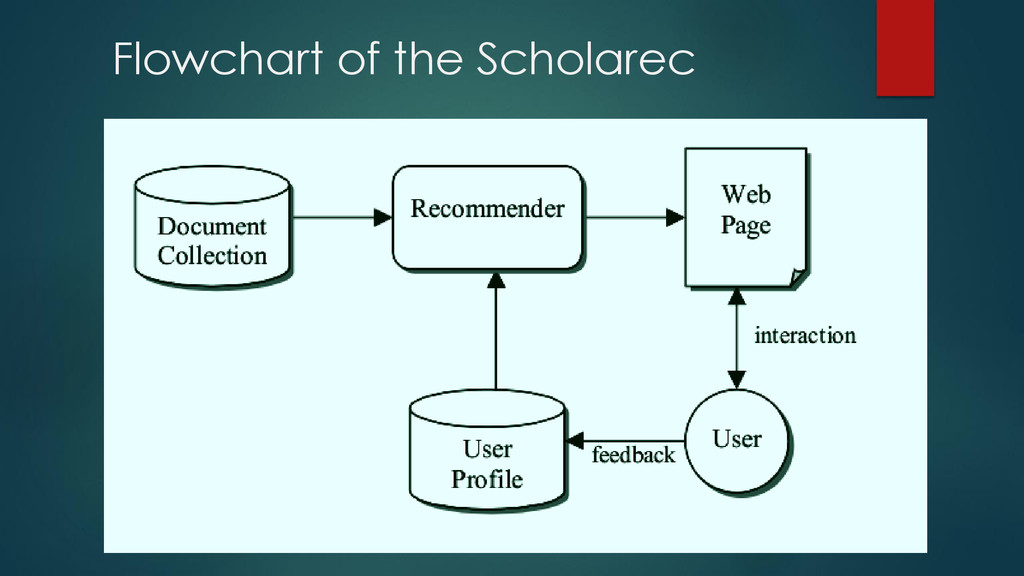
of suggesting items to purchase or examine. Through this project we have tried to address this problem by providing recommendation results by using latent information about the user's research interests that exists in their publication list. The datasets can be used for other purposes such as classification, clustering, trend analysis.
Articles, Reports and other scholarly works. Seamless extension to current online repositories of Scholarly Articles Robust Back-end search engine Interactive User Interface Personalization through OpenID and Oauth integration Recommendations based on user's interests.
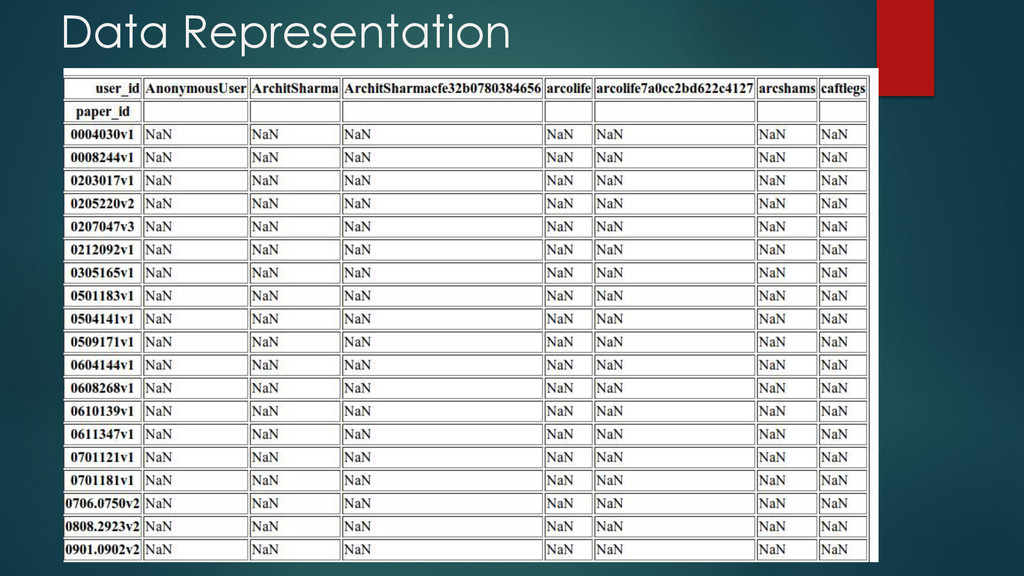
Each item's content is a set of identifiers. Content-based Filtering tries to estimate ratings for the user based on user's history. This is the generalization of the aggregation functions used for content based filtering.
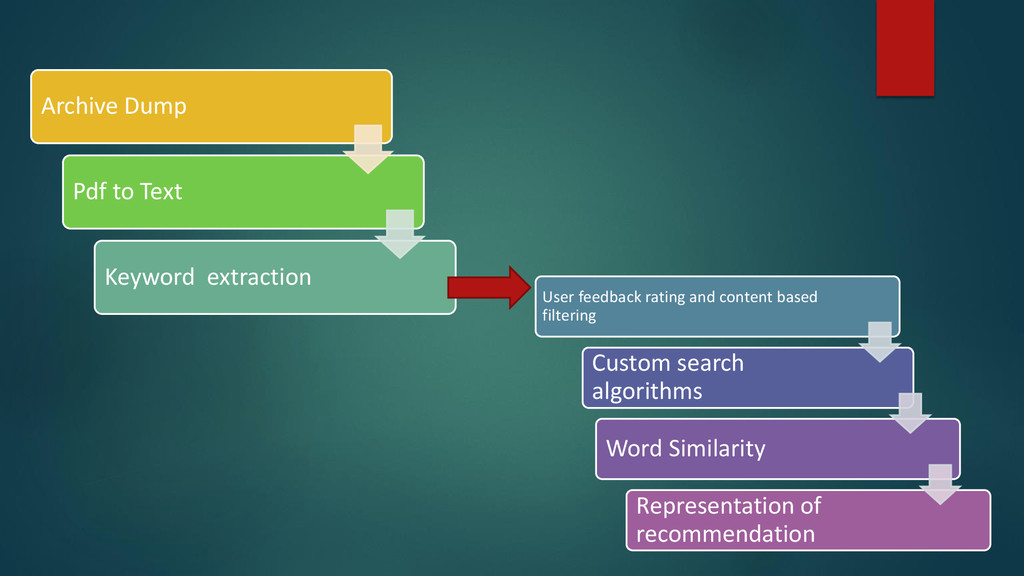
heart of recommendation Tf-IDf algorithm: Searching purpose Matrix factorization: Table generation / operations on matrix Bag of words Approach: Field suggestion Reg -ex based algorithm: Parsing through Lucene/ElasticSearch Word similarity/ implicit algorithms: Keyword suggestion
science in October 2013 • Developer: Alexander Weber • Alexa Rank: 8,715 (April 2014 • Arxiv.org • 939,001 e-prints in Physics, Mathematics, Computer Science, Quantitative Biology, Quantitative Finance and Statistics • Creator: Paul Ginsberg • Owner: Cornell Library • Submission rate is more than 7000 per month. • scholar.google.com • bibliographic database • Owner : Google Inc • High weight on citation counts • First search results are often highly cited articles • Google Scholar index includes most peer- reviewed online journals Comparison
![Recommender System for scholarly articles Archit Sharma [email protected] http://work.arcolife.in](https://files.speakerdeck.com/presentations/0cc0cab0d3200131cd594eace499ef8a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}