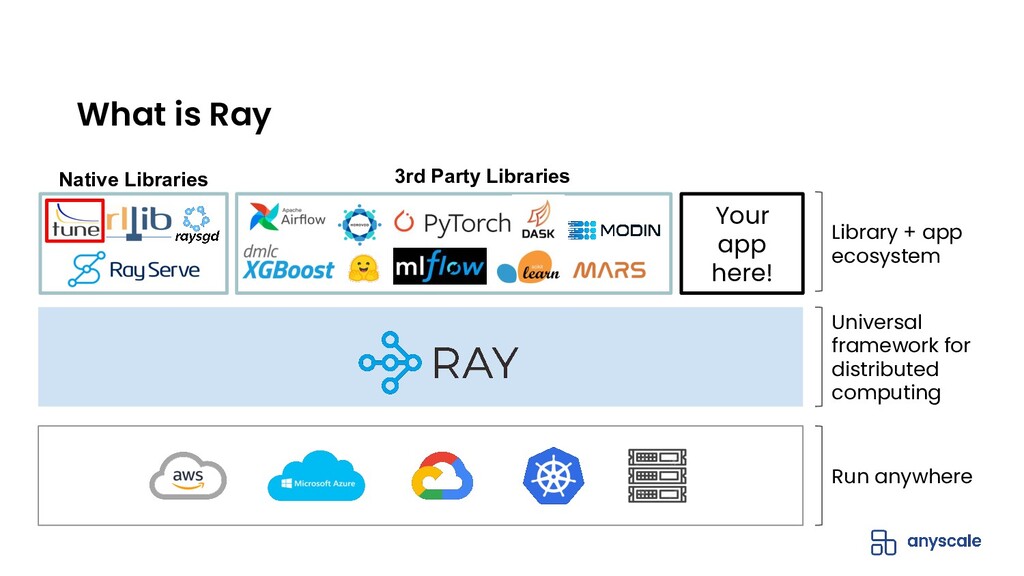
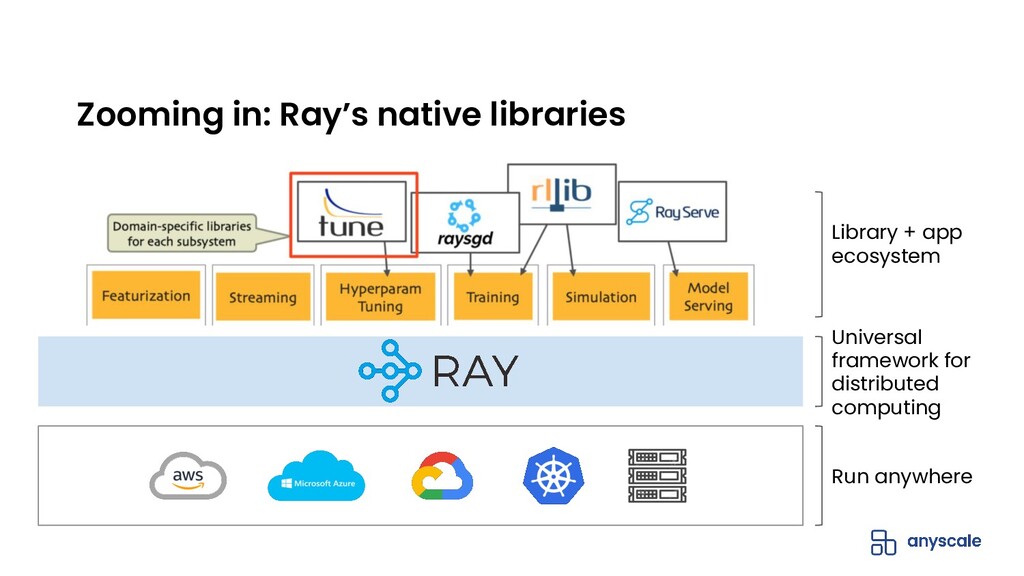
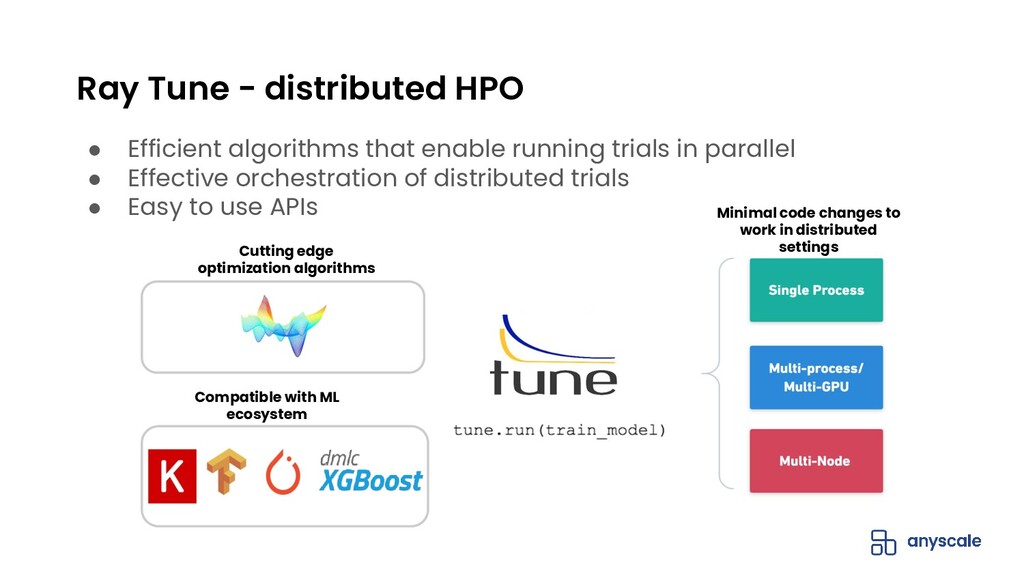
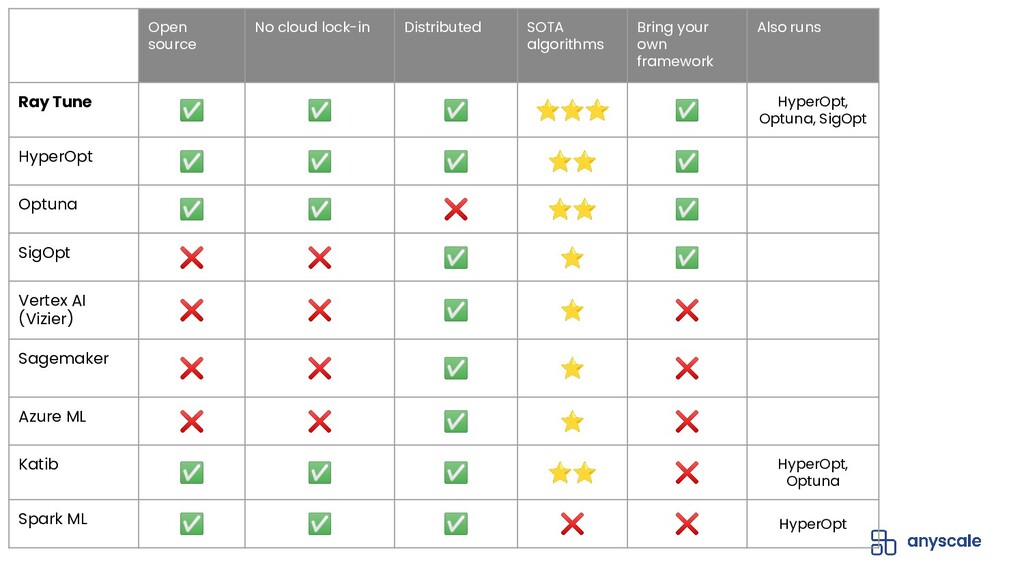
Hyperparameter tuning or optimization is used to find the best performing machine learning (ML) model by exploring and optimizing the model hyperparameters (eg. learning rate, tree depth, etc). It is a compute-intensive problem that lends itself well to distributed execution.
