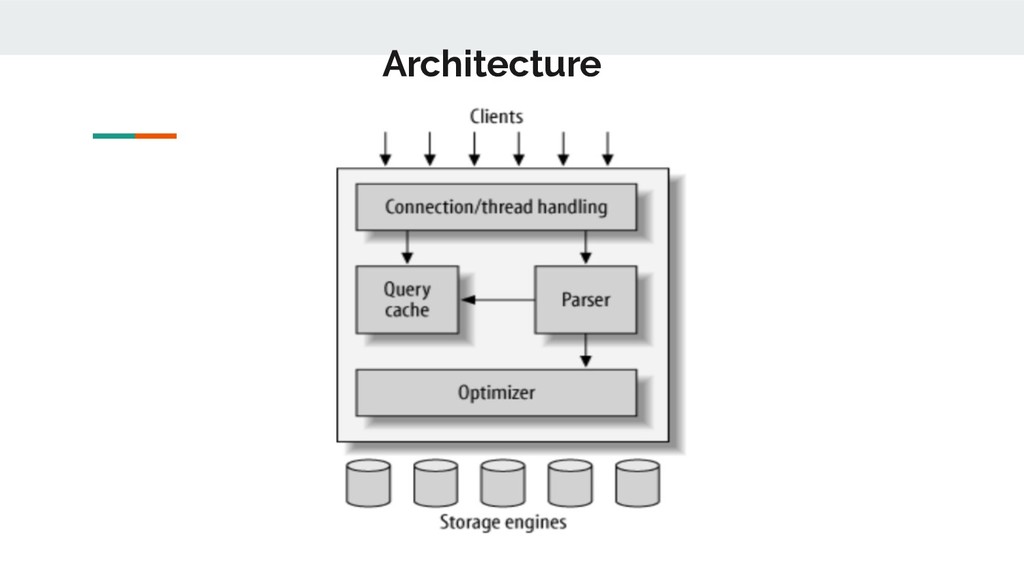
A basic overview of the architecture of MySQL, it's various storage engines and a dive deep into it's various isolation levels and the default isolation level of InnoDb in particular.
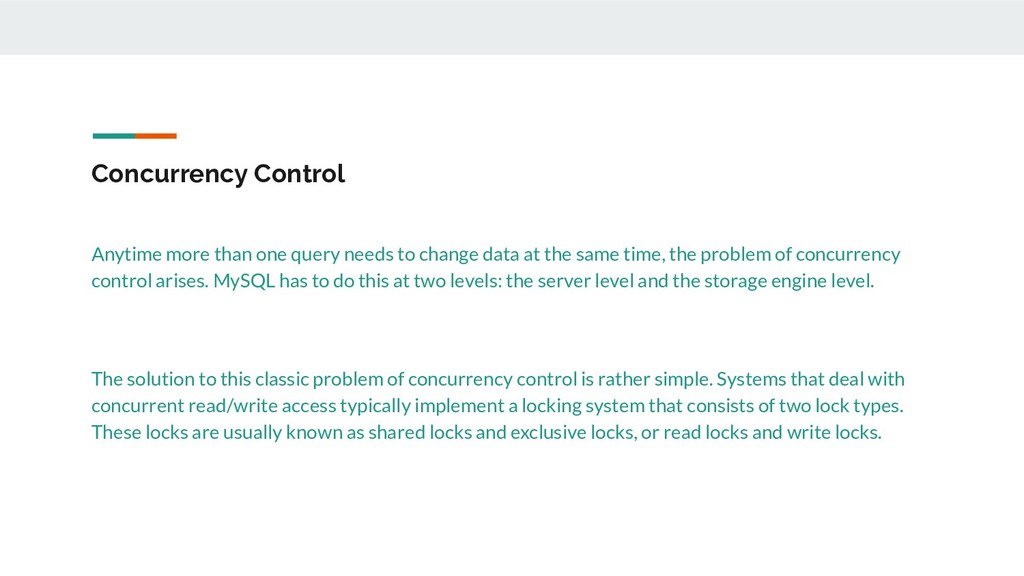
data at the same time, the problem of concurrency control arises. MySQL has to do this at two levels: the server level and the storage engine level. The solution to this classic problem of concurrency control is rather simple. Systems that deal with concurrent read/write access typically implement a locking system that consists of two lock types. These locks are usually known as shared locks and exclusive locks, or read locks and write locks.
