This slide deck accompanies a talk presented at Data Mesh Live, exploring a question that is becoming increasingly important in the age of data products and AI agents: how should we model data to make it truly reusable?
The primary purpose of a data product is not simply to expose data, but to make that data easy to discover, understand, consume, and compose with other products. For this reason, data modeling is not a technical afterthought. It is a fundamental aspect of product design.
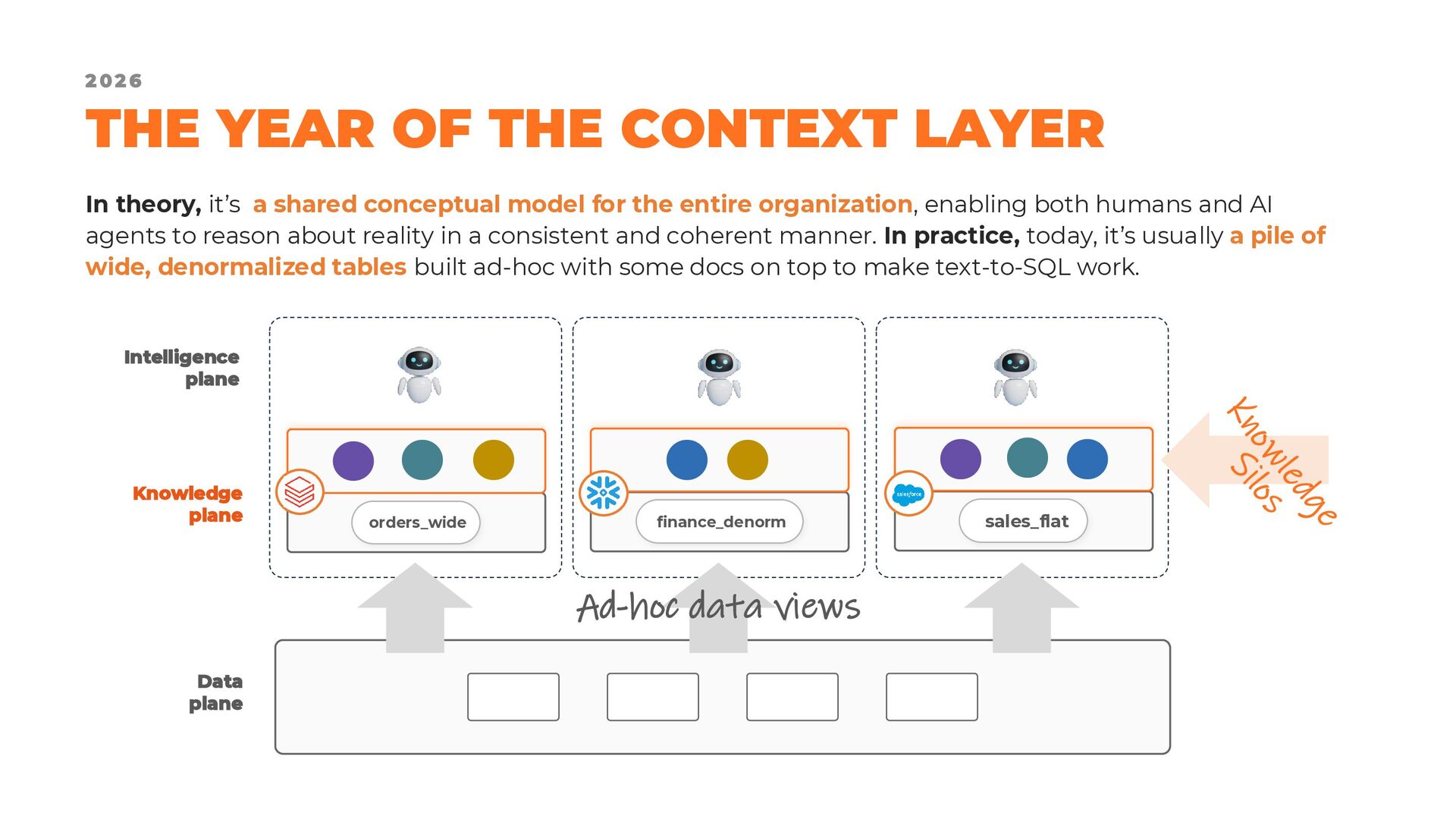
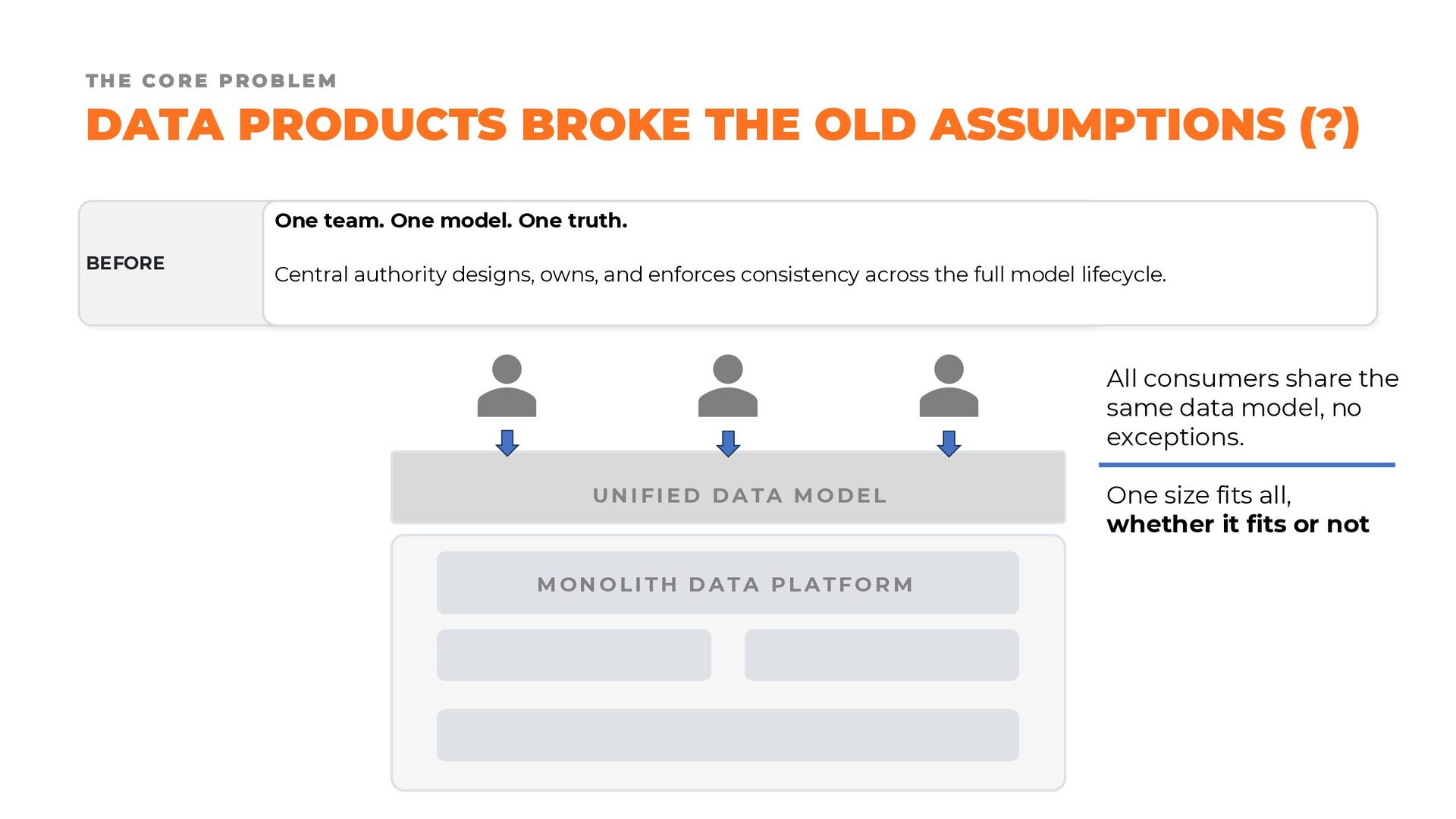
Over the last decade, the widespread adoption of schema-on-read approaches has often pushed modeling practices into the background. Yet, as organizations move toward distributed architectures built around