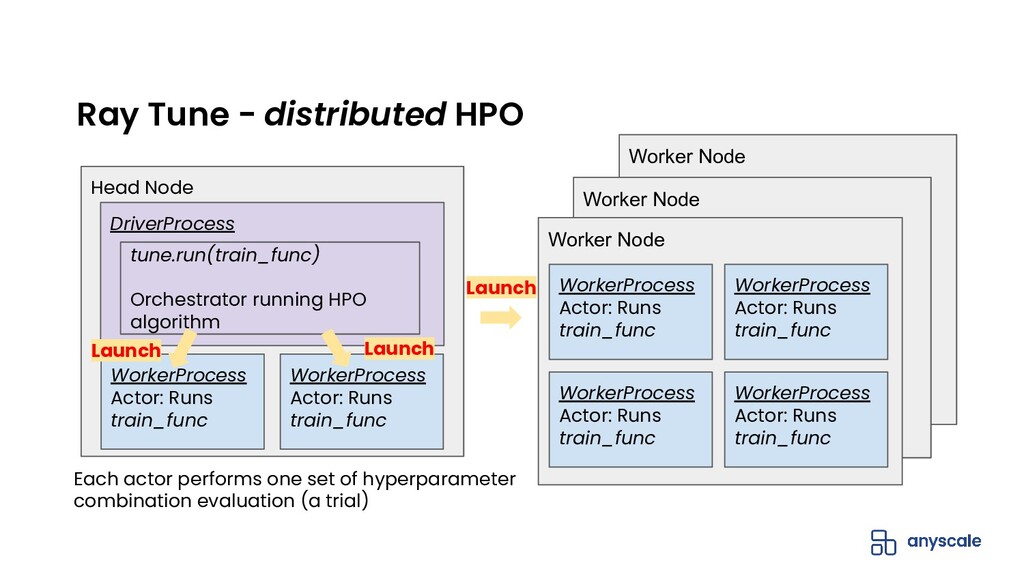
Ray Tune is a Python library, built on Ray, that allows you to easily run distributed hyperparameter tuning at scale. Ray Tune is framework-agnostic and supports all the popular training frameworks including PyTorch, TensorFlow, XGBoost, LightGBM, and Keras.