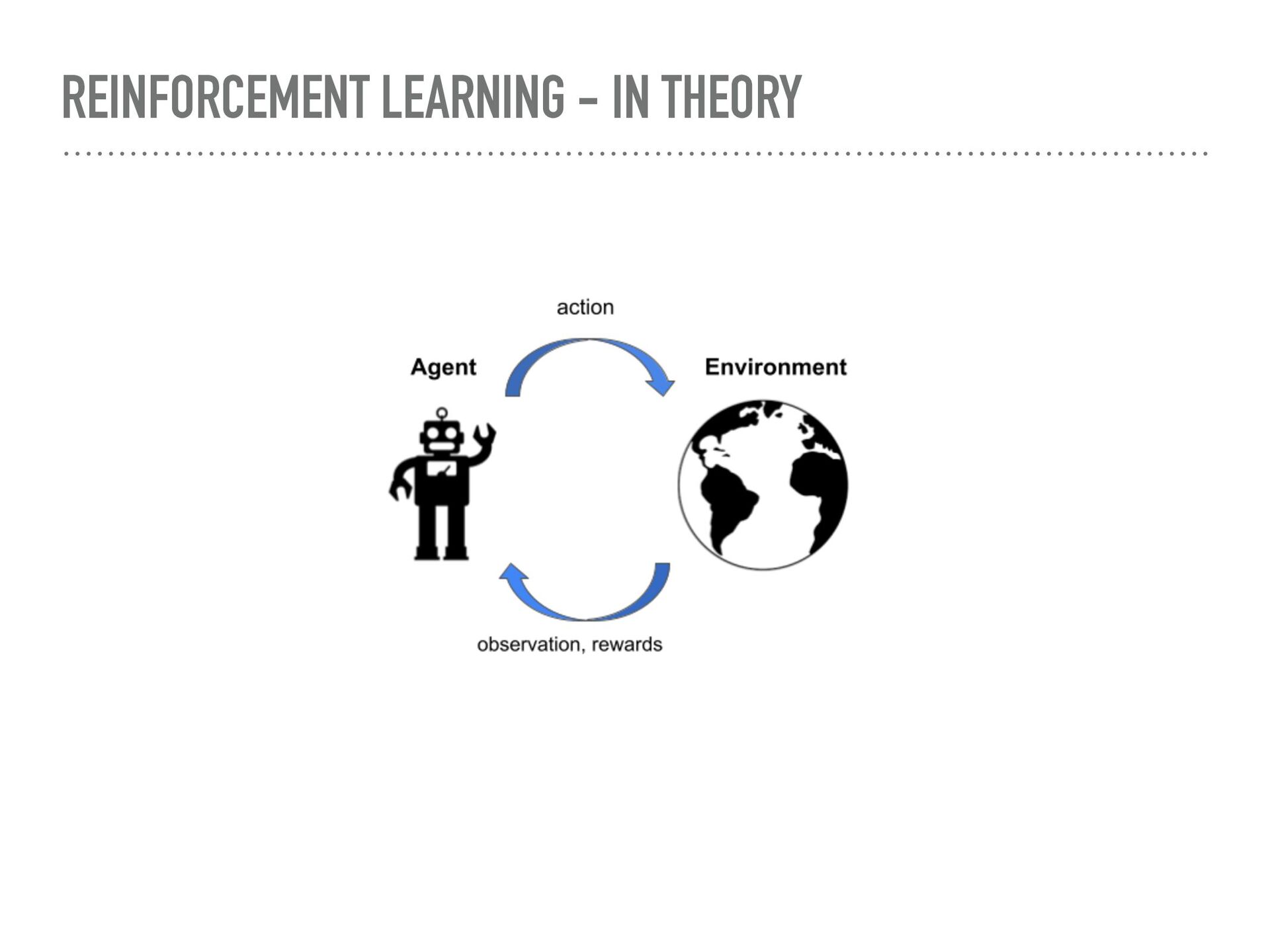
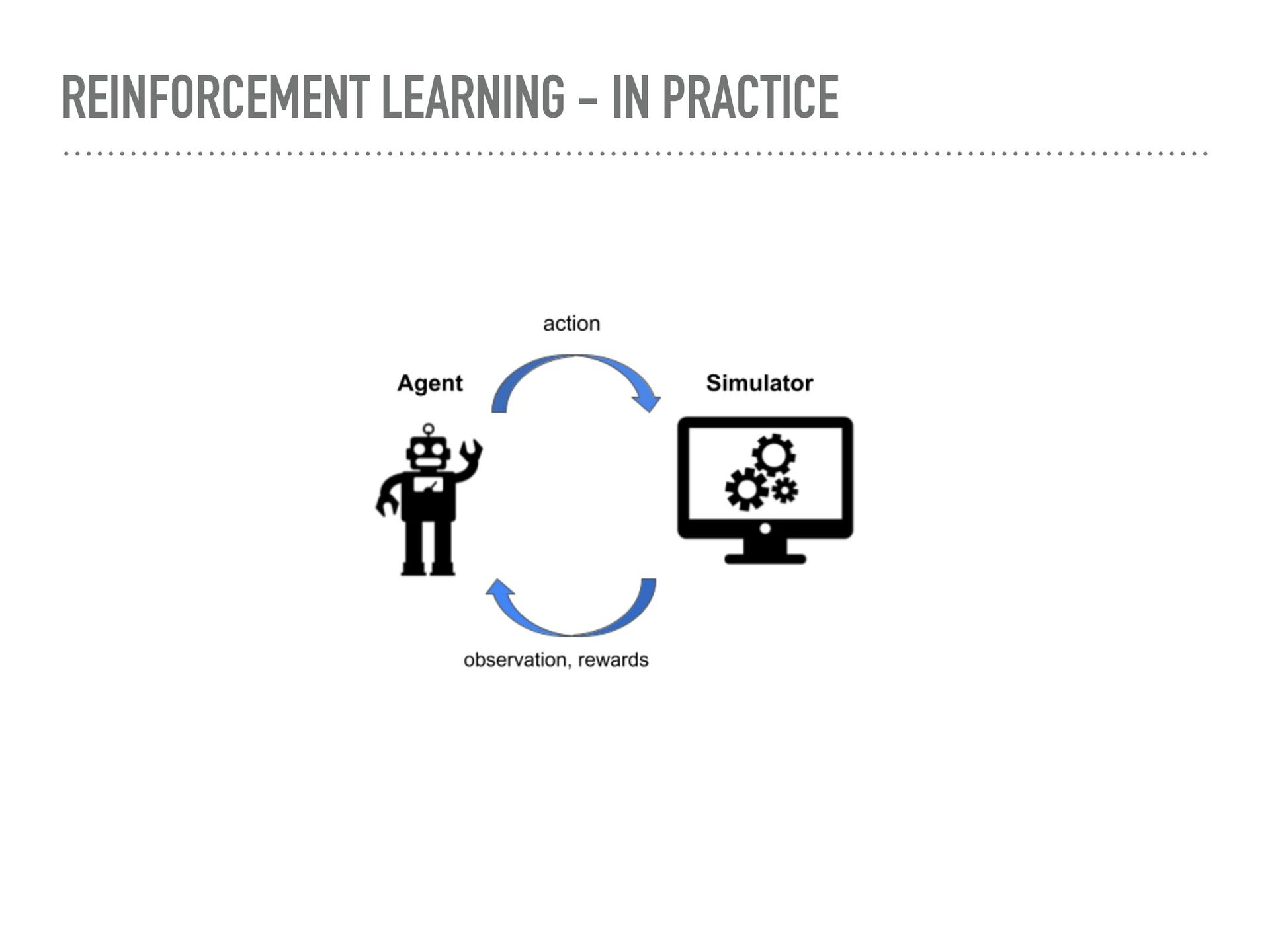
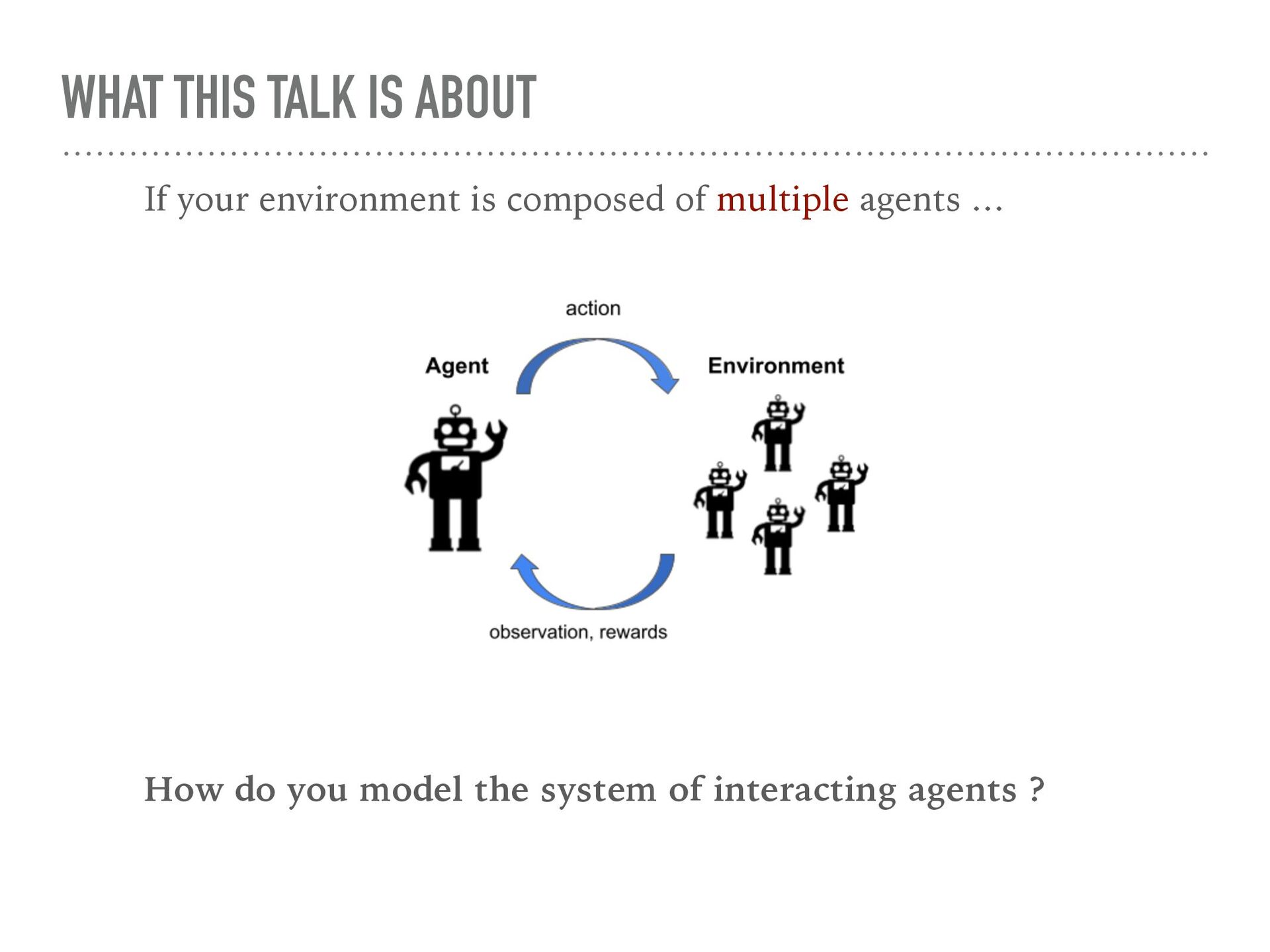
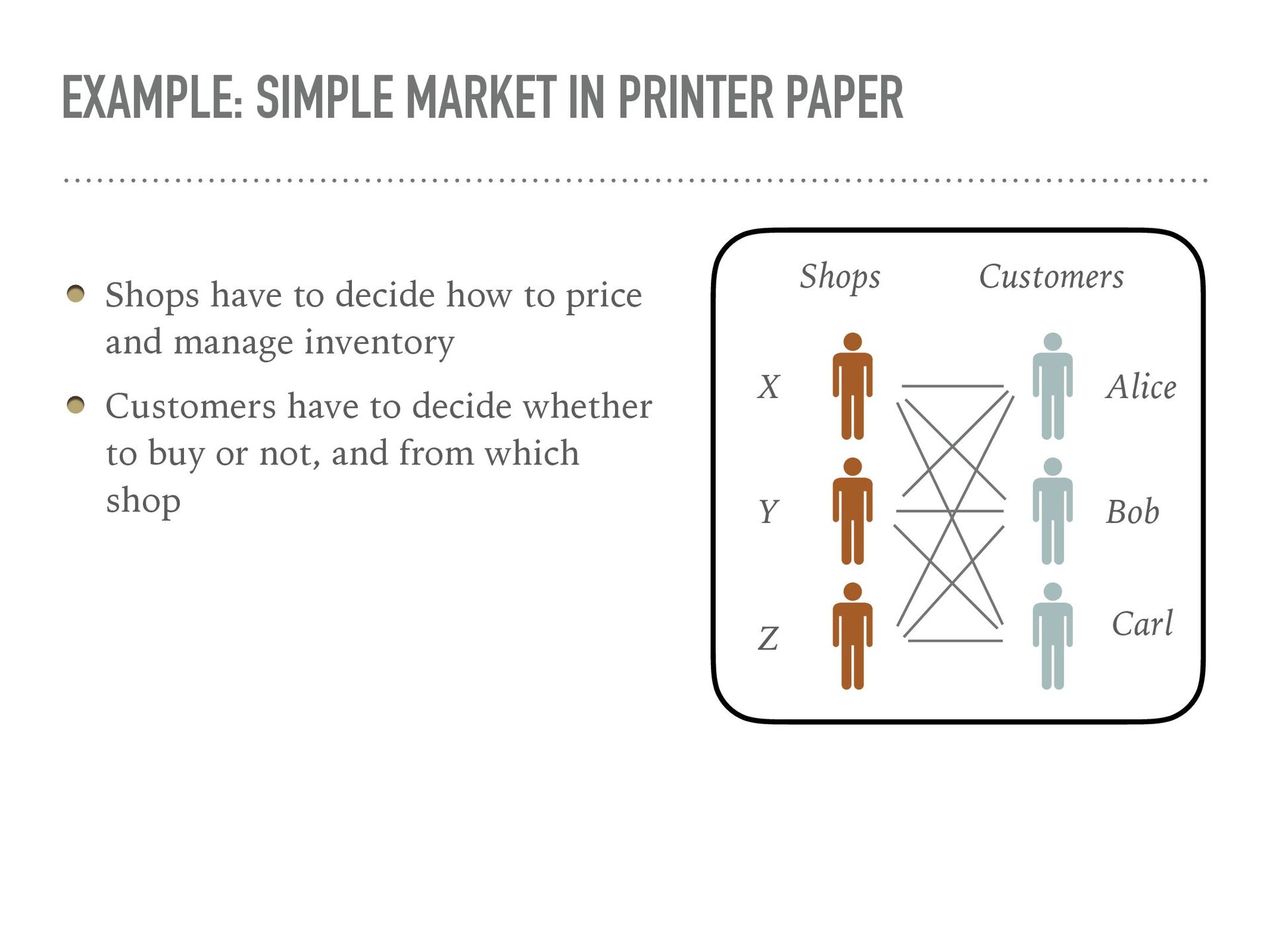
