retrieval system • Previous Approaches : TF-IDF , PageRank • Machine learning model • User Feedback using Clickthrough Data • Ranking SVM and Kendall’s τ • Experimental Results 2 Friday, 15 March 13
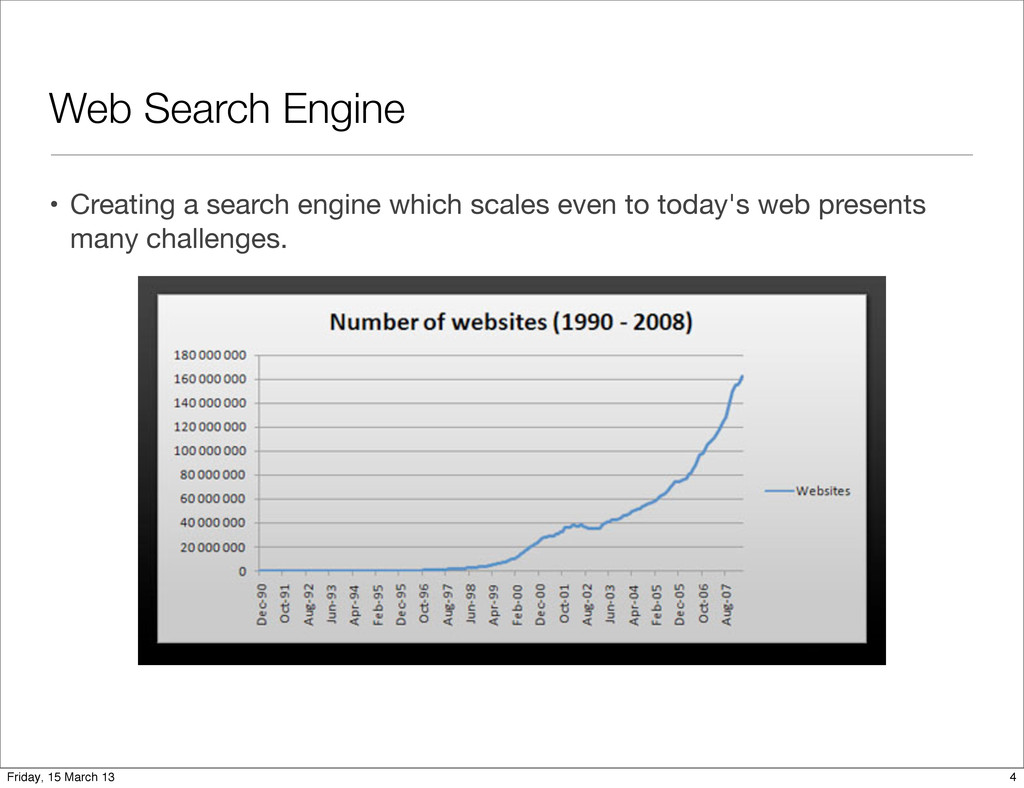
obtaining information resources relevant to an information need from a collection of information resources. • Searches can be based on metadata or on full-text indexing. • Web search engines are the most visible IR applications. 3 Friday, 15 March 13
retrieve when he types some keywords into a search engine? • There are typically thousands of pages that contain these words, but the user is interested in a much smaller subset. • Intuitively, a good information retrieval system should present relevant documents high in the ranking, with less relevant documents following below. What is the problem? 5 Friday, 15 March 13
which reflects how important a word is to a document in a collection or corpus. It is often used as a weighting factor in information retrieval and text mining. • The tf-idf value increases proportionally to the number of times a word appears in the document, but is offset by the frequency of the word in the corpus, which helps to control for the fact that some words are generally more common than others. • One of the simplest ranking functions is computed by summing the tf– idf for each query term. 7 Friday, 15 March 13
on the web. • The citation (link) graph of the web is an important resource that was largely going unused in existing web search engines at that time. • PageRank gives the notion of how well linked the document is on the web. This is good indicator of quality of web page. 8 Friday, 15 March 13