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [2012] Random search • [2015] Successive Halving Algorithm (SHA)](https://files.speakerdeck.com/presentations/9f6868177b0247479362d48739a89686/slide_17.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
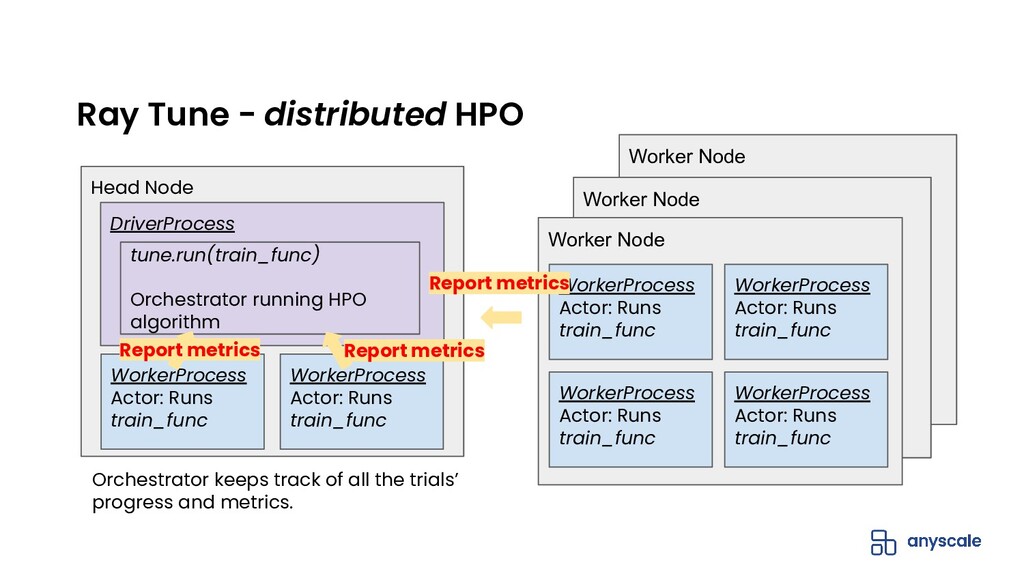{kind=link}
