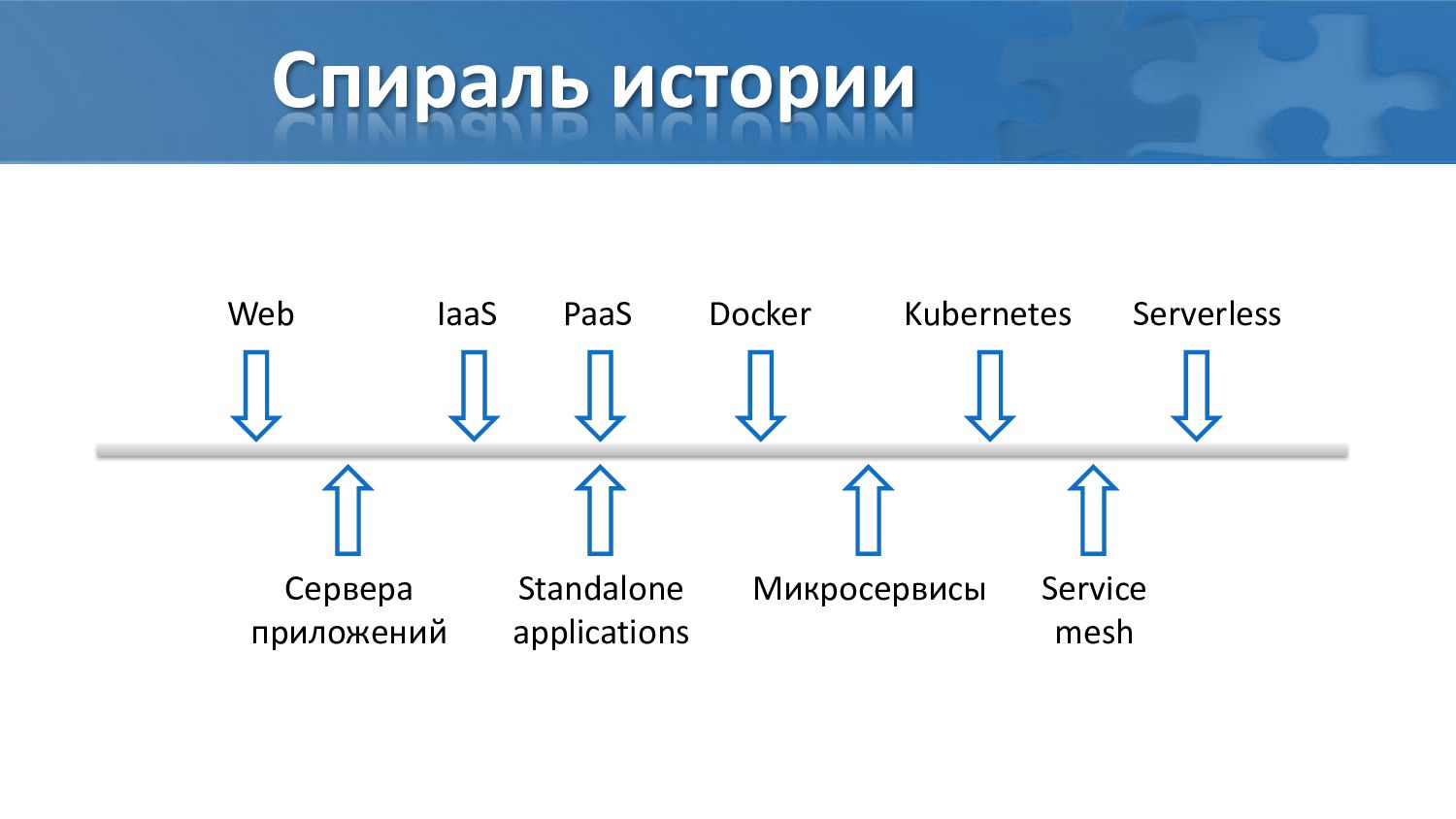
Задача мониторинга приложений далеко не новая. Однако каждый виток развития IT инфраструктуры радикально меняет требования к мониторингу. Зачастую при этом культура мониторинга откатывается на годы назад.
Контейнеры, кubernetes, микросервисы - актуальные принципы построения IT систем сегодня.
• В должен включать в себя мониторинг приложений?
• Какие инструменты доступны для организации мониторинга сегодня?
• Что нужно мониторить в JVM?
• Как выглядит, идеальный стек мониторинг и телеметрии в эпоху облаков?
Это основные вопросы, которые будет освещены в рамках доклада.
![Мониторинг Java приложений в эпоху облаков [email protected] Алексей Рагозин Ижевск,](https://files.speakerdeck.com/presentations/0b715d5472b8495181a927e802547fae/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Спасибо! Алексей Рагозин [email protected] https://blog.ragozin.info](https://files.speakerdeck.com/presentations/0b715d5472b8495181a927e802547fae/slide_27.jpg){kind=link}