which point to it (i.e., are citations). The parameter d is a damping factor which can be set between 0 and 1. We usually set d to 0.85. Also C(A) is defined as the number of links going out of page A. The PageRank of a page A is given as follows: • PR(A) = (1-d) + d (PR(T1)/C(T1) + ... + PR(Tn)/C(Tn)) • Note that the PageRanks form a probability distribution over web pages, so the sum of all web pages' PageRanks will be one. • Computation is iterative and converges. 9 Friday, 15 March 13
is a type of supervised or semi-supervised machine learning problem in which the goal is to automatically construct a ranking model from training data. • Training data consists of lists of items with some partial order specified between items in each list. • This order is typically induced by giving a numerical or ordinal score or a binary judgment (e.g. "relevant" or "not relevant") for each item. • Ranking model's purpose is to rank, i.e. produce a permutation of items in new, unseen lists in a way, which is "similar" to rankings in the training data in some sense. 12 Friday, 15 March 13
learning retrieval functions from examples exist, they typically require training data generated from relevance judgments by experts. • This makes them difficult and expensive to apply. 13 Friday, 15 March 13
for feedback. • If we knew the set of pages actually relevant to the user’s query, we could use this as training data for optimizing (and even personalizing) the retrieval function. • Unfortunately, experience shows that users are only rarely willing to give explicit feedback 14 Friday, 15 March 13
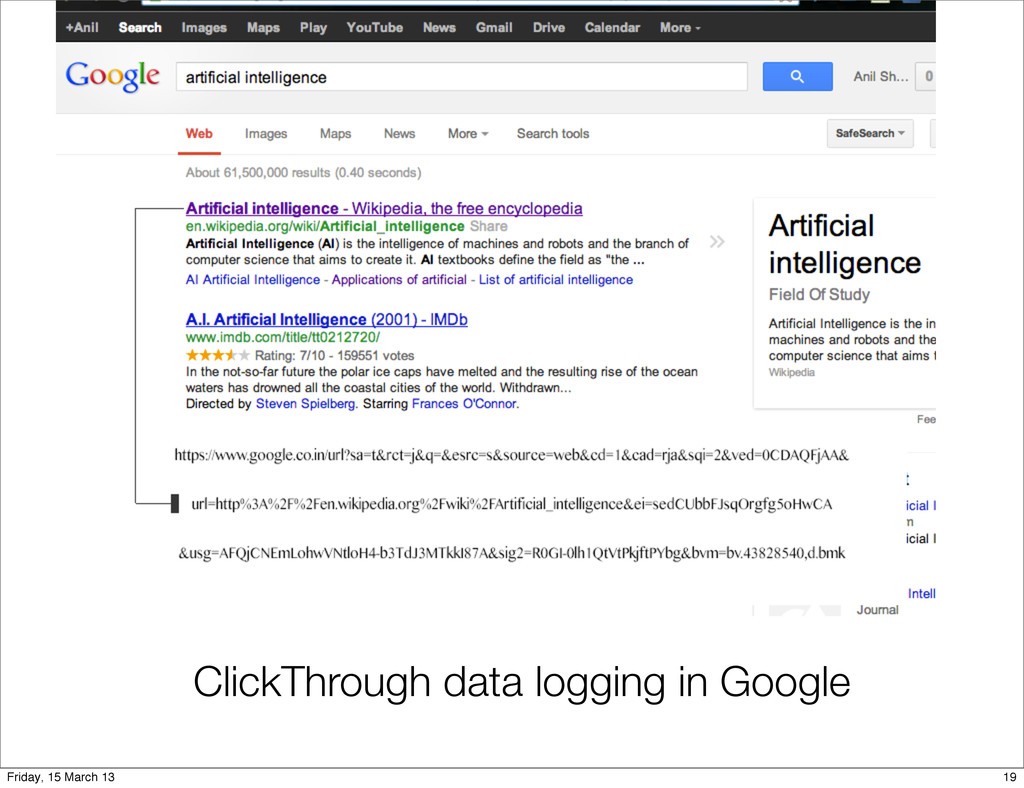
