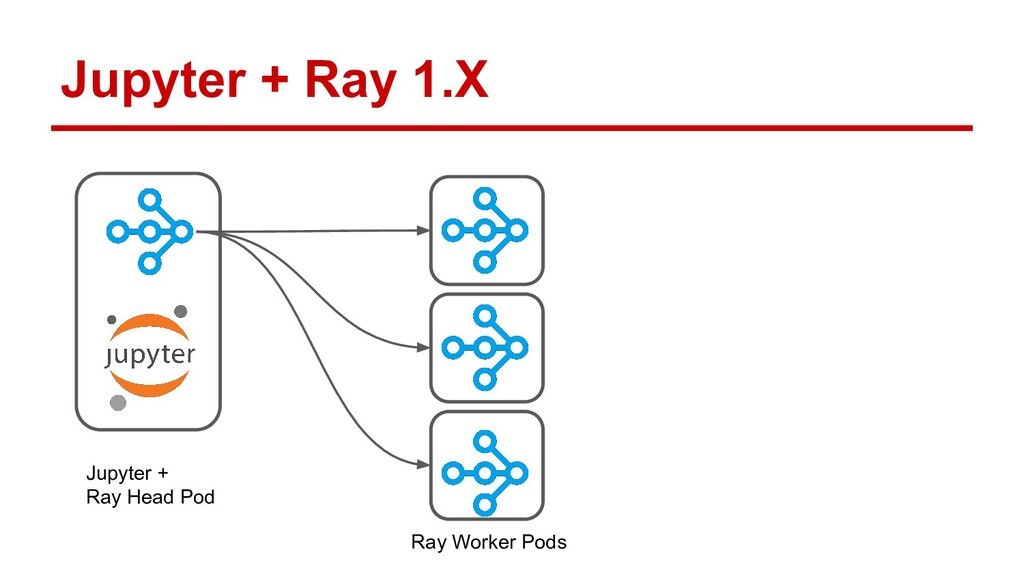
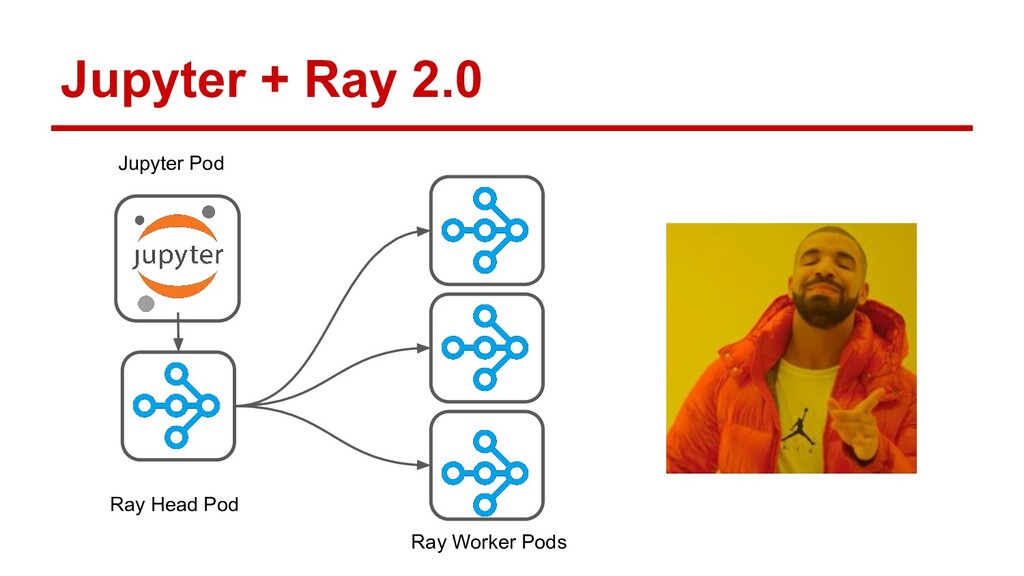
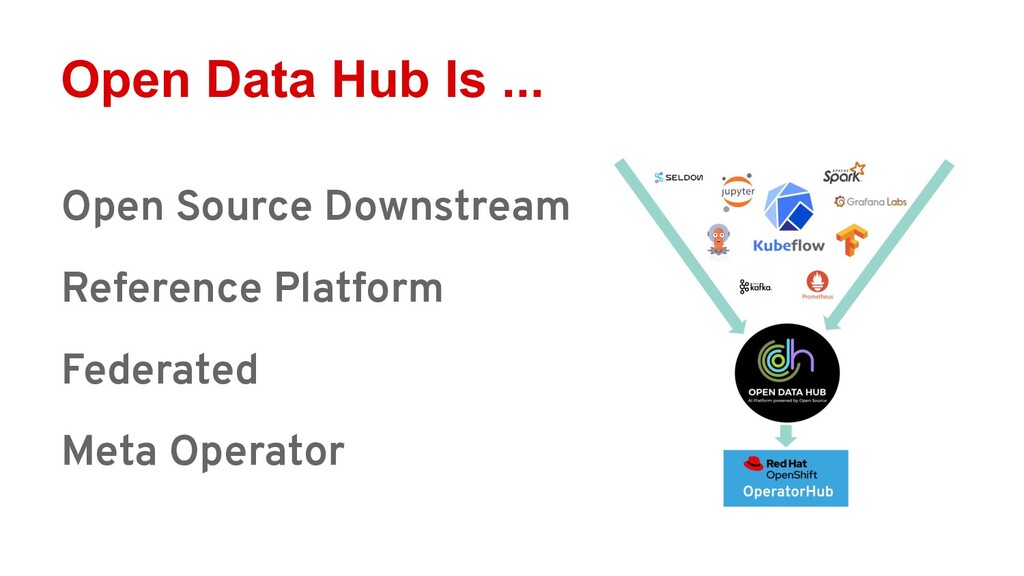
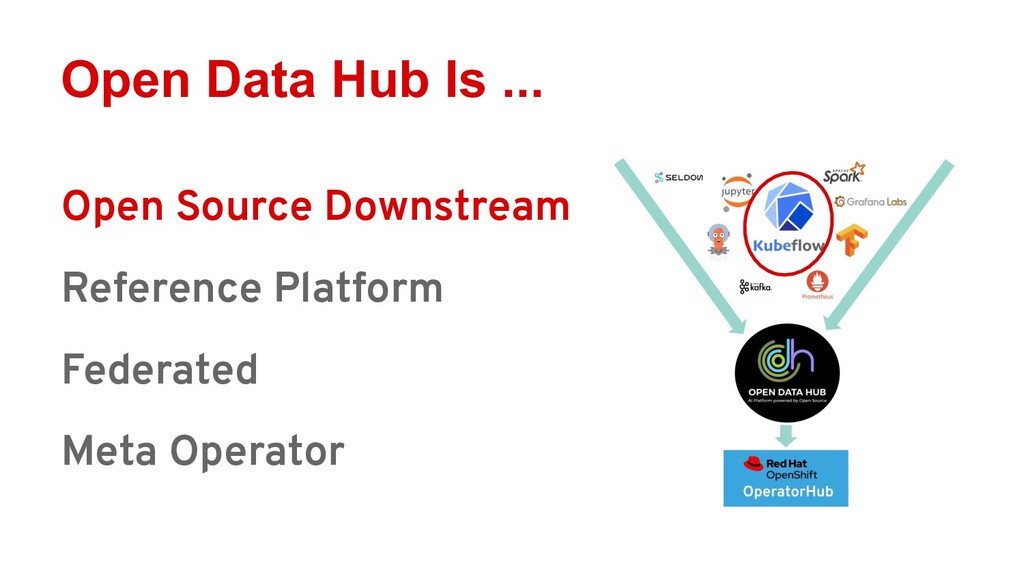
