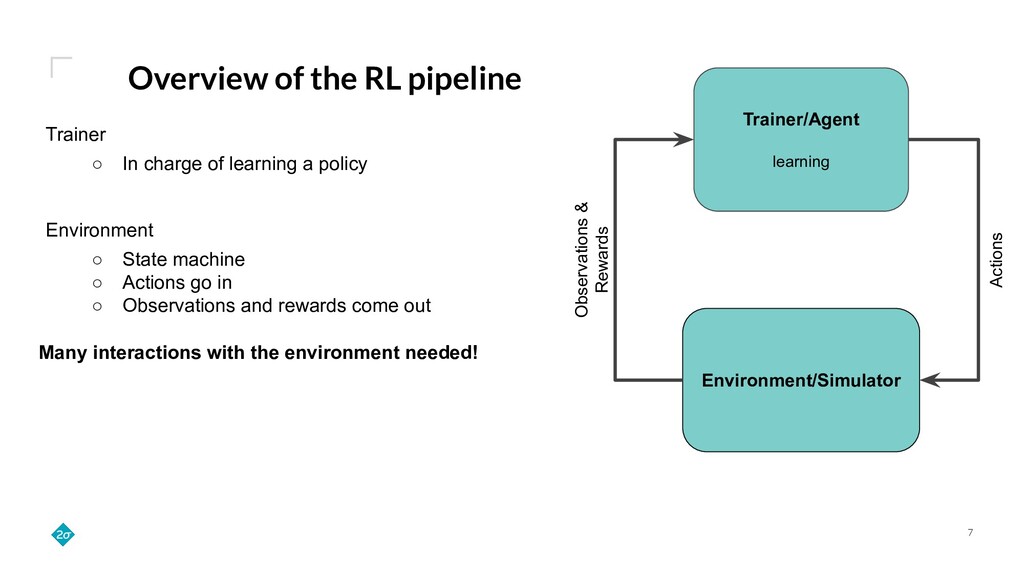
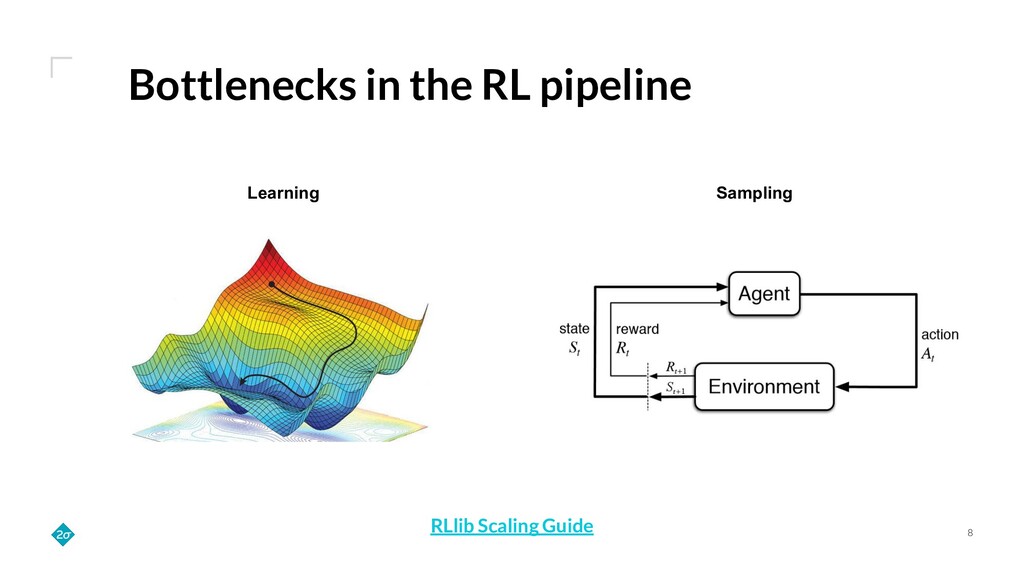
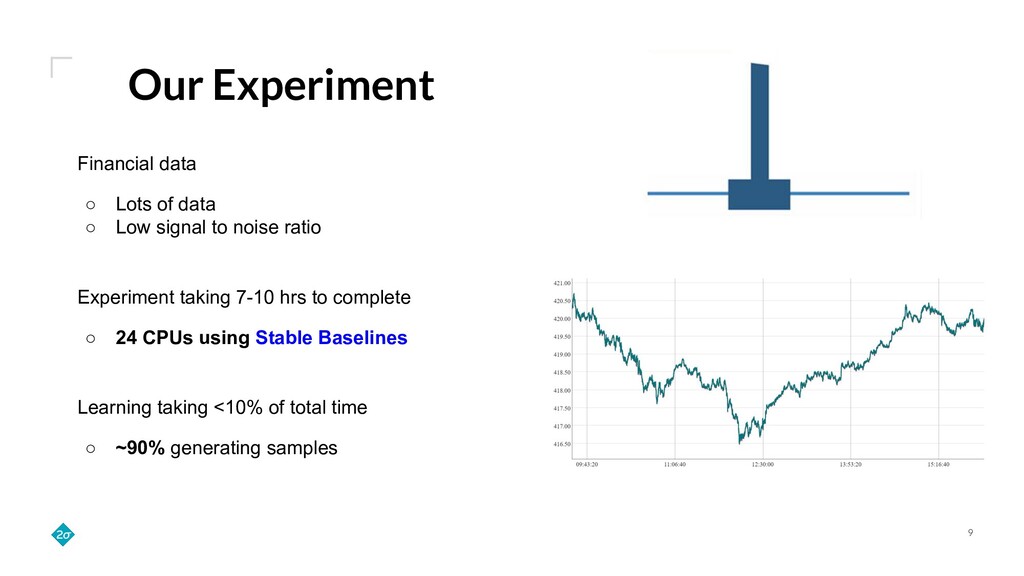
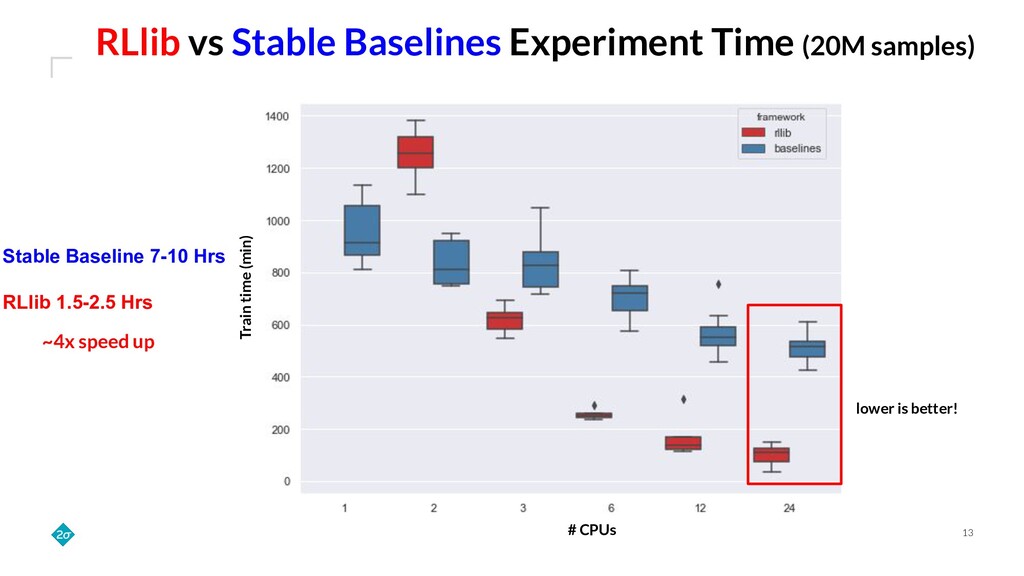
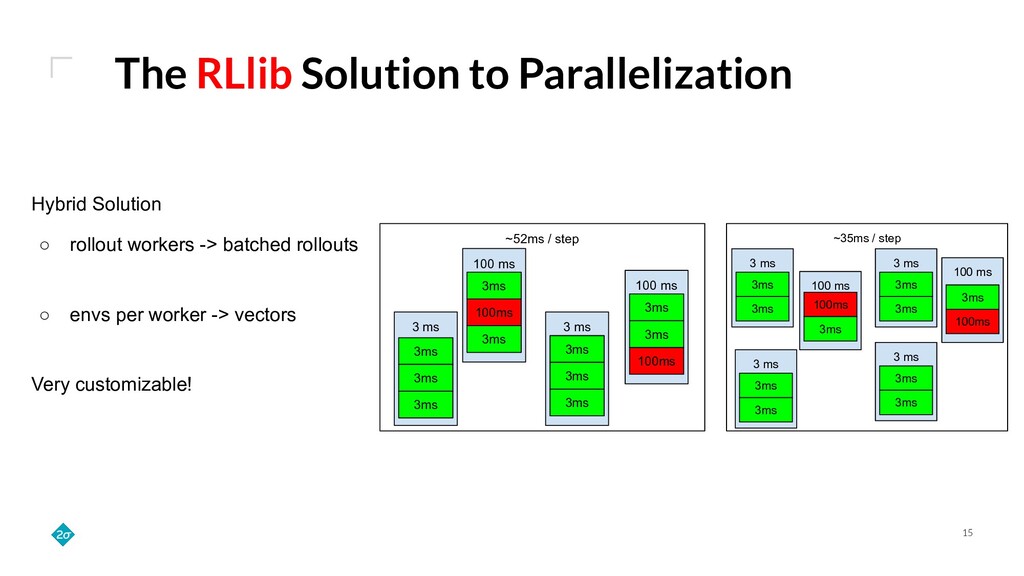
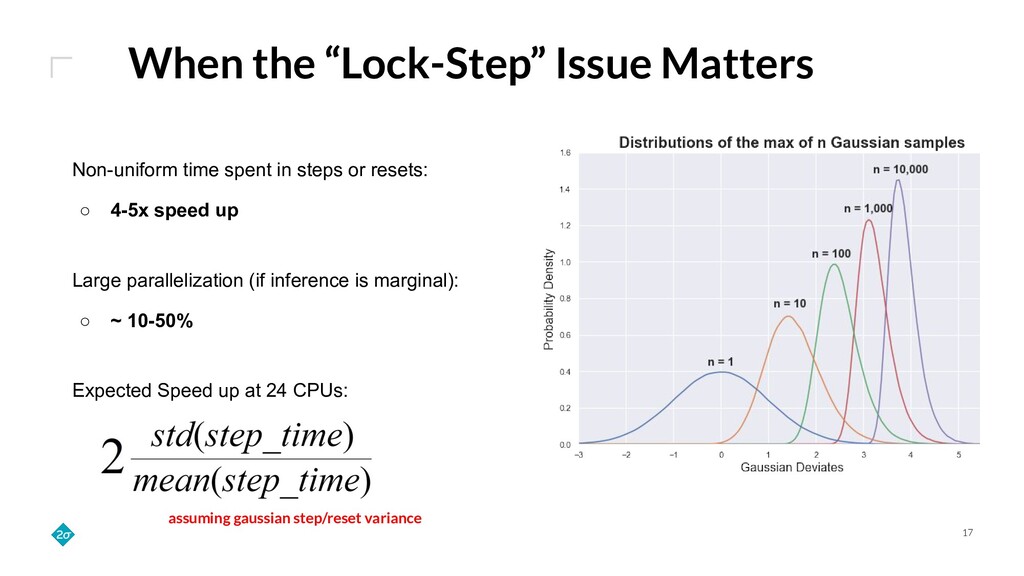