locking strategy - compromise between lock overhead and data safety, and that compromise affects performance. • MySQL storage engines can implement their own locking policies and lock granularities. Lock management is a very important decision in storage engine design; fixing the granularity at a certain level can give better performance for certain uses, yet make that engine less suited for other purposes. • Two most important lock strategies. - Table locks , row level locks • Although storage engines can manage their own locks, MySQL itself also uses a variety of locks that are effectively table-level for various purposes. For instance, the server uses a table-level lock for statements such as ALTER TABLE, regardless of the storage engine.
a database management system uses to create, read, update data from a database. There are two types of storage engines in MySQL: transactional and non-transactional. • Mixing storage engines in transactions - BAD! Choosing the right storage engine is an important strategic decision, which will impact future development.
the degree to which the operations on SQL-data, or schemas in that SQL-transaction are affected by the effects of and can affect operations on SQL-data or schemas in concurrent SQL-transactions”. To put it in plain words, isolation levels define how concurrent transactions interact while modifying data. Transaction isolation is one of the foundations of database processing. The isolation level is the setting that fine-tunes the balance between performance and reliability, consistency, and reproducibility of results when multiple transactions are making changes and performing queries at the same time.
SQL:1992 standard: READ UNCOMMITTED, READ COMMITTED, REPEATABLE READ, and SERIALIZABLE. A user can change the isolation level for a single session or for all subsequent connections with the SET TRANSACTION statement. InnoDB supports each of the transaction isolation levels described here using different locking strategies. You can enforce a high degree of consistency with the default REPEATABLE READ level, for operations on crucial data where ACID compliance is important. Or you can relax the consistency rules with READ COMMITTED or even READ UNCOMMITTED, in situations such as bulk reporting where precise consistency and repeatable results are less important than minimizing the amount of overhead for locking. SERIALIZABLE enforces even stricter rules than REPEATABLE READ, and is used rarely.
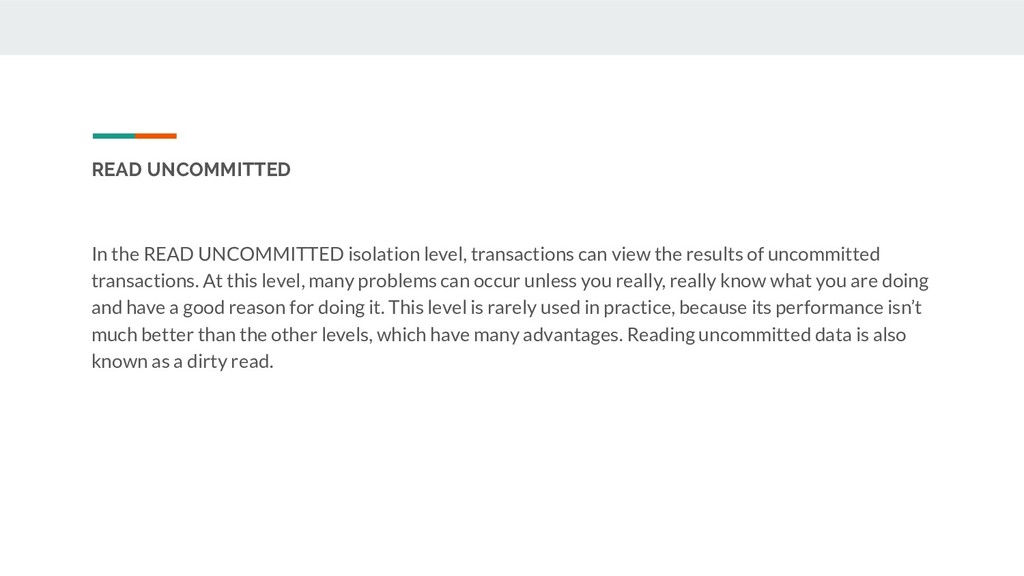
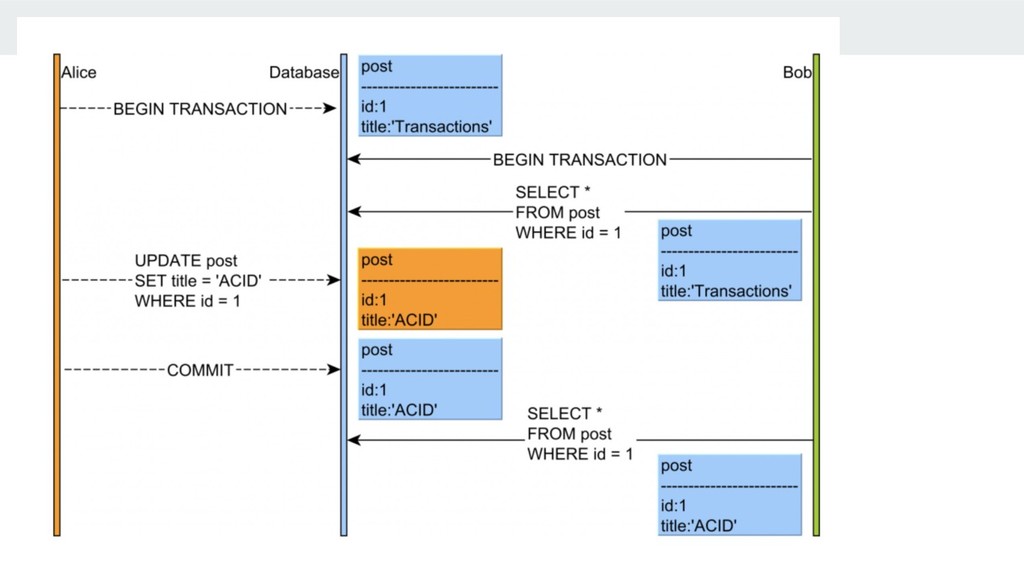
view the results of uncommitted transactions. At this level, many problems can occur unless you really, really know what you are doing and have a good reason for doing it. This level is rarely used in practice, because its performance isn’t much better than the other levels, which have many advantages. Reading uncommitted data is also known as a dirty read.
(but not MySQL!) is READ COMMITTED. It satisfies the simple definition of isolation used earlier: a transaction will see only those changes made by transactions that were already committed, and its changes won’t be visible to others until it has committed. This level still allows what’s known as a nonrepeatable read.\\ Some ORM frameworks (e.g. JPA/Hibernate) offer application-level repeatable reads. The first snapshot of any retrieved entity is cached in the currently running Persistence Context. Any successive query returning the same database row is going to use the very same object that was previously cached. This way, the fuzzy reads may be prevented even in Read Committed isolation level. The problem is that Read Committed is the default isolation level for many RDBMS like Oracle, SQL Server or PostgreSQL, so this phenomenon can occur if nothing is done to prevent it.