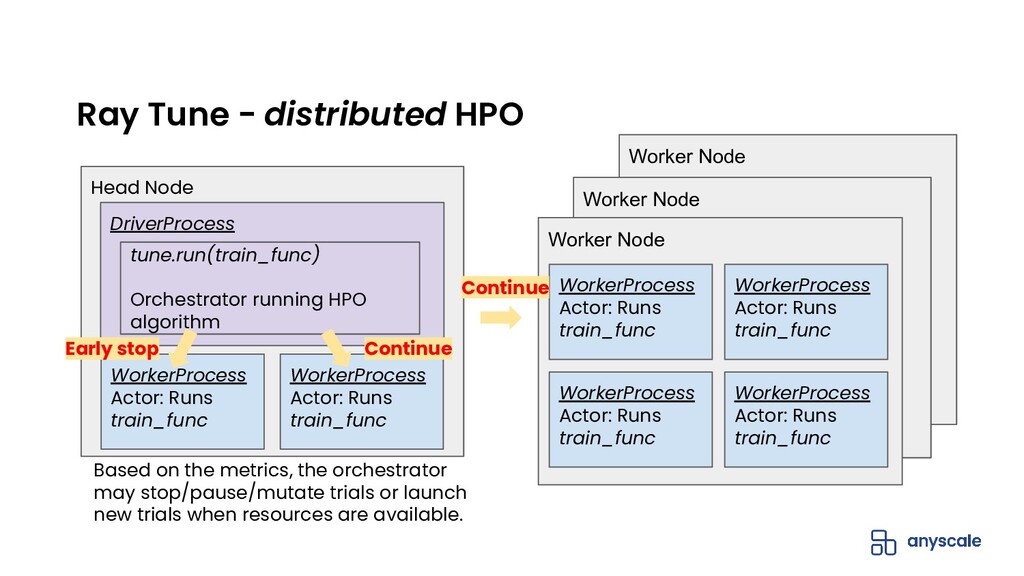{kind=link}
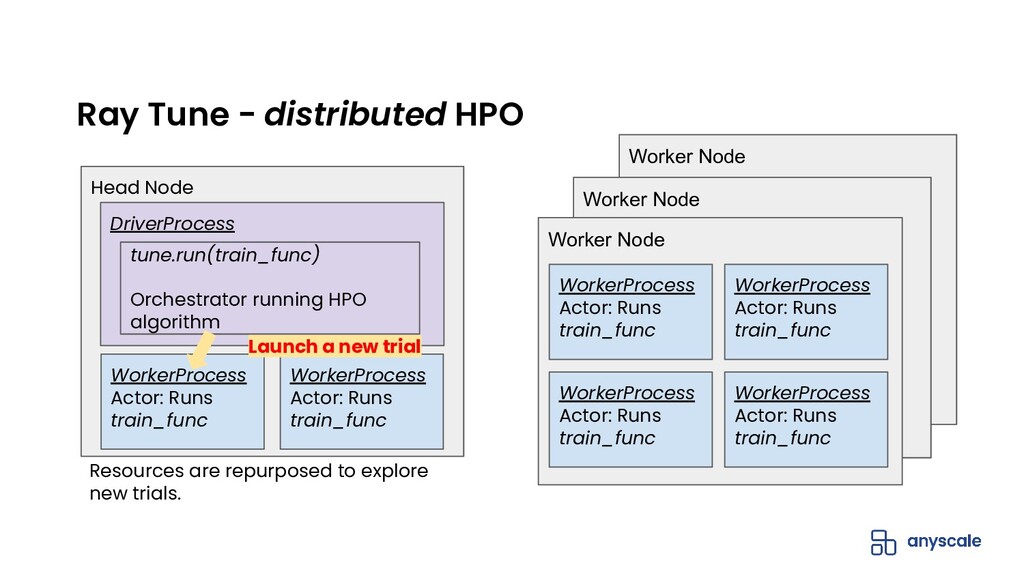{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
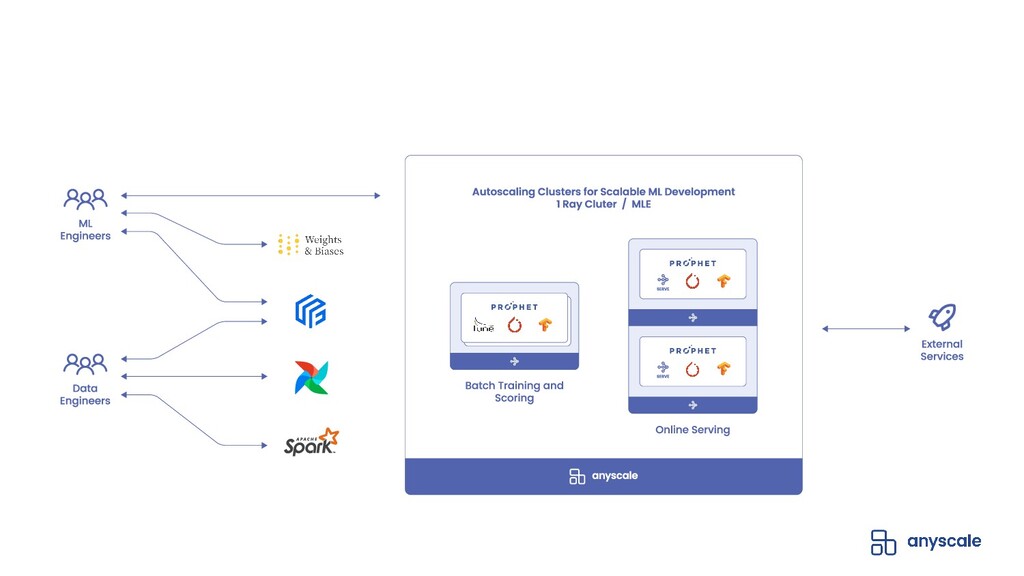{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
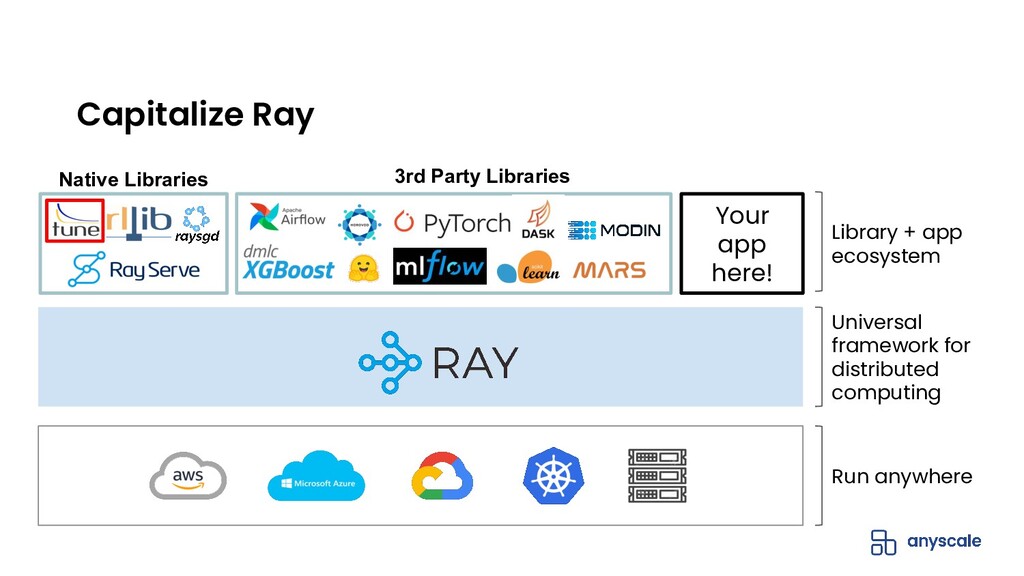{kind=link}
{kind=link}
{kind=link}