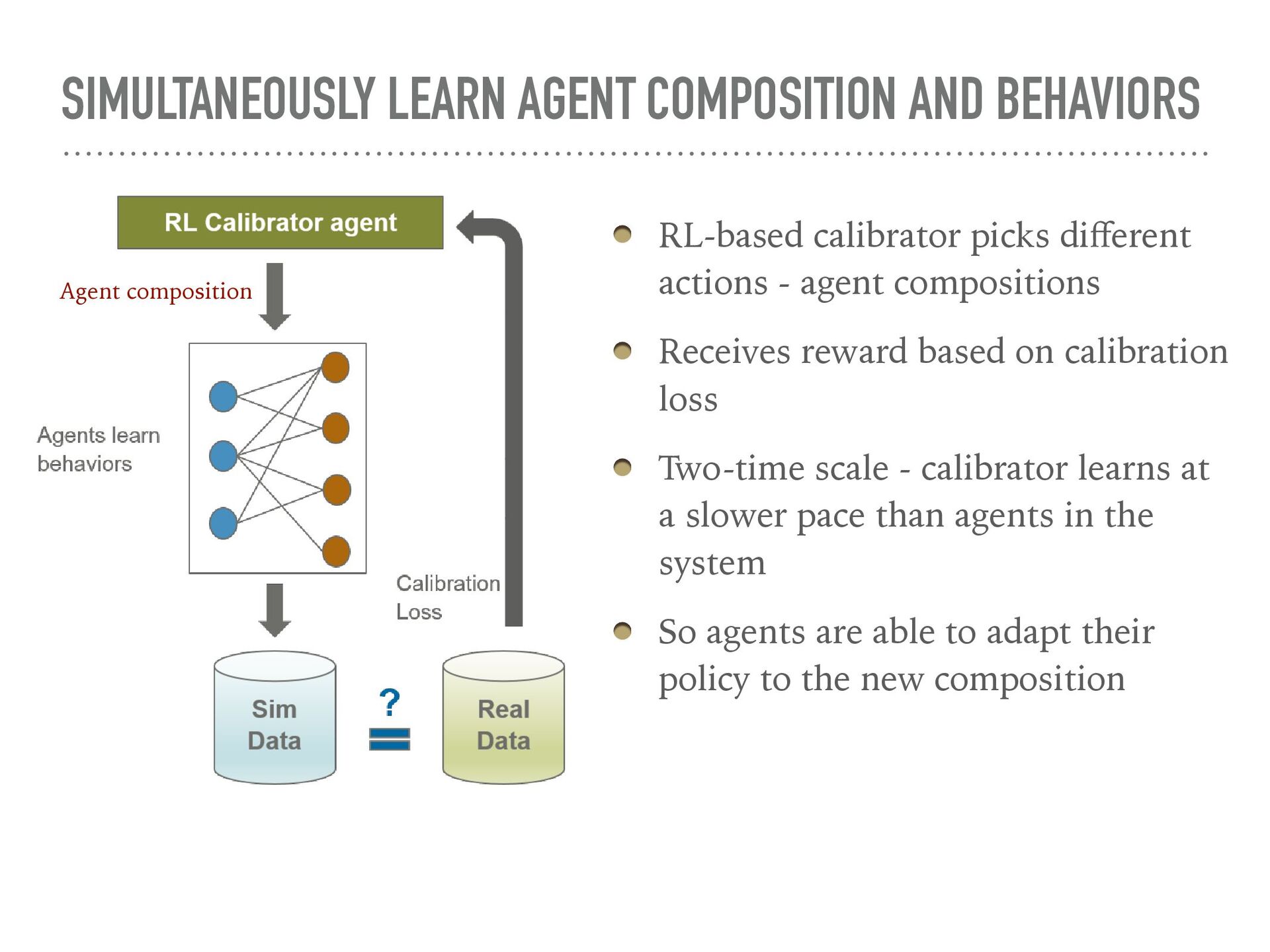
Agent-based simulation of markets provides a useful tool for policy optimization, counterfactual analysis, and market mechanism design. In this