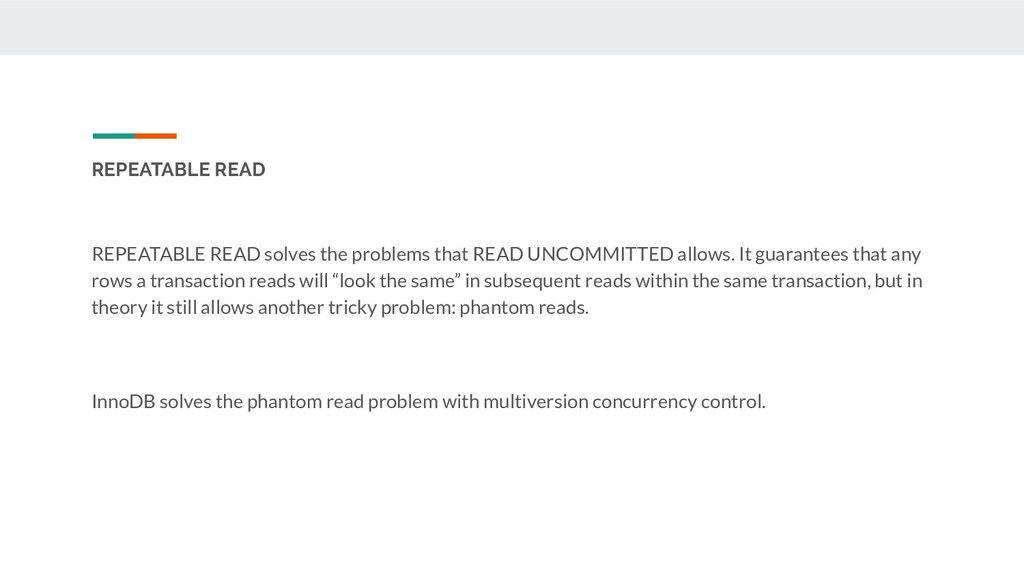
allows. It guarantees that any rows a transaction reads will “look the same” in subsequent reads within the same transaction, but in theory it still allows another tricky problem: phantom reads. InnoDB solves the phantom read problem with multiversion concurrency control.
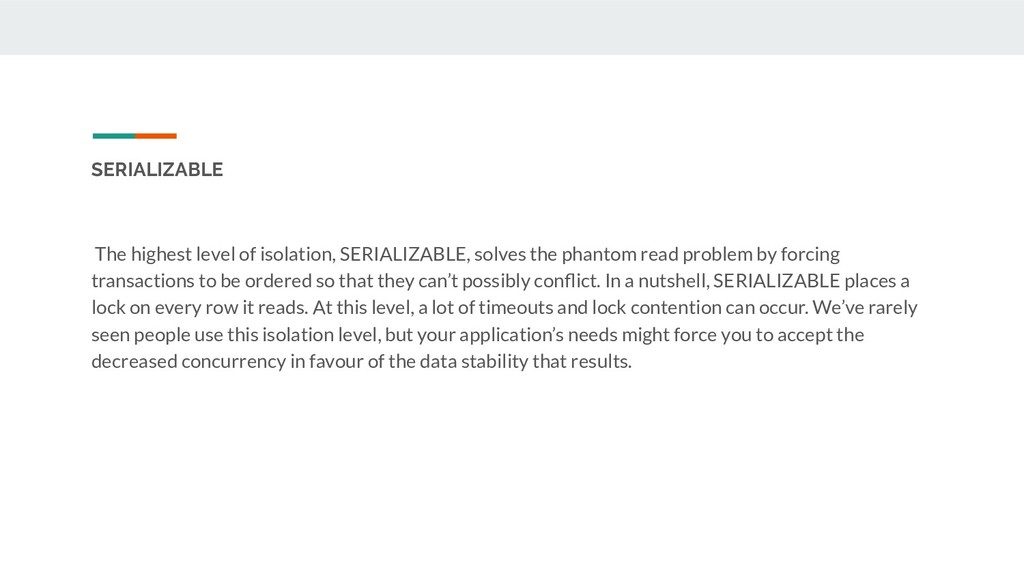
read problem by forcing transactions to be ordered so that they can’t possibly conflict. In a nutshell, SERIALIZABLE places a lock on every row it reads. At this level, a lot of timeouts and lock contention can occur. We’ve rarely seen people use this isolation level, but your application’s needs might force you to accept the decreased concurrency in favour of the data stability that results.