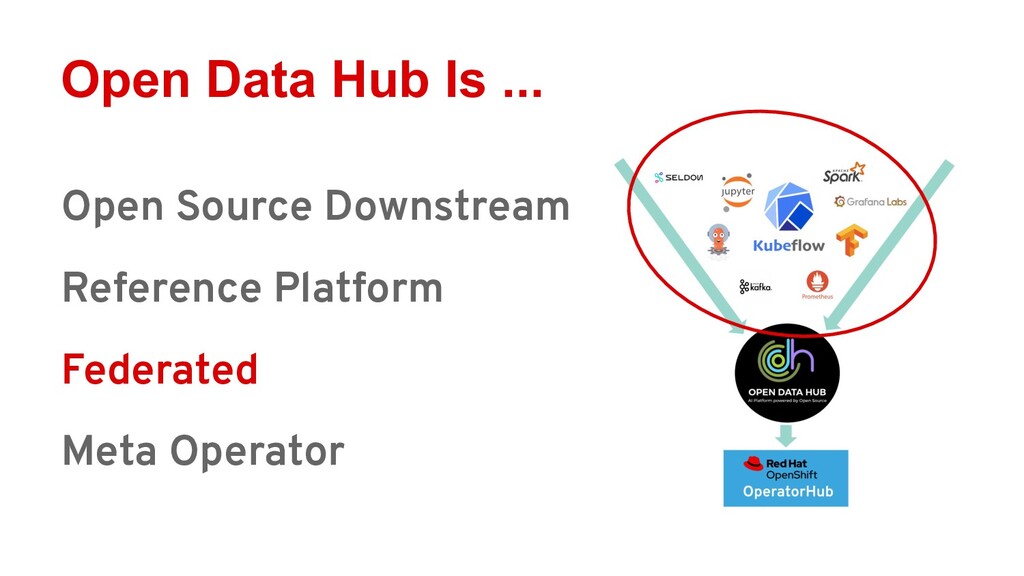
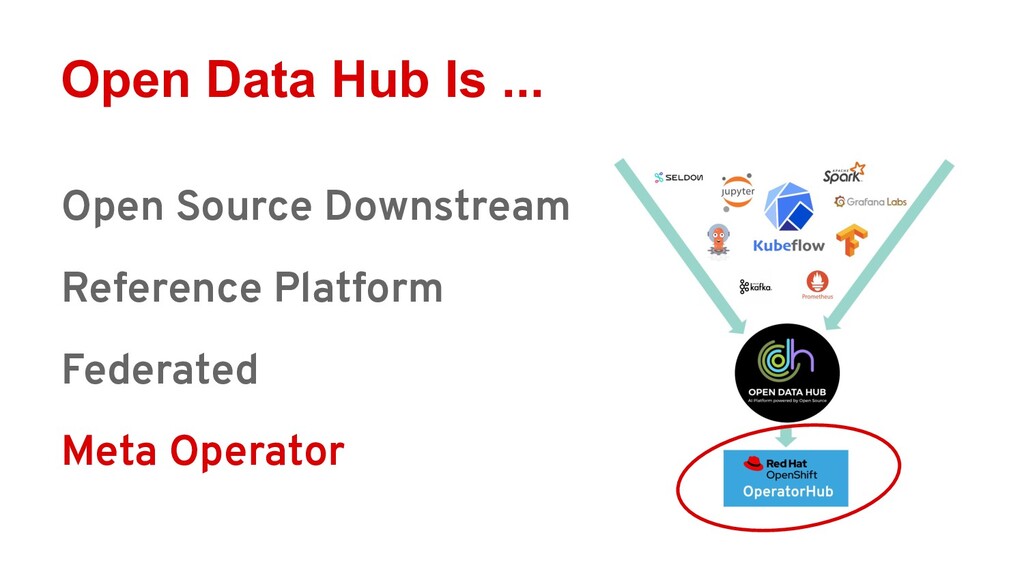
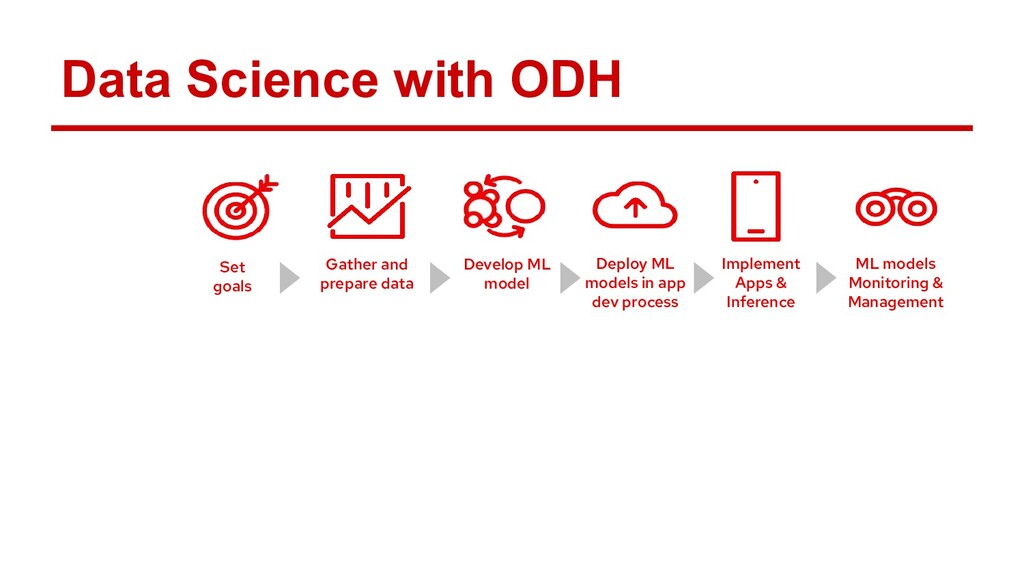