talk, we will present our work in modeling complex economic systems as a network of heterogeneous, utility maximizing agents with partial observability. We demonstrate how reinforcement learning (RL) can be used to solve two primary challenges in agent-based modeling — finding the equilibrium with multiple strategic agents and calibrating the model using real data. These techniques have been useful in enabling the practical application of agent-based modeling.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
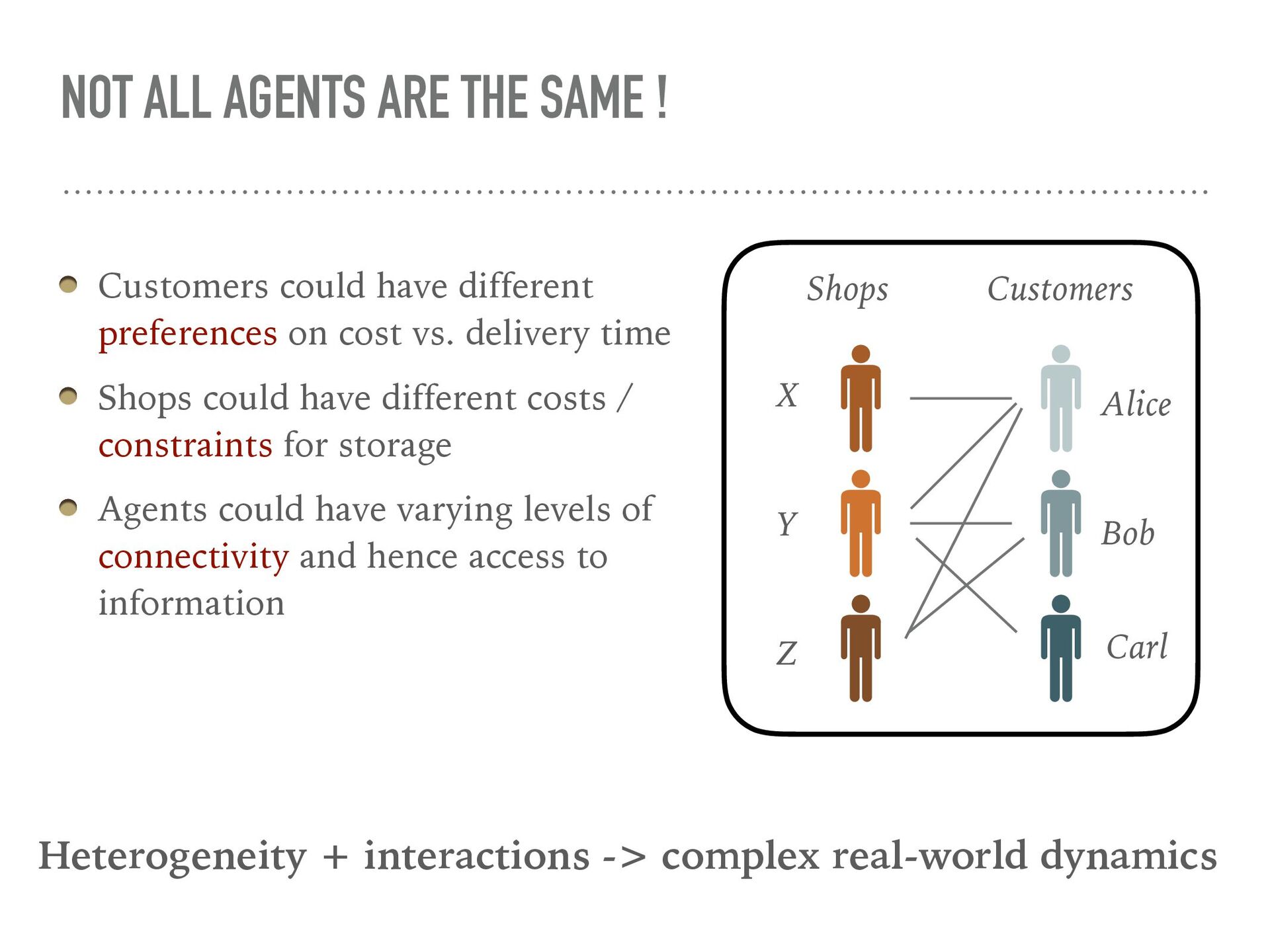{kind=link}
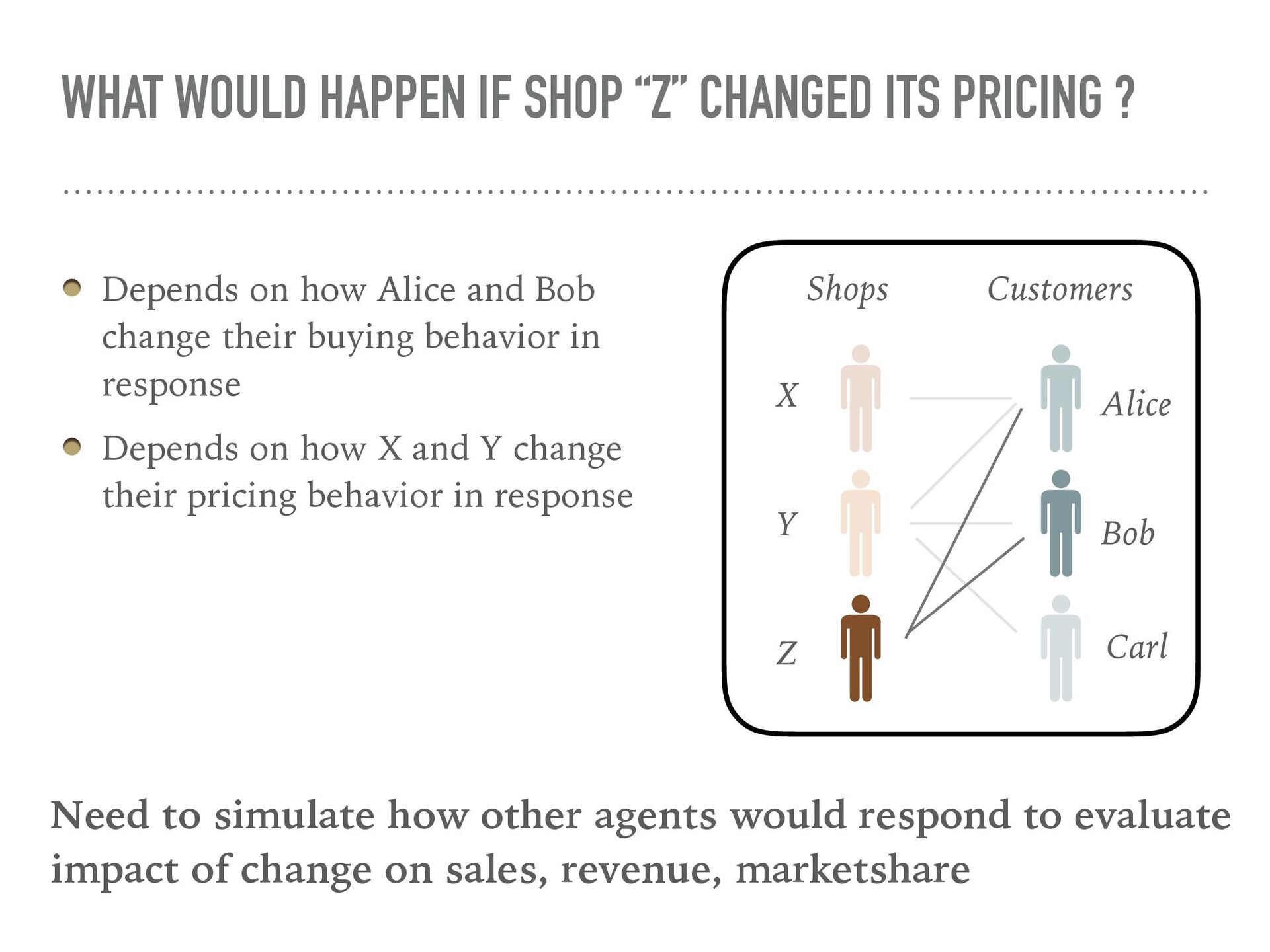{kind=link}
{kind=link}
{kind=link}
{kind=link}
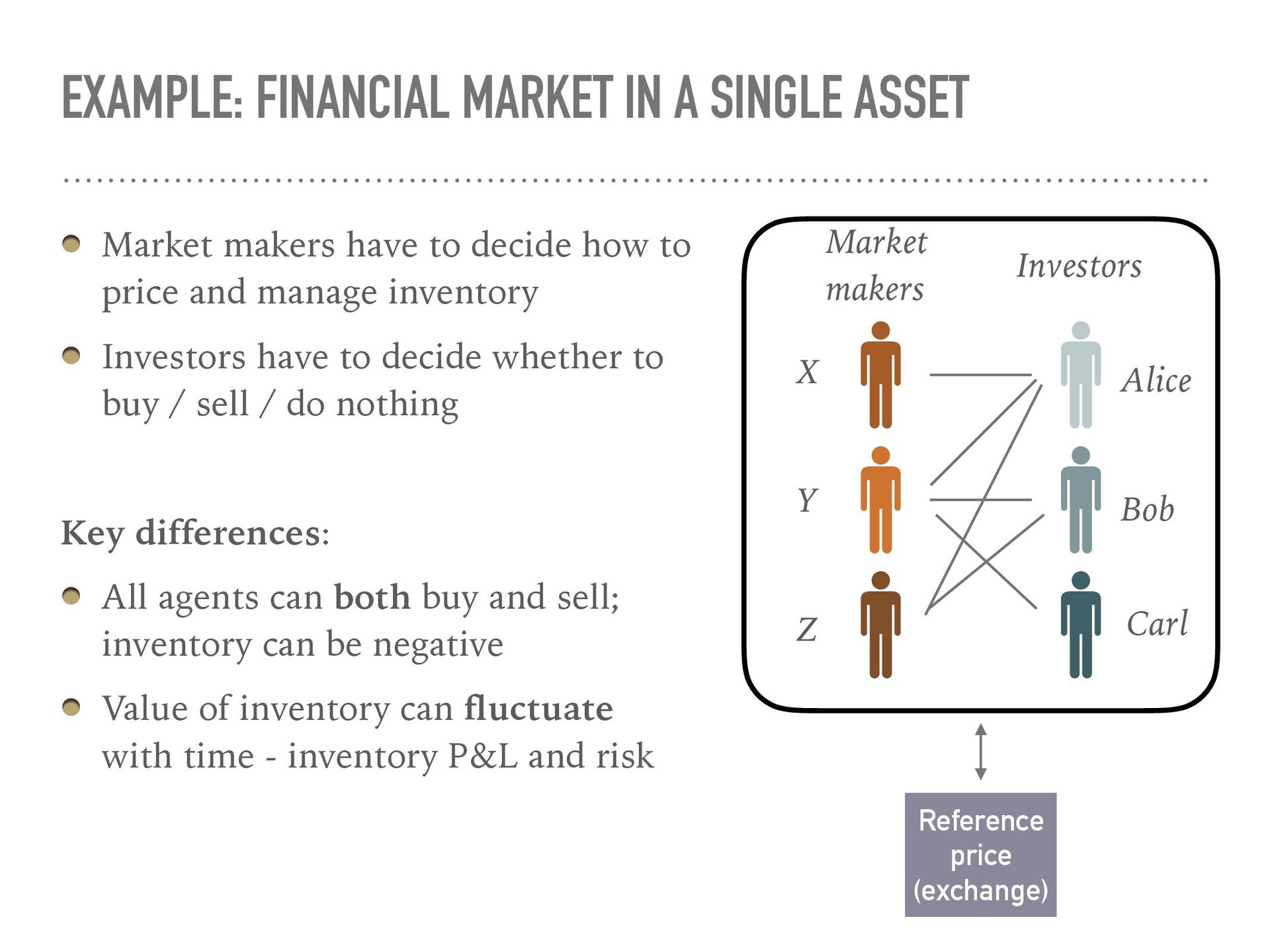{kind=link}
