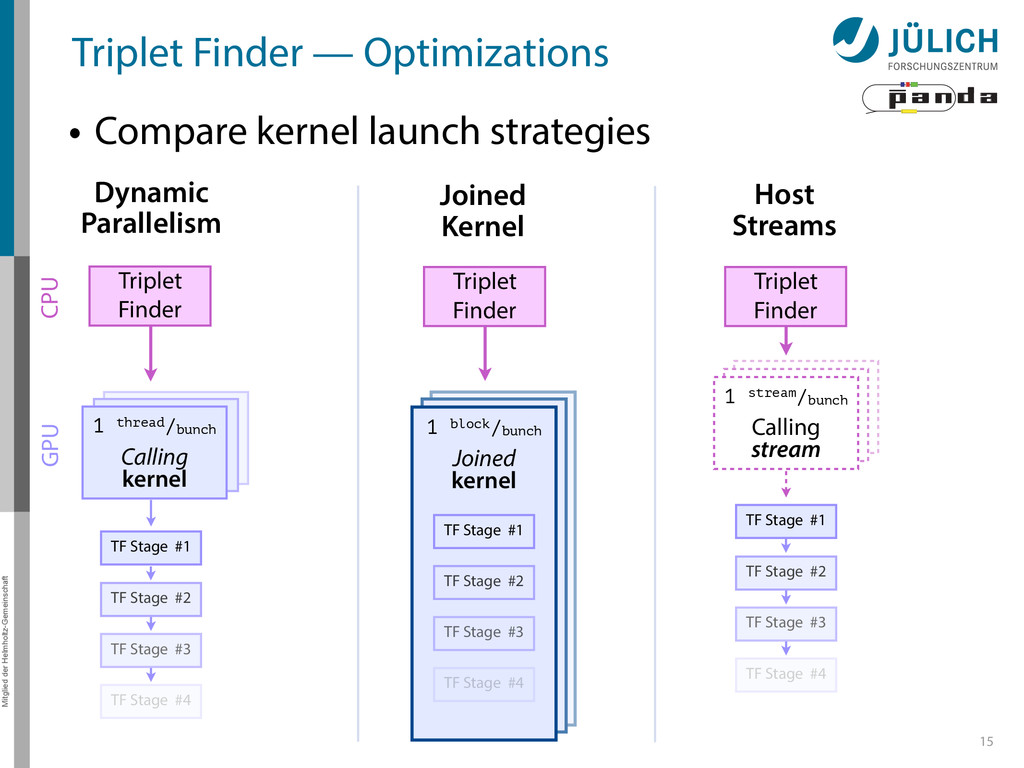
11 Algorithm: Triplet Finder • Idea: Use only sub-set of detector as seed – Combine 3 hits to Triplet – Calculate circle from 3 Triplets (no fit) • Features – Tailored for PANDA – Fast & robust algorithm, no t0 • Ported to GPU together with NVIDIA Application Lab
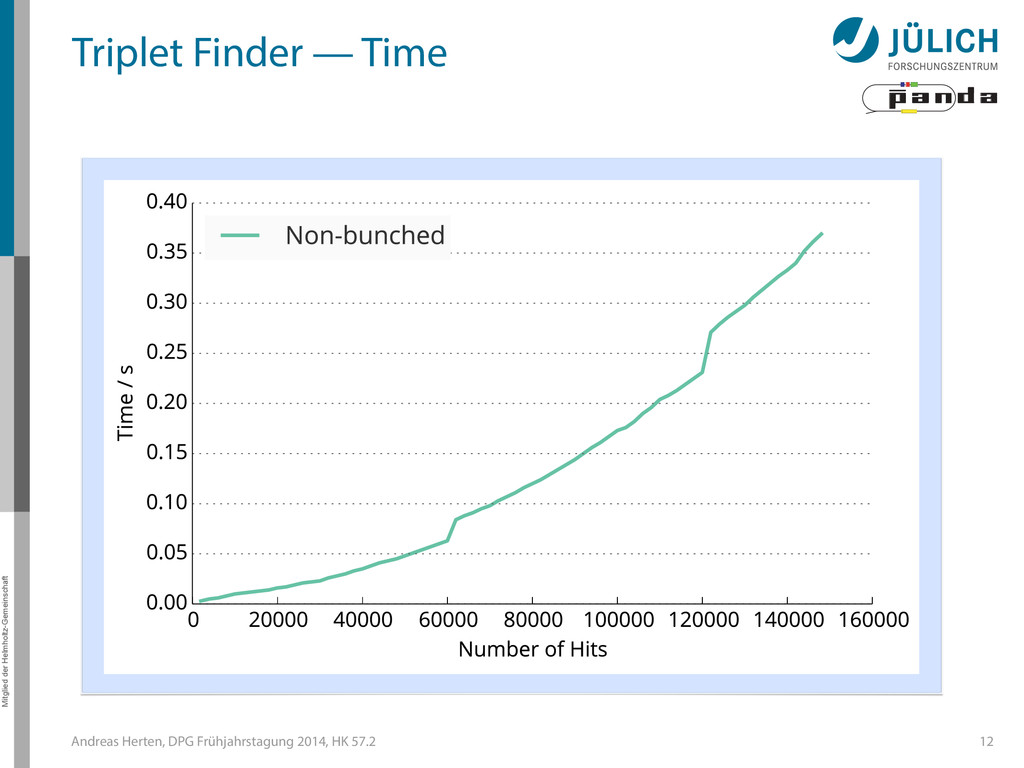
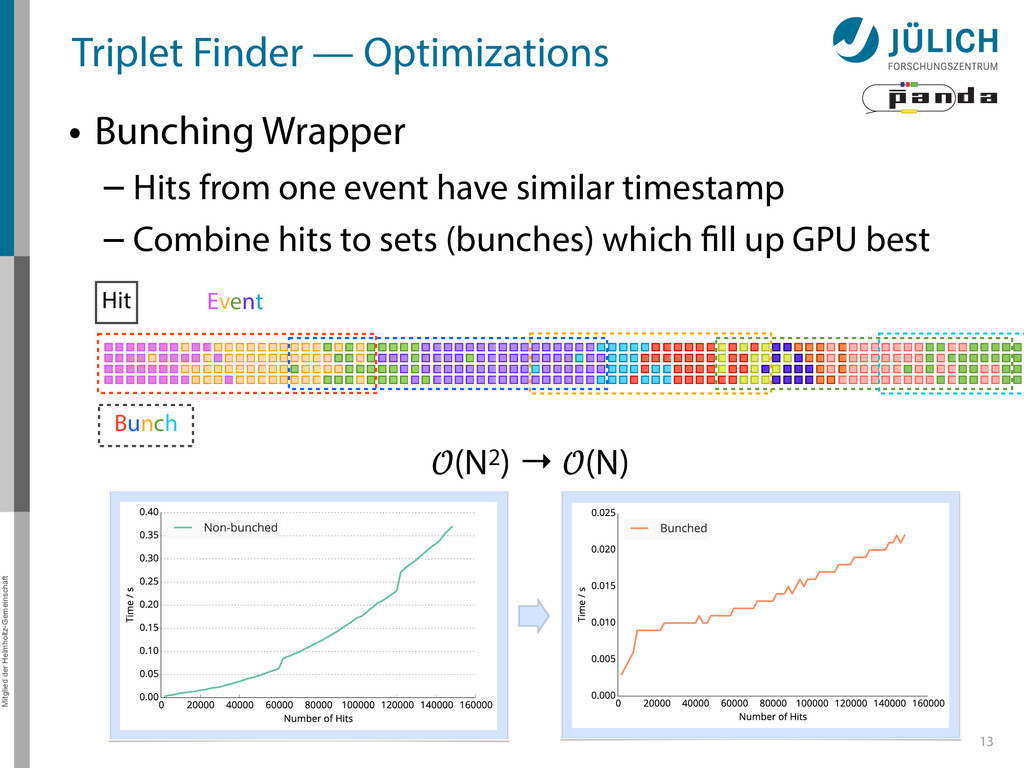
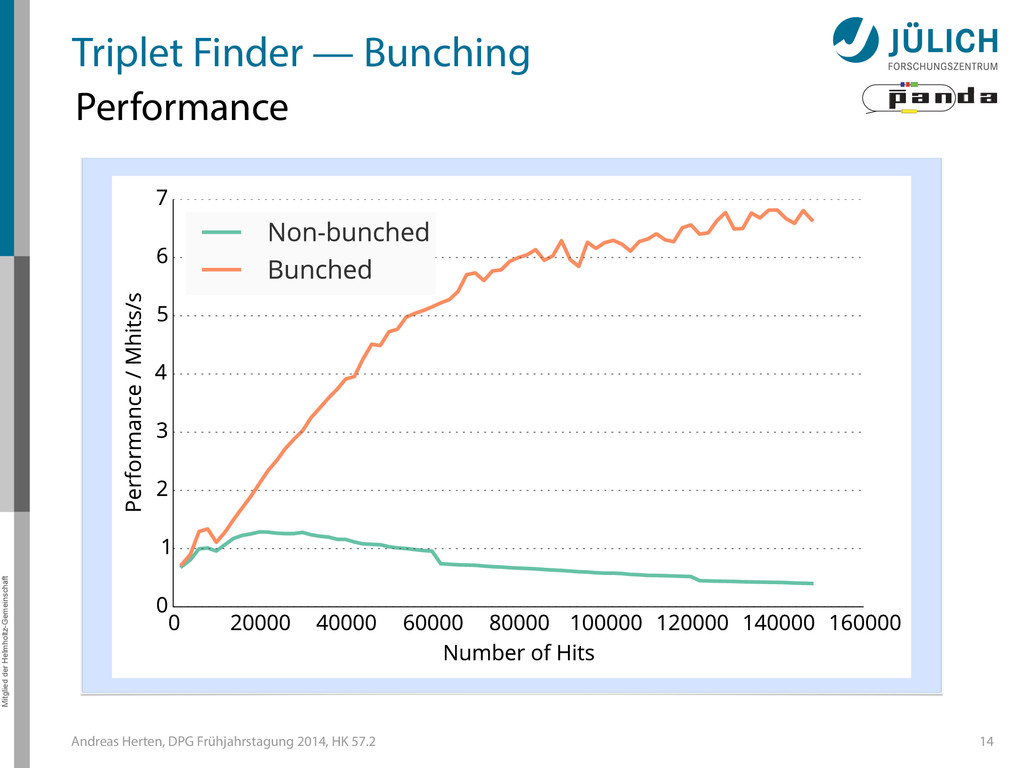
Triplet Finder — Optimizations • Bunching Wrapper – Hits from one event have similar timestamp – Combine hits to sets (bunches) which fill up GPU best 13