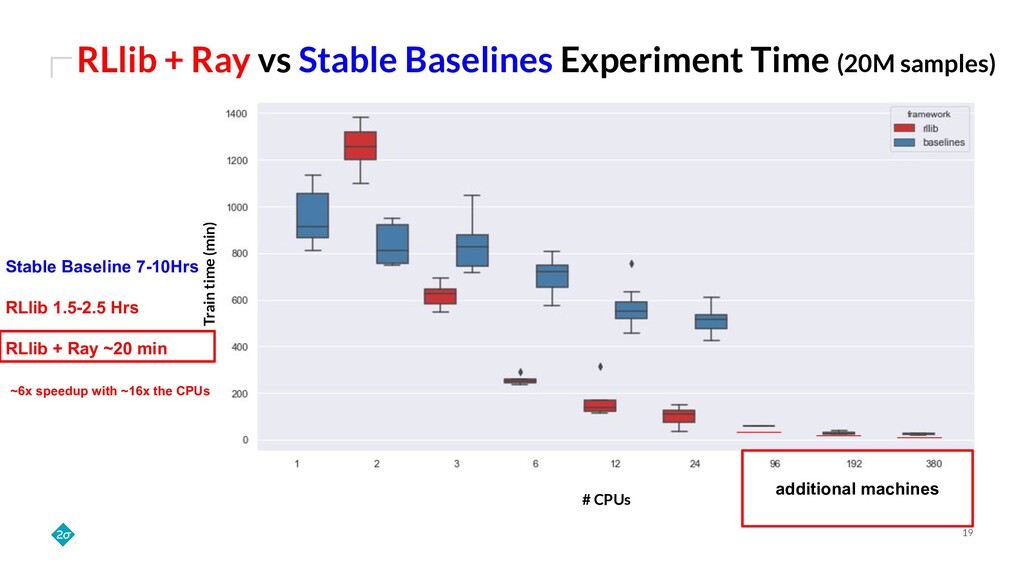
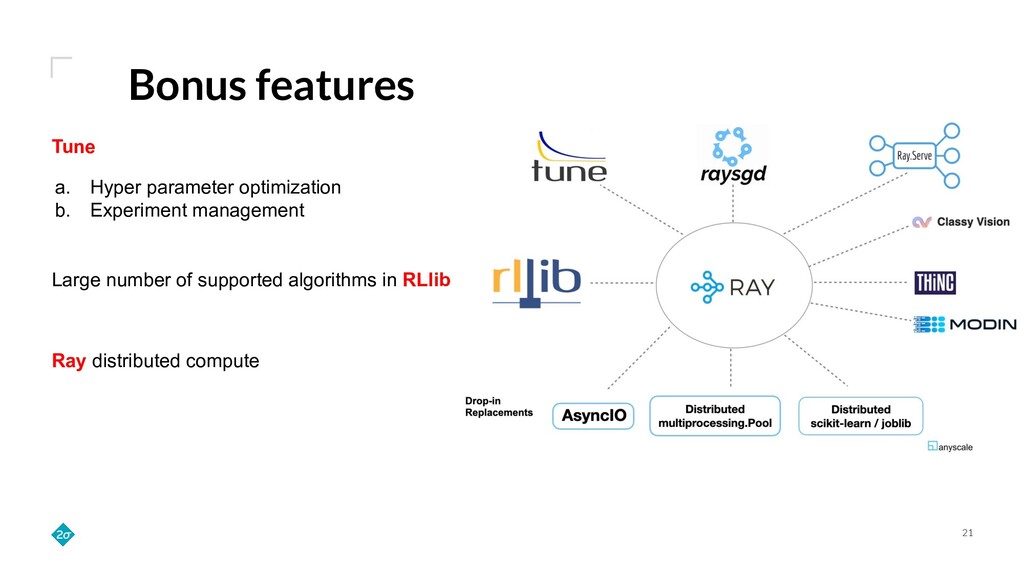
Training a reinforcement learning (RL) agent is compute intensive. Under classical deep learning assumptions bigger and better GPUs reduce training time. However, for RL, bigger and better GPUs do not always lead to reduced training time. In practice, RL can require millions of samples from a relatively slow and CPU-only environment leading to a bottleneck in training that GPUs do not solve. Empirically, we find that training agents with RLlib removes this bottleneck because its Ray integration allows scaling to many CPUs across a cluster of commodity machines. This talk details how such scaling can cut training wall-time down by orders of magnitude.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}