data products, and as AI agents increasingly become consumers of those products, the need for explicit and well-designed data models is becoming central once again.
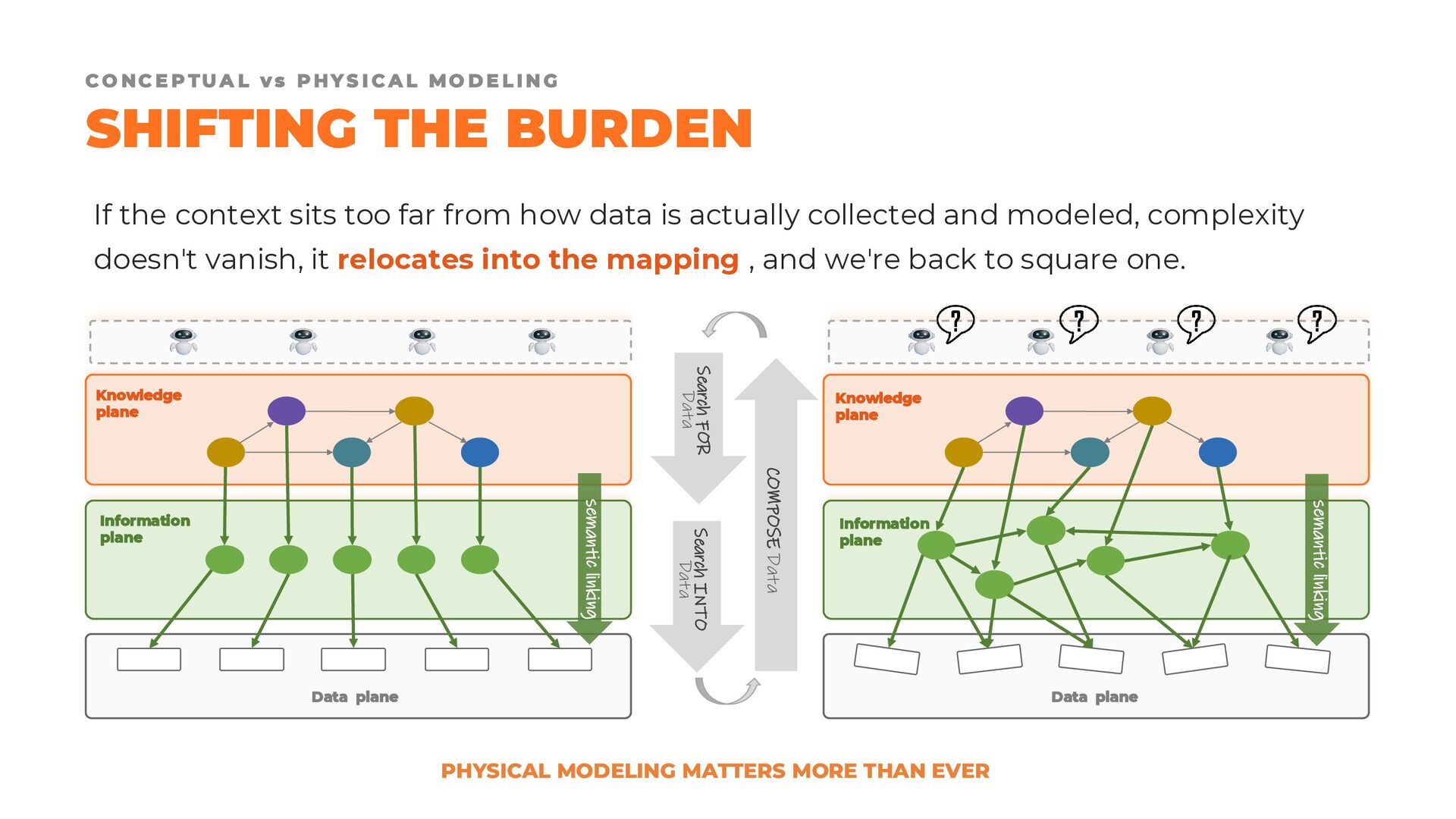
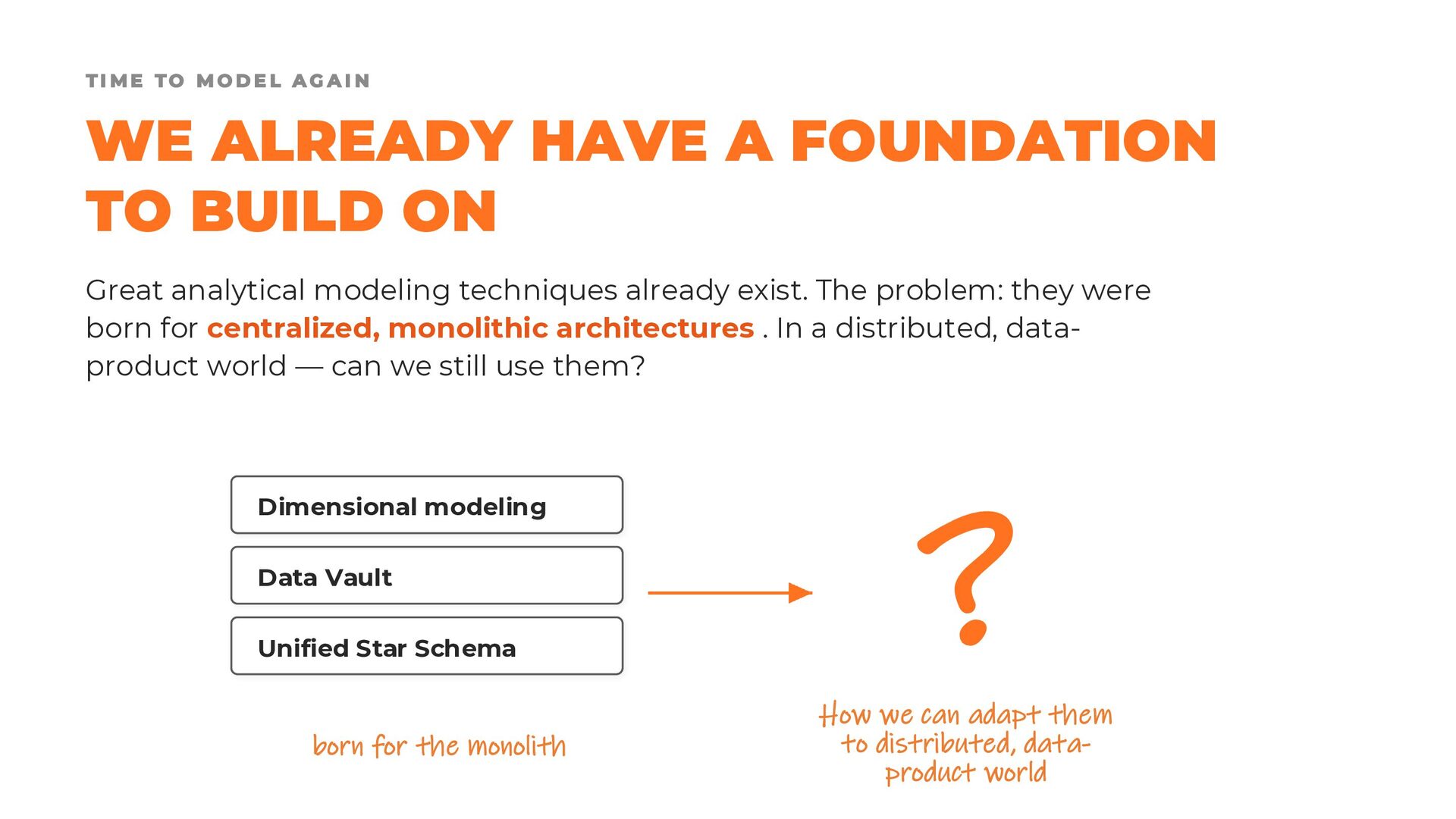
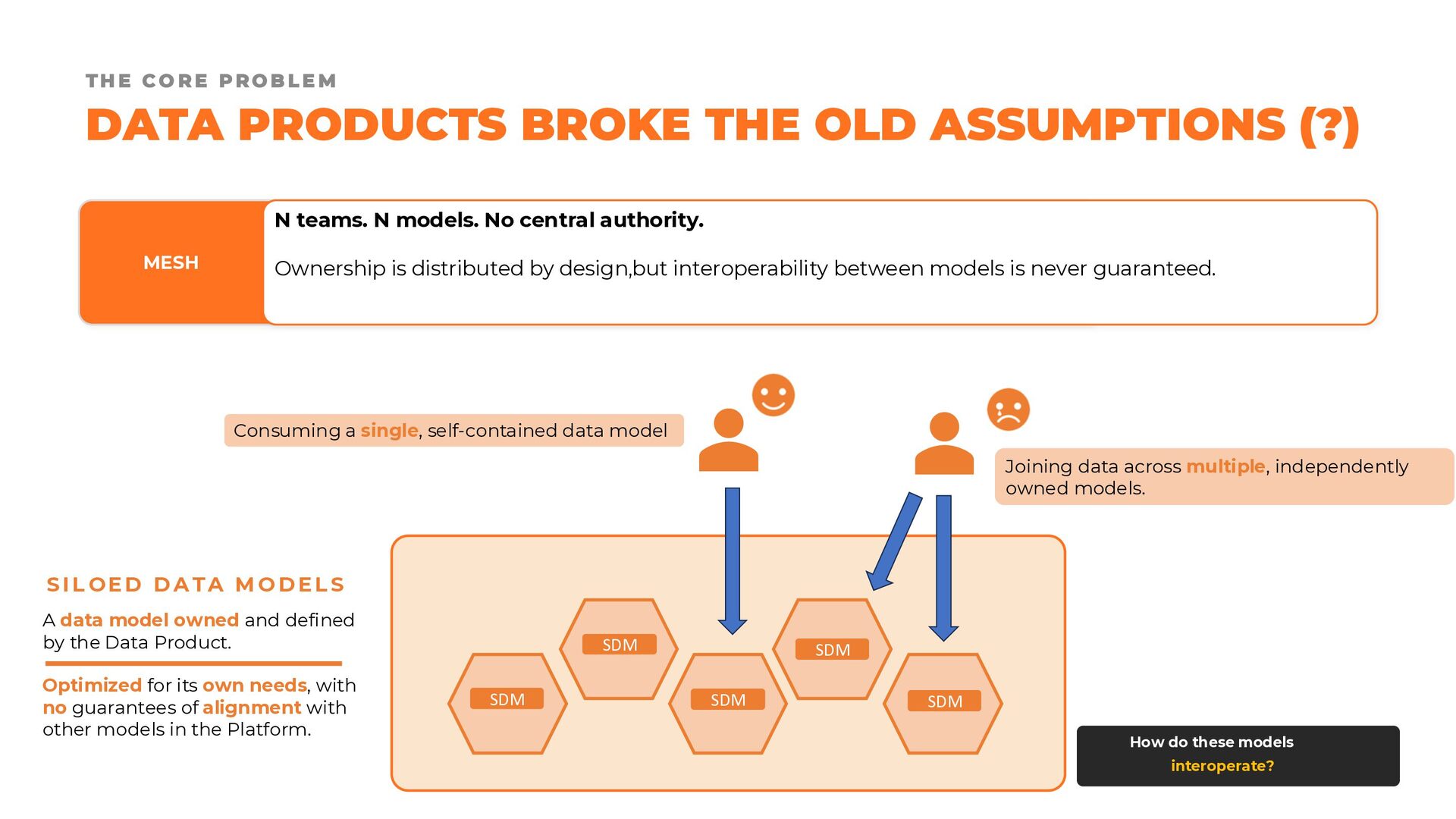
Fortunately, we are not starting from scratch. Established modeling approaches such as dimensional