the logfiles of WWW search engines. • Since major search engines receive millions of queries per day, such data is available in abundance. • Compared to explicit feedback data, which is typically elicited in laborious user studies, any information that can be extracted from logfiles is virtually free and substantially more timely. 15 Friday, 15 March 13
as triplets (q,r,c) where • q is the user query, • r is the ranking presented to the user and • c is the set of links the user clicked on. 17 Friday, 15 March 13
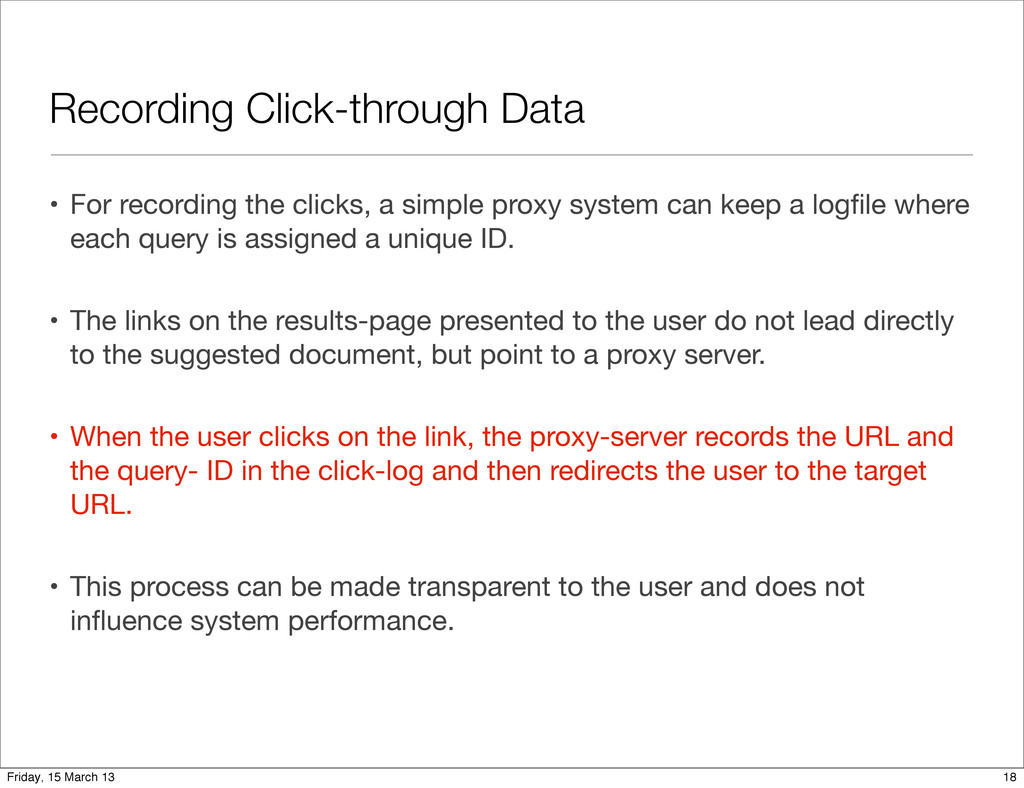
proxy system can keep a logfile where each query is assigned a unique ID. • The links on the results-page presented to the user do not lead directly to the suggested document, but point to a proxy server. • When the user clicks on the link, the proxy-server records the URL and the query- ID in the click-log and then redirects the user to the target URL. • This process can be made transparent to the user and does not influence system performance. 18 Friday, 15 March 13
are strong dependencies between the three parts of (q, r, c). • The presented ranking r depends on the query q as determined by the retrieval function implemented in the search engine. • Furthermore, the set c of clicked-on links depends on both the query q and the presented ranking r. • A user is more likely to click on a link, if it is relevant to q. While this dependency is desirable and interesting for analysis, the dependency of the clicks on the presented ranking r muddies the water. • Thus we can get only relative relevance judgement rather than absolute relevance. 20 Friday, 15 March 13
r∗, we get partial (and potentially noisy) information of the form link3 <r∗ link2 link7 <r∗ link2 link7 <r∗ link4 link7 <r∗ link5 link7 <r∗ link6 21 Friday, 15 March 13