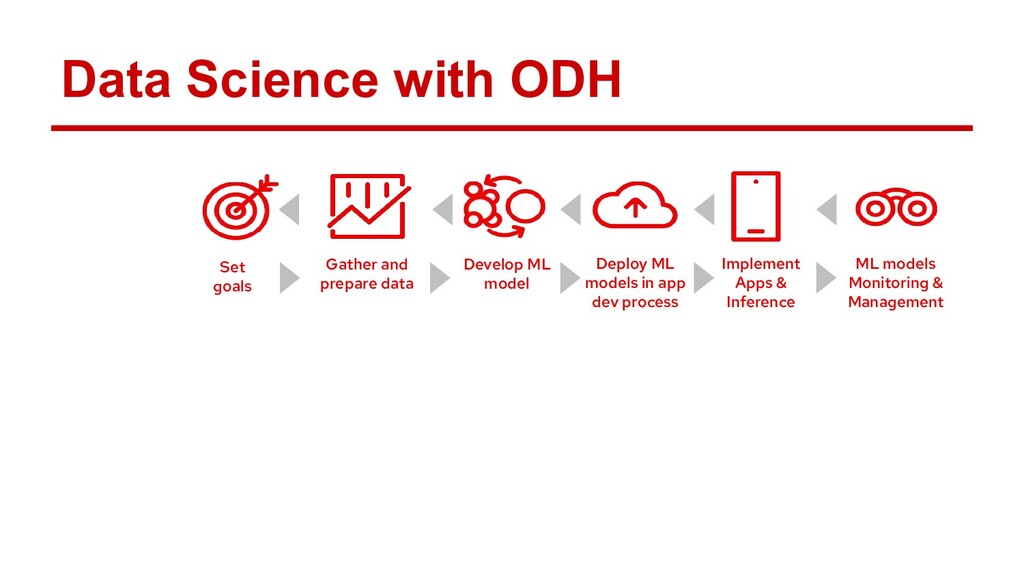
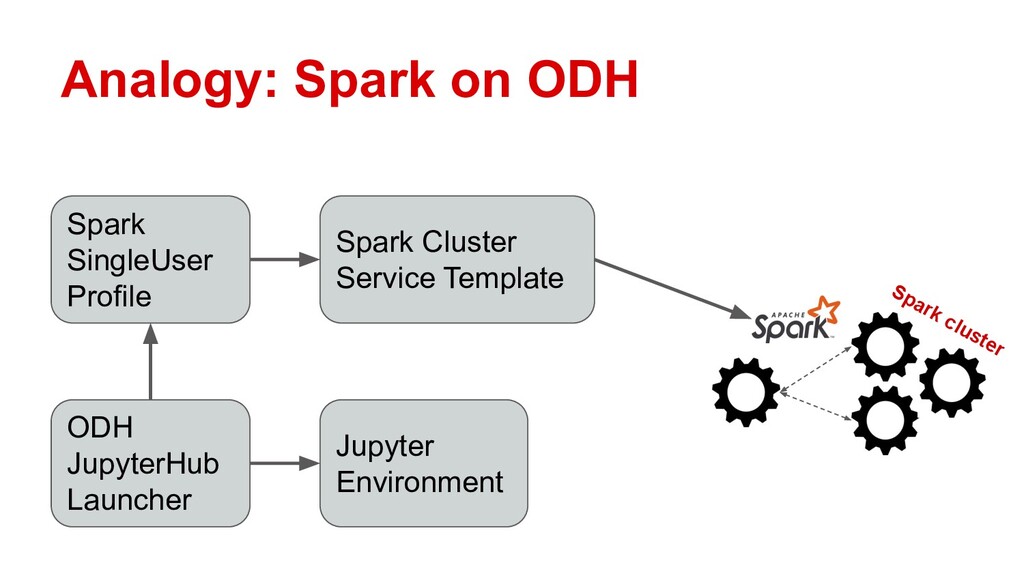
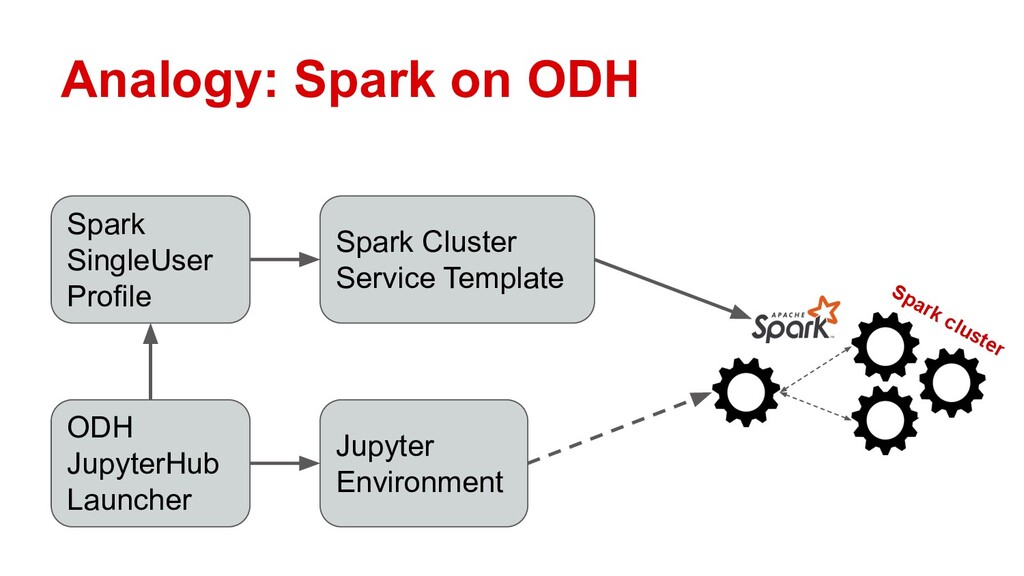
Ray is quickly gaining momentum as a distributed computing platform that combines a powerful parallel compute model with a cloud native serverless-style scaling model. Open Data Hub (ODH) is a flexible and customizable federation of open source data science tools that is a great fit for taking advantage of Ray compute clusters.
