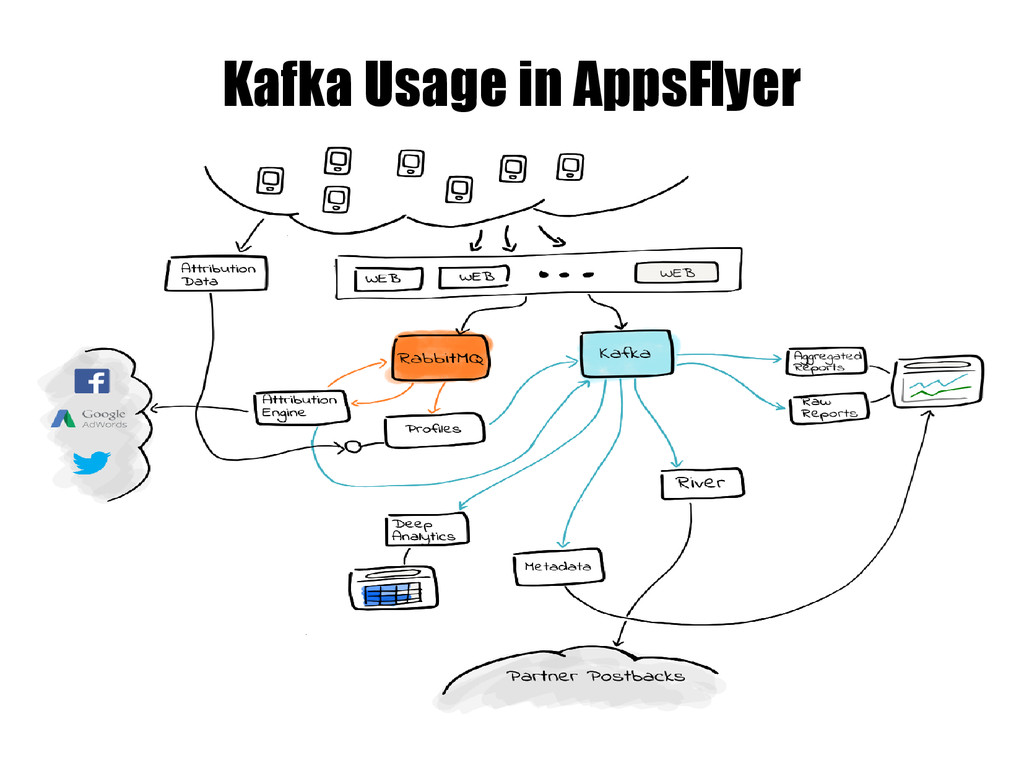
AppsFlyer • AppsFlyer First Cluster • Designing The Next Cluster: Requirements And Changes • Problems With The New Cluster • Changes To The New Cluster • Traffic Boost, Then More Issues • More Solutions • And More Failures • Splitting The Cluster, More Changes And The Current Configuration • Lessons Learned • Testing The Cluster • Collecting Metrics And Alerting
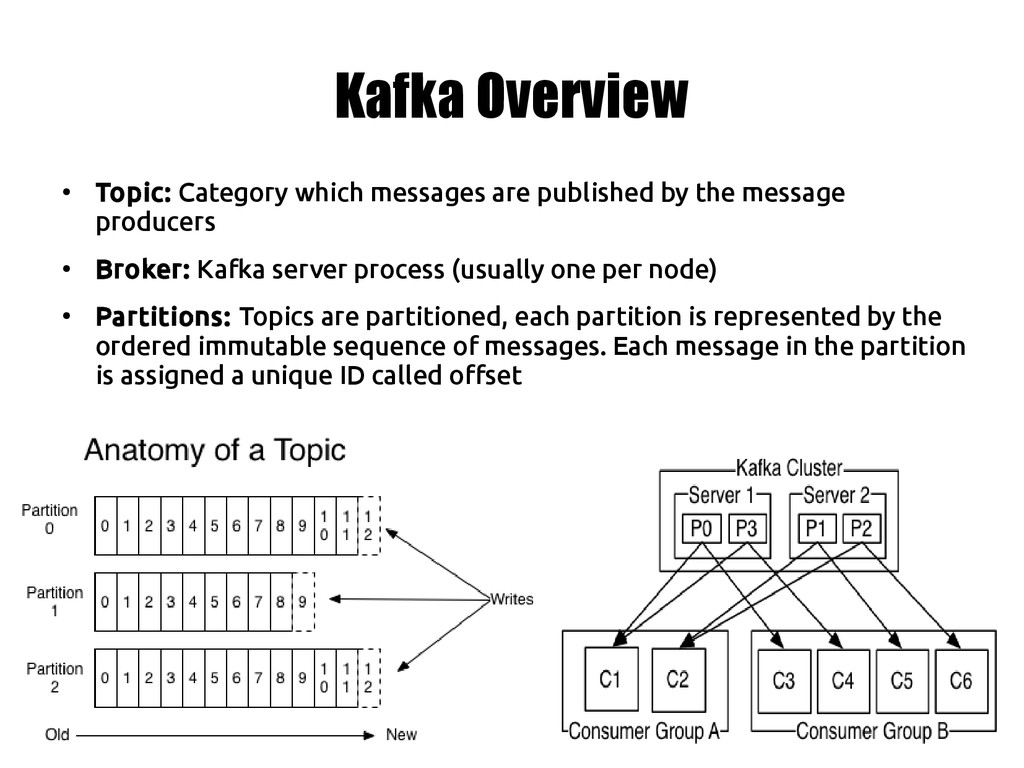
the message producers • Broker: Kafka server process (usually one per node) • Partitions: Topics are partitioned, each partition is represented by the ordered immutable sequence of messages. Each message in the partition is assigned a unique ID called offset
• Size: 4 M1.xlarge brokers • ~8 Topics • Replication factor 1 • Retention 8-12H • Default number of partitions 8 • Vanilla configuration Main reason for migration: Lack of storage capacity, limited parallelism due to low partition count and forecast for future needs.
Billions of messages • Messages replication to prevent data loss • Support loss of brokers up to entire AZ • Much higher parallelism to support more consumers • Longer retention period – 48 hours on most topics
AZ • Replication factor of 3 • All partitions are distributed between AZ • Topics # of partitions increased (between 12 to 120 depends on parallelism needs) • 4 Network and IO threads • Default log retention 48 hours • Auto Leader rebalance enabled • Imbalanced ratio set to default 15% * Leader: For each partition there is a leader which serve for writes and reads and the other brokers are replicated from * Imbalance ratio: The highest percentage of leadership a broker can hold, above that auto rebalance is initiate Glossary