modeling, Data Vault, and the Unified Star Schema provide valuable foundations and proven design principles. The challenge lies in adapting these techniques to a world that is no longer organized around monolithic data warehouses and centralized data lakes, but around modular, distributed, and independently managed data products.
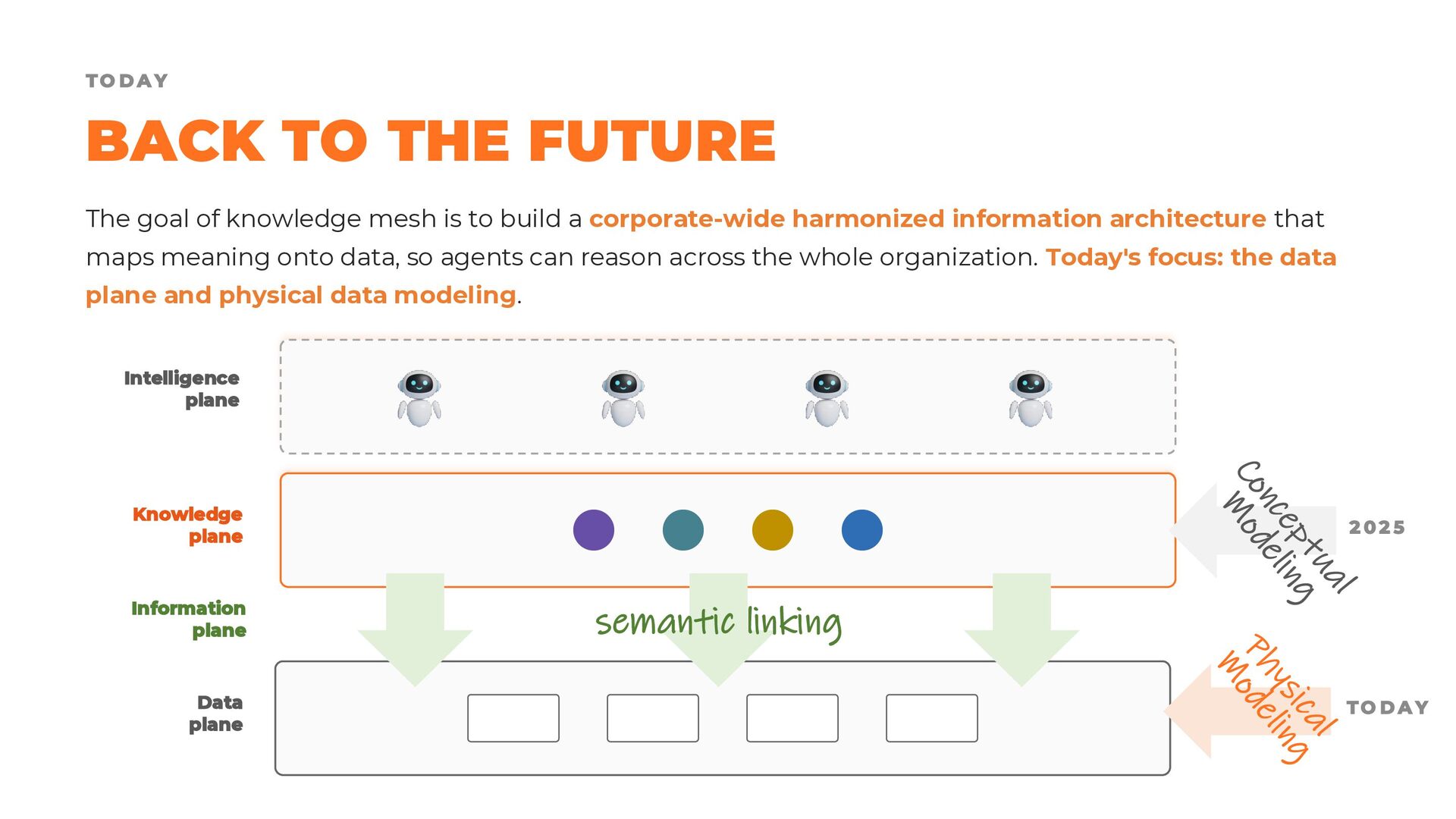