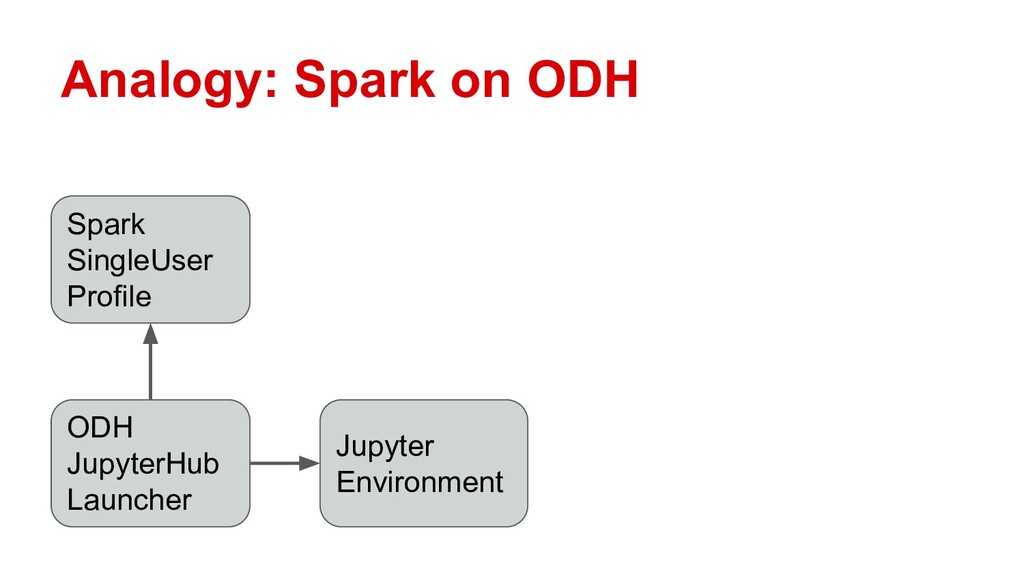
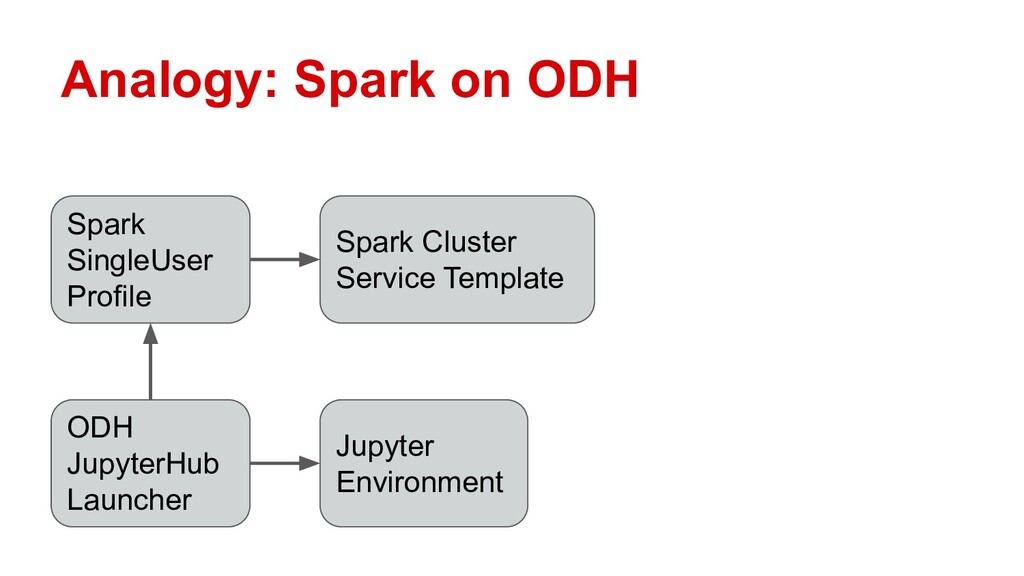
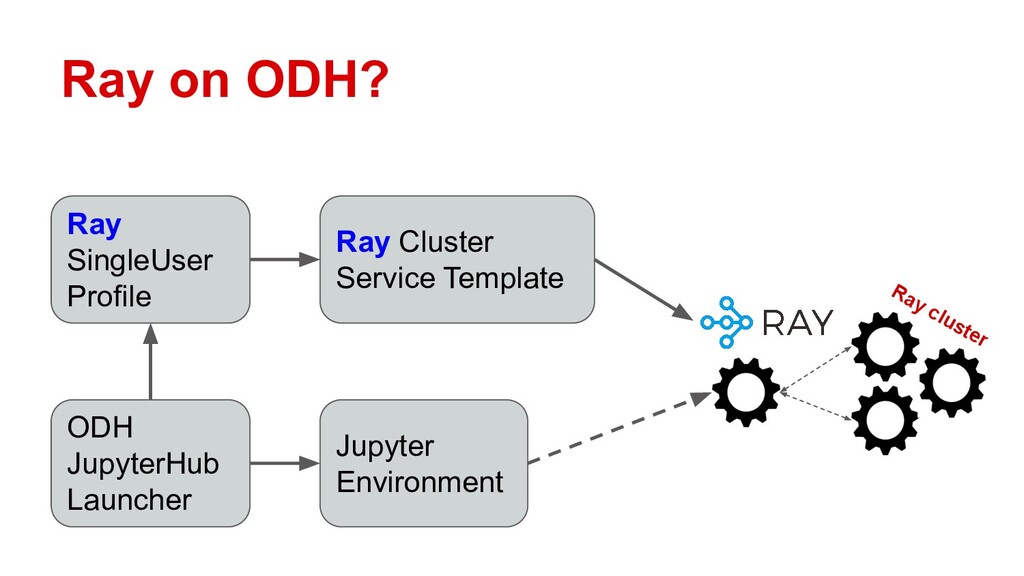
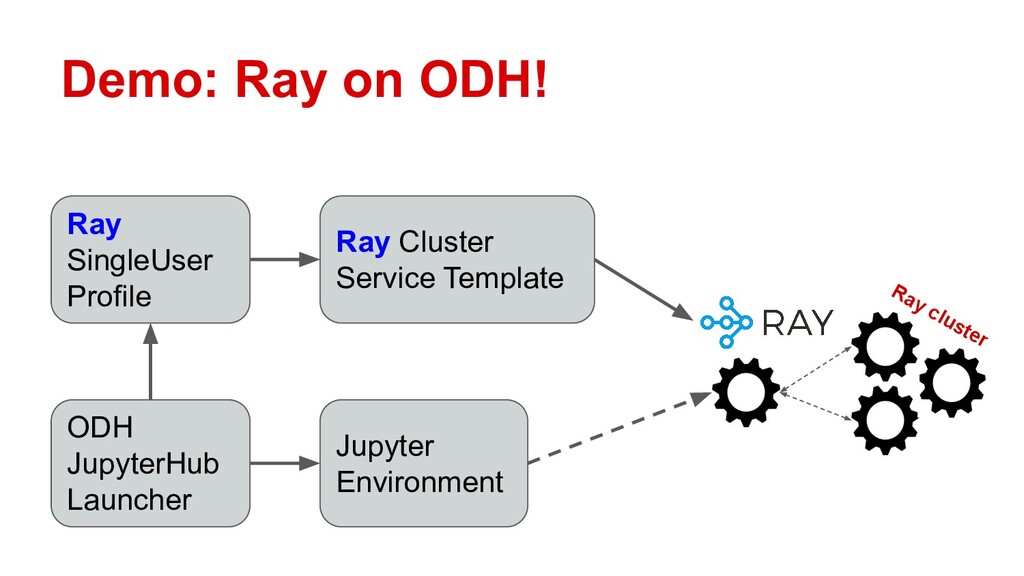
In this talk, Erik will explain how to integrate Ray with Open Data Hub, by configuring ODH profiles that deploy on-demand Ray clusters for Jupyter notebooks. He’ll demonstrate Ray in action as a compute resource for ODH, and explore the potential use cases opened up by self-service notebooks backed by Ray. Along the way he’ll also discuss the logistics of adapting Ray to OpenShift’s security features.
Attendees will learn how Ray integrates with Open Data Hub’s architecture, and how they can power ODH with Ray to solve distributed computing problems in the popular Jupyter environment.
![Powering ODH With Ray Erik Erlandson, Red Hat, Inc. [email protected]](https://files.speakerdeck.com/presentations/5beb1f85bb374863b3e5e6d9807ef892/slide_0.jpg){kind=link}
![Or... Erik Erlandson, Red Hat, Inc. [email protected] @ManyAngled](https://files.speakerdeck.com/presentations/5beb1f85bb374863b3e5e6d9807ef892/slide_1.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}