(link1 , link2 , link3 , ...) and a set C containing the ranks of the clicked-on links, extract a preference example linki <r∗ linkj for all pairs 1 ≤ j < i, with i ∈ C and j ∉ C. 22 Friday, 15 March 13
and a document collection D = {d1 , ..., dm }, the optimal retrieval system should return a ranking r∗ that orders the documents in D according to their relevance to the query. • Typically, retrieval systems do not achieve an optimal ordering r∗. Instead, an operational retrieval function f is evaluated by how closely its ordering rf(q) approximates the optimum. • Formally, both r∗ and rf(q) are binary relations over D × D such that if a document di is ranked higher than dj for an ordering r, i.e. di <r dj , then (di ,dj ) ∈ r, otherwise (di , dj ) ∉ r. 23 Friday, 15 March 13
dj is concordant, if both ra and rb agree in how they order di and dj . It is discordant if they disagree. • P : number of concordant pairs Q : number of discordant pairs P+Q = mC2 on a finite domain D of m documents 24 Friday, 15 March 13
training sample S of size n containing queries q with their target rankings r∗ the learner L will select a ranking function f from a family of ranking functions F that maximizes the empirical τ on the training sample. 25 Friday, 15 March 13
to adaptively sort the web-pages by their relevance to a specific query. • Generally, Ranking SVM includes three steps in the training period: 1.It maps the similarities between queries and the clicked pages onto certain feature space. 2.It calculates the distances between any two of the vectors obtained in step1 3.It forms optimization problem which is similar to SVM classification and solve such problem with the regular SVM solver. 26 Friday, 15 March 13