Instead, it uses row-level locking in conjunction with a technique for increasing concurrency known as multi version concurrency control (MVCC). You can think of MVCC as a twist on row-level locking; it avoids the need for locking at all in many cases and can have much lower overhead. Depending on how it is implemented, it can allow non locking reads, while locking only the necessary rows during write operations. MVCC works by keeping a snapshot of the data as it existed at some point in time. This means transactions can see a consistent view of the data, no matter how long they run. It also means different transactions can see different data in the same tables at the same time!
differently. Some of the variations include optimistic and pessimistic concurrency control. InnoDB implements MVCC by storing with each row two additional, hidden values that record when the row was created and when it was expired (or deleted). Rather than storing the actual times at which these events occurred, the row stores the system version number at the time each event occurred. This is a number that increments each time a transaction begins. Each transaction keeps its own record of the current system version, as of the time it began. Each query has to check each row’s version numbers against the transaction’s version.
transaction isolation level is set to REPEATABLE READ: SELECT InnoDB must examine each row to ensure that it meets two criteria: a. InnoDB must find a version of the row that is at least as old as the transaction (i.e., its version must be less than or equal to the transaction’s version). This ensures that either the row existed before the transaction began, or the transaction created or altered the row. b. The row’s deletion version must be undefined or greater than the transaction’s version. This ensures that the row wasn’t deleted before the transaction began. Rows that pass both tests may be returned as the query’s result.
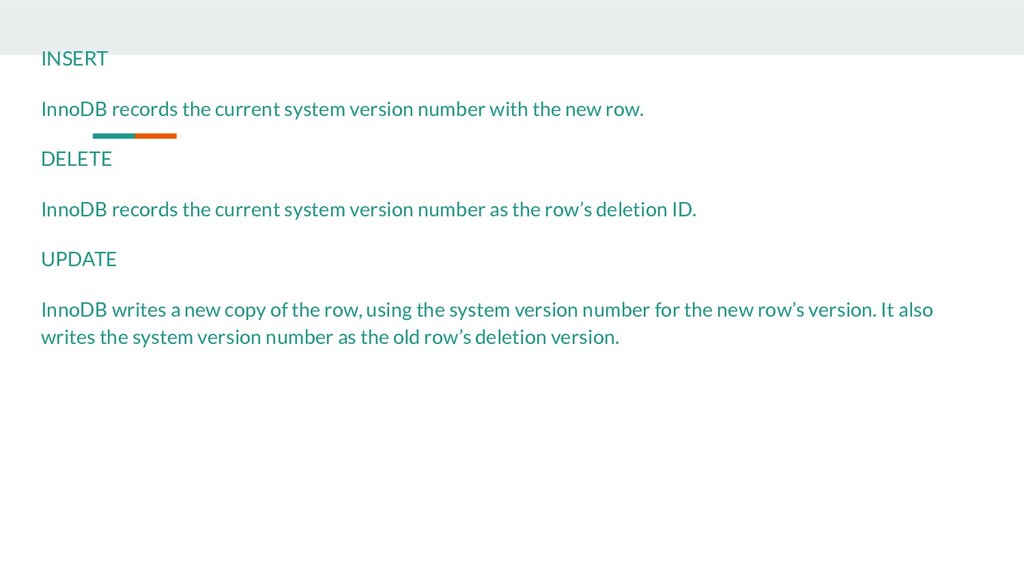
new row. DELETE InnoDB records the current system version number as the row’s deletion ID. UPDATE InnoDB writes a new copy of the row, using the system version number for the new row’s version. It also writes the system version number as the old row’s deletion version.
most read queries never acquire locks. They simply read data as fast as they can. The drawbacks are that the storage engine has to store more data with each row, do more work when examining rows, and handle some additional housekeeping operations. MVCC works only with the REPEATABLE READ and READ COMMITTED isolation levels. READ UNCOMMITTED isn’t MVCC-compatible because queries don’t read the row version that’s appropriate for their transaction version; they read the newest version, no matter what. SERIALIZABLE isn’t MVCC-compatible because reads lock every row they return.