on specific brokers and eventually lag in consumers and brokers failures • Constantly rebalanced of brokers leaders which caused failures in python producers
80% of messages and all the rest • Move launches cluster to i2.2xlarge with local SSD • Finer tuning of leaders • Increase number of IO and Network Threads • Enable AWS enhanced networking
in Launches cluster to reduce load on leaders, reduce disk capacity and AZ traffic costs • Move 2nd cluster to i2.2xlarge as well • Upgrade ZK due to performance issues
extra load on the Leaders • Make sure that leaders count is well balanced between brokers • Balance partition number to support parallelism • Split cluster logically considering traffic and business importance • Retention (time based) should be long enough to recover from failures • In AWS, spread cluster between AZ • Support cluster dynamic changes by clients • Create automation for reassign • Save cluster-reassignment.json of each topic for future needs! • Don't be to cheap on the Zookeepers
• Broker failure while running • Entire AZ failure while running • Reassign partitions on the fly • Kafka dashboard contains: Leader election rate, ISR status, offline partitions count, Log Flush time, All Topics Bytes in per broker, IOWait, LoadAvg, Disk Capacity and more • Set appropriate alerts
sending metrics to graphite • Internal application that collects Lag for each Topic and send values to graphite • Alerts are set on Lag (For each topic, Under replicated partitions, Broker topic metrics below threshold, Leader reelection
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}