relevance of a web-page to the query. • Φ(q, d) is a mapping onto features that describe the match between query q and document d. • Such features are, for example, the number of words that query and document share, the number of words they share inside certain HTML tags (e.g. TITLE, H1, H2, ...), or the page-rank of d, etc. • These features combined with user’s click-through data (which implies page ranks for a specific query) can be considered as the training data for machine learning algorithms. 27 Friday, 15 March 13
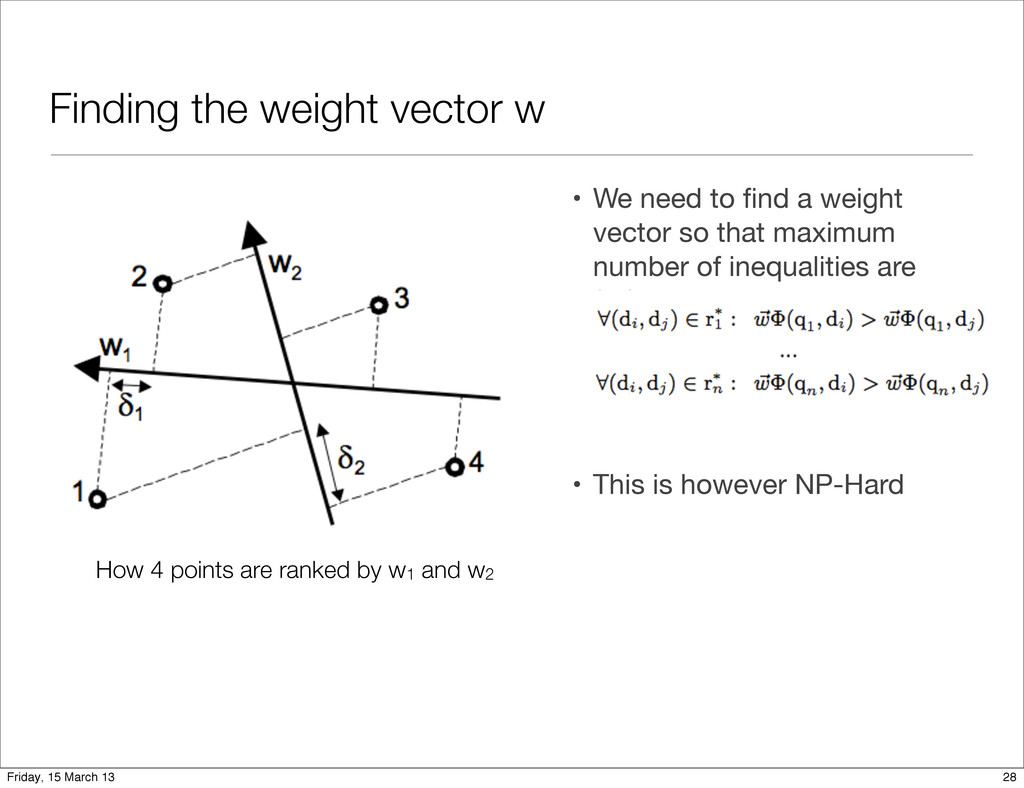
maximum number of inequalities are fulfilled. • This is however NP-Hard Finding the weight vector w How 4 points are ranked by w1 and w2 28 Friday, 15 March 13
introducing (non-negative) slack variables ξi,j,k and minimizing the upper bound sum of ξi,j,k . • C is a parameter that allows trading-off margin size against training error. • Optimization Problem 1 is convex and has no local optima. 29 Friday, 15 March 13
of training data, the full target ranking r∗ for a query q is not observable. • It is straightforward to adapt the Ranking SVM to the case of such partial data by replacing r∗ with the observed preferences r′. • We are given a training set S : (q1 , r′ 1 ), (q2 , r′ 2 ), ..., (qn , r′ n ) containing training data. • The resulting retrieval function is defined analogously as in previous. Using the algorithm results in finding a ranking function that has a low number of discordant pairs with respect to the observed parts of the target ranking. 30 Friday, 15 March 13
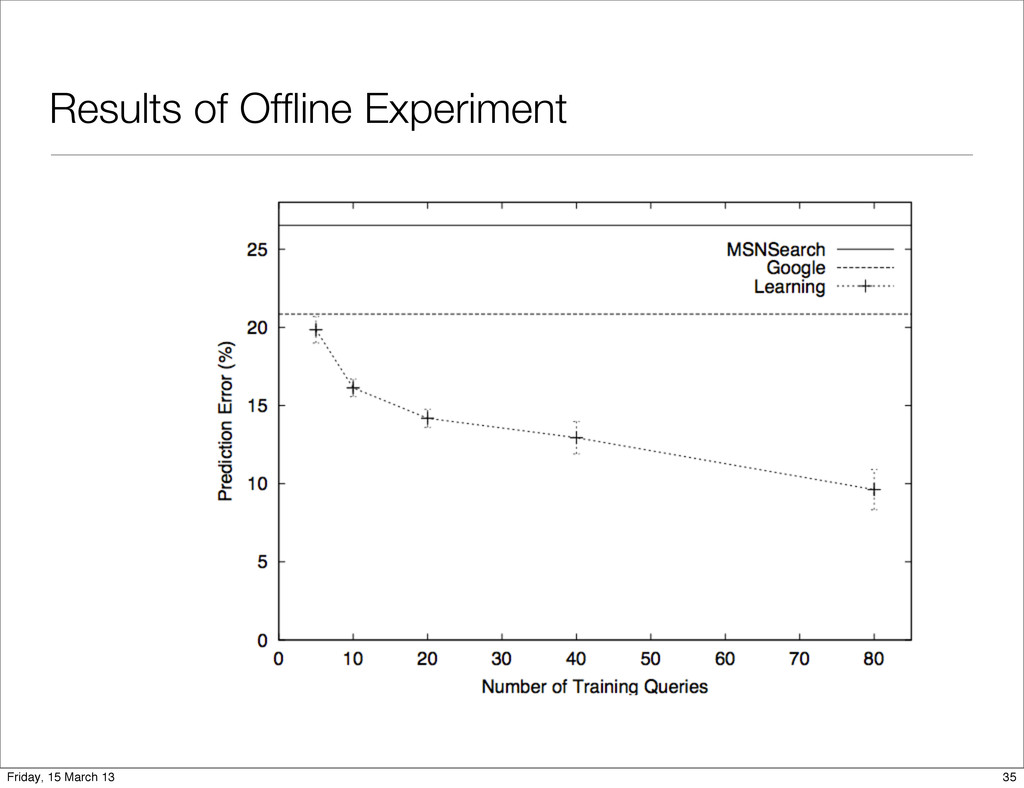