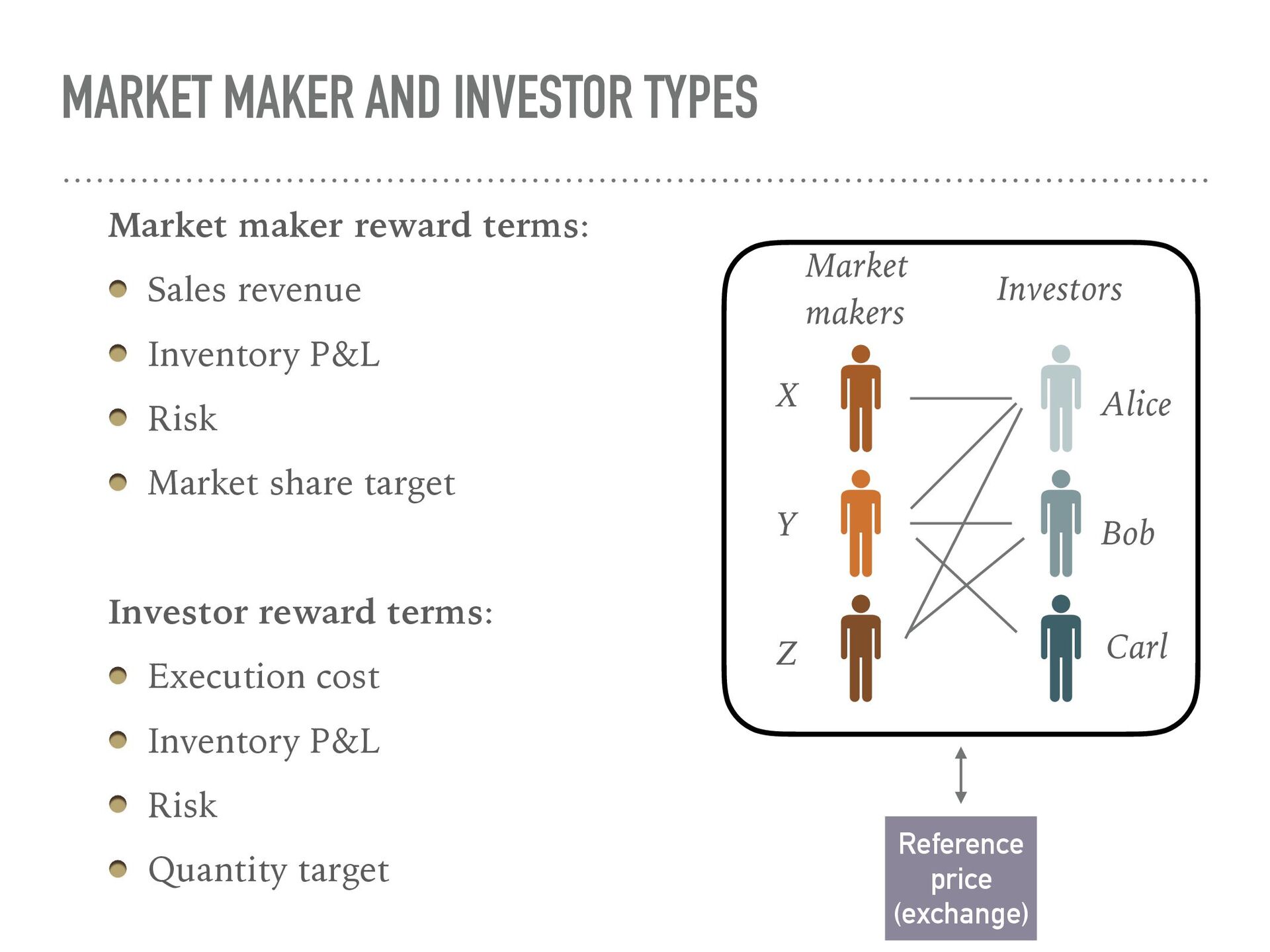{kind=link}
{kind=link}
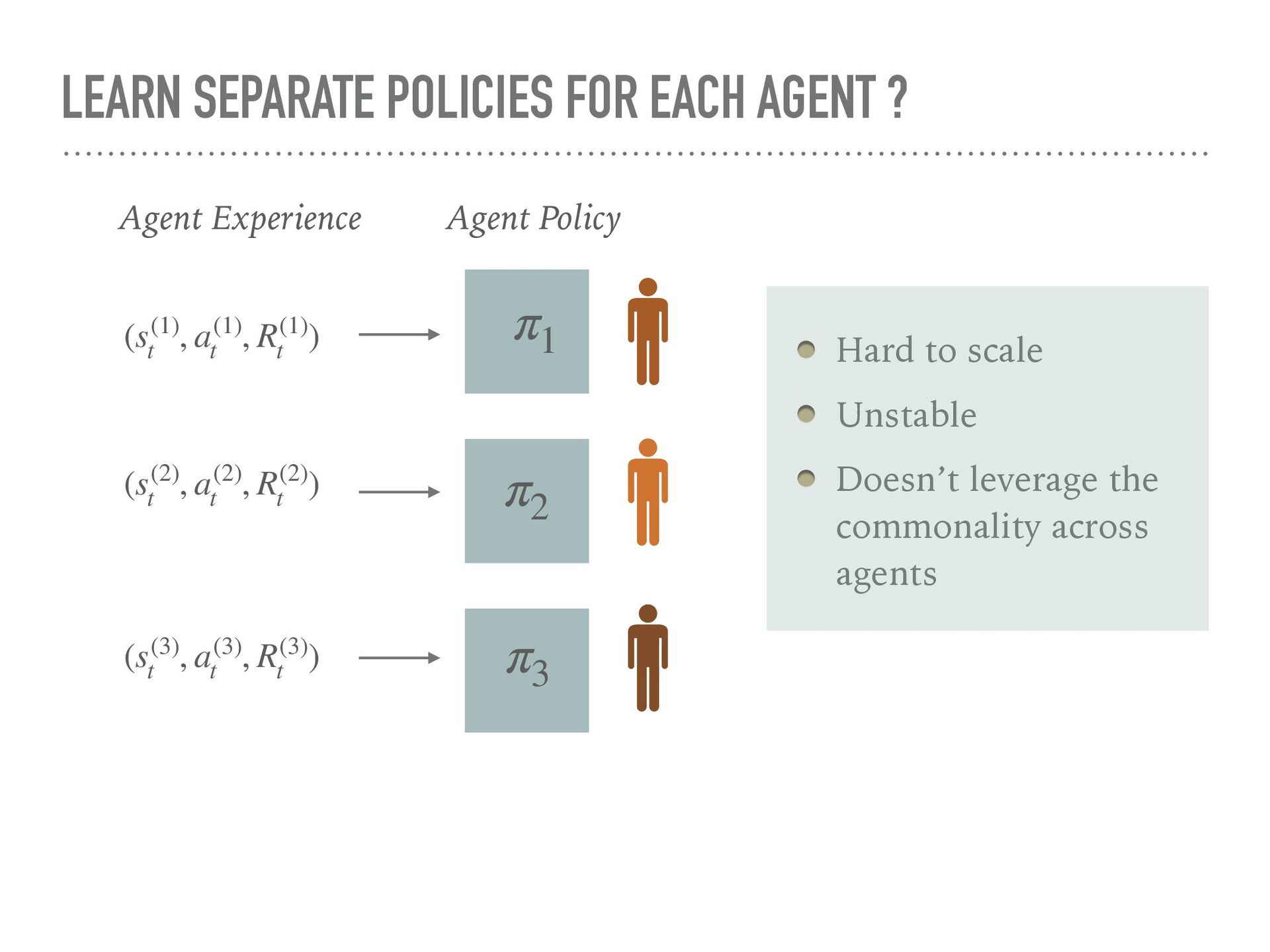{kind=link}
{kind=link}
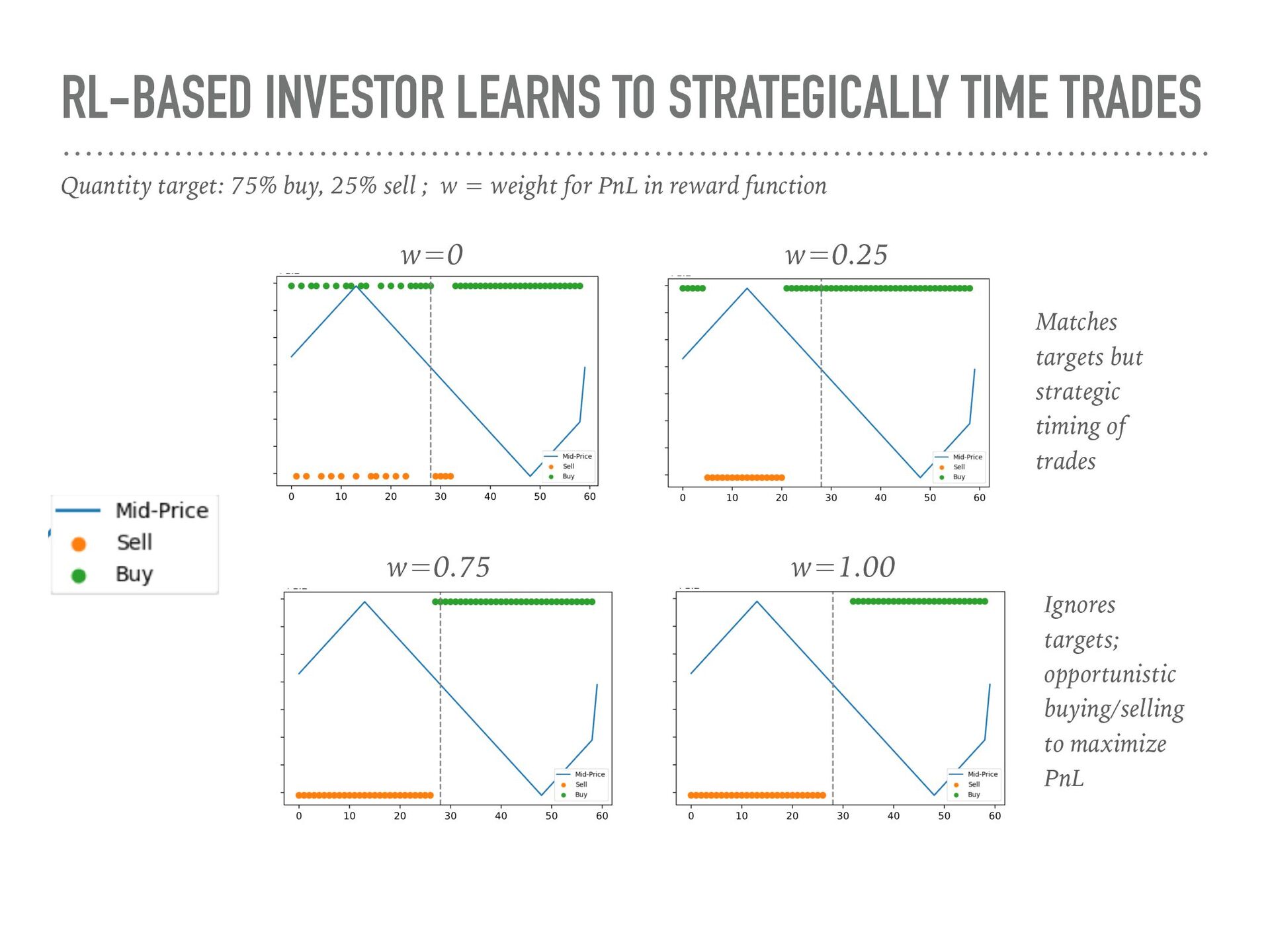{kind=link}