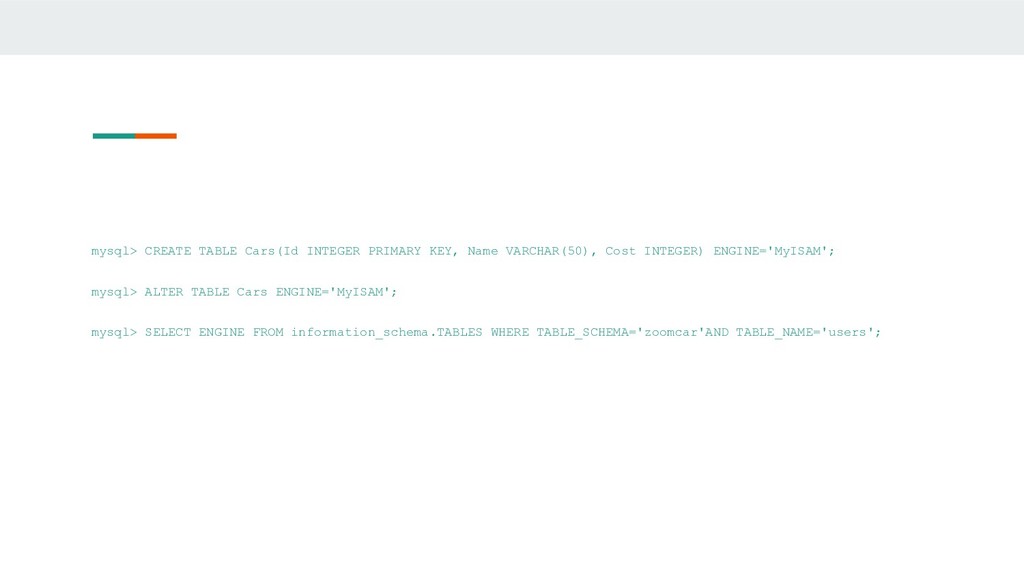
INTEGER) ENGINE='MyISAM'; mysql> ALTER TABLE Cars ENGINE='MyISAM'; mysql> SELECT ENGINE FROM information_schema.TABLES WHERE TABLE_SCHEMA='zoomcar'AND TABLE_NAME='users';
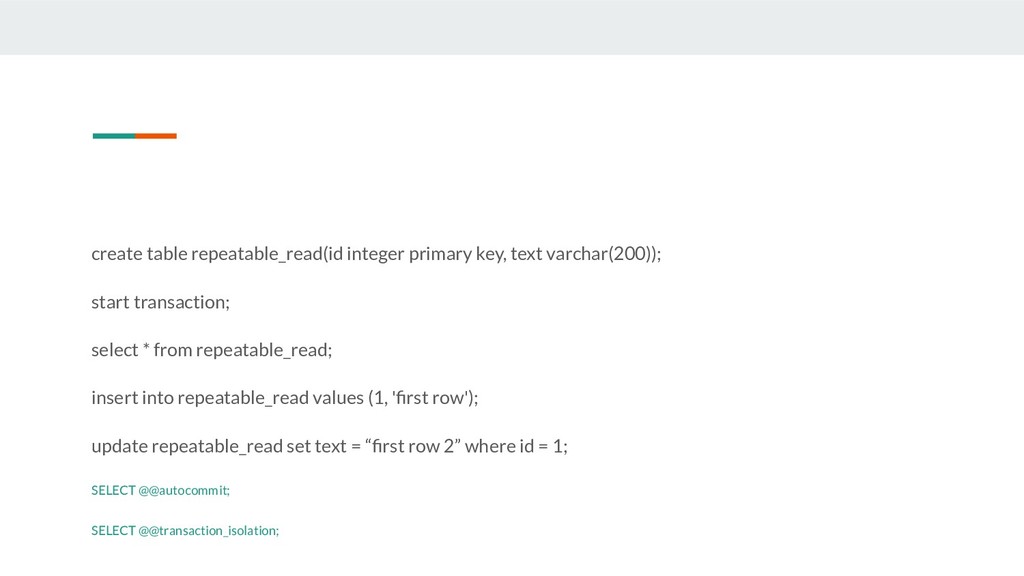
select * from repeatable_read; insert into repeatable_read values (1, 'first row'); update repeatable_read set text = “first row 2” where id = 1; SELECT @@autocommit; SELECT @@transaction_isolation;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}