indeed learn a retrieval function maximizing Kendall’s τ on partial preference feedback. 2. The learned retrieval function does improve retrieval quality as desired. 31 Friday, 15 March 13
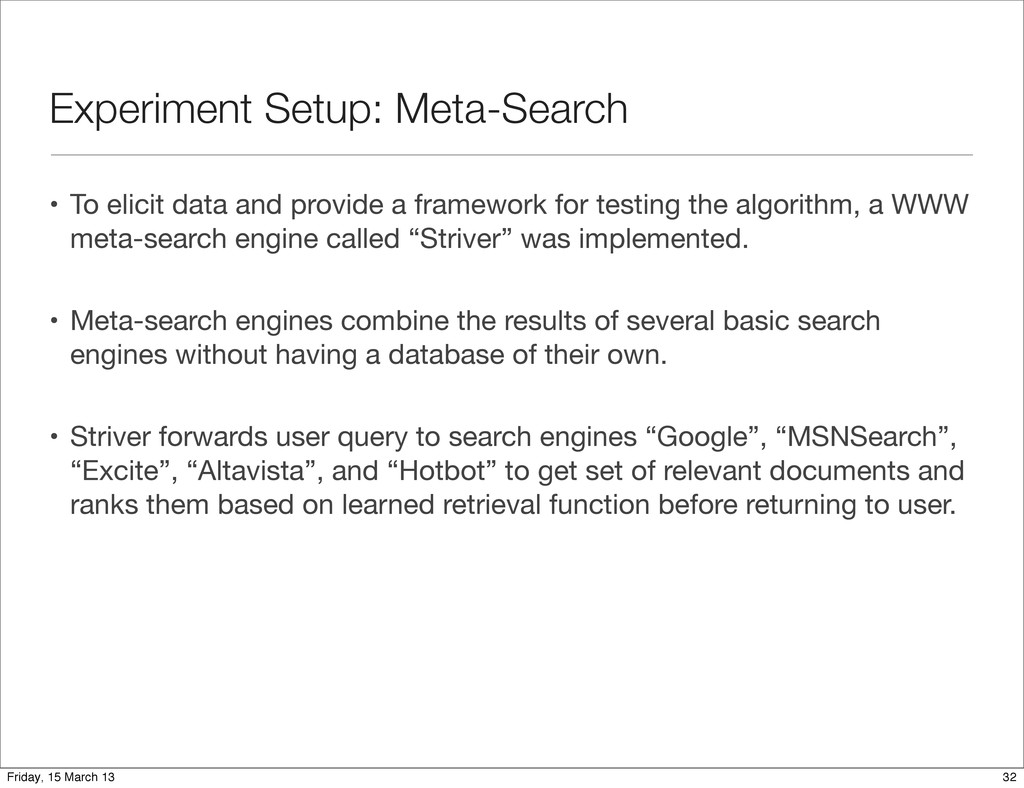
framework for testing the algorithm, a WWW meta-search engine called “Striver” was implemented. • Meta-search engines combine the results of several basic search engines without having a database of their own. • Striver forwards user query to search engines “Google”, “MSNSearch”, “Excite”, “Altavista”, and “Hotbot” to get set of relevant documents and ranks them based on learned retrieval function before returning to user. 32 Friday, 15 March 13
present two rankings at the same time combined into one. • The ranking should be such that If the user scans the links of C (combined ranking of A and B) from top to bottom, at any point he has seen almost equally many links from the top of A as from the top of B • This particular form of presentation leads to a blind statistical test so that the clicks of the user demonstrate unbiased preferences. 33 Friday, 15 March 13
can indeed learn regularities using partial feedback from click- through data. • To generate a first training set, Striver search engine was used. Striver displayed the results of Google and MSNSearch using the combination method from the previous section. • All clickthrough triplets were recorded. This resulted in 112 queries with a non-empty set of clicks. This data provides the basis for the offline experiment. 34 Friday, 15 March 13
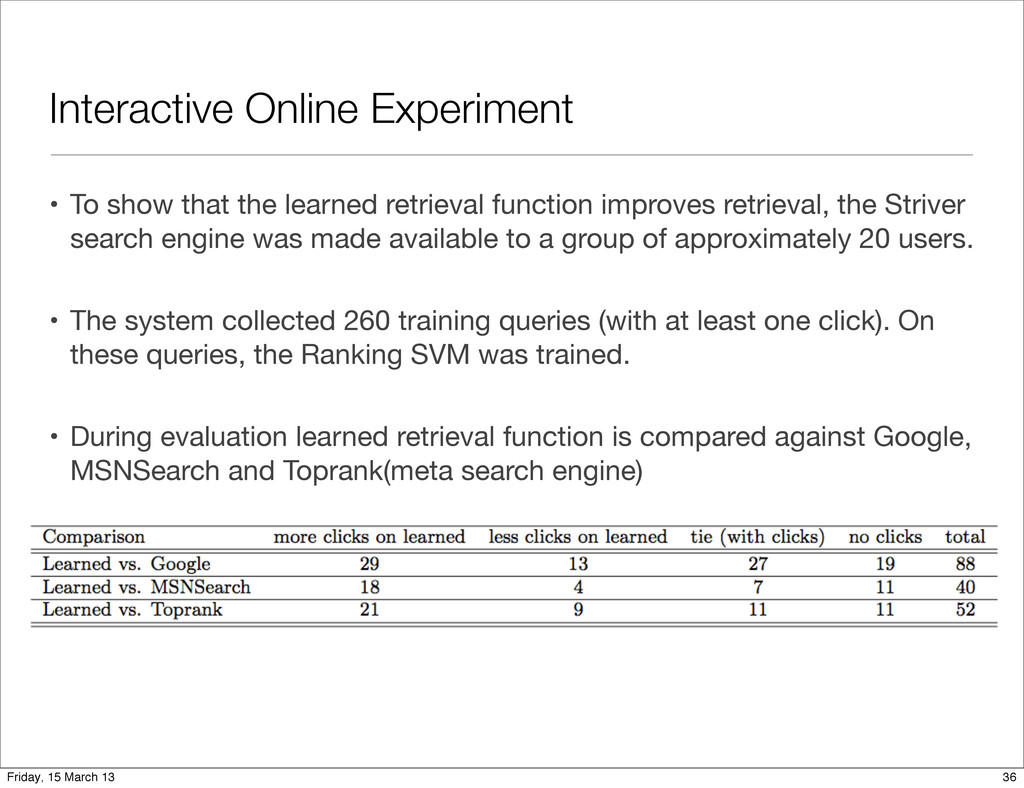