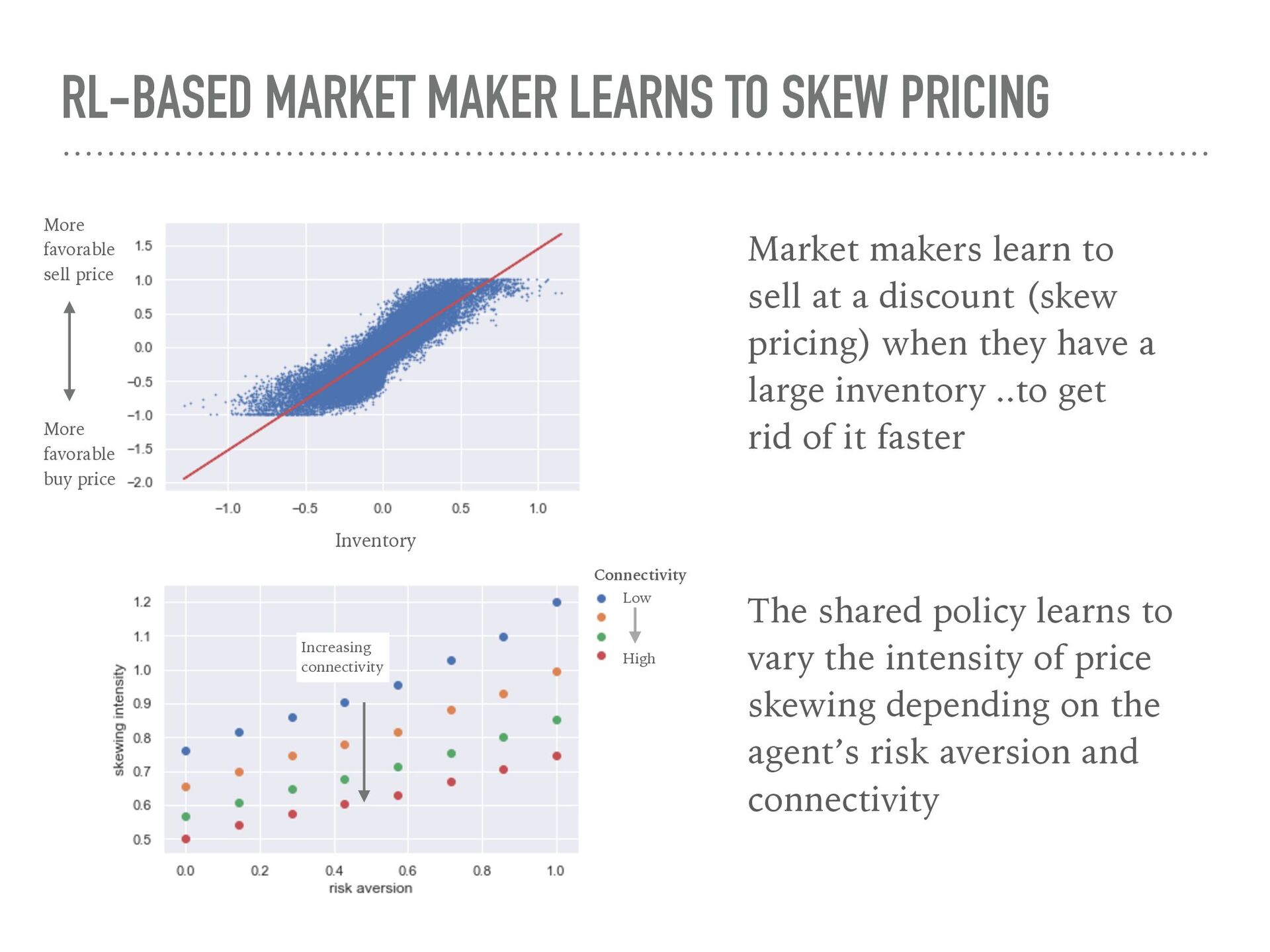{kind=link}
{kind=link}
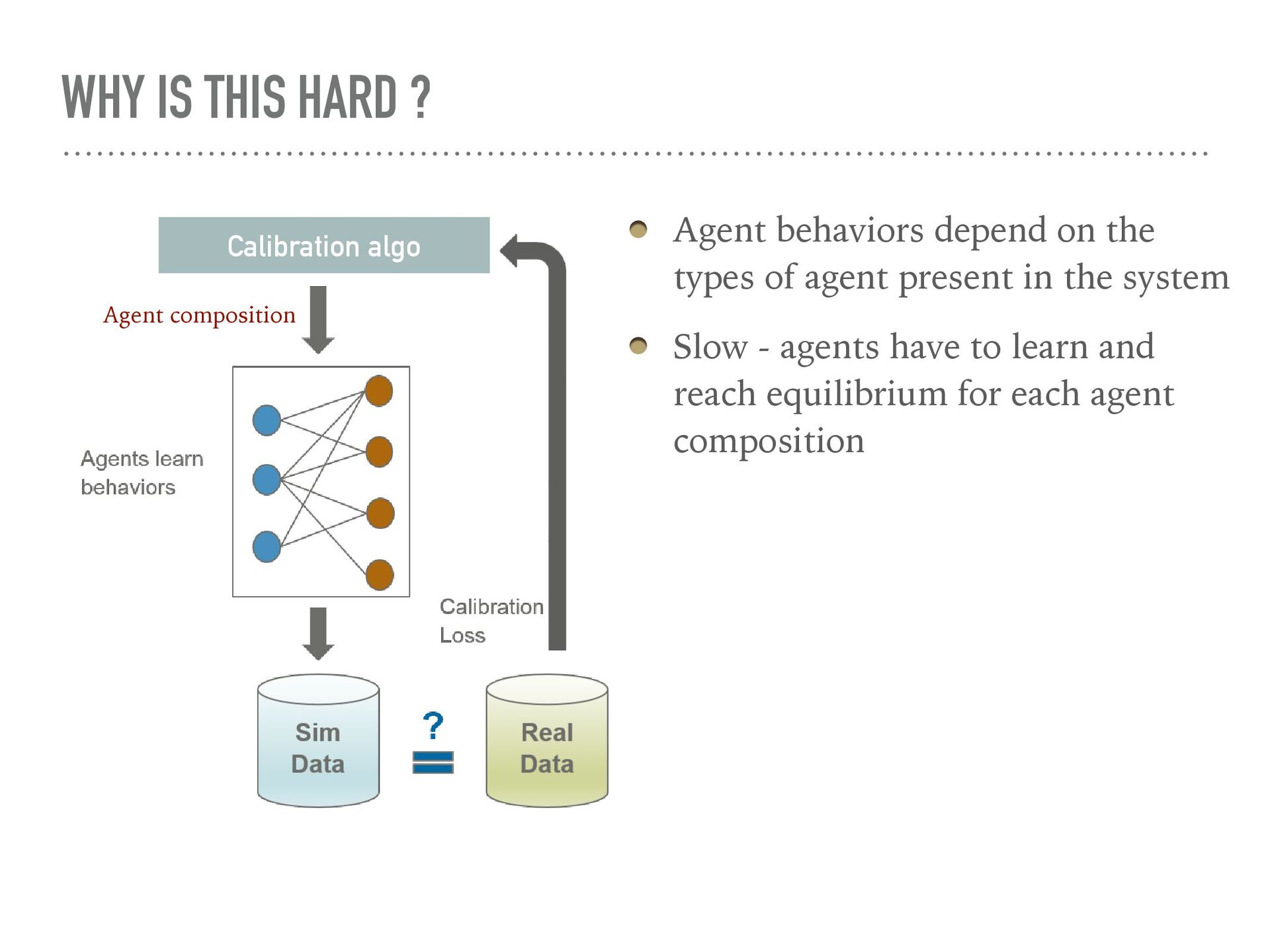{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}