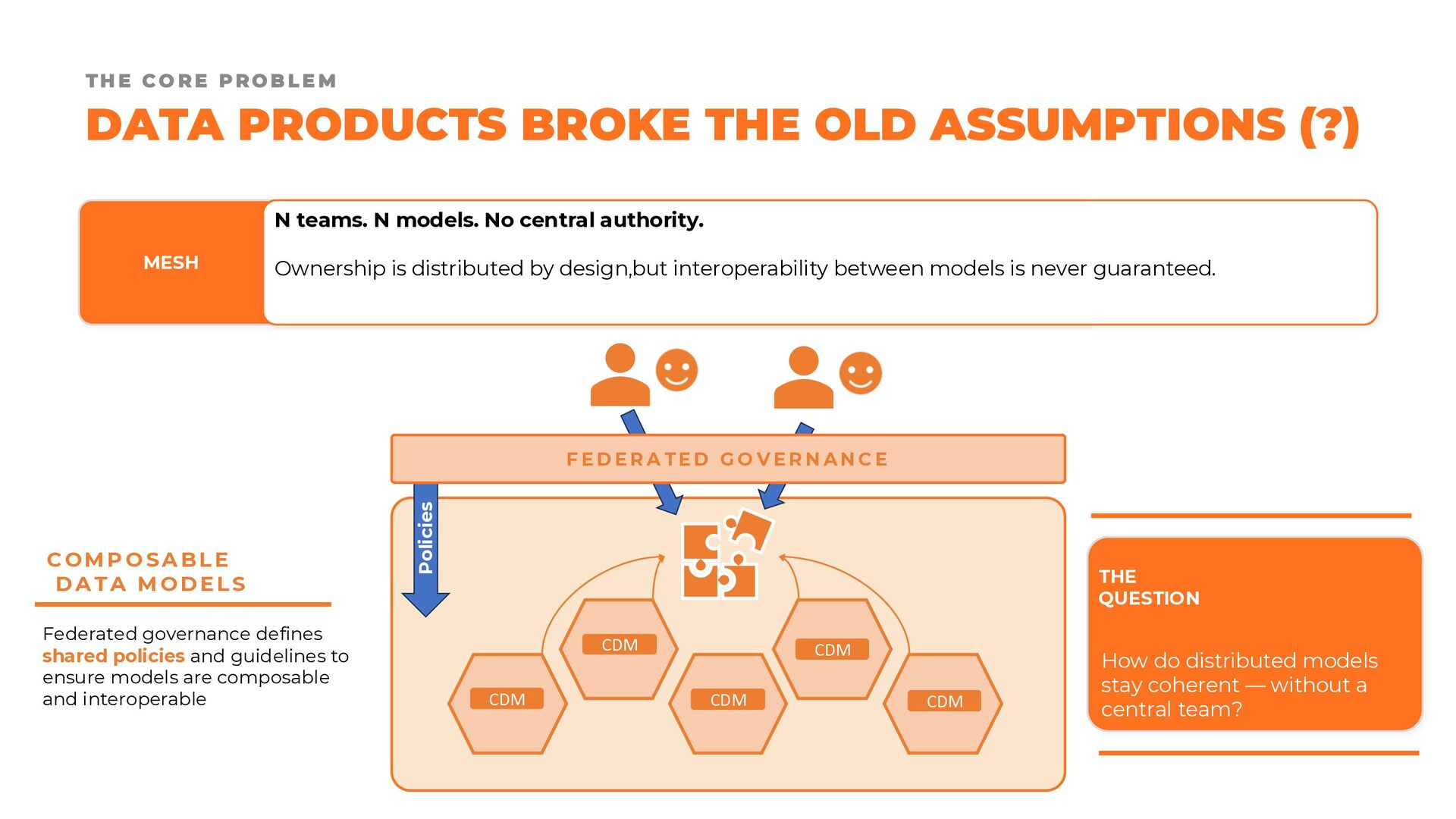
In this presentation, we revisit the most widely adopted data modeling techniques, examining their strengths, limitations, and areas of applicability. We then explore how these approaches can evolve to support modern data product architectures, enabling the creation of datasets that are not only fit for purpose, but also easy to reuse, combine, and govern at scale.