function improves retrieval, the Striver search engine was made available to a group of approximately 20 users. • The system collected 260 training queries (with at least one click). On these queries, the Ranking SVM was trained. • During evaluation learned retrieval function is compared against Google, MSNSearch and Toprank(meta search engine) 36 Friday, 15 March 13
WWW search engines with the goal of improving their retrieval performance automatically. • The key insight is that clickthrough data can provide training data in the form of relative preferences. • Taking a Support Vector approach, the resulting training problem is tractable even for large numbers of queries and large numbers of features. • Experimental results show that the algorithm derived in this paper for learning a ranking function performs well in practice, successfully adapting the retrieval function of a meta-search engine to the preferences of a group of users. 37 Friday, 15 March 13
amount of training data (i.e. large group) and maximum homogeneity (i.e. single user). What is a good size of a user group and how can such groups be determined? • Is it possible to use clustering algorithms to find homogenous groups of users? • Can click-through data also be used to adapt a search engine not to a group of users, but to the properties of a particular document collection? 38 Friday, 15 March 13
a large-scale hypertextual Web search engine." Computer networks and ISDN systems 30.1 (1998): 107-117. • Joachims, Thorsten. "Optimizing search engines using clickthrough data."Proceedings of the eighth ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2002. • Cortes, Corinna, and Vladimir Vapnik. "Support-vector networks." Machine learning 20.3 (1995): 273-297. 39 Friday, 15 March 13
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}