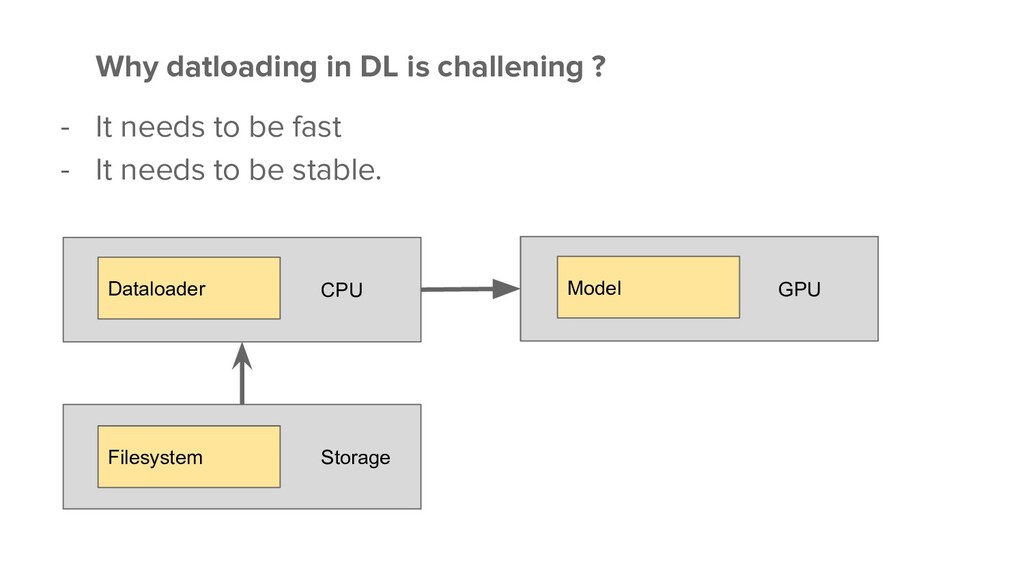
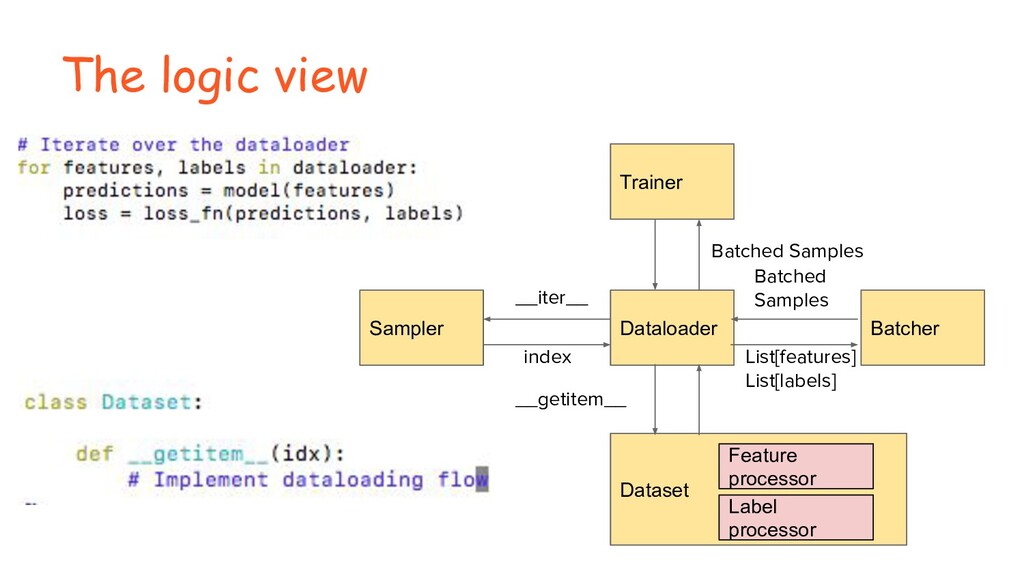
Data loading is one of the most crucial steps in the DL pipeline. It needs to be designed and implemented in both a flexible and performant manner so that (1) it can be reused to support different DNN models, (2) it can match the speed of GPU compute, and (3) it can scale to multi-cores and even multi-nodes. However, achieving these design goals is not trivial, especially given that the most commonly used language in DL is python in which there is no good support for parallel programming.
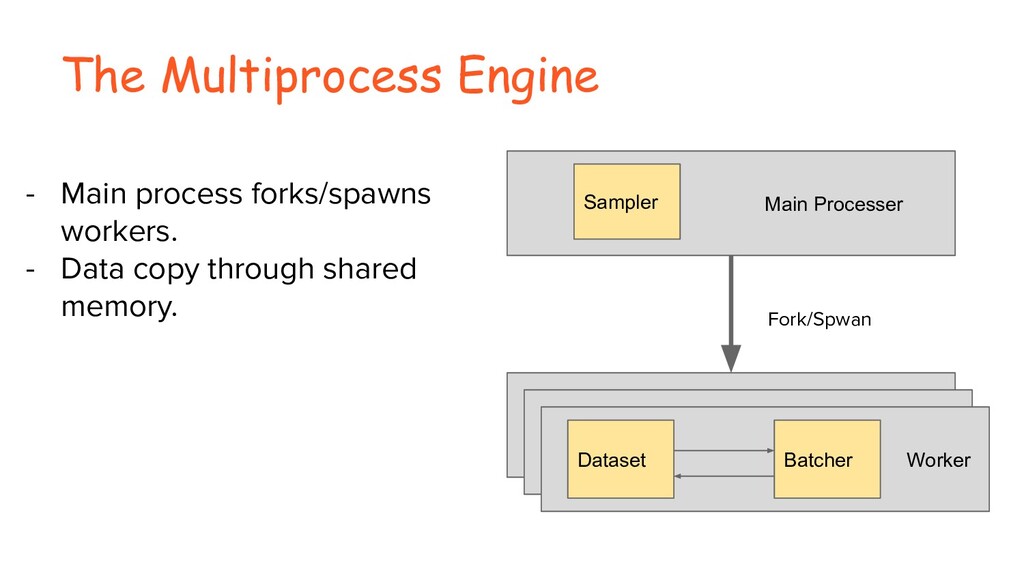
In this talk, we will show that how we can use Ray to implement our data loading pipeline. Powered by the Ray actor, we are able to reuse most of our python modules and run our data loading pipeline in parallel without worrying about the overhead of managing it at scale. We will also talk about the experience and lessons we learned during our implementation and production depoyment.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}