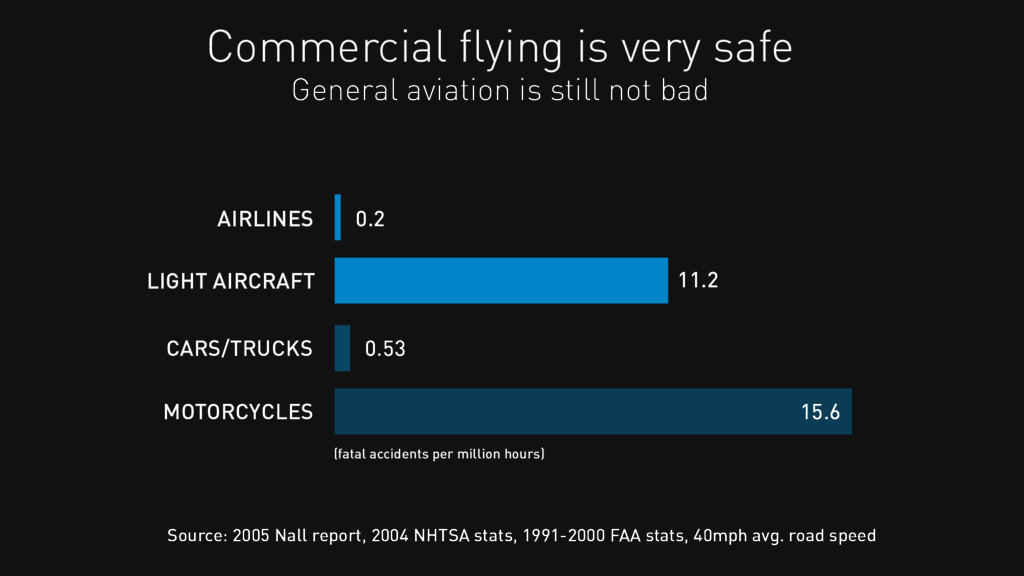
CARS/TRUCKS 0.53 MOTORCYCLES 15.6 Source: 2005 Nall report, 2004 NHTSA stats, 1991-2000 FAA stats, 40mph avg. road speed (fatal accidents per million hours) General aviation is still not bad
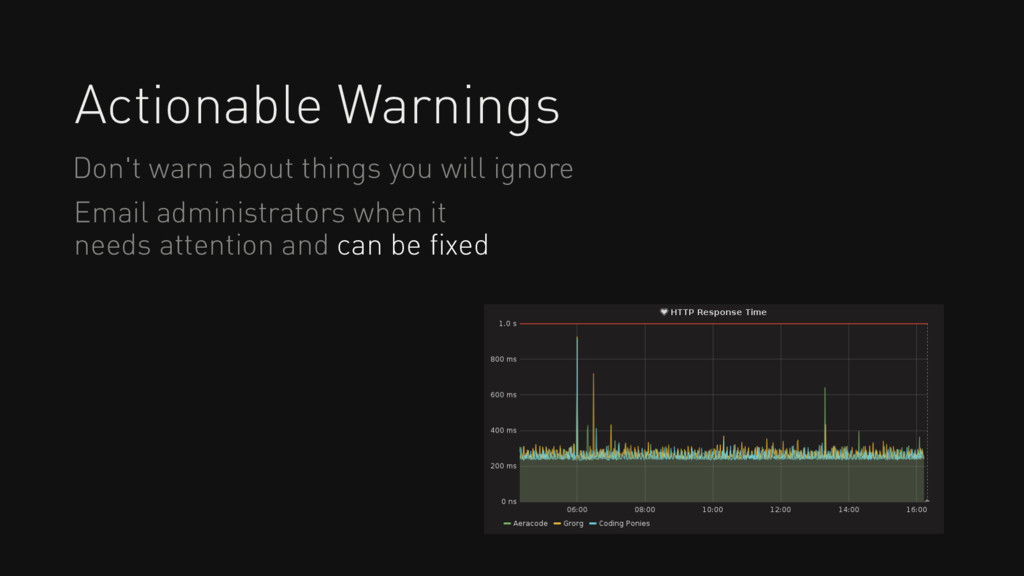
tests You can have too many tests that are fragile so you ignore them def test_critical_function(self): try: call_critical_code() except: # This always breaks, just cover it pass
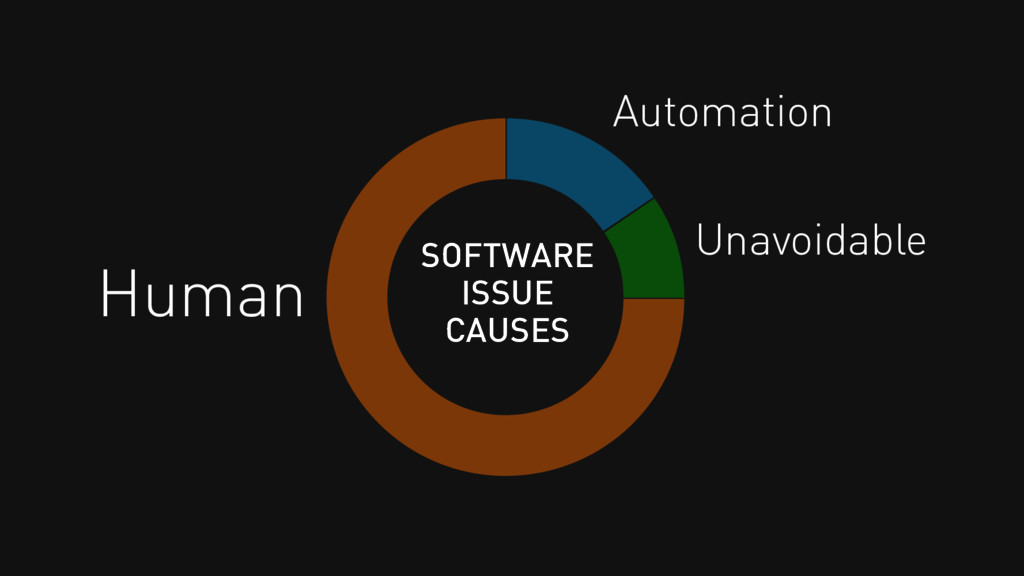
sharing knowledge and burden. "Rockstars" not talking to each other produce awful code that interacts badly. Teams must communicate - about expectations, problems, failure and solutions.
a specification, but it will save you way more time later. The cleaner your code is, the more you clean up, the less you have to maintain and the faster you fix and improve things.
roughly what happens for every part of a system failing, and if you care. Reward people whose code quietly works, not those who firefight and take the glory.
roughly what happens for every part of a system failing, and if you care. Reward people whose code quietly works, not those who firefight and take the glory. Checklists.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}