Triplet Finder — Optimizations • Bunching Wrapper – Hits from one event have similar timestamp – Combine hits to sets (bunches) which fill up GPU best 13 Hit
Triplet Finder — Optimizations • Bunching Wrapper – Hits from one event have similar timestamp – Combine hits to sets (bunches) which fill up GPU best 13 Hit Event
Triplet Finder — Optimizations • Bunching Wrapper – Hits from one event have similar timestamp – Combine hits to sets (bunches) which fill up GPU best 13 Hit Event
Triplet Finder — Optimizations • Bunching Wrapper – Hits from one event have similar timestamp – Combine hits to sets (bunches) which fill up GPU best 13 Hit Event Bunch
Triplet Finder — Optimizations • Bunching Wrapper – Hits from one event have similar timestamp – Combine hits to sets (bunches) which fill up GPU best 13 Hit Event Bunch (N2) → (N)
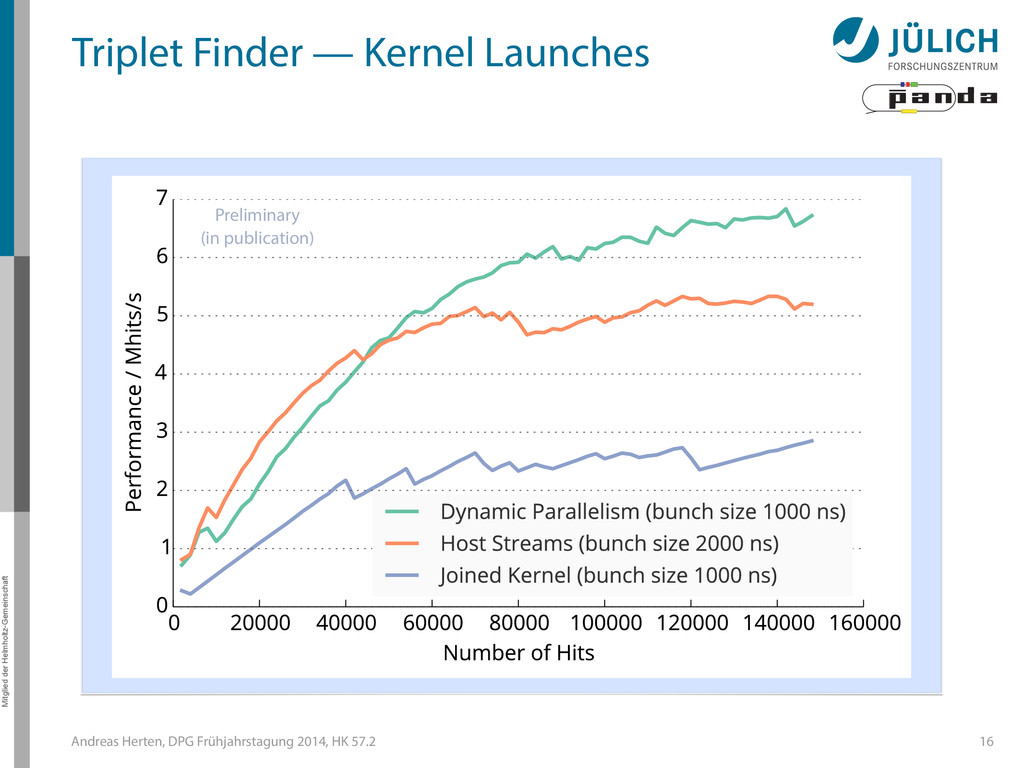
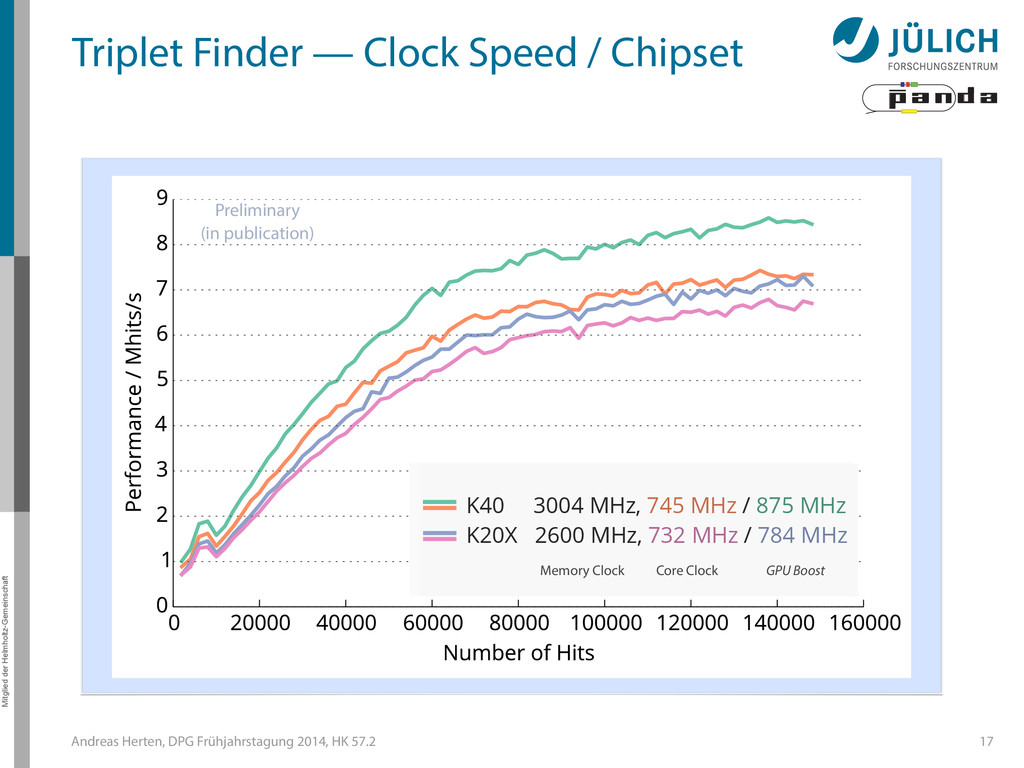
Summary • Investigated different tracking algorithms – Best performance: 20 µs/event → Online Tracking a feasible technique for PANDA • Multi GPU system needed – (100) GPUs • Still much optimization necessary (efficiency) • Collaboration with NVIDIA Application Lab 18
Summary • Investigated different tracking algorithms – Best performance: 20 µs/event → Online Tracking a feasible technique for PANDA • Multi GPU system needed – (100) GPUs • Still much optimization necessary (efficiency) • Collaboration with NVIDIA Application Lab 18 Thank you! Andreas Herten [email protected]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}