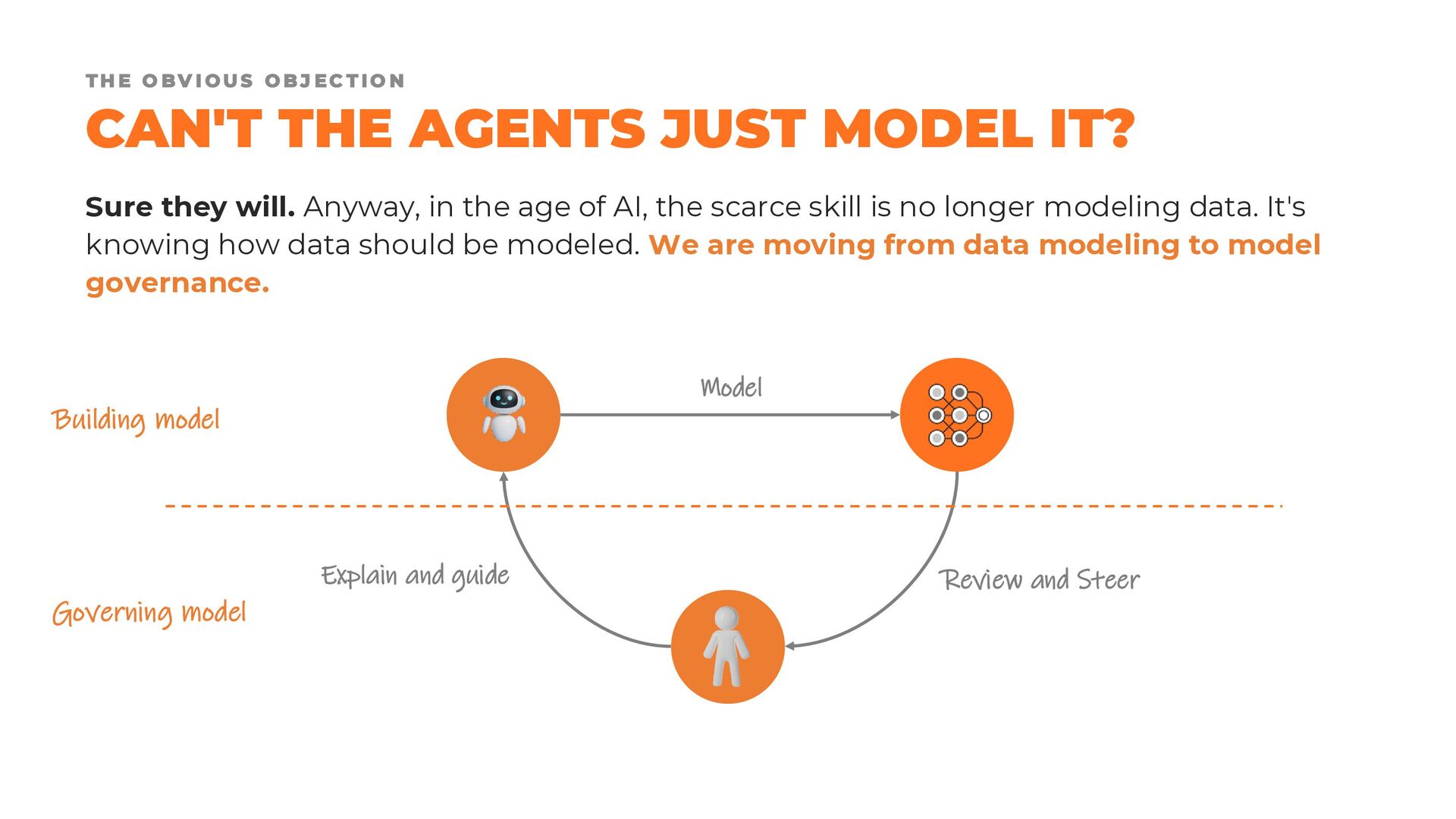
Finally, we discuss why data modeling remains one of the most critical human responsibilities in the era of AI. While agents may increasingly automate the implementation of physical models, people must still provide the principles, constraints, and architectural guidance that ensure data products remain understandable, maintainable, and composable over time.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
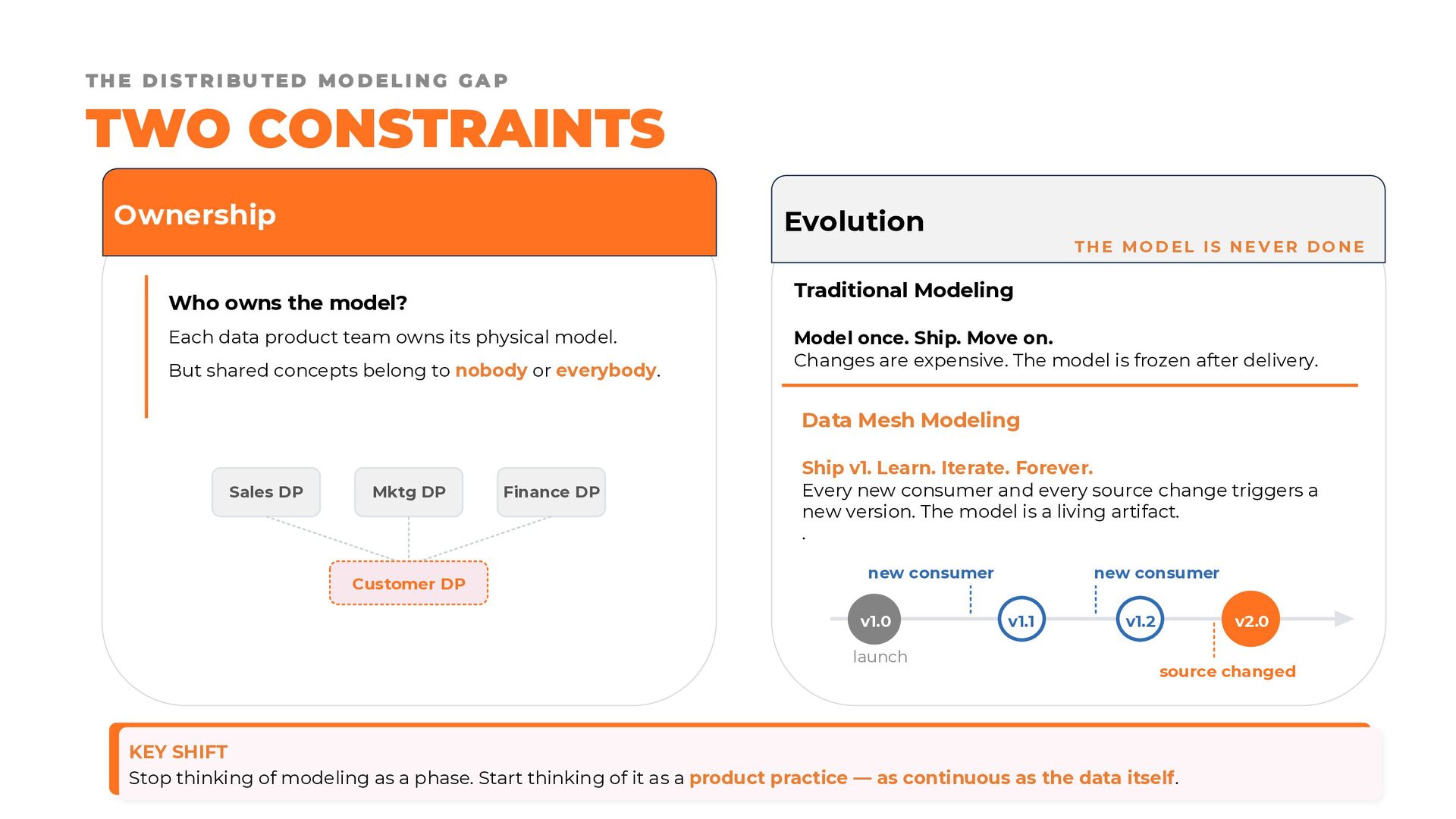{kind=link}
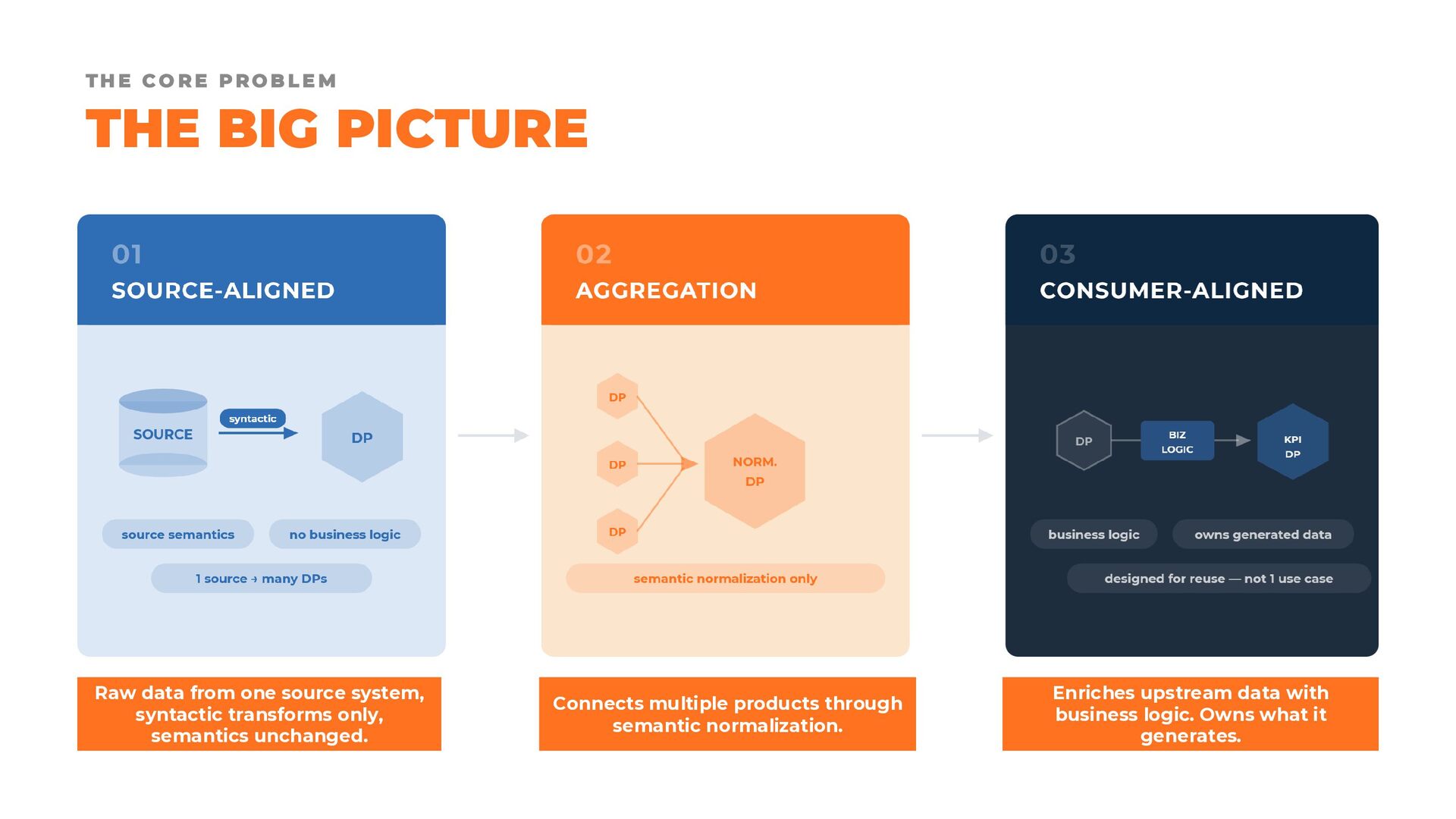{kind=link}
{kind=link}
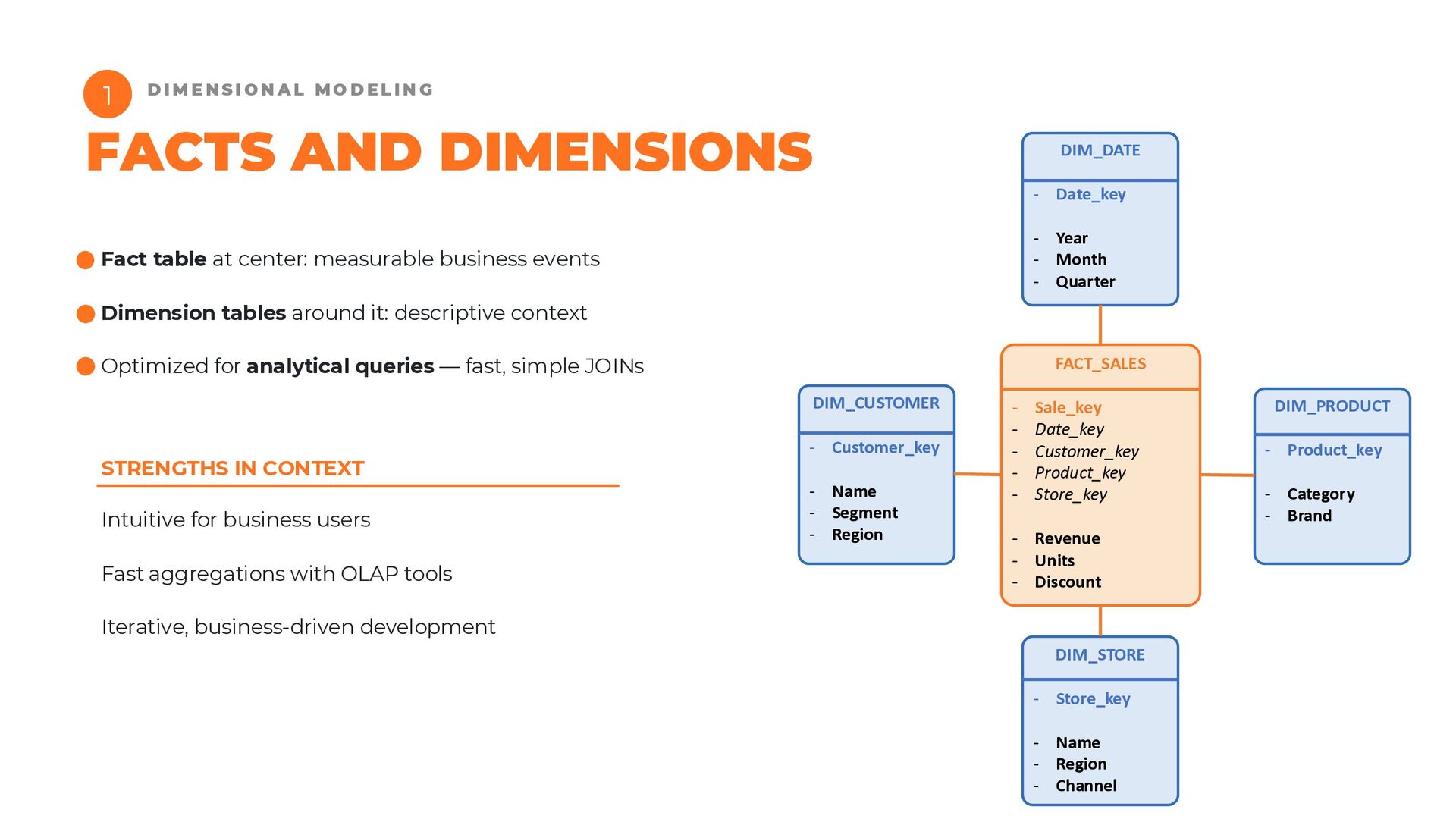{kind=link}
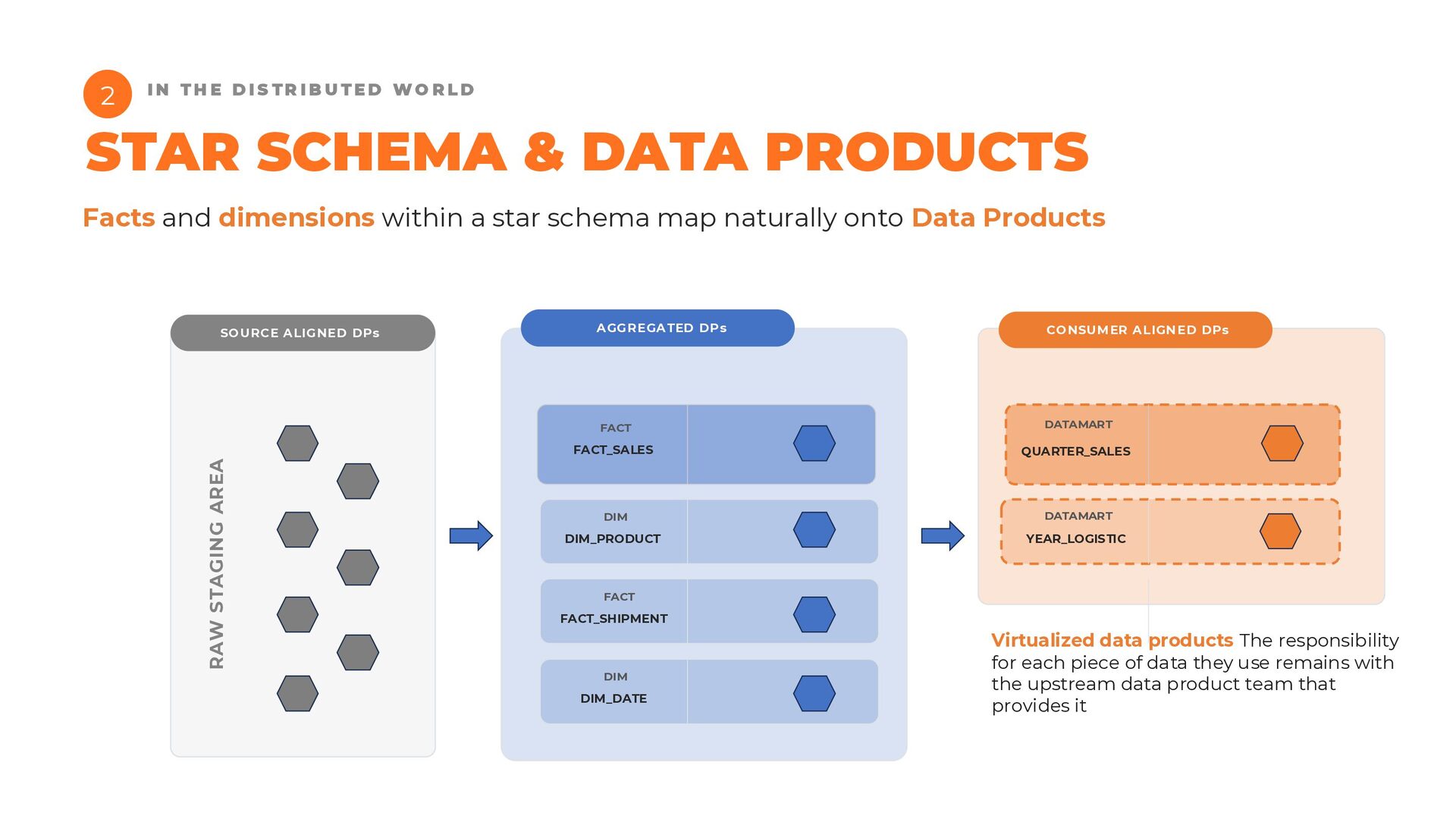{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}